本地视频转文字,音频转文字免费工具
找了下本地视频转文字的工具,都是各种限制,于是自己写了个自用的工具,如果帮助到您,请给个 star 吧!
完全免费,无时长限制,可转写视频和音频;基于 Whisper large-v3,精准实用,准确率高;集成 Ollama / NVIDIA 大模型,自动生成摘要;图形界面 + 命令行,Windows 绿色版已打包;可批量选择文件转写成文本和总结摘要,摘要可markdown格式查看;一键转写 + 总结,输出 TXT/SRT/VTT/JSON;完全开源,源代码:video2text GitHub 仓库(本地视频转文字工具)
一、界面
主界面GUI
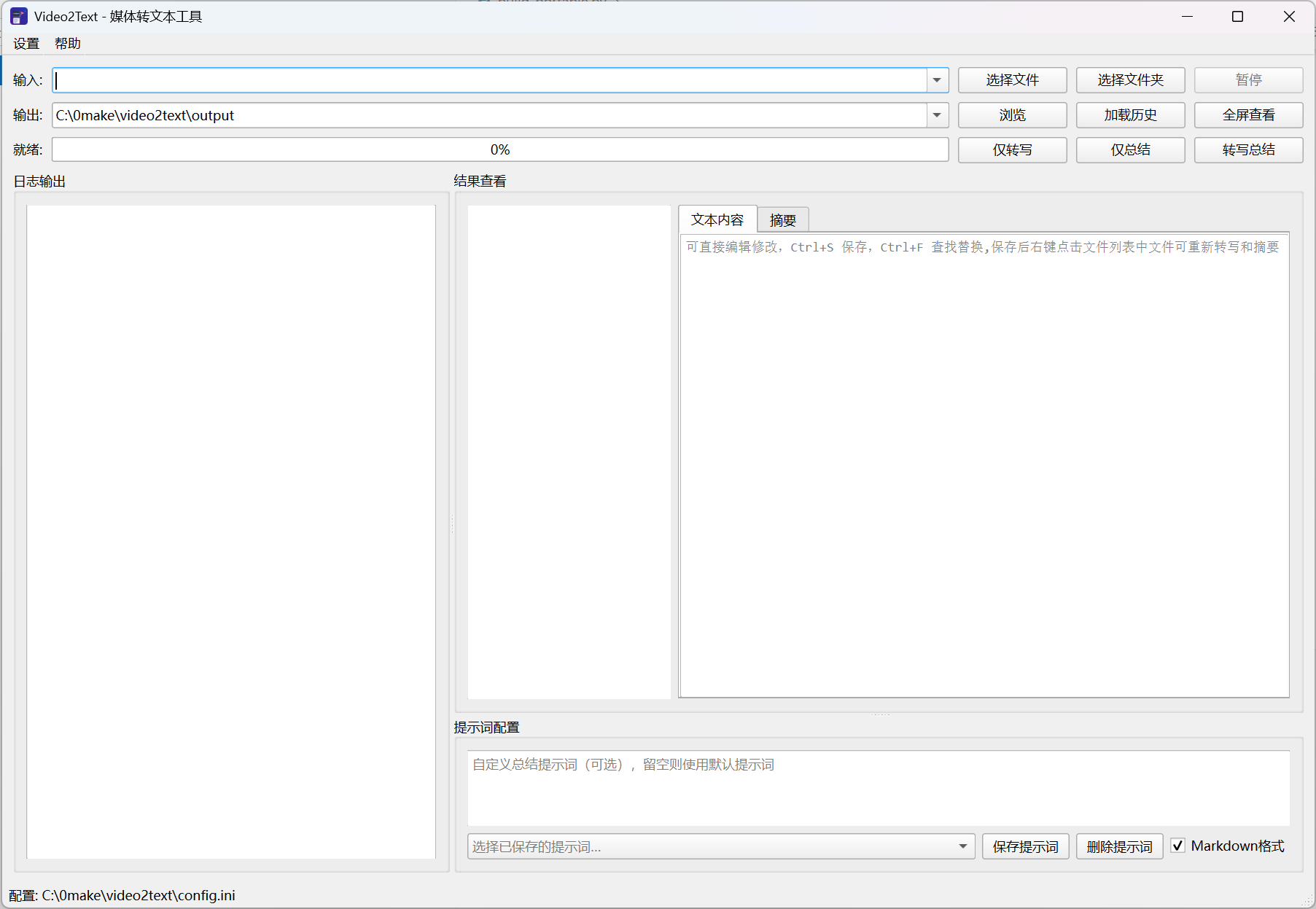
二、安装前的准备:系统要求与组件
在安装 video2text 这一本地视频转文字工具前,请先确认你的电脑满足以下条件。
2.1 最低配置与推荐配置
| 项目 | 最低要求 | 推荐配置 |
|---|---|---|
| 操作系统 | Windows 10 64位 | Windows 11 64位 |
| 磁盘空间 | 20 GB 可用空间 | 30 GB 以上(含模型文件) |
| 内存(RAM) | 8 GB | 16 GB 及以上 |
| 显卡 | 无(CPU模式可用但很慢) | NVIDIA 显卡(6GB显存以上) + CUDA |
注意:AMD 显卡暂不支持 GPU 加速。CPU 模式可以运行会比较慢。
显卡信息参考(nvidia-smi 输出示例):
这是我电脑上的驱动版本信息
| NVIDIA-SMI 572.83 | Driver Version: 572.83 | CUDA Version: 12.8 |
|---|---|---|
| GPU Name Driver-Model | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| MIG M. | ||
| =================================== | ================================ | ======================== |
| 0 NVIDIA GeForce RTX 4060 WDDM | 00000000:01:00.0 Off | N/A |
| N/A 41C P5 5W / 140W | 365MiB / 8188MiB | 0% Default |
| N/A |
如果驱动版本和 CUDA 版本太低也可能无法使用 GPU 加速。建议先在命令行执行
nvidia-smi确认显卡状态。
2.2 需要下载哪些文件
video2text 本地视频转文字工具的安装包体积较大,已上传至 123 云盘,内含以下组件:
| 组件 | 大小 | 是否下载 |
|---|---|---|
large-v3 语音模型 |
~3 GB | 可选,建议下载,自己有其它模型也行 |
Ollama 总结模型(qwen2.5:7b) |
~4.7 GB | 可选,看总结用不用Ollama |
| video2text 程序 | ~3 GB | 必须 |
请使用支持保留目录结构的解压工具(如 7-Zip 或 Bandizip)解压压缩包,确保文件夹结构完整。
下载地址:
『来自123云盘用户喵王龙的分享』video2text 本地视频转文字工具
链接:https://1840674647.share.123pan.cn/123pan/7CfNTd-SE7j3?pwd=viWa#
提取码:viWa
三、详细安装步骤
以下按顺序介绍 video2text 本地视频转文字工具的完整安装流程。
3.1 部署 video2text 本地视频转文字程序
第一步:解压程序包
将 video2text_portable_windows_*.zip 解压到你希望存放程序的位置,例如 D:\video2text。该程序为绿色版,无需安装,不会写入注册表,解压即用。解压后目录结构如下:
D:\video2text\
├── video2text.exe ← 主程序
├── video2text.bat ← 启动脚本(自动设置工作目录)
├── config.ini ← 配置文件
├── .env ← 环境变量配置(存放 API Key,需手动创建)
├── docs ← 文档
├── assets\ ← 图标资源
├── ffmpeg\ ← 内置 FFmpeg
├── models\ ← 模型目录(需要放入模型文件)
├── output\ ← 输出目录(可选)
├── logs\ ← 日志目录
└── README.md ← 说明文档
第二步:放入语音识别模型
将下载的 large-v3.zip 解压到程序目录下的 models 文件夹中。确保解压后模型文件位于 models\large-v3\ 子目录下,且包含以下核心文件:
D:\video2text\models\
└── large-v3\
├── config.json
├── model.bin ← 核心模型文件(约 2.9 GB)
├── preprocessor_config.json
├── tokenizer.json
└── vocabulary.json
放好模型后就可以使用视频转文本功能了.
需要使用其它模型的可以到huggingface上找,按照上面目录结构放好,再到配置文件中设置
3.2 总结模型安装
video2text 支持两种总结服务:NVIDIA 在线模型和本地 Ollama 模型,按需选择其一即可。
3.2.1 NVIDIA 在线(使用在线 NVIDIA 模型总结)
需要先在 NVIDIA Build 注册账号并创建 API Key(目前大部分模型免费使用)。获取 Key 后在程序目录下新建一个名为 .env 的文本文件(注意文件名以点开头,无扩展名)。用记事本打开,按需添加以下内容:
# NVIDIA API Key(使用在线 NVIDIA 模型总结时需要)
NVIDIA_API_KEY=nvapi-你的API密钥
保存文件。程序启动时会自动读取该文件中的环境变量。API Key 也可以通过系统环境变量设置,效果相同(系统环境变量优先级高于 .env 文件)。NVIDIA 提供有很多免费的模型,如果网络访问有问题需要自行解决。
3.2.2 安装 Ollama(使用本地模型总结)
Ollama 是一个本地大语言模型运行框架,video2text 使用它来生成文本摘要。
注意事项
- 目前测试下来发现,qwen2.5:7b-instruct-q4_K_M模型的总结能力较差,建议还是使用在线免费的模型
- Ollama也提供一些模型可免费使用,有一定额度限定,模型比如有:deepseek-v3.1:671b-cloud、gpt-oss:120b-cloud
- 官网地址:Ollama
- 如果你显卡比较好一些,可以考虑拉取一些比较好的模型本地运行,这边使用qwen2.5:7b-instruct-q4_K_M进行安装说明
第一步:运行安装程序
双击 OllamaSetup.exe,按提示完成安装。安装过程无需手动配置,会自动完成。
第二步:解压预下载模型
找到下载好的 models.zip 文件,将其解压到 C:\Users\你的用户名\.ollama 目录下。确保解压后的目录结构如下:
C:\Users\你的用户名\.ollama\
└── models\
└── blobs\ ← 模型数据文件
└── manifests\ ← 模型清单文件
第三步:启动 Ollama 服务
直接找到图标启动,或者ollama serve,其它模型安装直接参考官方文档,用命令拉取下就行,如果注册了账号使用ollama的在线模型,需要添加在文件.env中添加OLLAMA_API_KEY
# Ollama API Key(使用带认证的 Ollama 服务时可选配置)
OLLAMA_API_KEY=你的API密钥
3.3 验证安装是否成功
完成以上所有步骤后,按顺序验证各组件是否正常工作:
-
启动 video2text:
- 双击
video2text.exe或video2text.bat启动程序。 - 程序主窗口应正常显示,标题为「Video2Text - 视频转文本工具」。
- 底部状态栏会显示当前使用的配置文件路径。
- 双击
-
快速测试(可选):
- 选择一个短小的视频文件(1-2 分钟即可)。
- 点击「仅转写」按钮,观察日志面板是否有输出、进度条是否推进。
- 转写完成后,右侧面板应显示转写文本。
- 点击「仅总结」按钮,确认能正常生成摘要。
四、详细教程

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)