Top-K/Top-P等大模型解码采样算法原理与实战
·
目录
🎂3.Top-P(Nucleus核采样)——动态累积概率截断采样
✅1.前言
在大语言模型(LLM)自回归文本生成链路中,解码采样算法是决定模型输出多样性、流畅度、事实准确率的核心模块。传统贪心解码、束搜索(Beam Search)属于确定性解码,输出固定、多样性匮乏;而随机采样族(Top-K、Top-P)通过概率随机抽取Token,是对话、创意写作、开放式生成任务的主流方案。
✨2.Top-K采样——固定候选集截断随机采样
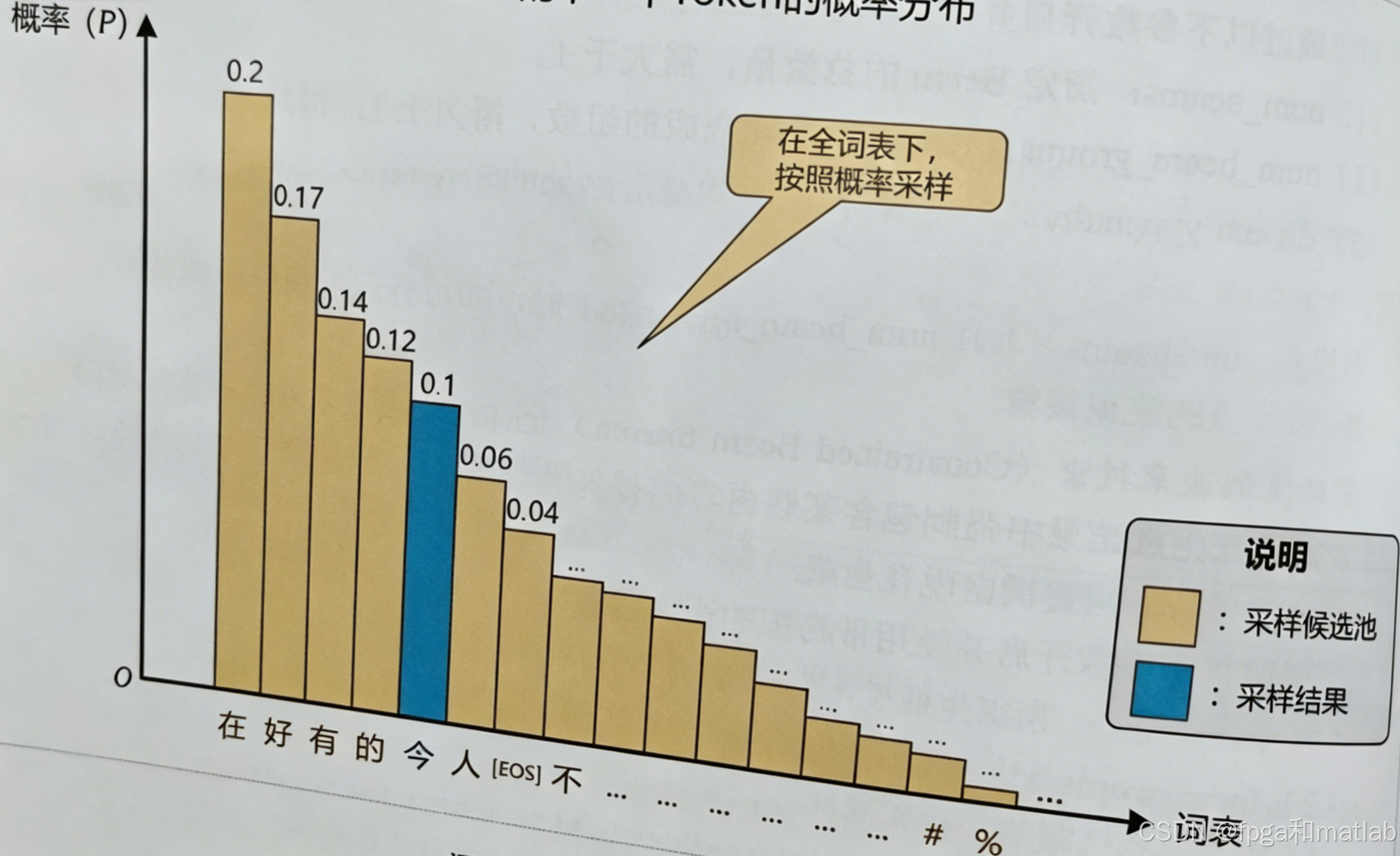
Top-K核心:固定保留全局概率最高前K个Token,剔除剩余所有低概率候选,在截断子集内重新归一化后多项式采样。

![]()
固定K带来缺陷:词表头部概率分布疏密随模型输出动态变化,固定K在头部概率极度集中时仍保留多余候选、头部稀疏时候选不足,是Top-P诞生的动因。其示意图如下图所示:
Python代码实现:
def top_k_sampling(prob, k):
# 步骤1:保留前k大元素下标
topk_idx = np.argsort(prob)[-k:]
mask = np.zeros_like(prob)
mask[topk_idx]=1.0
# 步骤2:掩码筛选+归一化
p_trunc = prob * mask
p_norm = p_trunc / np.sum(p_trunc)
# 步骤3:多项式采样
sample_idx = np.random.multinomial(1,p_norm).argmax()
return sample_idx, p_norm, mask
K=5
sample_k_idx,pk_norm,mask_k = top_k_sampling(p_raw,K)
# 绘图
plt.figure(figsize=(12,5))
bar_list = plt.bar(vocab,p_raw,color="#ffd270",label="全词表")
# 灰色:被剔除token,蓝色:采样结果
for i in range(len(vocab)):
if mask_k[i]==0:
bar_list[i].set_color("#bbbbbb")
bar_list[sample_k_idx].set_color("#3388dd")
plt.title(f"Top-K采样(K={K}),黄色=保留候选,灰色=剔除,蓝色=采样结果",fontsize=13)
plt.ylabel("原始概率P")
plt.legend()
plt.savefig("./topk_sample.png",dpi=300)
plt.show()
print(f"Top-K采样选中Token:{vocab[sample_k_idx]}")关键参数:top_k=5,do_sample=True。
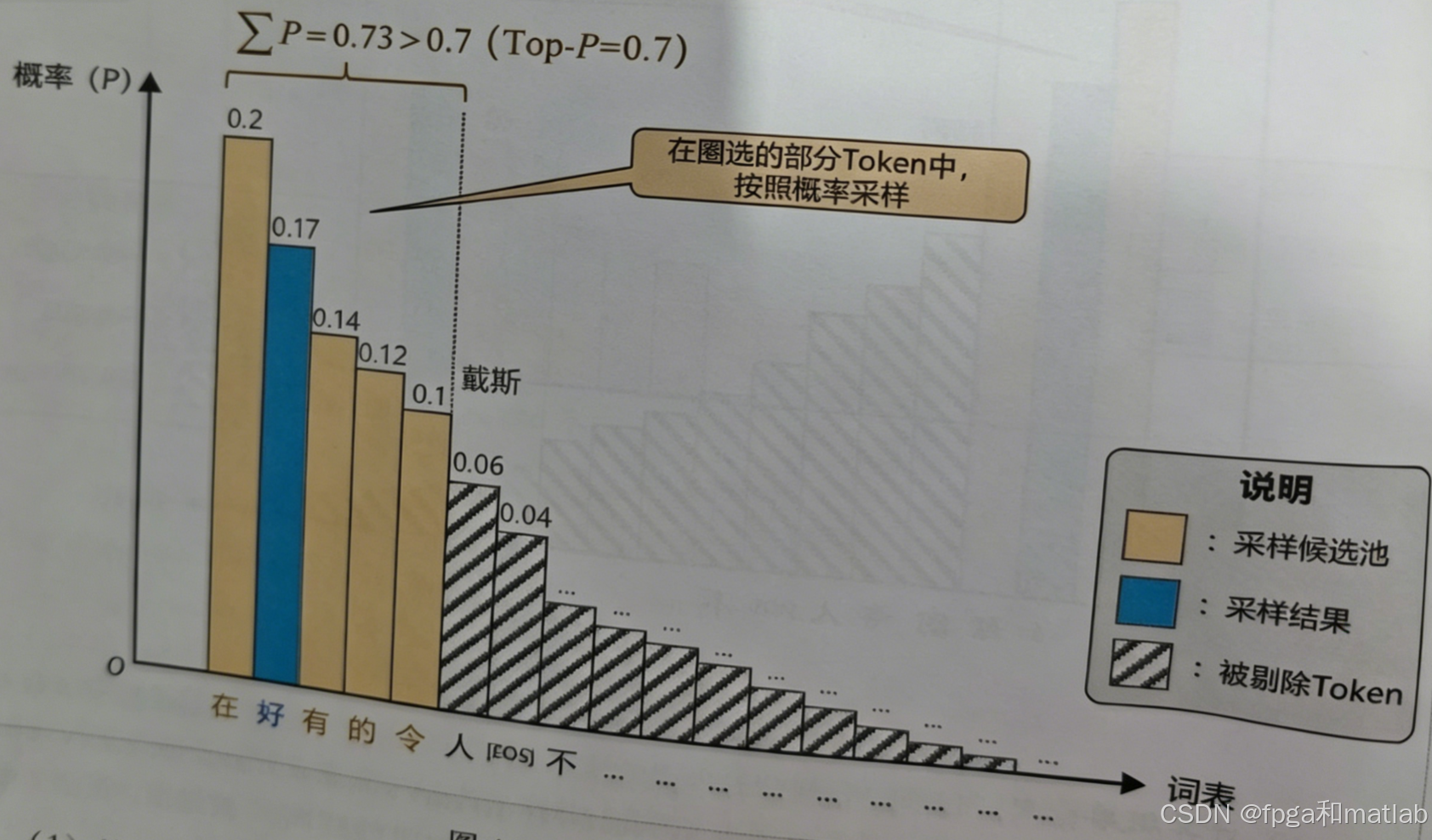
🎂3.Top-P(Nucleus核采样)——动态累积概率截断采样
Top-P摒弃固定K,动态从降序概率头部累加,直到累积概率≥设定阈值P,以此动态确定候选集合SP。
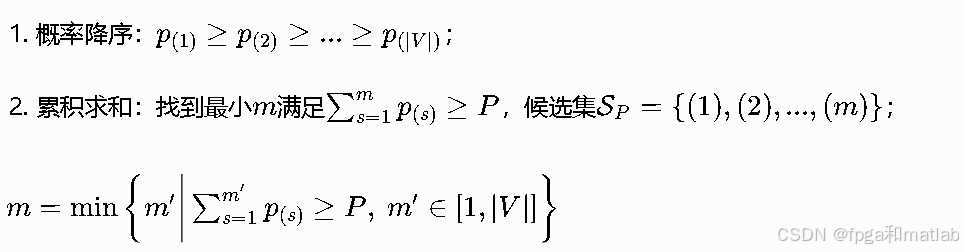
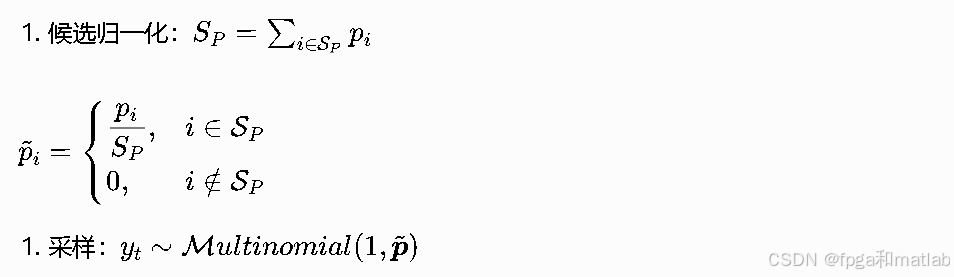
对比Top-K数学优势:候选数量m随概率分布自适应变化,高概率集中时m变小、稀疏时m自动变大,解决固定K的静态缺陷。其示意图如下图所示:
Python代码实现:
def top_p_sampling(prob,p_threshold):
# 1. 降序排序下标
sorted_idx = np.argsort(prob)[::-1]
sorted_p = prob[sorted_idx]
# 2. 累积概率
cum_p = np.cumsum(sorted_p)
# 3. 找到满足累积>=P的最小m
m = np.where(cum_p >= p_threshold)[0][0]+1
keep_idx = sorted_idx[:m]
mask = np.zeros_like(prob)
mask[keep_idx]=1.0
# 4.归一化+采样
p_trunc = prob*mask
p_norm = p_trunc / np.sum(p_trunc)
sample_idx = np.random.multinomial(1,p_norm).argmax()
return sample_idx,p_norm,mask,m
P=0.7
sample_p_idx,pp_norm,mask_p,m_val = top_p_sampling(p_raw,P)
# 绘图
plt.figure(figsize=(12,5))
bar_p = plt.bar(vocab,p_raw,color="#ffd270")
for i in range(len(vocab)):
if mask_p[i]==0:
bar_p[i].set_color("#888888",hatch="///") #斜线填充=被剔除
bar_p[sample_p_idx].set_color("#3388dd")
plt.title(f"Top-P采样(P={P},动态保留{m_val}个Token),斜线填充=剔除候选",fontsize=13)
plt.ylabel("原始概率P")
plt.savefig("./topp_sample.png",dpi=300)
plt.show()
print(f"Top-P动态保留候选数{m_val},采样结果:{vocab[sample_p_idx]}")与Top-K固定数量的区别,对应生成参数:top_p=0.7, do_sample=True。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 5
5 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)