ActionParser 微调模型收尾整理与可部署模型交付
在前期开发过程中,我围绕 StoryVerse 项目的 ActionParser 模块完成了从环境搭建、数据准备、半自动标注、数据集划分、模型基线评测、warmup 训练、中文任务微调到后端调用链路设计的一系列工作。经过前面几个阶段的推进,ActionParser 已经不再只是一个实验性质的模型任务,而是逐步形成了完整的数据、训练、评估和服务化接入流程。
本次工作重点,是对 ActionParser 微调模型进行最终交付整理。相比前面阶段的训练和调参,本阶段更偏向工程收尾:需要确认模型以什么形式交付、后端如何加载、是否还依赖 LoRA Adapter、最终目录是否完整、评估指标是否达标,以及这个模型是否已经满足项目部署和后续联调要求。因此,这一阶段的核心目标不是继续训练新模型,而是将已经完成的微调成果整理成一个稳定、独立、可直接加载的最终模型版本。
一、前期工作基础:从数据构建到 LoRA 微调
在进入最终模型交付之前,ActionParser 模块已经完成了较为完整的前期工作。最开始,我基于 StoryVerse 的小说交互场景,明确了 ActionParser 的任务目标:将用户输入的自然语言动作解析为统一的结构化 JSON,包括动作类型、执行者、目标对象、动作内容、是否需要拆分以及子动作等信息。
围绕这个目标,我先后处理了 Hermes、SGD 和中文小说标注数据。Hermes 数据主要用于帮助模型保持基础指令理解和格式输出能力,SGD 数据更偏向结构化意图与槽位映射,而中文小说数据则直接服务于 StoryVerse 的核心场景,是最终提升模型小说动作解析能力的关键数据。为了得到高质量中文数据,我还设计并使用半自动标注流程,对小说样本进行清洗、筛选、人工修正和结构化整理,最终形成可用于微调和测试的中文 ActionParser 数据集。
在训练方案上,本项目采用 LoRA 微调方式。这样做的好处是可以在不直接修改 base 模型主体参数的情况下,通过少量可训练参数完成任务适配。也就是说,微调阶段首先保持 base 模型参数不变,只训练并保存任务相关的参数增量,也就是 LoRA Adapter。这样既降低了训练成本,也便于保留原始模型能力,同时能够针对 ActionParser 任务进行定向增强。

二、为什么需要最终合并模型目录
在 LoRA 微调完成后,训练阶段通常会得到一个独立的 LoRA Adapter,而不是一个完整的 Hugging Face 模型目录。这个 Adapter 本质上只保存了微调过程中学习到的参数增量,不能完全等同于一个可以直接部署的完整模型。
如果后续部署时仍然采用“base 模型 + LoRA Adapter”的加载方式,虽然技术上可行,但会带来一些额外复杂度。首先,后端加载时必须同时指定 base 模型路径和 adapter 路径,容易出现路径配置错误。其次,团队其他成员在调用模型时需要理解 LoRA 加载流程,增加了交接成本。再次,如果部署环境中 adapter 和 base 模型版本没有严格对应,就可能出现加载失败或推理结果不一致的问题。
因此,本次核心任务就是将 base 模型和 LoRA Adapter 合并,生成一个完整的、独立的、与 Hugging Face 原始模型目录格式一致的模型目录。这样后续无论是评估脚本、FastAPI 后端,还是项目展示中的推理脚本,都可以直接通过标准方式加载模型,而不需要额外处理 LoRA 参数。
这一步实际上是从“训练产物”到“交付模型”的关键转换。训练过程中保存 Adapter 是为了提高训练效率,而项目交付时生成完整模型目录,则是为了降低部署复杂度、提高可复现性和交接清晰度。
三、使用 PEFT 完成模型合并:从 LoRA Adapter 到完整 HF 模型
我根据项目初始部署要求,对 LoRA 微调结果进行了最终合并处理。具体来说,微调阶段保持 base 模型参数不变,LoRA 只保存参数增量;在交付阶段,我使用 PEFT 提供的 merge_and_unload() 方法,将 base 模型与 LoRA Adapter 进行合并。
merge_and_unload() 的作用是把 LoRA 学到的增量权重合并回 base 模型权重中,并卸载 LoRA 结构。合并完成后,模型不再依赖外部 Adapter,而是成为一个完整的普通因果语言模型。这样生成的目录结构与 Hugging Face 原始模型目录保持一致,可以直接通过 AutoTokenizer.from_pretrained() 和 AutoModelForCausalLM.from_pretrained() 加载。
最终生成的交付模型目录为:
/root/storyverse/deliverables/actionparser_zh_best_hf
这个路径是本次收尾阶段最重要的交付结果。相比训练过程中的 checkpoint 或 adapter 目录,它代表的是最终可部署、可加载、可验证的完整模型版本。后续只要使用这个目录,就可以直接进行 ActionParser 推理,不需要再额外指定 base 模型路径,也不需要额外加载 LoRA 参数。
四、最终模型目录验证:确认能够标准加载
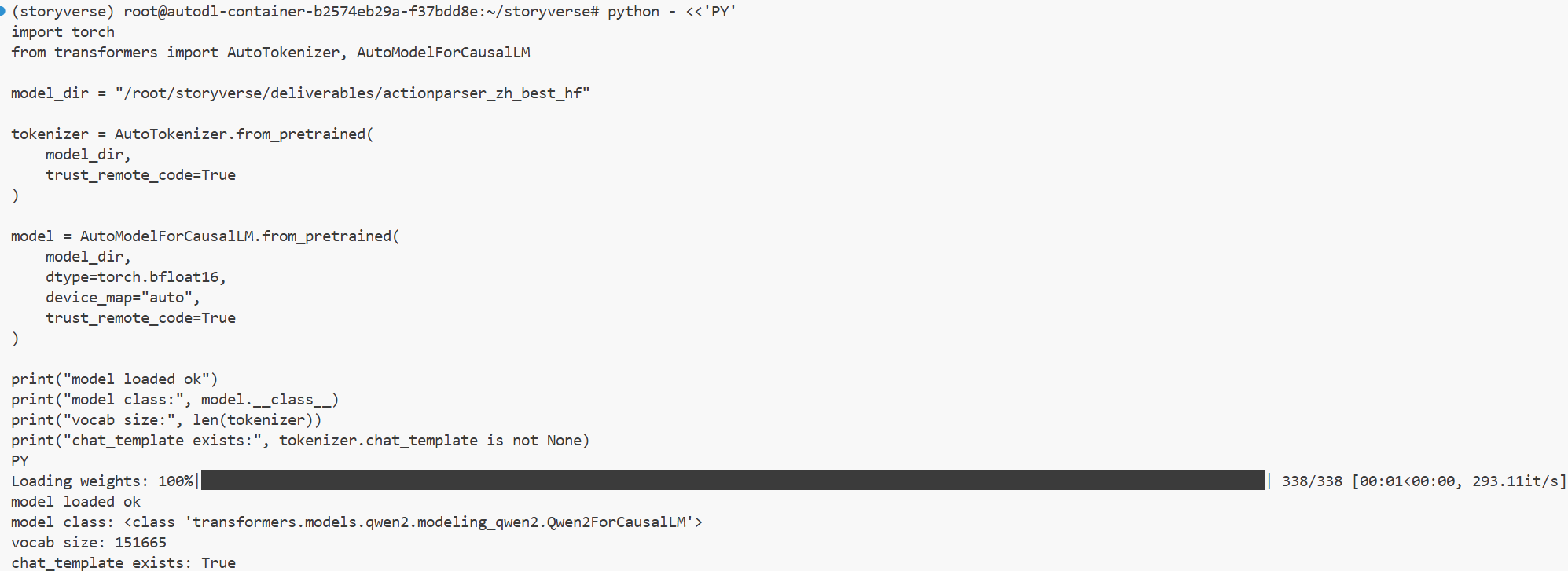
模型合并完成后,我没有直接将其视为交付完成,而是继续进行了模型目录验证。因为最终交付模型必须满足一个基本要求:它不仅要存在于指定目录中,还必须能够被标准 Hugging Face 加载接口正常读取。
因此,我对 /root/storyverse/deliverables/actionparser_zh_best_hf 进行了加载测试,确认它可以直接通过以下方式加载:
AutoTokenizer.from_pretrained()AutoModelForCausalLM.from_pretrained()
这一步验证非常重要。它说明当前模型目录已经具备完整 Hugging Face 模型目录所需的结构,包括 tokenizer 文件、模型配置文件、权重文件以及相关生成配置。更重要的是,它证明该模型已经摆脱了对 LoRA Adapter 的额外依赖,后续后端部署或团队成员复现时不需要再额外理解 LoRA 合并逻辑。
从工程交付角度看,这一步相当于确认模型已经从“训练环境可用”转变为“部署环境可用”。如果没有这一步验证,后续 FastAPI 后端在启动服务时可能会因为模型目录不完整、tokenizer 不匹配或权重文件缺失而报错。通过今天晚上的验证,可以提前排除这些风险。

五、最终测试结果:模型达到部署与交付要求
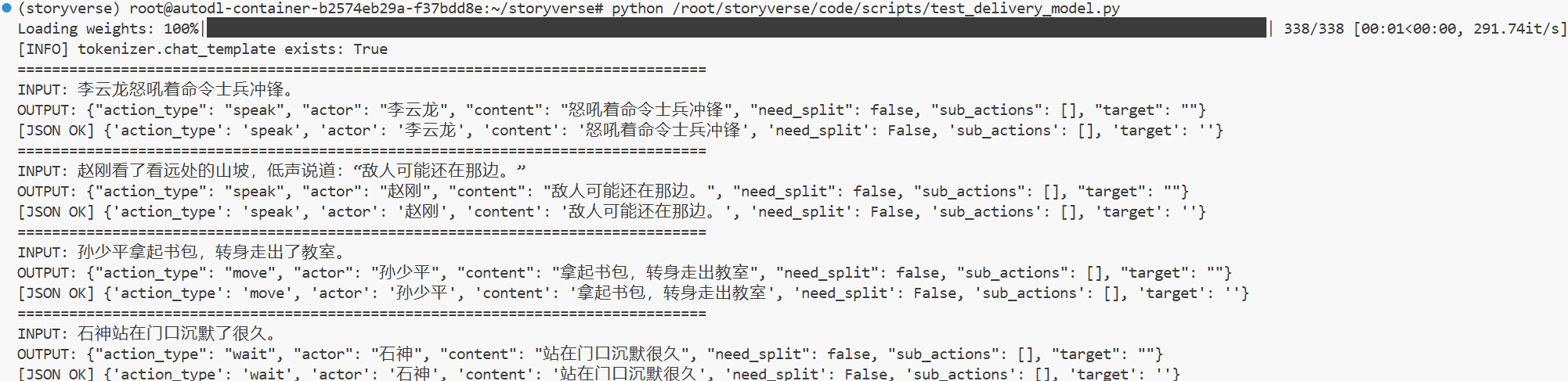
在确认模型可以标准加载之后,我进一步对最终模型进行了测试评估。本次测试使用的是 99 条中文小说 ActionParser 测试集,用于检验模型在项目核心任务上的实际表现。评估重点包括 JSON 合法率、动作类型准确率、actor 字段准确率、target 字段准确率以及 content 字段 ROUGE-L F1。
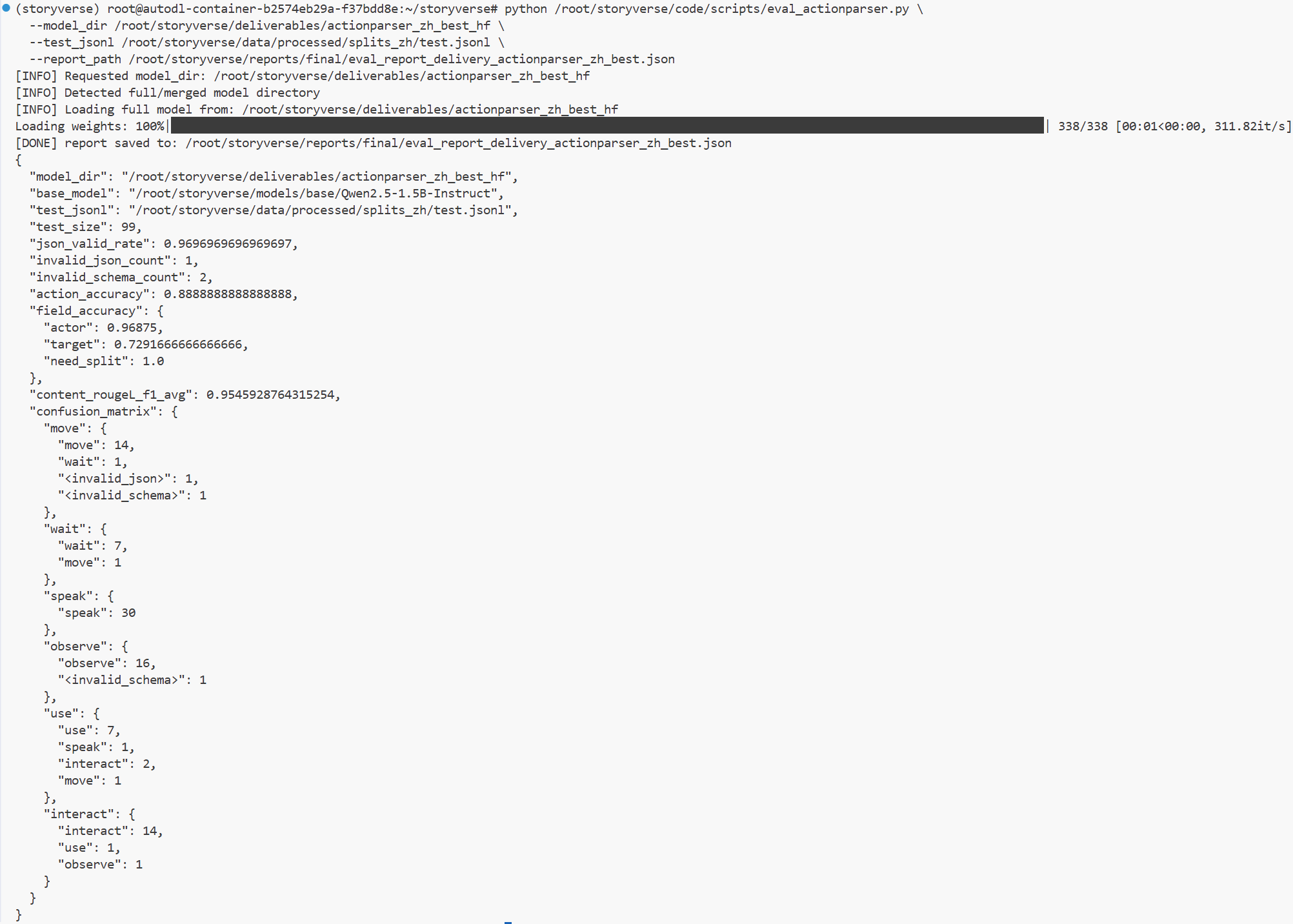
最终测试结果如下:模型 JSON 合法率达到 96.97%,说明模型在绝大多数测试样本上都能够输出符合要求的合法 JSON 结构。对于 ActionParser 任务来说,这是非常关键的指标,因为后端服务必须能够解析模型输出,并将其传递给后续世界状态更新和角色响应模块。如果 JSON 输出不稳定,模型即使语义上理解正确,也很难真正接入系统。
动作类型准确率达到 88.89%,说明模型已经能够较稳定地区分 StoryVerse 中预设的动作类别,例如说话、移动、观察、交互、使用和等待等。这个结果表明,中文微调确实让模型学习到了小说动作解析任务中的核心分类边界。
actor 字段准确率达到 96.88%,说明模型对动作执行者的识别非常稳定。对于多角色小说交互系统来说,明确“谁在执行动作”是后续剧情推进的基础,因此 actor 字段表现较高,说明当前模型在动作主体识别方面已经具备较好的可靠性。
target 字段准确率达到 72.92%,相对其他指标低一些,但已经具备基本可用性。target 字段本身是 ActionParser 中较难的部分,因为小说文本中的目标对象经常会省略、使用代词指代,或者依赖上下文才能判断。例如“他看了过去”“她伸手接住”“我走到门边”这类表达中,动作目标并不总是以明确实体形式出现。因此,当前 target 指标虽然还有提升空间,但整体符合该字段的任务难度。
content 字段 ROUGE-L F1 达到 95.46%,说明模型对动作内容的概括与人工标注结果高度接近。这个指标反映出模型不仅能够输出正确格式,还能够较准确地保留输入文本中的核心动作语义。
综合来看,最终模型已经满足项目部署和交付要求。它在结构合法性、动作分类、执行者识别和动作内容生成方面表现较好,可以作为 StoryVerse 后续 FastAPI 后端调用和系统联调的基础模型。
六、微调与合并前后工作的意义
从整个 ActionParser 模块的开发过程来看,今天晚上的工作并不是简单地“保存一下模型”,而是完成了模型交付前最后一段非常关键的工程闭环。
在训练阶段,LoRA Adapter 的存在是合理的,因为它可以减少训练成本,提高实验迭代效率。但在交付阶段,如果仍然要求后端同时加载 base 模型和 adapter,就会增加部署复杂度。通过 merge_and_unload() 合并后,最终模型变成了一个标准 Hugging Face 模型目录,后端只需要面对一个单独路径即可完成加载。这不仅降低了系统部署门槛,也减少了团队协作中的理解成本。
同时,最终模型目录被固定在 /root/storyverse/final_delivery/actionparser_zh_best_hf,也使项目成果更加清晰。这个目录可以被视为本阶段 ActionParser 微调工作的最终交付物。它既包含前期数据构建和微调训练的结果,也经过了加载验证和测试集评估,因此具备明确的可用性证明。
更重要的是,本次交付整理让模型结果与后端开发形成了稳定衔接。前期我已经围绕 FastAPI 后端、ActionParser 调用链路以及 build_role_task_instruction 函数进行了设计。现在模型侧已经提供了标准可加载目录,后端就可以直接围绕该目录进行模型服务封装,而不需要再处理训练阶段的复杂权重结构。
七、当前仍存在的问题与后续优化方向
虽然当前模型已经满足项目部署和交付要求,但从进一步优化角度看,仍然存在一些可以继续提升的部分。
首先,target 字段仍然是当前模型最明显的薄弱项。后续如果继续提升 ActionParser 的精度,可以重点围绕目标对象识别补充训练数据,尤其是目标对象省略、代词指代、环境物体交互和多人互动场景。通过增加这些样本,可以让模型更好地区分动作执行者和动作作用对象。
其次,当前测试集规模为 99 条,能够验证模型的基本能力,但对于真实交互中更加自由、多样的用户输入来说,仍然需要继续扩展测试样本。尤其是复合动作输入,例如“我走到桌边,拿起信封,然后问他这是什么”,需要模型同时判断是否拆分、如何组织子动作以及如何保持动作顺序。这部分能力在后续系统联调中还需要继续观察。
再次,虽然最终模型可以稳定输出合法 JSON,但在真实后端环境中仍然应保留必要的 JSON 校验和异常处理逻辑。因为大语言模型输出具有一定随机性,后端不能完全依赖模型本身保证 100% 合法。当前 96.97% 的 JSON 合法率已经较高,但剩余少量异常情况仍需要工程兜底。
八、下一步工作计划
完成最终模型合并和验证后,下一步工作将主要围绕部署接入和系统联调展开。首先,需要将 FastAPI 后端中的 ActionParser 模型路径统一配置为:
/root/storyverse/final_delivery/actionparser_zh_best_hf
后端可以直接通过 Hugging Face 标准加载方式读取模型,不再需要额外加载 LoRA Adapter。这样可以简化后端启动流程,也方便后续项目展示时快速复现。
其次,需要继续测试模型在真实用户输入场景下的表现。离线测试集能够说明模型在标准样本上的能力,但真实系统中用户输入可能更加口语化、复合化和上下文依赖。因此,后续需要结合前端或接口测试,收集模型在真实调用中的错误样例,再进一步判断是否需要补充数据或优化 prompt。
最后,需要将本次最终交付模型目录、加载验证截图、测试指标截图和预测样例整理到项目文档中,作为 ActionParser 微调工作的最终成果证明。这不仅能够展示模型训练的最终效果,也能说明本项目已经完成了从数据处理、LoRA 微调、模型合并到验证交付的完整流程。
九、本阶段总结
本次工作完成了 ActionParser 微调模型的最终交付整理。按照项目部署要求,LoRA 微调阶段首先保持 base 模型参数不变,只保存参数增量为独立 LoRA Adapter;随后使用 PEFT 的 merge_and_unload() 方法将 base 模型与 LoRA Adapter 合并,生成与 Hugging Face 原始模型目录格式一致的完整模型目录。
最终交付模型目录为:
/root/storyverse/final_delivery/actionparser_zh_best_hf
该模型可以直接通过 AutoTokenizer.from_pretrained() 和 AutoModelForCausalLM.from_pretrained() 加载,无需额外加载 LoRA 参数。经过最终测试,在 99 条中文小说 ActionParser 测试集上,模型 JSON 合法率达到 96.97%,动作类型准确率达到 88.89%,actor 字段准确率达到 96.88%,target 字段准确率达到 72.92%,content 字段 ROUGE-L F1 达到 95.46%。
这说明当前模型已经完成从训练产物到可部署交付物的转换,满足项目部署和交付要求。至此,我负责的 ActionParser 微调工作完成了最终收尾,为 StoryVerse 后续 FastAPI 后端接入、系统联调和项目展示提供了稳定可靠的模型基础。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 13
13 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)