19. 大数据- BI - AI 应用4-构建高质量 AI 基座
文章目录
前言
系列文章完整串联业务系统 + 数据集成 + 数据仓库 + BI 落地全链路。
结合上一篇中AI处理数据的能力进行展开深入的场景案例知识点讲解,结合案例全面系统的对AI处理结果化、半结构化、非结构化数据的实践落地,及关键点拆解解析。
结构化与非结构化数据落地处理方案解析
全流程质量管控方案
本文作为上一篇内容的深度补充,将跳出纯理论的框架,重点聚焦于 AI 数据处理的落地场景。结合目前独立设计并正在推进的 AI 数据项目,本文将直观展示 AI 在数据处理能力上的实现路径与对应方案,深度拆解 AI 在企业数字化场景中,针对结构化、半结构化、非结构化三类主流数据的真实处理流程与实操方式。
同时,系统性讲解在 AI 加工处理数据后,如何建立一套完整、可落地的数据质量全维度管控体系,从源头规避数据乱象、抑制 AI 幻觉,确保经过 AI 处理的数据真正满足业务使用、数据分析、智能检索与问答等正式落地场景的标准。

一、AI 针对结构化数据实战处理场景
自研产品落地实践
结构化数据作为企业数字化的核心根基,广泛存在于 MySQL、Doris、ClickHouse、Oracle 等数仓与业务数据库中,具备格式统一、字段规整、逻辑清晰的特性,是数据治理最先发力的核心对象。
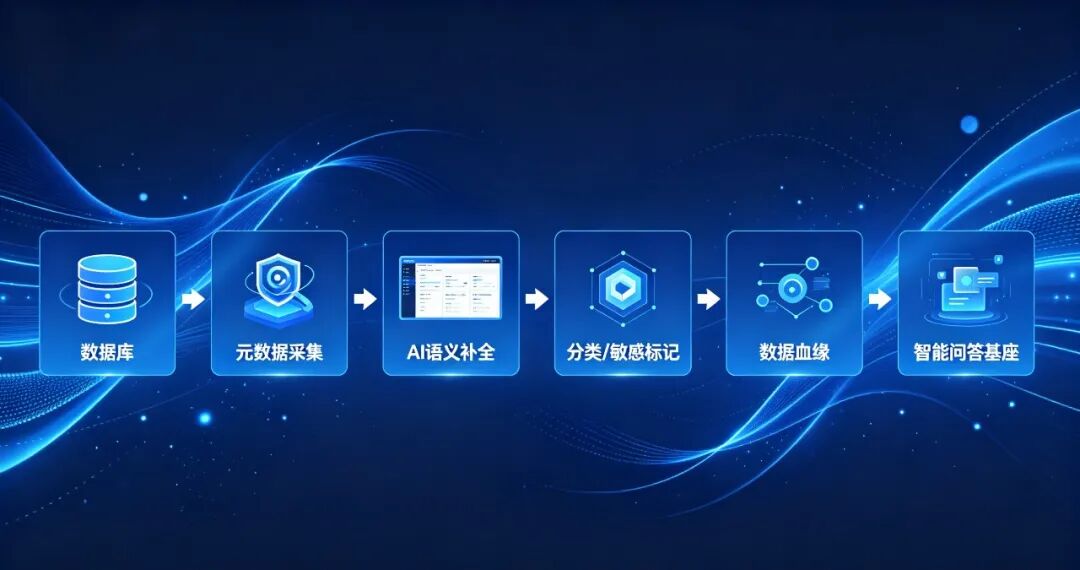
在目前的 AI 项目中,我通过适配集成主流的各类数据库数据源,实现自动拉取数据仓库内指定表的结构信息(包含数据表名称、注释、字段名称、数据类型、备注、业务别名、长度、主外键关联关系等完整元数据)。将这些元数据批量投喂给 AI 大模型,依托大模型的语义理解能力完成全链路智能化处理,具体落地场景如下:
-
元数据语义补全与标准化优化针对业务开发中遗留的无注释字段、简写字段、英文缩写及中文拼音拼写字段,AI 能够自动结合业务库的整体语境与数据表的业务用途,完成字段含义的语义补全,统一字段命名规范与业务释义。这有效解决了行业内大量数据表字段表意模糊、新人运维难以理解字段含义的治理难题。
-
全自动业务维度分类划分AI 依托元数据字段属性、数据存储特征及业务关联关系,自动对全量数据表和字段完成业务归类,精准划分为维度数据、度量指标数据、核心业务交易数据、企业主数据、配置基础数据、日志流水数据六大类别。全程无需人工手动梳理,大幅降低了数据资产梳理的人力成本。
-
智能敏感数据自动识别标记AI 通过深度识别结构化字段的内容与命名特征,能够自动精准筛查企业内部的隐私敏感字段,快速识别身份证号、手机号、银行卡号、员工工号、客户隐私地址、企业核心经营机密等字段,并完成敏感数据标签的挂载与等级划分,为后续的数据脱敏、权限隔离及安全管控提供前置依据。
-
数据表血缘自动梳理优化结合多库之间的同步关系与字段关联关系,AI 可自动梳理数据表的上下游数据流转链路,生成可视化的数据血缘图谱,并识别出冗余数据表、废弃冷数据表及重复业务数据表,从而精简数仓的冗余架构。
-
前置构建智能问答底层基座经过 AI 标准化分类、语义补全和敏感标记后的高质量结构化元数据,能够直接作为 AI 智能问答的底层标准数据源。这不仅大幅提升了后续自然语言查询数据表、查询字段含义、调取业务指标等问答场景的准确率,更从源头夯实了智能问答的数据基础。
依托 AI 对结构化元数据的自动化处理,彻底改变了传统人工逐表梳理、逐字段标注的低效治理模式,成倍提升了企业全域结构化数据的治理效率,实现了企业数据资产的轻量化与标准化管理。
二、AI 对半结构化、非结构化数据全场景落地处理
在企业日常经营中,业务工单、会议纪要、办公文档、图片资料、网页资讯、Excel 自由表单、音视频文件等数据体量持续暴涨。这类无固定格式、自由散漫的数据价值极高,但传统手段几乎无法完成高效加工。以下结合目前的 AI 平台项目实践进行讲解:
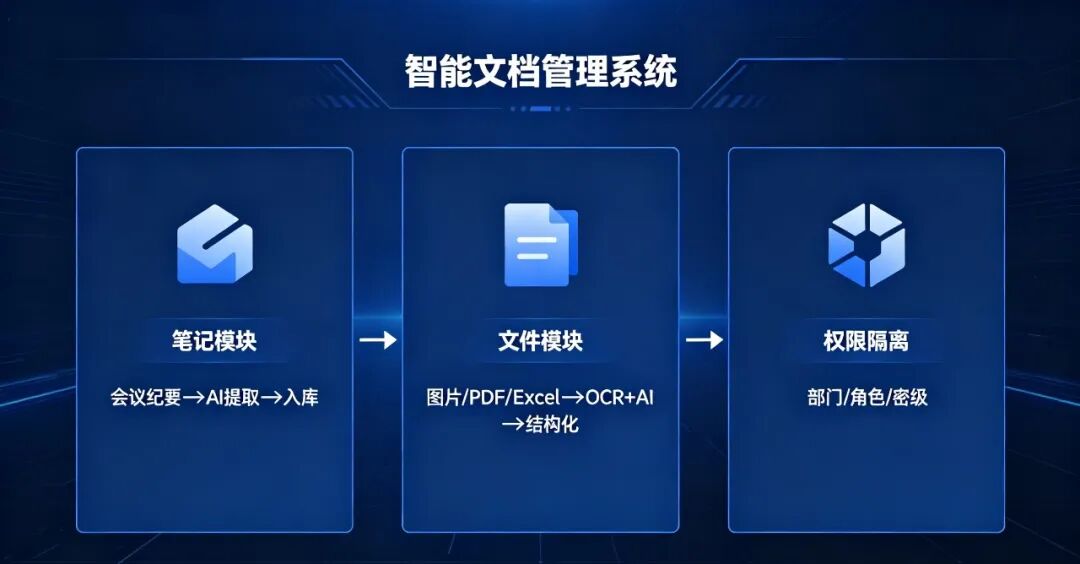
1. 通过笔记管理模块实现对企业重要临时性数据的收集及处理
-
关键信息提取与入库
:针对重要的会议纪要、日程安排记录以及其他需要记录的关键企业信息,可以通过笔记管理模块上传。AI 前置获取并记录笔记的关键信息,进行提取、打标签、分类,获取源数据后经过审核修正即可入库。
-
网页抓取半结构化数据规整入库
:针对业务需求抓取的行业资讯、竞品数据、公开业务资料等网页半结构化零散数据,AI 能够自动完成杂乱网页内容的清洗、无效广告的剔除以及碎片化信息的拆分。按照预设的业务字段逻辑,AI 将零散的网页数据规整为统一格式,直接完成结构化拆分后批量入库存储,实现了外部数据的快速资源化利用。
2. 通过文件管理模块实现对文件的接入及 AI 智能化管理(图片、文档、PDF 等)
该模块内置了 OCR 与多模态大模型的融合能力:
-
图片数据智能处理
:通过上传业务截图、凭证图片、流程单据图片、合同图片等文件,AI 可一键完成图片文字的精准提取、核心信息萃取及业务内容识别。同时,自动生成图片的专属元数据标签(包含图片来源、拍摄场景、核心内容、业务归属、上传时间、密级等级等),完成图片数据的统一分类管理与标记归档,解决了企业海量业务图片散乱难管理、信息无法检索的痛点。
-
本地文档类文件自动化处理
:支持 Word、PDF、TXT、Excel 自由文档等全格式办公文件的接入。AI 能够自动完成大体积长文档的智能分片、内容拆分、段落提纯以及无效冗余内容的剔除,将长篇杂乱的文档拆解为标准化知识片段。同时,自动提取文档的核心观点、业务流程、规章制度、操作规范、风险要点等核心信息,实现文档知识的轻量化萃取。
-
多格式文件统一归类归档
:AI 自动识别文件的用途、业务领域及优先级,完成全量非结构化文件的智能分组归档。搭配平台权限体系,实现不同部门、不同角色的文件查看权限隔离,兼顾了数据利用效率与内部数据安全。
三、AI 处理数据后,数据质量管控核心体系方案
1. 开展 AI 数据质量管控的核心原因
AI 具备强大的数据加工、萃取、改写与整合能力,但其输出内容存在极强的主观性与不确定性。首先,投喂给 AI 的原始数据本身可能存在脏数据、残缺数据、错误数据或冗余数据,劣质的原始数据会直接导致 AI 加工后的内容偏离业务事实;其次,大模型天生存在 “AI 幻觉” 问题,极易凭空编造不存在的字段信息、业务规则或数据内容,造成输出数据失真;此外,AI 无法精准适配企业内部定制化的业务规则与行业专属数据标准。因此,单纯依靠 AI 自主输出的数据无法直接投入正式业务统计、经营决策、报表分析等核心场景,建立一套完善的 AI 数据质量管控体系必不可少。
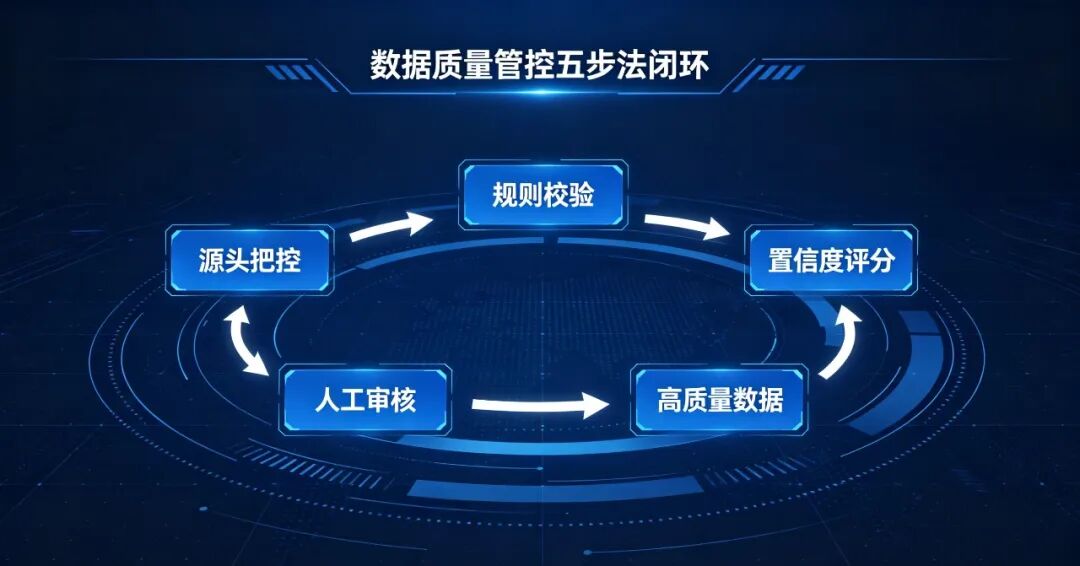
2. 五大落地式数据质量具体管控方法
-
源头把控:输入侧严控原始数据质量从数据接入源头建立准入标准,设立前置拦截与清洗机制,最大程度过滤缺失注释、错乱关联的劣质元数据。同时,提前完成原始结构化与非结构化数据的前置清洗,剔除重复数据、空白无效数据及过期失效数据,从根源上减少劣质数据流向 AI 加工环节,降低 AI 错误输出的概率。
-
硬性约束:搭建行业定制化数据校验规则库脱离 AI 的主观判断,搭建企业专属的刚性数据校验规则,完成标准化强制校验,不满足规则的数据直接判定为不合格:
-
通用基础规则:如 11 位纯数字手机号码校验、18 位标准身份证号码格式校验、统一时间格式校验、金额数值合规校验等。
-
业务专属规则:如行业专属编码格式、业务状态枚举值限定、数据取值区间限定、关联字段逻辑一致性校验等。所有经过 AI 处理后的数据,必须优先通过硬性规则校验通道,校验不通过者直接拦截,禁止直接入库。
- 智能评级:AI 置信度多维度综合评分体系
依托自研平台搭建独立的置信度评分模型,对 AI 加工生成的所有数据进行 0-100 分的量化可信度打分,并划分为优质、合格、待核查、不合格四大等级。评分模式包含三类:
-
自研模型自主评估
-
第三方通用大模型交叉评估
-
多模型混合综合评估
- 人工兜底:分级推送人工审核修正机制
建立 “机器审核 + 人工复核” 的双层兜底机制,形成完整的数据修正闭环:
-
硬性校验不通过 → 推送业务负责人
-
置信度偏低 → 进入人工审核
-
人工修正 → 反向训练 AI → 形成数据飞轮
- 动态巡检:全周期数据质量回溯监测
数据完成入库使用并非治理的终点。平台需搭建定时自动化质量巡检任务,定期对存量 AI 处理数据进行二次复核,监测数据的时效性、内容准确性及业务适配性,自动清理过期失效数据,修正随业务变动产生的不合规数据,实现数据质量的全周期长效稳定管控。
四、补充拓展:AI 数据治理落地避坑要点
在从去年接触 AI 理论,到今年独立设计开发平台的实战过程中,我总结出 AI 数据处理与质量管控的三大核心避坑要点,助力项目平稳落地:
-
区分场景,界定 AI 使用边界基础标准化工作交给 AI;核心经营、涉密数据以人工为主、AI 为辅。
-
数据治理与业务场景深度绑定切勿脱离业务单独做 AI 数据治理,避免治理与应用脱节。
-
分级管控不同类型数据核心业务数据高标准;参考类资讯适度放宽,平衡质量与效率。
五、总结及思考
本文结合自研数据智能治理平台的实战开发经验,完整拆解了 AI 在结构化数据元数据治理、半结构化网页数据规整、非结构化图片与文档文件管理中的全流程落地应用场景,清晰展现了 AI 如何全方位赋能企业全域数据的高效加工。
同时,从源头数据管控、硬性规则校验、AI 置信度综合评分、人工审核兜底、全周期动态巡检五大维度,搭建起一套完整且可落地的 AI 数据质量管控体系,有效规避了原始数据劣质问题与 AI 幻觉风险,让经过 AI 处理的数据合规、准确、可用。
核心思考
-
从 “能用” 到 “好用”,数据质量是 AI 的生死线
-
人机协同是现阶段最优解,而非全自动替代
-
结构化与非结构化融合是未来趋势
-
脱离业务场景的数据治理都是 “耍流氓”
本文的引用仅限自我学习如有侵权,请联系作者删除。
参考知识
AI 应用实战系列第四篇:结构化与非结构化数据 AI 落地处理场景 + 全流程质量管控方案

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 4
4 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)