本地部署大模型:Ollama全攻略
1. 为什么要本地部署大模型?
-
成本高:调用云端API(如GPT-4)测试多了费用高。
-
数据隐私:处理敏感数据的公司项目,担心传给第三方不安全。
-
网络不稳定:云端API可能出现请求超时。
2. Ollama是什么?
-
定位是“大模型领域的Docker”——一个开源工具,能把复杂的本地模型部署简化为一两行命令。
-
它负责下载、安装、运行和管理主流模型(如阿里的Qwen、Meta的Llama 3等),无需自己配置框架、驱动或写加载代码。
3. 硬件要求
-
内存:至少16GB(8GB只能玩小模型且卡)。
-
硬盘:建议至少50GB可用空间(模型文件几GB到几十GB不等)。
-
显卡:
-
NVIDIA显卡(最佳):需安装CUDA驱动,版本≥11.2。
-
AMD显卡:Linux支持较好,Windows逐步完善。
-
Apple Silicon(M1/M2/M3):支持良好。
-
4. Windows安装关键步骤
-
提供图形化安装包,过程简单。
-
重要前置操作:检查NVIDIA驱动。
-
打开“NVIDIA控制面板” → “系统信息” → “组件”选项卡,查看
NVCUDA64.DLL对应的版本号。 -
确保CUDA驱动版本≥11.2;若过低或没有控制面板,需去NVIDIA官网下载安装最新驱动并重启电脑。
-
-
或者win+R cmd 然后输入
nvidia-smi 可以看到表格左上角有版本号

进入到Ollama的官网进行下载安装,很简单。默认是下载到C盘。
然后执行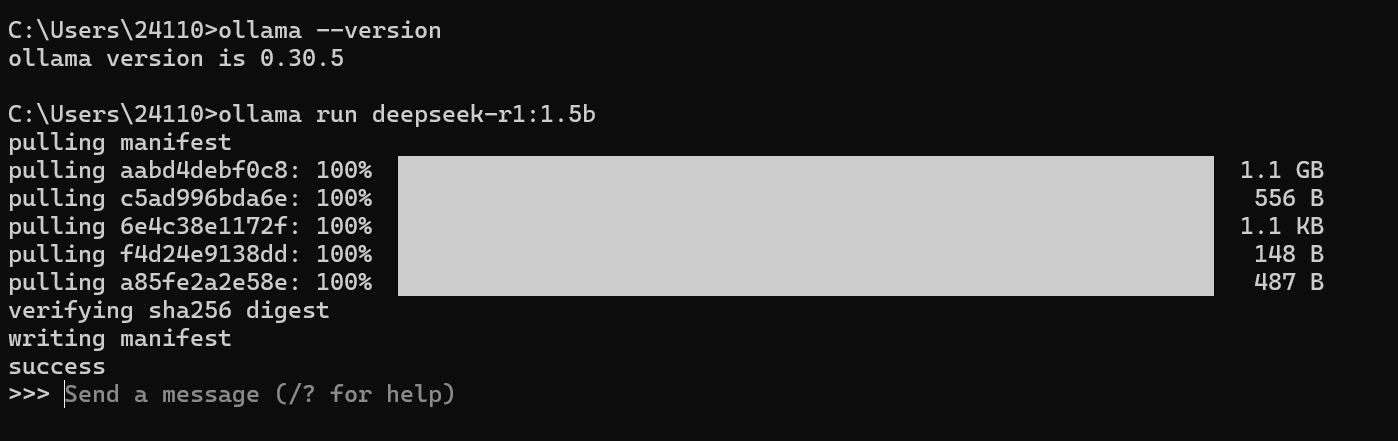
这是运行一个指定的模型,如果本地没有的话就会像这样去下载。
然后就可以实行对话了
导入Ollma的依赖
<dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-ollama</artifactId> <version>${langchain4j.version}</version> </dependency>
@Test
void test04() {
ChatLanguageModel model = OllamaChatModel
.builder()
.baseUrl("http://localhost:11434")
.modelName("deepseek-r1:1.5b")
.build();
String s = model.chat("你是谁啊");
System.out.println("s = " + s);
}这样就可以使用本地部署的deepseek-r1模型了。

ollama list 可以查看你本地部署了哪些大模型。
ollma pull 就像git pull和docker pull只是先下载下来,而不去运行他。
如果要删除本地大模型的话
ollama rm
ollama cp 复制一个已有的大模型
ollama show 具体的模型名称 可以查看一个模型的具体参数
ollama ps 可以查看具体有哪些模型在运行
创建属于自己的大模型
首先创建一个Modelfile文件
FROM (必需): 指定你创建的模型基于哪个基础模型。这必须是Ollama本地已经存在的模型。
PARAMETER: 设置模型的默认运行参数。这会覆盖基础模型中的参数。常用的有:
temperature: 控制输出的随机性。值越高(如1.0),回答越有创意和多样性;值越低(如0.2),回答越确定和保守。
top_p: 一种替代temperature的采样方法,控制生成文本的“焦点”。
stop: 定义一个或多个字符串,当模型生成这些字符串时,会自动停止。比如可以设置为"用户:",防止模型角色扮演时自己生成下一轮对话。
SYSTEM: 设置一个系统级的指令。这个指令会在每次会话开始时被加载,告诉模型它应该扮演什么角色、遵循什么规则。这是进行角色扮演(Role-Playing)和能力定制的核心。
TEMPLATE: 定义模型的完整对话模板。Ollama使用这个模板来组织用户的输入、历史记录和系统提示,然后喂给模型。你可以通过修改它来改变模型的交互方式。
————————————————
版权声明:本文为CSDN博主「杨小威v」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_22017479/article/details/148834583
下面是一个示例
# 基于 deepseek-r1:1.5b 模型
FROM deepseek-r1:1.5b
# 设置参数,让审查意见更具确定性和专业性
PARAMETER temperature 0.2
PARAMETER top_p 0.9
# 定义一个非常严格的系统提示词,赋予模型"Java代码审查专家"的人格
SYSTEM """
你是一位资深的Java代码审查专家,你的名字叫"码神"。
你将收到用户提供的一段Java代码。
你的任务是分析代码中潜在的错误、风格问题(遵循Java编码规范,如Google Java Style Guide)、性能瓶颈和安全漏洞。
你必须以结构化的格式提供反馈:
1. **总体评价:** 对代码质量进行一句话的简短总结。
2. **改进建议:** 以编号列表的形式,给出具体的、可操作的建议。对于每条建议,请提供"修改前"和"修改后"的代码块,以清晰地展示变化,并解释*为什么*推荐这样修改。
3. **最终评分:** 对代码进行1到10分的评分(1=需要完全重写, 10=完美)。
你的语气应该专业、有建设性且富有鼓励性。不要进行闲聊,只专注于代码审查本身。
注意审查时应关注:命名规范、异常处理、资源管理(如try-with-resources)、空指针安全、并发问题、性能优化等Java特有方面。
注意 如果没有优点,就说代码存在较多问题即可。
"""
进入到你的Modelfile文件所在的文件夹cmd,然后输入命令
ollama create java-reviewer -f ./Modelfile
ollama create: 这是创建自定义模型的命令。java-reviewer: 这是你给新模型起的名字。-f ./Modelfile:-f参数指定了你的Modelfile文件的路径。
然后ollama run 你设置的命令运行模型即可
可以看到是按照你设置的规则进行输出的。
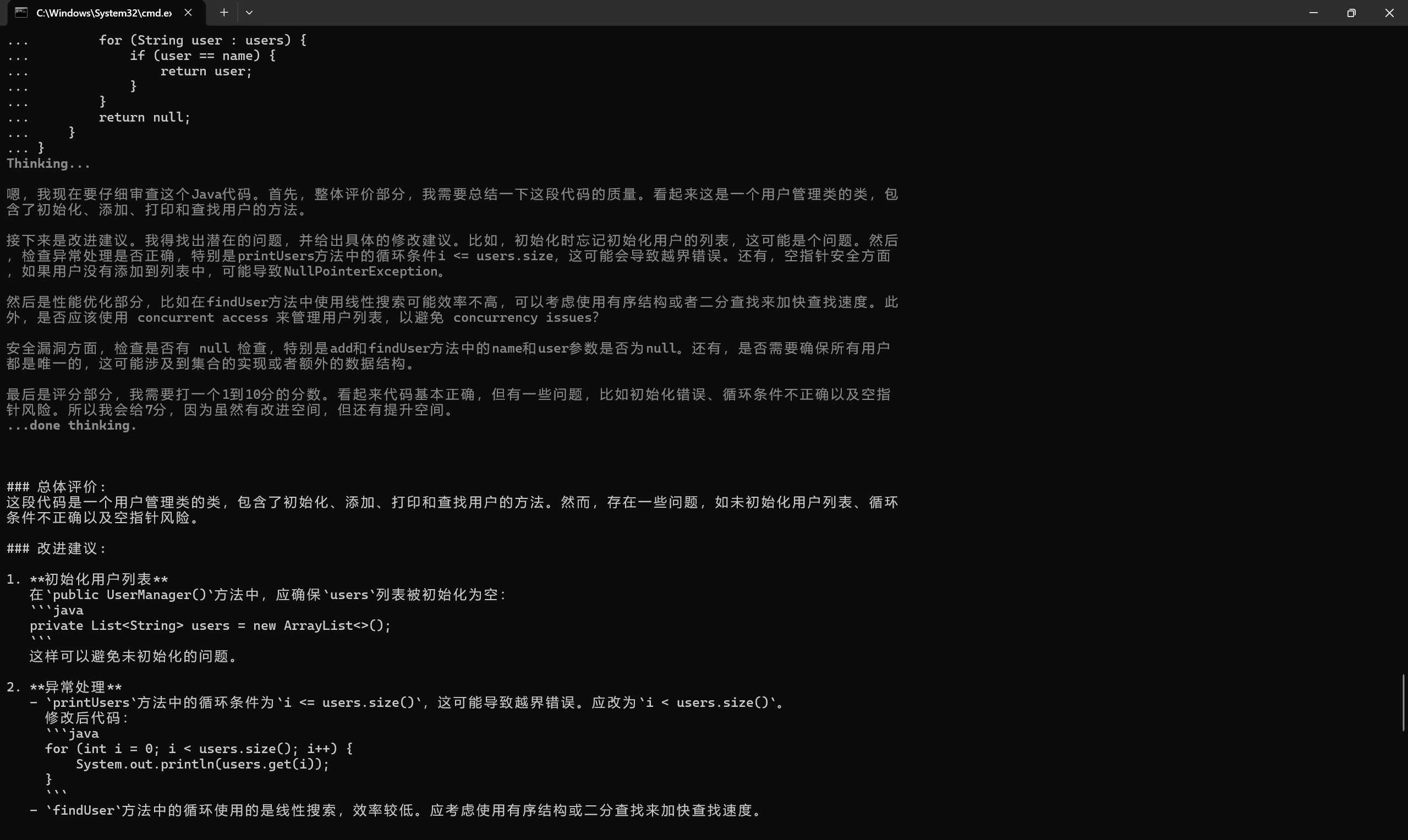

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 13
13 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)