LLM-大模型微调
一 、大模型基础架构
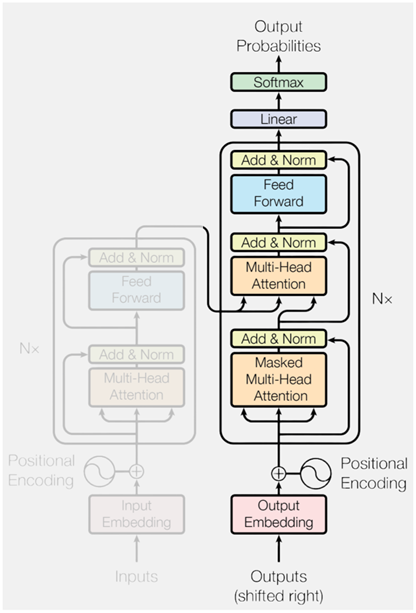
1、输入层
将原始文本转化成模型能处理的向量表示,
2、Transformer-block
通过多个transformer层堆叠而成的,每个block内部都包含自注意力机制和前馈网络层,并且为了深层结构的训练稳定性,采用残差连接和归一化技术,让梯度能顺利传播。
2.1 Attention
Transformer中的自注意力机制,通过计算序列中每个元素与其他元素之间的权重,来记录序列不同元素间的依赖关系,从而高效建立长距离依赖关系。
(1)MHA 多头自注意力。就是把QKV,通过参数矩阵映射然后计算注意力分数,将这个过程重复做h次,再进行拼接就是MHA。在多个自注意力头上并行计算xx(缺点:每个头都有独立生成并保存一组k,v,导致缓存量持续累积)
(2)MQA多查询自注意力。让多个自注意力头共享同一组key,value值(缺点:表达能力差)
(3)GAQ分组查询自注意力。将自注意力头分成多个组,每组的内部多个查询共享同一套K,V
2.2 FFN层
经过多头自注意力子层后,就要经过前馈神经网络层。这一层主要是实现对每个位置的非线性变化。先线性变化实现升维(为了将特征扩展到高位空间),再经过激活函数(引入非线性),最后再降维
激活函数:
(1)Relu
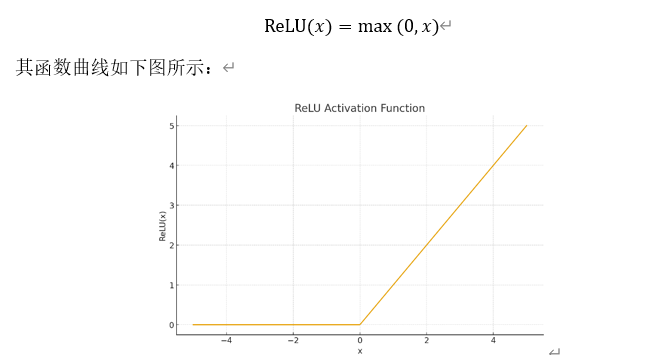
由于在负区间上存在“硬截断”问题,也就是梯度完全为0,导致神经元永久失活。并且不可导,在训练过程中不够平稳
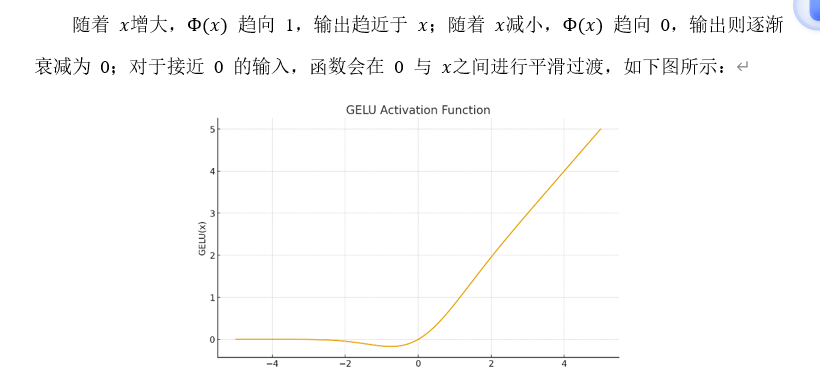
(2)GeLU
是一种平滑非线性的且连续可导的激活函数,在激活值中引入了随机正则化。在X<0处有个极小的负值点,保留了梯度更新的能力。
根据当前输出x的值,利用高斯累积分布函数进行加权缩放。
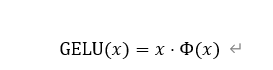
(3)SILU(Swish就是"Swish"(x)=x⋅σ(βx),可看作是一般形式)
一种连续可导的激活函数,通过sigmoid函数对线性输入进行加权,也具有平滑非线性的特点。
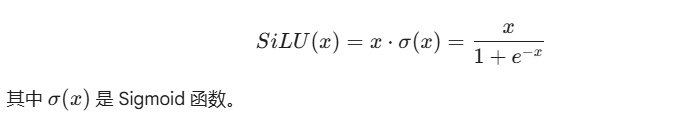
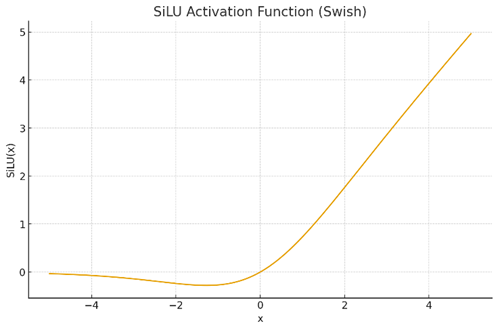
(4)GLU(SwiGLU)
GLU这种门控线性单元,加入了线性的门控机制(一个主分支,一个门控分支),让模型对信息流实现更细致的筛选和调控,增强非线性的表达能力,能更有效的缓解深层网络中的梯度消失或爆炸问题。
而SwiGLU就是在门控分支中采用SILU作为激活函数。将门控分支得到的激活值与原始线性变化的结果进行相乘,能学习到输入特征中更复杂的关系,增强非线性的表达能力。(与Relu对比?ReLU是强制稀疏,SwiGLU通过门控机制实现了动态稀疏,能保留负值信息)
2.3 位置编码
self-attention层中只进行了qkv的计算,无法捕捉不同词语之间的顺序关系。在经过词嵌入层之后,对序列中每个token都添加一个位置编码向量,最终输入向量=词向量 (语义)+位置向量 (位置)。从而使模型能感知词语之间的位置关系。
1、正余弦位置编码
通过正余弦函数来对位置进行建模,也就是为每一个序列中的token生成一个固定的位置编码向量,并直接添加到词向量中。
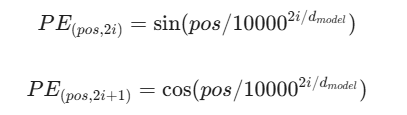
缺点:对复杂结构的建模能力弱,表达能力有限。实际的长度外推能力不足,因为模型在处理从未见过的数值时,缩放点积注意力不稳定,模型混乱。
2、可学习的位置编码
给序列中每个Token关联一个可学习的向量参数,与词向量相加后,随着模型的训练进行更新。
缺点:外推能力弱,无法处理超过训练长度的序列。
3、旋转位置编码(ROPE)
根据token在序列中的位置,对每个token的Q和K向量进行旋转变化然后来注入位置信息,使得注意力权重只取决于两个token之间的相对距离,同一个词在不同的位置会有不同的向量表示。具体操作就是:根据token的位置m,先计算出一个特定的旋转角度,把这个token中的Q,K向量按照这个角度进行旋转,这样每个token表示除了内容还隐含了其位置信息,做点积时,也能天然表示它们之间的相对位置关系。
缺点:计算复杂度高,需要对向量进行旋转矩阵运算
2.4、层归一化+残差连接
(1)layernorm->Pre-LayerNorm vs Post-LayerNorm
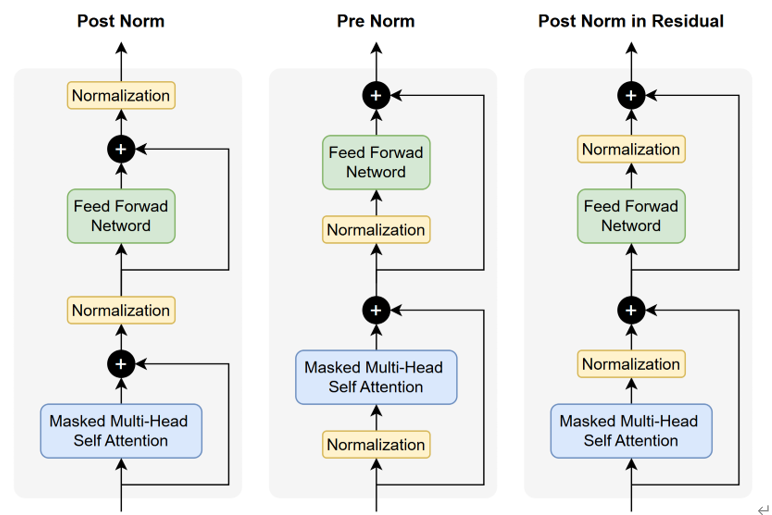
Post-LN:在子层计算完成并与残差结果相加后,对结果再进行归一化处理。
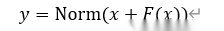
问题:梯度传播不稳定,因为在每一层梯度都经过了LN,会被LN干扰,没有一条稳定训练的恒等梯度通道,所以xx
Pre-LN: 是在进入子层之间先对输入进行归一化,然后经过子层计算与残差结果相加,
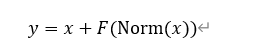
优点:提供了一条不收干扰稳定的梯度路径
(2)RMSnorm
认为起主要作用的是方差,所以计算了输入向量的均方根(计算平方和的均值再开方),去掉了中心化(减去均值)保留了缩放(除以特征的标准层)。而传统的LayerNM要计算均值跟方差。带来更高的计算效率和数值稳定性
2.6 MOE
混合专家模型,通过多个并行的FFN专家去代替单一的FFN层,然后经过router机制动态分配(也就是根据输入token的不同特征让其选择少量最合适的专家参与计算,而其他专家保持非活跃状态)。
优点: 引入了这种稀疏激活机制(只激活部分参数进行计算),实现了高效的计算
2.7 学习率
就是梯度下降法中控制梯度每一次更新的步长。
训练过程:先预热(warm-up)刚开始模型参数是随机初始化的,学习率从0开始,才能保证训练平稳启动。然后稳定阶段:让模型在峰值学习率学习一段时间,快速学习到主要的特征。余弦退火:训练中后期,去逐步降低学习率,让参数更新步伐变小。如果太大,会使参数来回震荡,从而导致模型无法收敛。
2.8 蒸馏
将大模型(教师模型)的知识迁移到小模型(学生模型)的方法。让小模型在保持轻量化的同时,性能也接近大模型。在特定任务上跨越参数量的限制(小模型占用显存少,生成token速度快,大幅降低部署成本)
Qwen3?
off-policy离蒸馏策略:使用教师模型在大模型上生成高质量的输出(思考和非思考模式),接着学生模型去学习教师模型产生的概率分布,掌握基本的推理能力。损失函数:学生模型+教师模型的交叉熵损失函数
on-policy 同蒸馏策略:让学生模型先自己进行采样然后生成回答,与教师模型的预测分布进行对齐。损失函数就是KL散度
3、输出层
通过线性层+softmax,将向量映射到词表上,得到一个概率分布
二、LLM微调理论
1、SFT(监督微调
使用高质量的指令-回答对的数据集(问答对)来对模型进行微调,让模型在已知问题的情况下, 输出产生该问题结果的概率最大化,也就是让模型生成更符合特定任务的输出。所以SFT不对prompt进行损失计算,对答案进行损失计算。
目标:让模型获得特定任务执行的能力,以及产生遵循人类指令的回答。(跟预训练不同,海量数据,无标注,损失训练,任务?获得基本生成和理解文本的能力)
缺点:多轮训练会 导致过拟合监督微调的数据,让模型发生灾难性遗忘。因为损失函数中没有KL散度,也就是没有约束新旧模型偏差的这个能力。
2、DPO(直接偏好优化)
使用高质量的偏好数据集(正负例数据集),也就是人类标注的偏好数据,一步到位去训练对齐模型,而不再需要奖励模型。其训练目标(损失函数)是:使得生成好回答(chosen)的概率高于生成坏回答(reject)的概率,并引入一个固定的参考模型来约束优化的方向。
数据集:prompt,chosen,reject
3、RLHF训练过程
(1)先通过SFT监督微调,让模型获得基本对话能力,和指令遵循的能力。
(2)训练奖励模型。然后基于SFT后的模型,通过对同一个Prompt的多个回答进行人类偏好训练得到RM。
(3)强化学习优化策略(ppo),对输入进行采样生成回答,再通过奖励模型计算奖励,并加入KL散度惩罚项来约束强化学习后的模型𝜋不要远离原始SFT模型得到总奖励。接着利用value价值网络模型来计算优势,最后用PPO裁剪目标函数来对策略π进行更新,在限制新旧策略差异前提下,尽可能提高产生高奖励的回答。
2、参数高效微调(PEFT)
2.1 Lora (Low-Rank Adaptation)
(1)定义:在不改变模型原始权重的条件下,为模型中的线性层权重矩阵添加一个低秩可训练的增量,进而能实现极少参数实现对大模型的适配。
在传统的全参微调下,需要更新模型所有的权重矩阵,在这个过程中全参微调会学习一个增量矩阵ΔW,使得更新后的权重是 W=W_0+ΔW。而这个权重变化矩阵 ΔW 具有“低秩(Low-Rank)”的特性,进而可以将其分解成两个低秩矩阵的乘积。
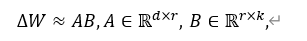
(2)Lora两个矩阵的初始化 A: 采用随机正态分布进行初始化,让A具有随机性,能够捕捉输入特征的不同维度。 B: 初始化为0。使其刚开始训练时表现跟原始预训练模型一致。
(3)LoRA作用在线性层中的权重矩阵,例如注意力层中的Wq、Wk、Wv、Wo, 或者在FFN层中的W_gate,W_up,W_down
(4)在实际工程中,还会引入alpha超参数(缩放因子),通过α/r来控制Lora对模型输出的影响强度。r影响Lora能表达多复杂的变化
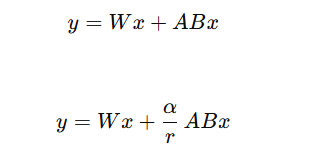
alpha通常设置为r的倍数,通常是alpha = 2r。
r小:参数少训练快,但模型表达能力有限。 r大:参数多,表达能力强,接近全参微调的效果,但容易过拟合,成本高
(5)Lora矩阵是否可以进行合并?优缺点
正常的W = W x + A B x。合并后: W = (W + AB) x
优点:减少了一次矩阵运算,显存占用更低,推理速度更快
缺点:失去灵活性,因此在训练时候不合并,推理的时候合并
Qlora: 在Lora基础上引进4-bit量化(NF4)技术。
通过标准正态分布将累积概率均分成16个等概率区间,然后每个区间选取其中位数作为该区间的量化值。这样量化点在0附近就更密集,两端就更系数。
KV cache :在模型推理过程中,每生成一个token,模型都会计算历史所有的K,V值,每一次都重新计算序列的k,v会造成重复计算开销。
因此在prefill阶段,先将所有token的k,v缓存下来,在decode阶段,每生成一个新的token就只需要计算当前token的QKV,与缓存的k,v进行注意力计算,再把结果缓存进k,v中去。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 4
4 0
0- 0



 已为社区贡献230条内容
已为社区贡献230条内容

所有评论(0)