UnityMAS-O:专用于多 agent 工作流训练的 RL 框架
一句话总结
现有 RL 框架(verl、OpenRLHF 等)本质上还是面向具体的策略模型做优化,工作流编排被当作环境搭建的一部分,使得每个多智能体系统都需要手工编排,训练难度较大,不同系统也难以做公平比较。UnityMAS-O 实现了一套真正面向多智能体工作流的训练流程,支持自定义的角色设置、模型拓扑结构,在多种任务和实验设置下都拿到了显著提升(代码任务最高 +169%)
- 论文标题:UnityMAS-O: A General RL Optimization Framework for LLM-Based Multi-Agent Systems
- 论文地址:https://arxiv.org/pdf/2605.26646
- 作者背景:中国人民大学、小红书
- 代码地址:https://github.com/chenyiqun/UnityMAS-O
一、动机
基于 LLM 搭建的多智能体系统成为近来最火热的研发方向之一,它把一个复杂任务拆成 planner、retriever、coder、critic、answerer 等角色,让它们用自然语言和工具互相配合,从而解决复杂的实际问题,扩大 LLM 本身的能力边界
但有一个长期被绕开的短板:大多数系统无法训练。工作流靠 prompt、路由规则、手工设计的交互协议拼出来;真要引入训练,往往也只训其中一个模型或一个角色,整体的交互模式基本是固定的,这极大地压制了系统的整体上限
那为什么不直接拿现成的 RL 后训练框架来训多智能体系统?因为现有框架(TRL、OpenRLHF、slime、verl/HybridFlow)虽然把大规模 rollout、优化、分布式执行都做得很成熟,但它们的组织核心都是单策略优化。多轮交互、工具调用、agentic 行为可以通过定制环境塞进去,但框架的抽象单位始终是 “一个可训练的策略”,而不是 “一张互相交互的逻辑角色图”
作者认为,一个真正通用的多智能体 LLM 优化框架,应该同时表达四样东西:用户定义的工作流图、图里的逻辑角色、从逻辑角色到物理可训练模型的映射、以及定义在结构化多智能体轨迹上的奖励函数。缺了这层抽象,每搭一个多智能体训练管线都变成一次性的定制实现 —— 这导致没法公平比较各类系统性能,也难以跨工作流复用训练设施
UnityMAS-O 的核心目的就是补上这个抽象,它通过扩展 verl 来实现,把后训练的对象从 “单策略” 提升到 “多智能体工作流”
Unity:跨工作流、角色、模型映射、奖励的统一抽象
MAS:多智能体系统
O:优化
二、核心思路与系统设计
2.1设计思路
为了把优化对象改造成一整张多智能体工作流,作者认为需要满足三点设计要求:
首先,要在多智能体轨迹上优化,而不是孤立的输入输出对。真正有用的学习信号可能藏在中间证据、verifier 打分、工具输出、状态更新里,分散在不同角色的不同阶段。所以框架必须记录结构化的执行过程,并在角色和工作流两个层面暴露奖励
其次,要把逻辑角色和物理模型实例解耦,实现不改动训练管线的情况下,能自由切换模型指派与共享逻辑,这是后续做专精模型、协作模式、变量控制、成本权衡等进阶优化的前提
第三,要支持异构分布式执行。一条轨迹里可能调用不同的 LLM、工具和环境,框架要把工作流级别的控制和模型本地的优化分开:不同 worker 组管不同的可训练模型,中央控制器则维护全局轨迹和奖励的一致性
2.2 工作流设计
UnityMAS-O 包括 4 个基本概念:逻辑角色、角色到模型的映射、工作流图、奖励函数
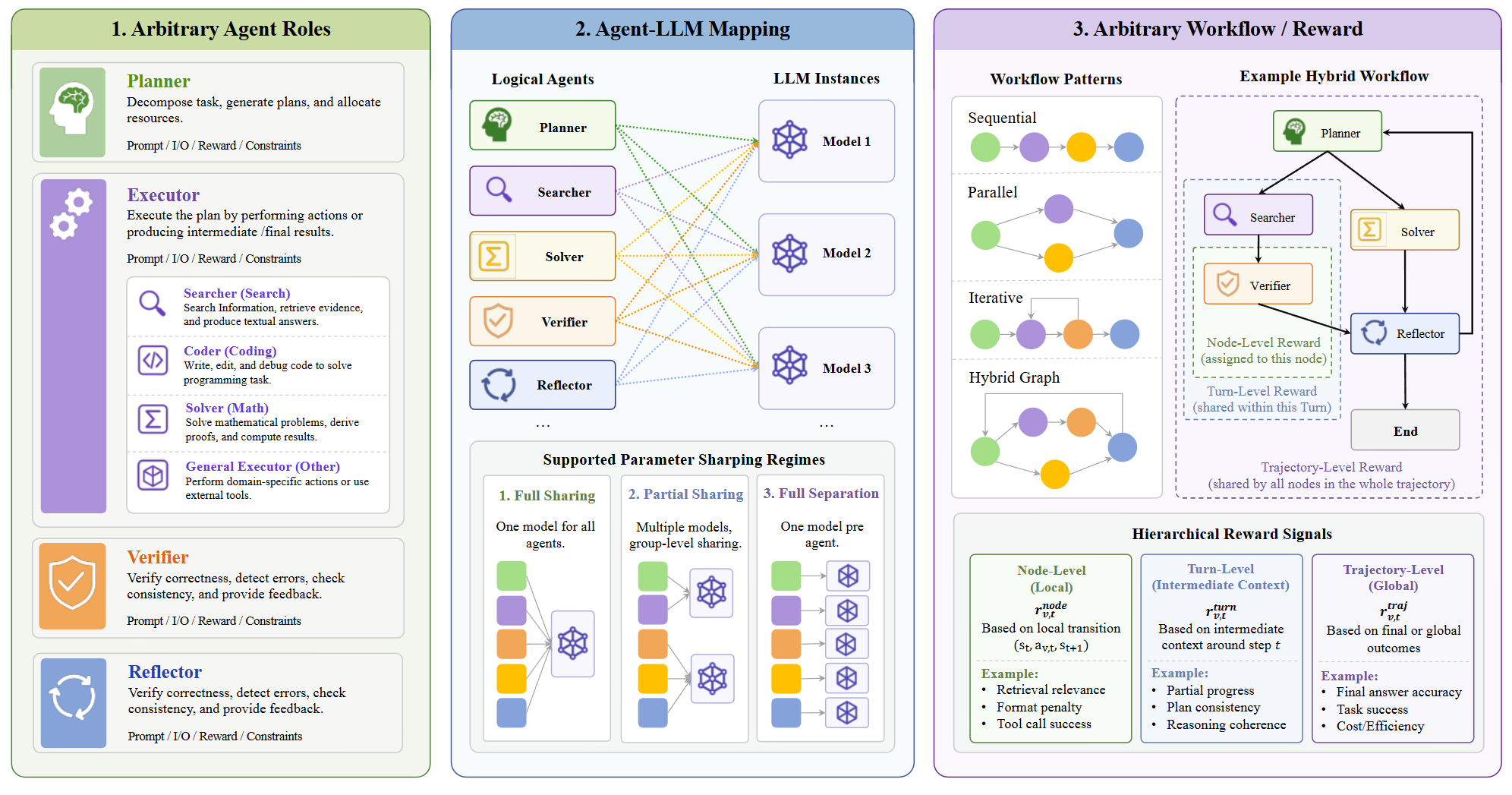
- 逻辑角色
描述某个节点在工作流里负责什么,比如 planner、retriever、extractor、coder、verifier、reflector、answerer 等。关键在于,角色是工作流级别的对象,它规定的是行为和接口,不是一份独有的参数
具体来说,每个角色可以带自己的 prompt 模板、输入输出格式、可用工具、执行约束(比如停止条件或输出格式要求)。这层抽象的好处是:同一个逻辑角色可以由不同的 LLM 来实现,多个角色也可以由同一个 LLM 来实现。框架优化的是角色的行为,而不强制角色和参数
- 角色到模型的映射
把每个逻辑角色指派给一个物理 LLM 实例,映射方案主要包括三类:
- 全共享:所有角色映射到同一个模型,靠各自的角色 prompt、输入输出、工作流位置来区分
- 部分共享:相关的角色分组共享参数,不同组用不同模型
- 全分离:每个角色一个独立模型,专精最强,但显存、算力、优化成本也最高
很多 RAG-MARL 工作也在训多智能体,但它们往往让所有功能角色全共享一个 backbone
- 工作流图
给定角色集合,工作流被表示成一张有向图,边定义了信息、控制、环境状态在角色之间怎么流动。这张图完全由用户定义,可以是顺序流水线、并行分支、迭代循环,混合结构等。下图展示了作者在后续实验中使用的几种不同工作流设置(并行检索、检索-提取-回答、迭代搜索、代码迭代执行)
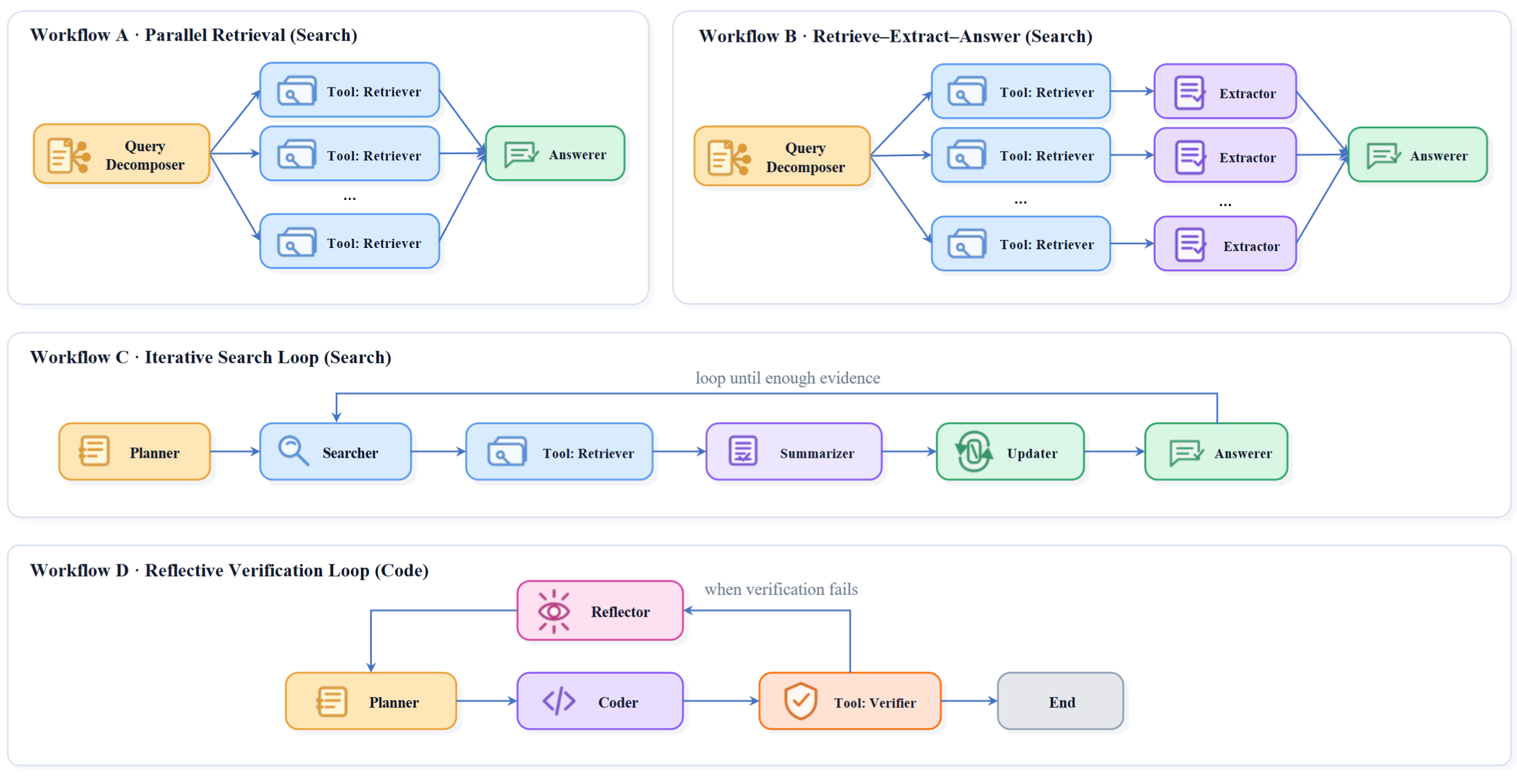
在一个任务实例上执行这张图,就会产生一条结构化轨迹:每一步都有 “当前工作流状态、当前激活的角色、该角色产出”。状态可以包含用户查询、中间推理、检索到的证据、工具输出、半成品答案、verifier 反馈、记忆状态等
- 奖励函数
UnityMAS-O 不强加一个全局奖励函数。每个角色可以根据自己的职责、在工作流里的位置、能拿到的监督信号,定义自己的奖励。这个奖励可以同时用三个层面的信息:
- 节点级:当前这次调用的局部输入输出行为
- 轮次级:当前调用周围的工作流上下文
- 轨迹级:最终或全局的工作流质量
这个接口覆盖了规则式格式奖励、环境奖励、模型式奖励,以及任务指标,也支持把局部和全局监督加权组合,但并不强制用加法形式 —— 稀疏的、稠密的、延迟的、非加性的、任务特定的归因规则都可以写。每个奖励都能被提交到最终执行的物理模型上,框架帮你做好信用分配
三、系统实现
3.1 系统概览
UnityMAS-O 设计了一套星型拓扑的 runtime 框架来实现工作流图运行和物理 LLM 更新:
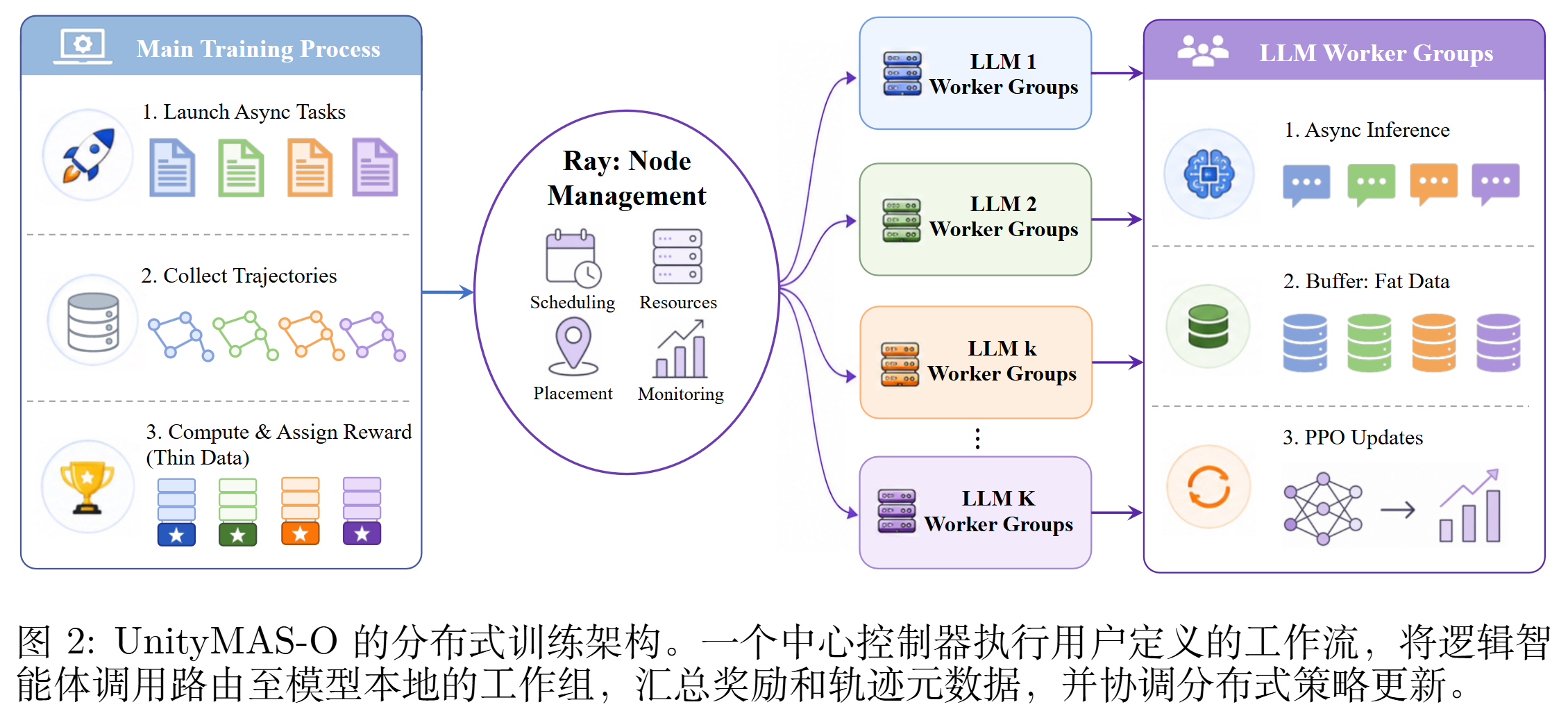
- 中央控制器:维护全局训练循环,调度激活的工作流状态,评估停止条件,调用工具或环境,组装奖励,协调更新
- Ray 执行层:提供远程调用、worker 生命周期管理、跨机器的 GPU 放置
- LLM worker 组:每个 worker 组绑定一个物理 LLM 实例,处理路由到该模型的所有角色调用
关键设计原则:工作流的控制数据与模型的训练数据要分开
控制器只需要轻量信息 —— 角色身份、路由标识、生成的输出、工作流状态、奖励元数据。而生成时产生的重型张量(token 对数概率、注意力掩码、价值估计、rollout 元数据)全部留在产生它们的 worker 组本地
3.2 训练流程
- 任务进入控制器: 控制器查工作流图,识别出第一个激活的角色,比如 “query 拆解”,按映射把它路由到对应的 worker 组
- 工作组本地生成: worker 组的 LLM 执行 agent 角色的具体任务,比如把拆分后的子 query 回传给控制器。这一过程中的 token 概率、注意力掩码、价值估计等重型张量缓存在本地
- 推进工作流: 控制器拿着 worker 返回的中间结果,更新工作流状态并推进后续任务,直到工作流图中的所有任务做完
- 奖励组装与回传: 计算最终奖励(比如最终结果的 F1),按用户定义的归因规则把奖励回传给沿途所有角色,提交到对应 worker 组的缓存中
- 工作组更新: 当缓存区样本量累积到某个阈值后,各工作组独立地把本地张量打包成 ready batch,对齐延迟奖励、计算优势、做 PPO 更新,再把新权重同步回框架的 rollout 后端(如 vLLM),保证下一道题进来时,工作流能用上新参数
整条链路中控制器只搬动 “角色—路由—奖励” 这些轻量的元数据,重型张量始终就近停在产生它们的工作组里,这是它能在保持工作流一致性和支撑大规模分布式训练的关键
工作流 C 和 D 的奖励设计是理解这篇论文价值的关键:它们都不是简单的"最后答对给分"。C 把全局 F1 拆成逐轮增量,D 把代码质量拆成逐轮 delta。能把这种延迟、增量、角色异构的奖励干净地表达出来,正是"角色级奖励接口"这个抽象存在的意义。
四、实验结果
4.1 实验设置
在检索和代码两类可验证任务上评估,评测指标分别是答案 F1、测试集的全过率;可训练角色用 Qwen3 系列 backbone;与如 2.2 的架构图所示,作者测试了 4 种工作流:
- 并行检索: 把问题拆成检索子 query,并行收集证据后再生成答案。每个可训练角色都受自己的格式惩罚约束,并共享同一个最终答案 F1,即 “局部管格式,全局管答对”
- 检索-提取-回答: 在并行检索的基础上增加「证据抽取」角色,奖励规则同上
- 迭代搜索: 「planner」构建初始知识状态和回答,其奖励为初始答案的质量;后续进入「搜索-更新-回答」的循环,每轮回答的质量作为「回答器」的奖励;其他角色「searcher」、「summarizer」、「updater」共享答案的边际提升奖励(即做完这轮循环后,答案 F1 相比上一轮提升多少)
- 迭代编码: 第一轮中 「planner」 和 「coder」 按初版代码的测试通过率拿分;之后每一轮的 「reflector + planner + coder」 只按本轮通过率减去上一轮通过率拿分
4.2 QA 与 agentic 搜索任务
下图展示了在问答与搜索数据集上,利用 UnityMAS-O 框架做 RL 前后的 F1 分数变化情况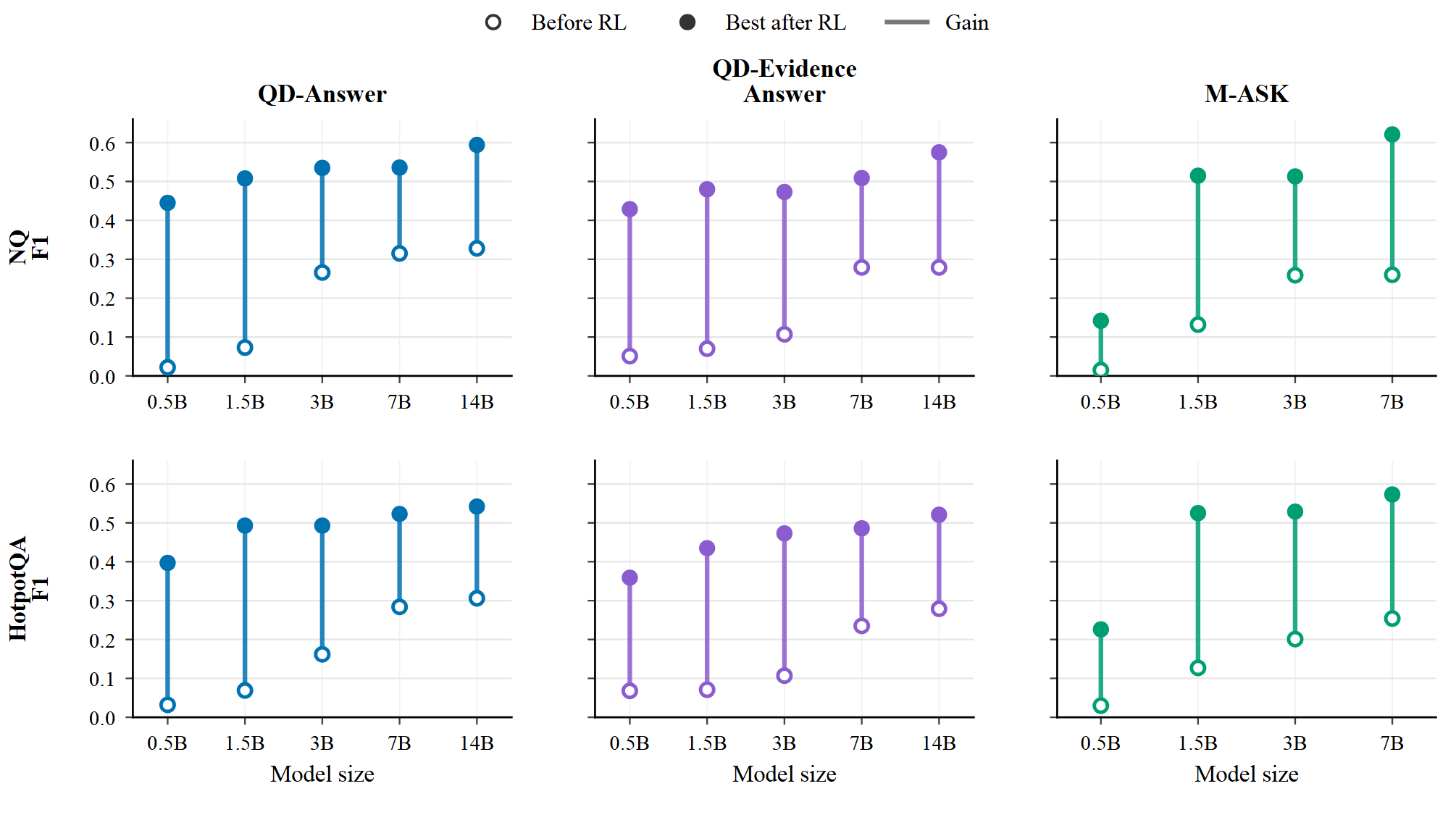
可见所有 QA 工作流、所有模型规模训练后都提升了,哪怕它们的角色结构和通信路径各不相同
小模型的增益尤其夸张,因为未训练的多智能体工作流常常一开始就接近失败。比如 QD-Retrieve-Answer 在 NQ 上用 0.5B 智能体从 0.022 涨到 0.445,HotpotQA 上从 0.032 涨到 0.397。这说明 MARL 不是从一个本来就很能干的策略里挑了个更好的 checkpoint,而是真的帮角色专精的智能体学会了满足工作流协议、保留承载答案的证据、朝最终答案质量协作
4.3 代码任务
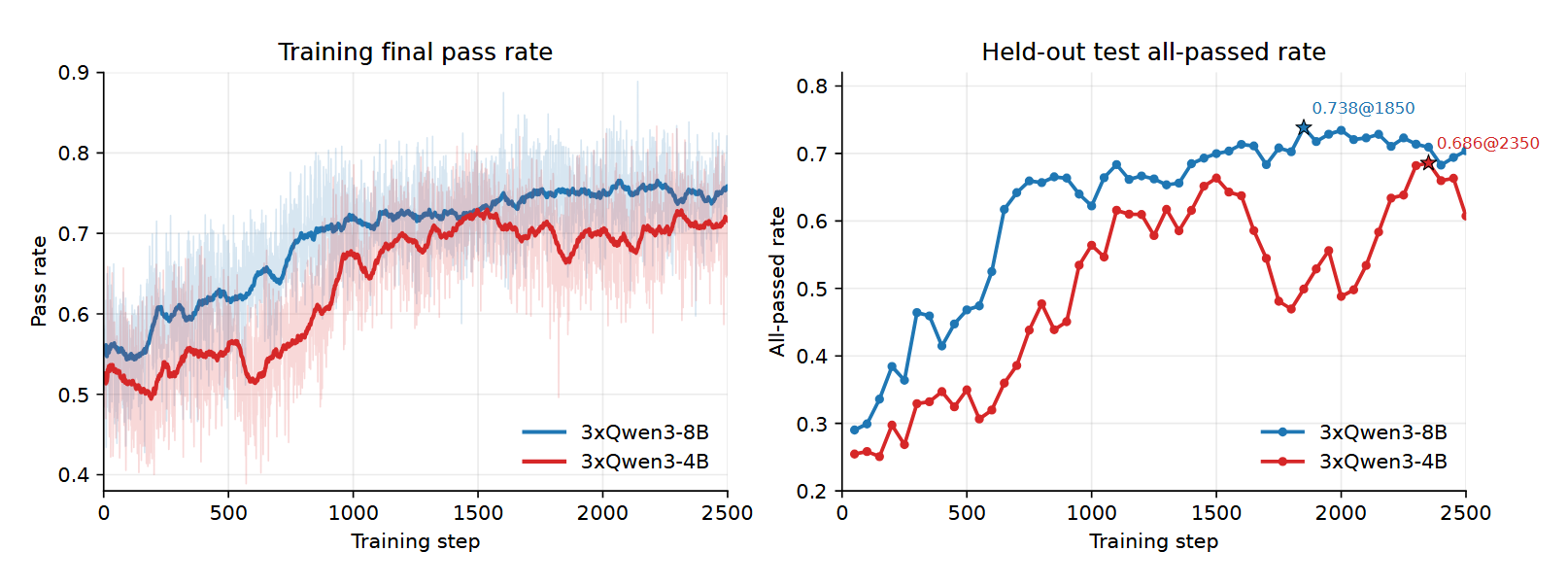
代码任务训练前后的测试集全过率变化如下所示:
训练过程:
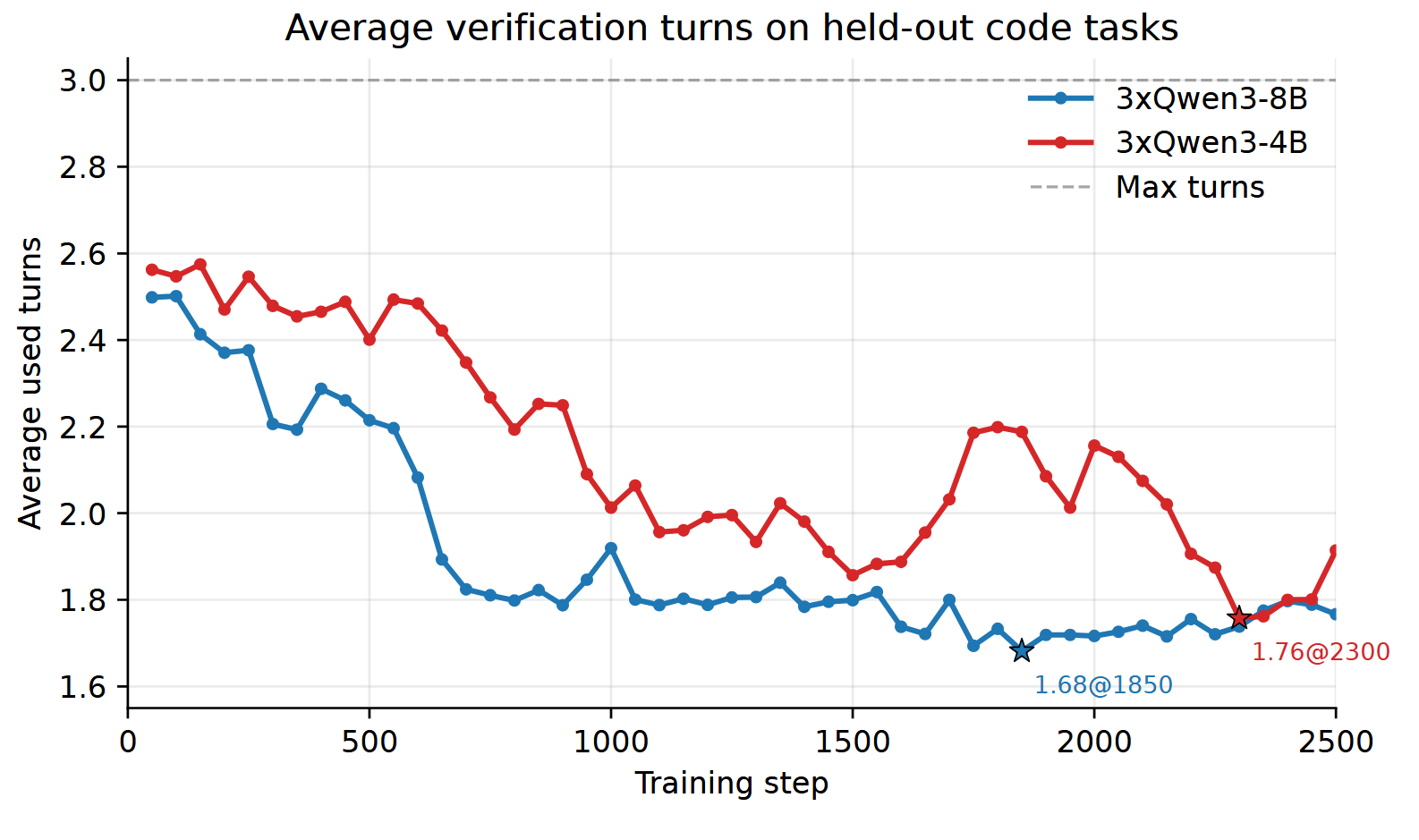
平均验证轮次变化情况如下,说明训练不仅逐步提高了代码准确率,还提高了工作效率:
4.4 参数共享
为了验证框架最大亮点 —— 角色-模型解耦设计的有效性,作者在 HotpotQA M-ASK 上对比了「所有角色共享一个 3B 模型」和 「4 个角色都使用独立模型」两种设置的训练效果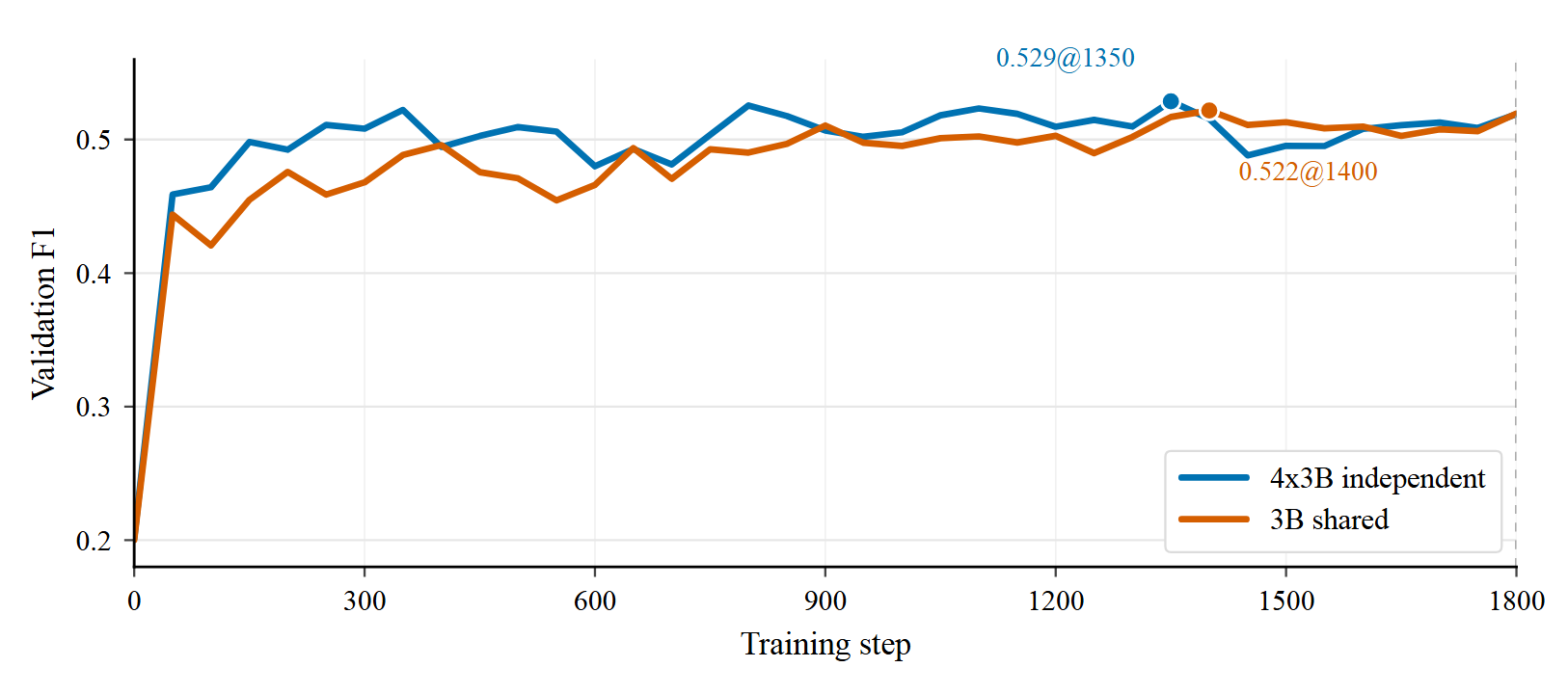
如上图所示,两者起点几乎相同,全独立设置爬升略快,但最终水平相近。这说明多角色共享物理模型参数时,UnityMAS-O 仍然训得动,实践中可以利用这点来减少模型组数量
4.5 其他实验
作者提到还在尝试使用 UnityMAS-O 对其他领域,包括具身智能(ALFWorld)、网络交互(WebShop)、软件工程任务(SWE-bench)进行多智能体强化学习实验,但目前尚未完成

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)