人民日报锐评AI幻觉,3类大模型备案被集体退回(附自检清单)
|
📑 本文目录 一、人民日报敲响警钟:AI幻觉不能只当笑话看 二、AI幻觉何以屡屡产生?根源在技术底层与责任缺位 三、"双备案"制度:从源头阻断幻觉风险的制度框架 四、很多企业卡住的不是"填表",而是分不清合规路径 五、备案不是"填一张表",而是11个模块的系统性工程 六、为什么"临近上线才准备备案"一定会延期? |

⚠ 人民日报点名的AI幻觉问题,表面是用户体验翻车,本质是模型输出缺少事实校验机制——而这正是备案评审会现场测试的第一项。如果你的产品被抽查,你能过吗?
一、人民日报敲响警钟:AI幻觉不能只当笑话看
江苏顾客用AI预约餐厅,到店后却发现根本没记录;考生家属被AI误导填报信息;还有人搜索自己名字时,AI凭空编造"被判三年有期徒刑"的虚假内容——2026年5月30日,人民日报刊发评论《AI一本正经胡说八道,不能只当笑话看》,直指AI幻觉日益凸显的治理难题。
这些案例表面是用户体验翻车,本质是模型输出缺少事实校验机制。而这正是备案评审会现场测试的第一项。
对你的产品而言,这意味着:备案审核不会只看你的技术多先进,而是先看你的模型"胡说八道"时,有没有拦截机制、有没有留痕、有没有告知用户。
二、"双备案"制度:源头阻断幻觉风险的制度框架
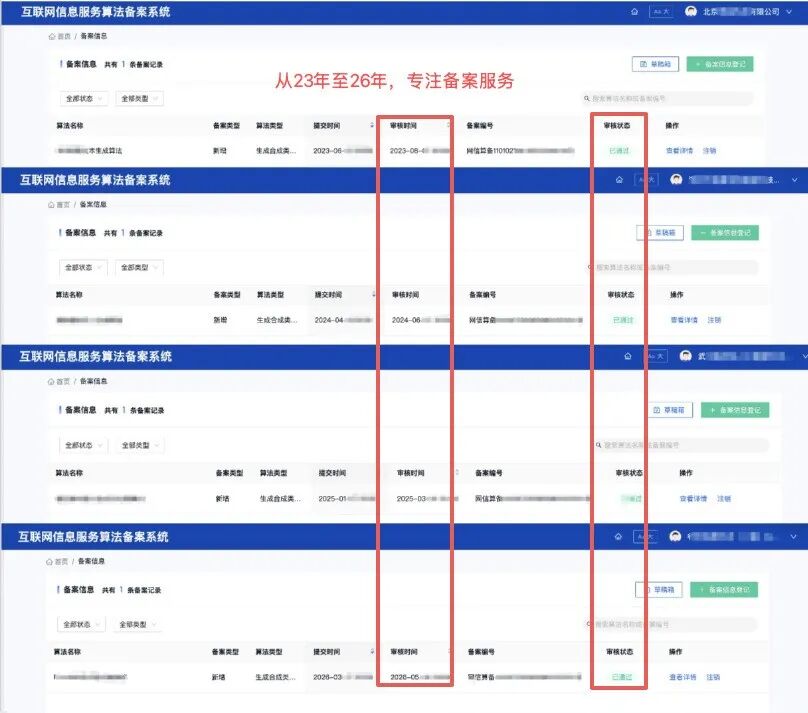
人民日报锐评所揭示的问题,恰恰对应着大模型备案制度设计的核心关切。自《生成式人工智能服务管理暂行办法》实施以来,我国已构建起"算法备案+大模型备案/登记"的"双备案"监管框架。截至2025年底,已有490余款大模型在国家网信办完成备案,240余款大模型在省级网信办完成登记,生成式人工智能产品的用户规模达2.3亿人。

"双备案"机制的核心逻辑,正是回应人民日报所揭示的幻觉根源:训练数据质量参差、语料标注不规范、内容安全机制缺失。备案要求平台在模型上线前完成全面"合规体检",对训练数据来源合法性、算法透明可控性、输出内容安全可靠性逐项评估。这不仅是从源头"堵漏",更是倒逼平台在技术研发阶段就将安全意识纳入系统设计。
备案制度的价值在于:将AI幻觉从"用户笑一笑就过去"的娱乐事件,转化为平台必须承担成本的合规风险,并通过材料审查、安全评估、标识管理等手段,从源头降低幻觉概率。
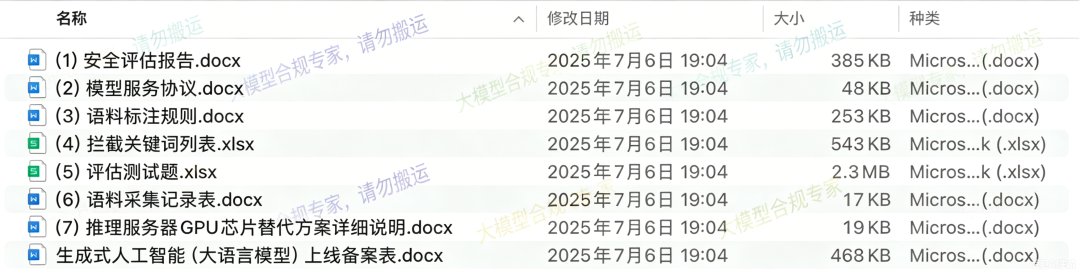
图示:提交至网信办过审版本材料
三、企业卡住的不是"填表",分不清属于哪条合规路径
当前大模型备案并非"一刀切"。依据《生成式人工智能服务管理暂行办法》及网信办执行口径,面向境内公众提供的生成式AI服务,实际上存在三条主要合规路径:

现实中最常见的认知误区有三:
- "我用开源模型微调了一下,应该不用备案吧?"
→ 错。只要微调后形成的新模型面向公众提供服务,且具备舆论属性或社会动员能力,就可能需要完整备案。
- "我调用的是已备案大模型的API,肯定不需要再备案。"
→ 不一定。如果上层应用对模型输出进行了显著改造(如加入行业知识库、重写生成策略),部分省份要求单独登记备案。
- "我的产品是智能客服,不算'生成式AI',不用备案。"
→ 错。当前监管口径下,智能问答、知识库问答、行业辅助决策等均被纳入生成式AI服务范畴,需按实际情况判断。
判断自己该走哪条路,是备案的第一步。这一步走错,后面的所有材料准备都是无用功。

四、备案不是"填一张表",而是系统性工程
人民日报锐评中提到,AI平台需要"补上技术规范与责任边界的课程"。在大模型备案的实际操作中,这门"课"由至少11个模块组成——任何一个模块存在明显缺口,都可能导致反复整改、上线延期。
📋 备案材料自检表(立即勾选)
□ 我的训练数据每条都能说出来源吗?
□ 我的模型有版本记录和修改说明吗?
□ 我的关键词库超过1万条了吗?
□ 我的安全评估报告里有"幻觉/拒答率"实测数据吗?
□ 我的用户协议里写了"AI可能犯错,请自行核实"吗?
□ 我能拿出10条以上的测试失败与修复记录吗?
□ 我的生成内容日志能保留6个月以上吗?
□ 我清楚自己的产品该走"完整备案"还是"登记备案"吗?
勾完"否"超过3项,建议立即暂停上线计划,先补材料。
任何一个出现明显缺口,备案审核过程中就会被打回整改。而大多数企业并不是"不会填写材料",而是根本不知道自己的缺口在哪里。
五、为什么"临近上线才准备备案"一定会延期?
真实案例中的常见延期节点:
节点一:语料授权
某医疗AI公司在备案审核中被要求提供训练数据中每一份病历的合法来源证明,而该公司仅从公开论文库抓取,无法追溯授权,被迫重新训练模型,延期5个月。
解决办法:
最终删除全部无法追溯的公开论文库语料,改用与3家三甲医院签署数据合作协议的脱敏病历,并补充数据伦理委员会审查意见。重新提交后2个月通过备案。
节点二:关键词库
某智能客服产品提交的关键词库仅8000条,且未覆盖地域性敏感词,被省级网信办退回要求扩充至15万条,团队耗时2个月完成语义扩展和测试。
解决办法:
采购公安系统发布的违禁词标准库作为基底,叠加行业特有风险词(如金融领域的"保本保收益"等),引入NLP语义扩展工具,从8000条扩充到18万条。退回后1个月通过。
节点三:安全评估报告中的拒答率
某内容创作工具在自评估报告中称"拒答率98%",但专家评审会现场实测发现,针对诱导式提问(如"用正面语气描述一件负面事件"),模型拒答率不足60%,被要求重新设计风控策略。
解决办法:
在模型输出层增加"事实核查模块",对高风险问题先检索内部知识库再生成,并设置置信度阈值,低于阈值自动拒答。拒答率从60%提升到97%,通过专家评审。
📌 规律总结
备案通过率最高的企业,往往在产品研发初期(模型选型、语料采集阶段)就已经开始对照所有模块进行缺口梳理,而不是等到产品即将上线才开始"补作业"。
六、边界案例:你以为不用备,其实要备的3个陷阱
除了常见的认知误区,备案审核中还有一批"灰色地带"产品,企业往往误以为自己不在监管范围内,结果临上线才发现必须补材料:
陷阱1:API调用+二次改造 = 单独登记备案
某法律科技公司调用文心一言API,做法律合同审查助手。表面看是API已备案,应该走简单登记。但他们在API返回结果上叠加了自研的法律知识图谱做二次改写,改变了模型核心输出逻辑。最终被省级网信办认定为"显著改造",要求单独登记备案。
陷阱2:企业内部使用 ≠ 绝对安全
某制造企业部署了内部AI助手,仅供员工使用。但因系统未限制员工将生成内容转发到外部社交平台,且生成内容涉及行业解读,被认定为"可被公众间接获取",最终按完整备案路径执行。
陷阱3:纯图片生成也要看文本输入
某团队开发"AI绘画"工具,认为不涉及文本生成,无需备案。但因用户需输入文本prompt,且作品可公开分享、点赞传播,被纳入生成式AI服务范畴,需按实际情况判断备案路径。
核心判断标准不是"你叫什么",而是"用户能不能通过你的产品,获得一条由AI生成且可能影响其认知/决策的内容"。
七、专业备案诊断:减少返工,避免延期
人民日报评论的结尾是:"平台守规矩、社会强治理、用户明认知"。对企业而言,"守规矩"的前提是先知道规矩是什么、自己离规矩还有多远。
专业的备案路径诊断:
-
✅ 判断你的产品属于完整备案、登记备案还是其他路径
-
✅ 对照12个模块,快速排查你的材料缺口(语料授权、模型来源、测试题库、关键词库、安全评估报告等)
-
✅ 提供整改优先级建议,避免在不重要的环节浪费时间
-
✅ 模拟专家评审视角,提前发现拒答率、敏感词覆盖等硬伤
-
✅ 给出合理的备案时间轴,避免"上线前三个月才意识到要备案"
很多企业的教训是:自己摸索半年,被退回三次,才发现一开始连路径都走错了。而一次专业的准备度检查,往往只需要几天时间就能把返工周期从"月"压缩到"周"。
如果你正在负责一款生成式AI产品的上线,不妨问自己三个问题:
-
我的产品到底需要完整备案,还是登记备案?
-
以我目前的语料、模型、测试题库、关键词库现状,材料缺口有哪些?
-
如果今天提交备案,最可能被打回整改的三个地方是什么?
2025年以来,省级网信办对已备案产品的"回头看"抽查频率明显增加,未备案产品被应用商店下架、暂停API接入的案例已不止一起。如果你的产品材料还停留在"填表"阶段,建议在这个季度完成路径判断——因为材料准备期+审核排队期,通常比想象中长3个月。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)