打破模型孤岛:小马算力(TokenPony)如何重构企业大模型接入底座?
在大模型落地进入深水区的今天,CTO 和开发者们面临一个共同痛点:模型选型难、对接成本高、长上下文支持弱、算力价格波动大。当企业需要同时调用 DeepSeek、Qwen、GLM 等多款模型时,跨平台对接、反复调试 API、应对不稳定推理性能,往往会消耗大量研发精力。
小马算力(TokenPony) 给出的答案是:一站式 AI 大模型 API 聚合平台。它不炼丹,只做最专业的“送水人”——让企业以最低成本、最高效率用上最合适的大模型。
一、主流大模型全覆盖:从“单点调用”到“按需选配”
对于企业技术决策者而言,模型能力必须服务于业务场景,而非反过来被单一模型限制。
小马算力现已全面接入 DeepSeek、Kimi、Qwen、GLM、MiniMax 等主流大语言模型,覆盖通用对话、代码生成、数学推理、长文档分析、工具调用等关键能力。无论是需要 DeepSeek‑V4‑Pro 的百万级上下文推理,还是 GLM‑5.1 的长程自主执行能力,亦或是 MiniMax‑M2.5 的高效 Agent 拆解能力,都能在同一平台上精准匹配。
值得注意的是,这种“全覆盖”并非简单接口堆叠,而是对不同模型特性进行深度适配,确保调用稳定性与响应速度。
二、1024K 超长上下文:解锁复杂 Agent 与企业级应用
上下文长度一直是制约大模型落地的关键瓶颈。小马算力提供高达 1024K 的超大上下文窗口,直接解决三大工程难题:
|
场景 |
传统方案痛点 |
TokenPony 解决方案 |
|---|---|---|
|
长文档处理 |
万字报告需切片,语义断裂 |
完整解析,语义连贯 |
|
多轮复杂对话 |
历史信息丢失,体验割裂 |
沉浸式角色交互 |
|
复杂 Agent 任务 |
多步流程易中断 |
连续执行多步骤任务 |
这对正在布局 AI Agent 的企业尤为重要——更大的上下文意味着更强的任务规划与跨工具协同能力。
三、统一 API + 一行代码切换:极致降低集成门槛
1. 零配置、免部署
平台采用 OpenAI / Claude 兼容规范,开发者无需搭建底层环境或调试模型参数,获取 API Key 后即可直接接入。
2. 一行代码切换模型
创新实现 “一行代码切换模型” 的能力,无需重构复杂集成逻辑,即可在 DeepSeek、Qwen、GLM 之间灵活迁移与 A/B 测试,显著提升迭代效率。
四、硬核算力与极致成本:为规模化落地而生
极速推理
依托自建高性能算力集群,配备 英伟达 H200 及昇腾系列服务器,结合自研推理加速引擎,在高并发场景下仍能保持 平均 TTFT < 500ms 的稳定表现。
更优成本结构
-
按需计费、实时扣款:用多少花多少,避免预付费导致的资源闲置。
-
百万 Tokens 成本低至 ¥7:远低于行业平均水平。
-
充值福利:算力金充值 100 送 30,进一步降低试错成本。
稳定可靠
建立全链路监控与多层次容错机制,实现 7×24 小时不间断服务,已通过数万开发者、百亿级 Tokens 调用验证,为高并发与长时间运行场景提供坚实保障。
五、真实数据背书:已被 6w+ 开发者验证
|
指标 |
数据 |
|---|---|
|
Tokens 月调用量 |
90B+ |
|
总用户数 |
60,000+ |
|
平均 TTFT |
< 500ms |
|
百万 Tokens 成本 |
< ¥7 |
这些数据不仅体现了平台的技术实力,也为 CTO 在做技术选型时提供了可量化的决策依据。
六、结语:大模型时代的基础设施选择
综上所述,大模型竞争的下半场,比拼的不只是参数规模,而是 算力调度效率、工程化落地能力与成本控制水平。小马算力(TokenPony)通过模型聚合、超长上下文支持、统一 API 管理与高性能低成本算力,正在成为企业智能化升级背后的关键基础设施。
对于希望快速落地 AI 应用、又不愿被底层复杂度拖累的团队来说,选择一个像 TokenPony 这样 “懂模型、懂算力、更懂开发者” 的平台,或许是通往 AGI 时代的最短路径。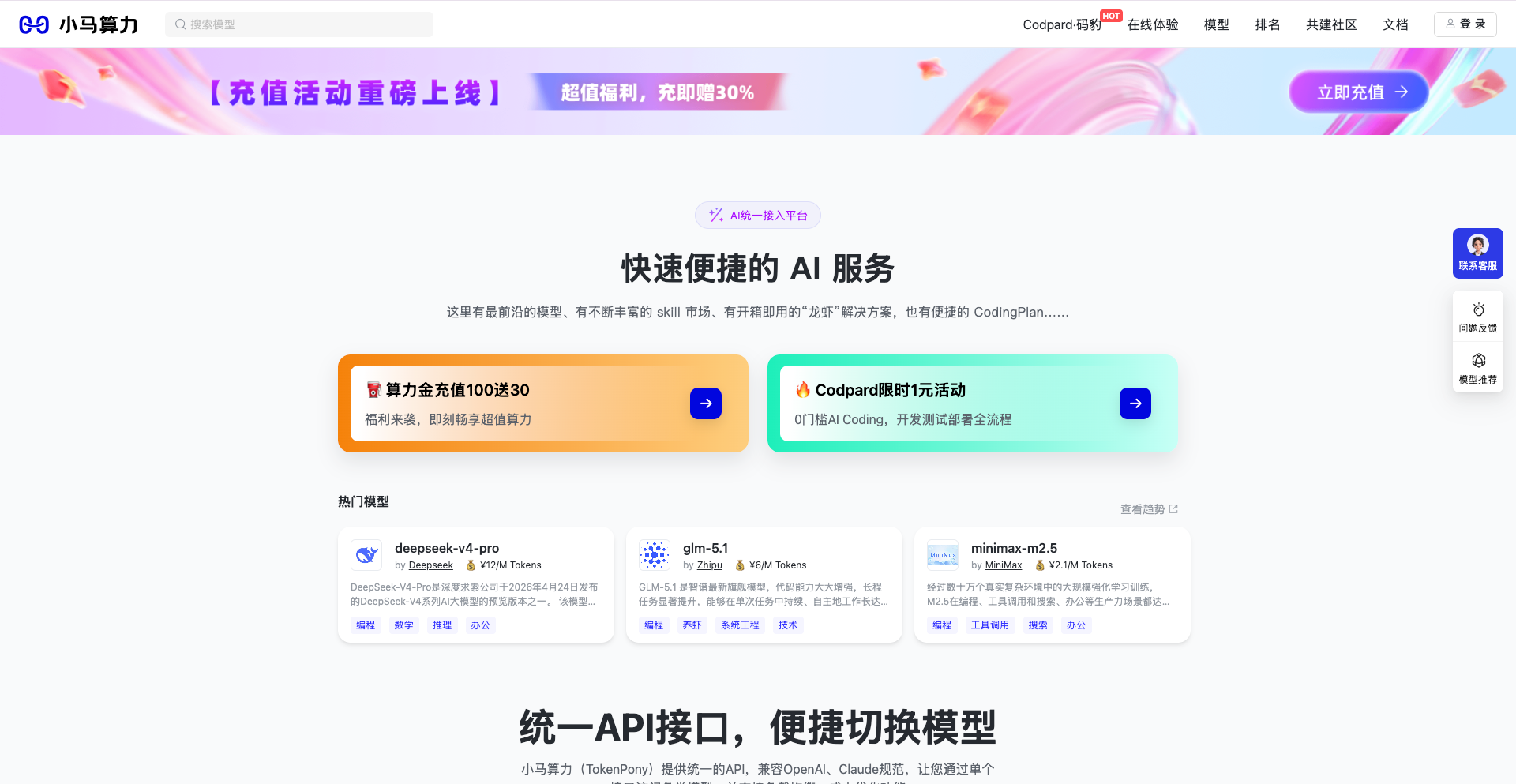
官网直达: https://www.tokenpony.cn/#/
适用人群: CTO / CIO / 技术负责人 / 一线开发者 / AI 创业者

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)