[智能体-263]:文档 Embedding 嵌入模型全解(RAG 第四步 Embed 环节)
·
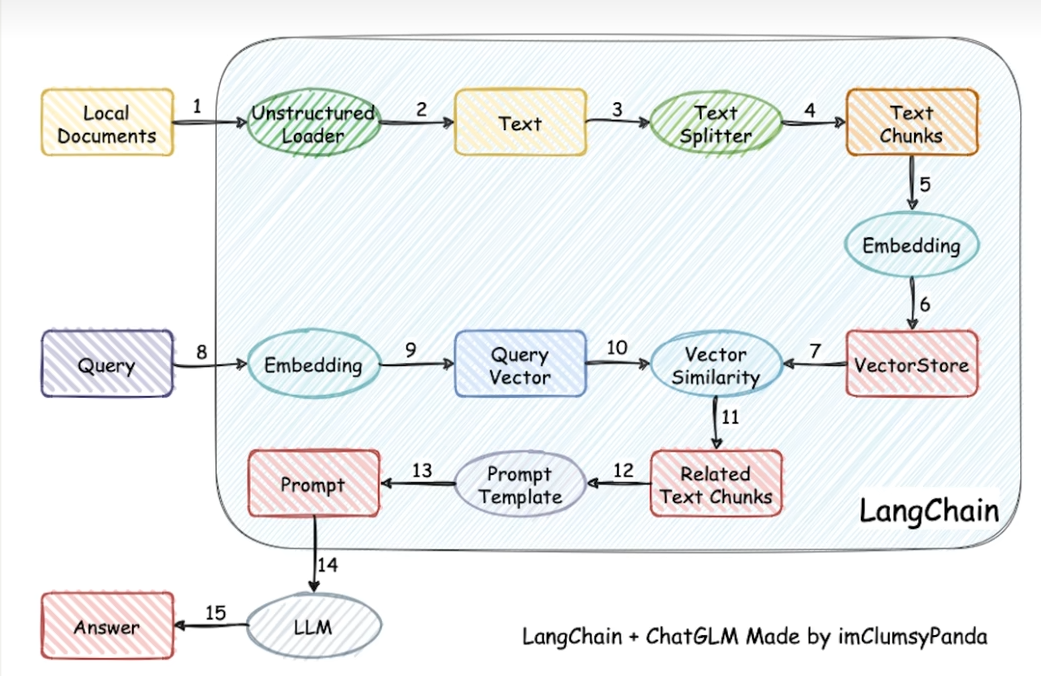
一、作用定位
把 Chunk 文本 → 高维浮点向量。语义相近→向量空间距离近,用于向量库余弦相似度检索 RAG 链路:
分片chunk → EmbeddingModel → 多维向量 → 存入向量库;用户 Query 同样用同一个模型向量化,才能匹配召回。关键:入库、查询必须使用同一个 Embedding 模型,否则向量空间不匹配,召回失效。
二、三大分类:闭源 API 模型 / 开源本地模型 / 多模态 Embedding
1. 商用闭源嵌入(API 调用,省心、效果优)
① OpenAI Embedding(工业最常用)
python
运行
from langchain_openai import OpenAIEmbeddings
embedding = OpenAIEmbeddings(model="text-embedding-3-small")
# 可选:text-embedding-3-large(高精度、向量维度3072)
vec = embedding.embed_query("北京住宿报销标准")
- 优点:泛化强、中英文通用、不用本地部署;缺点:付费、依赖外网。
② 阿里通义 / 百度千帆 / 讯飞 embedding
国产云端嵌入,适配中文,国内企业内网云场景。
2. 开源本地 Embedding(离线私有化首选,无费用、本地 CPU/GPU 运行)
国内 RAG 标配:BGE 系列(BGE-small、BGE-base-zh),中文 SOTA,LangChain 通过HuggingFaceEmbeddings加载。
示例代码
bash
运行
pip install sentence-transformers
python
运行
from langchain_community.embeddings import HuggingFaceEmbeddings
# 中文最优:bge-small-zh-v1.5
model_name = "BAAI/bge-small-zh-v1.5"
embedding = HuggingFaceEmbeddings(model_name=model_name)
# 单个文本向量化
vec = embedding.embed_query("江南春天景色")
# 批量文档向量化(RAG入库用)
doc_vecs = embedding.embed_documents([chunk1,chunk2])
主流开源清单:
- BGE(BAAI):国内 RAG 首选,
bge-small/base/large-zh,中文语义匹配极强; - all-MiniLM:英文轻量化、体积小、速度快;
- m3e:另一款国产轻量化中文嵌入。
3. 多模态 Embedding(图文混合 RAG:PDF 带图片、图表)
如 CLIP、bge-visual,同时编码文字 + 图片,适合图纸、说明书、教材类文档。
三、两个关键 API 接口(LangChain 统一规范)
.embed_query(text:str) → list[float]:用户问题向量化.embed_documents(list[str]) → list[list[float]]:知识库批量分片入库向量化
Retriever 底层自动调用这两个方法做相似度比对。
四、和 RAG 全链路结合完整示例
python
运行
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_core.documents import Document
from langchain_chroma import Chroma
from langchain_community.embeddings import HuggingFaceEmbeddings
# 1.原文
article = """江南的春天,总在绵绵细雨里悄悄降临。清晨推开窗,潮湿的水汽裹挟着草木清香扑面而来。"""
docs = [Document(page_content=article)]
# 2.递归切分
splitter = RecursiveCharacterTextSplitter(chunk_size=150,chunk_overlap=20,separators=["\n\n","\n","。",","])
chunks = splitter.split_documents(docs)
# 3.加载本地BGE嵌入模型
emb = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh-v1.5")
# 4.向量化+存入向量库
db = Chroma.from_documents(chunks,embedding=emb,persist_directory="./emb_db")
ret = db.as_retriever(k=2)
# 5.检索测试
res = ret.invoke("江南春季风景")
五、选型落地标准
- 公有云项目、追求简单高效:OpenAI / 百度千帆 API Embedding
- 企业内网、涉密离线部署、私有化 RAG:BGE 本地开源模型(首选)
- 文档带图纸、图片、扫描件:多模态 Embedding
六、重要避坑点
- 入库和查询不能混用两个不同 Embedding;
- 嵌入维度:small≈384 维、base≈768 维、large≈1024+,维度越大精度越高、存储开销越大;
- 中文文档严禁使用英文专用 embedding (all-MiniLM),召回效果暴跌。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 0
0 0
0- 0



 已为社区贡献234条内容
已为社区贡献234条内容

所有评论(0)