一文搞懂计算机视觉四大核心任务:从分类到追踪,附 PyTorch 极简代码
计算机视觉就像给 AI 装上了 “眼睛”,让机器能看懂图像和视频里的世界。从手机相册的自动分类,到自动驾驶的行人检测,再到监控里的目标追踪,背后都离不开四个最基础也最核心的任务:目标分类、目标检测、目标分割、目标跟踪。
一、目标分类:给整张图片 “贴个标签”
核心任务:只回答 “图里有什么”
目标分类是计算机视觉最基础的任务,它的工作特别简单:输入一张完整的图片,输出这张图片属于哪个类别,以及对应的概率。
它完全不关心物体在图片里的位置,也不关心有几个物体,只给整张图打一个(或多个)标签。比如输入一张猫咪照片,它只会告诉你 “这是猫,概率 98%”,不会说猫在图片左上角还是右下角。
任务特点
- 最基础的视觉任务,分为单标签分类(一张图只有一个物体)和多标签分类(一张图有多个物体)
- 不管目标的数量、大小和坐标,只关注整体类别
- 经典应用:手写数字识别、图片分类检索、垃圾邮件图片过滤
PyTorch 极简实现:LeNet5 手写数字分类
# PyTorch核心库
import torch
# 构建神经网络需要的模块
import torch.nn as nn
# 优化器(更新模型参数)
import torch.optim as optim
# 数据集、图像预处理工具
from torchvision import datasets, transforms
# 数据加载器:批量读取数据
from torch.utils.data import DataLoader
# 画图工具,用于显示测试图片
import matplotlib.pyplot as plt
# ------------------- 定义LeNet5卷积神经网络 -------------------
# 继承nn.Module,所有PyTorch模型都要继承这个类
class LeNet5(nn.Module):
# 初始化函数:定义网络的每一层
# num_classes=10 表示手写数字10分类(0-9)
def __init__(self, num_classes=10):
# 调用父类初始化方法,固定写法
super(LeNet5, self).__init__()
# 特征提取层:卷积+池化,用来提取图像特征
self.features = nn.Sequential(
# 第一层卷积:输入通道1(灰度图),输出通道6,卷积核5×5,步长1
nn.Conv2d(1, 6, kernel_size=5, stride=1),
# 激活函数:增加非线性
nn.Tanh(),
# 平均池化:缩小图片尺寸,减少计算量
nn.AvgPool2d(kernel_size=2, stride=2),
# 第二层卷积:输入通道6,输出通道16,卷积核5×5
nn.Conv2d(6, 16, kernel_size=5, stride=1),
nn.Tanh(),
nn.AvgPool2d(kernel_size=2, stride=2),
)
# 分类器:全连接层,把特征映射成类别概率
self.classifier = nn.Sequential(
# 第一层全连接:输入是16个通道×4×4特征图
nn.Linear(16 * 4 * 4, 120),
nn.Tanh(),
# 第二层全连接
nn.Linear(120, 84),
nn.Tanh(),
# 最后一层:输出10个分类(0-9)
nn.Linear(84, num_classes),
)
# 前向传播函数:数据在网络中流动的路径
def forward(self, x):
# 图像 -> 特征提取层
x = self.features(x)
# 把多维特征展平成一维(全连接层需要一维输入)
x = torch.flatten(x, 1)
# 展平后的特征 -> 分类层 -> 输出结果
x = self.classifier(x)
return x
# ------------------- 设置超参数 -------------------
# 每次训练喂入64张图片
batch_size = 64
# 学习率:控制参数更新的步长
lr = 0.001
# 训练5轮(整个数据集过5遍)
epochs = 5
# 自动选择设备:有GPU用GPU,没有用CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# ------------------- 图像预处理(标准化) -------------------
transform = transforms.Compose([
# 把图片转成PyTorch张量
transforms.ToTensor(),
# 归一化:让数据分布更稳定,训练更快
transforms.Normalize((0.1307,), (0.3081,))
])
# ------------------- 加载MNIST数据集 -------------------
# 训练集:train=True
train_dataset = datasets.MNIST(
root='./data', # 数据集路径
train=True, # 训练集
download=False, # 不下载,使用本地已有数据
transform=transform # 应用预处理
)
# 测试集:train=False
test_dataset = datasets.MNIST(
root='./data',
train=False,
download=False,
transform=transform
)
# 数据加载器:批量、乱序加载数据
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# ------------------- 模型、损失函数、优化器 -------------------
# 创建模型,并搬到GPU/CPU
model = LeNet5().to(device)
# 损失函数:分类任务用交叉熵
criterion = nn.CrossEntropyLoss()
# 优化器:Adam,自动更新网络参数
optimizer = optim.Adam(model.parameters(), lr=lr)
# ------------------- 6. 训练函数 -------------------
def train():
# 开启训练模式(启用Dropout/BatchNorm等)
model.train()
# 循环训练多轮
for epoch in range(epochs):
total_loss = 0 # 累计损失
correct = 0 # 预测正确的数量
total = 0 # 总样本数
# 遍历训练集的每一批数据
for data, target in train_loader:
# 数据搬到设备上
data, target = data.to(device), target.to(device)
optimizer.zero_grad() # 清空上一轮梯度
output = model(data) # 前向传播,得到预测结果
loss = criterion(output, target) # 计算损失
loss.backward() # 反向传播,计算梯度
optimizer.step() # 更新参数
# 统计
total_loss += loss.item()
pred = output.argmax(dim=1) # 取概率最大的类别
correct += pred.eq(target).sum().item() # 正确数
total += target.size(0) # 总数
# 计算这一轮的平均损失和准确率
avg_loss = total_loss / len(train_loader)
acc = 100 * correct / total
print(f"Epoch [{epoch + 1}/{epochs}] | Loss: {avg_loss:.4f} | Acc: {acc:.2f}%")
# ------------------- 测试函数:计算测试集准确率 -------------------
def test():
# 开启评估模式,不计算梯度
model.eval()
correct = 0
total = 0
# 无梯度上下文,节省内存
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
pred = output.argmax(dim=1)
correct += pred.eq(target).sum().item()
total += target.size(0)
acc = 100 * correct / total
print(f"\n测试集准确率: {acc:.2f}%")
# ------------------- 显示测试样本与预测结果 -------------------
def show_test_sample(n=8):
model.eval()
# 从测试集取一批图片
test_iter = iter(test_loader)
imgs, labels = next(test_iter)
imgs = imgs.to(device)
# 不计算梯度,进行预测
with torch.no_grad():
preds = model(imgs).argmax(dim=1)
# 反归一化:把图片恢复成正常灰度图
mean = torch.tensor(0.1307)
std = torch.tensor(0.3081)
imgs_restore = imgs.cpu() * std + mean
# 画图
plt.figure(figsize=(12, 5))
for idx in range(n):
plt.subplot(2, n // 2, idx + 1)
# 显示图片,去掉通道维度
plt.imshow(imgs_restore[idx].squeeze(), cmap='gray')
# 标题显示真实标签和预测标签
plt.title(f"True:{labels[idx].item()}, Pred:{preds[idx].item()}")
plt.axis('off') # 关闭坐标轴
plt.tight_layout() # 自动调整布局
plt.show()
# ------------------- 9. 主程序入口 -------------------
if __name__ == "__main__":
print("开始训练...")
train() # 训练模型
print("\n训练完成,开始测试...")
test() # 测试准确率
print("\n输出测试样本图片...")
show_test_sample(n=8) # 显示8张测试图输出结果:


二、目标检测:不仅认得出,还能 “框得住”
核心任务:回答 “有什么、在哪里、有几个”
目标分类只能告诉我们图里有什么,而目标检测在分类的基础上,多了定位能力。它会用矩形框(包围盒 bbox)把每个物体圈出来,同时标注物体的类别和置信度。
输入还是一张图片,输出是多个(类别, 包围框坐标[x1,y1,x2,y2], 置信度)的组合。比如一张有 2 只猫 1 只狗的图片,它会输出 3 个矩形框,分别标注 “猫”“猫”“狗”,并给出每个框的准确位置。
任务特点
- 解决 “在哪 + 是什么 + 有几个” 三大问题
- 用矩形框近似物体轮廓,框内所有像素都算该目标
- 工业界最常用的算法:YOLO 系列(速度快)、Faster R-CNN(精度高)
- 经典应用:自动驾驶的车辆 / 行人检测、安防监控的异常检测、电商的商品识别
PyTorch 极简实现:MNIST 数字检测
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import matplotlib.patches as patches # 用来画检测框
# ==================== 定义目标检测网络 ====================
# 继承nn.Module,这是Pytorch模型的固定写法
class MNISTDetNet(nn.Module):
# 初始化函数:搭建网络结构
def __init__(self, num_classes=10):
super(MNISTDetNet, self).__init__()
# 主干网络 Backbone:负责提取图像特征
self.backbone = nn.Sequential(
# 第一层卷积:输入1通道(灰度图) → 输出16通道,3x3卷积核
nn.Conv2d(1, 16, kernel_size=3, padding=1),
nn.ReLU(), # 激活函数,增加非线性
nn.MaxPool2d(2), # 最大池化,图片尺寸缩小一半
# 第二层卷积:16通道 → 32通道
nn.Conv2d(16, 32, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2),
)
# 检测任务有两个输出头:分类头 + 回归头
# 1. 分类头:输出数字类别 0-9
# 输入是32个通道,每个通道7x7,展平后输入全连接层
self.cls_head = nn.Linear(32 * 7 * 7, num_classes)
# 2. 回归头:输出4个值 → 检测框坐标 (x1, y1, x2, y2)
self.reg_head = nn.Linear(32 * 7 * 7, 4)
# 前向传播:数据在网络中怎么走
def forward(self, x):
# 第一步:图像经过卷积层提取特征
x = self.backbone(x)
# 展平:把多维特征变成一维向量,才能输入全连接层
x = torch.flatten(x, 1)
# 第二步:两个头分别输出结果
cls_out = self.cls_head(x) # 分类结果
reg_out = self.reg_head(x) # 检测框结果
return cls_out, reg_out # 返回:类别 + 框坐标
# ==================== 超参数 & 设备设置 ====================
batch_size = 64 # 每次训练喂入64张图片
lr = 0.001 # 学习率:控制参数更新步长
epochs = 5 # 训练5轮
# 自动选择设备:有GPU用GPU,没有用CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# ==================== 加载本地MNIST数据集 ====================
# 图像预处理:转张量 + 归一化
transform = transforms.Compose([
transforms.ToTensor(), # 图片 → 张量
transforms.Normalize((0.1307,), (0.3081,)) # 归一化,训练更稳定
])
# 训练集
train_dataset = datasets.MNIST(
root='./data',
train=True,
download=False,
transform=transform
)
# 测试集
test_dataset = datasets.MNIST(
root='./data',
train=False,
download=False,
transform=transform
)
# 数据加载器:批量、乱序加载数据
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# ==================== 模型、损失函数、优化器 ====================
model = MNISTDetNet().to(device) # 创建模型并搬到设备上
# 分类损失:判断数字预测是否正确
cls_loss_fn = nn.CrossEntropyLoss()
# 回归损失:判断检测框坐标是否准确
reg_loss_fn = nn.SmoothL1Loss()
# 优化器:Adam,自动更新网络参数
optimizer = optim.Adam(model.parameters(), lr=lr)
# ==================== 训练函数 ====================
def train():
model.train() # 开启训练模式
# 循环训练多轮
for epoch in range(epochs):
total_cls_loss = 0 # 累计分类损失
total_reg_loss = 0 # 累计框损失
correct = 0 # 预测正确数量
total = 0 # 总样本数
# 遍历每一批数据
for data, target in train_loader:
data, target = data.to(device), target.to(device)
# 目标检测标签:
# 分类标签:target(真实数字)
# 框标签:MNIST数字占满整个图片,固定标签 [0,0,1,1]
box_target = torch.tensor([[0.0, 0.0, 1.0, 1.0]] * data.size(0)).to(device)
optimizer.zero_grad() # 清空上一轮梯度
cls_out, reg_out = model(data) # 前向传播,得到两个输出
# 计算两个损失
cls_loss = cls_loss_fn(cls_out, target)
reg_loss = reg_loss_fn(reg_out, box_target)
# 总损失 = 分类损失 + 回归损失
loss = cls_loss + reg_loss
loss.backward() # 反向传播,计算梯度
optimizer.step() # 更新模型参数
# 统计训练信息
total_cls_loss += cls_loss.item()
total_reg_loss += reg_loss.item()
pred = cls_out.argmax(dim=1) # 取概率最大的类别
correct += pred.eq(target).sum().item() # 正确数
total += target.size(0)
# 计算这一轮的准确率
cls_acc = 100 * correct / total
# 打印日志
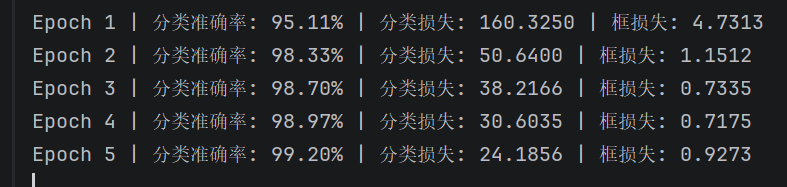
print(f"Epoch {epoch + 1} | 分类准确率: {cls_acc:.2f}% | "
f"分类损失: {total_cls_loss:.4f} | 框损失: {total_reg_loss:.4f}")
# ==================== 测试 + 可视化检测结果 ====================
def visualize_detection():
model.eval() # 开启评估模式
# 从测试集取一批数据
data, target = next(iter(test_loader))
data = data.to(device)
# 不计算梯度,节省内存
with torch.no_grad():
cls_out, reg_out = model(data)
preds = cls_out.argmax(dim=1) # 预测数字
boxes = reg_out.cpu().numpy() # 预测框坐标
# 绘制前8张测试图片 + 检测框
plt.figure(figsize=(12, 5))
for i in range(8):
img = data[i].cpu().squeeze() # 去掉通道维度,显示图片
pred_num = preds[i].item() # 预测数字
true_num = target[i].item() # 真实数字
# 取出模型预测的框
x1, y1, x2, y2 = boxes[i]
# 把归一化坐标(0~1)转为图片像素坐标(0~28)
x1 *= 28
y1 *= 28
x2 *= 28
y2 *= 28
plt.subplot(2, 4, i + 1)
plt.imshow(img, cmap='gray')
# 获取当前绘图对象,用于画框
ax = plt.gca()
# 画红色检测框
rect = patches.Rectangle(
(x1, y1), # 框左上角
x2 - x1, # 宽度
y2 - y1, # 高度
linewidth=2, # 线宽
edgecolor='r', # 红色
facecolor='none'
)
ax.add_patch(rect)
plt.title(f"True:{true_num}, Pred:{pred_num}")
plt.axis('off') # 关闭坐标轴
plt.tight_layout() # 自动调整布局
plt.show()
# ==================== 主程序入口 ====================
if __name__ == "__main__":
train()
visualize_detection()输出结果:
三、目标分割:像素级精准 “描轮廓”
目标检测用矩形框圈物体,但很多时候我们需要更精准的边界 —— 比如医疗影像里分割肿瘤、自动驾驶里分割车道线,这时候就需要目标分割。它不再用方框近似,而是逐像素判断每个像素属于哪个物体,精准勾勒出物体的轮廓。
目标分割主要分为两类,适用场景完全不同:
(1)语义分割:按类别分像素,不区分个体
语义分割会给图片里的每个像素分配一个类别标签,但同类物体不会区分不同个体。比如一张有两只猫的图片,语义分割会把所有猫的像素都标成同一种颜色,但分不清哪只是猫 A,哪只是猫 B。
(2)实例分割:检测 + 分割,区分每个个体
实例分割是目前目标分割的主流,它相当于目标检测 + 像素掩码。它不仅能区分不同类别的物体,还能区分同一类别的不同个体,给每个独立目标生成一张不规则的蒙版,精准贴合物体的边缘(比如毛发、身体曲线)。
代表算法:Mask R-CNN、YOLO-Seg 经典应用:人像抠图、医疗影像分割、工业零件缺陷检测
PyTorch 极简实现:Mini U-Net 数字分割
# PyTorch核心库
import torch
# 构建神经网络的模块
import torch.nn as nn
# 优化器,用于更新网络参数
import torch.optim as optim
# 导入数据集(MNIST)和图像预处理工具
from torchvision import datasets, transforms
# 数据加载器,用于批量读取数据
from torch.utils.data import DataLoader
# 绘图库,用于显示图片
import matplotlib.pyplot as plt
# 数值计算库,用于处理图像数组
import numpy as np
# ==================== 定义经典分割网络:Mini U-Net ====================
# 任务:输入一张手写数字图,输出一张同样大小的掩码图
# 掩码图中:数字区域=1,背景区域=0
class MiniUNet(nn.Module):
# 初始化函数,定义网络的每一层结构
def __init__(self):
super(MiniUNet, self).__init__() # 固定写法,调用父类初始化
# ------------------- 编码器 (Encoder):下采样 -------------------
# 作用:通过卷积和池化,把图片变小,提取图像特征
# 输入: 28x28 -> 输出: 14x14
self.enc1 = nn.Sequential(
# 卷积层:输入1通道(灰度图),输出16通道,卷积核3x3
nn.Conv2d(1, 16, kernel_size=3, padding=1),
# 激活函数:增加网络非线性表达能力
nn.ReLU(),
# 池化层:尺寸减半 (28x28 -> 14x14)
nn.MaxPool2d(2)
)
# 输入: 14x14 -> 输出: 7x7
self.enc2 = nn.Sequential(
# 卷积层:输入16通道,输出32通道
nn.Conv2d(16, 32, kernel_size=3, padding=1),
nn.ReLU(),
# 池化层:尺寸减半 (14x14 -> 7x7)
nn.MaxPool2d(2)
)
# ------------------- 解码器 (Decoder):上采样 -------------------
# 作用:通过反卷积,把小图放大,恢复成原图尺寸
# 输入: 7x7 -> 输出: 14x14
self.dec1 = nn.Sequential(
# 反卷积(转置卷积):专门用于放大图像
# 输入32通道 -> 输出16通道,尺寸扩大2倍
nn.ConvTranspose2d(32, 16, kernel_size=2, stride=2),
nn.ReLU()
)
# 输入: 14x14 -> 输出: 28x28
self.dec2 = nn.Sequential(
# 反卷积:输入16通道,输出16通道,尺寸再扩大2倍 (回到28x28)
nn.ConvTranspose2d(16, 16, kernel_size=2, stride=2),
nn.ReLU()
)
# ------------------- 输出层 -------------------
# 最后输出1个通道,代表分割结果(前景/背景)
self.out = nn.Conv2d(16, 1, kernel_size=3, padding=1)
# Sigmoid函数:把输出值压缩到 [0, 1] 之间,表示是数字的概率
self.sigmoid = nn.Sigmoid()
# 前向传播函数:定义数据在网络中的流动路径
def forward(self, x):
# 1. 编码器提取特征(图像变小)
x1 = self.enc1(x)
x2 = self.enc2(x1)
# 2. 解码器恢复尺寸(图像变大)
x = self.dec1(x2)
x = self.dec2(x)
# 3. 输出分割掩码
out = self.out(x)
# 经过sigmoid,每个像素值都在0~1之间
out = self.sigmoid(out)
return out
# ==================== 超参数与设备设置 ====================
batch_size = 64 # 批次大小:训练时一次性喂入64张图片
lr = 0.001 # 学习率:控制参数更新的速度
epochs = 5 # 训练轮数:把整个数据集完整过5遍
# 自动检测设备:有GPU用GPU,没有就用CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# ==================== 4. 加载本地MNIST数据集 ====================
# 图像预处理操作
transform = transforms.Compose([
transforms.ToTensor(), # 将PIL图片转换为Tensor张量 (值范围0~1)
])
# 加载训练集(使用本地data文件夹下的数据,不重新下载)
train_dataset = datasets.MNIST(root='./data', train=True, download=False, transform=transform)
# 加载测试集
test_dataset = datasets.MNIST(root='./data', train=False, download=False, transform=transform)
# 创建数据加载器
# 训练集:打乱数据(shuffle=True),保证训练随机性
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# 测试集:batch_size=8只为了方便画图,不打乱顺序
test_loader = DataLoader(test_dataset, batch_size=8, shuffle=False)
# ==================== 5. 模型、损失函数、优化器初始化 ====================
# 创建模型实例,并将模型搬到GPU/CPU上
model = MiniUNet().to(device)
# 损失函数:BCELoss (二值交叉熵损失)
# 用于比较:预测的掩码 和 真实的掩码 之间的差距
criterion = nn.BCELoss()
# 优化器:Adam
# 作用:根据计算出的梯度,自动更新网络的参数
optimizer = optim.Adam(model.parameters(), lr=lr)
# ==================== 训练函数 ====================
def train():
model.train() # 开启训练模式
for epoch in range(epochs):
total_loss = 0 # 累计每一轮的总损失
# 遍历训练集中的每一批数据
for data, _ in train_loader:
data = data.to(device) # 将数据搬到指定设备
# -------- 构造分割标签(真值掩码)--------
# 原理:原图中像素值 > 0.5 的是数字(白色),标记为1
# 像素值 < 0.5 的是背景(黑色),标记为0
mask_target = (data > 0.5).float()
optimizer.zero_grad() # 清空上一步的梯度
pred_mask = model(data) # 前向传播,得到模型预测的掩码
# 计算损失:预测值 和 真实值 差多少
loss = criterion(pred_mask, mask_target)
loss.backward() # 反向传播,计算梯度
optimizer.step() # 更新网络参数
total_loss += loss.item() # 累加损失
# 打印训练日志
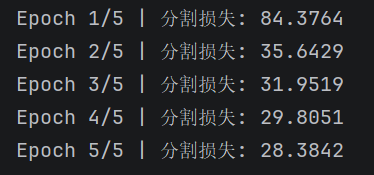
print(f"Epoch {epoch + 1}/{epochs} | 分割损失: {total_loss:.4f}")
# ==================== 可视化分割结果 ====================
def show_segmentation():
model.eval() # 开启评估/测试模式
# 从测试集中取一批数据(8张图片)
data, _ = next(iter(test_loader))
data = data.to(device)
# with torch.no_grad():测试时不计算梯度,节省内存和算力
with torch.no_grad():
pred_mask = model(data) # 模型预测分割掩码
# 绘图
plt.figure(figsize=(12, 5))
for i in range(8):
# 上排:显示原始输入图片
plt.subplot(2, 8, i + 1)
# .squeeze() 去掉多余的维度,从 (1,28,28) 变成 (28,28)
plt.imshow(data[i].cpu().squeeze(), cmap='gray')
plt.title("Input")
plt.axis('off') # 不显示坐标轴
# 下排:显示模型输出的分割掩码
plt.subplot(2, 8, i + 9)
# 将预测结果从Tensor转为numpy数组
mask = pred_mask[i].cpu().squeeze().numpy()
# -------- 将灰度掩码转为黄色掩码 --------
yellow_mask = np.zeros((28, 28, 3)) # 创建一个黑色的RGB图
yellow_mask[..., 0] = mask # 红色通道 = 掩码值
yellow_mask[..., 1] = mask # 绿色通道 = 掩码值
# 红色 + 绿色 = 黄色,背景保持黑色
plt.imshow(yellow_mask)
plt.title("Mask")
plt.axis('off')
plt.tight_layout()
plt.show()
# ==================== 主程序入口 ====================
if __name__ == "__main__":
train()
show_segmentation()输出结果:

关键知识点:
反卷积:即转置卷积,在线性代数层面等价于卷积权重矩阵转置后的矩阵运算,区别于固定规则的插值上采样,它依靠自主学习的卷积参数实现特征图尺寸扩充,普通卷积依靠池化、大步长压缩图像完成下采样,转置卷积则通过步长插零、边缘补零的预处理再卷积实现上采样放大,虽无法精准还原卷积前原始像素,但能自适应恢复图像细节,是语义分割、图像生成网络解码器的核心上采样模块,代码中两层转置卷积依次把 7×7→14×14、14×14→28×28,最终复原原图尺寸用于像素分割预测。
构造分割标签:MNIST 里数字是白色(像素值高),背景是黑色(像素值低),所以我们直接把像素值大于 0.5 的标记为 1(数字),小于 0.5 的标记为 0(背景)
四、目标跟踪:视频里 “追着跑” 的技术
核心任务:跨帧锁定同一个目标
前面三个任务都是处理单张图片,而目标跟踪是视频时序任务。它基于前一帧的检测 / 分割结果,在后续的视频帧里持续锁定同一个目标,给每个目标分配唯一的 ID,不管目标怎么移动、遮挡,都能保持 ID 不变。
输入是连续的视频帧,输出是每个目标的唯一 ID、实时位置(或掩码)。它的前置依赖是目标检测或分割:第一帧先检出所有目标,后续帧不用重复检测全图,只需要追踪这些 ID 对应的目标。
任务分类
- 检测跟踪(一阶段):一帧同时完成检测和跟踪 ID 分配,速度快、工业界最常用,代表算法:JDE、ByteTrack
- 单目标跟踪(SOT):手动框选一个目标,全程只跟踪这一个物体,适用于特定目标追踪场景
经典应用:监控视频的行人追踪、体育赛事的运动员追踪、无人机的目标跟随
PyTorch 极简实现:SiamFC 单目标跟踪
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.animation as animation # 用于动态画图(视频效果)
from torchvision import datasets, transforms # 加载MNIST数据集
# ==================== 1. 定义经典目标跟踪网络:SiamFC(孪生全卷积网络) ====================
# 核心思想:输入两个图
# template(模板):要跟踪的目标
# search(搜索图):在这张图里找目标
# 输出:响应图(越亮表示越像目标)
class SiamFC(nn.Module):
def __init__(self):
super().__init__()
# 主干特征提取网络(两个输入共享这一套权重!)
self.backbone = nn.Sequential(
nn.Conv2d(1, 16, 3, 1, 1), nn.ReLU(), # 卷积+激活
nn.Conv2d(16, 32, 3, 1, 1), nn.ReLU() # 卷积+激活
)
# 前向传播:同时处理模板和搜索图
def forward(self, template, search):
ft = self.backbone(template) # 提取目标模板特征
fs = self.backbone(search) # 提取搜索区域特征
# 互相关操作:用目标特征在搜索图上“滑动匹配”
return nn.functional.conv2d(fs, ft)
# ==================== 2. 加载MNIST数据集,随机取一个数字作为跟踪目标 ====================
transform = transforms.ToTensor() # 图片转张量
# 加载MNIST
dataset = datasets.MNIST(root='./data', train=True, download=False, transform=transform)
# 随机取一张数字图作为“模板”
template_img, _ = dataset[np.random.randint(len(dataset))]
# 增加batch维度,变成 [1, 1, 28, 28]
template_img = template_img.unsqueeze(0)
# ==================== 3. 配置设备、模型、超参数 ====================
DEVICE = torch.device("cpu") # 使用CPU运行
model = SiamFC().to(DEVICE) # 实例化跟踪模型
template = template_img.to(DEVICE) # 模板送到设备上
SEARCH_SIZE = 64 # 搜索区域(大图)大小 64x64
OBJ_SIZE = 28 # 数字目标大小 28x28
# ==================== 4. 生成“数字随机移动”的一帧图像 ====================
# 输入:上一帧的坐标 (prev_x, prev_y)
# 输出:新的一帧 + 新坐标
def create_moving_frame(prev_x, prev_y):
# 随机生成小位移(-3,-2,-1,0,1,2,3)
dx = np.random.randint(-3, 4)
dy = np.random.randint(-3, 4)
# 更新位置,并确保不会跑出画面(clip)
x = np.clip(prev_x + dx, 0, SEARCH_SIZE - OBJ_SIZE)
y = np.clip(prev_y + dy, 0, SEARCH_SIZE - OBJ_SIZE)
# 创建全黑的64x64大图
frame = torch.zeros(1, 1, SEARCH_SIZE, SEARCH_SIZE)
# 将数字贴到新位置
frame[:, :, y:y+OBJ_SIZE, x:x+OBJ_SIZE] = template_img
return frame, x, y
# ==================== 5. 跟踪函数:输入搜索图,输出目标坐标 ====================
def track(search_img):
# 不计算梯度,推理更快
with torch.no_grad():
response = model(template, search_img.to(DEVICE)) # 得到响应图
# 把响应图转成numpy,找到最大值位置(最像目标的地方)
res = response[0,0].cpu().numpy()
y, x = np.unravel_index(np.argmax(res), res.shape)
# 将响应图坐标映射回64x64大图的坐标
scale = SEARCH_SIZE - OBJ_SIZE + 1
x = int(x * (SEARCH_SIZE - OBJ_SIZE) / (scale - 1))
y = int(y * (SEARCH_SIZE - OBJ_SIZE) / (scale - 1))
return x, y
# ==================== 6. 动态显示:左边模板,右边跟踪画面(带绿色框) ====================
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10, 4)) # 1行2列图
# 初始化数字起始位置
x, y = 10, 10
frame, _, _ = create_moving_frame(x, y)
# 左图:显示要跟踪的目标(模板)
ax1.imshow(template_img[0,0], cmap="gray")
ax1.set_title("Template") # 标题
ax1.axis("off") # 不显示坐标轴
# 右图:显示跟踪画面(数字+跟踪框)
im = ax2.imshow(frame[0,0], cmap="gray", vmin=0, vmax=1)
# 创建绿色矩形框,表示跟踪到的目标
rect = plt.Rectangle((x, y), 28, 28, fill=False, edgecolor="green", linewidth=2)
ax2.add_patch(rect)
ax2.set_title("Tracking")
ax2.axis("off")
# ==================== 动画更新函数:每一帧都会调用 ====================
def update(frame_idx):
global x, y # 使用全局坐标
frame, x, y = create_moving_frame(x, y) # 生成移动后的新帧
tx, ty = track(frame) # 用模型跟踪目标位置
im.set_data(frame[0,0]) # 更新图像
rect.set_xy((tx, ty)) # 更新绿色框位置
return im, rect
# ==================== 启动动画 ====================
ani = animation.FuncAnimation(
fig, update, frames=100, interval=80, blit=True
)
plt.tight_layout()
plt.show()输出结果:

关键知识点:
这段代码不需要训练,是因为它仅在纯黑背景、单一白色数字的极简场景下,依靠随机初始化卷积核天然具备的边缘、灰度对比检测能力,就能通过孪生网络的互相关运算完成简单的模板匹配,目标与背景差异极大、无干扰、无遮挡、无形态变化,仅需简单的特征相似度计算即可准确定位,无需通过数据学习优化权重,因此可以直接实现跟踪效果。
互相关运算以目标模板特征为卷积核,在搜索区域特征图上进行滑动卷积计算,通过逐窗口匹配得到相似度响应图,响应图中的最大值坐标对应搜索图中与目标最相似的位置,从而实现目标定位,是孪生跟踪网络 SiamFC 的核心匹配机制。
五、总结
- 目标分类:认图,只说 “这是什么”
- 目标检测:画框,说清 “有什么、在哪里、有几个”
- 目标分割:描边,像素级精准勾勒物体轮廓
- 目标跟踪:追人,在视频里跨帧锁定同一个目标

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)