手写数据集MINIST训练
PyTorch 入门第01个项目:MNIST 手写数字识别完整流程
一、项目简介
前面已经完成了 Python 开发环境配置和 PyTorch GPU 版安装。本文开始运行第一个 PyTorch 入门项目:MNIST 手写数字识别。
MNIST 是深度学习入门中非常经典的数据集,包含 0-9 共 10 类手写数字图片。每张图片大小为 28×28,是灰度图像。
本文使用一个简单的全连接神经网络完成手写数字分类任务。重点不是追求最高准确率,而是理解 PyTorch 项目的基本流程:
数据加载 → 模型定义 → 前向传播 → 损失计算 → 反向传播 → 参数更新 → 准确率测试 → 预测可视化
二、运行环境
| 项目 | 配置 |
|---|---|
| 操作系统 | Windows 11 |
| Python 版本 | Python 3.10 |
| 深度学习框架 | PyTorch |
| 开发工具 | PyCharm |
| 环境管理 | Anaconda / conda |
| 数据集 | MNIST |
如果使用之前创建的 PyTorch 环境,可以先激活环境:
三、MNIST 数据集说明
MNIST 图片大小为:
28 × 28
由于本文使用的是全连接神经网络,所以需要把每张图片从二维图像展平成一维向量:
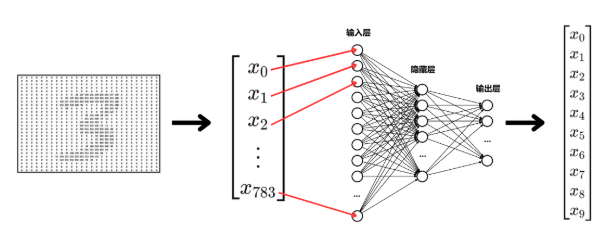
28 × 28 = 784
代码中对应操作是:
x.view(-1, 28 * 28)
其中,-1 表示自动推断 batch size。
四、完整代码
import torch
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision.datasets import MNIST
import matplotlib.pyplot as plt
# 定义神经网络模型
class Net(torch.nn.Module):
def __init__(self):
super().__init__()
# MNIST 图片为 28×28,展平后是 784 维
self.fc1 = torch.nn.Linear(28 * 28, 64)
self.fc2 = torch.nn.Linear(64, 64)
self.fc3 = torch.nn.Linear(64, 64)
# 输出 10 个类别,对应数字 0-9
self.fc4 = torch.nn.Linear(64, 10)
def forward(self, x):
# 全连接层 + ReLU 激活函数
x = torch.nn.functional.relu(self.fc1(x))
x = torch.nn.functional.relu(self.fc2(x))
x = torch.nn.functional.relu(self.fc3(x))
# 输出每个类别的对数概率
x = torch.nn.functional.log_softmax(self.fc4(x), dim=1)
return x
# 加载 MNIST 数据集
def get_data_loader(is_train):
to_tensor = transforms.Compose([
transforms.ToTensor()
])
data_set = MNIST(
root="",
train=is_train,
transform=to_tensor,
download=True
)
return DataLoader(
data_set,
batch_size=15,
shuffle=True
)
# 评估模型准确率
def evaluate(test_data, net):
n_correct = 0
n_total = 0
# 测试阶段不需要计算梯度
with torch.no_grad():
for (x, y) in test_data:
# 将图片展平成 784 维
outputs = net.forward(x.view(-1, 28 * 28))
for i, output in enumerate(outputs):
# 取预测概率最大的类别
if torch.argmax(output) == y[i]:
n_correct += 1
n_total += 1
return n_correct / n_total
def main():
# 加载训练集和测试集
train_data = get_data_loader(is_train=True)
test_data = get_data_loader(is_train=False)
# 创建模型
net = Net()
# 训练前测试初始准确率
print("initial accuracy:", evaluate(test_data, net))
# Adam 优化器
optimizer = torch.optim.Adam(net.parameters(), lr=0.001)
# 训练 2 个 epoch
for epoch in range(2):
for (x, y) in train_data:
# 清空梯度
net.zero_grad()
# 前向传播
output = net.forward(x.view(-1, 28 * 28))
# 计算损失
loss = torch.nn.functional.nll_loss(output, y)
# 反向传播
loss.backward()
# 更新参数
optimizer.step()
print("epoch", epoch, "accuracy:", evaluate(test_data, net))
# 显示部分预测结果
for (n, (x, _)) in enumerate(test_data):
if n > 3:
break
predict = torch.argmax(net.forward(x[0].view(-1, 28 * 28)))
plt.figure(n)
plt.imshow(x[0].view(28, 28), cmap="gray")
plt.title("prediction: " + str(int(predict)))
plt.show()
if __name__ == "__main__":
main()
五、关键代码解释
1. 为什么输入是 28×28?
MNIST 每张图片大小是 28×28。由于本文使用全连接网络,所以需要将图片展平成:
784 维向量
对应代码:
x.view(-1, 28 * 28)
2. 为什么最后输出是 10?
因为 MNIST 是 0-9 的数字分类任务,一共有 10 个类别:
self.fc4 = torch.nn.Linear(64, 10)
3. log_softmax 和 nll_loss 的关系
模型最后使用:
torch.nn.functional.log_softmax()
损失函数使用:
torch.nn.functional.nll_loss()
这两个通常搭配使用,适合分类任务。
4. 训练过程包括哪些步骤?
核心训练流程如下:
net.zero_grad()
output = net.forward(x.view(-1, 28 * 28))
loss = torch.nn.functional.nll_loss(output, y)
loss.backward()
optimizer.step()
对应含义:
| 代码 | 含义 |
|---|---|
net.zero_grad() |
清空上一轮梯度 |
net.forward() |
前向传播 |
nll_loss() |
计算损失 |
loss.backward() |
反向传播 |
optimizer.step() |
更新模型参数 |
六、运行结果
运行后,控制台会输出训练前和训练后的准确率: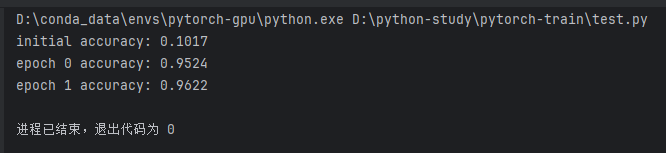
初始准确率较低,是因为模型参数是随机初始化的。经过训练后,准确率明显提高,说明模型已经从训练集中学习到了手写数字的基本特征。
训练完成后,程序会显示几张测试集图片,并在标题中显示模型预测结果: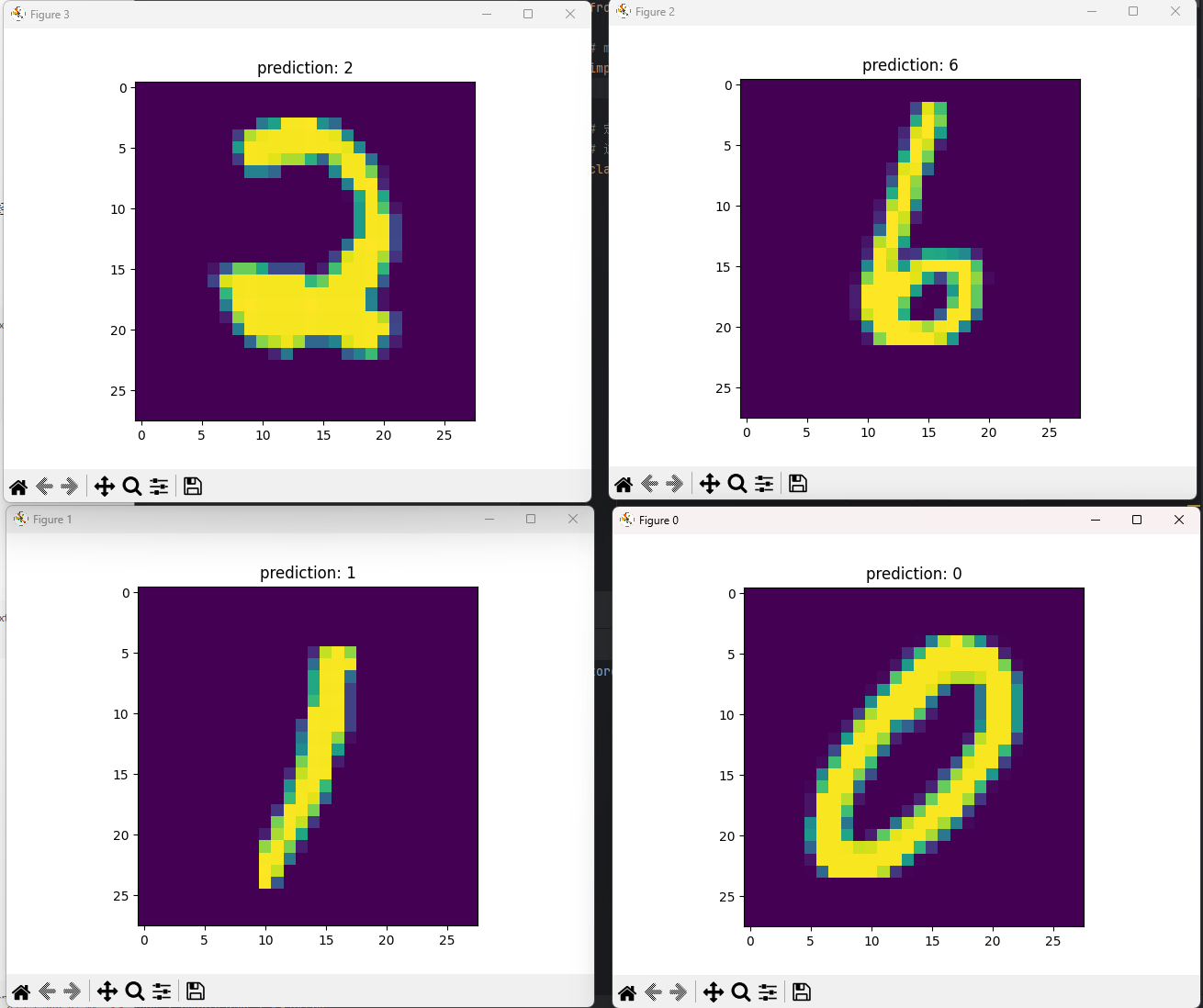
七、常见问题与避坑
1. PyCharm 提示找不到 torch 怎么办?
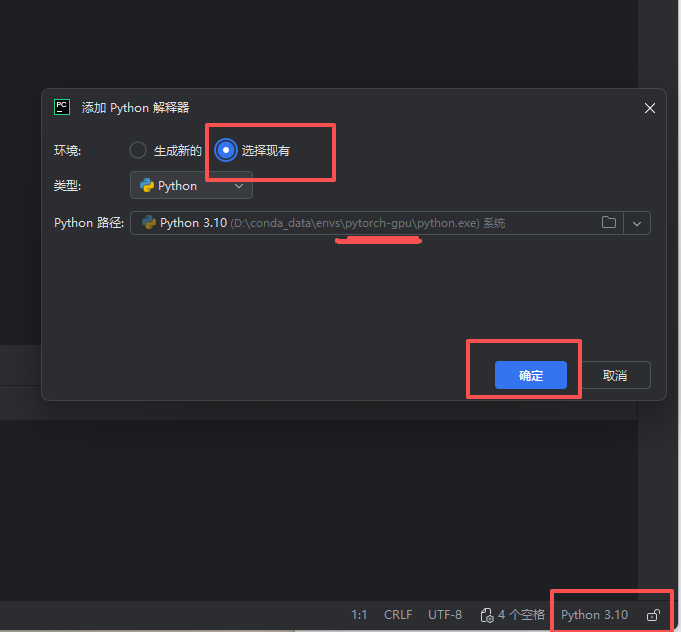
大概率是解释器选错了。需要选择安装 PyTorch 的 conda 环境,例如:
pytorch-gpu 环境中的 python.exe
不要选择 base 环境或系统自带 Python。
2. MNIST 下载失败怎么办?
可能是网络问题,可以多运行几次,或者更换网络环境。
3. 这段代码有没有使用 GPU?
这段代码默认运行在 CPU 上。对于 MNIST 这种小项目,CPU 也可以正常运行。
如果想使用 GPU,需要将模型和数据都移动到 CUDA 设备上,例如:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
net = net.to(device)
x = x.to(device)
y = y.to(device)
不过作为第一个入门项目,建议先把完整训练流程跑通。
4. 为什么不用 CNN?
本文使用全连接网络,是为了让入门者更容易理解完整训练流程。对于图像任务,CNN 通常效果更好,后续可以继续使用卷积神经网络改进 MNIST 分类效果。
八、总结
本文完成了第一个 PyTorch 入门项目:MNIST 手写数字识别。
通过这个项目,主要理解了:
- 如何加载 MNIST 数据集;
- 如何定义简单神经网络;
- 如何进行前向传播;
- 如何计算损失;
- 如何反向传播并更新参数;
- 如何评估准确率;
- 如何显示预测结果。
这个项目虽然简单,但已经包含了深度学习训练的完整流程。后续可以继续学习 CNN、CIFAR-10 图像分类、迁移学习和 YOLO 目标检测项目。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)