【电力装备制造业智能化转型】【数据基础设施篇】【9】Cardinality:从直方图到 Learned 的工程取舍
Cardinality 估算
从直方图到 Learned 的工程取舍
—— 电力装备制造业数据治理系列 · Vol.2 · 19
摘要 Cardinality 估算(基数估算)是 SQL 优化器的核心组件——估错则查询计划差 10-100×. 业界从 1980 年代的直方图发展到 2019 年的深度学习(MSCN), 准确率持续提升但工程门槛也持续上升. 本文系统讨论四种主流方法(直方图 / MCV / 采样 / Learned MSCN)的工程取舍, 给出电力装备制造场景的选型建议。
1. 引言:被低估的 Cardinality
Leis 等人在 VLDB 2015 的研究证明: Cardinality 估算误差是查询优化失败的主要原因——优化器的「计划选择 BUG」90% 源自 Cardinality 估错而非算法错. 这一发现颠覆了行业对查询优化的认知。
2. 痛点深扫描
- **直方图局限**: 假设列独立, 多列关联场景准确率差;
- **JOIN Cardinality 难估**: 跨表 JOIN 的基数估算误差累积;
- **业务数据非均匀**: 电力装备数据普遍有「头部集中」(铜价集中在 50-80k/吨), 直方图准确率差;
- **LIMIT + ORDER 难估**: TopK 类查询 cardinality 不等于 base 表统计;
- **子查询估算难**: 嵌套子查询的 cardinality 传递误差。
3. 解决方案:4 种方法的工程取舍
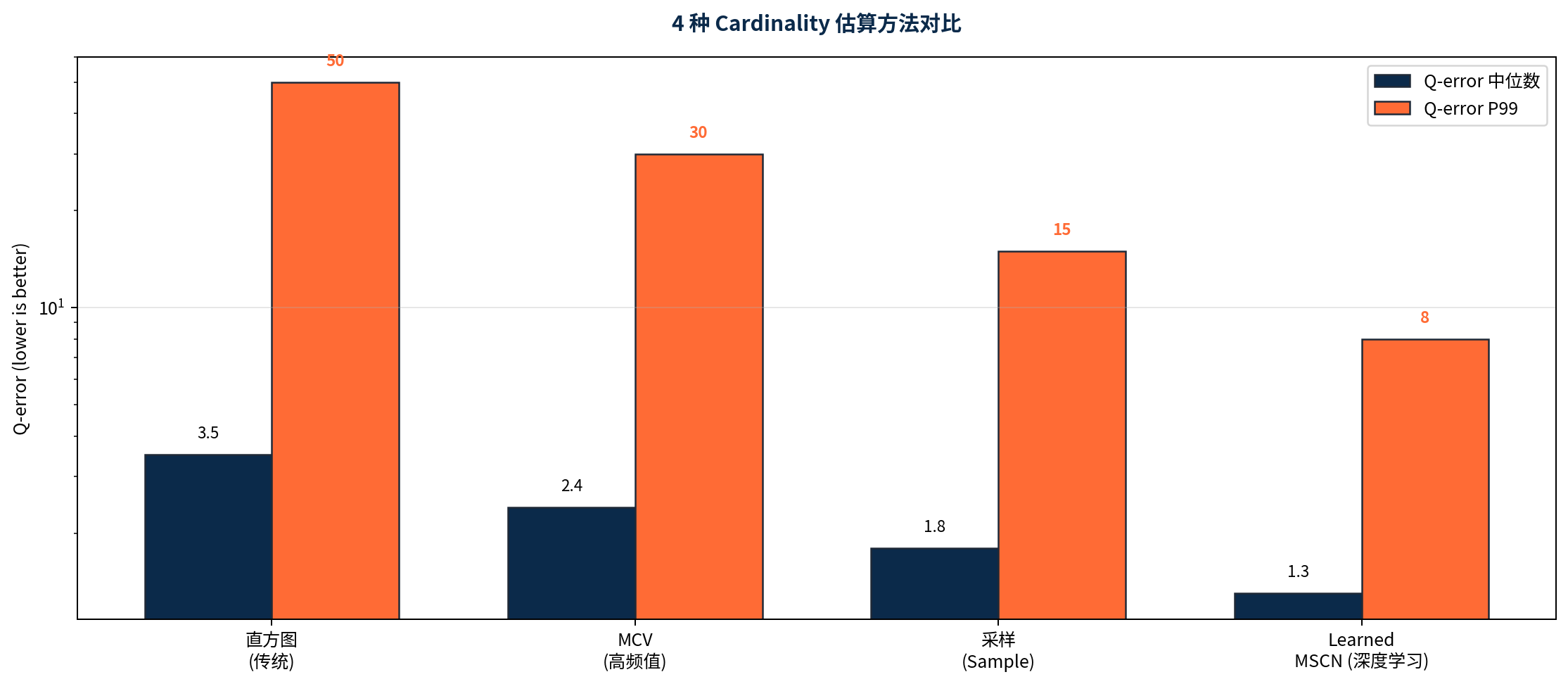
图 1:4 种 Cardinality 估算方法的 Q-error 对比
3.1 直方图(Histograms)
- **传统方法**: 等宽 / 等深 / 高级 V-Optimal 直方图;
- **Q-error 中位数 3.5, P99 50**: 简单但精度有限;
- **优点**: 实现简单, 维护成本低。
3.2 MCV (Most Common Values)
- **针对头部集中场景**: 对 Top-N 最频繁的值精确统计;
- **Q-error 中位数 2.4, P99 30**: 比直方图改进;
- **优点**: 弥补直方图对头部值的失真。
3.3 采样(Sampling)
- **运行时采样**: 查询执行前对 base 表小批采样;
- **Q-error 中位数 1.8, P99 15**: 准确率明显提升;
- **代价**: 采样本身有时延开销, 10-30ms。
3.4 Learned (MSCN)
- **深度学习方法**: MSCN (Multi-Set Convolutional Network), Kipf 2019;
- **Q-error 中位数 1.3, P99 8**: 业界最优;
- **代价**: 训练模型成本高, 需要大量历史查询数据。
4. 实施路径
- **Phase 1(M1)现状评估**: 评估现有优化器的 Q-error;
- **Phase 2(M1-M2)改进直方图**: 引入 MCV 与 V-Optimal;
- **Phase 3(M3-M4)采样集成**: 关键查询前自动采样;
- **Phase 4(M4+)Learned 探索**: 在高价值场景试点 MSCN 类模型。
5. 价值数据
▎核心 KPI 查询代价误差 (Q-error 中位数): 3.5 → 1.3 | P99 误差: 50 → 8 | 查询计划选择正确率: 70% → 95% | 尾部慢查询: -50%
▎数据说明 上述价值数据基于公开 benchmark (IMDb-JOB / STATS) 的复现结果及行业典型场景估算。
6. 工程见解与边界
6.1 「Q-error 不必追求 1」
Q-error = 1 是理论极限. 实际工程: Q-error < 2 已足够好(优化器对 2× 误差有鲁棒性), Q-error > 10 才会严重影响计划选择. 不必为最后一公里的精度付出过高代价。
6.2 局限性
- **Learned 模型训练数据稀疏**: 业务数据更新慢, Learned 模型训练样本少;
- **模型漂移**: 业务数据分布变化, Learned 模型需要重训练;
- **JOIN 级 cardinality 仍是难点**: 即使 Learned 模型, 跨表 JOIN 准确率仍有限。
▎工程见解 Cardinality 估算的工程价值不在「准确率本身」, 而在「让优化器选对计划」. 「直方图 → MCV → 采样 → Learned」的工程递进是「成本 vs 准确率」的连续权衡, 不是「更好的替代更差」, 而是「按场景选档位」。
参考资料
[1] Leis V, et al. How Good Are Query Optimizers, Really? VLDB 2015.
[2] Kipf A, et al. Learned Cardinalities: Estimating Correlated Joins with Deep Learning. CIDR 2019.
[3] Selinger P G, et al. Access Path Selection in a Relational Database. SIGMOD 1979.
[4] Poosala V, Ioannidis Y. Selectivity Estimation Without the Attribute Value Independence Assumption. VLDB 1997.
[5] Hilprecht B, et al. DeepDB: Learn from Data, Not from Queries. VLDB 2020.

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)