【AI测试路线图3】2026 年企业到底需要什么样的 AI 测试工程师?
文 / 周周
副标题:2026 年企业到底需要什么样的 AI 测试工程师?我画了一张地图,6 个维度,3-4 个月可落地。
01
"你觉得 AI测试工程师,最核心的能力是什么?"
"设计测试用例的能力?"
"那是传统测试。AI测试,核心是定义什么是'好'的 AI 输出。"
我画出了这张AI测试工程师能力地图。
今天,我想把它分享给你。
02
先说结论。
2026 年,企业招聘 AI测试工程师,最看重这6 项核心能力:
┌─────────────────────────────────────────┐
│ AI测试工程师能力地图 │
├─────────────────────────────────────────┤
│ 1. Python 编程能力(必会) │
│ 2. 大模型理解能力(必会) │
│ 3. Prompt 工程能力(必会) │
│ 4. Agent 框架能力(核心) │
│ 5. 评测体系设计(差异化) │
│ 6. 测试工程化(加分项) │
└─────────────────────────────────────────┘
注意顺序——这不是随机排的。
前 3 项是门槛,第 4 项是核心,第 5 项是差异化,第 6 项是加分。
下面我逐一拆解。
03
能力 1:Python 编程能力(必会)
为什么必会?
AI测试不是"点点点",是要写代码的。
- 调用大模型 API → 需要 Python
- 开发评测脚本 → 需要 Python
- 集成 CI/CD → 需要 Python
- 数据分析 → 需要 Python
需要学到什么程度?
不需要成为 Python 专家,但要能独立完成以下任务:
| 任务 | 涉及知识点 | 重要度 |
|---|---|---|
| 调用 API | requests、json、异常处理 | ⭐⭐⭐⭐⭐ |
| 数据处理 | pandas、列表推导式 | ⭐⭐⭐⭐ |
| 文件操作 | JSON、Excel、CSV读写 | ⭐⭐⭐⭐ |
| 测试框架 | pytest、unittest | ⭐⭐⭐⭐ |
| 自动化脚本 | 循环、条件、函数 | ⭐⭐⭐⭐⭐ |
不需要学的(暂时):
- 装饰器、元类(用不到)
- 异步编程(除非做高性能)
- Web 开发(Django/Flask)
学习建议:
第 1 周:Python 基础语法(变量、循环、函数)
第 2 周:数据结构(列表、字典、集合)
第 3 周:文件操作 + JSON 处理
第 4 周:requests 库 + API 调用
第 5 周:pytest 测试框架
实战项目:
写一个脚本,完成以下任务:
- 调用阿里云 DashScope API
- 发送 10 个测试问题
- 将结果保存到 Excel
- 用 pytest 写 3 个测试用例
能做到这个,Python 就够用了。
04
能力 2:大模型理解能力(必会)
误区警示:
不需要会训练大模型!
很多测试同行被"大模型"三个字吓到了,以为要学机器学习、深度学习、Transformer……
错。
AI测试工程师需要的是理解大模型的能力边界,不是会造大模型。
需要知道什么?
| 知识点 | 深度要求 | 用途 |
|---|---|---|
| Token 是什么 | 理解概念 | 计算成本、处理长文本 |
| Embedding | 理解概念 | 向量检索、RAG |
| Temperature | 会用参数 | 控制输出随机性 |
| Top-P | 会用参数 | 控制输出多样性 |
| Context Window | 理解限制 | 设计 Prompt |
| 幻觉 | 理解成因 | 设计测试用例 |
| Prompt 注入 | 理解原理 | 安全测试 |
不需要知道什么?
- Transformer 架构细节
- 反向传播算法
- 损失函数优化
- 分布式训练
学习资源推荐:
- 吴恩达《AI For Everyone》(4 小时,入门首选)
- 李宏毅 Transformer 讲解(B 站,选看前 3 集)
- 阿里云ACP大模型教程(系统学习)
自测题(能答对 3 个就算及格):
- Token 是什么?中文和英文的 Token 数量怎么估算?
- Temperature=0 和 Temperature=1 有什么区别?
- 什么是幻觉?举一个实际例子。
- 为什么大模型会有上下文长度限制?
- 什么是 Prompt 注入?怎么防御?
05
能力 3:Prompt 工程能力(必会)
为什么是必会?
Prompt 是 AI测试的核心工具。
- 生成测试用例 → 需要 Prompt
- 构造测试数据 → 需要 Prompt
- 分析测试结果 → 需要 Prompt
- 自动化报告 → 需要 Prompt
需要掌握的技巧:
我总结了7 个核心技巧,按优先级排序:
| 技巧 | 学习难度 | 使用频率 | 示例 |
|---|---|---|---|
| 角色设定 | ⭐ | ⭐⭐⭐⭐⭐ | "你是一个资深测试工程师..." |
| 任务拆解 | ⭐⭐ | ⭐⭐⭐⭐⭐ | "第一步...第二步...第三步..." |
| 输出格式化 | ⭐⭐ | ⭐⭐⭐⭐ | "请用 JSON 格式输出..." |
| 少样本学习 | ⭐⭐⭐ | ⭐⭐⭐⭐ | "示例 1:... 示例 2:..." |
| 思维链 | ⭐⭐⭐ | ⭐⭐⭐ | "请逐步思考..." |
| 自我反思 | ⭐⭐⭐⭐ | ⭐⭐⭐ | "请检查是否有遗漏..." |
| 迭代优化 | ⭐⭐⭐⭐ | ⭐⭐⭐ | "基于上次输出改进..." |
实战练习:
用以下 Prompt 模板,生成测试用例:
你是一个资深软件测试工程师,擅长设计全面的测试用例。
任务:为以下功能设计测试用例
功能描述:用户登录接口
要求:
1. 覆盖正常场景和异常场景
2. 每个用例包含:用例名称、前置条件、测试步骤、预期结果
3. 用表格格式输出
功能细节:
- 输入:用户名(字符串)、密码(字符串)
- 输出:登录成功/失败
- 失败原因:用户不存在、密码错误、账户锁定
评估标准:
- 用例覆盖度(正常 + 异常)
- 用例可执行性(步骤清晰)
- 格式规范性(表格完整)
06
能力 4:Agent 框架能力(核心)
为什么是核心?
2026 年,大部分 AI应用都是 Agent 驱动的。
测试 AI应用,本质上就是测试 Agent 的行为。
需要掌握哪些框架?
| 框架 | 学习优先级 | 特点 |
|---|---|---|
| LangGraph | ⭐⭐⭐⭐⭐ | 生产就绪,状态管理,多节点流程 |
| CrewAI | ⭐⭐⭐⭐⭐ | 上手简单,文档友好 |
| AutoGen | ⭐⭐⭐⭐ | 功能强大,微软出品 |
| LangChain | ⭐⭐⭐⭐ | RAG 应用首选 |
| Dify | ⭐⭐⭐ | 低代码,快速原型 |
| Coze | ⭐⭐ | 字节出品,适合 Bot |
我的建议:
先精通一个,再横向扩展。
我选的是 LangGraph,原因:
- 生产就绪架构
- 状态管理完善
- 多节点流程控制
- 企业级应用首选
学习路径:
第 1 天:安装 + 跑通 Hello World
第 2 天:理解 Node、State、Graph 概念
第 3 天:创建第一个状态节点(测试用例生成)
第 4 天:多节点流程编排
第 5 天:集成工具(API 调用)
第 6 天:完整项目(测试用例生成系统)
第 7 天:复习 + 总结
实战项目:
用 LangGraph 搭建一个"测试用例生成智能体":
from langgraph.graph import StateGraph
from typing import TypedDict, List
class TestState(TypedDict):
requirements: str
test_cases: List[str]
current_step: str
def parse_requirements(state: TestState):
"""解析测试需求"""
# 使用 LLM 解析需求文档
parsed_reqs = llm_call(f"解析以下测试需求: {state['requirements']}")
return {"current_step": "parsed", "test_cases": []}
def generate_test_cases(state: TestState):
"""生成测试用例"""
# 基于解析的需求生成测试用例
test_cases = llm_call(f"为以下需求生成测试用例: {state['requirements']}")
return {"test_cases": test_cases.split('\n'), "current_step": "generated"}
def validate_test_cases(state: TestState):
"""验证测试用例"""
# 验证生成的测试用例完整性
validated_cases = llm_call(f"验证并完善以下测试用例: {state['test_cases']}")
return {"test_cases": validated_cases, "current_step": "validated"}
# 构建状态图
workflow = StateGraph(TestState)
workflow.add_node("parse", parse_requirements)
workflow.add_node("generate", generate_test_cases)
workflow.add_node("validate", validate_test_cases)
# 定义流程
workflow.add_edge("parse", "generate")
workflow.add_edge("generate", "validate")
workflow.set_entry_point("parse")
workflow.set_finish_point("validate")
# 编译并运行
app = workflow.compile()
result = app.invoke({"requirements": "用户登录功能"})
能做到这个,Agent 框架就算入门了。
07
能力 5:评测体系设计(差异化)
为什么是差异化?
前 4 项能力,大部分人花 3 个月都能学会。
评测体系设计,是区分"会用 AI"和"懂 AI测试"的关键。
需要掌握什么?
| 知识点 | 用途 | 学习资源 |
|---|---|---|
| 评测指标设计 | 定义什么是"好"的 AI 输出 | DeepEval 文档 |
| 测试用例构造 | 覆盖各种边界情况 | RAGAS 论文 |
| 量化评估方法 | 用数据说话 | 统计学基础 |
| 红队测试 | 发现安全漏洞 | Garak 文档 |
| LLM-as-a-Judge | 自动化评估 | 相关论文 |
我的实战经验:
我设计了5 维度评测体系:
┌─────────────────────────────────────┐
│ AI Agent 评测体系 │
├─────────────────────────────────────┤
│ 1. 任务规划(3.37/5) │
│ 2. 工具使用(2.64/5) │
│ 3. 多轮对话(4.26/5) │
│ 4. 代码能力(4.10/5) │
│ 5. 知识应用(3.33/5) │
└─────────────────────────────────────┘
每个维度,我又拆解了 3-4 个细粒度指标。
比如"任务规划":
- 任务分解覆盖率
- 依赖关系识别准确率
- 重规划能力
怎么学?
- 先跑通 DeepEval/RAGAS 官方示例
- 理解每个指标的含义
- 用自己的数据测试
- 尝试设计新指标
这是真正的技术壁垒。
08
三个反直觉认知:AI 测试跟你想的不一样
反直觉一:用例断言在 AI 测试中反而有害
传统测试的根基是"断言"——assert result == expected。但在 AI 测试中,大多数场景没有标准答案。
用户问"帮我写一封邮件",没有一个唯一的正确答案。如果你用 assert "感谢" in output 做断言,要么误报(模型没写"感谢"但邮件很好),要么漏报(模型写了"感谢"但邮件不相关)。
AI 测试的核心不是"验证结果对不对",而是"评估结果好不好"。从布尔判断到连续评分,这个转变是认知上的第一道槛。
反直觉二:覆盖率思维会害死你
传统测试讲究覆盖率——行覆盖、分支覆盖、路径覆盖。但在 AI 测试中,输入空间是无限的。
同一个 Prompt 问 100 次,可能拿到 100 个不同的输出(temperature > 0 时)。代码覆盖率再高,监控不到"模型今天输出质量变差"这种退化。
AI 测试更需要的是:语义覆盖(是否覆盖了关键能力维度)、边界探测(模型在什么情况下开始犯错)、退化检测(同一 Prompt 在不同版本的输出对比)。覆盖率的对象从"代码"变成了"行为空间"。
反直觉三:AI 测试更像"评估员",不是"找 Bug 的人"
传统测试的价值定位是"发现缺陷"。但 AI 测试中,"缺陷"是模糊的。
模型回答慢了 2 秒——是 Bug 还是正常波动?用户问"讲个故事",模型讲了一个平淡无奇的故事——是 Bug 还是能力边界?模型在两个版本之间输出风格变了——是退化还是优化?
AI 测试的核心工作是定义"好"的标准、设计评测维度、建立监控基线。你不是在找 Bug,你是在给 AI 系统的质量画刻度尺。
这三条认知,能帮你从"传统测试思维"切换到"AI 测试思维"。做不到这个转变,工具学再多也是白搭。
09
能力迁移路径图(传统测试 → AI 测试)
如果你是传统测试工程师,不用担心从零开始。你已有的能力可以这样迁移到 AI 测试:
┌─────────────────────────────────────────────────────────────────┐
│ 传统测试能力 → AI测试能力 │
├─────────────────────────────────────────────────────────────────┤
│ 用例设计 → Prompt 工程(任务拆解+角色设定) │
│ 测试执行 → Agent 框架(流程编排+工具调用) │
│ 缺陷管理 → 评测体系(指标设计+红队测试) │
│ 自动化脚本 → Python + CI/CD 集成 │
│ 覆盖率分析 → 语义覆盖 + 退化检测 │
└─────────────────────────────────────────────────────────────────┘
核心洞察:你不需要抛弃已有经验,只需要用新的"翻译"方式重新包装你的技能。
10
转型避坑清单(AI 测试 10 大雷区)
很多人的转型失败,不是因为学不会,而是踩了不该踩的坑:
| 避坑项 | 说明 | 预防措施 |
|---|---|---|
| ❌ 不理解"幻觉"的危害 | 导致测试用例无效,误判模型表现 | 专门学习幻觉类型,设计针对性检测用例 |
| ❌ 过度依赖 Prompt 模板 | 缺乏灵活性,无法应对复杂场景 | 重点学 Prompt 原理,而非背模板 |
| ❌ 忽视退化检测 | 同一 Prompt 在不同版本输出差异,无法发现性能下降 | 建立基线对比机制,定期回归测试 |
| ❌ 把 AI 测试当成"自动化测试" | 忽略了"质量评估"的本质 | 从"验证结果对错"转向"评估结果好坏" |
| ❌ 忽视安全性测试 | Prompt 注入、越权攻击等风险未覆盖 | 学习红队测试,掌握安全评估方法 |
| ❌ 不做数据沉淀 | 无法建立基线,无法做趋势分析 | 建立测试数据仓库,记录历史对比 |
| ❌ 忽视团队协作 | 测试无法融入研发流程 | 主动与开发、产品沟通,建立协作机制 |
| ❌ 过早追求"大模型训练" | 走偏方向,浪费时间 | 专注测试能力,训练交给算法工程师 |
| ❌ 不建立反馈闭环 | 测试结果无法驱动产品迭代 | 定期输出质量报告,推动问题修复 |
| ❌ 缺乏可视化报告 | 团队无法感知质量变化 | 学习报表工具,制作直观的质量dashboard |
提前避开这些坑,能让你的转型之路顺畅 50%。
11
学习资源推荐矩阵(按阶段精准匹配)
不同阶段需要不同的学习资源,避免"资源浪费":
第 1 月(基础阶段):
- Python基础:廖雪峰 Python 教程(免费)
- AI基础:吴恩达《AI for Everyone》(4小时入门)
- 大模型入门:阿里云ACP大模型认证课程
第 2 月(实战阶段):
- LangGraph:官方文档 + GitHub 示例
- CrewAI:官方教程 + 实战项目
- Prompt工程:《Prompt Engineering Guide》
第 3 月(进阶阶段):
- 评测体系:DeepEval官方示例 + RAGAS论文
- 安全测试:Garak开源工具 + 红队测试指南
- LLM-as-a-Judge:相关学术论文解读
第 4 月(输出阶段):
- 工程化:GitHub Actions + Docker基础
- 项目展示:搭建个人作品集网站
- 社区输出:写技术博客、录制教学视频
12
能力 6:测试工程化(加分项)
为什么是加分?
前 5 项是"单兵作战能力",这项是"团队作战能力"。
企业喜欢能搭建体系的人。
需要掌握什么?
| 技能 | 用途 | 重要度 |
|---|---|---|
| CI/CD 集成 | 自动化测试流水线 | ⭐⭐⭐⭐ |
| 测试报告生成 | 可视化测试结果 | ⭐⭐⭐⭐ |
| 版本管理 | Git 基础 | ⭐⭐⭐ |
| 容器化 | Docker 基础 | ⭐⭐⭐ |
| 监控告警 | 线上质量监控 | ⭐⭐⭐ |
学习建议:
优先学:
- GitHub Actions(CI/CD)
- Markdown/HTML报告生成
- Git 基础命令
可以后学:
- Docker(除非做部署)
- Kubernetes(除非做大规模)
实战项目:
搭建一个自动化评测流水线:
- 代码提交到 GitHub
- 自动触发测试
- 生成评测报告
- 发送到飞书/钉钉
13
能力地图总览
我把 6 项能力整理成一张表:
| 能力 | 学习周期 | 重要度 | 面试考察方式 |
|---|---|---|---|
| Python 编程 | 1 个月 | ⭐⭐⭐⭐⭐ | 笔试/现场 coding |
| 大模型理解 | 2 周 | ⭐⭐⭐⭐⭐ | 概念问答 |
| Prompt 工程 | 2 周 | ⭐⭐⭐⭐⭐ | 现场设计 Prompt |
| Agent 框架 | 1 个月 | ⭐⭐⭐⭐⭐ | 项目展示 |
| 评测体系 | 1 个月 | ⭐⭐⭐⭐ | 方案设计 |
| 测试工程化 | 2 周 | ⭐⭐⭐ | 经验问答 |
总学习周期:3-4 个月(每天 2 小时)
学习顺序建议:
第 1 月:Python + 大模型基础 + Prompt
第 2 月:Agent 框架 + 项目实战
第 3 月:评测体系 + 工程化
第 4 月:面试准备 + 简历优化
14
自我评估雷达图(20 道题升级版)
读完这篇文章,花 10 分钟做个自测。不再用简单的"题数对错"判断,改用雷达图评估各维度能力:
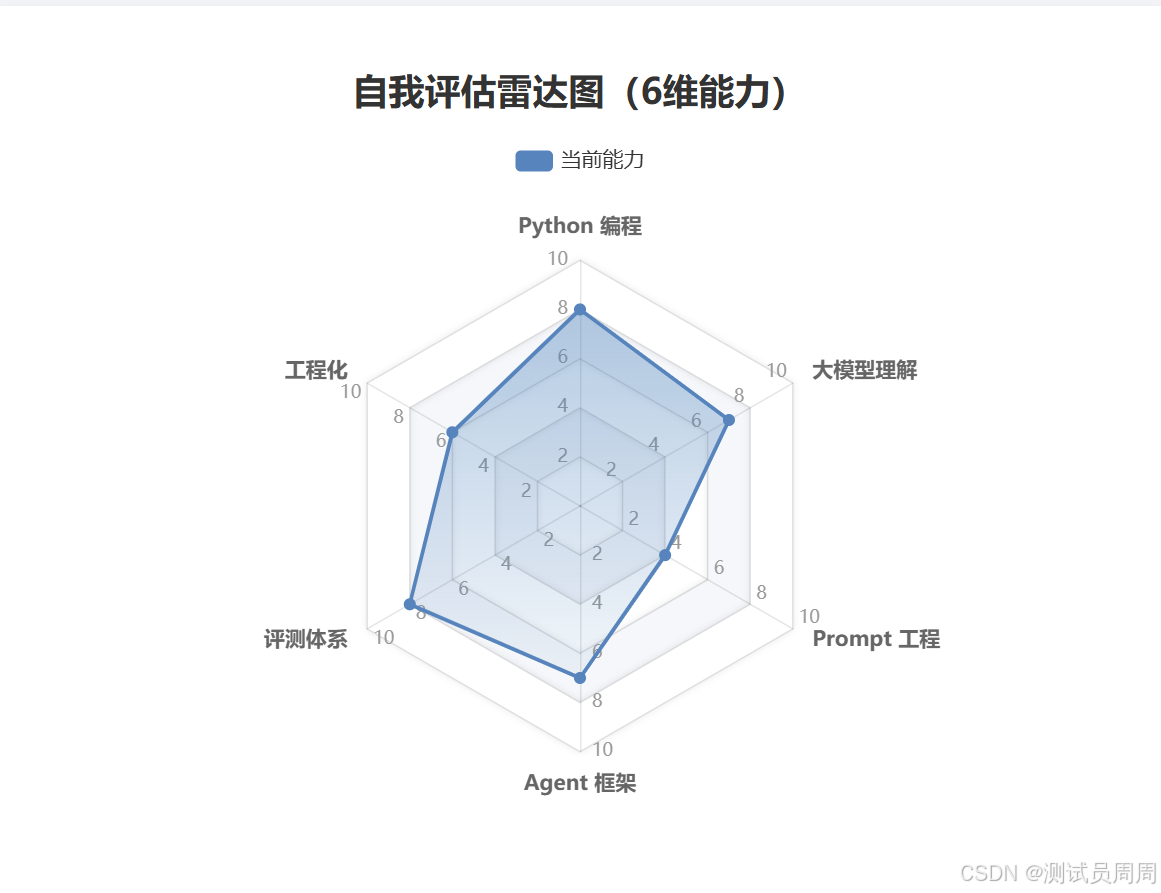
评分标准(0-10 分制):
- 0-3 分:完全不了解,需要系统学习
- 4-6 分:入门水平,能完成基础任务
- 7-8 分:熟练水平,能独立交付
- 9-10 分:专家水平,能指导他人
Python 编程(4 题,每题 0-2.5 分)
- 如何用 Python 发送 HTTP 请求?(requests 库)
- 如何读取 JSON 文件?(json.load)
- 如何用 pytest 写一个测试用例?
- 列表推导式的语法是什么?
大模型理解(4 题,每题 0-2.5 分) 5. Token 是什么?中文和英文的 Token 数量怎么估算? 6. Temperature 参数的作用是什么? 7. 什么是上下文窗口限制? 8. 什么是幻觉?举一个例子。
Prompt 工程(4 题,每题 0-2.5 分) 9. 角色设定的作用是什么? 10. 什么是思维链(CoT)? 11. 少样本学习的原理是什么? 12. 如何设计输出格式化的 Prompt?
Agent 框架(4 题,每题 0-2.5 分) 13. LangGraph 的三个核心概念是什么? 14. 如何定义一个状态节点? 15. 如何编排多节点流程? 16. 如何处理异常状态?
评测体系(2 题,每题 0-5 分) 17. 评测 AI 应用,应该用哪些指标? 18. 什么是 LLM-as-a-Judge?
测试工程化(2 题,每题 0-5 分) 19. 如何将测试集成到 CI/CD? 20. 测试报告应该包含哪些内容?
雷达图解读指南:
| 维度 | 得分 ≥7 | 得分 4-6 | 得分 ≤3 |
|---|---|---|---|
| Python 编程 | 可直接投简历 | 再练 2 周 | 系统学习 1 月 |
| 大模型理解 | 概念过关 | 补上腾讯课堂 | 看吴恩达入门课 |
| Prompt 工程 | 可做导师 | 多练实战 | 先学基础模板 |
| Agent 框架 | 面试加分项 | 多做项目 | 跑通 Hello World |
| 评测体系 | 核心优势 | 需要理解指标 | 从了解概念开始 |
| 测试工程化 | 全栈能力 | 能搭流水线 | 学习基础工具 |
综合建议:
- 4 个维度 ≥7 分:可以投简历了
- 3 个维度 ≥6 分:再学 2 周,重点补薄弱项
- 2 个维度 ≥5 分:需要系统学习 1 个月
- ≤2 个维度 ≥5 分:建议重新评估职业方向,从基础开始
15
最后说几句
中间我也怀疑过:14 年了还能学会新技术吗?跟年轻人拼拼得过吗?
答案是:能。但别走弯路。
你不需要学 Transformer 原理、不需要搞模型训练、不需要搭深度学习环境。专注在 6 件事上:Python 调 API、理解大模型边界、写 Prompt、用 Agent 框架、设计评测体系、搭 CI/CD。
3-4 个月,每天 2 小时,足够了。
16
下期预告
《传统测试 vs AI测试:10 个核心差异,不知道会吃大亏》
我会用真实案例告诉你:
- 为什么 assert result == expected 在 AI测试中不适用
- 如何测试"没有标准答案"的 AI 输出
- AI测试的思维模式转变
谢谢你看到这里。
如果你在做自我评估,或者有任何问题,欢迎留言交流。
留言告诉我:你的自测得分是多少?哪项能力最薄弱?
我是周周,一个 14 年测试老兵,已成功转型 AI测试的实践者。每一条留言我都会看,都会回。
别想太多,先试试。知道往哪走,比走得快更重要。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 23
23 0
0- 0



 已为社区贡献60条内容
已为社区贡献60条内容

所有评论(0)