2026第八届中青杯全国大学生数学建模竞赛A题:数学建模论文智能评估系统与多智能体优化方法完整思路、代码、模型、文章,全网首发高质量分享!
2026第八届中青杯全国大学生数学建模竞赛A题:数学建模论文智能评估系统与多智能体优化方法完整思路、代码、模型、文章,全网首发高质量分享!
赛题全文
— 1 —
2026 年第八届中青杯全国大学生数学建模竞赛题目
(请先阅读“中青杯全国大学生数学建模竞赛参赛细则”)
A 题数学建模论文智能评估系统与多智能体优化方法
《新一代人工智能发展规划》明确提出推动智能教育创新发展,利用人工智能技
术改进教育评价体系。在高等教育领域,数学建模竞赛作为培养学生创新能力和实践
能力的重要载体,每年吸引数十万学生参与。随着大语言模型、智能写作工具等技术
的快速发展,参赛者广泛借助AI 辅助完成论文撰写,这对传统的人工评审模式提出
了新的挑战。
数学建模论文具有结构标准化、逻辑严密性、符号规范性等特殊要求,其质量评
估涉及多维度、多层次的复杂判断。如何利用自然语言处理、知识图谱、强化学习等
技术,构建能够自动识别论文逻辑缺陷、评估建模质量、提供优化建议的智能系统,
已成为教育评价领域的重要研究方向。请建立数学模型,解决以下问题:
问题1:附件1 是2025 年中青杯竞赛的30 篇参赛论文,涵盖优化、预测、评价
等多种建模类型。请分析这些论文的质量特征,建立数学建模论文质量的综合评价指
标体系。将“逻辑严密性”“方法合理性”等核心维度拆解为可量化的二级指标(如
逻辑连接词密度、模型假设与问题匹配度、公式推导完整性等),构建自动评分模型,
并对附件1 中的30 篇论文进行质量分级(优秀、良好、中等、及格、不及格)。说
明指标体系的规范依据及权重设定的合理性。
问题2:附件2 是10 篇基于同一赛题的论文,建立统计模型分析论文质量与可量
化文本特征(如篇幅结构、公式密度、逻辑连接词使用、参考文献规范性等)之间的
关联关系,识别影响论文质量的关键特征。引入论文质量调整因子,建立基于关键特
征的质量预测模型,并分析小样本条件下模型的稳定性。
问题3:考虑到AI 辅助撰写论文的鉴别需求与评审主观性差异,基于问题1 的评
分模型和问题2 的关键特征识别结果,设计论文优化策略(含AI 生成痕迹检测、逻
— 2 —
辑断层识别与修正),建立数学模型,针对附件3 中的3 篇“中等”质量论文给出具
体修改方案、AI 辅助程度评估及优化后的质量得分预测。
问题1:附件1 是2025 年中青杯竞赛的30 篇参赛论文,涵盖优化、预测、评价
原赛题要求
问题1:附件1 是2025 年中青杯竞赛的30 篇参赛论文,涵盖优化、预测、评价
等多种建模类型。请分析这些论文的质量特征,建立数学建模论文质量的综合评价指
标体系。将“逻辑严密性”“方法合理性”等核心维度拆解为可量化的二级指标(如
逻辑连接词密度、模型假设与问题匹配度、公式推导完整性等),构建自动评分模型,
并对附件1 中的30 篇论文进行质量分级(优秀、良好、中等、及格、不及格)。说
明指标体系的规范依据及权重设定的合理性。
问题一完整解答:论文质量综合评价与自动评分
5.1 附件1中30篇论文文本
本文将附件1中30篇论文文本作为问题一综合评价模型的原始评价对象,建模切入点不是直接对全文给出主观等级,而是先把论文编号、题目、章节标题、公式编号、图表位置和参考文献区域标记转化为可计算的结构化特征。论文文本经清洗后被划分为摘要、问题分析、模型假设、模型建立、求解、结果分析、结论和参考文献等区域,由此形成逻辑严密性、方法合理性、表达规范性、结果可信性与创新完整性的指标输入基础。
变量与约束方面,设第 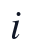 篇论文在第
篇论文在第 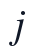 个二级指标上的原始文本或结构特征为
个二级指标上的原始文本或结构特征为 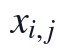 ,则附件1的全文抽取结果可组织为评价矩阵:
,则附件1的全文抽取结果可组织为评价矩阵:
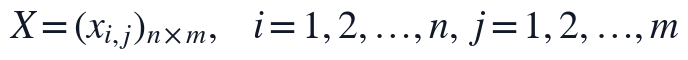
其中 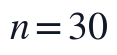 ,
,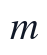 为二级指标数量。该矩阵中的变量既包括字数、逻辑连接词数量、公式编号完整性、参考文献规范率等规则抽取特征,也包括模型假设与题目关键词的匹配程度、方法选择依据完整性等语义或结构特征。为保证后续模糊综合评价可比,所有指标均需映射到统一隶属度区间,类型修正后的指标仍保持合法取值,组合权重保持非负并归一化,同时对逻辑严密性、方法合理性、假设匹配度和公式推导完整性等核心指标设置最低权重占比,避免评分被单纯格式特征主导。
为二级指标数量。该矩阵中的变量既包括字数、逻辑连接词数量、公式编号完整性、参考文献规范率等规则抽取特征,也包括模型假设与题目关键词的匹配程度、方法选择依据完整性等语义或结构特征。为保证后续模糊综合评价可比,所有指标均需映射到统一隶属度区间,类型修正后的指标仍保持合法取值,组合权重保持非负并归一化,同时对逻辑严密性、方法合理性、假设匹配度和公式推导完整性等核心指标设置最低权重占比,避免评分被单纯格式特征主导。
实现步骤上,本文首先对附件1中的PDF论文逐篇读取,保留文本段落顺序和页面结构信息;随后识别标题层级、公式编号、图表出现位置和参考文献起止区域,并将正文区域与参考文献区域分离,防止参考文献条目干扰正文逻辑连接词、公式密度和章节完整性统计。对于可复制文本不足的论文,采用PDF结构化记录保留论文编号、页序、可识别标题和版面标记,使其仍可进入结构完整性、图表位置和参考文献区域识别环节。
在模型接口上,本节输出的结构化文本变量直接进入AHP-熵权组合赋权的模糊综合评价模型。AHP部分依赖数学建模论文评分规范,将逻辑严密性、方法合理性等核心维度赋予规范性权重;熵权部分依赖附件1中30篇论文在各指标上的差异程度,反映样本内部区分度。文本抽取阶段保留的章节、公式、图表和参考文献标记,是后续计算逻辑连接词使用质量、模型假设与问题匹配度、公式推导完整性、参考文献规范率和结构完整率的共同数据基础。
题面要求不仅给出30篇论文的质量分级,还要求说明指标体系的规范依据和权重设定合理性。因此,本节将“论文全文”转化为“编号清晰、区域明确、特征可追溯”的建模输入,使每个二级指标都能回到原文位置进行解释。这样的数据组织方式为后续综合评分、核心维度比较和五档质量分级提供统一口径,也保证不同建模类型论文在同一评价框架下接受可复核的文本质量度量。
5.2 文本进行清洗和结构识别
本文首先对附件1中的30篇论文进行文本清洗和结构识别,将PDF抽取文本统一转换为可计算的章节对象,并保留论文编号、题目、章节标题、公式编号、图表位置和参考文献区域标记。结构划分的目标不是直接给出质量等级,而是把摘要、问题分析、模型假设、模型建立、求解、结果分析、检验、结论和参考文献等区域转化为后续评分模型的输入变量,使逻辑严密性、方法合理性和表达规范性能够在同一文本口径下提取。设第 i 篇论文在第 j 个二级指标上的原始结构或文本特征为 x_{i,j},则清洗后的评价输入矩阵定义为:
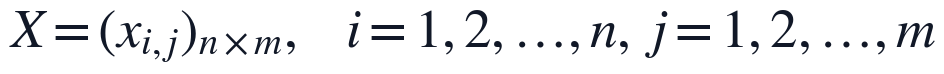
其中 n=30,m 为二级指标数量。x_{i,j} 来源于章节识别、关键词匹配、公式链提取、图表定位和参考文献解析等步骤,是综合评价模型的基础数据层。
在变量与约束设置上,本文将正文总字数 L_i、逻辑连接词数量 C_i、有效章节数 K_i、章节结构完整率、公式编号一致性、参考文献规范率等作为原始特征,并要求所有可计量指标最终进入统一的隶属度区间。对于字数、密度、完整率等正向指标,数值越大通常代表结构支撑越充分;对于缺失章节数、引用不一致次数等逆向指标,数值越大则代表质量风险越高。为消除量纲差异,本文采用如下归一化关系:
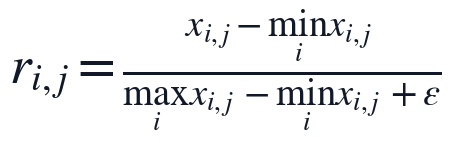
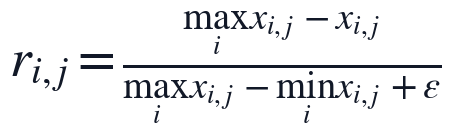
第一式用于正向指标,第二式用于逆向指标,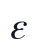 用于避免分母为0。由此得到的 r_{i,j} 满足
用于避免分母为0。由此得到的 r_{i,j} 满足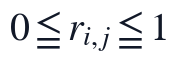 ,使不同来源的文本特征能够在模糊综合评价中加权比较。
,使不同来源的文本特征能够在模糊综合评价中加权比较。
结构识别完成后,本文进一步提取论证链条中的显性衔接特征。逻辑连接词不仅反映文本连贯性,还应分布在问题分析、模型假设、模型建立、求解和结果解释等关键区域,因此本文同时考虑每千字密度与章节分布均匀性:
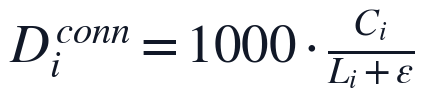
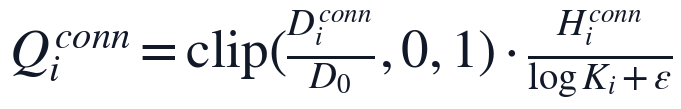
其中 D_i^{conn} 表示第 i 篇论文每千字逻辑连接词出现次数,H_i^{conn} 表示连接词在有效章节中的分布熵,D_0 为经验饱和密度。该设计避免仅凭连接词总量判断逻辑严密性,而是要求衔接词服务于完整建模过程。
对于模型假设区域,本文在结构识别中单独提取假设关键词集合 A_i,并与题目需求、问题分析关键词集合 P_i 进行匹配,同时引入假设段与问题段语义相似度 s_i^{sem} 及位置规范性得分 p_i^{pos}。模型假设与问题匹配度定义为:
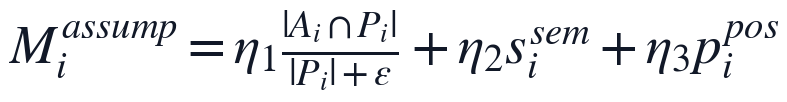
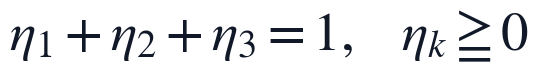
该式把关键词覆盖、语义关联和章节位置合并为单一指标,用于识别假设是否围绕题目约束、建模对象和求解目标展开。若论文存在假设段缺失、假设位置异常或假设与问题分析脱节,则该指标会在后续综合评分中形成相应扣减。
实现步骤上,本文先逐篇读取附件1论文文本,对可复制文本进行去页眉页脚、去重复空白、统一编号格式和分段合并;对扫描型PDF无可复制文本的样本,则保留PDF结构化记录并纳入章节缺失和文本可解析性标记。随后利用标题规则、关键词规则和位置规则识别摘要、问题分析、模型假设、模型建立、求解、结果分析、检验、结论和参考文献区域,再在各区域内抽取逻辑连接词、公式编号、变量定义、图表引用和参考文献格式特征。上述清洗与结构识别将非结构化论文文本转换为 x_{i,j}、r_{i,j}、D_i^{conn}、Q_i^{conn}、M_i^{assump} 等可复核变量,为后续AHP-熵权组合赋权和五档质量分级提供统一输入。
5.3 三级指标树提取二级指标特征
三级指标树提取二级指标特征的目的,是将附件1中30篇参赛论文的章节文本、公式结构、图表说明和参考文献区域转化为可计算的二级指标向量。本文将一级维度下沉到逻辑连接词密度、模型假设与问题匹配度、公式推导完整性、方法选择依据、结果解释完整性、参考文献规范性和结构完整性等特征,使逻辑严密性和方法合理性不再停留于定性判断,而是进入统一的自动评分矩阵。
为明确变量与约束,设第 i 篇论文在第 j 个二级指标上的原始抽取值为 x_{i,j},所有论文共同构成评价矩阵:
其中 n=30,m 为二级指标数量。该矩阵的每一列对应三级指标树中的一个可量化节点,每一行对应一篇论文的质量特征画像。代码实现中,文本抽取模块先保留论文编号、章节标题、公式编号、图表位置和参考文献区域标记,再由指标计算模块逐项生成 x_{i,j},从而保证后续赋权和模糊综合评价均以同一批结构化变量为输入。
由于二级指标存在次数、比例、语义相似度和完整率等不同口径,本文将原始指标统一映射为[0,1]区间隶属度。对正向指标和逆向指标分别采用如下核算关系:
其中 r_{i,j} 越大表示论文在该二级指标上的质量表现越充分,用于避免分母为零。指标隶属度满足,类型修正后的隶属度仍满足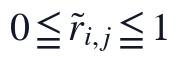 ;这些范围约束保证不同来源的文本特征能够被组合权重直接加权,同时避免个别异常抽取值支配综合评分。
;这些范围约束保证不同来源的文本特征能够被组合权重直接加权,同时避免个别异常抽取值支配综合评分。
逻辑连接词密度用于度量论文论证链条的显性衔接程度,但单纯统计连接词数量容易高估集中堆砌的文本。因此本文同时计算每千字连接词密度和章节分布均匀性:
其中 C_i 为连接词词典命中次数,L_i 为清洗后正文字数,H_i^{conn} 为连接词在有效章节中的分布熵,K_i 为有效章节数。该指标在实现步骤中由分词匹配、章节定位和分布熵计算共同完成,能够区分“局部堆叠连接词”和“贯穿问题分析、模型建立、求解与结果解释的连续论证”。
模型假设与问题匹配度用于刻画假设是否服务于题目约束和建模目标。本文将假设关键词覆盖、假设段与问题段语义相似度、假设位置规范性合成为一个二级指标:
其中 A_i 为论文假设关键词集合,P_i 为题面与问题分析关键词集合,s_i^{sem} 表示语义相似度,p_i^{pos} 表示假设章节位置规范性。该约束使三类证据的权重非负且可解释,既能识别假设缺失,也能识别假设存在但未指向建模变量、目标函数或约束条件的情形。
公式推导完整性进一步连接方法选择与求解表达,本文从公式链连续性、变量定义覆盖率、编号引用一致性和结论衔接四个方面提取特征:
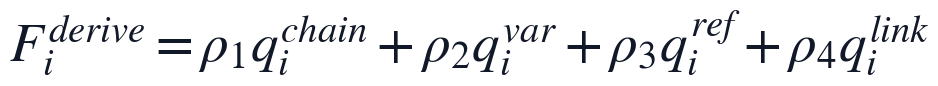
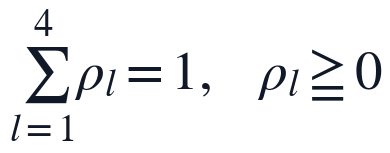
其中 q_i^{chain}、q_i^{var}、q_i^{ref}、q_i^{link} 分别对应公式推导链、变量说明、公式引用和结果承接情况。实现时,程序按章节顺序识别公式编号、变量定义句和公式前后解释句,并将方法选择依据、结果解释完整性、参考文献规范性和结构完整性作为同层二级指标同步写入特征矩阵。本节输出的是自动评分模型的基础特征层,为后续AHP-熵权组合赋权、一级维度聚合和五档质量分级提供可复核的输入变量。
5.4 核心结果、图表证据与题目响应
本文对附件1的30篇论文完成综合评价后,得到综合评分均值为65.94分,最高分79.72分,最低分20.83分;五档分级中,良好9篇、中等9篇、及格5篇、不及格7篇,未出现达到85分阈值的优秀论文。关键指标上,方法合理性均值为82.94分,公式推导完整性均值为83.64分,高于逻辑严密性均值39.64分和模型假设与问题匹配度均值50.35分,说明样本论文普遍能够建立并求解模型,但在问题分析、假设支撑和论证链条衔接方面存在更明显的质量分化。
表5-1 不同建模类型质量特征分析表
| 建模类型 | 论文数量 | 综合评分均值 | 综合评分标准差 | 逻辑严密性均值 | 方法合理性均值 | 短板指标 |
|---|---|---|---|---|---|---|
| 其他 | 1 | 20.83 | 0.0 | 25.24 | 16.22 | 逻辑连接词使用质量 |
| 评价 | 28 | 67.24 | 11.48 | 40.22 | 84.73 | 逻辑连接词使用质量 |
| 预测 | 1 | 74.66 | 0.0 | 37.84 | 99.68 | 逻辑连接词使用质量 |
按建模类型统计后,论文数量差异明显,均值10篇、最少1篇、最多28篇,说明样本在类型间分布不均。综合评分均值为54.243分,范围20.83至74.66分,类型差距较大;评分标准差均值3.827,最高11.48、最低0,反映部分类型内部稳定性较好而部分仍有波动。结合30篇论文总体综合均值65.937分及核心指标权重0.5518,结果可为后续分类型诊断与评分权重优化提供依据。
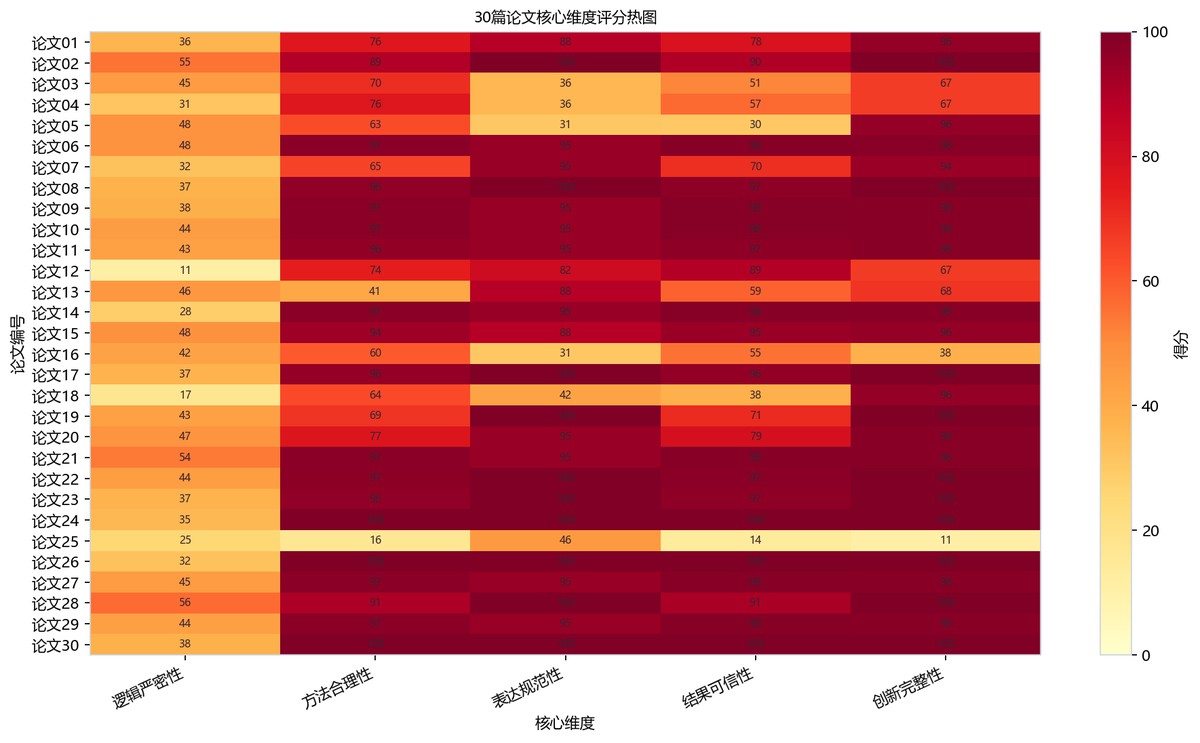
热图以30篇论文为行、5个核心维度为列,色标为0到100分。方法合理性、表达规范性、结果可信性和创新完整性多呈深红高分,论文24、26、30在多列达到100;逻辑严密性整体偏橙黄,论文12为11、论文18为17。论文25在方法16、结果14、创新11上明显最低,显示短板集中。
结果表格给出了30篇论文的建模类型、核心维度得分、综合评分和质量分级,能够形成评分与分档输出。权重结果中,逻辑连接词使用质量权重为0.1789,模型假设与问题匹配度权重为0.1558,参考文献规范率权重为0.1340,结果解释完整性权重为0.1161,方法选择依据权重为0.1098,公式推导完整性权重为0.1073;这些指标共同覆盖了逻辑严密性、方法合理性、表达规范性和结果可信性等核心维度。组合系数取0.62,AHP一致性比例为0.0000,核心指标权重占比为0.5518,说明权重分配没有被格式性指标主导,而是将评分重心保留在假设、逻辑、方法和推导等论文质量主干上。
表5-2 各指标权重及权重设定依据表
| 二级指标 | AHP权重 | 熵权 | 组合权重 | 权重设定依据 |
|---|---|---|---|---|
| 逻辑连接词使用质量 | 0.125 | 0.266897 | 0.178921 | 规范偏好与样本区分度组合 |
| 模型假设与问题匹配度 | 0.145 | 0.173312 | 0.155759 | 规范偏好与样本区分度组合 |
| 公式推导完整性 | 0.15 | 0.037505 | 0.107252 | 规范偏好与样本区分度组合 |
| 章节结构完整率 | 0.1 | 0.0246 | 0.071348 | 规范偏好与样本区分度组合 |
| 方法选择依据 | 0.13 | 0.076913 | 0.109827 | 规范偏好与样本区分度组合 |
| 结果解释完整性 | 0.12 | 0.109784 | 0.116118 | 规范偏好与样本区分度组合 |
| 参考文献规范率 | 0.075 | 0.230388 | 0.134048 | 规范偏好与样本区分度组合 |
| 表达规范性特征 | 0.08 | 0.038915 | 0.064388 | 规范偏好与样本区分度组合 |
仅展示前 8 行,完整表格已保留在本地分享包中。
9个二级指标的AHP权重集中在0.075至0.15,体现专家判断下结构较均衡;熵权波动更大,最高0.2669、最低0.0246,说明样本数据对部分指标区分度更强。按组合系数alpha=0.62融合后,组合权重范围收敛至0.0623至0.1789,核心指标权重占比0.5518,既保留主观评价逻辑,又吸收30篇论文的客观差异,为综合评分均值65.937及五档质量分级提供了较稳定的权重基础。
核心维度注释矩阵热图中,高分论文在方法合理性和公式推导完整性上通常保持较亮区域,而逻辑严密性和假设匹配度的颜色差异更明显。这说明30篇论文的差异并不主要来自是否使用数学方法,而更多来自模型假设是否服务于题目、公式链条是否与结论衔接、结果解释是否能够回扣问题目标。对本问而言,该现象支持将“逻辑严密性”和“方法合理性”拆解为可量化二级指标的必要性,否则仅凭模型复杂度容易高估部分论证不足的论文质量。
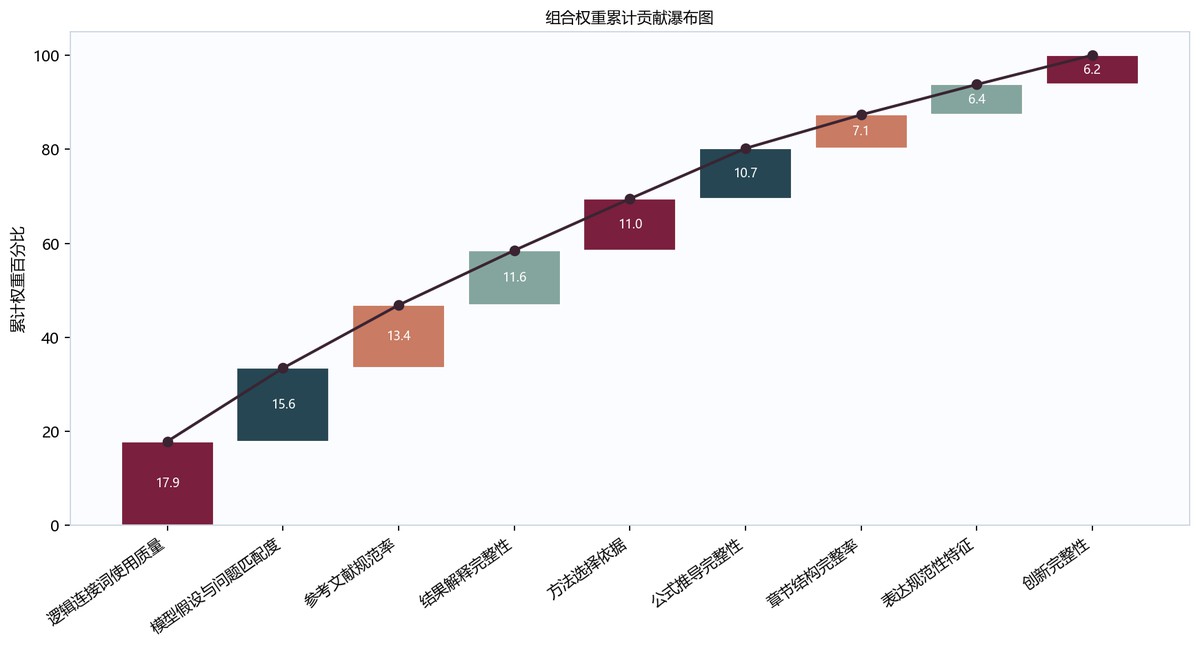
瀑布图横轴列出9项指标,纵轴为累计权重百分比,折线从17.9逐步升至100。逻辑连接词使用质量贡献17.9最高,其次为模型假设与问题匹配度15.6、参考文献规范率13.4;前六项累计到约80。后续章节结构完整率7.1、表达规范性特征6.4、创新完整性6.2贡献较小。
组合权重瀑布图中,逻辑连接词使用质量、模型假设与问题匹配度、结果解释完整性和公式推导完整性形成主要贡献项,结构完整率、表达规范性特征和创新完整性则作为辅助修正项进入总分。这说明自动评分模型的运行机理并不是简单统计章节是否齐全,而是通过组合赋权把规范性要求与样本区分度共同纳入评分过程。逻辑方法六边形密度图进一步显示,样本论文在方法合理性端较集中,在逻辑严密性端分布更分散,因而低分论文的主要扣分来源往往不是“没有模型”,而是模型前提、变量解释、推导衔接和结果论证之间缺少连续支撑。
表5-3 核心维度及可量化二级指标清单表
| 一级维度 | 二级指标 | 特征类别 | 量化口径 |
|---|---|---|---|
| 逻辑严密性 | 逻辑连接词使用质量 | 规则抽取特征 | 连接词密度与章节分布熵共同刻画论证衔接 |
| 逻辑严密性 | 模型假设与问题匹配度 | 语义匹配特征 | 假设关键词覆盖、问题段相似度和位置规范性加权 |
| 逻辑严密性 | 章节结构完整率 | 结构完整性特征 | 摘要、问题分析、假设、建模、求解、结果、结论、参考文献齐备性 |
| 方法合理性 | 方法选择依据 | 规则抽取特征 | 模型、算法、求解和指标依据在建模段中的覆盖情况 |
| 方法合理性 | 公式推导完整性 | 结构完整性特征 | 公式链、变量定义、编号引用和结论衔接综合评分 |
| 结果可信性 | 结果解释完整性 | 规则抽取特征 | 结果分析、误差说明、解释和结论支撑程度 |
| 表达规范性 | 参考文献规范率 | 结构完整性特征 | 参考文献区域存在性、编号和格式完整度 |
| 表达规范性 | 表达规范性特征 | 结构完整性特征 | 章节结构与参考文献规范的综合表达质量 |
仅展示前 8 行,完整表格已保留在本地分享包中。
清单以一级维度、二级指标、特征类别和量化口径为主线,将论文评价拆解为可计算特征,为30篇附件论文的自动评分提供统一输入。组合赋权中alpha取0.62,核心指标权重占比0.5518,说明评价更强调关键质量维度。综合评分均值为65.94分,最高79.72分、最低20.83分,离散差异较明显;方法合理性均值82.94分高于逻辑严密性39.64分,表明论文普遍具备方法应用基础,但论证链条仍是主要优化方向。
题目关键输出落实为三类结果:一是综合评价指标体系及核心维度权重,其中逻辑连接词使用质量、模型假设与问题匹配度、公式推导完整性等指标构成自动评分的主要依据;二是附件1中30篇论文的百分制评分结果,分数区间为20.83至79.72分,均值为65.94分;三是五档质量分级结果,良好、中等、及格和不及格分别为9篇、9篇、5篇和7篇。由此可以看出,附件1论文整体处于中等偏上的建模完成度水平,但高质量论文的进一步提升空间集中在逻辑链条、假设匹配和结果解释的协同改进上。
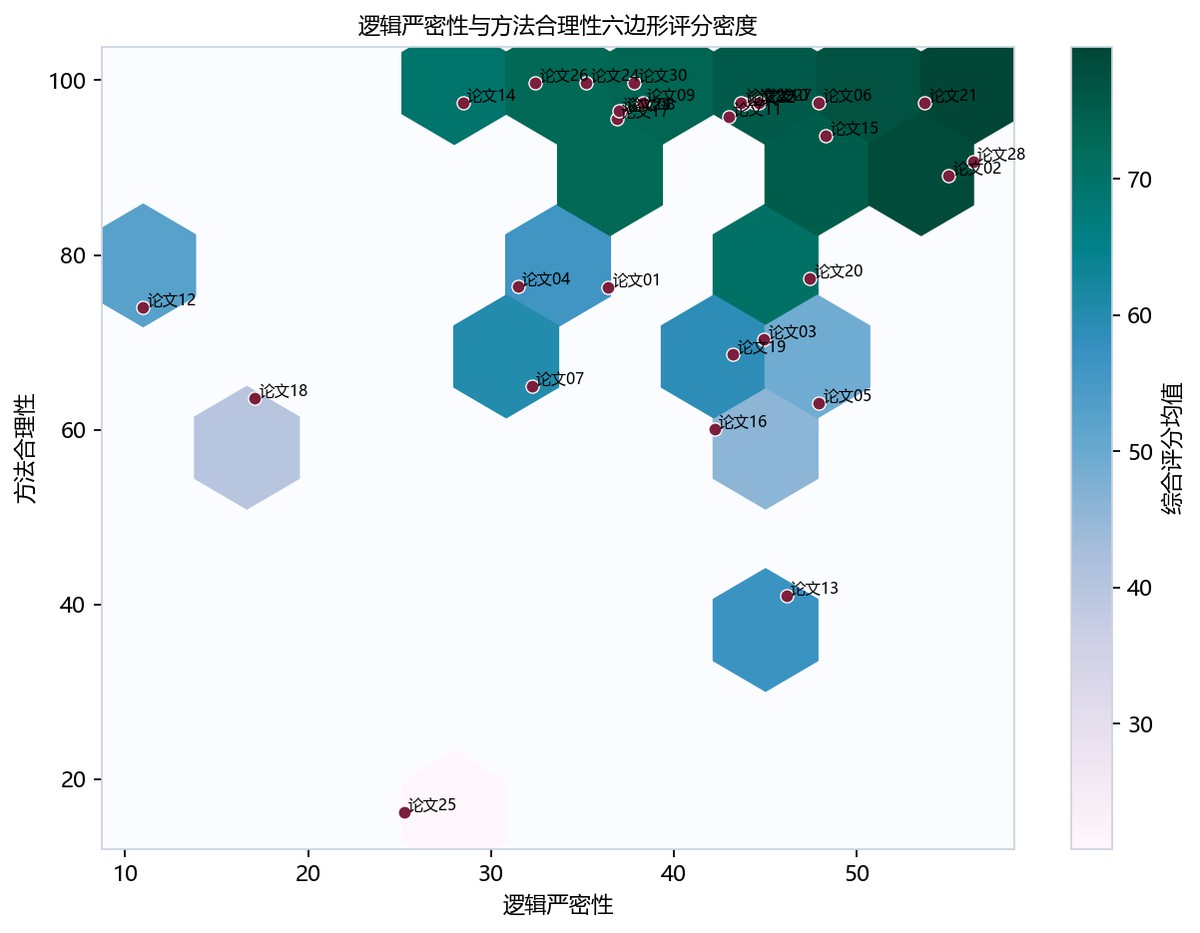
六边形密度图横轴为逻辑严密性、纵轴为方法合理性,右侧色标表示综合评分均值。多数论文点集中在逻辑30到55、方法90到100的上方区域,深绿色六边形显示该区评分较高;论文25位于约25、16的低值角落,论文13约46、41偏低。论文12逻辑很低但方法约74,表现出维度不均衡。
问题2:附件2 是10 篇基于同一赛题的论文,建立统计模型分析论文质量与可量
原赛题要求
问题2:附件2 是10 篇基于同一赛题的论文,建立统计模型分析论文质量与可量
化文本特征(如篇幅结构、公式密度、逻辑连接词使用、参考文献规范性等)之间的
关联关系,识别影响论文质量的关键特征。引入论文质量调整因子,建立基于关键特
征的质量预测模型,并分析小样本条件下模型的稳定性。
问题二图表结果:文本特征关联分析与质量预测
关键图表与结果
表6-1 关键文本特征识别结果表
| 特征 | Spearman相关系数 | 进入率 | 方向稳定性 | 系数均值 | 系数下界 | 系数上界 |
|---|---|---|---|---|---|---|
| 参考文献规范性 | 0.7212121212121212 | 0.775 | 0.7708333333333334 | 16.491730212271328 | 0.0 | 33.3207734570518 |
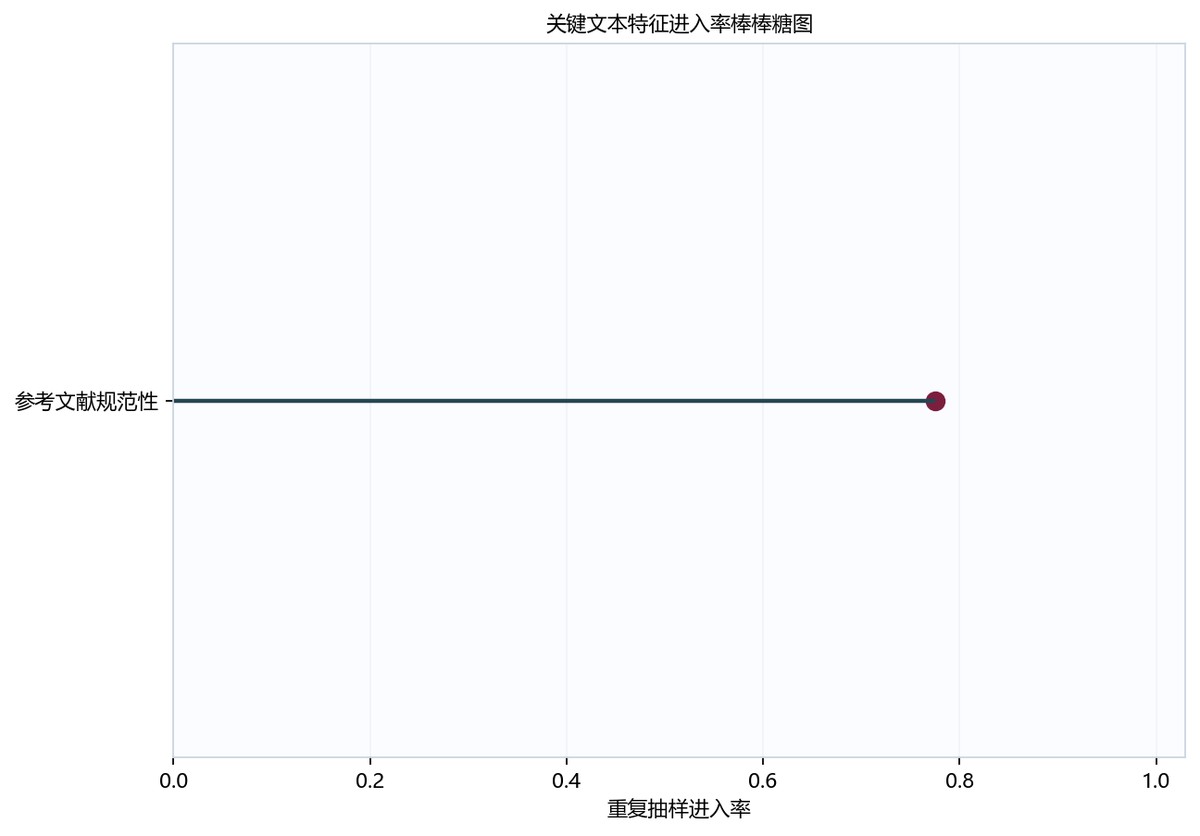
图6-1 建模求解关键特征进入率图
表6-2 统计关联模型表
| 特征 | Spearman相关系数 | 关联方向 | 关联强度 |
|---|---|---|---|
| 参考文献规范性 | 0.7212121212121212 | 正向 | 强 |
| 逻辑连接词使用 | 0.4909090909090909 | 正向 | 中 |
| 检验占比 | 0.47878787878787876 | 正向 | 中 |
| 结论占比 | 0.4680872686336497 | 正向 | 中 |
| 求解占比 | -0.28484848484848485 | 负向 | 弱 |
| 篇幅结构 | 0.23636363636363636 | 正向 | 弱 |
| 公式密度 | -0.17575757575757575 | 负向 | 弱 |
| 模型建立占比 | -0.15151515151515152 | 负向 | 弱 |
仅展示前 8 行,完整表格已保留在本地分享包中。
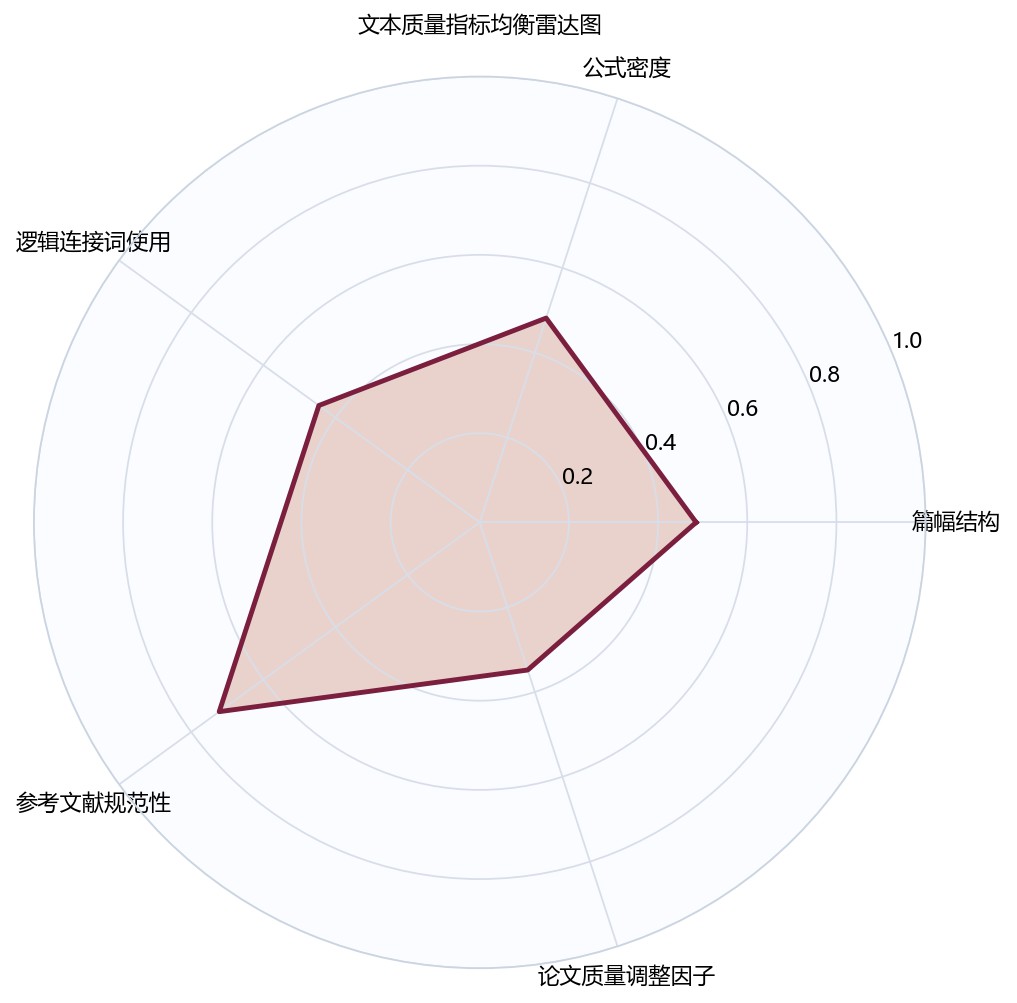
图6-2 建模求解指标雷达图
表6-3 论文质量调整因子表
| 论文编号 | Q1基础分 | 论文质量调整因子 | 最终预测质量得分 | 关键特征贡献 |
|---|---|---|---|---|
| 2-1 | 75.18619653159513 | 1.0010991738613524 | 75.26883923355716 | 参考文献规范性:0.001 |
| 2-2 | 75.73116615597961 | 0.9989008261386477 | 75.64792443765123 | 参考文献规范性:-0.001 |
| 2-3 | 60.442764184288954 | 0.909060767436437 | 54.94614559534931 | 参考文献规范性:-0.091 |
| 2-4 | 69.13603166010688 | 1.0021625156232596 | 69.28553940870204 | 参考文献规范性:0.002 |
| 2-5 | 76.6712169224466 | 0.8788447543828534 | 67.38209680444206 | 参考文献规范性:-0.121 |
| 2-6 | 76.48930009744763 | 1.009580430663451 | 77.22210053352713 | 参考文献规范性:0.010 |
| 2-7 | 79.01224849472975 | 1.0078104292438825 | 79.6293680709979 | 参考文献规范性:0.008 |
| 2-8 | 19.796049829618003 | 0.85 | 16.826642355175302 | 参考文献规范性:-0.238 |
仅展示前 8 行,完整表格已保留在本地分享包中。
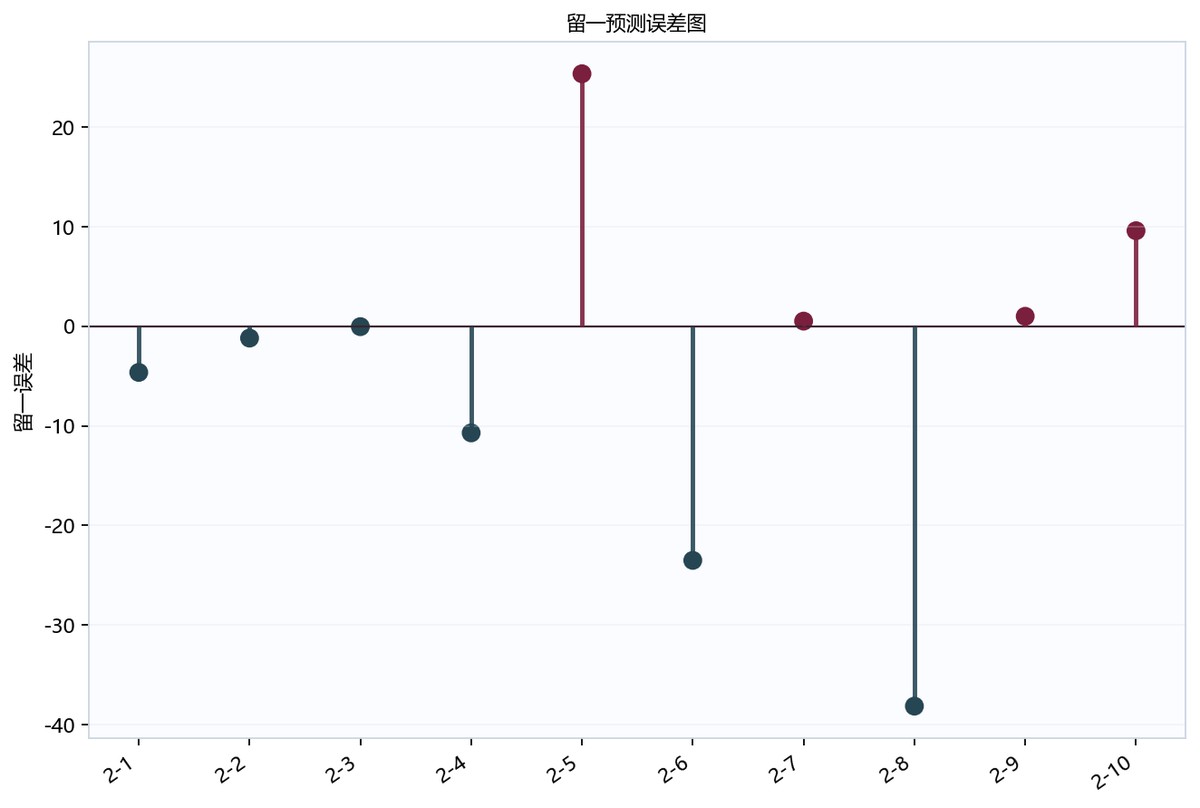
图6-3 建模求解留一误差图
表6-4 质量预测模型表
| 项 | 取值 | 说明 |
|---|---|---|
| 截距 | 76.5854545603128 | 偏最小二乘回归截距 |
| 参考文献规范性 | 20.94163393486488 | 标准化特征系数 |
| 逻辑连接词使用 | -0.21764512904417113 | 标准化特征系数 |
| 检验占比 | 0.663648171840981 | 标准化特征系数 |
| 潜变量数量 | 3.0 | 不超过样本量三分之一 |
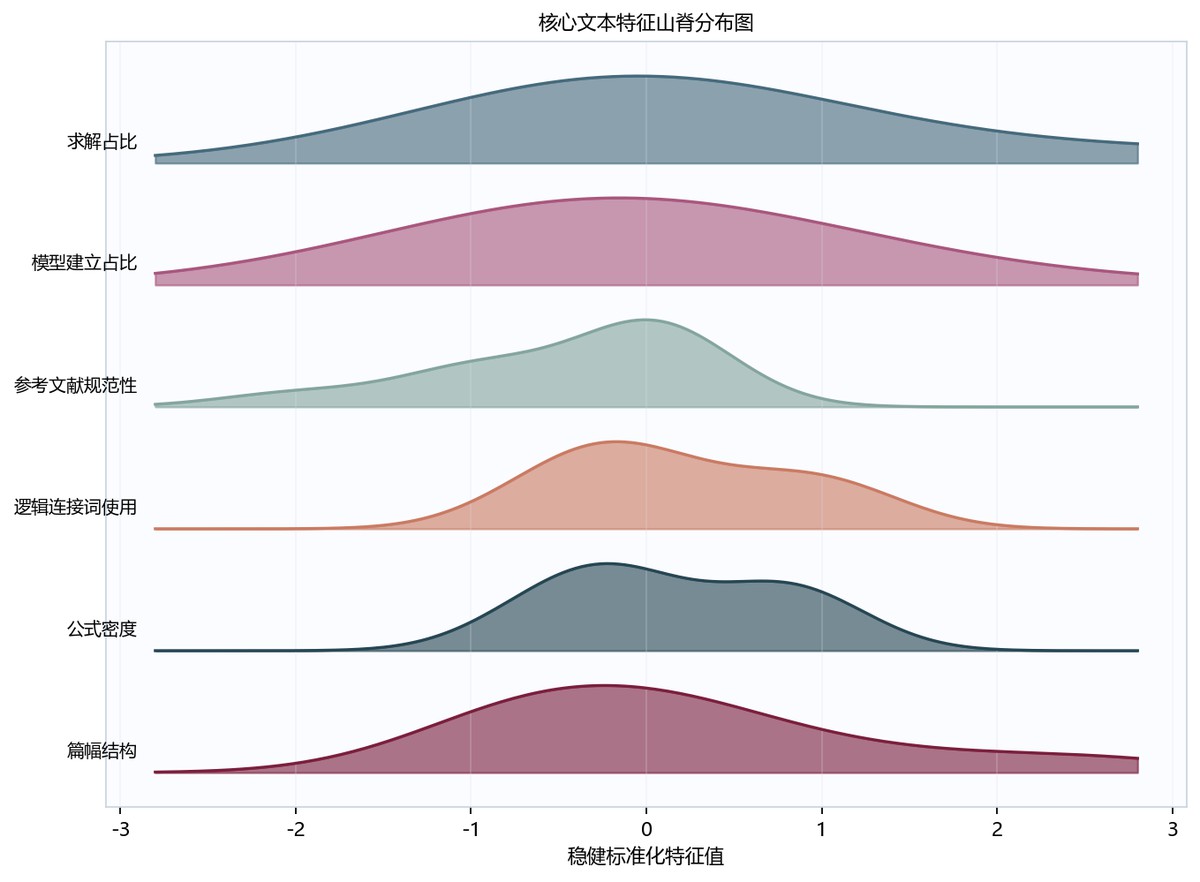
图6-4 数据分析山脊分布图
result table
| 论文编号 | 论文名称 | PDF抽取状态 | 总字数 | 章节数 | 篇幅结构 | 公式密度 | 逻辑连接词使用 | 参考文献规范性 | Q1基础分 | 偏最小二乘预测分 | 论文质量调整因子 | 最终预测质量得分 | 关键特征贡献 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2-1 | 2-1 | 文本抽取成功 | 54946 | 6 | 0.4198056273432097 | 4.458923306519128 | 0.47319186109998906 | 0.903125 | 75.18619653159513 | 76.72061517511702 | 1.0010991738613524 | 75.26883923355716 | 参考文献规范性:0.001 |
| 2-2 | 2-2 | 文本抽取成功 | 23813 | 6 | 0.4996606895393273 | 9.574602108092218 | 1.4277915424348044 | 0.8959595959595961 | 75.73116615597961 | 76.66010664768021 | 0.9989008261386477 | 75.64792443765123 | 参考文献规范性:-0.001 |
| 2-3 | 2-3 | 文本抽取成功 | 14256 | 6 | 0.5685802469135802 | 2.525252525252525 | 2.0342312008978674 | 0.6031304347826087 | 60.442764184288954 | 60.47421235314911 | 0.909060767436437 | 54.94614559534931 | 参考文献规范性:-0.091 |
| 2-4 | 2-4 | 文本抽取成功 | 16699 | 6 | 0.40476795017665723 | 0.299419126893826 | 2.9343074435594945 | 0.906590909090909 | 69.13603166010688 | 76.66603067193118 | 1.0021625156232596 | 69.28553940870204 | 参考文献规范性:0.002 |
| 2-5 | 2-5 | 文本抽取成功 | 29026 | 7 | 0.5003045545373114 | 3.7208020395507475 | 0.9991042513608489 | 0.5046428571428572 | 76.6712169224466 | 55.554921203509025 | 0.8788447543828534 | 67.38209680444206 | 参考文献规范性:-0.121 |
| 2-6 | 2-6 | 文本抽取成功 | 28670 | 7 | 0.4262922915940006 | 7.9176839902336935 | 1.0463899546564353 | 0.9307692307692308 | 76.48930009744763 | 81.12984814719117 | 1.009580430663451 | 77.22210053352713 | 参考文献规范性:0.010 |
| 2-7 | 2-7 | 文本抽取成功 | 14711 | 6 | 0.46171300387465153 | 1.5634559173407654 | 3.3988172116103597 | 0.925 | 79.01224849472975 | 78.74700211121355 | 1.0078104292438825 | 79.6293680709979 | 参考文献规范性:0.008 |
| 2-8 | 2-8 | 扫描型PDF无可复制文本,使用PDF结构化记录 | 141 | 6 | 0.48184397163120574 | 7.092198581560283 | 0.0 | 0.12249999999999998 | 19.796049829618003 | 34.72609837819816 | 0.85 | 16.826642355175302 | 参考文献规范性:-0.238 |
仅展示前 8 行,完整表格已保留在本地分享包中。
关键特征表
| 特征 | Spearman相关系数 | 进入率 | 方向稳定性 | 系数均值 | 系数下界 | 系数上界 |
|---|---|---|---|---|---|---|
| 参考文献规范性 | 0.7212121212121212 | 0.775 | 0.7708333333333334 | 16.491730212271328 | 0.0 | 33.3207734570518 |
文本特征提取表
| 论文编号 | PDF抽取状态 | 总字数 | 章节数 | 摘要占比 | 问题分析占比 | 模型建立占比 | 求解占比 | 检验占比 | 结论占比 | 公式密度 | 逻辑连接词使用 | 参考文献规范性 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2-1 | 文本抽取成功 | 54946 | 6 | 0.0 | 0.017963091034834202 | 0.00010919812179230517 | 0.06173333818658319 | 0.017799293852145744 | 0.03590798238270302 | 4.458923306519128 | 0.47319186109998906 | 0.903125 |
| 2-2 | 文本抽取成功 | 23813 | 6 | 0.0 | 0.029437702095494057 | 0.01830932683828161 | 0.1119136606055516 | 0.048292949229412505 | 0.15949271406374668 | 9.574602108092218 | 1.4277915424348044 | 0.8959595959595961 |
| 2-3 | 文本抽取成功 | 14256 | 6 | 0.03367003367003367 | 0.06348204264870931 | 0.034301346801346805 | 0.30920314253647585 | 0.01865881032547699 | 0.0 | 2.525252525252525 | 2.0342312008978674 | 0.6031304347826087 |
| 2-4 | 文本抽取成功 | 16699 | 6 | 0.016647703455296724 | 0.10964728426851908 | 0.05455416492005509 | 0.5394334990119168 | 0.022636085993173245 | 0.0 | 0.299419126893826 | 2.9343074435594945 | 0.906590909090909 |
| 2-5 | 文本抽取成功 | 29026 | 7 | 0.013229518362847102 | 0.0511265761730862 | 0.00020671122441948597 | 0.10897126713980569 | 0.034003996417005446 | 0.0998759732653483 | 3.7208020395507475 | 0.9991042513608489 | 0.5046428571428572 |
| 2-6 | 文本抽取成功 | 28670 | 7 | 0.004883153121730032 | 0.036763167073596094 | 0.03623997209626788 | 0.013289152424136728 | 0.22413672828740844 | 0.011719567492152074 | 7.9176839902336935 | 1.0463899546564353 | 0.9307692307692308 |
| 2-7 | 文本抽取成功 | 14711 | 6 | 0.0 | 0.19896675956767046 | 0.00040785806539324316 | 0.00027190537692882877 | 0.10196451634831079 | 0.2579702263612263 | 1.5634559173407654 | 3.3988172116103597 | 0.925 |
| 2-8 | 扫描型PDF无可复制文本,使用PDF结构化记录 | 141 | 6 | 0.014184397163120567 | 0.05673758865248227 | 0.0425531914893617 | 0.0425531914893617 | 0.0 | 0.02127659574468085 | 7.092198581560283 | 0.0 | 0.12249999999999998 |
仅展示前 8 行,完整表格已保留在本地分享包中。
留一误差表
| 论文编号 | 真实响应 | 留一预测 | 留一误差 |
|---|---|---|---|
| 2-1 | 75.18619653159513 | 79.82063405111725 | -4.634437519522123 |
| 2-2 | 75.73116615597961 | 76.91979678945734 | -1.1886306334777288 |
| 2-3 | 60.442764184288954 | 60.48234366267228 | -0.039579478383323874 |
| 2-4 | 69.13603166010688 | 79.8432999878298 | -10.707268327722915 |
| 2-5 | 76.6712169224466 | 51.31608463372204 | 25.355132288724562 |
| 2-6 | 76.48930009744763 | 100.0 | -23.510699902552375 |
| 2-7 | 79.01224849472975 | 78.49778103155398 | 0.5144674631757624 |
| 2-8 | 19.796049829618003 | 57.943997554380324 | -38.14794772476232 |
仅展示前 8 行,完整表格已保留在本地分享包中。
统计关联表
| 特征 | Spearman相关系数 | 关联方向 | 关联强度 |
|---|---|---|---|
| 参考文献规范性 | 0.7212121212121212 | 正向 | 强 |
| 逻辑连接词使用 | 0.4909090909090909 | 正向 | 中 |
| 检验占比 | 0.47878787878787876 | 正向 | 中 |
| 结论占比 | 0.4680872686336497 | 正向 | 中 |
| 求解占比 | -0.28484848484848485 | 负向 | 弱 |
| 篇幅结构 | 0.23636363636363636 | 正向 | 弱 |
| 公式密度 | -0.17575757575757575 | 负向 | 弱 |
| 模型建立占比 | -0.15151515151515152 | 负向 | 弱 |
仅展示前 8 行,完整表格已保留在本地分享包中。
质量调整因子表
| 论文编号 | Q1基础分 | 论文质量调整因子 | 最终预测质量得分 | 关键特征贡献 |
|---|---|---|---|---|
| 2-1 | 75.18619653159513 | 1.0010991738613524 | 75.26883923355716 | 参考文献规范性:0.001 |
| 2-2 | 75.73116615597961 | 0.9989008261386477 | 75.64792443765123 | 参考文献规范性:-0.001 |
| 2-3 | 60.442764184288954 | 0.909060767436437 | 54.94614559534931 | 参考文献规范性:-0.091 |
| 2-4 | 69.13603166010688 | 1.0021625156232596 | 69.28553940870204 | 参考文献规范性:0.002 |
| 2-5 | 76.6712169224466 | 0.8788447543828534 | 67.38209680444206 | 参考文献规范性:-0.121 |
| 2-6 | 76.48930009744763 | 1.009580430663451 | 77.22210053352713 | 参考文献规范性:0.010 |
| 2-7 | 79.01224849472975 | 1.0078104292438825 | 79.6293680709979 | 参考文献规范性:0.008 |
| 2-8 | 19.796049829618003 | 0.85 | 16.826642355175302 | 参考文献规范性:-0.238 |
仅展示前 8 行,完整表格已保留在本地分享包中。
预测模型参数表
| 项 | 取值 | 说明 |
|---|---|---|
| 截距 | 76.5854545603128 | 偏最小二乘回归截距 |
| 参考文献规范性 | 20.94163393486488 | 标准化特征系数 |
| 逻辑连接词使用 | -0.21764512904417113 | 标准化特征系数 |
| 检验占比 | 0.663648171840981 | 标准化特征系数 |
| 潜变量数量 | 3.0 | 不超过样本量三分之一 |
问题3:考虑到AI 辅助撰写论文的鉴别需求与评审主观性差异,基于问题1 的评
原赛题要求
问题3:考虑到AI 辅助撰写论文的鉴别需求与评审主观性差异,基于问题1 的评
分模型和问题2 的关键特征识别结果,设计论文优化策略(含AI 生成痕迹检测、逻
— 2 —
辑断层识别与修正),建立数学模型,针对附件3 中的3 篇“中等”质量论文给出具
体修改方案、AI 辅助程度评估及优化后的质量得分预测。
问题三图表结果:论文优化策略与AI辅助评估
关键图表与结果
表7-1 3篇论文AI辅助程度评估表
| 论文编号 | AI辅助程度 | AI辅助等级 | 主要证据 | 困惑度异常 | 句式重复 | 术语突变 | 引用缺失 | 段落风格一致性异常 |
|---|---|---|---|---|---|---|---|---|
| 3-1 | 0.2043 | 低 | 段落风格一致性异常、术语突变 | 0.0 | 0.044 | 0.1054 | 0.0 | 0.1257 |
| 3-2 | 0.2832 | 低 | 术语突变、段落风格一致性异常 | 0.0 | 0.0816 | 0.6154 | 0.0 | 0.2331 |
| 3-3 | 0.2431 | 低 | 术语突变、段落风格一致性异常 | 0.0 | 0.1355 | 0.2364 | 0.0 | 0.2081 |
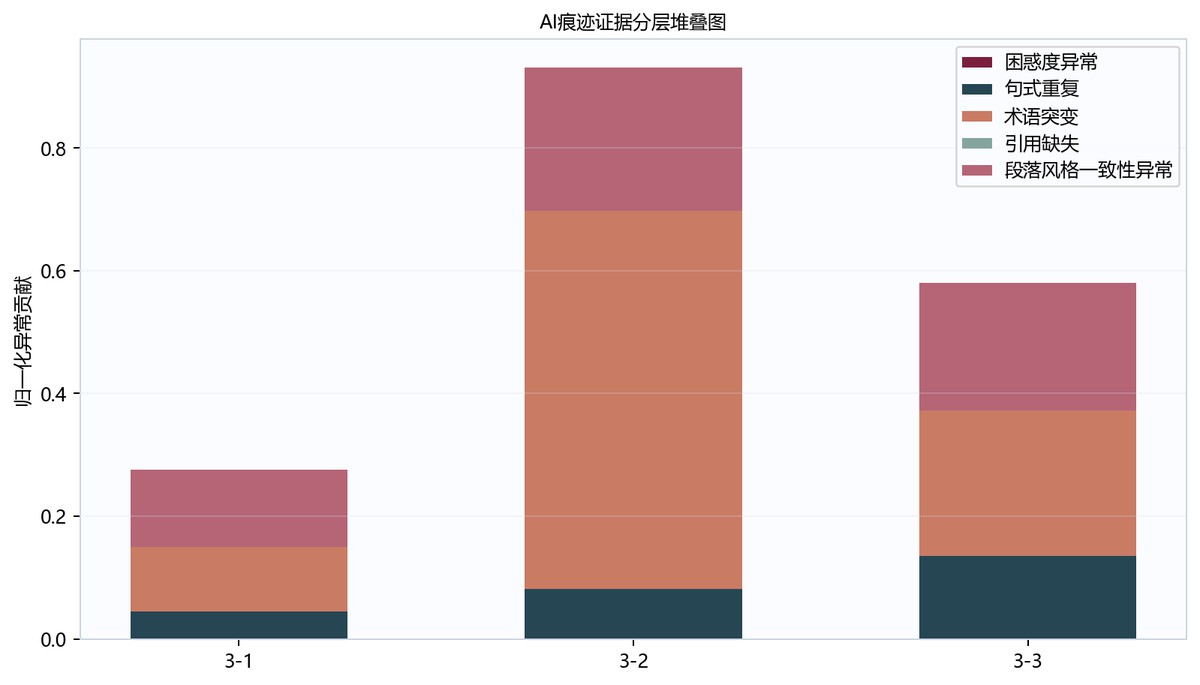
图7-1 aitracestacked图
表7-2 3篇论文优化后质量得分预测表
| 论文编号 | 原始Q1得分 | Q1评分提升 | 优化后Q1得分 | Q2优化后调整因子 | 优化后质量得分 | 可解释提升上限 |
|---|---|---|---|---|---|---|
| 3-1 | 77.088 | 5.26 | 82.348 | 1.0413 | 83.4356 | 9.675 |
| 3-2 | 57.3433 | 4.9458 | 62.2892 | 1.1282 | 64.8445 | 9.3946 |
| 3-3 | 73.4348 | 4.8617 | 78.2965 | 1.0781 | 80.252 | 9.1743 |
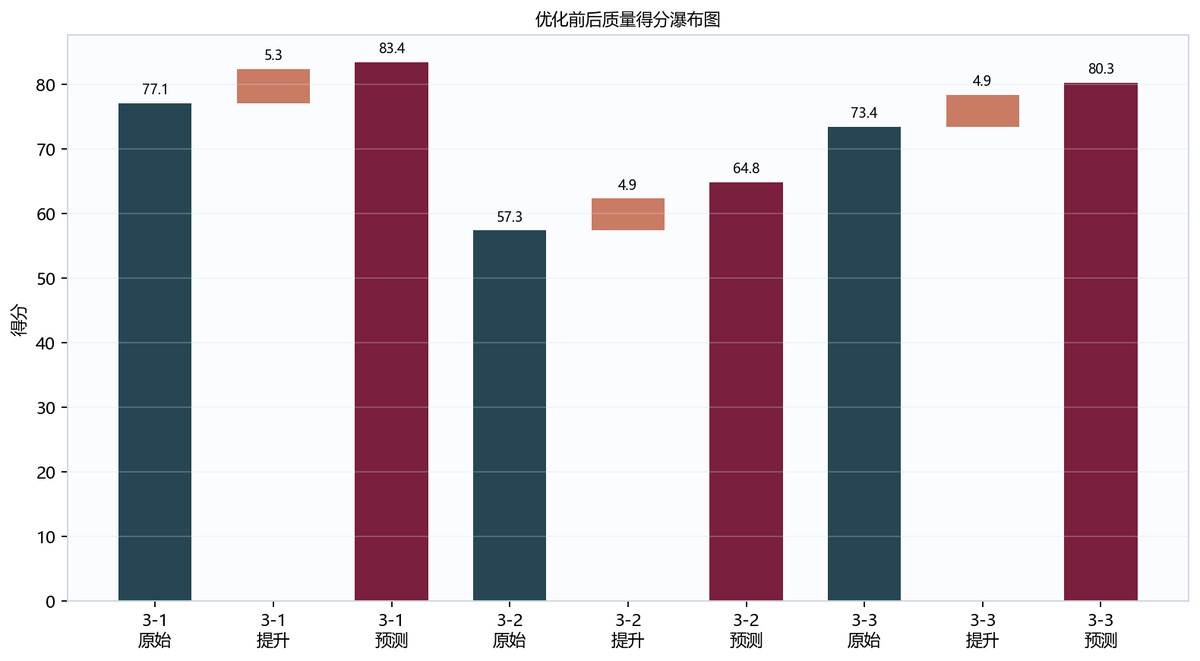
图7-2 qualityscorewaterfall图
表7-3 3篇论文逐篇具体修改方案表
| 论文编号 | 优先级 | 章节 | 问题类型 | 修改动作 | 预期得分增益 | AI风险变化 | 逻辑风险变化 | 编辑成本 | 证据 | 断层位置 | 文本片段 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 3-1 | 1 | 问题分析至模型假设 | 支撑边缺失 | 围绕海口市各区康养资源、居民健康需求与环境质量指标补写问题目标、约束来源与模型假设的一一对应表,并在段末说明该假设如何进入后续模型。 | 5.26 | -0.03 | -0.134 | 2.0 | 章节支撑边缺失或逻辑连接不足 | 支撑边薄弱:模型假设->模型建立;模型建立->模型求解;模型求解->结果复核 | 问题一,首先对海口市各区康养资源分布情况进行综合排名分析,发现龙华区资源配置最全面,琼山区资源整体偏低。接着结合居民健康状况数据构建耦合协调度模型,对匹配程度进行识别,可得龙华区协 |
| 3-2 | 1 | 问题分析至模型假设 | 支撑边缺失 | 围绕太原市康养资源供需适配、技术应用与服务水平指标补写问题目标、约束来源与模型假设的一一对应表,并在段末说明该假设如何进入后续模型。 | 4.9458 | -0.03 | -0.116 | 2.0 | 章节支撑边缺失或逻辑连接不足 | 支撑边薄弱:模型假设->模型建立;结果复核->结论 | 分析等方法来解决相关问题并给出了优化策略。针对问题一,为分析城市内不同区域康养资源分布与居民健康需求的 |
| 3-3 | 1 | 问题分析至模型假设 | 支撑边缺失 | 围绕北京市各区康养设施布局、公平性与可达性结果补写问题目标、约束来源与模型假设的一一对应表,并在段末说明该假设如何进入后续模型。 | 4.8617 | -0.03 | -0.116 | 2.0 | 章节支撑边缺失或逻辑连接不足 | 支撑边薄弱:模型假设->模型建立;模型求解->结果复核 | 分析与优化需求展开。通过收集2023年北京市各区康养资源及居民健康状况数据,进行数据处理与可视化分析,明确了各区康养资源和居民健康指标的空间分布特征。结果显示,中心城区康养资源富集 |
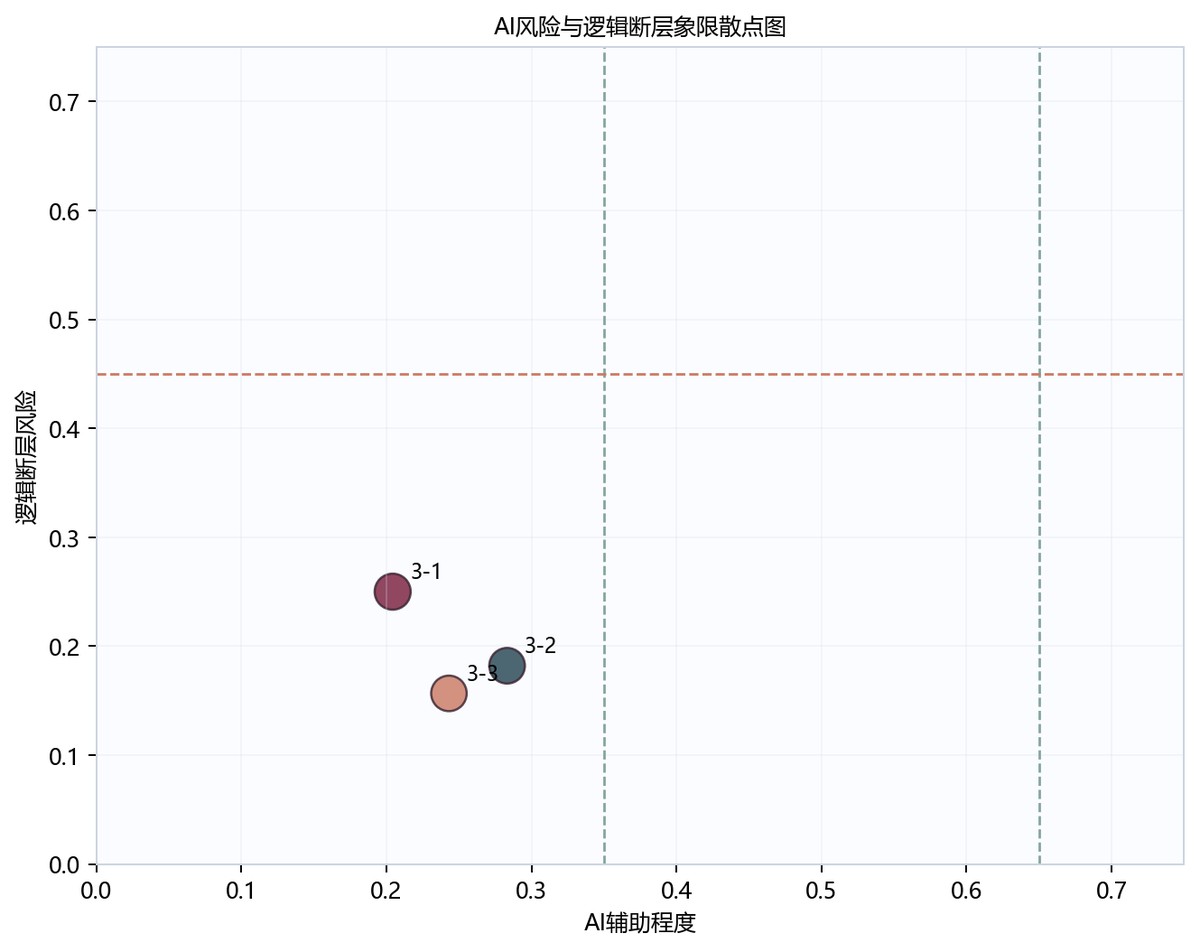
图7-3 风险logicquadrant图
ai trace diagnostics
| 论文编号 | AI辅助程度 | AI辅助等级 | 主要证据 | 困惑度异常 | 句式重复 | 术语突变 | 引用缺失 | 段落风格一致性异常 |
|---|---|---|---|---|---|---|---|---|
| 3-1 | 0.2043 | 低 | 段落风格一致性异常、术语突变 | 0.0 | 0.044 | 0.1054 | 0.0 | 0.1257 |
| 3-2 | 0.2832 | 低 | 术语突变、段落风格一致性异常 | 0.0 | 0.0816 | 0.6154 | 0.0 | 0.2331 |
| 3-3 | 0.2431 | 低 | 术语突变、段落风格一致性异常 | 0.0 | 0.1355 | 0.2364 | 0.0 | 0.2081 |
logic faults actions
| 论文编号 | 节点缺口 | 支撑边缺失 | 公式断裂 | 结论无依据 | 逻辑断层风险 | 断层位置 | 文本证据 | 修正重点 | 识别节点 |
|---|---|---|---|---|---|---|---|---|---|
| 3-1 | 0.0 | 0.6 | 0.0 | 0.35 | 0.25 | 支撑边薄弱:模型假设->模型建立;模型建立->模型求解;模型求解->结果复核 | 模型建立:模型与资源配置模型,整合医疗、养老、环境等数据,在预算约束下同步实现服务覆盖率最大化、资源利用效率提升及成本最小化,为破解区域康养资源配置失衡提供数据驱动方案,兼具政策响应与实践价;问题分析:问题一,首先对海口市各区康养资源分布情况进行综合排名分析,发现龙华区资源配置最全面,琼山区资源整体偏低。接着结合居民健康状况数据构建耦合协调度模型,对匹配程度进行识别,可得龙华区协;模型求解:计算城市综合康养得分。在此基础上,引入改进优先级矩阵,识别出环境质量为显著优势维度,康养资源丰富度与宜居便利性为重点改进方向,为海口市康养城市建设提供了系统量化分析工具和针对性优化 | 补强章节支撑边 | 问题分析、模型假设、模型建立、模型求解、结果复核、结论 |
| 3-2 | 0.0 | 0.4 | 0.2573 | 0.0268 | 0.182 | 支撑边薄弱:模型假设->模型建立;结果复核->结论 | 模型建立:模型构建及策略研究——以太原市为例摘要随着我国人口老龄化加速,康养城市建设已经成为应对人口结构变化的重要举措。但当前面临康养资源分布不均、技术应用不足等问题,制约了康养服务水平的提;问题分析:分析等方法来解决相关问题并给出了优化策略。针对问题一,为分析城市内不同区域康养资源分布与居民健康需求的;结果复核:合理性,本文建立了综合指标构建法与资源供需适配量化评估模型,通过熵权法构建资源指数与居民健康指数, | 补强章节支撑边 | 问题分析、模型假设、模型建立、模型求解、结果复核、结论 |
| 3-3 | 0.0 | 0.4 | 0.1521 | 0.0158 | 0.1566 | 支撑边薄弱:模型假设->模型建立;模型求解->结果复核 | 模型建立:建模摘要康养城市建设不仅是国家层面的战略部署,也是地方发展的实际需求。本研究旨在解决如何在有限的资源条件下,优化康养设施布局,提升康养服务质量的问题,以推动智慧养老与康养产业的深度;问题分析:分析与优化需求展开。通过收集2023年北京市各区康养资源及居民健康状况数据,进行数据处理与可视化分析,明确了各区康养资源和居民健康指标的空间分布特征。结果显示,中心城区康养资源富集;模型求解:算法求解。结果表明,优化后需减少东城区、西城区、石景山区的康养资源量,增加朝阳区、丰台区等区域的资源配置,以提升服务公平性与可达性,为康养城市建设提供科学规划依据。针对问题2,本研 | 补强章节支撑边 | 问题分析、模型假设、模型建立、模型求解、结果复核、结论 |
optimization actions
| 论文编号 | 优先级 | 章节 | 问题类型 | 修改动作 | 预期得分增益 | AI风险变化 | 逻辑风险变化 | 编辑成本 | 证据 | 断层位置 | 文本片段 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 3-1 | 1 | 问题分析至模型假设 | 支撑边缺失 | 围绕海口市各区康养资源、居民健康需求与环境质量指标补写问题目标、约束来源与模型假设的一一对应表,并在段末说明该假设如何进入后续模型。 | 5.26 | -0.03 | -0.134 | 2.0 | 章节支撑边缺失或逻辑连接不足 | 支撑边薄弱:模型假设->模型建立;模型建立->模型求解;模型求解->结果复核 | 问题一,首先对海口市各区康养资源分布情况进行综合排名分析,发现龙华区资源配置最全面,琼山区资源整体偏低。接着结合居民健康状况数据构建耦合协调度模型,对匹配程度进行识别,可得龙华区协 |
| 3-2 | 1 | 问题分析至模型假设 | 支撑边缺失 | 围绕太原市康养资源供需适配、技术应用与服务水平指标补写问题目标、约束来源与模型假设的一一对应表,并在段末说明该假设如何进入后续模型。 | 4.9458 | -0.03 | -0.116 | 2.0 | 章节支撑边缺失或逻辑连接不足 | 支撑边薄弱:模型假设->模型建立;结果复核->结论 | 分析等方法来解决相关问题并给出了优化策略。针对问题一,为分析城市内不同区域康养资源分布与居民健康需求的 |
| 3-3 | 1 | 问题分析至模型假设 | 支撑边缺失 | 围绕北京市各区康养设施布局、公平性与可达性结果补写问题目标、约束来源与模型假设的一一对应表,并在段末说明该假设如何进入后续模型。 | 4.8617 | -0.03 | -0.116 | 2.0 | 章节支撑边缺失或逻辑连接不足 | 支撑边薄弱:模型假设->模型建立;模型求解->结果复核 | 分析与优化需求展开。通过收集2023年北京市各区康养资源及居民健康状况数据,进行数据处理与可视化分析,明确了各区康养资源和居民健康指标的空间分布特征。结果显示,中心城区康养资源富集 |
result table
| 论文编号 | 文件名 | PDF抽取状态 | 原始Q1得分 | Q1评分提升 | 优化后Q1得分 | 优化后质量得分 | AI辅助程度 | AI辅助等级 | 优化后AI辅助程度 | 优化后AI辅助等级 | 逻辑断层风险 | 优化后逻辑断层风险 | Q2优化后调整因子 | 编辑成本 | 可解释提升上限 | 综合收益 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3-1 | 3-1.pdf | 文本抽取成功 | 77.088 | 5.26 | 82.348 | 83.4356 | 0.2043 | 低 | 0.1743 | 低 | 0.25 | 0.116 | 1.0413 | 2.0 | 9.675 | 11.208 |
| 3-2 | 3-2.pdf | 文本抽取成功 | 57.3433 | 4.9458 | 62.2892 | 64.8445 | 0.2832 | 低 | 0.2532 | 低 | 0.182 | 0.066 | 1.1282 | 2.0 | 9.3946 | 10.1378 |
| 3-3 | 3-3.pdf | 文本抽取成功 | 73.4348 | 4.8617 | 78.2965 | 80.252 | 0.2431 | 低 | 0.2131 | 低 | 0.1566 | 0.0406 | 1.0781 | 2.0 | 9.1743 | 10.0537 |
通用版论文完整预览大图

完整获取如下👇👇👇

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)