你的旧笔记本值钱了——Google 发布 Gemma 4 12B,16GB 内存跑满血多模态
Google DeepMind 在 6 月 3 日放出了 Gemma 4 系列的最新成员:Gemma 4 12B。
这不是一个简单的参数升级。它是一个无编码器的统一多模态模型——Google 用一种全新的架构思路,把视觉、音频、文本三种模态的输入,全部直接送进同一个 Transformer 主干,不再依赖独立的视觉编码器或音频编码器。
结果是:一个 12B 参数的模型,只需要 16GB 内存就能跑,基准测试成绩却逼近自家 26B 的大模型。

截至目前,Gemma 4 系列在 Hugging Face 和 Kaggle 上的累计下载量已经突破 1.5 亿次。这不是一次常规的模型迭代,这是 Google 在端侧 AI 赛道上扔下的一枚重磅炸弹。
亮点一:无编码器统一架构——砍掉 ViT,只用 35M 模块
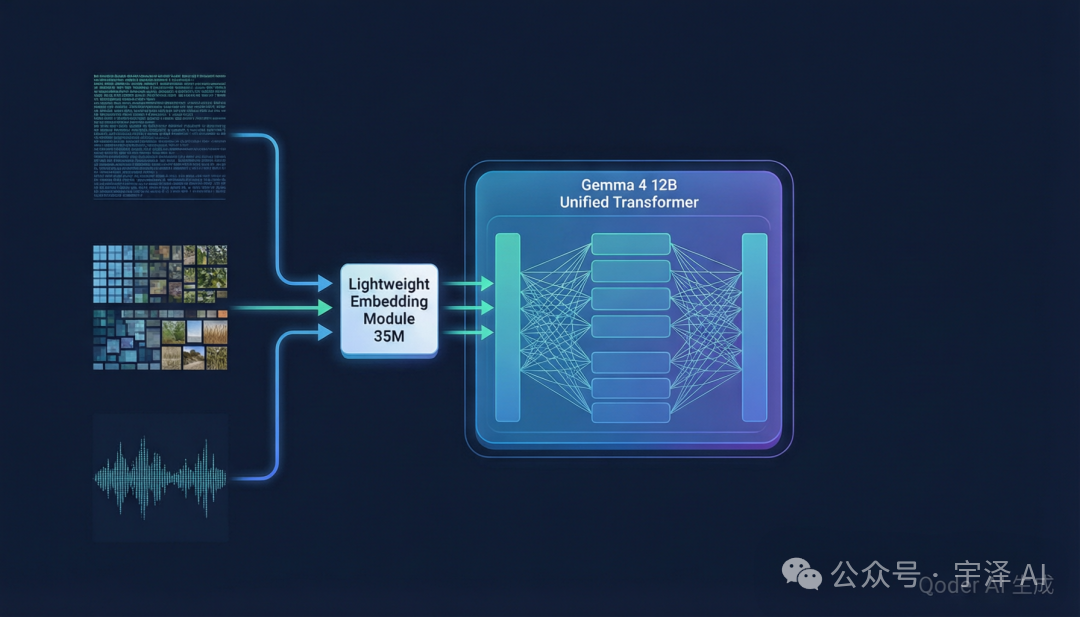
这是 Gemma 4 12B 最核心的技术创新:彻底移除了多模态编码器。
在 Gemma 3 时代,视觉输入需要通过一个 27 层的 Vision Transformer(ViT)先提取特征,再喂给语言模型。这个 ViT 体积不小,计算开销也大。
Gemma 4 12B 把这个 27 层 ViT 整块砍掉,替换成一个只有 35M 参数的超轻量嵌入模块——本质上就是一次矩阵乘法。图像像素经过这个模块后,直接映射到和文本 token 相同的向量空间,然后一起进入 LLM 主干处理。
音频部分更激进:音频编码器被完全移除。原始的 16kHz 音频信号直接投影到文本 token 的同一维度空间,让 LLM 自己学会从原始波形中理解语义。
这意味着什么?模型变得更小、更快、更高效。三种模态不再需要三套独立的编码器,一个统一的 Transformer 就能处理所有输入。这也是为什么 12B 参数就够用——因为参数不再被冗余的编码器吃掉了。
亮点二:原生三模态——文字、图像、音频一把抓
Gemma 4 12B 不是"支持"多模态,它天生就是多模态的。
文本理解:256K 上下文窗口,支持 140+ 种语言。一整本书、一个完整的代码仓库、几十页的 PDF 文档——都可以一次性塞进去处理。在 MRCR v2(128K 长上下文检索)测试中,12B 模型的表现与 26B 模型持平。
视觉理解:不需要额外的视觉管线,模型直接理解图像内容。不管是文档截图、图表分析、还是自然场景照片,Gemma 4 12B 都能给出详细的描述和推理。在 DocVQA(文档视觉问答)上拿下 94.9 分,InfoVQA 得分 88.4——这意味着它读图表、看截图的能力已经非常强。

音频理解:这是 Gemma 4 12B 的独家能力——它是 Gemma 系列中最大的支持原生音频输入的模型。你可以直接给它一段语音,它能理解内容、识别情感、甚至分析语气。注意,这个能力在 Gemma 4 26B 和 31B 大模型上反而没有(大模型只支持文本+图像),12B 是目前唯一同时吃三种模态的版本。
亮点三:12B 打 27B——参数少一半,性能不输
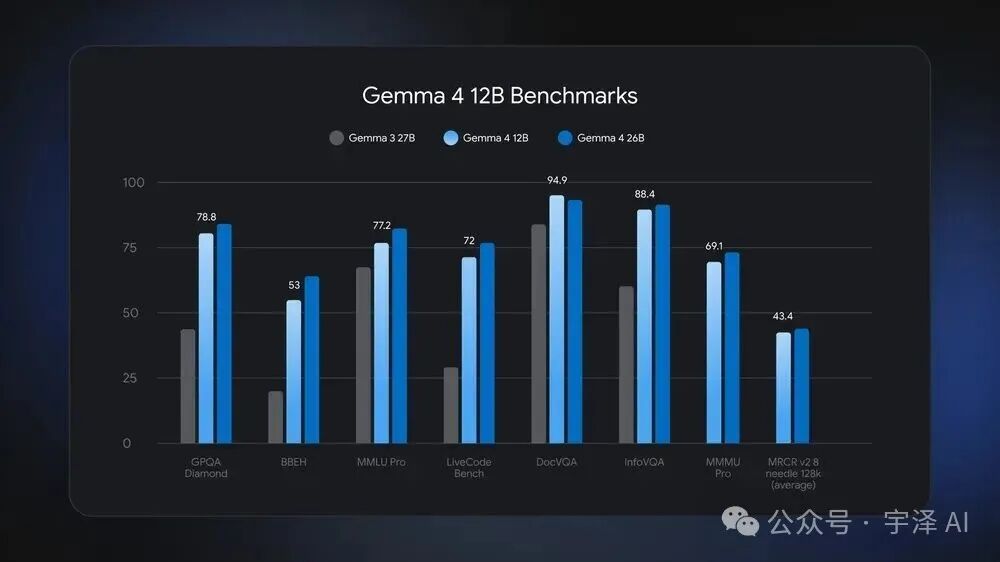
这是 Gemma 4 12B 最让人意外的地方。看 Google 官方给出的基准测试对比:
GPQA Diamond(研究生级推理):12B 得分 78.8,26B 模型略高,但 Gemma 3 27B 只有约 45 分——代际提升翻倍。
MMLU Pro(综合知识):12B 得分 77.2,几乎追平 26B 模型。上一代 Gemma 3 27B 在这个测试上大约只有 65 分左右。
LiveCode Bench(编程能力):12B 得分 72,代码生成和理解能力接近 26B 水准。
BBEH(Big-Bench Hard,困难推理):12B 得分 53,大幅超越 Gemma 3 27B 的约 20 分。
一个 12B 参数的模型,在几乎所有维度上碾压上一代 27B 模型——这就是架构优化的力量。不是靠堆参数,而是靠更聪明的设计。
亮点四:Multi-Token Prediction——推理提速
Gemma 4 12B 引入了 Multi-Token Prediction(MTP) 技术。
传统的 LLM 推理是逐 token 生成的——每预测一个 token,就要做一次完整的 forward pass。MTP 允许模型在一次 forward pass 中预测多个 token,从而显著降低推理延迟。
对于实时交互场景(语音对话、实时翻译、在线聊天),这意味着更快的响应速度和更流畅的体验。在笔记本上跑模型,延迟是最直接影响用户体验的因素,MTP 让 12B 模型在端侧也能做到"秒回"。
亮点五:思考模式 + 函数调用——不止是问答
Gemma 4 12B 支持思考模式(Thinking Mode)。在系统提示中加入 <|think|> 标签,模型会先进行内部推理(Chain of Thought),再输出最终答案。这在数学推理、逻辑分析、代码调试等复杂任务上效果显著。
在 AIME 2026(美国数学邀请赛)无工具测试中,12B 模型达到 77.5% 的准确率。31B 模型则是 89.2%——但 12B 能在笔记本上跑,31B 需要服务器。
同时,模型完整支持函数调用(Function Calling)。你可以给它定义一组工具(搜索、计算器、数据库查询等),它会在推理过程中自主决定什么时候调用哪个工具。这让 Gemma 4 12B 不只是一个问答模型,而是一个可以构建 Agent 工作流的基础底座。
亮点六:16GB 内存,笔记本就能跑

这可能是 Gemma 4 12B 最实用的亮点。
FP16 精度下,12B 模型需要约 24GB 显存。但通过 Unsloth 等工具的量化优化:
-
4-bit 量化(UD-Q4_K_XL):仅需约 8GB 内存,可以在大多数笔记本上运行
-
8-bit 量化(Q8_0):需要约 14GB 内存,质量损失极小
-
FP16 原始精度:约 24GB 显存,适合 GPU 服务器
Google 官方推荐的本地运行工具包括:Ollama、LM Studio、Google AI Edge Gallery、LiteRT-LM CLI。
以 Ollama 为例,一条命令就能跑起来:
ollama run gemma4:12b
如果你用 Mac(Apple Silicon),还可以通过 MLX 框架获得原生 Metal 加速:
pip install mlx-vlmpython -m mlx_vlm.chat --model google/gemma-4-12b-it-4bit
对于想用 llama.cpp 深度定制的用户,Unsloth 提供了预量化的 GGUF 格式:
./llama-cli -hf unsloth/gemma-4-12b-it-GGUF:UD-Q4_K_XL --temp 1.0 --top-p 0.95 --top-k 64
模型权重可以从 Hugging Face 和 Kaggle 两个渠道下载,完全免费。
亮点七:Apache 2.0 开源——商用无忧
Gemma 4 12B 采用 Apache 2.0 许可证发布,这是最宽松的开源许可之一。企业可以直接商用,不需要申请额外的商业授权。
相比上一代 Gemma 3 使用的自定义许可协议,Apache 2.0 的切换释放了一个明确信号:Google 要让 Gemma 成为开源 AI 的基础设施级模型。
Gemma 4 全家族一览
Gemma 4 不只有一个 12B,它是一个完整的模型家族:
-
E2B(2B Dense):手机/嵌入式设备,5GB 内存可跑,支持文本+图像+音频
-
E4B(4B Dense):平板/轻薄本,支持三模态,含约 3 亿参数的语音编码器
-
12B(12B Dense):笔记本/桌面端,256K 上下文,三模态统一架构
-
26B-A4B(MoE):高端桌面/服务器,256K 上下文,文本+图像
-
31B(Dense):服务器级,性能最强,文本+图像
一个值得注意的细节:E2B 和 E4B 这两个小模型自带语音编码器,反而支持音频输入;26B 和 31B 大模型则只支持文本和图像。12B 是唯一同时支持三种模态的大尺寸模型。
写在最后
Gemma 4 12B 的意义在于它证明了一件事:多模态 AI 不一定要靠堆参数来实现。
通过移除冗余的编码器、设计统一的嵌入模块、引入 Multi-Token Prediction,Google 把三种模态的能力压缩进了一个笔记本级别的模型里。GPQA 78.8、MMLU Pro 77.2、DocVQA 94.9——这些数字不是来自一个需要 A100 集群的巨兽,而是来自一台 16GB 内存的轻薄本。
当 1.5 亿次下载量说明开发者用脚投票的结果时,我们有理由相信:端侧 AI 的拐点,已经到了。
欢迎点赞收藏,有问题评论区见~
你的每一次支持,都是我持续输出的动力
持续分享 AI 提效实战、开源工具、工作流自动化,关注不迷路

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)