论文阅读笔记——OpenRCA: Can Large Language Models Locate the Root Cause of Software Failures?
1. 论文基本信息
- 论文题目:OpenRCA: Can Large Language Models Locate the Root Cause of Software Failures?
- 会议/年份:ICLR 2025
- 作者单位:CUHK-Shenzhen、Microsoft、Tsinghua University
- 研究方向:AIOps、Root Cause Analysis、LLM Agent、软件系统故障诊断
- 一句话总结:
这篇论文提出了一个面向真实软件系统故障根因分析的公开 benchmark —— OpenRCA,并评估了当前大语言模型在日志、指标、Trace 等大规模异构遥测数据上定位根因的能力。实验结果表明,即使使用工具增强的 RCA-agent,当前 LLM 也只能解决很少一部分案例,说明真实 RCA 任务仍然非常困难。
2. 这篇论文想解决什么问题?
现有 LLM 在软件工程中的应用主要集中在开发阶段,比如代码生成、代码修复、测试生成、debugging 等。但是软件生命周期中还有一个非常重要的阶段:部署后的运行维护阶段。
在真实系统中,服务可能出现:
- 延迟升高;
- 服务不可用;
- CPU / 内存 / 磁盘 / 网络异常;
- 日志报错;
- Trace 调用链异常;
- 多个服务同时出现异常。
运维工程师需要根据这些现象找出真正根因,这就是 Root Cause Analysis, RCA。
论文关注的问题是:
当前 LLM 能不能在真实软件运维场景下,根据大量日志、指标、Trace 等遥测数据,定位故障根因?
这里的根因通常包括三个要素:
1. 根因发生时间:什么时候开始故障?
2. 根因组件:哪个服务、节点、容器、数据库等组件最先出问题?
3. 根因原因:为什么出问题?例如 CPU 过载、磁盘 I/O 异常、网络丢包、内存泄漏等。
3. 为什么这个问题难?
这篇论文认为,真实 RCA 难在以下几个方面。
3.1 数据量巨大
一个故障案例往往涉及大量遥测数据,包括:
- Metrics:时间序列指标;
- Logs:半结构化日志;
- Traces:服务调用链和依赖关系。
OpenRCA 总共包含超过 68GB 的遥测数据。直接把所有数据塞进 LLM 上下文是不现实的。
3.2 数据类型异构
RCA 不是单纯读文本。模型需要同时理解:
时间序列异常
+
调用链依赖图
+
半结构化日志
+
系统拓扑与组件关系
这对 LLM 的长上下文理解、结构化推理和跨模态证据融合能力要求很高。
3.3 故障会传播
一个服务出问题后,可能导致上游或下游服务都表现异常。
例如:
ProductCatalogService 磁盘 I/O 异常
↓
RecommendationService 调用变慢
↓
CheckoutService 响应变慢
↓
Frontend 延迟升高
如果模型只看“最明显的异常”,很可能把 Frontend 误判为根因。真正难点是区分:
根因组件
受影响组件
传播症状
无关噪声
3.4 任务目标不统一
传统 RCA 数据集往往只要求定位一个目标,比如只找组件,或者只找异常日志。但真实运维场景中,用户可能问不同问题:
帮我找根因组件
帮我找根因原因
帮我找故障开始时间
帮我找组件和原因
帮我找时间、组件和原因
所以 OpenRCA 把 RCA 设计成一个 goal-driven task,即根据用户问题要求输出不同的根因要素。
4. OpenRCA benchmark 是什么?
OpenRCA 是论文提出的公开 benchmark,用于评估 LLM 在真实软件故障 RCA 任务上的能力。
4.1 数据来源
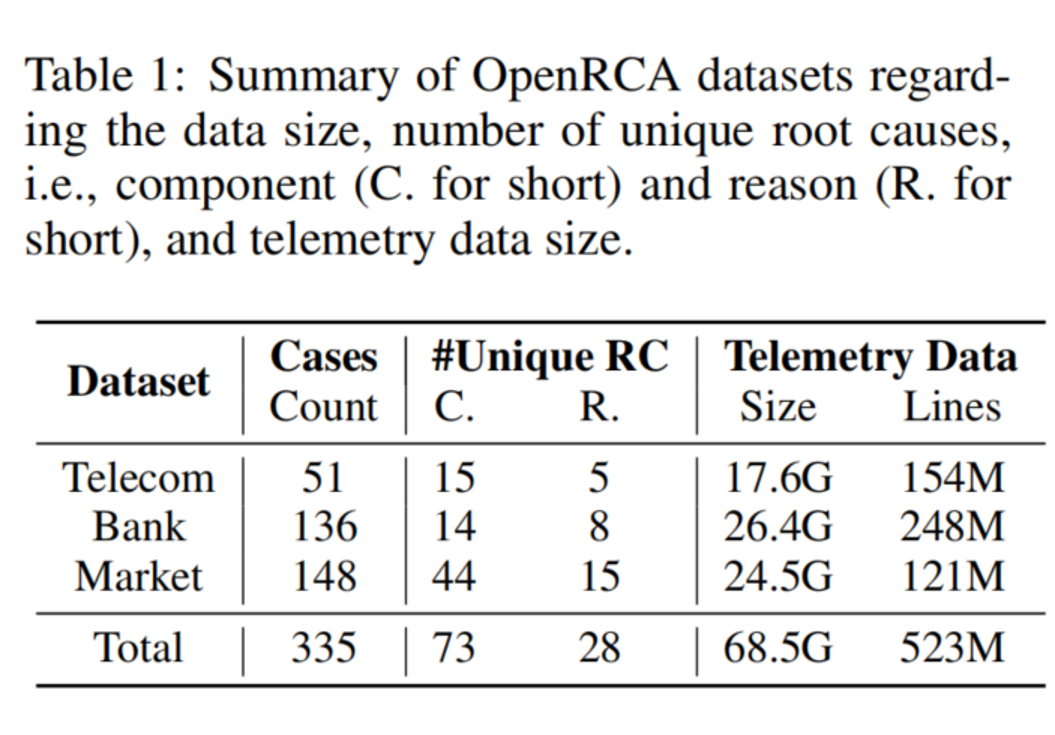
OpenRCA 的数据来自 AIOps Challenge 系列中的真实软件系统数据。论文最终整理出三个系统:
| 系统 | 案例数 | 特点 |
|---|---|---|
| Telecom | 51 | 电信数据库系统,包含 metrics 和 traces,没有 logs |
| Bank | 136 | 银行业务系统,包含 metrics、traces、logs |
| Market | 148 | 在线市场系统,包含 metrics、traces、logs |
| Total | 335 | 共 335 个故障案例,68GB+ 遥测数据 |
4.2 遥测数据类型
OpenRCA 包含三类主要遥测数据。
Metrics
Metrics 是时间序列指标,例如:
CPU 使用率
内存剩余量
磁盘读写
网络包数量
请求延迟
服务成功率
JVM GC 时间
每条 metric 通常包含:
timestamp, cmdb_id, kpi_name, value
其中:
timestamp:时间戳;cmdb_id:组件 ID;kpi_name:指标名称;value:指标值。
Trace
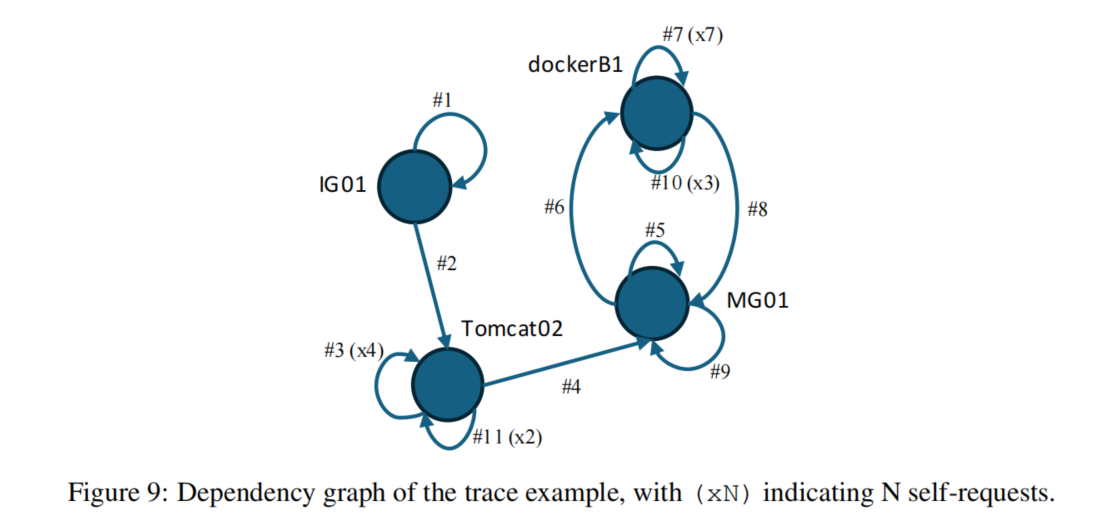
Trace 表示服务之间的调用关系。一个 trace 可以看成一棵调用树或一个依赖图。
例如:
IG01
└── Tomcat02
└── MG01
└── dockerB1
Trace 对 RCA 很重要,因为它可以帮助判断异常是如何沿服务依赖传播的。
Logs
Logs 是组件运行时产生的日志,例如:
GC 日志
Error 日志
连接失败日志
内存分配失败日志
TCP 波动日志
Logs 通常用于确认具体故障原因。
5. OpenRCA 如何构造数据?

论文的数据构造流程分四步:
- System Selection
先从 AIOps Challenge 中筛选出适合 RCA 的真实系统。很多原始数据存在标签不完整、只标注有故障但没有根因、或者只有单一类型数据的问题,因此需要筛选。 - Data Balancing
不同系统的数据规模差异很大。为了避免某个系统主导 benchmark,论文对大规模数据集进行了下采样,使三个系统的案例规模相对均衡。 - Data Calibration
原始数据有很多问题,例如:根因标签错误、故障时间不准、组件命名不一致等等,论文请了有 RCA 经验的工程师人工校准数据。如果数据不满足要求,就会被删除。 - Query Synthesis
OpenRCA 不是直接给模型一个固定任务,而是把每个故障案例转成自然语言问题。
例如:在 2021 年 3 月 6 日 23:00 到 23:30 之间,Bank 系统出现了一次故障。 请找出根因组件。
论文把 RCA 目标拆成三个要素:
time
component
reason
然后组合成 7 类任务:
| 任务类型 | 要求输出 |
|---|---|
| Task 1 | time |
| Task 2 | reason |
| Task 3 | component |
| Task 4 | time + reason |
| Task 5 | time + component |
| Task 6 | component + reason |
| Task 7 | time + component + reason |
这种设计使 OpenRCA 更接近真实运维中的多样化问题。
6. 任务定义和评价方式
6.1 输入
每个 OpenRCA 任务的输入包括:
自然语言故障问题
+
对应时间窗口内的 telemetry 数据
+
候选根因组件列表
+
候选根因原因列表
6.2 输出
模型需要以 JSON 格式输出根因信息,例如:
{
"1": {
"root cause component": "tomcat01",
"root cause reason": "network packet loss"
}
}
如果问题只要求组件,就只评估组件;如果问题要求组件和原因,则两个都必须答对。
6.3 评价方式
OpenRCA 使用严格准确率:
如果所有要求的根因要素都正确,则得 1 分;
只要有一个要求的要素错误,则得 0 分。
例如问题要求:
component + reason
模型回答:
component 正确,但 reason 错误
最终仍然算错误。
这使得 OpenRCA 的评估比较严格,也更能暴露 LLM 在多要素 RCA 上的不足。
7. Baseline 方法
论文主要比较了三类方法。
7.1 Oracle Sampling
由于 OpenRCA 中的 telemetry 数据规模很大,无法直接全部输入 LLM,论文首先对所有 telemetry 数据进行统一下采样。具体来说,作者将 trace、log 和 metric 都下采样到 每分钟一个采样点,做法是在每一分钟内选择最早记录的一条数据作为该分钟的代表值。
不过,仅仅进行时间维度的下采样还不够。对于 metrics 来说,系统中仍然包含大量 KPI 类型,例如 CPU、内存、磁盘 I/O、网络、JVM、数据库等相关指标。如果把所有 KPI 都输入 LLM,上下文仍然会过长。因此,论文进一步对 KPI 类型 进行采样。
Oracle sampling 是一种理想化采样方式。它使用 benchmark 构建过程中由工程师提前识别出的 golden KPIs,也就是对定位根因有帮助的一组关键 KPI。通过这种方式,论文将 KPI 类型数量从 1263 个减少到 53 个,大幅降低了输入规模和任务复杂度。
Oracle sampling 的目的不是模拟真实部署场景,因为真实故障发生时通常无法提前知道哪些 KPI 最关键。它更像是一个 upper-bound baseline,用于回答:
如果已经提前帮模型筛选出了最有可能包含根因证据的 KPI,LLM 最多能做到什么程度?
因此,Oracle sampling 可以看作一种“理想信息条件”下的采样方法。如果模型在 Oracle sampling 下表现仍然不好,就说明问题不只是数据太多或关键 KPI 没被选中,还可能包括:
LLM 不擅长理解时间序列异常
LLM 不擅长结合 Trace 推理故障传播
LLM 容易混淆根因组件和受影响组件
LLM 难以从 KPI / 日志证据映射到具体故障原因
7.2 Balanced Sampling
Balanced sampling 是一种更接近真实场景的采样方式。它同样建立在前面的 telemetry 下采样基础上:先将 trace、log 和 metric 都按 1 分钟频率下采样,然后再进一步处理 metrics 中过多的 KPI 类型。
与 Oracle sampling 不同,Balanced sampling 不提前知道哪些 KPI 是关键证据。它采用分层采样的思路,从不同 metric 文件中反复选择随机但不重复的 KPI 类型,直到采样出的 KPI 数量与 Oracle sampling 中的 KPI 数量一致。
通俗来说,Balanced sampling 的思想是:
我不知道这次故障到底和 CPU、内存、磁盘、网络还是 JVM 有关
所以我尽量从不同类型的 metric 文件里均衡抽一些 KPI
避免只抽到某一类指标
例如,如果系统中有 CPU、内存、磁盘、网络等多类指标,完全随机采样可能会刚好抽到很多 CPU 指标,却漏掉磁盘或网络指标。Balanced sampling 则希望不同 metric 文件都有机会被覆盖,从而提高采样数据的代表性。
它比较接近真实场景,因为在真实 RCA 中,模型或系统通常事先不知道哪些 KPI 最关键。它的缺点也很明显:由于是随机均衡采样,仍然可能漏掉真正与根因直接相关的关键 KPI。
因此,Balanced sampling 可以看作一个现实但较粗糙的 baseline:
它不依赖人工提前标注 golden KPIs
也不主动根据当前证据动态选择下一步要查什么
而是一次性从大量 KPI 中均衡抽取一部分
再把采样后的 telemetry 输入 LLM
所以,Oracle sampling 和 Balanced sampling 的区别可以总结为:
| 方法 | 是否提前知道关键 KPI | 采样对象 | 作用 |
|---|---|---|---|
| Oracle Sampling | 是 | 工程师标注的 golden KPI types | 测试理想信息条件下的性能上限 |
| Balanced Sampling | 否 | 从不同 metric 文件中均衡随机抽取 KPI types | 模拟更现实的盲采样场景 |
这两种方法都属于 sampling-based methods,本质上都是为了把过大的 telemetry 压缩到 LLM 可以处理的上下文范围内。但它们仍然是一次性采样方法,不能像 RCA-agent 那样根据中间分析结果动态决定接下来读取哪些数据。
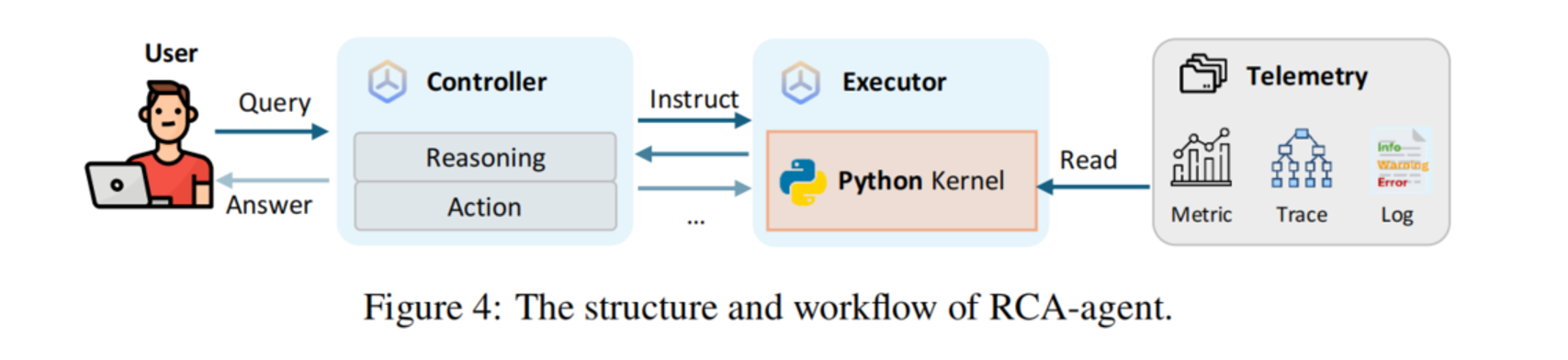
7.3 RCA-agent
RCA-agent 是论文提出的工具增强多智能体系统,用来避免把海量 telemetry 直接塞进 LLM 上下文。
它包含两个角色:
| Agent | 作用 |
|---|---|
| Controller | 负责诊断决策、分析结果、决定下一步 |
| Executor | 根据 Controller 指令编写并执行 Python 代码,读取和分析 telemetry |
整体流程是:
用户问题
↓
Controller 分析任务
↓
Controller 指示 Executor 读取数据
↓
Executor 写 Python 代码并执行
↓
Controller 根据执行结果继续分析
↓
多轮迭代
↓
输出最终根因
8. RCA-agent 的诊断流程
论文给 RCA-agent 设定了一个高层诊断流程:
preprocess
↓
anomaly detection
↓
fault identification
↓
root cause localization
也可以理解为:
数据预处理
↓
发现哪些指标 / 日志 / trace 异常
↓
确认哪些异常是真故障相关,而不是噪声
↓
结合调用关系和证据定位最初根因
其中三个核心阶段的区别是:
| 阶段 | 问题 | 输出 |
|---|---|---|
| Anomaly Detection | 哪里不正常? | 异常 KPI、异常日志、异常 Trace |
| Fault Identification | 哪些异常和故障相关? | 故障相关组件 / 故障症状 |
| Root Cause Localization | 谁最先导致故障?为什么? | 根因组件、根因时间、根因原因 |
这个流程对后续做 LLM Agent RCA 很有启发:不能让模型一上来直接猜根因,而应该先收集证据、筛异常、判断传播关系,再定位根因。
9. 实验结果
9.1 总体结果
论文表 2 是最关键的实验结果。
| 方法 | 最好模型 | Correct |
|---|---|---|
| Balanced Sampling | Gemini 1.5 Pro | 6.27% |
| Oracle Sampling | Gemini 1.5 Pro | 7.16% |
| RCA-agent | Claude 3.5 Sonnet | 11.34% |
结论非常明显:
当前 LLM 即使使用工具增强 Agent,也只能解决很少一部分真实 RCA 案例。
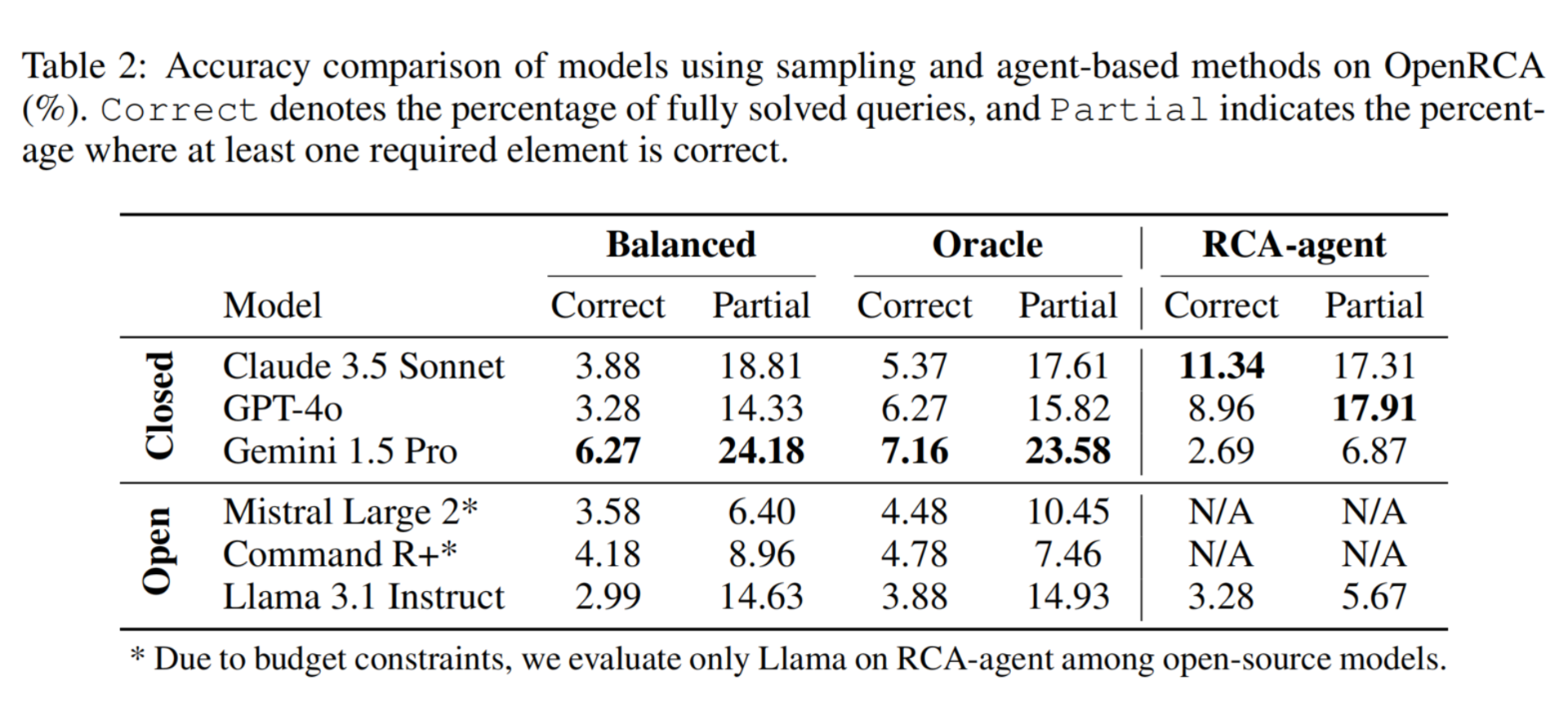
9.2 RCA-agent 优于 sampling-based 方法
整体上,RCA-agent 比 balanced sampling 和 oracle sampling 更好。
原因是:
Sampling 方法仍然依赖把采样后的 telemetry 塞进 prompt;
RCA-agent 则通过 Python 工具读取和分析数据,避免长上下文压力。
这说明:
对大规模 telemetry RCA 来说,工具增强 Agent 比单纯长上下文输入更有潜力。
9.3 但 RCA-agent 仍然很弱
即使最好的 Claude 3.5 + RCA-agent 也只有 11.34% 的正确率。
这说明当前方法仍然存在明显问题:
指标异常理解能力不足
日志解释能力不足
Trace 依赖推理不足
多跳故障传播推理不足
根因和症状容易混淆
多要素输出任务很难
Agent 代码执行和错误恢复能力有限
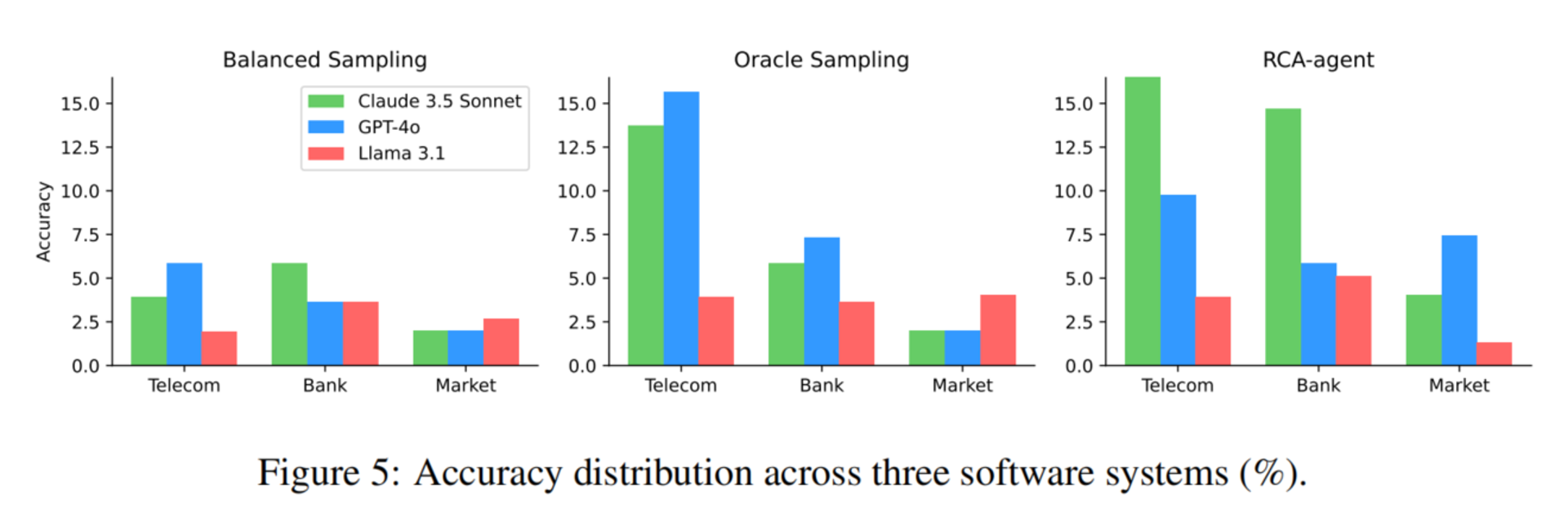
9.4 系统越复杂,准确率越低
论文发现模型在 Telecom 系统上表现更好,在 Bank 和 Market 上表现更差。
原因是 Telecom 更简单:
数据量更小
根因组件种类更少
根因原因种类更少
系统容错机制较少
而 Bank 和 Market 有更多 pod、服务副本、故障传播和容错机制,导致 RCA 更难。
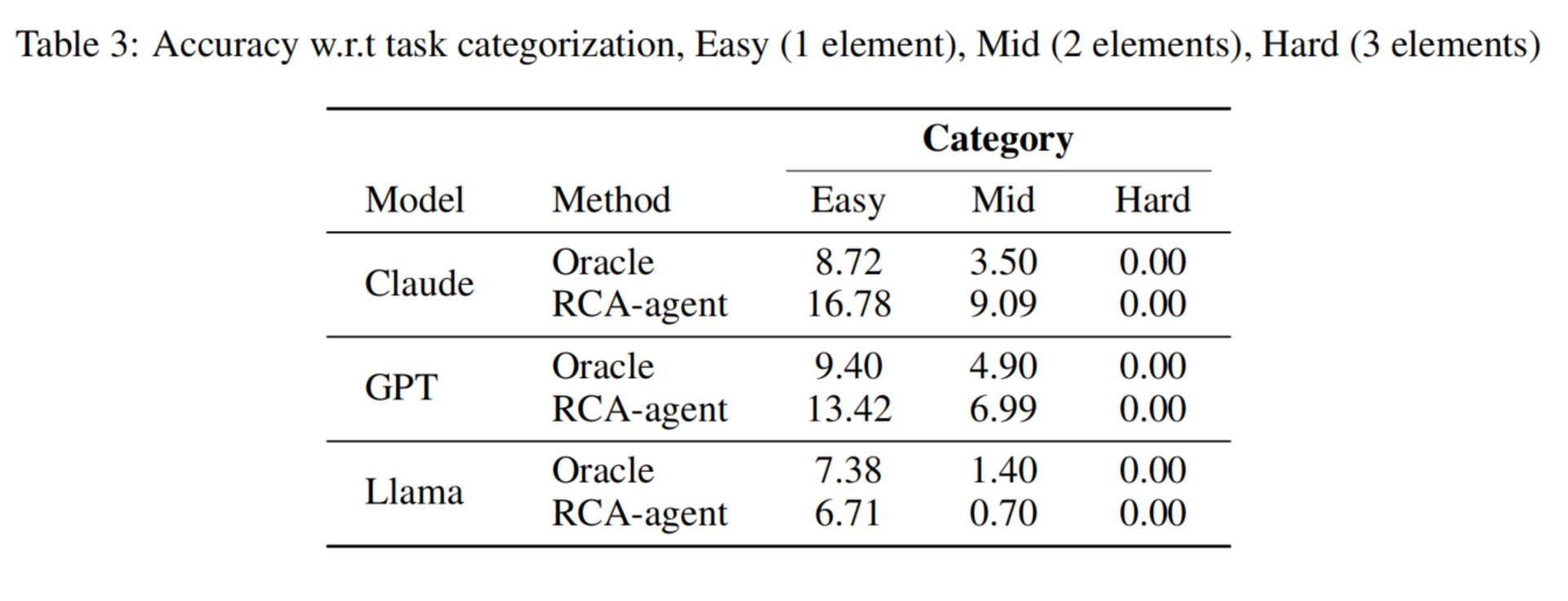
9.5 多要素任务更难
论文把任务分成三类:
| 难度 | 要求输出 |
|---|---|
| Easy | 1 个根因要素 |
| Mid | 2 个根因要素 |
| Hard | 3 个根因要素 |
结果显示:
输出要素越多,准确率越低。
Hard 任务,也就是同时要求 time + component + reason 时,当前方法几乎完全失败。
这说明 LLM 也许能偶尔猜对一个元素,但很难同时正确识别完整根因。
9.6 Reason 最难预测
补充分析中,论文比较了三个根因要素的难度:
reason 最难
component 和 time 相对容易
原因是 component 和 time 更容易从异常点和调用关系中找到,而 reason 需要模型理解 KPI、日志和故障类型之间的语义映射。
例如:
磁盘读写异常 → high disk I/O read usage
网络错误日志 + latency 增加 → network packet loss / network latency
GC 日志异常 + 内存指标异常 → memory leak / JVM issue
这种从证据到原因的映射,对 LLM 来说仍然很难。
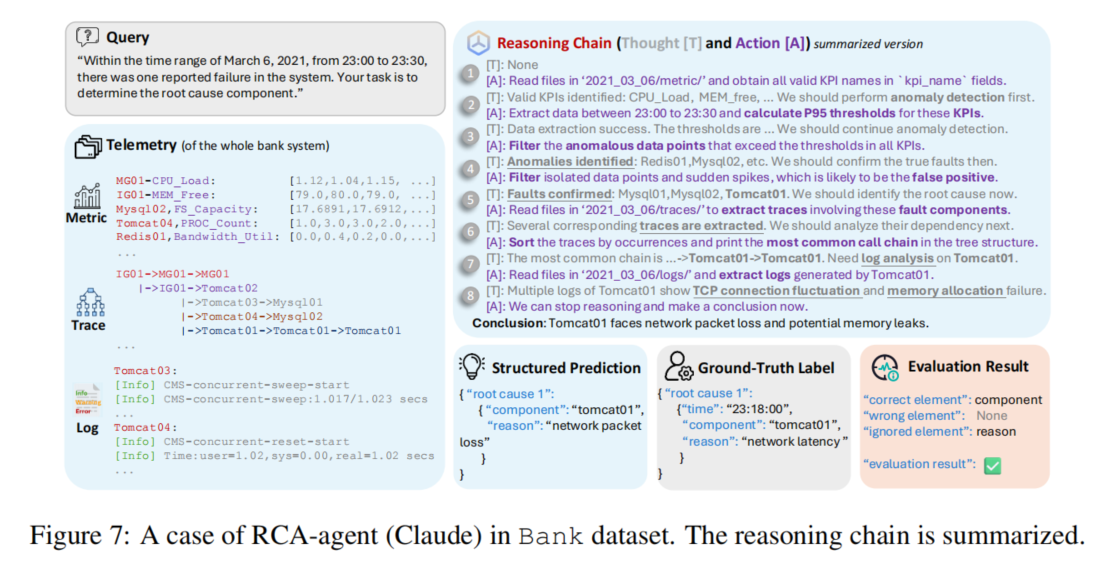
10. Case Study:RCA-agent 如何工作?
论文给了一个 Bank 系统的案例。
任务是:
在 2021 年 3 月 6 日 23:00 到 23:30 之间,系统发生一次故障。
请找出根因组件。
RCA-agent 的大致流程是:
1. 读取 metric 文件,获取所有 KPI 名称
2. 提取目标时间窗口内的数据
3. 计算 P95 threshold,筛选异常点
4. 过滤孤立噪声点和短时尖峰
5. 确认多个组件出现持续异常
6. 读取 trace,分析异常组件之间的调用关系
7. 发现 Tomcat01 在调用链中处于关键位置
8. 读取 Tomcat01 日志
9. 发现网络波动和内存分配相关日志
10. 输出 Tomcat01 为根因组件
这个案例说明 RCA-agent 的优势是:
不是直接让 LLM 看所有数据
而是让 LLM 指挥 Python 工具逐步查证据
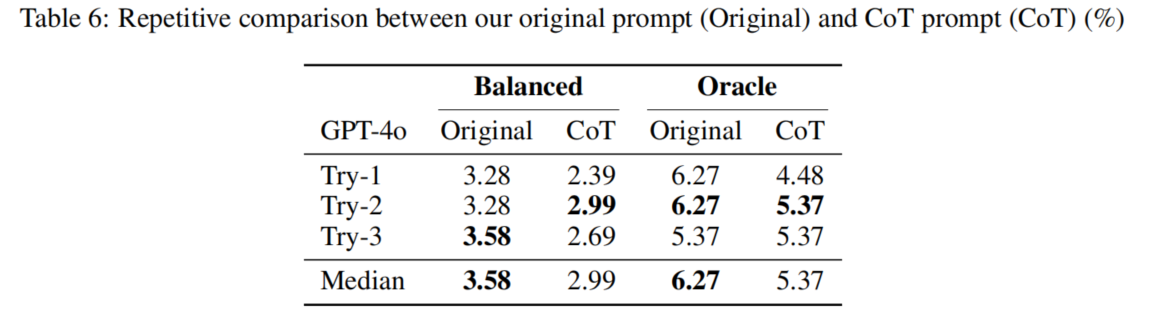
11. 为什么 CoT 不一定有用?
论文还做了一个有意思的分析:显式要求模型进行 Chain-of-Thought 反而效果更差。
原因是,在 RCA 这种任务中,模型可能会:
看到几个明显异常
↓
在自己的分析里过早锁定这些异常
↓
忽略更深层的调用链传播关系
↓
把症状组件误判为根因组件
也就是说,普通 CoT 可能让模型“看起来分析很多”,但不一定真的按照正确诊断流程查证据。
这对我们很有启发:
RCA 任务不能简单依赖“让 LLM 多想一步”,而需要结构化的证据收集流程和工具调用策略。
12. 论文的主要贡献
这篇论文的贡献可以总结为三点。
12.1 提出 OpenRCA benchmark
论文构建了一个真实、公开、较大规模的 RCA benchmark,包括:
335 个真实故障案例
3 个真实软件系统
68GB+ 遥测数据
metrics + logs + traces
7 类 goal-driven RCA 任务
这是它最核心的贡献。
12.2 系统评估当前 LLM 的 RCA 能力
论文评估了多个闭源和开源模型,包括:
Claude 3.5
GPT-4o
Gemini 1.5 Pro
Mistral Large 2
Command R+
Llama 3.1 Instruct
结果表明,当前 LLM 在真实 RCA 上表现仍然很差。
12.3 提出 RCA-agent 作为可能方向
RCA-agent 不是最终解决方案,但展示了一种有潜力的方向:
LLM 不直接处理所有 telemetry
而是通过代码执行和工具调用进行数据分析
这说明未来 RCA 系统可能需要走向:
LLM reasoning
+
tool execution
+
telemetry analysis
+
structured evidence chain
13. 论文的局限性
13.1 只覆盖分布式软件系统
OpenRCA 的故障主要来自分布式软件系统,不包含更多类型的系统架构,比如传统网络设备、工业控制网络、单体系统等。
13.2 查询是合成的
论文中的自然语言 query 是根据故障记录合成的,并不是真实工程师写下的故障工单或 incident report。
这可能导致 benchmark 和真实运维交互仍有差距。
13.3 RCA-agent 依赖模型代码生成和错误恢复能力
RCA-agent 需要模型生成 Python 代码读取和分析数据。如果模型写错代码,或者无法从执行错误中恢复,诊断过程就会失败。
论文也发现,不同模型作为 Agent 时的错误恢复能力差异很大。
13.4 正确率仍然很低
RCA-agent 虽然优于 sampling 方法,但最高正确率仍然只有 11.34%。这说明它更多是一个初步方向,而不是成熟方法。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)