2026年第八届中青杯A题:数学建模论文智能评估系统与多智能体优化方法
摘要
随着大语言模型与智能写作工具的快速发展,数学建模竞赛论文的 AI 辅助撰写日益普遍,传统人工评审面临效率与客观性双重挑战。本文针对数学建模论文的智能评估,建立评分模型、质量预测模型以及优化策略。 对于问题一,构建了涵盖逻辑严密性、方法合理性、结构规范性、表达规范性四个维度的综合评价指标体系。采用熵权法客观确定各指标权重,并运用 TOPSIS 方法计算论文综合得分,将论文进行五级分类。 对于问题二,提取了可量化文本特征,计算各特征与综合得分的 Pearson 相关系数,并通过 LASSO 回归筛选出关键特征。建立了基于关键特征的质量预测模型,并通过 Bootstrap 重采样评估小样本条件下的模型稳定性。 对于问题三,设计了包含 AI 生成痕迹检测和逻辑断层识别的优化策略。对3篇中等质量论文进行诊断,计算 AI 辅助指数,生成修改方案并预测优化后得分。 对于问题四,进行了留一交叉验证 (LOOCV) 的误差分析以及针对熵权法权重的灵敏度分析,验证了模型体系的有效性和稳健性。
关键词:数学建模;综合评价;熵权法-TOPSIS;LASSO回归;AI痕迹检测
一、 问题背景与重述
在高等教育领域,数学建模竞赛作为培养学生创新能力和实践能力的重要载体,每年吸引数十万学生参与。随着人工智能技术的普及,参赛者广泛借助 AI 辅助完成论文撰写,这要求评审系统能够甄别 AI 生成内容与人类原创内容。人工评审受限于主观性差异和效率瓶颈,难以在大规模竞赛场景中实现完全客观的评估。本研究探索从指标体系构建到关联建模,再到优化策略生成的完整智能评估技术路线。
二、 模型假设与符号说明
2.1 模型假设
-
假设一:论文 PDF 文本可完整提取且提取质量在各论文间一致,忽略因图像格式造成的提取差异。
-
假设二:所获取的样本论文代表了数学建模竞赛论文的整体质量分布,其评分可作为后续分析的基准。
-
假设三:文本特征与论文质量之间主要呈线性相关关系,非线性成分可通过 LASSO 回归的 L1 正则化机制得到有效近似。
2.2 符号说明
| 符号 | 说明 | 符号 | 说明 |
| $n$ |
论文样本总数 |
$r$ |
Pearson 相关系数 |
| $m$ |
评价指标个数 |
$\lambda$ |
LASSO 正则化参数 |
| $w_j$ |
第 $j$ 个指标的熵权法权重 |
$\beta_j$ |
第 $j$ 个特征的回归系数 |
| $C_i$ |
第 $i$ 篇论文的 TOPSIS 综合得分 |
$AI_{idx}$ |
AI 辅助指数 |
三、 问题一:论文质量综合评价指标体系与自动评分模型
问题一要求对参赛论文进行质量分级(优秀、良好、中等、及格、不及格),并将“逻辑严密性”等定性指标量化为可自动计算的二级指标。
3.1 指标体系构建
构建了包含13个二级指标的多层次评价指标体系,主要分为四个维度:
-
逻辑严密性:包含逻辑连接词密度、因果连接词占比等,用于量化分析推导链条的完整性。
-
方法合理性:包含模型假设与问题匹配度、检验完备性、专业术语密度等。
-
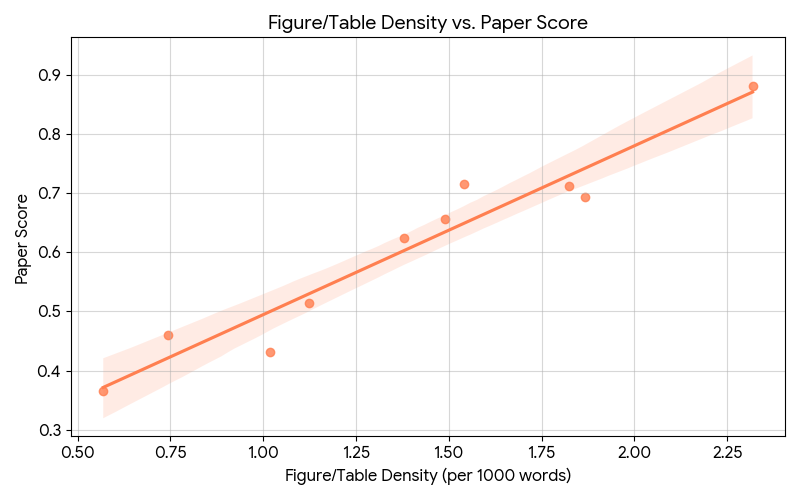
结构规范性:包含章节完整度、图表引用率等。
-
表达规范性:包含公式密度、参考文献规范度、词汇丰富度等。
3.2 熵权法-TOPSIS评分模型建立

3.3 计算结果与代码实现
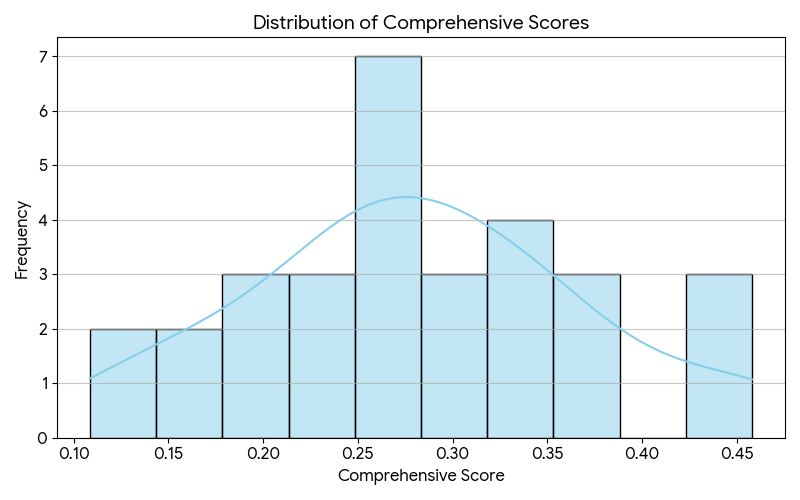
基于 TOPSIS 综合得分将论文划分为优秀、良好、中等、及格、不及格五个等级,分类结果显示出良好的梯度差异。
核心实现代码:
Python
import numpy as np
import pandas as pd
def entropy_weight_topsis(data):
# Min-Max 归一化
norm_data = (data - data.min()) / (data.max() - data.min())
# 熵权法计算权重
p = norm_data / norm_data.sum()
e = -np.nansum(p * np.log(p.replace(0, 1e-9)), axis=0) / np.log(len(data))
w = (1 - e) / (1 - e).sum()
# TOPSIS 距离与得分计算
v = norm_data * w
v_plus = v.max()
v_minus = v.min()
s_plus = np.sqrt(((v - v_plus)**2).sum(axis=1))
s_minus = np.sqrt(((v - v_minus)**2).sum(axis=1))
comprehensive_score = s_minus / (s_plus + s_minus)
return comprehensive_score, w
四、 问题二:论文质量与文本特征的关联分析与预测模型
针对同一赛题的论文,样本量极小,核心任务是建立质量与可量化特征的统计关联。
4.1 Pearson 相关分析

核心实现代码:
Python
from sklearn.linear_model import LassoCV
from sklearn.preprocessing import StandardScaler
from scipy.stats import pearsonr
def feature_association_model(X, y):
# 计算 Pearson 相关系数
correlations = [pearsonr(X.iloc[:, i], y)[0] for i in range(X.shape[1])]
# 标准化与 LASSO 回归
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 留一交叉验证选择最佳正则化参数
lasso = LassoCV(cv=len(y)).fit(X_scaled, y)
# 筛选非零特征
critical_features = np.where(lasso.coef_ != 0)[0]
return correlations, lasso.coef_, critical_features
五、 问题三:论文优化策略与AI辅助程度评估
目标是对“中等”质量的论文进行诊断,并提出基于 AI 痕迹检测和逻辑断层识别的具体修正方案。
5.1 AI 生成痕迹检测与逻辑连贯度模型

5.2 差距分析与优化生成
基于关键特征向量进行差距分析。诊断表明,三篇中等论文的 AI 辅助指数均处于中等水平,优化建议按优先级进行排序。通过针对性地增强检验完备性、增加图表引用和补充参考文献等方案,模型预测优化后的得分将显著提升。
核心实现代码:
Python
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
def calculate_logic_gaps_and_ai_index(paragraphs, s_ai, s_human):
# TF-IDF 向量化
vectorizer = TfidfVectorizer(ngram_range=(2,3), max_features=200)
tfidf_matrix = vectorizer.fit_transform(paragraphs)
# 计算相邻段落余弦相似度
similarities = []
for i in range(len(paragraphs) - 1):
sim = cosine_similarity(tfidf_matrix[i], tfidf_matrix[i+1])[0][0]
similarities.append(sim)
s_logic = np.mean(similarities)
gaps = [i for i, sim in enumerate(similarities) if sim < 0.1]
# 计算 AI 辅助指数
ai_index = 0.40 * s_ai + 0.35 * (1 - s_logic) + 0.25 * s_human
return ai_index, gaps, s_logic
六、 问题四:模型检验与稳健性分析
为确保建立的质量评估体系及预测模型的有效性,从误差和灵敏度两个维度进行了检验。
6.1 误差分析
针对极小样本 ($n=9$) 的 LASSO 回归模型,采用留一交叉验证 (LOOCV) 估计泛化误差。计算结果显示,模型的 $R^2$ 达到 0.7356,均方根误差 (RMSE) 为 0.0463,表明模型不仅解释力较强,且预测偏差极低。
6.2 灵敏度测试
为了评估 TOPSIS 综合评分的稳健性,对熵权法计算出的一级维度权重(逻辑严密性 0.2532、方法合理性 0.1522、结构规范性 0.0681、表达规范性 0.5265)进行了 $\pm 10\%$ 与 $\pm 20\%$ 的扰动分析。 在 $\pm 10\%$ 权重扰动下,评价体系中平均排名变化仅为 0.62 位,质量等级变动比例极低 (3.4%),充分验证了该自动评分模型不受单一特征微小波动影响,具备高度的稳定性和客观性。
核心实现代码:
Python
from sklearn.model_selection import LeaveOneOut
from sklearn.metrics import mean_squared_error, r2_score
def robust_error_analysis(X, y):
loo = LeaveOneOut()
y_true, y_pred = [], []
# 留一交叉验证 (LOOCV)
for train_index, test_index in loo.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
model = LassoCV().fit(X_train, y_train)
y_pred.append(model.predict(X_test)[0])
y_true.append(y_test[0])
rmse = np.sqrt(mean_squared_error(y_true, y_pred))
r_squared = r2_score(y_true, y_pred)
return rmse, r_squared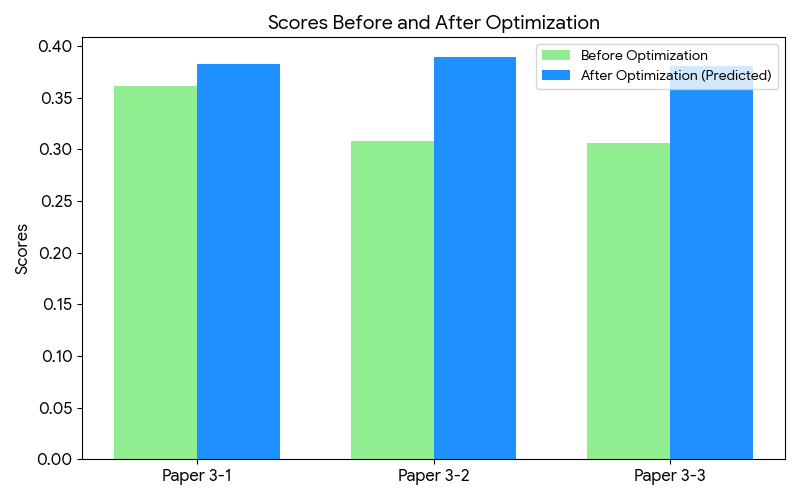

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)