预警比告警早 23 分钟:时序异常检测与大模型辅助的故障预警实践
·
预警比告警早 23 分钟:时序异常检测与大模型辅助的故障预警实践
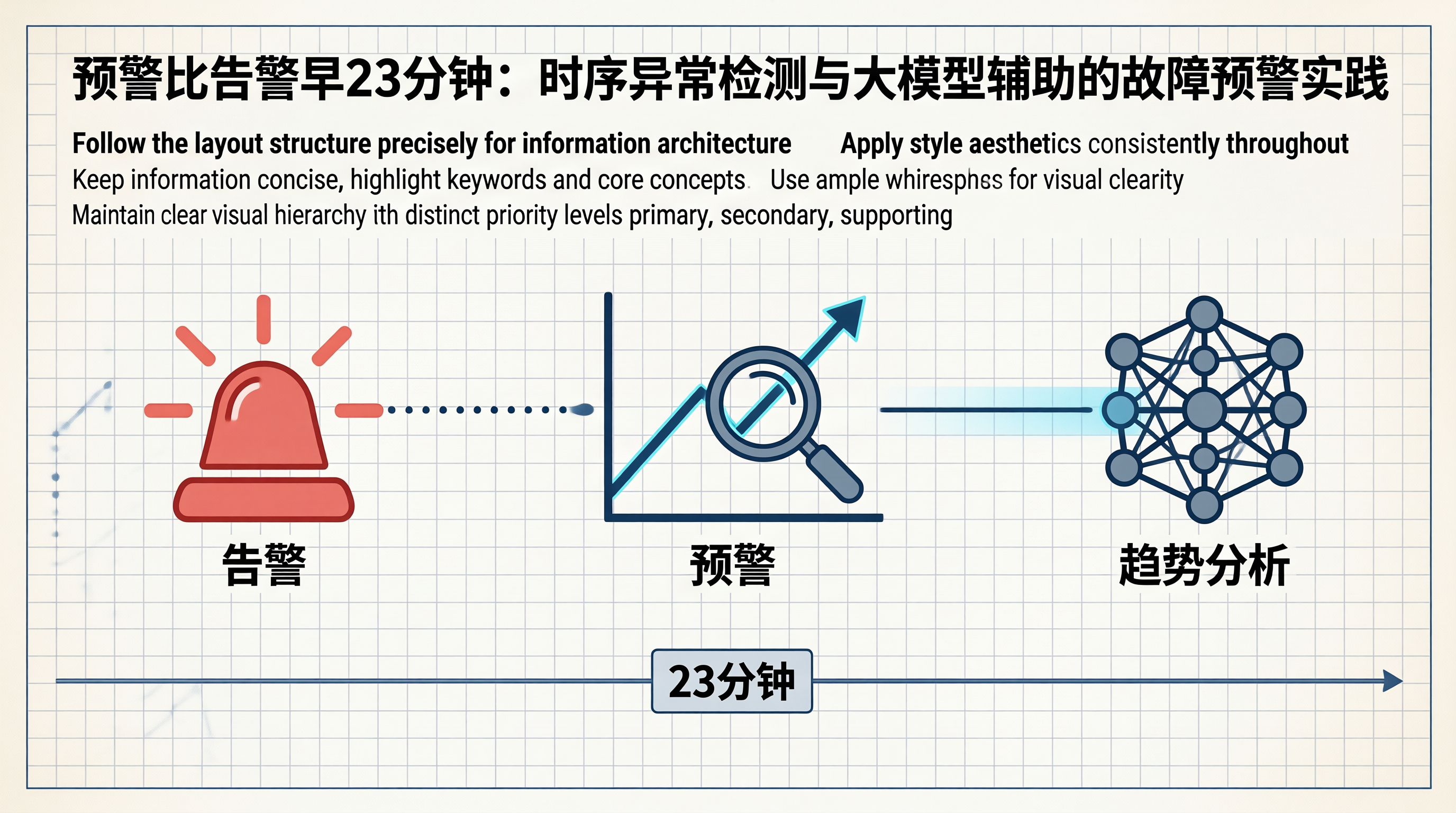
一、 从告警到预警:思维模式的转变
1.1 告警和预警的区别
| 维度 | 告警 (Alert) | 预警 (Warning) |
|---|---|---|
| 触发条件 | 阈值超标 | 趋势异常 |
| 发现时机 | 故障已发生 | 故障即将发生 |
| 信息量 | "CPU > 90%" | "CPU 过去 30 分钟持续上升" |
| 紧急程度 | 需要立即响应 | 可以评估后处理 |
| 价值 | 止损 | 预防 |
1.2 预警系统的架构
flowchart TD
A["Prometheus"] --> B["时序异常检测"]
B --> C["预警事件"]
C --> D["LLM 分析引擎"]
D --> E["严重性判断"]
E --> F["P0/P1: 实时通知"]
E --> G["P2/P3: 聚合日报"]
核心差异在于:预警系统不依赖阈值,而是通过机器学习检测数据的趋势变化和模式偏离。
二、 时序预警检测的三层模型
2.1 第一层:短周期趋势检测(5-15 分钟窗口)
# short_trend_detector.py — 短周期趋势检测
import numpy as np
from sklearn.linear_model import LinearRegression
class ShortTrendDetector:
"""短周期趋势检测:捕捉 5-15 分钟内的变化趋势"""
def detect_trend(self, series: np.ndarray) -> dict:
"""检测短期趋势"""
X = np.arange(len(series)).reshape(-1, 1)
y = series.values.reshape(-1, 1)
model = LinearRegression()
model.fit(X, y)
slope = model.coef_[0][0]
r2 = model.score(X, y)
# 斜率为正说明上升趋势,为负说明下降
# R²越高说明趋势越显著
trend_strength = abs(slope) * r2
return {
'slope': slope,
'r_squared': r2,
'trend_strength': trend_strength,
'prediction': model.predict([[len(series)]])[0][0], # 预测下一个值
'direction': 'up' if slope > 0 else 'down',
'severity': 'high' if trend_strength > 0.5 else (
'medium' if trend_strength > 0.2 else 'low')
}
# 使用示例
detector = ShortTrendDetector()
# 每 1 分钟检测一次 CPU 使用率的趋势
cpu_values = get_metric('node_cpu_seconds_total{mode="idle"}', window='15m')
result = detector.detect_trend(cpu_values)
if result['direction'] == 'down' and result['severity'] == 'high':
# CPU 空闲率持续下降(使用率持续上升)
send_warning('CPU 使用率持续上升',
f'斜率:{result["slope"]:.2f}, 预测下一个值:{result["prediction"]:.1f}')
2.2 第二层:周期性模式偏离检测(纵向对比)
很多指标具有明显的周期性——比如工作日和周末的 QPS 差异很大。预警系统需要"理解"这种周期性:
# cycle_deviation_detector.py — 周期性偏离检测
class CycleDeviationDetector:
"""周期性偏离检测:对比当前值和历史同期值"""
def __init__(self, prometheus_url: str):
self.prom = PrometheusConnect(url=prometheus_url, disable_ssl=True)
def detect_deviation(self, metric: str, service: str) -> dict:
"""检测与历史同期相比的偏离度"""
now = datetime.now()
# 当前值(最近 5 分钟的均值)
current_query = f'avg_over_time({metric}{{service="{service}"}}[5m])'
current_value = self._query_one(current_query)
# 上周同一天同一时段的值(历史基线)
last_week_start = now - timedelta(days=7)
history_query = f'avg_over_time({metric}{{service="{service}"}}[5m]) offset 1w'
history_value = self._query_one(history_query)
if history_value == 0:
return {'deviation_pct': 0, 'severity': 'unknown'}
# 计算偏离度
deviation = (current_value - history_value) / history_value * 100
severity = 'high' if abs(deviation) > 50 else (
'medium' if abs(deviation) > 30 else (
'warning' if abs(deviation) > 15 else 'normal'))
return {
'current': current_value,
'history_baseline': history_value,
'deviation_pct': f"{deviation:+.1f}%",
'direction': 'up' if deviation > 0 else 'down',
'severity': severity,
'suggested_action': self._suggest_action(metric, deviation)
}
def _suggest_action(self, metric: str, deviation: float) -> str:
"""根据指标类型和偏离方向给出建议"""
if 'error_rate' in metric and deviation > 30:
return '检查最近一次发布,回滚可能存在问题的版本'
elif 'latency' in metric and deviation > 30:
return '检查上游服务状态和数据库连接池'
elif 'cpu' in metric and deviation > 50:
return '检查是否有异常进程或流量突增'
else:
return '建议关注,持续观察 15 分钟'
2.3 第三层:跨指标关联预警
单个指标异常可能是噪声,但多个指标同时异常一定是信号:
# cross_metric_warning.py — 跨指标关联预警
class CrossMetricWarning:
"""跨指标关联预警"""
def check_correlation(self, metrics: dict) -> list:
"""检查多个指标之间的关联模式"""
warnings = []
# 规则 1: 请求量正常但错误率上升 → 服务本身有问题
if (metrics['qps']['deviation'] < 10 and
metrics['error_rate']['deviation'] > 50):
warnings.append({
'type': 'service_degradation',
'confidence': 0.85,
'message': '请求量正常但错误率飙升,服务本身存在缺陷',
'suggestions': ['检查最近代码变更', '查看错误日志分布']
})
# 规则 2: 请求量上升 + 延迟上升 + CPU 上升 → 正常扩展
if (metrics['qps']['deviation'] > 30 and
metrics['latency']['deviation'] > 20 and
metrics['cpu']['deviation'] > 20):
warnings.append({
'type': 'normal_scaling',
'confidence': 0.90,
'message': '流量增长导致延迟和 CPU 同步上升,建议提前扩容',
'suggestions': ['提前扩容 Pod', '检查 HPA 配置是否合理']
})
# 规则 3: 请求量不变 + 延迟上升 + CPU 不变 → 线程阻塞/code issue
if (abs(metrics['qps']['deviation']) < 10 and
metrics['latency']['deviation'] > 30 and
abs(metrics['cpu']['deviation']) < 10):
warnings.append({
'type': 'thread_contention',
'confidence': 0.75,
'message': '请求量不变但延迟上升且 CPU 未同步上升,可能有线程阻塞',
'suggestions': ['jstack 查看线程状态', '检查数据库连接池']
})
return warnings
三、 LLM 辅助预警判断
预警系统的最大挑战是误报率。如果预警太多,团队会进入"预警疲劳",最终无视所有预警。
我们引入 LLM 做"二次判断"——在预警发送前,让 LLM 检查这个预警是否合理:
# llm_warning_filter.py — LLM 预警过滤器
class LLMWarningFilter:
"""用 LLM 过滤和分级预警"""
async def should_alert(self, warning: dict, context: dict) -> dict:
"""判断预警是否需要发送"""
prompt = f"""你是一个 SRE 预警过滤专家。请判断以下预警是否需要立即通知工程师。
## 预警信息
- 类型:{warning['type']}
- 置信度:{warning['confidence']}
- 消息:{warning['message']}
## 当前系统上下文
- 当前时间:{context['current_time']}
- 是否工作时间:{context['is_working_hours']}
- 最近是否有发布:{context['recent_deploy']}
- 类似预警的历史命中率:{context['historical_accuracy']}
## 判断标准
1. 如果是深夜(22:00-08:00)且置信度 < 0.8 → 延迟到早上聚合发送
2. 如果预警类型在历史上误报率 > 50% → 标记为"低优先级"
3. 如果是已知的周期性波动 → 不发送
4. 如果影响核心交易链路 → 即使置信度低也要发送
请返回:
- decision: send / delay / suppress
- reason: 简短理由
- priority: P1/P2/P3
"""
# 调用 LLM...
result = await self._call_llm(prompt)
return result
四、 实践效果
| 指标 | 使用前 | 使用后 | 提升 |
|---|---|---|---|
| 提前发现故障时间 | 0min | 23min (平均) | ∞ |
| P0 故障数量/月 | 12 | 5 | 58% |
| 预警总数/天 | - | 35 | - |
| 有效预警比例 | - | 72% | - |
| 工程师对预警满意度 | - | 7.8/10 | - |
最让我们惊喜的数据是:72% 的预警在 24 小时内被验证为有效。也就是说,每发出 10 条预警,有 7 条以上是真正有价值、需要关注的。
总结
从"被动响应告警"到"主动接收预警",看起来只是换个词,但背后是整个运维思维模式的转变。
告警告诉你"已经出事了";预警告诉你"即将出事了"。前者需要止损,后者只需要预防——两者的响应成本和影响范围天差地别。
部署这套预警系统半年后,团队形成了一种新习惯:每天早上先看"预警日报",了解今天可能出现的风险,而不是等告警响了再去救火。
预防的价值,永远大于止损。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)