【学习笔记】数据库大家族:关系非关系?时序、图、向量?
·
【学习笔记】数据库大家族:关系非关系?时序、图、向量?
一、 前言:为什么数据库越来越多了?
曾几何时,只要会用一个 MySQL 就能走遍天下。但随着大数据和 AI 时代的到来,数据形态发生了巨变。
现在的数据库不再只是单纯的“存数据”,而是要针对特定的数据结构和查询逻辑进行深度定制。本文将带你理清数据库的分类逻辑,一张图看懂它们的关系。
二、 核心分类逻辑
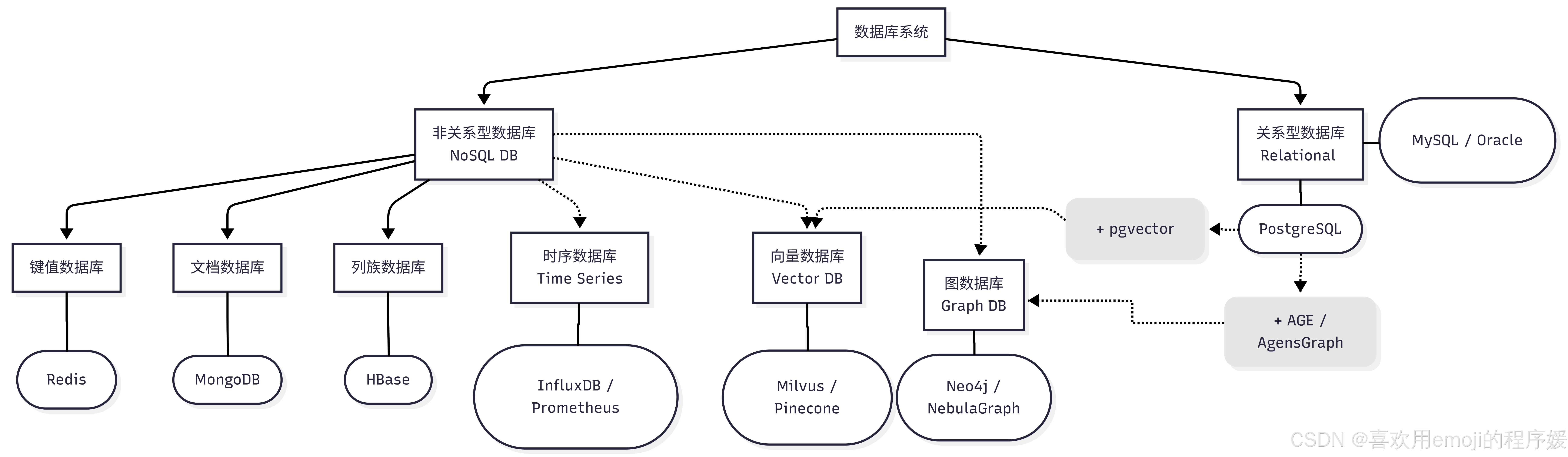
数据库的分类并非平行关系,而是层级递进的。
- 第一层(基础架构):分为 关系型(RDBMS) 和 非关系型(NoSQL)。这是存储范式的区别。
- 第二层(垂直细分):在 NoSQL 的基础上,为了应对 IoT、AI、社交网络等极端场景,演化出了 时序、向量、图 这三大“特种兵”数据库。
1. 数据库家族树
下面的图表展示了它们之间的从属关系和代表产品:
三、 五大数据库核心维度对比
为了更直观地理解它们的差异,我们从数据结构、查询逻辑和应用场景三个维度进行对比。
| 数据库类型 | 底层数据结构 | 核心查询逻辑 | 典型应用场景 |
|---|---|---|---|
| 关系型数据库 (Relational) |
二维表格 (行与列,Schema 严格) |
精确匹配与联表计算 (基于 SQL 的等值查询、聚合) |
电商交易、ERP、金融账务 (强一致性事务场景) |
| 时序数据库 (Time-Series) |
时间序列点 (时间戳 + 指标值) |
时间窗口聚合 (按区间提取趋势、平均值) |
服务器监控、IoT 传感器 (高并发写入、按时间查询) |
| 向量数据库 (Vector) |
高维浮点向量 (AI 特征数组) |
相似度计算 (余弦相似度、欧氏距离) |
大模型记忆、以图搜图 (AI 语义理解与模糊匹配) |
| 图数据库 (Graph) |
节点与边 (实体 + 关系) |
深度优先遍历 (顺着关系链多跳查询) |
社交推荐、反欺诈 (复杂关联网络分析) |
| 通用 NoSQL (Key-Value/Doc) |
灵活结构 (JSON/BSON/Key-Value) |
基于 Key 的简单检索 (牺牲复杂查询换扩展能力) |
商品详情页、缓存 (数据结构多变场景) |
四、 总结与选型建议
在实际架构中,它们通常是共存的,而非互相取代:
- 核心业务数据(订单、用户余额):必须用 关系型数据库(如 MySQL/PostgreSQL),保证不出错。
- 监控与日志(CPU 负载、设备上报):必须用 时序数据库(如 Prometheus),因为它们写得多、查得快。
- AI 与搜索(知识库、推荐):必须用 向量数据库(如 Milvus/pgvector),这是传统 SQL 做不到的。
- 复杂关系(社交好友、资金链路):必须用 图数据库(如 NebulaGraph),解决“六度人脉”难题。
一句话总结:关系型保底线,NoSQL 管扩展,特种数据库解决特定痛点。
下一篇预告:我们将深入探索 PostgreSQL,看看这个“全能型选手”是如何通过插件化身时序、向量和图数据库的。
传送门🚀-PostgreSQL:不只是关系型,更是 AI 时代的“数据底座”

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)