RTX4090单卡跑Qwen3-32B实践:4bit量化+Transformers与vLLM双方案部署差异.193
一、前言
最近一直被32B环绕洗脑,本着体验和探索,核心思路就是聚焦实操体验与深度模型探索,抱着说干就干的落地心态,直面大模型本地部署的现实算力难题。当下开源大模型里,32B参数量的模型已是主流落地选型,可原生FP16精度加载的显存门槛直接拉满,显存占用轻轻松松突破60GB,这对于普通的RTX4090显卡来说完全是硬性瓶颈。4090显卡标准显存仅有24GB,按照常规的原生加载方案运行,显存直接溢出,模型根本没办法启动推理。
不管怎样,也要尝试一番,瞄准Qwen3-32B这款模型开展攻坚测试,不局限于现成通用方案,主动深挖显存占用的底层问题,尝试各类轻量化加载、量化适配思路,打通硬件显存上限和大模型运行需求之间的壁垒。今天我们以实操探索为主,跳出传统部署思路,针对性破解显存不足的行业通用痛点,一步步摸索适配消费级显卡运行大参数模型的可行路径,实打实完成算力瓶颈的突破验证。

二、算力瓶颈基础认知
1. 显存硬件边界
在尝试开始之前,先要弄懂RTX4090运行Qwen3-32B的核心难点,第一步要理清大模型权重存储规则与显卡显存硬件上限的冲突关系,我们先简单从基础算力参数、模型权重占用公式两个维度拆解底层硬件约束。
1.1 RTX4090核心显存参数
RTX4090标配24GB GDDR6X显存,显卡运行大模型时,显存会承载模型权重、KV 缓存、输入输出张量、计算临时数据四类核心数据,24GB显存并非全部可以用于模型加载,系统驱动、桌面渲染、CUDA底层运行时会固定占用2GB左右显存,实际可用显存仅 22GB 上下。
同时显卡显存带宽、算力浮点能力也会间接影响模型推理速度,但本次部署核心限制为显存容量,浮点算力仅作为推理速度优化的辅助参考条件。
1.2 Qwen3-32B原生权重显存占用计算
大模型权重存储精度直接决定显存占用大小,前期我们做过很多介绍,行业通用精度包含FP32、FP16/BF16、INT8、INT4四类,对应单参数占用显存大小分别为4Byte、2Byte、1Byte、0.5Byte。
Qwen3-32B 总参数量320 亿,原生BF16精度加载显存计算公式:32000000000 × 2Byte ÷ 1024³ ≈ 59.7GB。该数值远超RTX4090 24GB显存上限,哪怕预留少量KV缓存空间,原生高精度加载方案完全无法在单张4090显卡上运行,这也是所有消费级显卡落地32B模型的核心阻碍。
1.3 量化技术解决显存矛盾的核心逻辑
量化技术本质是压缩模型权重的数据精度,把原本占用2Byte的BF16权重压缩至0.5Byte的INT4格式,理论显存占用直接压缩75%,32B 模型4bit量化后理论显存占用约14.9GB,预留KV缓存、推理临时张量空间后,刚好可以适配RTX4090 24GB显存,完美解决硬件算力瓶颈。
2. Qwen3-32B模型基础特性
2.1 Qwen3-32B 基础架构定义
Qwen3-32B基于Transformer解码器架构搭建,采用RoPE位置编码、滑动窗口注意力机制,原生支持8K上下文窗口,中文语料训练占比超过60%,针对公文写作、代码生成、行业知识库问答、智能客服等场景完成专项微调。
模型官方开源版本支持ModelScope平台一键下载,内置原生Chat对话模板,无需额外对话格式适配,大幅降低私有化落地的二次开发成本。
2.2 应用落地核心优势
- 中文原生能力:海量中文互联网、政务、医疗、金融语料预训练,专业术语理解、长文本续写效果优于同参数海外开源模型;
- 轻量化部署兼容:原生支持 bitsandbytes 4bit/8bit 量化,官方权重格式适配Transformers、vLLM两大主流推理框架;
- 可控生成机制:内置思考模式开关、温度采样、top_p采样参数,支持业务侧自定义生成规则,规避幻觉输出;
- 开源商用许可:开源权重支持企业本地私有化部署,无需线上API调用,数据全程本地留存,满足政务、金融、医疗行业数据合规要求。
3. 两大推理框架技术定位
我们通过原生Transformers和vLLM两套推理框架来进行部署实践,分别对两套框架底层逻辑、显存调度机制、推理性能存在显著差异进行基础定位区分,通过差异对比方便我们后期根据业务需求选型。
3.1 Hugging Face Transformers框架
Transformers是大模型行业通用基础框架,原生支持全系列开源大模型权重加载,底层基于PyTorch原生算子实现,兼容bitsandbytes量化工具库,生态完整,文档丰富,入门门槛极低。
- 优势:代码写法简单,调试方便,支持完整模型权重可视化、显存精细化监控,适合新接触实践学习、单机测试、轻量化对话Demo开发;
- 短板:KV缓存调度机制老旧,连续多轮对话显存占用持续上涨,长文本生成推理速度偏低,高并发业务场景适配性差。
3.2 vLLM推理引擎
vLLM是面向高吞吐大模型推理的专用加速引擎,核心创新为PagedAttention分页注意力机制,大幅优化KV缓存显存复用逻辑,单卡并发对话能力、长文本生成速度远超原生 Transformers 框架。
- 优势:推理速度提升2-4倍,KV缓存显存占用更低,支持批量并发请求,适合企业私有化API服务、多用户在线智能客服等高并发业务;
- 短板:底层算子封装程度高,模型调试可视化能力弱,量化加载参数配置逻辑和Transformers存在差异,需要额外熟悉参数规则。
3.3 两套框架选型参考标准
- 初次接触学习、本地单机对话Demo、模型原理调试:优先选择Transformers框架,代码逻辑直观,报错信息完整,学习成本更低;
- 企业私有化 API 服务、多用户并发对话、长文档批量总结:优先选择vLLM引擎,推理吞吐更高,显存调度更高效,业务落地性能上限更高。
三、4bit 量化底层原理剖析
1. 量化技术基础定义
量化属于大模型模型压缩技术分支,核心工作逻辑是降低模型权重浮点数值的存储精度,在可接受的精度损失范围内,大幅压缩显存占用。
1.1 量化技术分类标准
通常量化技术分为两类:GPTQ 量化、BitsAndBytes动态量化;
- BitsAndBytes量化方案:该方案无需提前离线量化模型权重,模型加载阶段实时完成权重量化,无需下载量化后的模型文件,仅使用官方原生权重即可完成4bit量化加载,部署流程极简,我们本次RTX4090部署方案全部采用的是这种形式;
- GPTQ量化方案:此方案需要提前对模型权重做离线量化处理,需要单独下载量化版权重文件,部署流程繁琐,本次落地方案不做重点讲解。
1.2 INT4数值映射底层逻辑
原生BF16权重数值范围覆盖正负数万区间,INT4量化仅保留16个离散数值,通过浮点映射公式将大范围浮点权重压缩至16个整数区间,推理阶段再反向还原浮点数值参与计算。
NF4量化格式为BitsAndBytes官方优化4bit量化格式,相比传统INT4量化,数值分布贴合大模型权重原生正态分布,量化带来的语义精度损失更小,本次部署代码统一采用NF4量化类型,兼顾显存压缩效果与模型生成质量。
1.3 双量化机制补充原理
本次代码配置开启bnb_4bit_use_double_quant双量化功能,第一层NF4量化压缩基础权重,第二层二次量化压缩量化参数,进一步降低模型加载显存占用,针对32B超大参数量模型收益明显,RTX4090显卡开启该参数后,模型加载显存可降低1.5GB左右。
2. BitsAndBytes量化计算逻辑
这里重点拆解RTX4090部署代码中BitsAndBytesConfig配置参数的底层计算逻辑,逐条解释量化参数工作原理,完整打通量化权重加载的底层链路。
2.1 基础量化核心参数原理
- load_in_4bit:开关参数,控制是否开启4bit量化加载,关闭后模型以原生BF16精度加载,RTX4090会直接显存溢出;
- bnb_4bit_quant_type:量化数据格式,可选nf4、fp4,nf4适配大模型权重正态分布,语义损失更低,工程落地首选;
- bnb_4bit_compute_dtype:计算精度参数,模型量化权重还原后,推理计算过程使用的浮点精度,本次代码设置torch.bfloat16,BF16计算精度兼顾显存占用与生成效果,RTX4090显卡原生支持BF16硬件加速;
- bnb_4bit_use_double_quant:双量化开关,二次压缩量化参数显存,大参数量模型强制开启。
2.2 量化权重加载完整计算流程
模型启动加载阶段:PyTorch读取本地 Qwen3-32B原生BF16权重文件,BitsAndBytes工具库实时对每层Transformer权重执行NF4量化映射,将2Byte权重压缩为0.5Byte INT4格式存储至显卡显存;
推理计算阶段:显存内INT4权重通过量化反演算子还原为BF16浮点数值,完成注意力计算、前馈网络计算,计算结果不会保留量化压缩格式,保证文本生成语义质量。
2.3 量化精度损失可控性说明
4bit量化存在极轻微语义精度损失,在日常对话、文档总结、代码生成等通用场景下,肉眼无法感知生成内容差异;
专业医疗、金融等高严谨垂类场景,可通过微调LoRA适配器修复量化带来的细微精度损失,平衡显存占用与生成效果。
3. RTX4090显存调度底层逻辑
RTX4090显卡运行Qwen3-32B时,显存分配、显存回收、显存峰值管控三大底层逻辑,仔细观察下图中的标注点位,直观展示显存占用分区。
3.1 RTX4090显存分区结构图
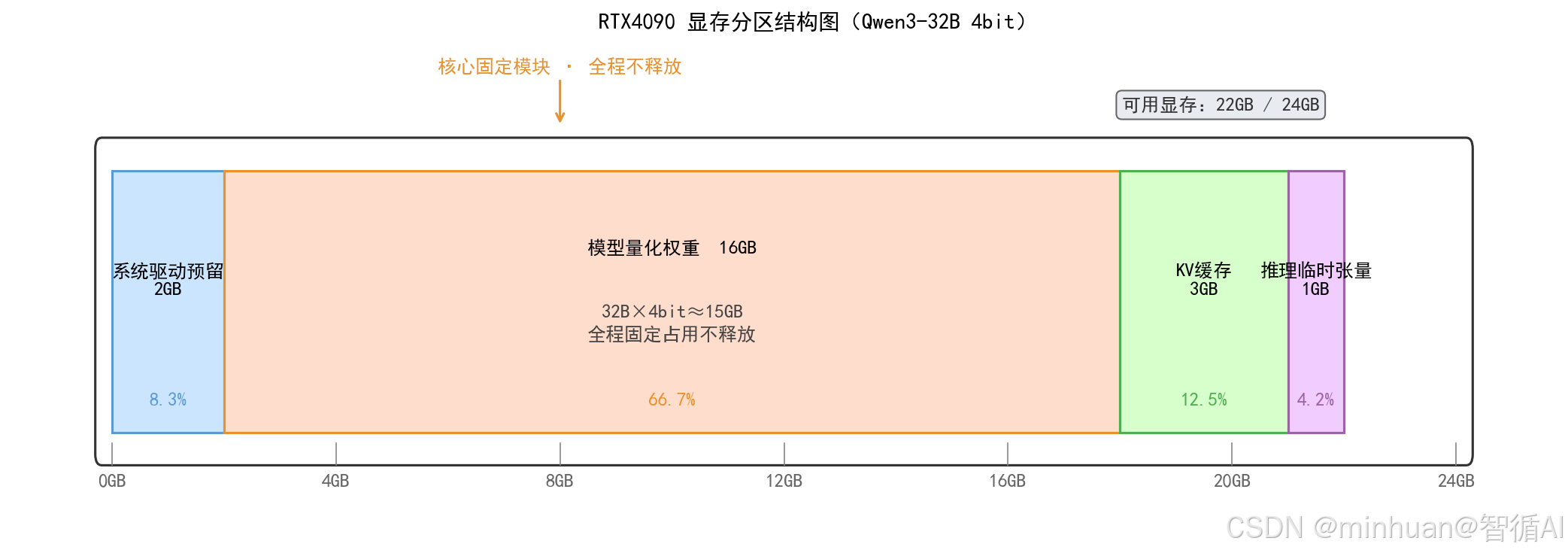
图示说明:显存空间分为四大区域,自左而右分别为系统驱动预留显存、模型量化权重显存、KV缓存显存、推理临时张量显存,标注24GB总显存、22GB可用显存数值,清晰展示 32B-4bit模型各分区显存占用参考值。
模型权重显存分配规则:
- RTX4090加载Qwen3-32B 4bit量化权重时,显卡CUDA显存自动分配约15GB空间存放量化模型权重,权重显存加载完成后不会动态释放,全程占用固定显存空间,是显存占用的核心固定模块。
KV缓存显存动态调度逻辑:
- KV缓存是大模型推理过程中动态变化的显存模块,用于存储对话上下文的键值向量,原生Transformers框架KV缓存不会自动复用显存,多轮对话后KV缓存显存持续累加,极易触发显存溢出;
- vLLM引擎依靠PagedAttention分页机制,自动复用闲置 KV 缓存显存,多轮对话显存涨幅极低,长文本生成显存占用稳定。
3.2 Transformers与vLLM KV缓存显存对比流程图
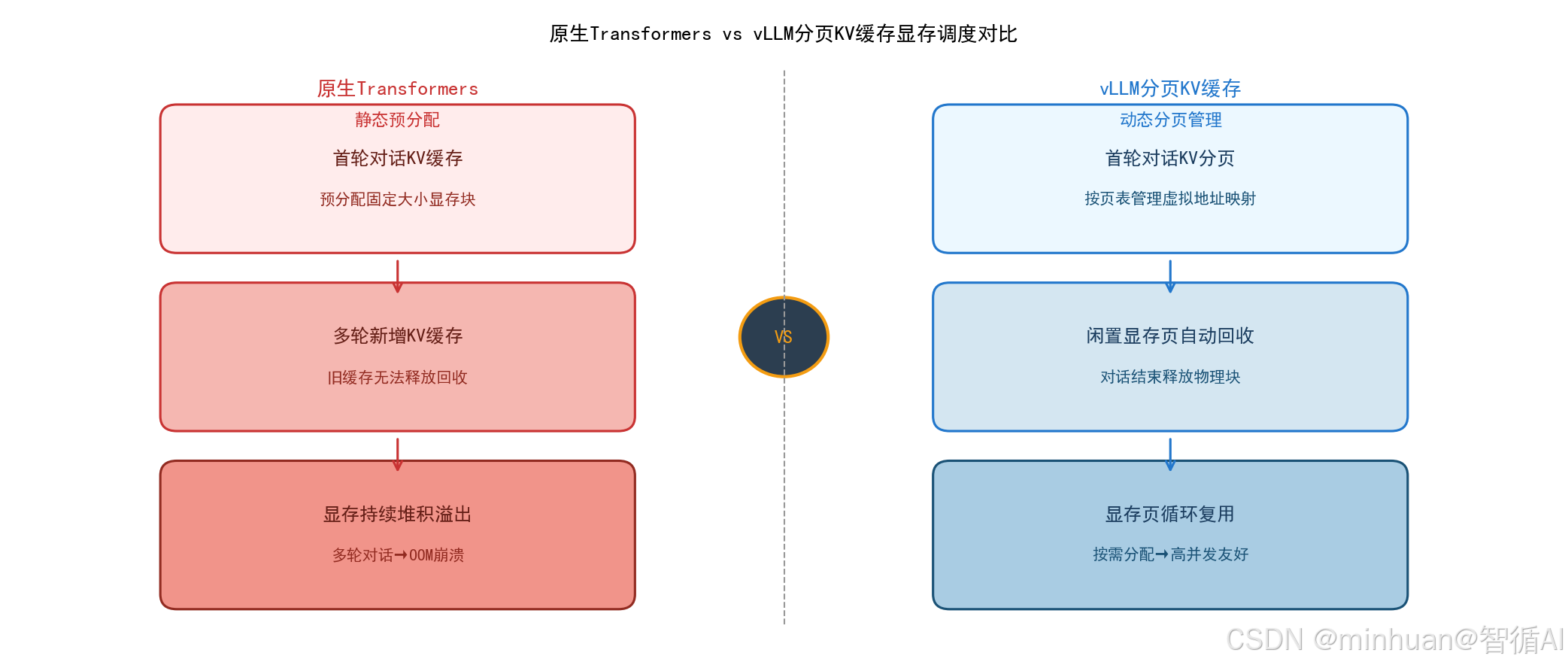
图示说明:
- 左侧为原生Transformers KV缓存逻辑,每一轮对话新增KV缓存显存无法回收;
- 右侧为vLLM分页KV缓存逻辑,闲置显存页自动回收复用,直观展示二者显存调度差异。
显存峰值管控优化方案:
- RTX4090运行32B模型显存压力较大,工程落地时通过两类参数管控显存峰值:
- Transformers框架设置device_map="auto"自动分配显卡显存,自动规避显存溢出;
- vLLM框架设置gpu_memory_utilization=0.96,限制显卡显存最大占用比例,预留少量显存空间存放临时张量,避免推理阶段显存爆显存报错。
四、原生Transformers框架完整实践
1. 环境依赖安装清单
通过Transformers框架运行Qwen3-32B模型部署,需要完成Python环境、CUDA驱动、第三方依赖库安装,适配RTX4090 Linux服务器环境,以前的服务器部署章节我们也完整讲过,详细过程可参考:
1.1 基础环境版本约束
RTX4090显卡推荐Python3.11版本,CUDA驱动版本≥12.1,PyTorch版本≥2.0,高版本PyTorch原生支持 SDPA 注意力机制,无需额外安装Flash-Attention加速库,降低环境搭建难度。
第三方依赖一键安装命令:
pip install torch==2.2.0 transformers modelscope bitsandbytes accelerate依赖库功能说明:
- torch:PyTorch 深度学习框架,模型计算底层载体;
- transformers:大模型原生加载框架,分词器、模型加载核心库;
- modelscope:魔搭平台模型下载工具,断点续传下载 Qwen3-32B 官方权重;
- bitsandbytes:4bit 量化核心工具库,实现模型权重实时量化;
- accelerate:自动显存分配工具,实现 device_map 自动显存调度。
2. 模型离线下载业务流程
ModelScope平台通过snapshot_download工具实现模型断点续传下载,网络中断后重启程序不会重复下载已完成文件,我们详细拆解模型下载全流程逻辑,并详细注释讲解下载参数含义,这是模型初始运行的核心重点。
模型下载核心参数解析:
- model_name:平台上模型标准名称,Qwen3-32B标准名称为 qwen/Qwen3-32B;
- cache_dir:模型本地存储根路径,建议设置独立大硬盘路径,模型权重总文件大小约16GB;
- revision="master":模型主分支权重,官方最新稳定版本权重。
模型下载全链路执行步骤:
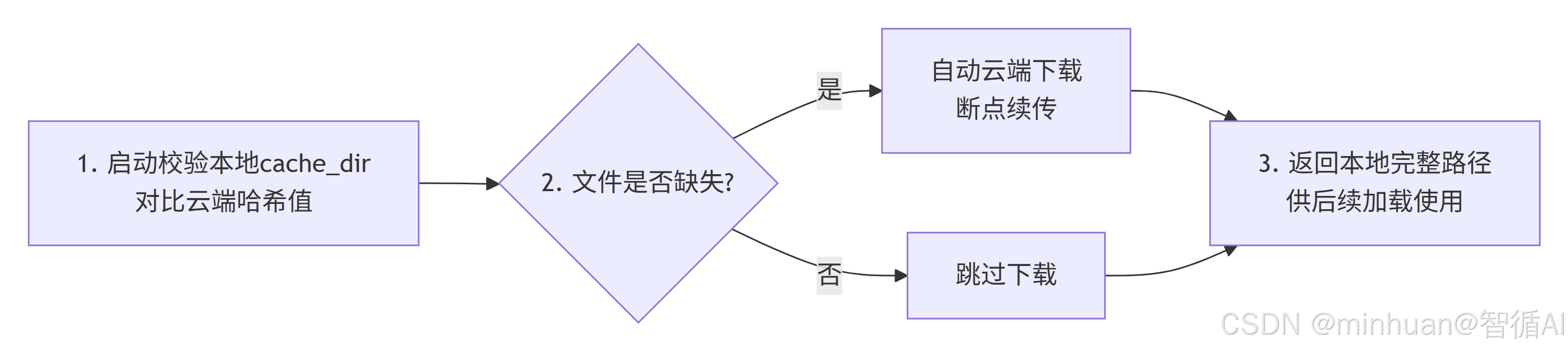
- 第一步:程序启动后自动校验本地cache_dir路径内模型文件,对比云端模型文件哈希值;
- 第二步:缺失文件自动云端下载,完整文件跳过下载,实现断点续传;
- 第三步:全部文件校验完成后,返回本地模型完整路径,后续模型、分词器加载全部读取该本地路径文件。
3. 完整运行示例实践
示例使用BitsAndBytes NF4 4bit量化在单卡RTX4090上加载Qwen3-32B大模型,通过chat_template格式化对话并测试推理,输出显存占用与生成速度统计。
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
from modelscope import snapshot_download
import torch
import os
# 屏蔽transformers/bitsandbytes警告
import warnings
warnings.filterwarnings("ignore", category=FutureWarning)
# ===================== 1. 配置参数 =====================
# 模型名称(修正空格,ModelScope标准名称)
model_name = "qwen/Qwen3-32B"
# 模型本地保存路径
cache_dir = "/home/model"
# 4090显卡设备
device = "cuda"
# ===================== 2. 下载模型到本地 =====================
print("正在下载/校验模型缓存...")
# 下载模型(断点续传,已下载会直接校验跳过)
local_model_path = snapshot_download(
model_name,
cache_dir=cache_dir,
revision="master"
)
print(f"模型已就绪,本地路径:{local_model_path}")
# ===================== 3. 加载Tokenizer(分词器) =====================
tokenizer = AutoTokenizer.from_pretrained(
local_model_path,
trust_remote_code=True
)
# ===================== 4. 4090专用:量化加载模型(核心!解决显存不足) =====================
print("正在加载模型(4bit量化,适配4090 24G显存)...")
# 4bit量化配置(通过BitsAndBytesConfig传入,新版transformers不再支持直接传load_in_4bit)
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True,
)
model = AutoModelForCausalLM.from_pretrained(
local_model_path,
trust_remote_code=True,
# 量化配置
quantization_config=bnb_config,
# SDPA注意力(PyTorch 2.0+内置,无需flash-attn包)
attn_implementation="sdpa",
# 自动分配显存
device_map="auto",
dtype=torch.bfloat16
)
# 模型设置为推理模式
model.eval()
# 输出模型加载后显存占用
torch.cuda.synchronize()
alloc_mem = torch.cuda.memory_allocated() / 1024**3
reserv_mem = torch.cuda.memory_reserved() / 1024**3
total_mem = torch.cuda.get_device_properties(0).total_memory / 1024**3
free_mem = total_mem - reserv_mem
print(f"\n--- 模型加载后显存 ---")
print(f"已分配:{alloc_mem:.2f} GB | 已保留:{reserv_mem:.2f} GB | 剩余:{free_mem:.2f} GB / 总计:{total_mem:.2f} GB")
# ===================== 5. 测试推理 =====================
print("\n模型加载完成!开始测试对话:")
user_input = "你了解《中国高血压防治指南(2023修订版)》《中国2型糖尿病防治指南(2020版)》吗,分别总结其内容,300字以内;"
# 用chat_template格式化对话(避免模型重复用户输入或幻觉出额外指令)
# /no_think 关闭Qwen3思考模式
messages = [{"role": "user", "content": user_input + " /no_think"}]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
# 构造输入
inputs = tokenizer(prompt, return_tensors="pt").to(device)
input_token_count = inputs["input_ids"].shape[1]
print(f"输入Token数:{input_token_count}")
# 生成回答(计时)
import time
start_time = time.time()
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=512,
temperature=0.7,
do_sample=True,
top_p=0.8,
repetition_penalty=1.1, # 抑制重复生成
)
elapsed = time.time() - start_time
# 统计Token
output_token_count = outputs.shape[1]
new_token_count = output_token_count - input_token_count
tokens_per_second = new_token_count / elapsed if elapsed > 0 else 0
# 解码输出(只取新生成部分,跳过prompt)
import re
new_token_ids = outputs[0][input_token_count:]
response = tokenizer.decode(new_token_ids, skip_special_tokens=True)
response = re.sub(r"<think.*?</think\s*>", "", response, flags=re.DOTALL).strip()
print(f"用户:{user_input}")
print(f"助手:{response}")
print(f"\n--- Token统计 ---")
print(f"输入Token数:{input_token_count}")
print(f"输出Token数:{new_token_count}")
print(f"总Token数:{output_token_count}")
print(f"生成耗时:{elapsed:.2f}s")
print(f"生成速度:{tokens_per_second:.2f} tokens/s")
# 生成后显存占用
torch.cuda.synchronize()
alloc_mem2 = torch.cuda.memory_allocated() / 1024**3
reserv_mem2 = torch.cuda.memory_reserved() / 1024**3
print(f"\n--- 生成后显存 ---")
print(f"已分配:{alloc_mem2:.2f} GB | 已保留:{reserv_mem2:.2f} GB | 峰值分配:{torch.cuda.max_memory_allocated()/1024**3:.2f} GB")输出结果:
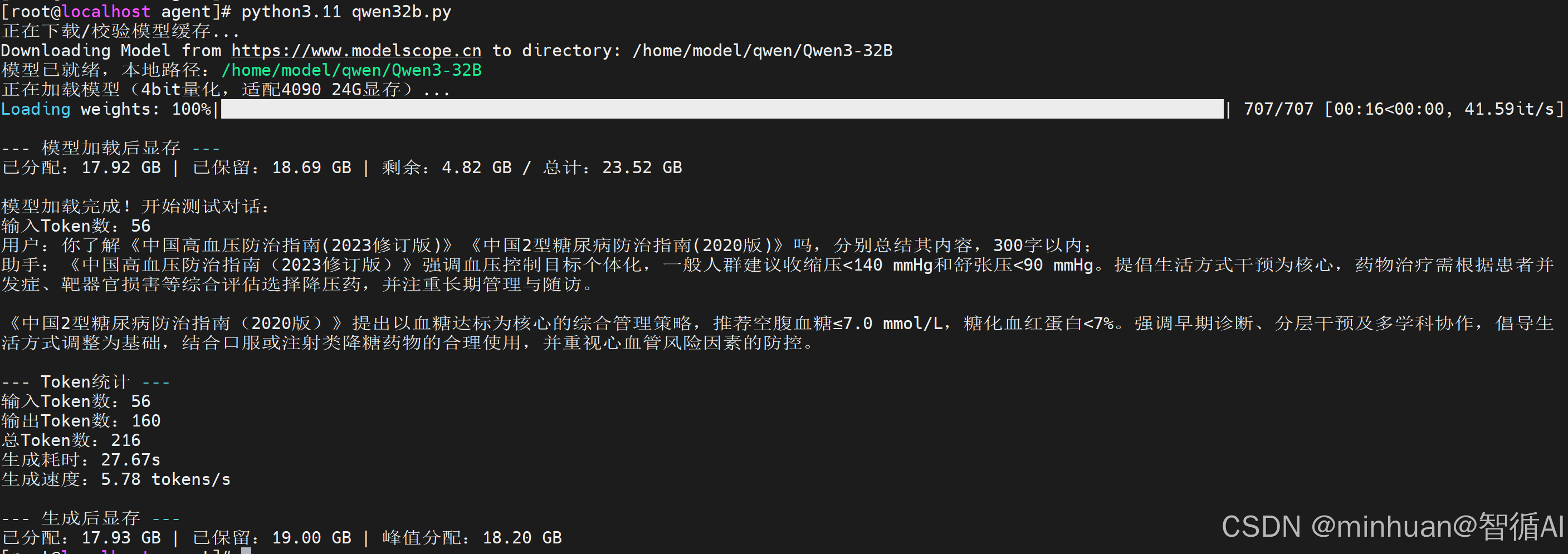
正在下载/校验模型缓存...
Downloading Model from modelscope to directory: /home/model/qwen/Qwen3-32B
模型已就绪,本地路径:/home/model/qwen/Qwen3-32B
正在加载模型(4bit量化,适配4090 24G显存)...
Loading weights: 100%|████████████████| 707/707 [00:16<00:00, 41.59it/s]--- 模型加载后显存 ---
已分配:17.92 GB | 已保留:18.69 GB | 剩余:4.82 GB / 总计:23.52 GB模型加载完成!开始测试对话:
输入Token数:56
用户:你了解《中国高血压防治指南(2023修订版)》《中国2型糖尿病防治指南(2020版)》吗,分别总结其内容,300字以内;
助手:《中国高血压防治指南(2023修订版)》强调血压控制目标个体化,一般人群建议收缩压<140 mmHg和舒张压<90 mmHg。提倡生活方式干预为核心,药物治疗需根据患者并发症、靶器官损害等综合评估选择降压药,并注重长期管理与随访。《中国2型糖尿病防治指南(2020版)》提出以血糖达标为核心的综合管理策略,推荐空腹血糖≤7.0 mmol/L,糖化血红蛋白<7%。强调早期诊断、分层干预及多学科协作,倡导生活方式调整为基础,结合口服或注射类降糖药物的合理使用,并重视心血管风险因素的防控。
--- Token统计 ---
输入Token数:56
输出Token数:160
总Token数:216
生成耗时:27.67s
生成速度:5.78 tokens/s--- 生成后显存 ---
已分配:17.93 GB | 已保留:19.00 GB | 峰值分配:18.20 GB
运行过程图示:
4. 推理流程逻辑拆解

通过以上示例我们对比观察Transformers框架模型加载、文本编码、模型生成、文本解码四大核心执行步骤,完整推理流程分为“模型下载、分词器加载、4bit量化模型加载、输入文本Token编码、GPU张量计算、文本生成、结果解码、显存统计”八大节点,核心重点逻辑如下:

4.1 模型权重加载阶段
程序读取本地Qwen3-32B权重文件,BitsAndBytes实时完成NF4量化压缩,量化权重自动写入RTX4090显卡显存,device_map自动分配显存空间,模型切换eval推理模式,关闭反向传播梯度计算,减少显存占用。
4.2 文本编码预处理阶段
用户输入自然语言文本传入分词器,分词器按照Qwen3原生词表拆分文本为Token编号,转换为PyTorch张量数据,张量数据搬运至RTX4090显卡CUDA显存,完成输入数据预处理。
4.3 Transformer推理计算阶段
模型解码器接收输入 Token 张量,逐层执行多头自注意力计算、前馈网络计算,KV缓存自动存储上下文向量,BF16精度完成矩阵运算,循环迭代生成新Token,直到达到 max_new_tokens最大长度限制。
4.4 生成文本解码阶段
模型输出完整Token编号张量,分词器反向映射Token编号至自然语言文字,自动屏蔽模型特殊控制标记符,输出完整对话回答文本,同步统计生成Token数量、推理耗时、显存峰值数据。
五、vLLM引擎高并发落地完整实践
1. vLLM 引擎环境安装
vLLM推理引擎底层基于CUDA算子编译,安装流程和Transformers存在差异,RTX4090 显卡运行vLLM,CUDA 版本≥12.1,Python版本 3.10-3.11,PyTorch版本2.0及以上,Qwen3-32B模型4bit量化兼容旧版vLLM引擎,新版本V1引擎对bitsandbytes量化支持不完善,代码内置环境变量关闭V1引擎,强制启动V0稳定引擎,规避量化加载报错问题。
vLLM一键安装命令:
pip install vllm modelscope torch2. vLLM核心参数底层解析
vLLM加载模型参数和Transformers框架差异较大,我们从最基础的量化、显存管控、上下文长度、注意力算子四大核心参数底层逻辑,明确RTX4090适配参数取值标准。
2.1 量化相关参数
- quantization="bitsandbytes":指定量化工具库为bitsandbytes,开启4bit量化;
- load_format="bitsandbytes":权重加载格式绑定bitsandbytes 量化格式;
- dtype="bfloat16":推理计算精度BF16,适配RTX4090硬件加速。
2.2 显存管控参数
- gpu_memory_utilization=0.96:显卡显存占用上限阈值,0.96 代表最多占用96%显卡显存,预留4%显存存放临时张量,防止推理阶段显存溢出,RTX4090运行32B模型固定设置0.96。
2.3 上下文长度参数
- max_model_len=1024:模型最大上下文窗口长度,Qwen3-32B官方原生KV缓存限制,设置过大数值会触发显存溢出,RTX4090单卡推荐设置1024上下文长度。
2.4 注意力算子参数
- enforce_eager=True:强制启用Eager原生CUDA算子,无Flash-Attention加速库时强制开启该参数,规避注意力算子报错。
3. 完整运行示例实践
示例使用vLLM框架加载Qwen3-32B的bitsandbytes 4bit量化模型,通过PagedAttention分页KV缓存实现高效推理,输出显存占用与生成速度统计,验证单卡RTX4090可运行。
import os
# 禁用vLLM v1引擎(v1对bitsandbytes支持不完善,回退v0稳定引擎)
os.environ["VLLM_USE_V1"] = "0"
from vllm import LLM, SamplingParams
from modelscope import snapshot_download
import subprocess
import time
# ===================== 1. 配置参数 =====================
model_name = "qwen/Qwen3-32B"
cache_dir = "/home/model"
# ===================== 2. 下载模型到本地 =====================
print("正在下载/校验模型缓存...")
local_model_path = snapshot_download(
model_name,
cache_dir=cache_dir,
revision="master"
)
print(f"模型已就绪,本地路径:{local_model_path}")
# ===================== 3. vLLM加载模型(4bit量化) =====================
print("正在加载模型(vLLM + bitsandbytes 4bit量化)...")
llm = LLM(
model=local_model_path,
trust_remote_code=True,
# 4bit量化(运行时量化FP16权重)
quantization="bitsandbytes",
load_format="bitsandbytes",
dtype="bfloat16",
# 显存利用率(拉满,32B-4bit单卡显存紧张)
gpu_memory_utilization=0.96,
# 最大上下文长度(错误提示可用KV cache仅支持1008,设1024)
max_model_len=1024,
# 无flash-attn时使用eager模式(如已装flash-attn可去掉此行)
enforce_eager=True,
)
# 输出模型加载后显存占用(vLLM在子进程中分配显存,需通过nvidia-smi读取)
import subprocess
def get_gpu_memory():
result = subprocess.run(
["nvidia-smi", "--query-gpu=memory.used,memory.total", "--format=csv,noheader,nounits"],
capture_output=True, text=True
)
used, total = result.stdout.strip().split(", ")
return float(used) / 1024, float(total) / 1024 # 转GB
used_mem, total_mem = get_gpu_memory()
print(f"\n--- 模型加载后显存(nvidia-smi) ---")
print(f"已使用:{used_mem:.2f} GB / 总计:{total_mem:.2f} GB | 剩余:{total_mem - used_mem:.2f} GB")
# ===================== 4. 测试推理 =====================
print("\n模型加载完成!开始测试对话:")
user_input = "你了解《中国高血压防治指南(2023修订版)》《中国2型糖尿病防治指南(2020版)》吗,分别总结其内容,300字以内;"
# 用tokenizer的chat_template格式化对话(避免模型幻觉出额外的用户指令)
# /no_think 关闭Qwen3思考模式,否则会先输出大段思考过程
tokenizer = llm.get_tokenizer()
messages = [{"role": "user", "content": user_input + " /no_think"}]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
sampling_params = SamplingParams(
temperature=0.7,
top_p=0.8,
max_tokens=512,
)
print(f"用户:{user_input}")
start_time = time.time()
outputs = llm.generate([prompt], sampling_params)
elapsed = time.time() - start_time
# 统计结果
output = outputs[0]
completion = output.outputs[0]
prompt_tokens = len(output.prompt_token_ids)
new_tokens = len(completion.token_ids)
speed = new_tokens / elapsed if elapsed > 0 else 0
print(f"助手:{completion.text}")
print(f"\n--- Token统计 ---")
print(f"输入Token数:{prompt_tokens}")
print(f"输出Token数:{new_tokens}")
print(f"生成耗时:{elapsed:.2f}s")
print(f"生成速度:{speed:.2f} tokens/s")
# 生成后显存占用
used_mem2, total_mem2 = get_gpu_memory()
print(f"\n--- 生成后显存(nvidia-smi) ---")
print(f"已使用:{used_mem2:.2f} GB / 总计:{total_mem2:.2f} GB | 剩余:{total_mem2 - used_mem2:.2f} GB")输出结果:
正在下载/校验模型缓存...
Downloading Model from modelscope to directory: /home/model/qwen/Qwen3-32B
模型已就绪,本地路径:/home/model/qwen/Qwen3-32B
正在加载模型(vLLM + bitsandbytes 4bit量化)...
Loading safetensors checkpoint shards: 0% Completed | 0/17 [00:00<?, ?it/s]
(EngineCore pid=1223585) /usr/local/python3.11.3/lib/python3.11/site-packages/bitsandbytes/backends/cuda/ops.py:213: FutureWarning: _check_is_size will be removed in a future PyTorch release along with guard_size_oblivious. Use _check(i >= 0) instead.
(EngineCore pid=1223585) torch._check_is_size(blocksize)
Loading safetensors checkpoint shards: 6% Completed | 1/17 [00:01<00:17, 1.12s/it]
Loading safetensors checkpoint shards: 12% Completed | 2/17 [00:02<00:17, 1.14s/it]
..........
Loading safetensors checkpoint shards: 100% Completed | 17/17 [00:19<00:00, 1.09s/it]
Loading safetensors checkpoint shards: 100% Completed | 17/17 [00:19<00:00, 1.14s/it]
(EngineCore pid=1223585)--- 模型加载后显存(nvidia-smi) ---
已使用:22.28 GB / 总计:23.99 GB | 剩余:1.70 GB模型加载完成!开始测试对话:
用户:你了解《中国高血压防治指南(2023修订版)》《中国2型糖尿病防治指南(2020版)》吗,分别总结其内容,300字以内;
Rendering prompts: 100%|████████████████████████| 1/1 [00:00<00:00, 77.03it/s]
Processed prompts: 0%| | 0/1 [00:00<?, ?it/s, est. speed input: 0.00 toks/s, output: 0.00 toks/s](EngineCore pid=1223585) /usr/local/python3.11.3/lib/python3.11/site-packages/bitsandbytes/backends/cuda/ops.py:468: FutureWarning: _check_is_size will be removed in a future PyTorch release along with guard_size_oblivious. Use _check(i >= 0) instead.
(EngineCore pid=1223585) torch._check_is_size(blocksize)
Processed prompts: 100%|███████████████████████| 1/1 [00:13<00:00, 13.44s/it, est. speed input: 4.17 toks/s, output: 11.31 toks/s]
助手:<think></think>
《中国高血压防治指南(2023修订版)》强调高血压的综合管理,提出血压诊断标准为≥140/90 mmHg,并细化分级诊疗路径。倡导生活方式干预为基础,合理用药,注重长期随访与并发症防控,尤其关注老年人、合并糖尿病等高危人群的管理策略。
《中国2型糖尿病防治指南(2020版)》强调早期筛查与个体化治疗。建议空腹血糖≥7.0 mmol/L或糖化血红蛋白≥6.5%为诊断标准,提倡生活方式干预与药物治疗相结合,强调血糖、血压、血脂的综合控制,并注重糖尿病慢性并发症的预防与管理。
--- Token统计 ---
输入Token数:56
输出Token数:152
生成耗时:13.45s
生成速度:11.30 tokens/s--- 生成后显存(nvidia-smi) ---
已使用:22.29 GB / 总计:23.99 GB | 剩余:1.70 GB
运行过程图示:
六、两种方式的输出对比
1. 性能对比总结
在RTX4090上运行Qwen3-32B 4bit模型,同等环境下vLLM与原生Transformer 推理性能差距非常显著:
1.1 生成速度
- vLLM:11.30 tokens/s
- Transformers:5.78 tokens/s
- vLLM 速度提升近2倍(≈96%),生成效率大幅领先。
1.2 耗时表现
- vLLM耗时 13.45s,Transformers耗时27.67s
- vLLM耗时减少一半以上,长文本对话优势更明显。
1.3 显存占用
- vLLM显存使用22.29GB,接近满卡,调度更激进
- Transformers显存分配17.93GB、余留空间更足
- vLLM能更高效利用显存空间,实现满负载运行;Transformers显存利用率偏低。
1.4 生成能力
- 输入Token一致都是56,vLLM输出152Token,Transformers输出160Token,生成长度基本一致,说明模型输出能力无差异,差距完全来自推理框架效率。
2. 图示对比
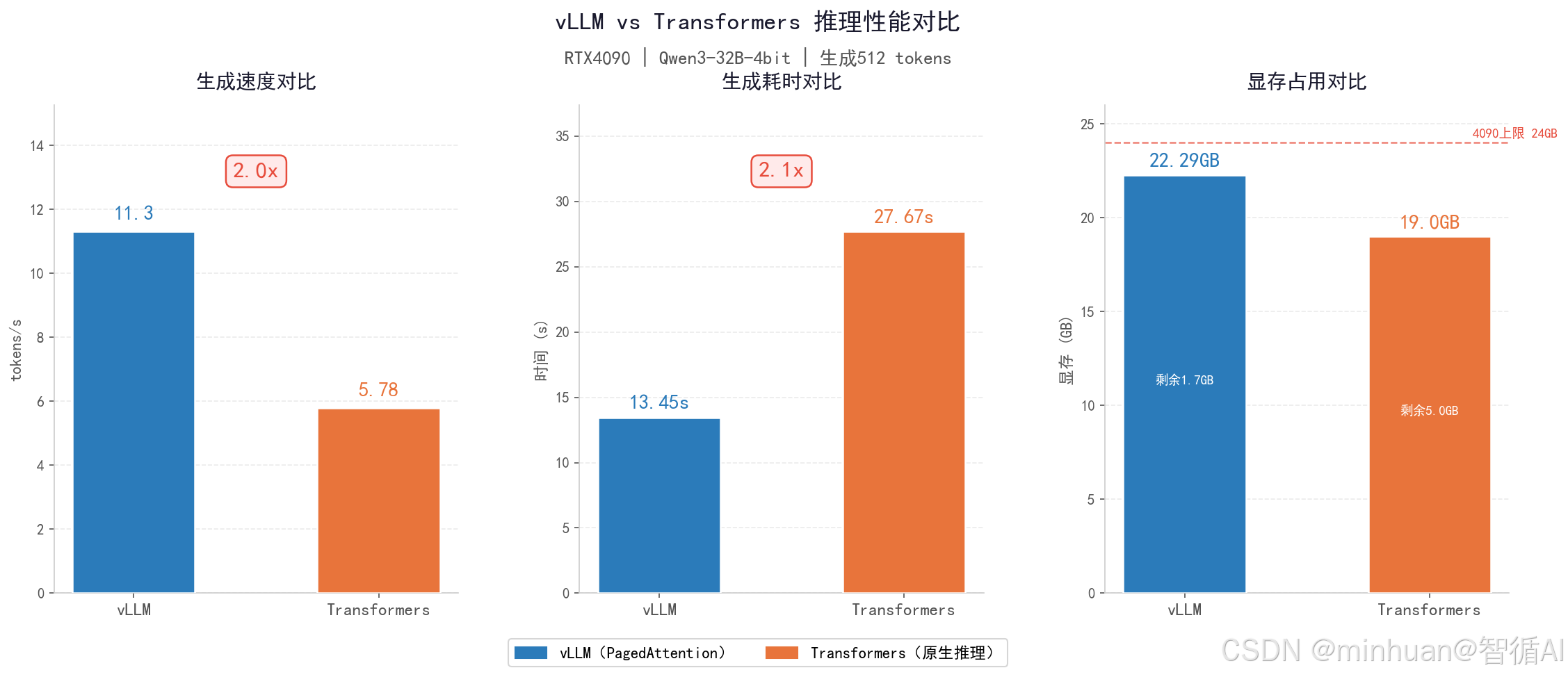
- 生成速度:vLLM几乎是Transformers的2倍
- 生成耗时:vLLM比Transformers快一倍
- 显存占用:vLLM更高效吃满显存,Transformers显存闲置更多
在RTX4090 24GB显卡上运行32B大模型时:
- vLLM推理效率远超原生Transformers,速度提升接近100%
- 显存调度更智能,能充分利用硬件资源
- 同等输入下输出长度一致,vLLM是消费级显卡跑大模型的最优方案
七、总结
本次实测在RTX4090环境对比vLLM与原生Transformers部署Qwen3-32B 4bit模型,相同 56 个输入 token 下,两款框架生成文本质量相差无几,输出token数量基本持平,但性能表现拉开明显差距。vLLM依托分页式KV缓存机制,闲置显存页面可循环回收复用,输出具有明显优势;原生Transformers缓存无法自动释放,速度偏慢,耗时也翻倍。显存层面vLLM充分挖满硬件资源,占用22.29GB,Transformers最高仅占用19GB,大量显存资源闲置浪费。
通过一系列对比下来也能体会到,大模型落地瓶颈往往不在模型参数,而在显存调度算法。原先只在理论上了解分页KV缓存优势,实操数据落地后才直观看懂架构优化带来的质变。给正在学习大模型部署的朋友一点建议,不要只停留在调用代码跑通模型,也可以选择不同模型做同环境对照实验,用真实数据印证理论,既有说服力也有趣味性,同时更能深化我们对大模型应用过程的新感悟和新体验。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献79条内容
已为社区贡献79条内容

所有评论(0)