Deep Multi-View Clustering viaCluster-Semantic Guidance
基于语义引导的深度多视图聚类
1、摘要
当前方法忽视了簇间分离性和跨视图数据的整合信息。提出一种簇语义引导的深度多视图聚类方法:通过簇分离来增强判别性,同时引入蒸馏机制,保证簇的稳定性(感觉像AI的创新点),醋精对聚类友好的表示学习。引导模型面向簇的学习策略,促进判别特征的提取。
——簇间分离性不够
——特征提取(特征表示)和聚类任务分离
2、引言
传统方法不适合复杂非线性问题。
深度学习方法中,AE提取深层特征,判别性上通过对比学习、互信息最大化技术、基于信息瓶颈原理的框架来实现。但仍然存在局限性:
- 只注重单个视图的建模,忽略多个视图之间的协同优化问题。
- 对比学习在构建正负样本对时,缺乏对样本之间关系的细致考量,导致存在假负例问题。部分研究采用伪标签的形式来区分假负例,但是不够。
本文贡献:
- 自编码器与自适应融合模块:特征提取与融合。
- 引入簇分离损失以得到判别性的簇,并采用知识蒸馏机制来优化学习到的簇表示。
- 簇引导的语义聚合模块,利用语义邻域关系与簇关联,保证学习到的表示具有更强的簇内一致性与簇间判别性。
3、理论基础
传统方法
深度表示学习
对比学习
知识蒸馏:将强大的教师模型迁移到学生模型当中,可以迁移参数、中间表示、特征等,多视图聚类背景下,被用于提升不同视图之间的表示一致性。
——?没懂 相当于共识信息作为教师,单一视图信息作为学生吧,本文蒸馏的是簇相似度分布——坏了。。。
4、本文方法
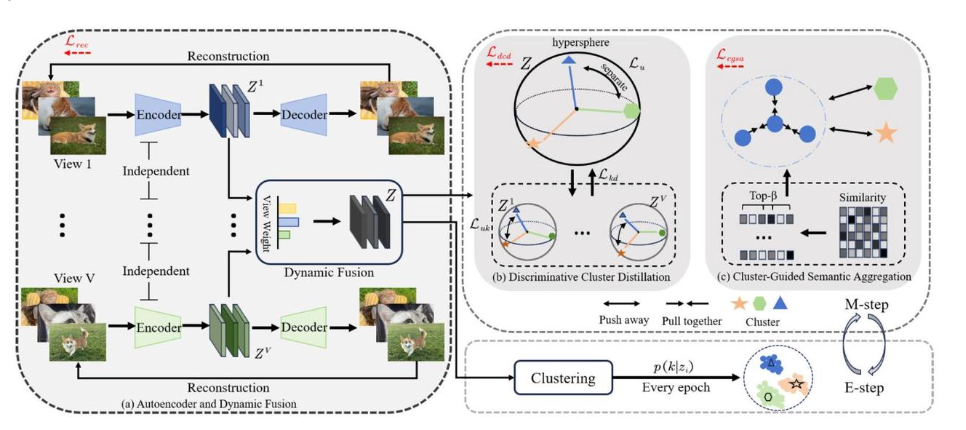
。。。跟24年那篇也太像了,24年那篇是基于簇原型做簇间分离,然后用伪标签和近邻图共同判别正样本和负样本对。
4.1 自编码器与动态融合模块
不说了
4.2 判别性簇蒸馏模块
希望在共识空间保证簇间分离性,用同样的方式构造共识/特征的簇表示: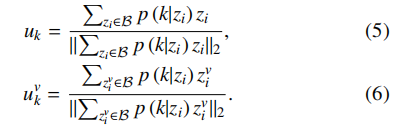
簇中心本质上是样本嵌入的加权平均,权重就是该样本属于这个簇的概率 p(k∣zi)。这其实是软版本的 K-means 质心。
判别性
为了增强簇间分离性,以共识表示为例,设计损失函数如下: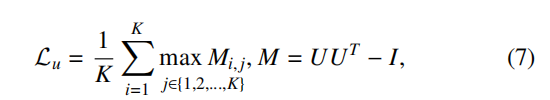
其中,U的每一行是每个簇的簇表示,即uki,UUT相当于计算两两簇之间的余弦相似度,减去一个I就是减去和自己的相似度,取max Mij,相当于取和当前簇最相似的簇,也就是为了推开最容易混淆的簇。
——不去管那些本来就离得远的簇,只盯着最危险的一对去拉开。比起用平均相似度,这种 max 形式收敛更快、簇间裕度更均匀。
同样的特定视图之间的簇混合也容易影响共识表示,所以每个视图的簇之间也要相互分离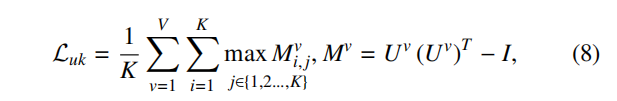
知识蒸馏来优化类间分布对齐(压根没读懂是啥意思)
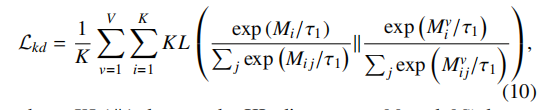
Mi相当于是一个簇i对所有簇的相似性度量,经 softmax(带温度 τ1)变成概率分布后,对共识空间的分布和各视图的分布计算 KL 散度并最小化。
方向是 KL(共识∥视图):共识空间充当老师(teacher),各视图充当学生(student),让每个视图的簇间几何关系去对齐共识的簇间几何关系。
——不就是转为概率分布之后加上KL散度约束吗?用共识分布作为目标,让视图分布接近它。该模块名为知识蒸馏,但如果共识端没有冻结或 detach,本质上更接近 KL 分布一致性约束,而不是严格 teacher-student 蒸馏。其有效性关键不在“蒸馏”这个概念,而在于共识分布是否确实比单视图分布更可靠。
4.3 簇引导的语义聚合模块
传统对比学习里,正负样本对的构造是个难点。
所以用KNN来选择正样本对,对于共识视图的每个样本,在每个视图里用余弦相似度找出最像它的 top-β 个邻居,认为这些邻居大概率和它同类。
所以对于共识空间的第 i 个样本,它的正样本合集是![]() 。
。
为解决负样本的问题,把不属于当前实例所在簇的样本都作为负样本。
——看损失函数设计就懂了
在此基础上,提出簇引导的聚合对比损失函数:
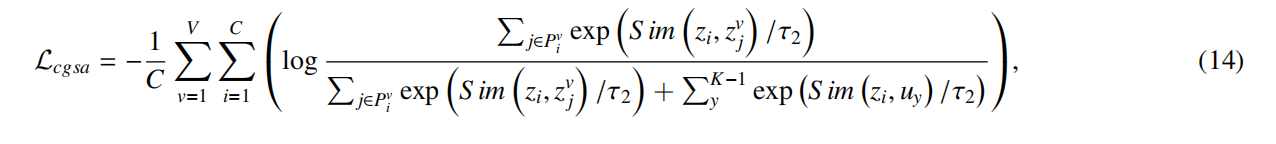
——所以正样本就是多个视图里相似度top几个样本表示,负样本是该样本所在簇之外的其他簇的簇表示。
4.4 两阶段
E-step 跑 K-means 给伪标签和簇中心,M-step 固定它们去最小化"重构 + 簇蒸馏 + 簇引导对比"的总损失,两步交替。
5、实验
6、总结
Mij=UU⊤ 这个思想挺好的,在簇表示层面,获取到簇和簇之间的相似性,找到相似性最大的簇,推开。
它的共识空间是自适应融合得到的,感觉在无监督学习中并不能很好的保证这个共识有效,所以在聚类任务中加自注意力机制对我来说也是一个难题。关键是怎么找到真正的共识?怎么保证共识的有效和稳定?

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)