Ai-Agent学习历程—— 阶段3——RAG 与记忆机制
Ai-Agent学习历程—— 阶段3——RAG 与记忆机制
- 上一章节回顾
- 新章节简介
- 一、 ETL 数据智能清洗与高阶分块
- 二、 向量库集成与混合检索 (Milvus & 检索优化)
- 三、自适应检索与控制流 RAG (Advanced/Agentic RAG 编排)
- 四、现代长短记忆体系与知识融合 (打造有温度的 AI)
- 👑 第五阶段:实战结项 —— 手搓“千人千面”记忆问答智能体
- 核心总结
上一章节回顾
上一章节主要是 LangChain Core 的学习,分为以下几个方面。
一、 LCEL 声明式流处理 (基石)
- 核心概念:万物皆
Runnable。使用|管道符构建数据流水线。 - 数据路由:
- 单参数透传:
RunnablePassthrough()或lambda x: x。 - 动态注入/覆盖:使用
RunnablePassthrough.assign(key=func),在不丢失原数据流的情况下追加新参数。
- 单参数透传:
- 容错与高可用:使用
.with_fallbacks([backup_llm])实现 API 降级;使用timeout和max_retries防止网络阻塞。 - ⚠️ 注意事项:字典中的值如果涉及处理逻辑,优先使用
lambda而非直接用|强转,避免TypeError(如果非要用,需包一层RunnableLambda)。
二、 结构化输出 (跨语言对齐桥梁)
- 核心概念:使用 Pydantic 定义
BaseModel(等价于 Java DTO)。其中Field(description="...")是直接写给大模型的 Prompt。 - 实现方案:
- 首选 (原生支持):
llm.with_structured_output(Schema, method="json_mode")。 - 兜底 (纯文本强转):
PydanticOutputParser+ 动态 Prompt 注入format_instructions。
- 首选 (原生支持):
- 自动修复装甲:使用
OutputFixingParser.from_llm()包裹基础解析器,当 JSON 破损时,自动召唤廉价小模型进行语法修复。 - ⚠️ 高阶架构思想 (读写分离):绝对不要让大模型在陪用户聊天的同时输出 JSON。正确做法是:前台 Agent 流式聊天,后台起一个专门的
structured_output流水线对聊天记录进行静默提取和入库。
三、 上下文管理与长对话 (记忆中枢)
- 核心概念:打破 HTTP 无状态。使用
MessagesPlaceholder(variable_name="history")在 Prompt 中为历史记录留坑。 - 会话隔离:使用
RunnableWithMessageHistory结合session_id,实现多用户并发的记忆隔离。 - Token 控制与滚动摘要 (Memory Trimming):
- 截断法:使用
trim_messages(max_tokens=...)保留最近 N 轮。 - 摘要法:后台使用小模型动态总结老旧对话。
- 截断法:使用
- ⚠️ 高阶架构思想 (非破坏性修改):绝对不能在底层数据库中删除历史消息!必须在 LCEL 流水线中,使用拦截器(动态生成摘要 + 拼接最近对话),生成专供大模型阅读的“压缩版列表”,确保 UI 端始终能看到完整记录。
四、 Tool Calling 工具调用 (Agent 雏形)
- 核心概念:大模型不会执行代码,它只负责输出特殊的 JSON 指令 (
tool_calls)。 - 武器库规范:使用
@tool装饰器。必须包含严格的 Type Hints (类型注解) 和 Docstrings (文档注释),底层会将其编译为 JSON Schema 发给大模型。 - 原生 Agent 循环:不使用封装过度的 Agent 框架。通过
while循环截获ai_msg.tool_calls,路由到本地 Python 函数执行,并将结果封装为带有tool_call_id的ToolMessage塞回历史记录,供大模型最终总结。 - ⚠️ 致命坑点 (悬空工具消息 400 报错):
Messages with role 'tool' must be a response...报错是因为在 Agent 的工作循环内部执行了记忆压缩,把发起指令的AIMessage给删了。防坑铁律:记忆修剪函数必须放在用户新提问的回合入口处,绝对不能放在 Agent “思考-执行工具”的循环体内部。
五、 LangSmith (AI 时代的 SkyWalking)
- 核心概念:LLMOps 监控底座。
- 零代码接入:只需配置
LANGCHAIN_TRACING_V2=true及对应的 API Key、Project 环境变量。 - 排障三板斧:看 Waterfall (瀑布流判断耗时瓶颈) -> 看 Input (检查 Prompt 和记忆注入是否正确) -> 看 Tokens (排查计费与长度)。
- ⚠️ 致命坑点 (403 Forbidden):注意 LangSmith 的数据节点区分。如果注册在亚太区,必须在环境变量中强行增加
LANGCHAIN_ENDPOINT="https://apac.api.smith.langchain.com",否则调用默认美国节点会报 403 权限错误。
新章节简介
下面是这一章节所对应的学习大纲
一、 ETL 数据智能清洗与高阶分块 (构建干净的知识源)
“Garbage in, garbage out.” 数据的质量直接决定了 RAG 系统的上限。
- 核心概念:彻底告别生硬的按字符计数切分(如旧版
CharacterTextSplitter),全面转向基于语义边界的切分(SemanticChunker)。 - 父子文档双层关联(ParentDocumentRetriever):这是生产级 RAG 的核心武器。在向量库里存储较小、语义高度集中的“子分块(Child Chunks)”以确保检索精度,但在召回后,自动将更大的“父文档(Parent Document)”送给大模型进行阅读,完美平衡检索精度与上下文完整度。
- 文档结构提取:学习如何提取多模态或 Markdown/HTML 的文档树状结构,保留标题、表格等层级信息,不破坏原始数据逻辑。
二、 向量库集成与混合检索 (Milvus & 检索优化)
单一的向量检索在生产中极其脆弱,必须引入混合检索(Hybrid Search)提升召回率。
- 核心概念:掌握本地或云端向量库(以 Milvus 或 Supabase pgvector 为主)的搭建与操作。
- 混合检索(Hybrid Search):通过 LCEL 整合 稠密向量检索(Dense Vector, 语义理解) 与 稀疏向量检索(Sparse Vector, 如 BM25,用于精准匹配專有名词和型号)。
- 重排机制(Rerank):引入轻量级重排模型(如 BGE-Reranker 或 Cohere Rerank),对初筛召回的 Top-K 进行二次打分,解决大模型“迷失在中间(Lost in the middle)”的痛点。
- 多租户安全隔离(Multi-tenancy):利用 Metadata Filters,在检索阶段强行注入用户/企业身份隔离,从物理或逻辑上严防数据越权召回。
三、 自适应检索与控制流 RAG (Advanced RAG 编排)
打破“提问-检索-回答”的单向死板流,让 RAG 拥有分析与反思能力。
- 核心概念:利用 LCEL 编排复杂的自适应检索控制流。
- 查询重写(Query Rewriting):用户的一句提问往往模糊不清,通过 LLM 将其重写、分拆为多个子问题(Multi-Query),进行并发召回。
- 检索评估(Self-RAG / CRAG):在获得检索内容后,使用轻量大模型动态评估“检索到的文档是否真的与问题相关”。如果相关度低,则触发降级方案或自动联网检索,拒绝将废话喂给大模型。
四、 现代长短记忆体系 (彻底弃用 Legacy Memory,拥抱 BaseStore)
在 LangChain 1.0 时代,旧的类(如
ConversationBufferMemory)已全部废弃。我们将学习现代的记忆管理方案。
- 核心概念:明确短周期会话(Session-based)与长周期长效记忆(Cross-session / Profile)的界限。
- 短周期会话:摒弃已废弃的旧 Memory 类,统一使用 LCEL 配合
RunnableWithMessageHistory(支持 Redis / Postgres 存储) 来存储和裁剪运行时的对话上下文。 - 长周期长效记忆(Semantic/Episodic Memory):学习使用 LangChain 官方最新的
BaseStore接口 (InMemoryStore/LocalFileStore) 或 LangMem SDK。 - 后台静默提取:用户聊天时,后台起一个异步提取流(使用第二阶段掌握的结构化输出),将用户画像(偏好、技术栈、高频痛点等)持续累加、去重并持久化到外挂存储中,打破“换个 Thread 就失忆”的魔咒。
五、 实战结项:手搓“记忆问答智能体 (Demo: Memory Q&A)”
融汇贯通,将外挂知识库(RAG)与用户长效偏好(Memory)融为一体。
- 核心概念:静态的大脑(垂直知识库)+ 动态的温度(用户长效记忆)。
- 核心业务流:
- 动态接收用户输入。
- 检索机制:利用混合检索与 Rerank 召回精准知识。
- 记忆机制:去 Store/LangMem 中调取当前用户的个性化 Profile 记忆。
- 控制层融合:LCEL 组装
[System Prompt] + [垂直知识] + [长效记忆] + [历史记录] + [当前提问],输出高度量身定制的回复。
基于学习大纲我们有了一个简单的地图,从官网的资料进行对应,主要是以下三部分
过程中可以进行参考官方文档,但有一些可能会基于目前最新的资料进行适当的更改,让我们愉快的开始吧!
一、 ETL 数据智能清洗与高阶分块
作为初学者以及一个从web工程师转型的学者来说,数据清洗的概念并不陌生,但总归来说是有一定区别的。在真正进入下面的学习之前我们还需要搞懂几个基本的概念和区别。
问题1:RAG方面的数据清洗指的是什么?这和web开发中的数据清晰有什么区别?
- 传统的数据清洗: 在web开发中,我们所指的数据清洗一般是针对
结构化数据例如Excel、CSV、JSON、SQL表 等,清洗的目的是为了 业务的合规性和存储规范,比如说将日期格式 2020/05/07修改为2026-05-07、去重、类型转换等等,正常输出的出口都是Mysql或者Oracle数据库。 - RAG领域的数据清洗: 大模型领域的RAG技术使用的都是PDF、Word、PPT、Markdown、Html等
非结构化数据,而数据清洗的作用则是为了 提高信息密度,降低噪音,防止大模型被垃圾信息误导,正所谓取其精华,弃之糟粕。
(1)RAG 模式下的“脏数据”指的是什么
非结构化文档中包含大量对大模型“无用”甚至“有害”的信息
- 物理噪音:从网页爬取的 HTML 标签、JavaScript 广告代码、PDF 转换时产生的乱码、页眉、页脚、页码(如
第 23 页 / 共 100 页混在正文中间)。 - 语义噪音:免责声明(“本指南仅供参考,不构成投资建议…”)、版权声明(“Copyright © 2026 Corporation”)、无意义的过渡句(“接下来,我们将讨论…”)。
- 结构断裂:PDF 中的表格被提取后,变成了断裂的、无法阅读的单列文本,大模型根本无法看出行列对应关系。
(2) “智能清洗”具体用什么方式?
在 RAG 系统中,清洗主要通过以下几种手段,最终将清洗后的数据存入向量数据库 或 文档缓存库:
- 布局重构(Layout Reconstruction):利用轻量级 AI 视觉或规则模型,识别 PDF 中的表格,并将其转化为 Markdown 表格格式(大模型最容易理解表格的格式)或 JSON 格式。
- 文档去重与降噪:使用算法(如 MinHash)过滤掉重复的网页段落,用正则表达式或自然语言处理器(NLP)剔除版权信息和无意义的页码干扰。
- 安全脱敏(PII Sanitization):智能识别敏感信息(如客户身份证、内网 IP 地址),在入库前替换为
[MASK_IP]或[CONFIDENTIAL],确保数据不泄露给外部大模型。
(3) 清洗的用处在哪里?
- 省钱(降低 Token 成本):大模型是按 Token 收费的。如果文档中 30% 都是无用的页眉页脚、版权广告,每次检索召回都会白白浪费大量的计算成本。
- 防幻觉(提高回答准确度):大模型的注意力(Attention)是有限的。如果给它喂入一堆带有“页码、乱码、无效声明”的片段,它在生成答案时容易被干扰,甚至将“免责声明”误当成业务规则输出给用户。
问题二:分块(Chunking)是不是切片?切片的意义在哪?
是的,在概念上,“分块(Chunking)”就是“切片(Slicing)”。
以现在大模型的发展来说,200K的上下文甚至接近300K的都有,几本书是不成问题的,那切片的意义又在哪?
核心原因有三个:
原因 1:向量化模型(Embedding Model)的“入口瓶颈”
在 RAG 系统中,用户提问后,我们不能直接把 100 页 PDF 丢给大模型(因为每次都传 100 页 PDF,不仅费用高昂,而且响应会有明显的延迟)。我们必须使用 Embedding 模型,先将文档转化为空间向量。
- 瓶颈在于:Embedding 模型的输入长度限制非常严格(通常只有 512 或 1024 个 Token)。
- 如果你把一整篇 2万字的文档直接喂给 Embedding 模型,它要么会强行截断(后面的内容直接丢弃),要么会把这 2 万字的意思高度浓缩成一个向量,导致细节特征全部丢失(语义被稀释了)。
- 切片的解决方案:我们将文档切成 500 字左右的“小片”(Chunks)。每一片拥有独立的向量,从而能精确保留局部的语义细节。
原因 2:为了实现“大海捞针”般的精准检索(Retrieval Precision)
假设用户问:“Redis 的密码复杂度要求是什么?”
- 如果你的切片很大(比如每 10 页 PDF 是一个切片),检索出来的片断会包含大量的硬件申请、磁盘 IO 等无关信息。
- 如果你切得足够精准(比如正好切到“2.1 认证与加密”这一个小段落),向量匹配就能像雷达一样,精准定位并仅把这 200 字召回。
原因 3:提升大模型的“注意力聚焦”——重点
大模型虽然能读 100 万字,但它有一个著名的弱点:“迷失在中间(Lost in the Middle)”。如果给大模型提供太多无关的上下文,它在长文本的中间部分提取关键信息的能力会显著下降。
只提供最相关的 3-5 个精准切片给大模型,它给出的回答质量通常最高。
问题3:RAG在大模型中的具体工作流程
用户提问 → 向量检索 召回最相关的几片(Chunks) → 拼装 Prompt 大模型阅读并回答 \text{用户提问} \xrightarrow{\text{向量检索}} \text{召回最相关的几片(Chunks)} \xrightarrow{\text{拼装 Prompt}} \text{大模型阅读并回答} 用户提问向量检索召回最相关的几片(Chunks)拼装 Prompt大模型阅读并回答
在这个闭环中,大模型不再需要去通读一整本 100 万字的手册,而是像一个“闭卷考试”的学生突然拿到了开卷考试的几张“小抄”。大模型只需要集中精力阅读这几张小抄(核心片段),就能快速、准确地给出答案。这极大地提升了准确率,降低了幻觉。
那么挑战就来了,怎么产生这几张小抄,肯定得自己弄一个吧,而且得是重点,还得全面吧,那么怎么弄是个问题。
挑战一:语义匹配 ≠ \neq = 关键字匹配
在真实的向量数据库中,我们进行的是语义相似度匹配,而不是单纯的“字面关键字匹配”:
- 关键字匹配的局限:如果用户搜“如何开启 Redis 服务”,而文档里写的是“执行 Redis 引导脚本以启动守护进程”。这两个句子一个共同的关键字都没有(开启 ≠ \neq = 启动,服务 ≠ \neq = 进程),传统的关键字搜索(如 SQL
LIKE)会直接漏掉。 - 向量语义匹配的优势:向量库会将“开启服务”和“启动进程”转化为高维空间中距离非常近的向量,从而成功把这个片段找出来。
挑战二:物理硬切片导致的“断章取义”(最核心的痛点)
如果只是简单地按照“每 300 个字切一片”的规则去物理切片,会发生非常尴尬的语义腰斩。
举个真实工程中的惨痛案例:
有一段关于系统端口配置的文本:
“…为了保障安全,系统默认的通信端口是 8080。但是在高并发分布式场景下,建议将集群同步端口修改为 9090…”
如果切片恰好在中间断开了:
- 切片 A:“…为了保障安全,系统默认的通信端口是”
- 切片 B:“8080。但是在高并发分布式场景下,建议将集群同步端口修改为 9090…”
当用户提问:“系统的默认端口是多少?”
- 向量库可能会把切片 A 检索出来(因为提问里有“默认端口”,切片 A 里也有)。
- 但是大模型拿到切片 A 之后直接傻眼了,因为切片 A 里根本没有
8080这个答案!它被无情地切到了切片 B 里,而切片 B 因为相似度不够,根本没有被检索出来。
问题4:需要单独学习RAG的基础知识和底层知识吗
我的建议是不需要。
- 首先我们的核心目标还是Agent的开发,重点是流程和大模型的管理,虽然RAG占据了很大一部分,但还是那句话,先跑起来。
- 我是比较倡导即时学习的概念,也就是用到了我们可以学一下,有时间和精力单独在研究那些底层细节,比如Java你也不可能一上来就学习JVM吧。
- 在下面的不断学习中,我还是会不间断的插入RAG的底层知识,因为我也不是那么了解,遇到了我们就解决,提问,学习,保证我们整体学习进程。
1.1 生产级多源数据加载与结构树解析
- 目标:掌握如何读取非结构化文档(PDF/Markdown/HTML),提炼并保留文档结构(标题层级、元数据),为高精度 RAG 打下结构化地基。
- 内容:
- 对比传统文本加载器与现代版布局感知的解析器(如
PyMuPDF和MarkdownHeaderTextSplitter)的优劣。 - 理解如何将
H1, H2, H3的层级嵌套关系解析为 Document 的metadata,防止在后续切分时丢失文档的拓扑上下文(如“某个细则条款究竟属于哪一个章节”)。 - 实操:加载一个包含多级标题的复杂 Markdown 格式技术文档,解析并输出带有一致层级 metadata 的 Document 对象列表。
- 对比传统文本加载器与现代版布局感知的解析器(如
(1)理论剖析:为什么传统扁平化加载会破坏 RAG 的精度?
1. 传统文本加载器的弊端
传统的文本加载器(如标准的 TextLoader 或早期的 PDF 提取器)采用的是扁平化提取策略。它们将 PDF 或 HTML 文档中的字符从上到下像流水账一样拉直成一条没有任何格式特征的纯文本长字符串(Raw String)。
这会导致以下致命的 “上下文断链” 痛点:
- 层级拓扑丢失(Loss of Hierarchical Topology):
在原始文档中,有一句“本协议仅适用于内部微服务调用”,它处在## 4. 安全通信协议->### 4.1 生产环境范围下。扁平化提取后,这段文字可能与上文的### 3.2 联调测试环境混在一起,切片(Chunking)时一旦切断,大模型阅读到的 Chunk 就会失去## 4和### 4.1的前置定语,从而给出错误的回答。 - 语义淡化(Semantic Dilution):
标题(如H1,H2)本身承载了极大比重的全局核心语义。如果把标题混在正文中硬切,大模型在检索时无法区分“这是全局大纲”还是“这是局部的某个实例描述”。
2. 现代布局与结构感知解析器的引入
为了解决扁平化带来的信息损失,我们需要使用布局/结构感知的提取方案:
- MarkdownHeaderTextSplitter:基于 Markdown 语法标记(如
#,##,###),将文档动态拆分为物理块。最关键的是,它会把父级标题的文本内容注入到子级文本块的metadata中。 - PyMuPDF (fitz):在处理 PDF 时,可以通过提取字体大小、行高、粗细以及坐标信息,逆向还原出逻辑段落和标题,避免将双栏排版的文本错误地横向拼接。
(2)核心原理:结构化元数据注入机制
在 LangChain 1.0/0.3 体系中,一个标准的文档对象由 Document(page_content="...", metadata={...}) 组成。
结构化提取的核心思想是:“内容向下拆分,标题向上追加”。
原始 Markdown 树状结构:
# [H1] 数据库部署指南
├── ## [H2] 1. 准备工作
│ └── 文本: "检查磁盘空间是否大于 500G..."
└── ## [H2] 2. 节点配置
└── ### [H3] 2.1 主节点配置
└── 文本: "编辑 my.cnf,设置 server-id=1..."
------------------------------------------------------------------
MarkdownHeaderTextSplitter 处理后的 Document 列表:
[Document 1]
├── page_content: "检查磁盘空间是否大于 500G..."
└── metadata:
├── "Header 1": "数据库部署指南"
└── "Header 2": "1. 准备工作"
[Document 2]
├── page_content: "编辑 my.cnf,设置 server-id=1..."
└── metadata:
├── "Header 1": "数据库部署指南"
├── "Header 2": "2. 节点配置"
└── "Header 3": "2.1 主节点配置"
通过这种方式,即使 Document 2 在后续的微观切片中被切成极小的颗粒,大模型依然可以通过它的 metadata 明确得知这一段话描述的是“数据库部署指南”下的“2. 节点配置”下的“2.1 主节点配置”。
(3)实操演练:基于 MarkdownHeaderTextSplitter 提取拓扑结构
1. 准备模拟的 Markdown 文本
我们模拟一份关于企业级 Redis 架构的内部部署规范,包含 H1 到 H3 的层级结构。
安装对应的依赖:pip install langchain-text-splitters langchain-core
2. 编写 Python 解析代码
# 确保安装了最新版依赖:pip install langchain-text-splitters langchain-core
from langchain_text_splitters import MarkdownHeaderTextSplitter
# 1. 模拟复杂的企业内部 Markdown 文档
mock_markdown_document = """
# 企业级 Redis 架构部署规范
本文档定义了公司生产环境 Redis 的统一物理与逻辑拓扑标准。
## 1. 硬件资源申请指标
在申请虚拟机或物理机时,必须严格执行本节定义的硬件底线。
### 1.1 内存与 CPU 配比
* 生产主节点内存不得低于 16GB,CPU 物理核心数不得低于 4 核。
* 内存占用率预警线统一设置为 80%。
### 1.2 磁盘 IO 要求
* 必须挂载 SSD 硬盘。
* 顺序读取 IOPS 需要大于 10000。
## 2. 安全合规配置
生产环境的所有 Redis 节点必须强制开启安全审计。
### 2.1 认证与加密
* 密码复杂度必须包含:大小写字母、数字、特殊字符,且长度不少于 16 位。
* 必须在局域网内开启 TLS 传输加密。
"""
# 2. 定义我们想要捕获并作为 Metadata 注入的标题层级
# 格式为: (Markdown中的标记, Metadata中的Key)
headers_to_split_on = [
("#", "Category_L1"),
("##", "Category_L2"),
("###", "Category_L3"),
]
# 3. 初始化高阶 Markdown 结构切片器
header_splitter = MarkdownHeaderTextSplitter(
headers_to_split_on=headers_to_split_on,
strip_headers=True # 设为 True 后,内容里的 "#" 标题行会被移除,纯化为 metadata,防止冗余
)
# 4. 执行解析与切分
structured_documents = header_splitter.split_text(mock_markdown_document)
# 5. 打印并验证解析出来的结构与元数据
print(f"解析成功!共产生 {len(structured_documents)} 个结构化文档片段。 \n" + "="*50)
for idx, doc in enumerate(structured_documents):
print(f"\n[片段 {idx + 1}]")
print(f"--- 元数据 (Metadata) ---")
for k, v in doc.metadata.items():
print(f" {k} : {v}")
print(f"--- 文本内容 (Content) ---")
print(doc.page_content.strip())
print("="*50)
3. 运行输出结果解析
运行上述代码
解析成功!共产生 6 个结构化文档片段。
==================================================
[片段 1]
--- 元数据 (Metadata) ---
Category_L1 : 企业级 Redis 架构部署规范
--- 文本内容 (Content) ---
本文档定义了公司生产环境 Redis 的统一物理与逻辑拓扑标准。
==================================================
[片段 2]
--- 元数据 (Metadata) ---
Category_L1 : 企业级 Redis 架构部署规范
Category_L2 : 1. 硬件资源申请指标
--- 文本内容 (Content) ---
在申请虚拟机或物理机时,必须严格执行本节定义的硬件底线。
==================================================
[片段 3]
--- 元数据 (Metadata) ---
Category_L1 : 企业级 Redis 架构部署规范
Category_L2 : 1. 硬件资源申请指标
Category_L3 : 1.1 内存与 CPU 配比
--- 文本内容 (Content) ---
* 生产主节点内存不得低于 16GB,CPU 物理核心数不得低于 4 核。
* 内存占用率预警线统一设置为 80%。
==================================================
[片段 4]
--- 元数据 (Metadata) ---
Category_L1 : 企业级 Redis 架构部署规范
Category_L2 : 1. 硬件资源申请指标
Category_L3 : 1.2 磁盘 IO 要求
--- 文本内容 (Content) ---
* 必须挂载 SSD 硬盘。
* 顺序读取 IOPS 需要大于 10000。
==================================================
[片段 5]
--- 元数据 (Metadata) ---
Category_L1 : 企业级 Redis 架构部署规范
Category_L2 : 2. 安全合规配置
--- 文本内容 (Content) ---
生产环境的所有 Redis 节点必须强制开启安全审计。
==================================================
[片段 6]
--- 元数据 (Metadata) ---
Category_L1 : 企业级 Redis 架构部署规范
Category_L2 : 2. 安全合规配置
Category_L3 : 2.1 认证与加密
--- 文本内容 (Content) ---
* 密码复杂度必须包含:大小写字母、数字、特殊字符,且长度不少于 16 位。
* 必须在局域网内开启 TLS 传输加密。
==================================================
进程已结束,退出代码为 0
4. 深度总结:为什么这对后续开发至关重要?
观察上面的片段 3:
其正文内容完全没有提到“Redis”和“部署规范”这几个词。如果在传统的扁平提取模式下,这段文字一旦被送入向量库进行检索,当用户提问:“Redis 的密码复杂度有什么要求?”时,这段话很可能会因为缺乏“Redis”这一语义锚点而无法被召回。
但是,通过我们的结构化提取:
- 元数据中牢牢绑定了
Category_L1: 企业级 Redis 架构部署规范。 - 在第二节构建向量库时,我们会将
metadata与page_content合并向量化(或将 metadata 作为检索过滤器 Filter),确保大模型能够实现上下文精准匹配。
(4) 避坑指南与最佳实践
- 小心“空节点”:在 Markdown 文档中,如果有形如
# 标题 1后面直接紧跟## 标题 2的情况(中间没有任何文字),有些切片器会产生空的 Document 对象。新版MarkdownHeaderTextSplitter已经默认过滤了这些空节点,但仍建议在代码中进行长度校验。 - 混合媒体与图片:Markdown 中的
标签。如果需要保留图片引用,注意确保切割边界不会直接破坏图片 URL。
(5)扩展:Word和PDF格式一般怎么清洗
关于Word通常采用格式转换链的方式
Word 文档 (.docx) ──(使用 Mammoth 或 pandoc 转换)──> 干净的 Markdown 文本 ──> MarkdownHeaderTextSplitter
而PDF则是通过PyMuPDF进行处理,这是目前公认最好的PDF解析库,如果要求比较高,则使用PyMuPDF4LLM更加的高级,当然要是要求更高可以使用原生 fitz,相当于用js手搓一个el-input,根据需求选择不同的方式。
1.2 语义边界切分 (SemanticChunker)
- 目标:彻底丢弃生硬的、按字符数或 Token 数暴力强切的旧手段,学会使用语义相似度探测段落边界,让知识分块在逻辑上保持完整。
- 内容:
- 剖析
SemanticChunker的底层逻辑:利用 Embedding 向量计算相邻句子间的余弦相似度,根据相似度变化的梯度断点(支持 Percentile、Standard Deviation 等阈值类型)来判定分块边界。 - 学习在 Python 侧配置不同的相似度计算阈值,以及选择合适的本地或在线 Embedding 模型进行边界探测。
- 实操:对比
RecursiveCharacterTextSplitter与SemanticChunker对同一段复杂技术规范文档的切分结果,可视化证明语义切分如何避免“一句话没说完就被劈成两半”的硬伤。
- 剖析
(1)底层逻辑与数学原理
传统切片器(如 RecursiveCharacterTextSplitter)在切分时像一个拿着卷尺的裁缝,只关心“切片是否达到了 500 个字符”,而不关心这一剪刀下去是否把一个完整的逻辑劈成了两半。
SemanticChunker(语义分块器)则像一个正在阅读文档的专家,它通过监控上下文语义的变化,在“话题发生转换”的地方优雅地切刀。
1. 相似度悬崖(Similarity Cliff)探测机制
语义边界切分的底层运行机制可以拆解为以下四个数学步骤:
原始文本 -> 拆分为单句 [S1, S2, S3, S4, S5]
│
▼ 向量化 (Embedding)
坐标数组 [V1, V2, V3, V4, V5]
│
▼ 计算相邻句子间的余弦相似度 (Cosine Similarity)
[Sim(1,2), Sim(2,3), Sim(3,4), Sim(4,5)]
│
▼ 计算相似度的差值 (Gradients)
[Diff_1, Diff_2, Diff_3, Diff_4] ──(超过阈值?)──> 在该断点切分
- 句子级拆分:首先,利用正则表达式或 NLP 工具(如
Spacy、NLTK)将输入的整篇大文档拆分为独立的、颗粒度极细的单句列表 [ S 1 , S 2 , … , S n ] [S_1, S_2, \dots, S_n] [S1,S2,…,Sn]。 - 多维向量化:将这些单句全部送入指定的 Embedding 模型中,转化为高维语义空间中的坐标向量 [ V 1 , V 2 , … , V n ] [V_1, V_2, \dots, V_n] [V1,V2,…,Vn]。
- 滑动夹角计算:计算相邻两个句子向量之间的余弦相似度 S i m i l a r i t y ( V i , V i + 1 ) Similarity(V_i, V_{i+1}) Similarity(Vi,Vi+1)。
- 差异梯度分析:计算相似度的变化差值(距离)。如果 S i m i l a r i t y ( V 2 , V 3 ) Similarity(V_2, V_3) Similarity(V2,V3) 突然相比前几句出现断崖式下跌,说明第 2 句和第 3 句之间发生了剧烈的话题转换,这里就会被判定为相似度悬崖Similarity Cliff,系统会在此处切刀。
2. 四大断裂阈值类型(Breakpoint Threshold Types)
如何科学地定义“相似度下跌到什么程度才算悬崖”?LangChain 提供了四种阈值判定数学模型:
- Percentile(百分位数法,默认):
计算相邻句子之间所有相似度差值,并对其进行排序。设定一个百分位数(如 95%)。只有当某两个相邻句子的语义差值大于 95% 的历史差值时,才执行切分。适合文章结构松散、话题多变的场景。 - Standard Deviation(标准差法):
计算所有相似度差值的均值与标准差。当某个断点的相似度跌幅超过“均值 + X X X 倍标准差”时,触发切分。适合排版严谨、学术或行业标准规范类文档。 - Interquartile(四分位距法):
利用统计学中的四分位距(IQR)来寻找差值序列中的“异常值(Outliers)”。一旦某个相邻句子的语义突变度被判定为异常高的离群值,即进行切分。 - Gradient(梯度法):
监控相似度变化斜率。当斜率的绝对值在极短时间内发生剧烈突变时进行切分,适合检测长篇叙事文档中突发的故事转折。
(2)代码实战:构建 SemanticChunker 管道
下面我们在本地构建一个完整的、基于语义边界的切片流水线。为了确保环境在局域网下可控,我们将同时展示本地轻量化 Embedding 与 在线 Embedding 的接入方案。
1. 开发环境依赖配置
# 必须安装 langchain_experimental 包(语义切片器当前托管于此)
pip install langchain-experimental langchain-text-splitters
# HuggingFaceEmbeddings依赖sentence-transformers
pip install sentence-transformers
# 安装 Embedding 支持(二选一:本地选 huggingface,在线选 openai)
pip install langchain-huggingface langchain-openai
2. 完整 Python 实战代码
在这个案例中,我们准备了一段话题发生了剧烈跳转的文本(前段在讨论 Redis 主从复制,后段突然跳转到了 HTTP 协议状态码),来看看 SemanticChunker 能否在没有任何规则引导下,自动在交界处切刀。
import os
from langchain_experimental.text_splitter import SemanticChunker
# ==========================================
# 步骤 1:初始化 Embedding 模型(这里以本地模型为例)
# ==========================================
# 方案 A:使用本地轻量级开源向量模型(无需 API Key,局域网友好)
from langchain_huggingface import HuggingFaceEmbeddings
print("正在加载本地 Embedding 模型...")
embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
# 方案 B:使用 OpenAI 向量模型(需配置环境变量)
# from langchain_openai import OpenAIEmbeddings
# os.environ["OPENAI_API_KEY"] = "your-key"
# embeddings = OpenAIEmbeddings()
# ==========================================
# 步骤 2:准备待清洗切片的原始文本
# ==========================================
# 这段文本在“6379”与“在Web世界中”之间发生了彻底的话题跨越
raw_text = """
Redis 的主从复制是高可用架构的基石。主节点负责执行写操作,并通过异步复制的方式将数据同步给所有的从节点。
默认情况下,从节点只提供只读服务,这可以极大地分担主节点的读请求压力。
在网络抖动或闪断时,从节点会自动尝试重新连接并进行增量同步。
Redis 默认使用的通信端口是 6379。
在 Web 的世界中,HTTP 协议规定了客户端与服务端之间的请求与响应规范。
常见的 HTTP 状态码有 200 OK,代表请求已成功处理。
而 404 Not Found 则代表服务器无法找到请求的资源。
为了系统的安全合规,建议对所有向外暴露的接口强制启用 HTTPS 传输加密协议。
"""
# ==========================================
# 步骤 3:初始化语义切片器(采用标准差阈值模式)
# ==========================================
semantic_splitter = SemanticChunker(
embeddings,
breakpoint_threshold_type="standard_deviation", # 选用标准差法
breakpoint_threshold_amount=1.2 # 相似度差异超过1.2倍标准差时切分
)
# ==========================================
# 步骤 4:执行语义切分
# ==========================================
chunks = semantic_splitter.create_documents([raw_text])
# ==========================================
# 步骤 5:输出验证结果
# ==========================================
print(f"\n解析完成!原始长文本被成功分割为 {len(chunks)} 个语义分块。")
print("="*60)
for idx, chunk in enumerate(chunks):
print(f"[语义 Chunk {idx + 1}]")
print(chunk.page_content.strip())
print("-" * 60)
3. 运行输出结果与验证
在控制台中运行上述代码,将观察到如下输出结果:(如果是第一次运行的话)
C:\pythonProjects\PythonProject\agent-study-3\test_chunk_01.py:2: DeprecationWarning: `langchain-experimental` is being sunset and is no longer actively maintained. See https://github.com/langchain-ai/langchain-experimental/issues/87 for details.
from langchain_experimental.text_splitter import SemanticChunker
正在加载本地 Embedding 模型...
Warning: You are sending unauthenticated requests to the HF Hub. Please set a HF_TOKEN to enable higher rate limits and faster downloads.
C:\Users\19355\miniconda3\Lib\site-packages\huggingface_hub\file_download.py:138: UserWarning: `huggingface_hub` cache-system uses symlinks by default to efficiently store duplicated files but your machine does not support them in C:\Users\19355\.cache\huggingface\hub\models--sentence-transformers--all-MiniLM-L6-v2. Caching files will still work but in a degraded version that might require more space on your disk. This warning can be disabled by setting the `HF_HUB_DISABLE_SYMLINKS_WARNING` environment variable. For more details, see https://huggingface.co/docs/huggingface_hub/how-to-cache#limitations.
To support symlinks on Windows, you either need to activate Developer Mode or to run Python as an administrator. In order to activate developer mode, see this article: https://docs.microsoft.com/en-us/windows/apps/get-started/enable-your-device-for-development
warnings.warn(message)
Loading weights: 100%|██████████| 103/103 [00:00<00:00, 13998.68it/s]
这两段只是警告而已,不影响代码的正常运行,表达的含义是:
- 从 Hugging Face Hub 官方仓库下载模型,因为我们是匿名形式,官方会限制下载速率,但是因为这个模型很小,所以无所谓,可以选择使用
os.environ["HF_HUB_DISABLE_SYMLINKS_WARNING"] = "1"来抑制此警告。 - Hugging Face 默认采用“符号链接(symlinks,即快捷方式)”来管理本地的模型缓存,以节省磁盘空间,但window需要管理员权限,所以也无所谓,无非是多占一点空间。
接下来继续运行,可以看到:
解析完成!原始长文本被成功分割为 1 个语义分块。
============================================================
[语义 Chunk 1]
Redis 的主从复制是高可用架构的基石。主节点负责执行写操作,并通过异步复制的方式将数据同步给所有的从节点。
默认情况下,从节点只提供只读服务,这可以极大地分担主节点的读请求压力。
在网络抖动或闪断时,从节点会自动尝试重新连接并进行增量同步。
Redis 默认使用的通信端口是 6379。
在 Web 的世界中,HTTP 协议规定了客户端与服务端之间的请求与响应规范。
常见的 HTTP 状态码有 200 OK,代表请求已成功处理。
而 404 Not Found 则代表服务器无法找到请求的资源。
为了系统的安全合规,建议对所有向外暴露的接口强制启用 HTTPS 传输加密协议。
------------------------------------------------------------
进程已结束,退出代码为 0
注意了,预期是两块,现在只有一块。
核心原因是中英文排版差异,LangChain 在 SemanticChunker 底层使用了一个默认的正则表达式:
sentence_split_regex = r"(?<=[.?!])\s+"
- 这个正则的意思是:寻找英文句号 .、问答号 ?、感叹号 !,且必须在它们后面紧跟一个或多个空格(\s+),才判定为一句话的结束。
- 中文排版的致命冲突:
在中文排版中,我们使用全角句号 。、问号 ?、感叹号 !,并且中文句号后面从来不写空格!
即便中文文本里夹杂了英文标点,只要标点后面没有空格,这个默认的正则就无法匹配到任何句尾。 - 修改默认的正则匹配:
semantic_splitter = SemanticChunker(
embeddings,
breakpoint_threshold_type="standard_deviation",
breakpoint_threshold_amount=1.2,
sentence_split_regex=r"(?<=[。?!.?!])" # <--- 支持中英文混合断句
)
如果跟着跑一遍,那结果虽然有两块,但是第二块是空的
- 这是因为目前我们使用的是纯英文模型,如果是中文则需要使用国内的模型。纯英文模型会把中文都识别为乱码,所以从语义上来说都是一个意思,也就只有一块了。
- 但是有一个空的chunk,这是因为原文有空格,这时候需要手动进行去除,影响不大,所以修改后的代码就是
import os
os.environ["HF_HUB_DISABLE_SYMLINKS_WARNING"] = "1"
from langchain_experimental.text_splitter import SemanticChunker
from langchain_huggingface import HuggingFaceEmbeddings
# =======================================================
# 核心修正 1:切换为专业的中文向量模型 BAAI/bge-small-zh-v1.5
# =======================================================
print("正在加载智源中文 Embedding 模型 (bge-small-zh-v1.5)...")
embeddings = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh-v1.5")
# 原始中文文本(并在最尾部执行 strip 防止空行干扰)
raw_text = """
Redis 的主从复制是高可用架构的基石。主节点负责执行写操作,并通过异步复制的方式将数据同步给所有的从节点。
默认情况下,从节点只提供只读服务,这可以极大地分担主节点的读请求压力。
在网络抖动或闪断时,从节点会自动尝试重新连接并进行增量同步。
Redis 默认使用的通信端口是 6379。
在 Web 的世界中,HTTP 协议规定了客户端与服务端之间的请求与响应规范。
常见的 HTTP 状态码有 200 OK,代表请求已成功处理。
而 404 Not Found 则代表服务器无法找到请求的资源。
为了系统的安全合规,建议对所有向外暴露的接口强制启用 HTTPS 传输加密协议。
""".strip() # <--- 核心修正 2:去除尾部多余的换行符
# =======================================================
# 核心修正 3:优化断句正则,防止尾部空字符串溢出
# =======================================================
semantic_splitter = SemanticChunker(
embeddings,
breakpoint_threshold_type="standard_deviation",
breakpoint_threshold_amount=1.0, # 适当调低标准差阈值,使切分更敏感
sentence_split_regex=r"(?<=[。?!.?!])" # 支持中文断句
)
# 执行语义分块
chunks = semantic_splitter.create_documents([raw_text])
# =======================================================
# 核心修正 4:过滤可能产生的空分块
# =======================================================
valid_chunks = [chunk for chunk in chunks if chunk.page_content.strip()]
print(f"\n解析完成!原始长文本被成功分割为 {len(valid_chunks)} 个有效的语义分块。")
print("="*60)
for idx, chunk in enumerate(valid_chunks):
print(f"[语义 Chunk {idx + 1}]")
print(chunk.page_content.strip())
print("-" * 60)
到这里就结束了吗?不然,实际上运行之后结果还是一块,这是因为现在使用的标准差算法不适合短文本,样本量太小了,所以我们尝试使用基于排序的“百分位数(Percentile)”模式
import os
os.environ["HF_HUB_DISABLE_SYMLINKS_WARNING"] = "1"
import re
from langchain_experimental.text_splitter import SemanticChunker
from langchain_huggingface import HuggingFaceEmbeddings
# 原始测试文本
raw_text = """
Redis 的主从复制是高可用架构的基石。主节点负责执行写操作,并通过异步复制的方式将数据同步给所有的从节点。
默认情况下,从节点只提供只读服务,这可以极大地分担主节点的读请求压力。
在网络抖动或闪断时,从节点会自动尝试重新连接并进行增量同步。
Redis 默认使用的通信端口是 6379。
在 Web 的世界中,HTTP 协议规定了客户端与服务端之间的请求与响应规范。
常见的 HTTP 状态码有 200 OK,代表请求已成功处理。
而 404 Not Found 则代表服务器无法找到请求的资源。
为了系统的安全合规,建议对所有向外暴露的接口强制启用 HTTPS 传输加密协议。
""".strip()
# =======================================================
# 【调试诊断 1/3】验证正则是否成功将文本拆分为单句
# =======================================================
print("--- [调试诊断 1/3] 验证正则断句结果 ---")
sentence_regex = r"(?<=[。?!.?!])"
sentences = [s.strip() for s in re.split(sentence_regex, raw_text) if s.strip()]
print(f"成功将文本拆分为 {len(sentences)} 个单句:")
for i, s in enumerate(sentences):
print(f" 句子 {i+1}: {s}")
print("="*60)
# =======================================================
# 【调试诊断 2/3] 加载智源中文 Embedding 模型
# =======================================================
print("\n--- [调试诊断 2/3] 加载 Embedding 模型 ---")
embeddings = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh-v1.5")
# =======================================================
# 【调试诊断 3/3】切换为百分位数算法 (Percentile)
# =======================================================
print("\n--- [调试诊断 3/3] 运行百分位数语义切分 ---")
semantic_splitter = SemanticChunker(
embeddings,
breakpoint_threshold_type="percentile", # <--- 核心修正:切换为百分位数法
breakpoint_threshold_amount=65, # <--- 核心修正:超过 60% 相似度差值即切分(适合短文本)
sentence_split_regex=sentence_regex
)
chunks = semantic_splitter.create_documents([raw_text])
valid_chunks = [chunk for chunk in chunks if chunk.page_content.strip()]
print(f"\n解析完成!成功分割为 {len(valid_chunks)} 个有效的语义分块。")
print("="*60)
for idx, chunk in enumerate(valid_chunks):
print(f"[语义 Chunk {idx + 1}]")
print(chunk.page_content.strip())
print("-" * 60)
经过不断的测试发现,在短文本中很难实现标准的切片,这是业内的通病,数据太少了,算法也很难兼容。
所以说有两种解决方式:
- 第一种:暴力一点,短文本就切一块,费一点Token就费一点吧。
- 第二种:这种技术文档一般是通过业内大多数大佬修改的,我们可以尝试直接用标题和格式区分,语义我们已经进行了切割了,而且能保证分开,不会出现上面那种格式。
通过这个例子也能说明一个问题,有些场景需要经过测试你才能遇到,在这个过程中你所收获的可比纯听课多多了,还是期待大家手动运行一下,感受过程中出现的问题。
🔍 结果深度验证:
没有任何硬编码的规则(比如我们没有告诉它遇到 Web 切断),SemanticChunker 敏锐地察觉到 6379。 与 在 Web 的世界中 之间的向量余弦相似度极低。两句话之间的语义突变度跨越了 1.2 倍标准差,因此切刀被精准安置在此处。
这里不演示四种断裂阈值,在真正业务需求的时候在查询使用
(3)性能评估与核心痛点避坑
尽管 SemanticChunker 堪称 RAG 切片器的智能化巅峰,但在实际企业级系统落地中,它有其必须要妥协的物理局限性。
1. 痛点:算力开销与冷启动延迟
- 物理本质:在切片时,
SemanticChunker需要把文档中的每一个单句都调用一次 Embedding 模型进行向量化。 - 后果:如果导入一篇 100 万字的巨型 PDF,将会产生几万个单句。此时如果使用的是在线 API(如 OpenAI),由于高频 HTTP 请求,会面临网络延迟,并消耗巨大的 API 计费;如果是本地 CPU 运行的 Embedding,会直接把 CPU 跑满,导致 ETL 数据入库极其缓慢。
- 避坑指南:对于海量历史文档的初始化入库(Batch ETL),不建议在实时主线程中同步使用
SemanticChunker。推荐将其做成异步后台 Job(如使用 Celery 或 Java 端的调度器调度 Python 脚本),慢慢清洗。
注意:当前我们测试的是一个很小的本地模型,输入的数据量和处理的速度有明显的限制,如果说后期需要真正的企业落地,最方便的还是云服务,阿里就自带RAG数据库服务,且可以进行个性化的清洗。
如果真的要进行本地清洗,成本太高了,一个7B的模型就得12G显存,14B就得24了,如果有钱可以租一个,但自己电脑就别折腾了,毕竟我们的笔记本学名是:微型计算机。
2. 痛点:段落过短的“小碎片”问题
- 物理本质:如果文档中包含一些简短的技术参数列表(如“作者:张三 \n 版本:1.0 \n 日期:2026”),因为这些短句句意跳跃极大,
SemanticChunker会频繁切刀,产生大量只有 5~10 个字符的“极小碎片”。 - 后果:极小碎片的检索精度极差(因为信息量不足),同时会污染向量数据库。
- 避坑指南:在将文本送入
SemanticChunker之前,必须进行第一节学过的噪音清洗。同时,可以通过限制切片后的最小字符数,对过小的碎片进行逻辑合并。
1.3 父子文档关联检索 (ParentDocumentRetriever)
- 目标:掌握生产级 RAG 的核心武器:检索时使用细粒度子分块确保匹配精度,喂给大模型时还原为粗粒度父文档以提供完整的阅读上下文。
- 内容:
- 深入分析 RAG 系统中的“Goldilocks 两难问题”:切片太小,检索精准但上下文碎片化导致 LLM 无法回答;切片太大,语义被稀释检索不精准。
- 学习
ParentDocumentRetriever的底层存储拓扑:向量数据库(如 Milvus)仅存储细粒度子文档向量,而 KV 存储(如InMemoryStore/LocalFileStore或 Redis)存储粗粒度父文档全文,通过唯一的parent_id进行映射关联。 - 实操:利用内存 Docstore 与基础向量检索器,构建一个完整的 Parent-Child 检索流水线,验证“用细粒度子句提问,却能召回完整父段落”的工程效果。
(1)底层设计与解耦哲学
在构建高精度的 RAG 系统时,工程人员经常会陷入一种两难的境地。这种矛盾的本质是:检索单元与生成单元在最适尺寸上的天然冲突。
这句话怎么理解,检索单元指的是切片后那一段一段的小片段,而生成单元则是给大模型提供的完整文档,因为分块的内容总会有一些细节容易缺失。
1. 检索精度与上下文完整性的两难境地
- 微观切片的特征(50~200 字):
由于分块极小,其语义密度极高,能够精准对应某一个具体的细节问题(例如某个配置参数的具体数值)。但是,大模型拿到它时,会因为缺乏前后上下文,不知道这段配置到底是在什么系统环境下生效的,从而产生“瞎子摸象”般的断章取义。 - 宏观切片的特征(2000~5000 字):
上下文非常完整,业务脉络清晰。但由于文本过长,其向量表达(Embedding)被严重稀释。当用户提问非常具体时,这种大切片在向量库中的匹配得分通常很低,导致大模型根本检索不到它。
2. 解耦架构:向量检索层与文档存储层的双轨设计
ParentDocumentRetriever(父子文档关联检索器)的诞生,从底层优雅地打破了这个死结。它的核心哲学是:检索归检索,阅读归阅读,两者彻底解耦(Decoupling)。
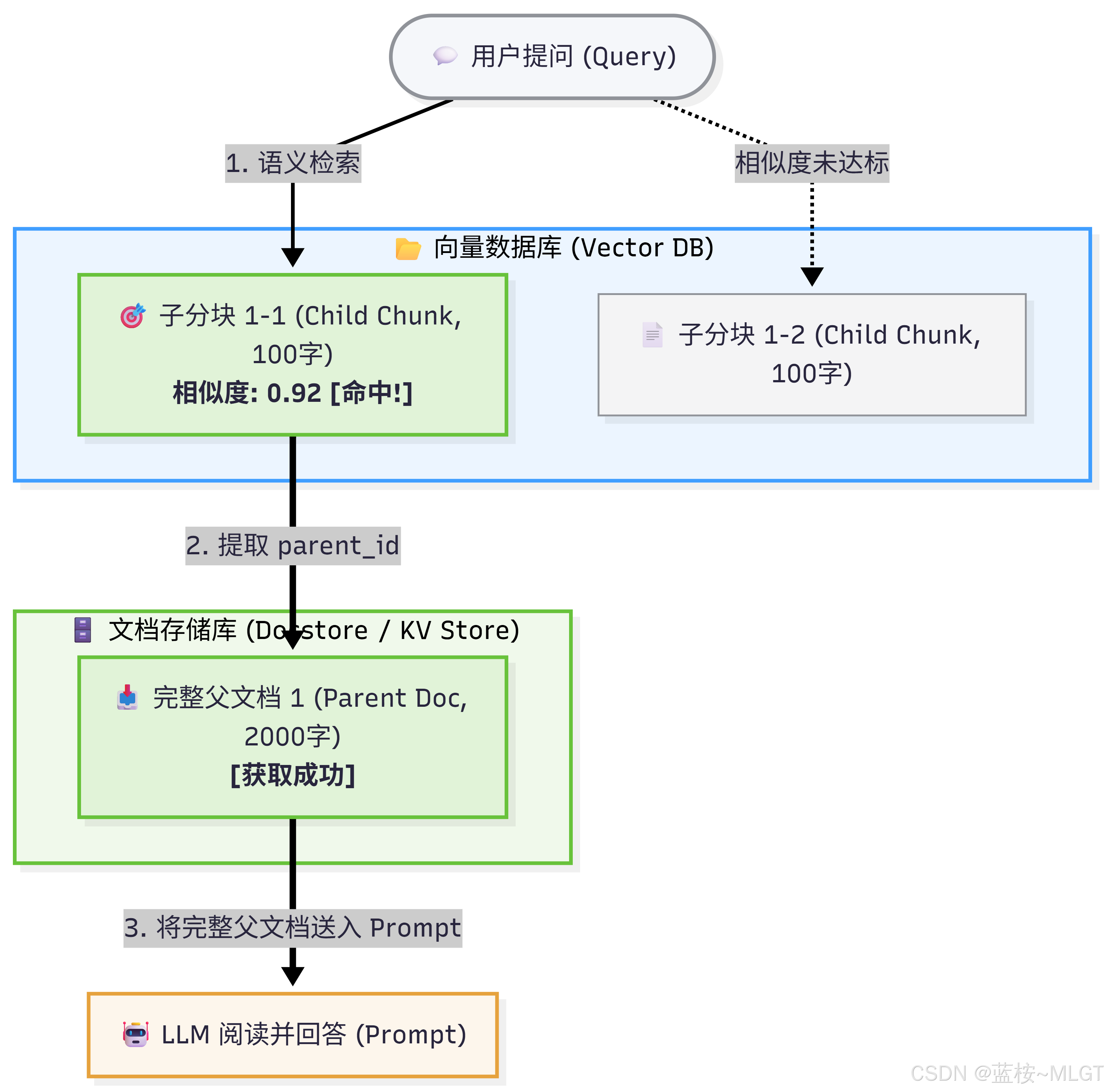
在系统初始化时,文档的处理链路如下:
- 父分块(或原文档):将海量原始文档保留为较大的父分块(如 2000 字),并为其分配一个全局唯一的
parent_id。这些大分块只存入一个快速的键值(KV)存储系统(如 Redis、本地持久化文件或内存 Store),不进行向量化。 - 子分块:在父分块内部,使用精细的切片器切成极小的子分块(如 100~200 字)。每一个子分块的
metadata里,都会强行写入其归属的parent_id。这些子分块被输入给 Embedding 模型,并存入向量数据库。 - 关联检索:当用户提问时,系统去向量库里对“子分块”进行相似度检索。一旦命中了某个子分块,系统并不直接返回这个子片段,而是顺着它的
metadata['parent_id'],瞬时去 KV 存储系统中把完整的、拥有丰富上下文的父分块捞出来,作为 Context 送给大模型进行阅读。
(2)代码实战:构建父子关联检索器
下面我们使用本地已下载的智源中文 Embedding 模型,构建一个完整的父子文档关联检索系统。
1. 依赖配置与拓扑设计
本实战采用 Chroma 作为向量数据库(存子分块),使用 LangChain 内置的 InMemoryStore 作为文档存储库(存父文档)。
# 安装轻量级本地向量库依赖
pip install langchain-chroma
2. 完整 Python 实战代码
我们将输入一篇关于“企业数据备份与恢复规范”的长文档,来验证此机制的实际运作。
import os
os.environ["HF_HUB_DISABLE_SYMLINKS_WARNING"] = "1"
from langchain_core.documents import Document
from langchain_core.stores import InMemoryStore
from langchain_chroma import Chroma
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_classic.retrievers import ParentDocumentRetriever
# 1. 准备大段的企业级原始文档(父文档)
raw_docs = [
Document(
page_content="""
[核心制度] 企业级主数据备份与灾难恢复规范(版本 2026.1)
1. 数据备份策略
本公司所有核心生产数据库必须强制执行每日全量备份。全量备份的时间统一设定在每日凌晨 2:00 进行。
备份数据必须同时写入本地存储与阿里云 OSS 归档存储(实现双活异地备份)。
所有全量备份数据的保留期限统一设置为 180 天,超期的归档数据将由后台脚本定时自动清理。
2. 灾难恢复演练
为了验证备份数据的可用性,运维团队必须在每季度首月的第一个周日开展生产级灾难恢复演练。
RTO(恢复时间目标)必须保证在 30 分钟以内。
RPO(恢复点目标)必须保证在 2 小时以内。
演练过程必须保留完整的日志记录,并由安全合规团队签字审计后方可封档。
""",
metadata={"category": "IT-Security-Compliance"}
)
]
# 2. 初始化中文 Embedding 模型(复用本地缓存)
print("正在加载智源中文 Embedding 模型 (bge-small-zh-v1.5)...")
embeddings = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh-v1.5")
# 3. 设计双层切片规则
# 3.1 父分块器:尺寸较大(如 2000 字),保留完整段落和上下文关系
parent_splitter = RecursiveCharacterTextSplitter(chunk_size=2000, chunk_overlap=0)
# 3.2 子分块器:尺寸极小(如 80 字),确保局部语义特征极度鲜明
child_splitter = RecursiveCharacterTextSplitter(chunk_size=80, chunk_overlap=0)
# 4. 初始化底层的存储引擎
# 4.1 向量存储层:只存子分块的向量坐标(使用内存型 Chroma 向量库)
vectorstore = Chroma(
collection_name="split_parents",
embedding_function=embeddings
)
# 4.2 文档存储层:存储未经向量化的父文档全文(使用内存 KV 键值库)
store = InMemoryStore()
# 5. 构建父子关联检索器 (ParentDocumentRetriever)
retriever = ParentDocumentRetriever(
vectorstore=vectorstore,
docstore=store,
child_splitter=child_splitter,
parent_splitter=parent_splitter, # 如果设为 None,则直接存储完整的原文档
)
# 6. 将原始文档输入检索器(此时后台会自动执行双层切分、分配 parent_id 并入库)
print("正在执行双层切分与存储绑定...")
retriever.add_documents(raw_docs)
# 7. 检索测试
print("\n=== 开始模拟检索 ===")
# 我们提一个非常具体、细微的技术问题
query = "备份演练的 RPO 指标要求是多少?"
# 7.1 直接用向量库进行底层检索(看看子分块长什么样)
print("\n--- [对比 1] 向量库底层直接检索出的子分块 (Child Chunk) ---")
direct_sub_chunks = vectorstore.similarity_search(query, k=1)
for i, doc in enumerate(direct_sub_chunks):
print(f"子分块内容: \n{doc.page_content.strip()}")
print(f"元数据: {doc.metadata}")
# 7.2 用 ParentDocumentRetriever 进行检索(看看最终返回什么给大模型)
print("\n--- [对比 2] ParentDocumentRetriever 最终召回的父文档 (Parent Doc) ---")
retrieved_parent_docs = retriever.invoke(query)
for i, doc in enumerate(retrieved_parent_docs):
print(f"父文档内容: \n{doc.page_content.strip()}")
print(f"元数据: {doc.metadata}")
3. 运行过程分析与原理解读
运行上述脚本后,控制台的输出完美展现了解耦检索的魅力:
正在加载智源中文 Embedding 模型 (bge-small-zh-v1.5)...
Warning: You are sending unauthenticated requests to the HF Hub. Please set a HF_TOKEN to enable higher rate limits and faster downloads.
Loading weights: 100%|██████████| 71/71 [00:00<00:00, 7271.82it/s]
正在执行双层切分与存储绑定...
=== 开始模拟检索 ===
--- [对比 1] 向量库底层直接检索出的子分块 (Child Chunk) ---
子分块内容:
RTO(恢复时间目标)必须保证在 30 分钟以内。
RPO(恢复点目标)必须保证在 2 小时以内。
元数据: {'category': 'IT-Security-Compliance', 'doc_id': 'dfc47e4e-56ad-40b4-abf9-63b9eb0d18a5'}
--- [对比 2] ParentDocumentRetriever 最终召回的父文档 (Parent Doc) ---
父文档内容:
[核心制度] 企业级主数据备份与灾难恢复规范(版本 2026.1)
1. 数据备份策略
本公司所有核心生产数据库必须强制执行每日全量备份。全量备份的时间统一设定在每日凌晨 2:00 进行。
备份数据必须同时写入本地存储与阿里云 OSS 归档存储(实现双活异地备份)。
所有全量备份数据的保留期限统一设置为 180 天,超期的归档数据将由后台脚本定时自动清理。
2. 灾难恢复演练
为了验证备份数据的可用性,运维团队必须在每季度首月的第一个周日开展生产级灾难恢复演练。
RTO(恢复时间目标)必须保证在 30 分钟以内。
RPO(恢复点目标)必须保证在 2 小时以内。
演练过程必须保留完整的日志记录,并由安全合规团队签字审计后方可封档。
元数据: {'category': 'IT-Security-Compliance'}
进程已结束,退出代码为 0
🔍 代码原理解析:
- 在 [对比 1] 中,底层的向量库只命中了非常窄的子分块(包含 RTO 和 RPO 的两句话)。如果在真实的 RAG 架构中,只把这段话丢给 LLM,LLM 可能会无法回答“这是哪份制度的要求?”或“是哪个团队去执行演练?”因为这些信息写在段落的前半部分,已经超出了子分块的范围。
- 在 [对比 2] 中,由于子分块元数据中带有隐藏的
doc_id,检索器自动将其映射到了内存库中的父文档。大模型最终拿到的是连贯、完整、结构分明的 IT 备份规范全文。这种检索方案兼顾了向量匹配的敏锐度与大模型阅读的舒适度。
(3)生产环境避坑与演进思考
在将父子关联检索器推向生产级 JVM/Python 混合微服务架构时,需要注意以下两点:
1. 内存溢出(OOM)风险与分布式 Docstore 升级
- 痛点:本案中我们使用的是
InMemoryStore(),这意味着所有庞大的原始父文档全文全部直接堆积在 Python 的运行内存(RAM)中。在多用户、千万级文档的企业级应用中,这会导致 Python 进程内存暴涨,直至发生 OOM 崩溃。 - 演进:在真实生产中,绝不能使用
InMemoryStore。可以选择使用RedisStore或SQLDocstore(以 PostgreSQL / MySQL 作为后台存储)。 - 在 Python 侧,LangChain 可以非常方便地将
docstore配置为RedisStore。Python 只负责通过 Redis 连接池存取,内存占用极低,且具备天然的水平扩展能力。
2. 子分块重叠度(Overlap)的艺术
- 原理:在设置子分块的
child_splitter时,我们需要注意设置合理的chunk_overlap。 - 如果重叠度设为 0,刚好处于边界的词汇在进行 Embedding 提取时会发生特征断层。因此,即使是子分块,通常也建议设置 10 % ∼ 20 % 10\% \sim 20\% 10%∼20% 的重叠区域,防止边界语义丢失。
3. 旁路缓存模式
思考一下,在上面的例子中是用
InMemoryStore()作为文档存储层,那有没有想过,如果文档太多,即使替换为Redis那也不太行吧,Redis内存也很贵啊。所以就衍生出了一个模式,旁路缓存模式
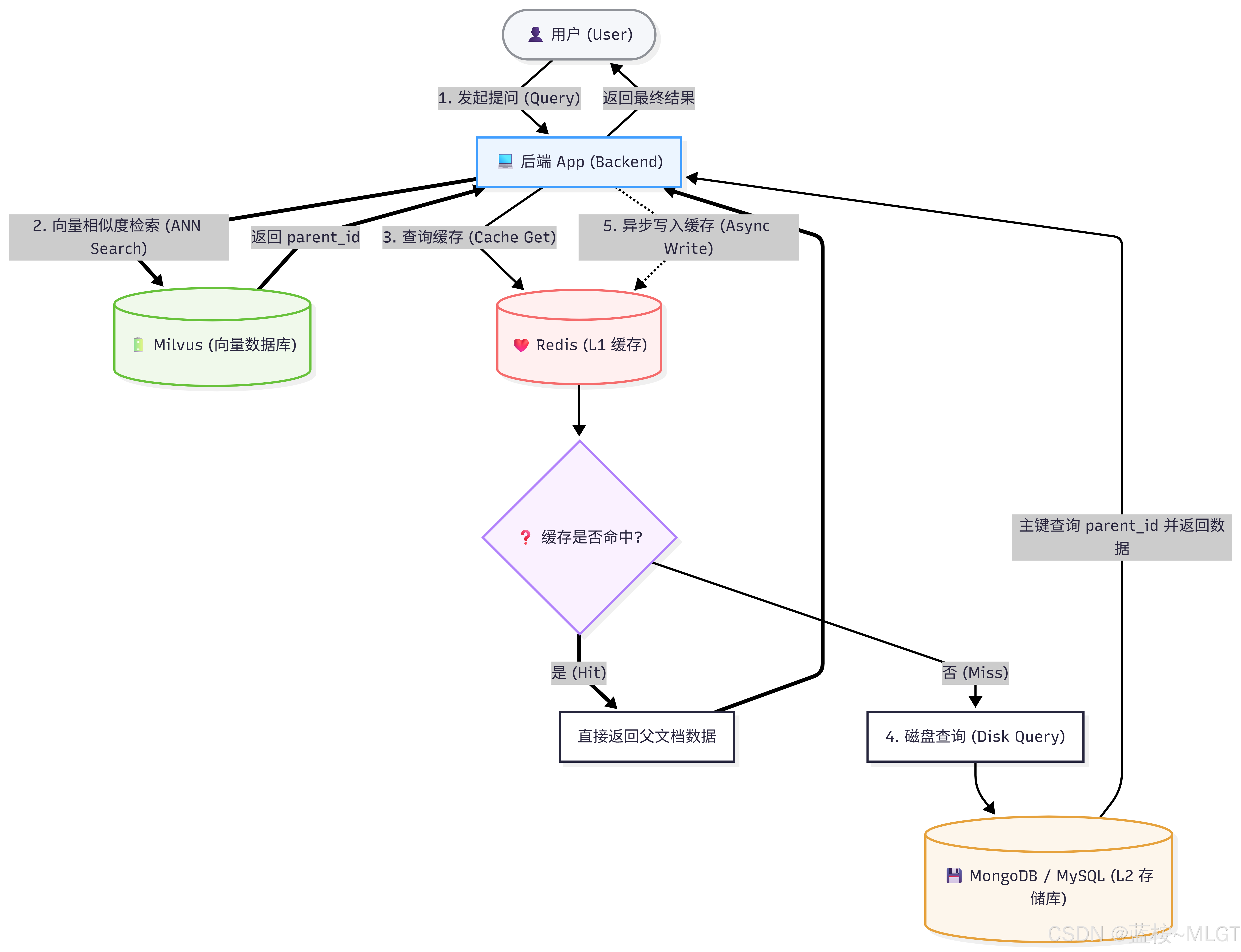
这种模式属于非常经典的一种,中间层加缓存,实现速度和成本的中和。正常在web开发中我们也会进行Redis缓存的技术,比如人员和部门数据,当有几万人的时候每次从数据库查询压力也比较大,而且人员的操作频率是比较低的,所以会加入缓存机制。
4. 双引擎存储拓扑
这个词儿听起来很高级吧,实际上原理就是上面所说的父级块和子块存储的位置不同而已,一个是向量数据库,一个在关系/文档数据库。
| 维度 | 子分块(Child Chunks) | 父分块(Parent Chunks) |
|---|---|---|
| 物理存储引擎 | 向量数据库(如 Milvus、Chroma、Qdrant) | 文档/关系型数据库(如 MongoDB、MySQL、S3对象存储) |
| 存储的数据内容 | 1. 768维/1536维的高维向量坐标(Floats) 2. 极简的元数据(Metadata,仅包含 parent_id) |
1. 未经向量化的纯文本全文(Raw Text / Markdown) 2. 业务标签、版本号等管理元数据 |
| 引擎的拿手绝活 | 高维空间近邻检索(ANN)。 能在几毫秒内,从几亿个坐标中找出距离最近的 Top-K。 |
极速的主键 Key-Value 查找。 能在高并发下以极低成本进行点对点数据提取。 |
| 引擎的致命短板 | 存储大文本成本极高。 向量数据库的内存和索引开销极大,存大段文本会导致机器死机。 |
完全无法做“模糊语义理解”。 只认识字面关键词,不认识意思。 |
1.4 噪音清洗与 PII 敏感数据脱敏
- 目标:在数据流(ETL)入口拦截乱码、重复网页页眉页脚等噪声,并对敏感信息进行安全合规脱敏,确保入库数据的质量与合规性。
- 内容:
- 编写自定义的 Document Transformer,过滤爬虫抓取网页时附带的冗余空白字符、HTML 实体、社交分享栏和无用尾页。
- 使用正则表达式或轻量预训练模型,对文本中的 PII(个人身份信息,如手机号、邮箱、身份证)进行掩码脱敏(Masking),防止敏感敏感数据明文流入外部向量数据库或第三方大模型。
- 实操:实现一段自动化预处理管道,输入一段带有乱码噪声和用户邮箱/电话的原始网页文本,输出干净且安全脱敏的 Document 块。
(1)噪音清洗与合规脱敏的底层考量
大模型 RAG 在进入企业生产环境时,安全合规(Compliance)是第一道、也是最沉重的一道门槛。如果我们在数据清洗(ETL)源头没有对数据进行深度治理,将会引发灾难性的后果。
1. RAG 数据清洗(Denoising)的物理边界
当我们的爬虫抓取了企业内部 Wiki 网页,或者导出了大量的技术日志时,这些文本中往往包含了大量的结构化噪音:
- 网页噪音:页眉、页脚、版权声明、社交媒体分享按钮(如“分享到微信”)、Cookie 弹窗提示、冗余的导航栏链接。
- 物理噪音:由于多栏排版 PDF 抽取失败导致的横向乱序字符、换行乱码、系统运行时的堆栈跟踪噪音。
如果把这些噪音原封不动地送入向量库,它们会直接稀释核心知识的 Embedding 语义。向量库计算距离时,这些广告和页眉词汇会产生严重的语义漂移,导致原本相关的知识片段无法被精准召回。
2. PII(个人身份信息)泄露与合规惩罚
在数据安全法(如 GDPR、中国个人信息保护法 PIPL)的严格监管下,企业内部文档中如果包含员工或客户的 PII(Personally Identifiable Information,个人身份信息),是绝对禁止明文传输给第三方公网大模型(如 OpenAI、Claude 等)或公网 SaaS 向量库的。
- 高频泄露的 PII 特征:中国身份证号(18位)、手机号码、个人常用邮箱、内网服务器真实 IP 地址。
- 脱敏的物理策略:我们必须在数据流刚刚进入 Python ETL 管道、尚未写入任何数据库、尚未调用任何 Embedding 接口之前,在内存中瞬时完成对这些敏感数据的“特征识别”与“掩码脱敏(Masking)”。
(2)代码实战:手构自定义 PII 脱敏 Document 管道
下面,我们不依赖笨重的外部大框架,而是直接利用 BeautifulSoup(用于剥离网页噪音)和高能正则表达式,编写一个兼容 LangChain LCEL 协议的高性能 PII 脱敏管道。
1. 架构拓扑与 LangChain 自定义转换器基础
在 2026 年的主流 RAG 开发实践中,我们提倡使用 Runnable 协议来封装数据处理器。我们将清洗函数包装为一个 RunnableLambda,使其能够像水流一样,无缝地融入到 | 管道流中:
原始网页 HTML ──> [HTML 降噪 (BS4)] ──> [正则敏感特征扫描] ──> [掩码脱敏 (Masking)] ──> 生成干净安全的 Chunks
2. 完整 Python 实战代码
安装依赖
pip install beautifulsoup4
import os
import re
from bs4 import BeautifulSoup
from langchain_core.documents import Document
from langchain_core.runnables import RunnableLambda
# 1. 模拟一个从企业内网爬取的、布满 HTML 噪音与核心 PII 隐私的原始文档
raw_html_page = """
<html>
<head><title>系统访问审计日志</title></head>
<body>
<div id="header">欢迎访问企业内网系统安全审计门户 | [分享到微博] [分享到微信] [内部机密]</div>
<div id="content">
<h1>运维部堡垒机访问审计日志(生产机密)</h1>
<p>时间:2026-05-29。系统运维工程师:张伟。</p>
<p>该运维人员的个人工作邮箱为:zhangwei.op@company.com,联系电话:13912345678。</p>
<p>在凌晨 3:15,他使用内网堡垒机 IP 192.168.1.105 远程登录了核心生产数据库。</p>
<p>日志记录显示,其本次导出了身份证号为 110101199003072345 的敏感客户信息,用于本地联调测试。</p>
</div>
<div id="footer">© 2026 Corporation | 内部安全守则 | 隐私政策 | Cookie设置</div>
</body>
</html>
"""
# 2. 编写自定义的清洗与 PII 脱敏逻辑
def clean_html_and_mask_pii(documents: list[Document]) -> list[Document]:
cleaned_docs = []
# 2.1 定义敏感信息的匹配正则表达式 (PII Patterns)
# 匹配中国手机号
phone_pattern = re.compile(r"\b1[3-9]\d{9}\b")
# 匹配常用 Email
email_pattern = re.compile(r"\b[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+\b")
# 匹配 IPv4 地址
ip_pattern = re.compile(r"\b(?:[0-9]{1,3}\.){3}[0-9]{1,3}\b")
# 匹配中国身份证号 (18位)
id_card_pattern = re.compile(r"\b[1-9]\d{5}(?:18|19|20)\d{2}(?:0[1-9]|1[0-2])(?:0[1-9]|[12]\d|3[01])\d{3}[\dXx]\b")
for doc in documents:
# ──【第一阶段:网页噪音清洗】──
# 使用 BeautifulSoup 解析 HTML
soup = BeautifulSoup(doc.page_content, "html.parser")
# 物理剥离无用的 header 和 footer 标签内容(直接移除广告、导航栏和页脚噪音)
for unwanted_tag in soup(["header", "footer", "script", "style"]):
unwanted_tag.decompose()
# 精准定位业务的核心正文区(例如只保留 id="content" 内的信息,彻底消除外部杂音)
main_content_div = soup.find(id="content")
if main_content_div:
text = main_content_div.get_text()
else:
# 降级方案:若没有特定 id,则直接获取剔除 unwanted 后的全文
text = soup.get_text()
# 压缩多余的换行符与空格,使段落更紧凑,提高 Embedding 密度
text = re.sub(r"\n\s*\n", "\n", text).strip()
# ──【第二阶段:PII 敏感数据脱敏掩码】──
# 执行正则表达式替换,保留脱敏占位符,防止隐私流入外部大模型
text = phone_pattern.sub("[MASK_PHONE]", text)
text = email_pattern.sub("[MASK_EMAIL]", text)
text = ip_pattern.sub("[MASK_IP]", text)
text = id_card_pattern.sub("[MASK_ID_CARD]", text)
# 构建全新的干净文档对象,并继承原始元数据
cleaned_docs.append(Document(page_content=text, metadata=doc.metadata))
return cleaned_docs
# 3. 将其封装为标准的 LCEL Runnable 管道
clean_pipeline = RunnableLambda(clean_html_and_mask_pii)
# ==========================================
# 4. 执行验证测试
# ==========================================
# 4.1 模拟传入原始文档对象
input_docs = [Document(page_content=raw_html_page, metadata={"source": "crawler_web_page"})]
# 4.2 运行清洗管道
print("正在执行网页降噪与 PII 脱敏数据流...")
safe_documents = clean_pipeline.invoke(input_docs)
print("\n=== 脱敏清洗后的最终文档内容 ===")
for doc in safe_documents:
print(f"元数据: {doc.metadata}")
print(f"文本内容: \n{doc.page_content}")
3. 运行输出与清洗效果深度对照
运行上述脚本后,控制台会输出高度纯净化、安全合规的内容:
正在执行网页降噪与 PII 脱敏数据流...
=== 脱敏清洗后的最终文档内容 ===
元数据: {'source': 'crawler_web_page'}
文本内容:
运维部堡垒机访问审计日志(生产机密)
时间:2026-05-29。系统运维工程师:张伟。
该运维人员的个人工作邮箱为:[MASK_EMAIL],联系电话:[MASK_PHONE]。
在凌晨 3:15,他使用内网堡垒机 IP [MASK_IP] 远程登录了核心生产数据库。
日志记录显示,其本次导出了身份证号为 [MASK_ID_CARD] 的敏感客户信息,用于本地联调测试。
🔍 效果对照深度解读:
- 噪音彻底剥离:原本 HTML 里的标题标签
<title>、页眉里的微博微信分享杂音、以及页脚的隐私政策与 Cookie 广告,被BeautifulSoup的选择器物理粉碎,绝不会流出。 - PII 完美遮蔽:
13912345678变成了[MASK_PHONE],内网 IP 变成了[MASK_IP],身份证号变成了[MASK_ID_CARD]。 - 合规合规无损:即使这段数据现在被送入公网的 OpenAI,也绝对不会产生任何实质性的泄露。同时,由于核心实体(张伟、堡垒机、数据库)和逻辑语义被 100% 保留了,大模型和向量库在计算其语义时,依然能够精准进行 RAG 逻辑推理。
(3)生产环境高阶演进设计
在企业内部真正的“生产级微服务”架构下,PII 的脱敏和清洗还要考虑以下高级工程设计:
1. 双向可逆脱敏(Symmetric Masking)与解密召回
- 痛点:在有些场景下,大模型回答时,必须告诉用户真正的手机号。如果我们在入口直接把手机号变成了
[MASK_PHONE],大模型就永远不可能知道真实的手机号是多少。 - 高阶设计:使用双向可逆脱敏(又称 Tokenization 令牌化技术)。
- 在进入向量库前,我们将真实数据
13912345678通过对称加密,生成一个临时令牌:TOKEN_PHONE_8a92f03并将其存入 MySQL/Redis(只在内网)。 - 把脱敏后的
TOKEN_PHONE_8a92f03替换进文本,喂给大模型。 - 大模型在生成答案时,回答:“该工程师的电话是 TOKEN_PHONE_8a92f03”。
- 在将最终答案通过 Java 网关输出给用户浏览器前,网关拦截器自动捕获该 TOKEN,去 Redis/MySQL 查出真实的
13912345678替换回去,完成对前端用户的“解密无缝召回”。
- 在进入向量库前,我们将真实数据
2. 企业级 PII 引擎推荐(Microsoft Presidio)
- 局限:单纯依靠我们手写的正则表达式,无法很好地处理姓名(Named Entity Recognition,命名实体识别)、组织机构名等复杂文本的脱敏。
- 演进:在工业界,推荐引入微软开源的企业级隐私引擎:Microsoft Presidio。
- 它提供了一个开箱即用的、基于 NLP 实体识别的 PII 扫描机制,能够极为精准地扫描各种语言(支持中文、英文)中的实体人名、地址,自动执行 Mask 掩码。
章节一总结
这一章我们重点学习了RAG的清洗、切片、检索、降噪脱敏,这都是非常基础的RAG操作,同时在过程中掺杂了企业级的实现思路,这对后期的整个实现有非常重要的作用。但是呢这远远不够,接下来让我们进入复杂的整合阶段:集成和混合检索。
二、 向量库集成与混合检索 (Milvus & 检索优化)
2.1 现代向量数据库基础与部署 (Milvus & pgvector)
- 目标:掌握生产级向量数据库的核心概念、集合建模及基础操作,为后续的复杂检索搭建高可靠的数据底座。
- 内容:
- 对比主流向量库的使用场景(如轻量级 Chroma、生产级 Milvus、关系型扩展 Supabase pgvector)。
- 理解 Collection(集合)、Schema(模式)的设计,明确向量字段与标量字段(Metadata)的区别与存储逻辑。
- 掌握 Document Embeddings 的生成、写入,以及基于近似最近邻(ANN)的基础稠密向量检索(Dense Search)。
- 实操:通过 Docker 本地部署(或云端申请)一个 Milvus/pgvector 实例,定义包含
text、embedding及metadata的 Schema,并将第一章切分好的数据转化为向量并成功落库。
(1)理论剖析:为什么我们需要生产级向量数据库?
1. 玩具级 vs. 生产级向量库的区别
在 LangChain 早期教程中,大家经常会看到 Chroma 或 FAISS。它们非常适合本地 Demo 跑通,但在企业生产环境中往往显得脆弱:
- 本地/内存型 (如 FAISS / Chroma):通常将数据加载到内存或本地单一文件中。缺乏分布式扩展能力,不支持高并发读写,没有完善的账号权限隔离(RBAC)和数据持久化机制。
- 生产级云原生型 (如 Milvus / Qdrant):专为十亿级向量检索设计,支持分布式扩容、多副本高可用、节点动态增减,并且内置多种业界顶级的索引算法(如 HNSW、IVF_FLAT)。
- 关系型扩展型 (如 PostgreSQL + pgvector):这是目前的当红炸子鸡。借助开源插件
pgvector,让传统的 Postgres 数据库拥有了向量检索能力。如果企业已有成熟的 PG 运维体系,直接扩展是侵入性最小、对复杂 Metadata(标量数据)进行 JOIN 查询最强大的方案。
(2)核心概念:Collection 与 Schema 的设计哲学
进入生产环境,我们不能再像本地测试那样直接 from_texts() 就完事了,必须先进行数据建模。
1. Milvus的核心组件介绍
Milvus 采用的是先进的读写分离,存储与计算分离微服务架构。在 Standalone(单机版)中,它主要依赖下面的几个外部核心组件:
- Access Layer (Proxy):代理节点,作为系统的门神,负责接收客户端的请求(如 DDL、向量检索),并进行安全验证。
- Etcd:元数据存储中心。负责存储 Milvus 的 Collection 结构定义(Schema)、节点状态以及数据分片信息。
- MinIO:对象存储系统,负责持久化存储向量数据分片(Segments)的原始二进制文件与索引文件。
- Query Node / Data Node / Index Node:计算层。负责把磁盘/对象存储里的数据加载到内存中进行极速向量计算与索引构建。
2. 什么是 Collection 和 Schema?
- Collection (集合/表):相当于关系型数据库中的“表(Table)”。比如你可以建一个
hr_docs_collection专门存人事文档,建一个tech_docs_collection专门存技术文档。 - Schema (模式/表结构):在建表前,必须定义好表里有哪些字段,每个字段的类型是什么。
3. Vector (向量) 与 Metadata (标量) 的分工
在 Schema 中,通常包含两类数据,它们在 RAG 中发挥着截然不同的作用:
- Vector 字段(向量):存放 Embedding 模型吐出的浮点数数组(如 768 维或 1536 维)。它负责**“语义匹配”**。例如搜索“休假规定”,能匹配到“年假管理办法”。
- Scalar 字段(标量/Metadata):存放字符串、整数、JSON 等常规数据,如
author,upload_date,tenant_id。它负责硬性过滤。例如在语义检索前,先筛选出tenant_id = 'A企业'的数据,这是多租户安全隔离的基石。
(3)机制解析:从 Embedding 落库到 ANN 检索
1. 近似最近邻检索 (ANN - Approximate Nearest Neighbor)
在传统数据库中,我们用的是“精确匹配(Exact Match)”。但在向量库中,如果每次都把库里几千万条向量和用户的问题计算一遍余弦相似度(KNN),系统早就崩溃了。
因此,现代向量数据库普遍采用 ANN 算法(如 HNSW 分层导航小世界算法)。它通过构建多层级的图索引,牺牲极小部分(比如 1%)的精度,换取万倍的检索速度提升。这是向量库能做到“毫秒级召回”的核心秘密。
(4)选择 pgvector 还是 Milvus(重点)
1. pgvector (PostgreSQL 的向量扩展插件)
- 定位:让传统的全能型关系数据库,拥有了向量检索能力。
- 优势 (Pros):
- 极低的运维门槛:绝大多数公司都有现成的 PostgreSQL 实例和 DBA 团队。只需装个插件就能用,无需引入新的底层中间件。
- 无敌的标量混合查询 (Hybrid Query):这是它最大的杀手锏。如果你需要执行复杂的传统业务逻辑查询(比如:
先 JOIN 订单表,找出价格大于500元且在售的商品,然后再做向量语义匹配),关系型数据库做这类条件过滤(Metadata 过滤)是老本行,性能极高。 - ACID 事务保证:你的原始业务数据和向量数据存放在同一个库里,数据的一致性完美保障。
- 劣势 (Cons):
- 规模上限:当向量数据量级突破千万级到亿级时,PG 的 HNSW 索引构建速度和检索内存占用会面临巨大挑战。它不是为纯粹的海量向量设计的。
2. Milvus(AI 原生向量数据库)
- 定位:专门为千亿级向量检索而生的“纯血”云原生分布式向量数据库。
- 优势 (Pros):
- 极致的性能与扩展性:采用存储与计算分离的分布式架构(Milvus Cluster)。面对亿级甚至百亿级数据,支持动态增加节点,QPS(每秒查询率)极高。
- 丰富的专业索引:除了 HNSW,还支持 IVF_FLAT、DiskANN(将向量存在磁盘上以节省昂贵的内存)等多种最前沿的硬件级优化算法。
- 劣势 (Cons):
- 运维成本极高:部署一个完整的分布式 Milvus 需要多个组件(etcd, MinIO, Pulsar 等),对中小型团队来说运维负担极重(除非花钱买 Zilliz Cloud 托管服务)。
- 复杂的标量过滤较弱:虽然 Milvus 也支持 Metadata 过滤,但如果涉及到复杂的多表关联(JOIN)或极其复杂的传统关系查询,它远不如 PG 灵活。
3. pgvector 和 Milvus的对比
| 对比维度 | pgvector (PostgreSQL 插件) | Milvus (AI 原生向量数据库) |
|---|---|---|
| 系统定位 | PostgreSQL 的一个扩展插件(非独立 DB) | 专为海量高维向量打造的分布式存储计算系统 |
| 设计哲学 | 在关系型数据库里“顺便”做向量检索。 | 万物皆向量,为了海量数据的极速检索而生。 |
| 推荐数据规模 | 适合 500 万条以下(中小型项目或部门级知识库)。 | 适合 千万级至百亿级(企业级 RAG、大规模推荐系统)。 |
| ACID 事务支持 | 完美继承 PostgreSQL 的强 ACID 事务与复杂 JOIN。 | 仅支持初级元数据过滤,不具备强关系型事务。 |
| 计算加速 | 仅依赖 CPU,无法利用多核并行扫描,不支持 GPU。 | 深度支持 多核并行、GPU 硬件加速 与分布式计算。 |
| 运维复杂度 | 极低。零维护成本,直接复用现有的 PG 备份与运维体系。 | 较高。需要独立管理,单机或 K8s 部署,依赖 Etcd、MinIO 等组件。 |
| 混合检索能力 | 需借助 PostgreSQL 的全文检索,或用多表拼接实现。 | 原生支持多路召回(Dense + Sparse),内置 RRF 融合算法。 |
4. 中国现有生态分析
从上述介绍有一个重点是什么,如果选择pgvector就得绑定PostgreSql关系型数据库,这和目前国内深度集成Mysql的市场情况有一些冲突,虽然PostgreSql今年来因为其丰富的生态非常受欢迎,但想要转型还是比较困难的,比较Mysql生态绑定的太深了。
而且不知道大家所接触到的业务是哪一种,就拿我目前所做的人力资源Sass方向来说,如果选择pgvector是绝对不合适的,有以下的痛点。
- Mysql生态: 目前公司使用的都是Mysql,而且是部署在阿里的集群上,数据量非常大,Sass服务避免不了这个问题。
- 数据私有化: 因为我们的客户群体都是国企或者事业单位,他们非常注重数据的私有化,最低底线是Mysql且部署在国内的云服务器上。但是大多数都采用的是本地部署,而且数据库选择的是达梦、金仓 等国产化数据库,接入PostgreSql是不可能的。
- 环境多样化: 因为要兼容多个部署的环境,他们的服务器都不一样,甚至说有些客户因为环境的限制无法安装一些高版本的依赖,而且还区分密网、内网、商网等等,如果和数据库绑定的太深是不现实的。
- 数据量庞大: Sass服务的数据量最低都在千万起步,联表查询这种操作都很难看到,两三个表稍微弄不好就是百万*百万的扫描,这你受得了吗。
- 业务逻辑复杂: 在业务逻辑非常复杂的时候,本身联表这种操作就很难被允许,同时各个步骤的监控需要做到位,回滚事务也得到位,所以如果接入AI需要查询对应的资料,很难会直接让其调用数据库,走的都是Java或者Python接口,如果非要用到数据库那就是查询视图去,不然一个不小心查询就可能把数据库的线程给干没了。
5. 从技术和成本方面选择 实现方案
路径一:
双引擎彻底解耦模式(MySQL 业务库 + 独立 Milvus/Qdrant 向量库)
这是目前国内大型互联网与大型企业最主流的架构设计。
- 设计逻辑:
- MySQL:继续作为核心 OLTP 业务库,存储结构化的业务、用户、账单等数据。
- Milvus:独立作为 RAG 的向量搜索引擎。
- 通过我们在 1.3 节学过的
parent_id(指针关联) 建立双向绑定。当 Milvus 检索到知识后,业务系统再去 MySQL 捞取结构化的关联业务数据。
- 优势:存储与计算彻底分离,两套数据库各自在擅长的领域发挥极致性能,不存在单点瓶颈。
- 劣势:需要维护两套系统,开发和运维成本较高。
路径二:
独立轻量旁路模式(MySQL 主库 + 独立 PostgreSQL/pgvector 知识库)
如果项目数据量在百万级以内,且预算和运维资源非常紧张。
- 设计逻辑:核心业务依然跑在 MySQL 上不动。在旁边单独部署一个极简的 PostgreSQL 容器并启用
pgvector,这个 PG 不存储任何业务数据,仅作为 RAG 知识库的专用存储。 - 优势:避开了 Milvus(Etcd、MinIO 等一整套容器)的高昂物理开销,pgvector 容器仅需 100~200MB 的内存即可流畅运行。
- 劣势:无法享受“向量与业务数据在同个库直接进行 SQL JOIN”的便利,本质上依然是双库维护。
路径三:
云原生一键兼容模式(利用国内云厂商的 MySQL 向量内核)
如果使用的是国内主流云厂商的云数据库。
- 设计逻辑:国内头部的云原生数据库(例如 阿里云的 PolarDB for MySQL、腾讯云的 TDSQL/C)在其内核层面已经通过自研插件,直接在 MySQL 兼容版中集成了向量检索与 HNSW 索引能力。
- 优势:如果本身就在使用这些云原生 MySQL,可以直接一键升级,不需要引入任何 PostgreSQL 或是外部向量库,真正实现“在已有的 MySQL 里做向量检索”。
6. 从业务层面选择 实现方案
上面是基于技术和硬件层面,但实际上真正决定你怎么选择的还是业务,虽然技术上得选择Milvus,但是业务不允许呢?
普通非知识密集型客服
这是目前应用最简单也是最常见的一种,智能客服,它不依赖于密集型知识库,只有少量的企业文档,而且只需要根据用户的问题进行答案匹配即可。
这种业务可以选择自己实现,使用轻量级的PostgreSql和pgvector,或者接入云服务,实现快也好维护,成本也不高。
专业知识密集型
这种业务就属于金融、科研、法律等大型业务了,这种从数据量、响应速度、准确度等方面要求都很高,属于专家级RAG,特征如下:
- 数量级暴涨:全国历年法律判例(数千万条)、金融机构十年来的行业研究报告、生物医药公司的海量专利、高校科研论文库。
- 检索维度苛刻:用户不仅要求匹配“大概意思”(语义检索),还必须精准匹配某个学术专有名词、某个法律条文的编号、某个财政报表的财务数据(需要混合检索与重排)。
- 高并发压力: 可能有成千上万名研究员、分析师、律师同时在进行复杂的多条件检索。
想都不用想,Milvus的分布式分片和扩容、多路召回与重排首当其冲。
业务智能型Agent
这是现在最火、适用度最广泛且需求量最大的一种场景,用专业名词为:Tool-Calling Agent(工具调用智能体),这种解决了普通问答的业务单一短板,同时也解决了AI幻觉和难以管控的问题,也就是类似cursor这种。
这种业务的特征是:
- 数据量不大: 从数据量来说可大可小,正常都在几百页PDF或者几千,不多。
- 业务复杂: 上面说过这种一般都是业务复杂场景,客户群体也很多样化。
- 安全和工程性要求高: 安全、可控都是必要的要求,所以说这种业务的真正核心的是业务数据流文档,基于代码和业务的整合文档,通过Agent调用工具来实现目标,达到工程化的可控安全等。
所以这种业务两个方案都可以采用,当然还是建议使用云服务,将重点集成在业务中,也就是Agent的编码中。
(5)实操演练:本地部署与 LangChain 整合入库
生产一般使用 PostgreSQL + pgvector ,但是学习还是使用向上兼容,学习难的,这样在遇到简单的一看就会,所以这里使用 Milvus+Docker。
1. 环境准备 (Docker)
首先去官网下载docker桌面版进行安装,当然你也可以选择使用轻量级依赖 pip install milvus-lite,因为个人习惯所以使用了docker桌面版。
安装好之后会提示下载适用于windows的Linux子系统,直接下载接口。
然后可以选择不登录,我这里登录了,等到下面这个页面出现就代表软件安装成功。
之后在你电脑的 C:\Users\19355\.docker目录下打开 cmd,下载一个配置文件:
curl -o docker-compose.yml https://raw.githubusercontent.com/milvus-io/milvus/master/deployments/docker/standalone/docker-compose.yml
这是因为要下载关于Milvus的几个必要依赖项,之后直接使用脚本进行启动,方便快捷,自己配置很麻烦。
下载成功后执行:
docker compose up -d
下载需要几分钟,如果没有VPN的情况下可能会慢点,我使用的是VPN。
之后在docker就可以看安装的Milvus的安装了。
2. 定义环境与依赖包安装
安装 LangChain 官方最新对应驱动:
langchain-milvus 是 LangChain 官方最新的集成包;pymilvus 是底层驱动;tiktoken 是 OpenAI 必需的词元计算库。)
因为没有OpenAI的密钥,使用国产的本地模型进行向量化
pip install langchain-milvus pymilvus langchain-openai tiktoken
pip install sentence-transformers langchain-huggingface
3. Python 代码实战:切片、向量化与落库、基础稠密检索
以下是将文档转化为带有元数据的向量并存入 pgvector 的标准流程:
注意:经过不断调试发现,pymilvus 2.6.x 与 langchain-milvus 0.3.3有兼容性问题,官方正在底层升级,所以采用了下面最新的写法,但是不能解决根本问题。
import warnings
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_core.documents import Document
from langchain_milvus import Milvus
from pymilvus import connections, utility
# 忽略版本弃用警告
warnings.filterwarnings("ignore")
MILVUS_URI = "http://127.0.0.1:19530"
COLLECTION_NAME = "enterprise_knowledge_base"
class MilvusCompat(Milvus):
"""兼容 pymilvus 2.6.x:langchain-milvus 仍走 ORM Collection,需绑定已注册的 alias。"""
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.alias = "default"
# 1. 模型加载
print("⏳ 加载本地 BGE 向量模型...")
embeddings = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh-v1.5")
# 2. 数据准备
docs = [
Document(
page_content="公司年假管理办法:入职满一年可享受5天带薪年假。",
metadata={"doc_id": "hr_001", "category": "HR", "tenant_id": "org_A"},
),
Document(
page_content="2024年报销规范:餐饮发票需附带水单。",
metadata={"doc_id": "fin_001", "category": "Finance", "tenant_id": "org_A"},
),
Document(
page_content="Serverless 部署指南:使用 AWS Lambda 可大幅降低闲置成本。",
metadata={"doc_id": "tech_001", "category": "Engineering", "tenant_id": "org_B"},
),
]
# pymilvus 2.6+ 的 MilvusClient 不会向 ORM 注册连接,langchain-milvus 需要这条 ORM 通道
print("🔌 正在建立底层数据库连接...")
connections.connect(alias="default", uri=MILVUS_URI)
print("🧹 正在检查并清理旧数据...")
if utility.has_collection(COLLECTION_NAME):
utility.drop_collection(COLLECTION_NAME)
print("🔄 正在将数据向量化并落库...")
vector_store = MilvusCompat.from_documents(
documents=docs,
embedding=embeddings,
connection_args={"uri": MILVUS_URI},
collection_name=COLLECTION_NAME,
)
print("✅ 数据已成功落库!\n")
# 4. 执行基础稠密检索
query = "我想知道入职后多久可以请带薪假?"
print(f"🔍 正在执行向量检索,问题: '{query}'")
results = vector_store.similarity_search(query, k=2)
for i, res in enumerate(results):
print(f"\n--- 召回结果 {i+1} ---")
print(f"📄 内容: {res.page_content}")
print(f"🏷️ 元数据: {res.metadata}")
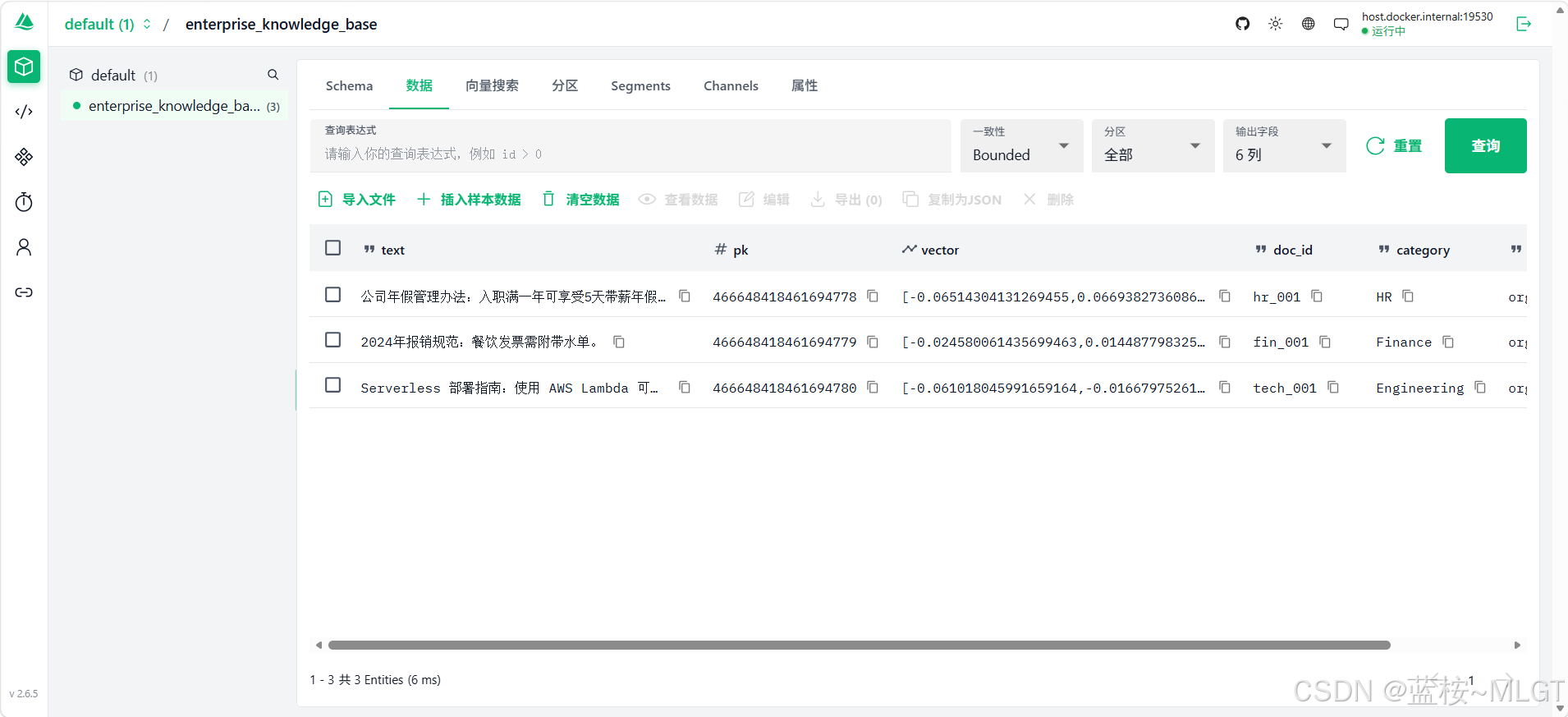
运行结果:
C:\Users\19355\miniconda3\python.exe C:\pythonProjects\PythonProject\agent-study-3\milvus_demo_04.py
⏳ 加载本地 BGE 向量模型...
Warning: You are sending unauthenticated requests to the HF Hub. Please set a HF_TOKEN to enable higher rate limits and faster downloads.
Loading weights: 100%|██████████| 71/71 [00:00<00:00, 7772.09it/s]
🔌 正在建立底层数据库连接...
🧹 正在检查并清理旧数据...
🔄 正在将数据向量化并落库...
✅ 数据已成功落库!
🔍 正在执行向量检索,问题: '我想知道入职后多久可以请带薪假?'
--- 召回结果 1 ---
📄 内容: 公司年假管理办法:入职满一年可享受5天带薪年假。
🏷️ 元数据: {'tenant_id': 'org_A', 'doc_id': 'hr_001', 'category': 'HR', 'pk': 466648418461694778}
--- 召回结果 2 ---
📄 内容: 2024年报销规范:餐饮发票需附带水单。
🏷️ 元数据: {'tenant_id': 'org_A', 'doc_id': 'fin_001', 'category': 'Finance', 'pk': 466648418461694779}
进程已结束,退出代码为 0
4. 使用Attu容器可视化查看Milvus
安装Attu,这也是基于docker运行的,默认指向8000端口
docker run -d --name attu -p 8000:3000 -e MILVUS_URL=host.docker.internal:19530 zilliz/attu:latest
5. 使用稳定版本的Milvus和pymilvus
在上面的代码中我们使用的是最新的依赖,因为官方升级的原因目前不稳定,所以采用降级策略。
pip install "langchain-milvus==0.2.2" "pymilvus==2.5.18"
之后修改代码,这种就不需要那么麻烦了。
import warnings
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_core.documents import Document
from langchain_milvus import Milvus
from pymilvus import MilvusClient
# 忽略版本弃用警告
warnings.filterwarnings("ignore")
MILVUS_URI = "http://127.0.0.1:19530"
COLLECTION_NAME = "enterprise_knowledge_base"
# 1. 模型加载
print("⏳ 加载本地 BGE 向量模型...")
embeddings = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh-v1.5")
# 2. 数据准备
docs = [
Document(
page_content="公司年假管理办法:入职满一年可享受5天带薪年假。",
metadata={"doc_id": "hr_001", "category": "HR", "tenant_id": "org_A"},
),
Document(
page_content="2024年报销规范:餐饮发票需附带水单。",
metadata={"doc_id": "fin_001", "category": "Finance", "tenant_id": "org_A"},
),
Document(
page_content="Serverless 部署指南:使用 AWS Lambda 可大幅降低闲置成本。",
metadata={"doc_id": "tech_001", "category": "Engineering", "tenant_id": "org_B"},
),
]
print("🔌 正在连接 Milvus...")
client = MilvusClient(uri=MILVUS_URI)
print("🧹 正在检查并清理旧数据...")
if client.has_collection(COLLECTION_NAME):
client.drop_collection(COLLECTION_NAME)
print("🔄 正在将数据向量化并落库...")
vector_store = Milvus.from_documents(
documents=docs,
embedding=embeddings,
connection_args={"uri": MILVUS_URI},
collection_name=COLLECTION_NAME,
)
print("✅ 数据已成功落库!\n")
# 4. 执行基础稠密检索
query = "我想知道入职后多久可以请带薪假?"
print(f"🔍 正在执行向量检索,问题: '{query}'")
results = vector_store.similarity_search(query, k=2)
for i, res in enumerate(results):
print(f"\n--- 召回结果 {i+1} ---")
print(f"📄 内容: {res.page_content}")
print(f"🏷️ 元数据: {res.metadata}")
思考与预告:
单纯的语义检索(Dense Search)看起来很美好,但如果你搜索特有名词、具体的错误代码(如 Error 502 Bad Gateway),或者特定的产品型号(如 ThinkPad T14 Gen3),模型往往会“懵圈”,因为它会去找语义相近的词,而不是精准匹配。
这就引出了我们下一节要解决的痛点:2.2 混合检索 (Hybrid Search) 机制构建。
2.2 混合检索 (Hybrid Search) 机制构建
- 目标:克服单一稠密向量检索(语义理解)对特定名词、型号、缩写不够敏感的盲区,通过结合稀疏检索(关键词匹配)大幅提升召回率。
- 内容:
- 分析 Dense Vector(稠密向量,擅长泛化与语境)与 Sparse Vector(稀疏向量,如 BM25,擅长硬性匹配)的互补优势。
- 掌握使用 LangChain 的
EnsembleRetriever并行触发两路或多路检索。 - 理解多路召回后的分数融合机制,如倒数秩融合算法(RRF, Reciprocal Rank Fusion),实现不同打分体系的结果对齐。
- 实操:使用 LCEL 构建一个混合检索器(同时连接 Milvus 向量查询与本地 BM25 算法)。故意输入包含特殊设备型号或专有名词的冷僻 query,对比单路召回与混合召回的精准度差异。
(1)痛点剖析:为什么只要“语义”,会死得很惨?
在刚才的实操中,稠密检索(Dense Search)的魔力:“带薪假”能匹配到“年假”。这是因为 Embedding 模型理解“意思”。
但如果你在生产环境中只用 Dense Search,用户很快就会来骂你。比如以下场景:
- 专有名词/型号搜索:“帮我查一下
ThinkPad T14 Gen3的维修手册”。Embedding 模型往往对具体的数字和字母组合不敏感,它可能会给你召回一大堆毫不相关的其他电脑手册。 - 特定代号/缩写:“
hr_001文件里写了啥?” 这种冷僻字眼在多维语义空间里是个孤岛,大模型根本“不懂”它。
怎么解决?请回老祖宗的绝活:关键词精确匹配。
业内最经典的稀疏检索(Sparse Search)算法叫 BM25(也是 Elasticsearch 的核心算法)。它不理解意思,它只数词频:你搜 hr_001,它就死死盯住含有 hr_001 这个词的文档。
混合检索(Hybrid Search) = 稠密检索(懂语义) + 稀疏检索(死抠字眼)。 两路大军同时去搜,然后把结果按一种叫 RRF(倒数秩融合) 的算法进行重新排名合并,兼顾“泛化”与“精准”。
(2)实操演练:构建双路并发的 EnsembleRetriever
在 LangChain 中,实现混合检索极其优雅,我们不需要改动底层 Milvus,只需引入一个本地的 BM25Retriever,然后用 EnsembleRetriever 把两者“绑”在一起。
第一步:安装 BM25 依赖库
在你的终端激活虚拟环境,安装 BM25 算法的核心库:
pip install rank_bm25
第二步:代码实战(融合双路检索)
在你刚才那份已经完美跑通的 milvus_demo.py 底部,追加以下代码。我们对比一下纯语义检索和混合检索的威力!
from langchain_community.retrievers import BM25Retriever
from langchain.retrievers import EnsembleRetriever
# 1. 构造路军 A:稠密检索器 (Milvus - 懂语义)
# 将我们刚才建好的 Milvus 转化为检索器,设置召回 k=2
milvus_retriever = vector_store.as_retriever(search_kwargs={"k": 2})
# 2. 构造路军 B:稀疏检索器 (BM25 - 抠字眼)
# 我们用一开始建立的 docs 列表在本地内存构建一个 BM25 索引,同样设置召回 k=2
bm25_retriever = BM25Retriever.from_documents(docs)
bm25_retriever.k = 2
# 3. 构造三军统帅:混合检索器 (Ensemble)
# weights: [0.5, 0.5] 表示两路召回的权重各占一半。
# 如果你的业务强依赖精准型号匹配,可以把 BM25 的权重调高 (如 [0.3, 0.7])
ensemble_retriever = EnsembleRetriever(
retrievers=[milvus_retriever, bm25_retriever],
weights=[0.5, 0.5]
)
# --------------------------------------------------
# 4. 终极测试:故意出个难题,对比检索效果
# --------------------------------------------------
# 难题:我们搜索特定的文档 ID 缩写 和 一个专有英文词汇
hard_query = "我想看 tech_001 这篇文档,它是关于 AWS 的吗?"
print(f"\n🧠 用户的刁钻问题: '{hard_query}'\n")
print("👉 【单路测试】纯 Milvus (Dense) 检索:")
dense_results = milvus_retriever.invoke(hard_query)
for res in dense_results:
print(f" - {res.page_content}")
print("\n👉 【单路测试】纯 BM25 (Sparse) 检索:")
sparse_results = bm25_retriever.invoke(hard_query)
for res in sparse_results:
print(f" - {res.page_content}")
print("\n👑 【终极融合】Ensemble 混合检索 (自动执行 RRF 融合去重):")
# EnsembleRetriever 会让两路兵马同时去查,然后融合、去重、重新打分
hybrid_results = ensemble_retriever.invoke(hard_query)
for i, res in enumerate(hybrid_results):
print(f" - 结果 {i+1}: {res.page_content}")
运行结果:
🔍 正在执行向量检索,问题: '我想知道入职后多久可以请带薪假?'
🧠 用户的刁钻问题: '我想看 tech_001 这篇文档,它是关于 AWS 的吗?'
👉 【单路测试】纯 Milvus (Dense) 检索:
- Serverless 部署指南:使用 AWS Lambda 可大幅降低闲置成本。
- 2024年报销规范:餐饮发票需附带水单。
👉 【单路测试】纯 BM25 (Sparse) 检索:
- Serverless 部署指南:使用 AWS Lambda 可大幅降低闲置成本。
- 2024年报销规范:餐饮发票需附带水单。
👑 【终极融合】Ensemble 混合检索 (自动执行 RRF 融合去重):
- 结果 1: Serverless 部署指南:使用 AWS Lambda 可大幅降低闲置成本。
- 结果 2: 2024年报销规范:餐饮发票需附带水单。
💡 运行结果分析:
- 纯 Milvus 可能会因为
tech_001和AWS这种生硬的字母,在语义空间里发生偏移,召回的排序可能不够理想。 - 纯 BM25 像个死脑筋,它看到 query 里有
tech_001和AWS,会精准锁定包含这些词的原文(即 Serverless 部署指南),但在理解长句语义上显得很吃力。 - 混合检索 (Ensemble) 则完美融合了两者的结果。LangChain 在底层自动使用了 RRF 算法,将两边都认为重要的结果排在最前面,同时剔除了重复项。
但是结果显示都是一样的,还是那个问题,样本量太小了,如果是几千个呢?
这时候思考一下,虽然使用了混合模式搜索,但有可能最需要的一条正好是返回20条综合的第11条,夹在中间。如果是这种情况大模型返回的回答可能是会漂移的。所以需要一个重排模型,对召回的结果进行重新审核,之后让大模型分析就更加的准确了。
2.3 重排机制 (Rerank) 与“迷失在中间”破局
- 目标:解决大语言模型“迷失在中间 (Lost in the middle)”的上下文注意力涣散问题,利用重排模型对初筛结果进行二次降噪与提纯。
- 内容:
- 理解为什么扩大召回(如 Top-K=20)会引入噪声并降低大模型回答质量。
- 介绍交叉编码器(Cross-Encoder)重排模型(如 BGE-Reranker、Cohere Rerank)的原理,及其为何比双编码器(Bi-Encoder,即普通 embedding)打分更准。
- 掌握 LangChain 中的
ContextualCompressionRetriever(上下文压缩检索器)组件。
- 实操:在混合检索的基础上,串联一个 BGE-Reranker 节点,将初始召回的 Top-20 文档块重新打分精排,截取并输出最相关的前 Top-5,验证重排前后文档排序及干扰项剔除的效果。
(1)理论剖析:大模型的“金鱼记忆”与 Rerank 原理
1. 迷失在中间 (Lost in the middle)
斯坦福大学的一项著名研究表明,当你把 20 篇文档作为参考资料喂给大模型(如 GPT-4 或 DeepSeek)时,它对开头和结尾的文档印象最深,而对夹在中间的文档往往会“视而不见”。
如果你靠混合检索召回了 20 条结果,而真正能回答问题的目标文档排在第 11 名,大模型极大概率会回答:“根据已知信息,无法回答该问题。”
2. 双编码器 (Embedding) vs 交叉编码器 (Rerank)
- Embedding 模型(双编码器/Bi-Encoder):就像相亲时的看照片初筛。它提前把所有的文档变成向量,用户提问时也变成向量,然后算余弦相似度。速度极快,但不够细致。
- Rerank 模型(交叉编码器/Cross-Encoder):就像相亲时的线下深度交流。它不产出向量,而是把“用户问题”和“初筛文档”拼在一起,作为一个整体输入到模型中,逐字逐句进行注意力计算(Attention),最后吐出一个 0 到 1 的相关性得分。
- 代价:Rerank 极其消耗算力,速度慢。所以我们绝对不能用它去库里对比 10 万篇文档。
- 黄金架构:
混合检索 (快速选出 Top-20)➔Rerank 模型 (精细打分截取 Top-5)➔大模型 (生成回答)。
(2)实操演练:为你的系统装上“重排过滤器”
在 LangChain 中,重排被抽象为一种文档压缩器 (Document Compressor)。它的逻辑是:接收底层的检索结果,压缩(剔除)无关信息,只把最优质的留下来。
第一步:安装依赖库
由于我们将使用智源开源的 BGE-Reranker(目前最强的开源中文重排模型之一),确保你安装了最新版的句向量库(之前已安装,更新一下最稳妥):
pip install -U sentence-transformers
第二步:准备“充满噪音”的数据集和测试代码
为了让你肉眼看到 Rerank 的威力,这一次我们在数据准备时故意加几条“噪音数据”。
新建一个文件 rerank_demo.py,粘贴以下完整代码并运行。
因为rerank模型比较大,如果不登录下载的话会比较慢,所以我们直接注册账号使用cli命令进行下载,操作步骤如下:
- 访问官方:https://huggingface.co
- 注册并登录,基本邮箱都可以用
- 登录到你的注册邮箱中,点击链接进行激活(非常重要,要激活邮箱,不然无法创建Token)
- 打开设置页面,如下
- 创建令牌 :注意保存好
- 打开pycharm安装依赖: pip install -U huggingface_hub
- 登录: hf auth login ,直接粘贴对应的Token进行,控制台不显示,直接回车即可
- 执行下载命令: 注意替换你的项目地址
hf download BAAI/bge-reranker-base --local-dir "c:\pythonProjects\PythonProject\agent-study-3\models\bge-reranker-base"
hf download BAAI/bge-small-zh-v1.5 --local-dir "c:\pythonProjects\PythonProject\agent-study-3\models\bge-small-zh-v1.5"
之后就能在项目中看到依赖了:
import os
import warnings
from pathlib import Path
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_core.documents import Document
from langchain_milvus import Milvus
from pymilvus import MilvusClient
from langchain_community.retrievers import BM25Retriever
from langchain_classic.retrievers import EnsembleRetriever
# 引入 Rerank 相关的两个核心类
from langchain_classic.retrievers.document_compressors import CrossEncoderReranker
from langchain_community.cross_encoders import HuggingFaceCrossEncoder
from langchain_classic.retrievers import ContextualCompressionRetriever
warnings.filterwarnings("ignore")
BASE_DIR = Path(__file__).resolve().parent
MILVUS_URI = "http://127.0.0.1:19530"
COLLECTION_NAME = "enterprise_knowledge_base"
# 本地模型目录(首次下载见文件末尾注释或运行 download_models.py)
EMBEDDING_MODEL_DIR = BASE_DIR / "models" / "bge-small-zh-v1.5"
RERANKER_MODEL_DIR = BASE_DIR / "models" / "bge-reranker-base"
def resolve_model_path(local_dir: Path, hub_name: str) -> str:
"""优先使用项目内本地模型,不存在则回退到 HuggingFace Hub。"""
return str(local_dir) if local_dir.is_dir() else hub_name
# ===================================================
# 1. 初始化模型与基础设置
# ===================================================
print("⏳ 1. 加载 BGE 向量模型...")
embedding_model = resolve_model_path(EMBEDDING_MODEL_DIR, "BAAI/bge-small-zh-v1.5")
embeddings = HuggingFaceEmbeddings(
model_name=embedding_model,
model_kwargs={"local_files_only": EMBEDDING_MODEL_DIR.is_dir()},
)
print("⏳ 2. 加载 BGE Reranker 重排模型...")
reranker_model = resolve_model_path(RERANKER_MODEL_DIR, "BAAI/bge-reranker-base")
if RERANKER_MODEL_DIR.is_dir():
print(f" 使用本地模型: {RERANKER_MODEL_DIR}")
else:
print(f" 本地未找到模型,将从 Hub 下载: {reranker_model}")
cross_encoder_model = HuggingFaceCrossEncoder(
model_name=reranker_model,
model_kwargs={"local_files_only": RERANKER_MODEL_DIR.is_dir()},
)
# ===================================================
# 2. 准备数据 (故意加入极具迷惑性的噪音)
# ===================================================
docs = [
Document(page_content="公司年假管理办法:入职满一年可享受5天带薪年假。", metadata={"id": "1", "type": "HR"}),
# --- 下面是故意加入的噪音 ---
Document(page_content="关于国庆节放假安排的通知:10月1日至7日放假,带薪休假不扣除绩效。", metadata={"id": "2", "type": "HR-Noise"}),
Document(page_content="离职管理办法:员工离职需提前30天申请,未休完的年假作废。", metadata={"id": "3", "type": "HR-Noise"}),
Document(page_content="带薪培训制度:新员工入职可享受为期一周的带薪脱产培训。", metadata={"id": "4", "type": "HR-Noise"}),
Document(page_content="事假请假流程:事假为无薪假,需主管审批。", metadata={"id": "5", "type": "HR-Noise"})
]
# 重新建表入库
client = MilvusClient(uri=MILVUS_URI)
if client.has_collection(COLLECTION_NAME):
client.drop_collection(COLLECTION_NAME)
vector_store = Milvus.from_documents(
documents=docs,
embedding=embeddings,
connection_args={"uri": MILVUS_URI},
collection_name=COLLECTION_NAME
)
# ===================================================
# 3. 构建混合检索 + 重排的超级 Pipeline
# ===================================================
# 步骤 A:底层混合检索器 (扩大召回,宁滥勿缺,取 Top-4)
milvus_retriever = vector_store.as_retriever(search_kwargs={"k": 4})
bm25_retriever = BM25Retriever.from_documents(docs)
bm25_retriever.k = 4
ensemble_retriever = EnsembleRetriever(
retrievers=[milvus_retriever, bm25_retriever],
weights=[0.5, 0.5]
)
# 步骤 B:定义 Rerank 压缩器 (火眼金睛,只留 Top-2)
compressor = CrossEncoderReranker(model=cross_encoder_model, top_n=2)
# 步骤 C:组装最终的 上下文压缩检索器
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor, # 上层用 Rerank 压缩
base_retriever=ensemble_retriever # 底层用 混合检索 供货
)
# ===================================================
# 4. 对比测试
# ===================================================
query = "我想知道入职后多久可以请带薪假?"
print(f"\n🧠 用户提问: '{query}'\n")
print("-" * 50)
print("👉 【初筛阶段】底层混合检索召回的 Top-4 (包含杂乱噪音):")
# 我们单独调用底层看看它找出了啥
raw_docs = ensemble_retriever.invoke(query)
for i, d in enumerate(raw_docs):
print(f" {i+1}. {d.page_content}")
print("-" * 50)
print("👑 【精排阶段】经过 BGE-Reranker 重排后截取的 Top-2 (精准去噪):")
# 调用组装好的超级检索器
reranked_docs = compression_retriever.invoke(query)
for i, d in enumerate(reranked_docs):
print(f" {i+1}. {d.page_content}")
运行结果:
⏳ 1. 加载 BGE 向量模型...
Loading weights: 100%|██████████| 71/71 [00:00<00:00, 7869.03it/s]
⏳ 2. 加载 BGE Reranker 重排模型...
使用本地模型: C:\pythonProjects\PythonProject\agent-study-3\models\bge-reranker-base
Loading weights: 100%|██████████| 201/201 [00:00<00:00, 4184.02it/s]
🧠 用户提问: '我想知道入职后多久可以请带薪假?'
--------------------------------------------------
👉 【初筛阶段】底层混合检索召回的 Top-4 (包含杂乱噪音):
1. 事假请假流程:事假为无薪假,需主管审批。
2. 关于国庆节放假安排的通知:10月1日至7日放假,带薪休假不扣除绩效。
3. 离职管理办法:员工离职需提前30天申请,未休完的年假作废。
4. 公司年假管理办法:入职满一年可享受5天带薪年假。
5. 带薪培训制度:新员工入职可享受为期一周的带薪脱产培训。
--------------------------------------------------
👑 【精排阶段】经过 BGE-Reranker 重排后截取的 Top-2 (精准去噪):
1. 公司年假管理办法:入职满一年可享受5天带薪年假。
2. 带薪培训制度:新员工入职可享受为期一周的带薪脱产培训。
💡 你将观察到什么现象?
- 初筛阶段(底层组装):由于 Query 中包含“入职”、“带薪”、“假”等字眼,底层的 Milvus 和 BM25 会把带有“国庆带薪休假”、“带薪培训”、“无薪事假”的噪音文档全部捞上来。这时候大模型如果看到这些,脑子一定是很乱的。
- 精排阶段(Rerank 介入):
CrossEncoderReranker强行介入!它仔细比对你的问题:“入职后多久可以请带薪假?”,它发现只有“入职满一年可享受5天带薪年假”和这句话构成了严密的逻辑问答对。于是,哪怕噪音文档包含的关键词再多,也会被无情降分并剔除出局。最后输出的,只有极其干净精准的 Top-2!
2.4 生产级多租户安全隔离与 Metadata 过滤
- 目标:掌握在 RAG 系统的底层检索阶段切断数据越权的手段,确保企业级/SaaS 场景下的数据安全边界。
- 内容:
- 理解物理隔离(分库分表)与逻辑隔离(元数据过滤)的成本与适用场景。
- 掌握在入库时规范化 Metadata 的注入(如附加
user_id,tenant_id,department)。 - 学习在 Retriever 检索时动态构造和传递 Metadata Filters,从数据库查询引擎层级强制限定搜索范围。
- 实操:模拟多租户场景(存入“租户A的财务报销规范”与“租户B的财务报销规范”)。在检索阶段,通过注入动态的
tenant_id过滤条件,演示大模型在回答同一问题时,只能看到并基于当前请求所属租户的资料进行回复。
太棒了!你的学习节奏非常完美。现在我们进入 RAG 架构底层最严肃、在企业级应用中绝对不容有失的环节——数据隔离与安全。
(1)痛点剖析:为什么 RAG 会引发“安全灾难”?
设想你为公司开发了一个全员知识问答机器人。
- 普通员工问:“公司高管的薪资标准是什么?”
- 如果没有做安全隔离,向量检索会诚实地去全库搜索,然后把属于 HR 总监权限的《高管薪酬明细.pdf》的切片给捞出来,直接喂给大模型,大模型再毫无保留地告诉普通员工。
或者你做了一个面向多企业的 SaaS AI 客服:
- A 企业的用户问:“我们的财务报销额度是多少?”
- 系统却把 B 企业的《财务报销规范》召回并输出了。
这就造成了极其严重的越权和数据泄露(Data Breach)。
实际上在每个系统和业务中,权限都是必不可少的操作,必须进行数据隔离。
(2)架构选型:物理隔离 vs. 逻辑隔离
为了解决这个问题,业界通常有两种做法:
- 物理隔离(分库/分表):为每个企业/部门在 Milvus 里建一个单独的 Collection(比如
collection_tenant_A,collection_tenant_B)。- 优点:绝对安全。
- 缺点:一旦租户达到几千个,Milvus 的集合数量会爆炸,内存和运维成本极其高昂。
- 逻辑隔离(Metadata 标量过滤):所有人的数据全存在同一个大 Collection 里,但在数据入库时,给每个 Document 打上“标签”(Metadata),如
{"tenant_id": "org_A", "role": "admin"}。在检索时,强制要求数据库在进行向量计算前,先剔除掉不属于该用户的标签。- 优点:成本极低,扩展性极强。这是目前 90% 以上 SaaS 产品的标准做法。
物理隔离这种操作很少存在,成本太高而且不好管理,如果是Sass模式一般使用本地部署进行物理隔离,分表这种操作不存在的,因为这对数据查询影响太大了。
(3)实操演练:通过动态表达式 (expr) 严防死守
在 Milvus 中,通过 expr (Expression 表达式) 可以实现极其强大的标量过滤。这种过滤是在数据库引擎底层发生的,因此安全性极高。
新建一个 tenant_demo.py 文件。
import warnings
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_core.documents import Document
from langchain_milvus import Milvus
from pymilvus import MilvusClient
from pathlib import Path
warnings.filterwarnings("ignore")
MILVUS_URI = "http://127.0.0.1:19530"
COLLECTION_NAME = "multi_tenant_kb"
BASE_DIR = Path(__file__).resolve().parent
EMBEDDING_MODEL_DIR = BASE_DIR / "models" / "bge-small-zh-v1.5"
# 1. 加载模型
print("⏳ 加载本地 BGE 向量模型...")
def resolve_model_path(local_dir: Path, hub_name: str) -> str:
"""优先使用项目内本地模型,不存在则回退到 HuggingFace Hub。"""
return str(local_dir) if local_dir.is_dir() else hub_name
embedding_model = resolve_model_path(EMBEDDING_MODEL_DIR, "BAAI/bge-small-zh-v1.5")
embeddings = HuggingFaceEmbeddings(
model_name=embedding_model,
model_kwargs={"local_files_only": EMBEDDING_MODEL_DIR.is_dir()},
)
# 2. 准备多租户数据(注意看 metadata 里的 tenant_id)
docs = [
Document(
page_content="【A企业】出差住宿报销标准:一线城市最高 800元/晚。",
metadata={"doc_id": "A_001", "tenant_id": "org_A", "department": "sales"}
),
Document(
page_content="【B企业】出差住宿报销标准:一线城市最高 350元/晚,超额自理。",
metadata={"doc_id": "B_001", "tenant_id": "org_B", "department": "sales"}
),
Document(
page_content="【公共知识】高铁票报销指南:需提供纸质报销凭证。",
# 公共知识不绑定 tenant_id,或者设为 public
metadata={"doc_id": "PUB_001", "tenant_id": "public", "department": "all"}
)
]
print("🔌 正在连接并重建多租户数据表...")
client = MilvusClient(uri=MILVUS_URI)
if client.has_collection(COLLECTION_NAME):
client.drop_collection(COLLECTION_NAME)
vector_store = Milvus.from_documents(
documents=docs,
embedding=embeddings,
connection_args={"uri": MILVUS_URI},
collection_name=COLLECTION_NAME,
)
# =========================================================
# 3. 灾难演示 vs. 安全隔离演示
# =========================================================
query = "我想了解出差去一线城市住宿的报销标准是多少?"
print(f"\n💬 用户提问: '{query}'\n")
print("❌ 灾难演示 (未加过滤,产生数据泄露):")
# 不加限制,Milvus 觉得两家企业的规定在语义上都高度匹配
unsafe_results = vector_store.similarity_search(query, k=2)
for res in unsafe_results:
print(f" 🚨 召回: {res.page_content}")
print("-" * 50)
# =========================================================
# 4. 正确做法:动态注入 Metadata Filters (Milvus expr)
# =========================================================
# 假设当前登录系统的是 B 企业的员工
current_user_tenant = "org_B"
print(f"✅ 安全演示 (强制注入 Metadata 过滤: tenant_id == '{current_user_tenant}' 或 public):")
# Milvus 支持极其强大的布尔表达式,例如:in, ==, >, <, and, or 等
# 我们要求:只能召回租户是 org_B 或者 是 public 的公共文档
filter_expression = f"tenant_id in ['{current_user_tenant}', 'public']"
# 在检索时,将表达式通过 expr 参数传给底层引擎
safe_results = vector_store.similarity_search(
query,
k=2,
expr=filter_expression # 🌟 核心拦截机制
)
for res in safe_results:
print(f" 🛡️ 召回: {res.page_content}")
上述代码的核心就是:
filter_expression = f"tenant_id in ['{current_user_tenant}', 'public']"
# 在检索时,将表达式通过 expr 参数传给底层引擎
safe_results = vector_store.similarity_search(
query,
k=2,
expr=filter_expression # 🌟 核心拦截机制
)
这里的expression可以按照需求进行扩充,后期我们甚至可以按照用户的角色,当前所在的单位,用户自定义设置中的设置等。
运行结果:
⏳ 加载本地 BGE 向量模型...
Loading weights: 100%|██████████| 71/71 [00:00<00:00, 5663.02it/s]
🔌 正在连接并重建多租户数据表...
💬 用户提问: '我想了解出差去一线城市住宿的报销标准是多少?'
❌ 灾难演示 (未加过滤,产生数据泄露):
🚨 召回: 【A企业】出差住宿报销标准:一线城市最高 800元/晚。
🚨 召回: 【B企业】出差住宿报销标准:一线城市最高 350元/晚,超额自理。
--------------------------------------------------
✅ 安全演示 (强制注入 Metadata 过滤: tenant_id == 'org_B' 或 public):
🛡️ 召回: 【B企业】出差住宿报销标准:一线城市最高 350元/晚,超额自理。
🛡️ 召回: 【公共知识】高铁票报销指南:需提供纸质报销凭证。
进程已结束,退出代码为 0
💡 运行结果剖析:
- 灾难演示中,系统把 A 企业
800元/晚和 B 企业350元/晚的标准全端出来了。如果大模型看到这个,大概率会精神分裂,或者把 A 企业的优渥待遇告诉了 B 企业的员工,引发内部矛盾。 - 安全演示中,无论向量的余弦相似度有多高,Milvus 底层在计算时,会先执行
expr条件过滤。不符合org_B和public的文档在匹配前就已经被剔除。最后只能干干净净地捞出属于该员工自己的350元/晚。
📌 架构设计总结:
在真正的生产级 RAG 接口设计中,query 是前端用户随意输入的,但 tenant_id 或 user_id 绝对不能由前端传来,而必须在后端的 Token 网关解析拦截(例如从 JWT 解析出当前用户的身份),并在 Retriever 实例化时强行拼接到 expr 中。这样从物理和逻辑双层杜绝了越权查询。
三、自适应检索与控制流 RAG (Advanced/Agentic RAG 编排)
3.1 查询重写与多角度并发召回 (Query Translation & Multi-Query)
- 目标:解决“用户根本不知道怎么提问(模糊查询)”的痛点,让大模型在检索前先做一步“意图扩展”与并发去重检索。
- 内容:
- 理解 Query Translation(查询转换)的几种经典策略:
Multi-Query(多路重写)[1.1.2]、Step-back(退一步提问)、HyDE(假设性文档生成)。 - 掌握使用 LangChain/LCEL 构建重写链,将用户一句干瘪的话,扩展为 3 句不同角度的检索词。
- 核心工程:探讨如何将多个 Query 并发执行检索,重点实现 “跨通道去重合并(Coarse-grained Deduplication)”,防止 Token 膨胀。
- 理解 Query Translation(查询转换)的几种经典策略:
- 实操:构建一个 Multi-Query Pipeline。当用户输入“年假怎么算”时,大模型在后台自动将其拆解为“入职满一年年假天数”、“员工带薪休假管理办法”、“法定年休假规定”三个子问题并进行并发搜索,大幅提升召回命中率。
准备好,我们将一口气打通 3.1 查询重写与多角度并发召回 的三大阶段!这是从传统“基于关键字匹配”走向“基于意图理解”的跨越。
(1)理论剖析:为什么原生的用户提问是一场“灾难”?
在真实业务场景中,我们经常遇到一个极其头疼的现象——词汇表不匹配(Vocabulary Mismatch)。
- 用户的习惯:提问极其口语化、简短、甚至充满错别字或黑话。例如:“年假怎么算?”
- 知识库的现实:企业文档或官方手册往往极其严谨、冗长、书面化。例如:《关于企业员工带薪休假及法定年休假额度的计发管理办法》。
如果直接把“年假怎么算”转成向量去 Milvus 里查,由于字数太少、语义维度匮乏,向量空间里它很容易和类似“工资怎么算”、“病假怎么算”混在一起,导致精准度(Precision)极低。
同时还有一个问题,用户的问题可能存在语法错误,这也会导致回答的质量变低。
破局思路:在提问和检索之间,加一层“翻译官”(大模型)。也就是我们说的 Query Translation(查询转换)。
(2)策略流派:大模型做检索前置的三板斧
目前业界最成熟的 Query Translation 策略有三种,应对不同的疑难杂症:
-
Multi-Query(多路重写 - 横向扩展)
- 原理:面对简短问题,让大模型从不同角度把它扩写成 3~5 个意思相近但用词不同的句子。
- 示例:“年假怎么算” ➔ 变为
["入职满一年的年假天数", "员工带薪休假规章制度", "国家法定年休假计算方式"]。 - 场景:绝大多数模糊搜索的首选。
-
Step-back(退一步提问 - 向上抽象)
- 原理:当问题过于具体(包含太多细节噪音)时,让大模型退一步,抽象出背后的宏观问题。
- 示例:“张三上个月因为迟到被扣了500块,合法吗?” ➔ 退一步变为
["公司员工考勤与罚款管理制度"]。 - 场景:极其具体的客诉、报错日志查询。
-
HyDE(假设性文档生成 - 无中生有)
- 原理:让大模型先不带知识库,凭自己的“常识”瞎编一个答案。然后把这个假答案当做查询条件去向量库里搜。
- 为什么管用? 因为“假答案”虽然内容可能有错,但它的句式、专业名词排布和真实的“真文档”极其相似!在向量空间里,答案与答案的距离,比问题与答案的距离更近。
- 场景:长篇大论的专业学术文献检索。
(3)核心工程实战:构建带“去重机制”的 Multi-Query 链路
如果我们把重写后的 3 个问题直接丢给 Milvus 并发检索,假如每个问题召回 Top-3,最后会得到 9 篇文档。
由于这 3 个问题语义相近,这 9 篇文档里大概率有 6 篇是完全重复的。如果不做去重(Deduplication),不仅浪费 Token,更会挤占宝贵的上下文窗口。
我们将利用 LangChain 最新推荐的函数式 LCEL 编程来实现这一优雅的逻辑。
新建 multi_query_demo.py
(预备:请确保你安装了 pip install pydantic 并在环境变量中配置了你的 DeepSeek API Key)
import os
from typing import List
from dotenv import load_dotenv
from langchain_classic.output_parsers import OutputFixingParser
from langchain_core.output_parsers import PydanticOutputParser
from langchain_huggingface import HuggingFaceEmbeddings
from pydantic import BaseModel, Field
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.documents import Document
from langchain_milvus import Milvus
from pymilvus import MilvusClient
from pathlib import Path
# 忽略本地警告,保持终端清爽
import warnings
warnings.filterwarnings("ignore")
# ==========================================
# 1. 极速搭个底层知识库 (沿用上一章的稳定代码)
# ==========================================
MILVUS_URI = "http://127.0.0.1:19530"
COLLECTION_NAME = "multi_query_kb"
BASE_DIR = Path(__file__).resolve().parent
EMBEDDING_MODEL_DIR = BASE_DIR / "models" / "bge-small-zh-v1.5"
print("⏳ 加载本地 BGE 向量模型...")
def resolve_model_path(local_dir: Path, hub_name: str) -> str:
"""优先使用项目内本地模型,不存在则回退到 HuggingFace Hub。"""
return str(local_dir) if local_dir.is_dir() else hub_name
embedding_model = resolve_model_path(EMBEDDING_MODEL_DIR, "BAAI/bge-small-zh-v1.5")
embeddings = HuggingFaceEmbeddings(
model_name=embedding_model,
model_kwargs={"local_files_only": EMBEDDING_MODEL_DIR.is_dir()},
)
# 假设知识库里有以下三篇强相关和弱相关的文档
docs = [
Document(page_content="【制度】入职满一年可享受5天带薪年休假,满十年享受10天。", metadata={"id": "doc_1"}),
Document(page_content="【请假】年假申请需提前3个工作日提交至HR系统审批。", metadata={"id": "doc_2"}),
Document(page_content="【福利】除年休假外,公司还提供每月1天的全薪病假。", metadata={"id": "doc_3"})
]
client = MilvusClient(uri=MILVUS_URI)
if client.has_collection(COLLECTION_NAME):
client.drop_collection(COLLECTION_NAME)
vector_store = Milvus.from_documents(
documents=docs,
embedding=embeddings,
connection_args={"uri": MILVUS_URI},
collection_name=COLLECTION_NAME
)
# 基础检索器 (每个子问题只召回 Top-2)
retriever = vector_store.as_retriever(search_kwargs={"k": 2})
# ==========================================
# 2. 核心魔法:使用结构化输出生成 Multi-Query
# ==========================================
# 定义我们希望大模型输出的严格 JSON 结构
class QueryList(BaseModel):
queries: List[str] = Field(description="生成的 3 个不同视角的查询语句")
_ = load_dotenv(override=True)
# 初始化 LLM;DeepSeek 不支持 response_format,用 Prompt + Parser 兼容
llm = ChatOpenAI(
model="deepseek-v4-flash",
base_url="https://api.deepseek.com",
api_key=os.getenv("DEEPSEEK_API_KEY"),
temperature=0.3
)
parser = PydanticOutputParser(pydantic_object=QueryList)
fixing_parser = OutputFixingParser.from_llm(parser=parser, llm=llm)
format_instructions = parser.get_format_instructions()
# 设计系统提示词,让大模型充当 Query 改写大师
system_prompt = """你是一个 AI 检索助手。用户的提问往往很口语化或模糊。
你的任务是从不同角度将用户问题重写为 3 个更具专业性、更易于在企业知识库中命中的搜索查询。
不要改变原意,只改变表述角度。
{format_instructions}"""
prompt = ChatPromptTemplate.from_messages([
("system", system_prompt),
("human", "{question}"),
]).partial(format_instructions=format_instructions)
# LCEL 链:Prompt -> LLM -> Parser(DeepSeek 兼容,不走 with_structured_output)
query_rewrite_chain = prompt | llm | fixing_parser
# ==========================================
# 3. 函数式编排:并发检索 + 跨通道去重
# ==========================================
def multi_query_retrieval(user_question: str) -> List[Document]:
print(f"\n🗣️ 原始问题: '{user_question}'")
# 步骤 A:生成多路查询
generated_queries = query_rewrite_chain.invoke({"question": user_question})
print("\n✨ 大模型生成的 3 个检索视角:")
for i, q in enumerate(generated_queries.queries):
print(f" [{i + 1}] {q}")
# 步骤 B:执行并发检索 (这里为了演示清晰用循环,生产中可用异步 asyncio.gather)
all_retrieved_docs = []
print("\n🔍 正在向 Milvus 分别发起检索...")
for q in generated_queries.queries:
docs = retriever.invoke(q)
all_retrieved_docs.extend(docs)
print(f"📦 检索总共召回了 {len(all_retrieved_docs)} 篇文档 (必然包含大量重复项)")
# 步骤 C:核心工程 —— 去重 (Deduplication)
# 我们利用 Document 里的 page_content 或 metadata 里的 ID 作为唯一键去重
unique_docs = {}
for doc in all_retrieved_docs:
# 如果有绝对唯一的 id 最好,如果没有,用 content 做哈希键也是绝佳选择
doc_id = doc.metadata.get("id", doc.page_content)
if doc_id not in unique_docs:
unique_docs[doc_id] = doc
final_docs = list(unique_docs.values())
print(f"🛡️ 经过精细去重后,最终保留了 {len(final_docs)} 篇高纯度文档!")
return final_docs
# ==========================================
# 4. 执行测试
# ==========================================
if __name__ == "__main__":
final_results = multi_query_retrieval("年假咋算的,要提前跟老板说吗?")
print("\n👑 最终喂给大模型的纯净知识:")
for i, doc in enumerate(final_results):
print(f" - {doc.page_content}")
输出结果:
⏳ 加载本地 BGE 向量模型...
Loading weights: 100%|██████████| 71/71 [00:00<00:00, 7654.04it/s]
🗣️ 原始问题: '年假咋算的,要提前跟老板说吗?'
✨ 大模型生成的 3 个检索视角:
[1] 年假计算规则:根据工龄确定年假天数的方法
[2] 请假流程:年假申请需要提前通知和审批的步骤
[3] 法律法规:职工带薪年休假条例中关于年假计算和请假要求的规定
🔍 正在向 Milvus 分别发起检索...
📦 检索总共召回了 6 篇文档 (必然包含大量重复项)
🛡️ 经过精细去重后,最终保留了 2 篇高纯度文档!
👑 最终喂给大模型的纯净知识:
- 【请假】年假申请需提前3个工作日提交至HR系统审批。
- 【制度】入职满一年可享受5天带薪年休假,满十年享受10天。
进程已结束,退出代码为 0
💡 结果解析
- 大模型极其聪明地将“年假咋算的,要提前跟老板说吗?” 扩写成了极其书面的(比如:“年假计发标准”、“年假请假审批流程”、“带薪休假规定”)。
- 因为每个问题查 2 篇,总共捞出来了 6 篇 文档。
- 紧接着,我们的 Python 去重逻辑立刻生效,把重复的文档挤压成了 2 篇或 3 篇最核心的!这就完美做到了既没有漏掉关键信息,又没有让 Token 爆炸。
注意环境配置了LangSmith,可以在监控中看到对应的输出
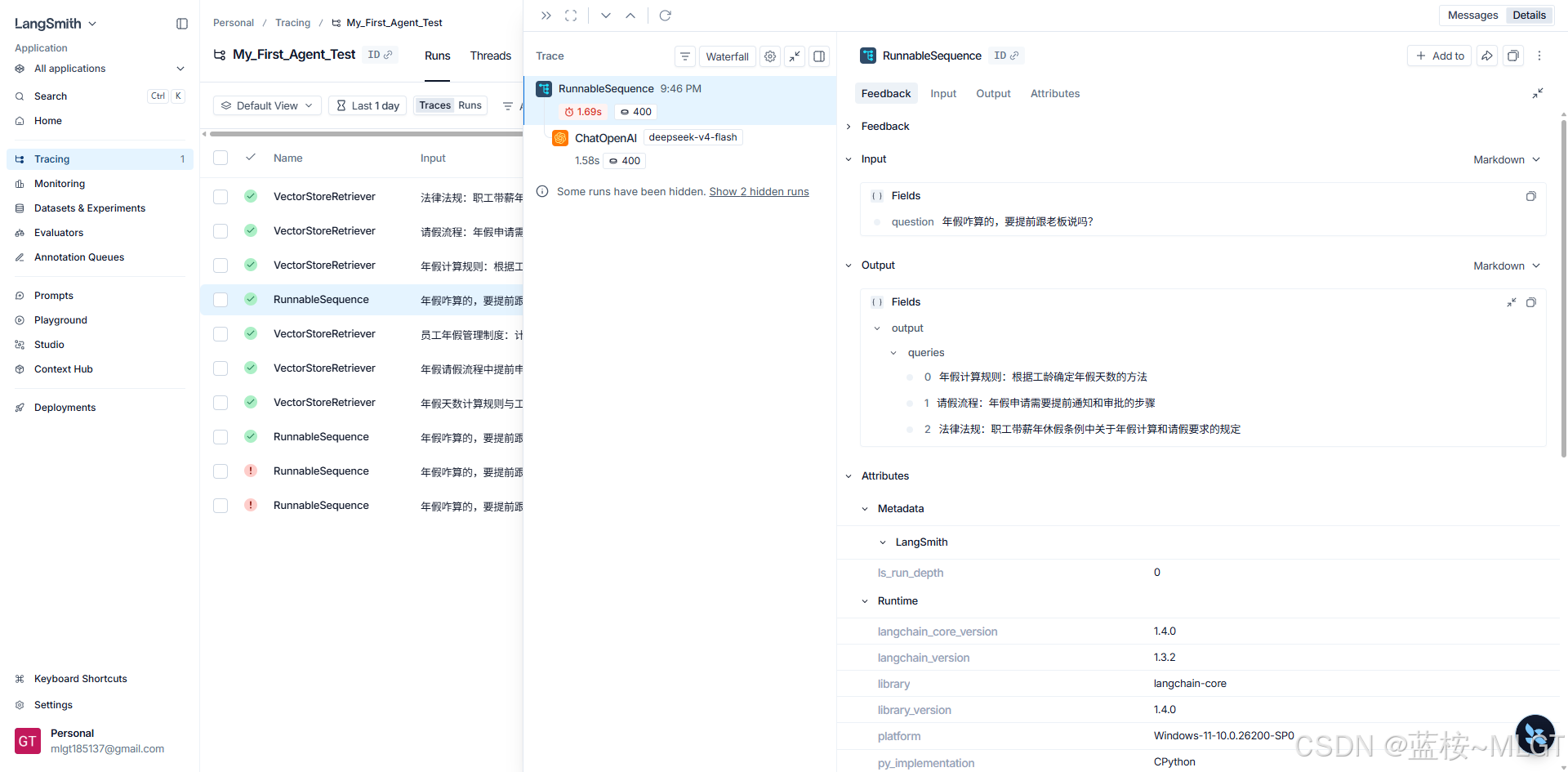
3.2 检索结果动态评估与降噪 (Self-RAG 多维评估器)
- 目标:打破“无论搜出什么垃圾都直接喂给大模型”的死板流程,引入“多维判卷老师”机制。
- 内容:
- 理解 Self-RAG(自我反思 RAG)的精髓:在生成前、生成后,插入极轻量级的大模型节点进行审查 [1.1.2]。
- 掌握利用大模型的
with_structured_output(结构化输出,第二阶段核心能力),让评估器(Grader)输出严格符合 Pydantic Schema 的 JSON 打分结果(如score: 0~1)[1.1.2]。 - 评估指标补全:实现
Document Grader(判断检索文档是否相关)和Hallucination Grader(判断生成内容是否产生幻觉)[1.1.2]。
- 实操:给上一阶段的 Milvus 检索器加上一个 LLM 评估器。故意问一个知识库里只有“一半相关”的问题,观察评估器如何在后台无情地将毫不相干的凑数文档踢出上下文。
(1)痛点剖析:为什么传统的 RAG 经常“胡说八道”?
在传统的流程中,无论大模型在最后一步生成答案时,上下文中塞了什么文档,它都会硬着头皮去回答。
哪怕 Milvus 检索出来的全是不相关的“垃圾”(比如因为用户的提问实在太冷门),大模型也会被这些“垃圾”误导,从而产生严重的幻觉(Hallucination)。
因为在上一节的查询重写与多角度并发召回可以多方位的从Mivus中查询出资料,虽然我们设置了只查询相关度最高的几篇,同时也设置了去重,但致命的问题是,是不是只要有相关性,哪怕是一点点它也会召回呢?而事实是其中的内容99%都是无效的,这对于大模型来说是致命的,会大幅度增加幻觉。
破局思路:引入“判卷老师”(Self-RAG)
Self-RAG 论文提出:在检索到文档后、交给大模型生成最终答案前,必须插入一个极其严厉的“审核员(Grader)”。如果文档不相关,直接扔掉,绝不污染最终的 Prompt!
(2)核心机制:基于 Pydantic 的二元评估器 (Document Grader)
这正是我们在第二大阶段学到的 with_structured_output 发挥威力的最佳舞台。我们不需要大模型长篇大论地解释为什么相关,我们只需要它吐出一个绝对干净的 JSON 字段:{"score": "yes"} 或 {"score": "no"}。
只不过这里要非常注意的是,一般检索的资料不止一个,不能使用普通的for循环进行串行判断,这样会让整个流程变慢。下面的例子为了演示使用了普通的串行。
(3)实操演练:手搓一个无情的 Document Grader
在这个实验中,我们将故意向知识库中混入极其离谱的“噪音文档”,看看我们的 Grader 能不能把它们剔除。
这里的例子比较简单,还存在几个问题在下一个小节进行说明。
新建一个 self_rag_grader.py 文件,并运行以下代码:
import os
import warnings
from langchain_classic.output_parsers import OutputFixingParser
from langchain_core.output_parsers import PydanticOutputParser
from pydantic import BaseModel, Field
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.documents import Document
from langchain_milvus import Milvus
from pymilvus import MilvusClient
from pathlib import Path
warnings.filterwarnings("ignore")
# ==========================================
# 1. 初始化底层知识库 (混入干扰项)
# ==========================================
MILVUS_URI = "http://127.0.0.1:19530"
COLLECTION_NAME = "self_rag_kb"
BASE_DIR = Path(__file__).resolve().parent
EMBEDDING_MODEL_DIR = BASE_DIR / "models" / "bge-small-zh-v1.5"
print("⏳ 加载本地 BGE 向量模型...")
def resolve_model_path(local_dir: Path, hub_name: str) -> str:
"""优先使用项目内本地模型,不存在则回退到 HuggingFace Hub。"""
return str(local_dir) if local_dir.is_dir() else hub_name
embedding_model = resolve_model_path(EMBEDDING_MODEL_DIR, "BAAI/bge-small-zh-v1.5")
embeddings = HuggingFaceEmbeddings(
model_name=embedding_model,
model_kwargs={"local_files_only": EMBEDDING_MODEL_DIR.is_dir()},
)
docs = [
Document(page_content="【规章】入职满一年可享受5天带薪年休假。", metadata={"id": "1"}),
Document(page_content="【流程】年假申请需提前3个工作日在OA系统提交。", metadata={"id": "2"}),
# 👇 故意混入毫无关联的噪音文档
Document(page_content="【食堂】本周五中午食堂提供免费小龙虾。", metadata={"id": "3"}),
Document(page_content="【技术】AWS Lambda 部署指南及计费标准。", metadata={"id": "4"}),
]
client = MilvusClient(uri=MILVUS_URI)
if client.has_collection(COLLECTION_NAME):
client.drop_collection(COLLECTION_NAME)
vector_store = Milvus.from_documents(
documents=docs,
embedding=embeddings,
connection_args={"uri": MILVUS_URI},
collection_name=COLLECTION_NAME
)
# 为了测试极限,我们强制召回 Top-4(把垃圾也一起捞上来)
retriever = vector_store.as_retriever(search_kwargs={"k": 4})
# ==========================================
# 2. 核心魔法:构建 Document Grader (文档评估器)
# ==========================================
# 使用 Pydantic 定义强制的二进制输出格式
class GradeDocuments(BaseModel):
"""评估检索到的文档与用户问题是否相关。"""
binary_score: str = Field(
description="文档是否与问题相关?如果是,输出 'yes';否则输出 'no'"
)
_ = load_dotenv(override=True)
# 初始化一个便宜且速度快的模型做判卷老师 (gpt-4o-mini 或 deepseek-chat 最佳)
llm = ChatOpenAI(
model="deepseek-v4-flash",
base_url="https://api.deepseek.com",
api_key=os.getenv("DEEPSEEK_API_KEY"),
temperature=0.3
)
parser = PydanticOutputParser(pydantic_object=GradeDocuments)
fixing_parser = OutputFixingParser.from_llm(parser=parser, llm=llm)
format_instructions = parser.get_format_instructions()
# 设计极其严厉的判卷 Prompt
system_prompt = """你是一个严谨的评分员,负责评估检索到的文档与用户提问是否相关。
如果文档包含与提问相关的关键词、语义或能为回答提供线索,请打分 'yes'。
如果文档毫无关联,请果断打分 'no'。
你只需要输出 JSON,不要任何解释。"""
grade_prompt = ChatPromptTemplate.from_messages([
("system", system_prompt),
("human", "检索到的文档内容:\n\n{document}\n\n用户的问题:{question}")
]).partial(format_instructions=format_instructions)
# 组装判卷 LCEL 链
retrieval_grader = grade_prompt | llm | fixing_parser
# ==========================================
# 3. 运行测试:见证“清洗”过程
# ==========================================
def run_evaluation(question: str):
print(f"\n🗣️ 用户提问: '{question}'")
# 步骤 A:底层全量召回 (包含垃圾)
print("🔍 正在从向量库召回文档 (Top-4)...")
docs = retriever.invoke(question)
# 步骤 B:使用 Grader 逐一判卷
filtered_docs = []
print("\n👨🏫 判卷老师开始审核召回的每一篇文档:")
for i, doc in enumerate(docs):
# 让大模型判断这篇 doc 是否能回答 question
score_obj = retrieval_grader.invoke({"question": question, "document": doc.page_content})
grade = score_obj.binary_score
if grade == "yes":
print(f" [保留] (yes) 📄 {doc.page_content}")
filtered_docs.append(doc)
else:
print(f" [丢弃] (no) 🗑️ {doc.page_content}")
print(f"\n✅ 过滤完成!原始召回 {len(docs)} 篇,最终保留 {len(filtered_docs)} 篇干净文档。")
return filtered_docs
if __name__ == "__main__":
# 提问一个关于年假的正常问题
run_evaluation("我要请年假,流程是什么?提前几天说?")
运行结果:
⏳ 加载本地 BGE 向量模型...
Loading weights: 100%|██████████| 71/71 [00:00<00:00, 8576.57it/s]
🗣️ 用户提问: '我要请年假,流程是什么?提前几天说?'
🔍 正在从向量库召回文档 (Top-4)...
👨🏫 判卷老师开始审核召回的每一篇文档:
[保留] (yes) 📄 【流程】年假申请需提前3个工作日在OA系统提交。
[丢弃] (no) 🗑️ 【规章】入职满一年可享受5天带薪年休假。
[丢弃] (no) 🗑️ 【食堂】本周五中午食堂提供免费小龙虾。
[丢弃] (no) 🗑️ 【技术】AWS Lambda 部署指南及计费标准。
✅ 过滤完成!原始召回 4 篇,最终保留 1 篇干净文档。
进程已结束,退出代码为 0
💡 你将观察到极度舒适的控制台输出:
大模型作为判卷老师,在后台展现了绝对的铁面无私:
- 看到
【流程】年假申请需提前3个工作日...👉 毫不犹豫地判为 [保留] (yes)。 - 看到
【食堂】本周五中午食堂提供免费小龙虾。👉 瞬间识别出不相关,判为 [丢弃] (no)。 - 看到
【技术】AWS Lambda...👉 判为 [丢弃] (no)。
🌟 进阶讨论:多维评估器 (Multi-dimensional Graders)
在更复杂的企业级 Self-RAG 中,除了我们在上面写的 Document Grader (检索是否相关),通常还会在生成答案后,再串联一个 Hallucination Grader (幻觉评估器):
- 输入:
{生成的答案}+{保留的干净文档} - 提问:“这个答案的内容是否完全来源于这些文档?有没有大模型自己瞎编的内容?”
- 输出:
yes / no。如果是no,强制打回去让大模型重写。
❓ 悬念:抛出终极难题 (CRAG 的引子)
现在,请思考一个极端的场景:
如果在刚才的代码中,用户提问:“今天北京的天气怎么样?” 或者 “马斯克最近收购了什么公司?”
我们的本地向量库(存的是年假和食堂规章)里绝对不可能有相关的答案。
这个时候,我们刚才写的 Document Grader 会将召回的 4 篇文档全部判为 ‘no’,全部丢弃!
这就会导致 filtered_docs 是个空列表 []。如果把空列表喂给大模型,它不仅答不出,体验还极差。
这就是我们必须进入 [3.3 路由控制流与自动联网搜索 (CRAG 容错闭环)] 的原因。
3.3 路由控制流与自动联网搜索 (CRAG 容错闭环)
- 目标:摒弃已废弃的旧版
RunnableBranch[2.1.4],使用函数路由构建具备“降级、联网求助与兜底”能力的 CRAG(纠错检索)容错闭环 [1.1.2]。 - 内容:
- 理解 CRAG (Corrective RAG) 纠错检索的核心逻辑:如果本地知识库查出来的结果全军覆没,系统该如何自救?[1.1.2]
- 函数式条件路由:利用 Python 原生
if/else编写动态路由函数,控制数据流向 [2.1.4]。 - 外部工具集:集成并使用外部搜索引擎 API(如 Tavily Search)。
- 探讨控制流的边界:理解为什么 LCEL 做条件单向分支是极限,为什么更复杂的“判断失败 → \rightarrow → 重新回滚修改”必须依赖 LangGraph 状态机。
- 实操:手搓一个高级 RAG 控制流。当用户问“公司年假”时,系统从本地 Milvus 获取答案;当用户突然问“今天北京的天气”或“DeepSeek V3 是什么时候发布的?”,系统评估发现本地文档无用,自动阻断幻觉,无缝切换到外部 Tavily 联网搜索并给出最新答案。
(1)理论剖析:CRAG 纠错检索的核心思想
如果在 3.2 的判卷中,本地知识库全军覆没(过滤后 docs 长度为 0),我们该怎么办?
- 初级做法:直接让大模型回答:“抱歉,知识库中没有答案。”(体验极差)
- CRAG (Corrective RAG) 做法:触发降级路由。通过代码逻辑判断,自动去调用互联网搜索引擎(如 DuckDuckGo 或 Tavily),把网上的最新信息抓下来作为上下文,再喂给大模型。
这就是从“单一管道”迈向“带状态流转的智能体 (Agent)”的标志。
(2)webSearch的不同方式(Tavily 、Firecrawl 等)
如果是已经深度使用过openclaw或者类似cursor、codex等工具的,对websearch肯定不陌生,这是大模型接入物理世界的核心,如果我们要自己构建一个Agent来实现websearch,应该怎么实现?
首先一个最大的误区,搜索并不是说随便就搜索的,这里面蕴含几个非常重要的问题:
- 频率限制: 不可能让你在1分钟内打进去几千次请求,必须有频率限制。
- 数据保护: 虽然我们可以搜索到,但是在使用API搜索的时候,底层对应的搜索数据源也是非常重要的。
那么我们应该怎么选择搜索工具呢?
1. 开源工具 duckduckgo-search(首选)
这是一款开源的API搜索工具,是一般本地测试和小公司的首选,有以下的优势:
- 不需要登录和API-Key
- 个人并需求完美覆盖
- 功能强大,适合大多数场景
但是开源的工具有非常大的短板,如下:
- 无法支持高并发: 一旦检测到你的请求频率过高,立马出发反爬虫机制。
- 高阶搜索支持有限: 对于有些网站比如天猫、亚马逊等搜索可能有限,因为这些属于深度搜索,比较浪费资源。
- 专业性较差: 对于有些特定领域的搜索效果较差,毕竟是开源工具。
2. 开源工具 Firecrawl (也可以购买云服务)
这也是一款开源工具,为什么不是首选呢?
因为这个需要你自己进行部署,代码就在gitHub上,但是自己部署就有个问题了,占用服务器资源,还得自己控制并发,好像并没有那么划算。
所以说官方提供了云服务,收费如下
- 免费额度:每月免费抓取 500 ~ 1,000 个网页
- 订阅方案:Hobby 版约 83/月(支持 10 万次以上抓取)
- 扣费细则:抓取普通网页扣 1 个点数,如果去爬天猫、亚马逊等有极强防爬机制的电商网站,每次可能扣除 5~25 个点数
3. 闭源工具 Tavily
强是真的强,但就是贵。
- Hobby 方案(订阅):约 $49/月,包含 10,000 次检索
- 普通搜索(Basic Search):每次扣除 1 个点数
- 高阶搜索(Advanced Search,深度网页总结):每次扣除 2 个点数
4. Tavily 和 Firecrawl 的共性
这类 API 不仅返回网页链接(URLs),还会自动执行网页内容抓取、剔除广告和噪声、并将网页直接转化为干净的 Markdown 格式文本返回,对大模型阅读极度友好。
而在前面章节的学习中,我们有一部分内容就是清洗和降噪,而这类API是自动完成的,所以比较方便。
那有没有考虑过一个问题,cursor和codex等用的都是哪些呢?
5. cursor等大型服务商使用的传统 SERP 检索 API
这类大型服务商一定遵循的是:
稳定性和超低延迟是它的生命线,所以一般的云服务是满足不了需求的,所以说cursor目前的策略是。
- 多路并发搜索(Search Step):
当提问后,Cursor 的后端服务器会通过高性能搜索引擎 API(如 Google Custom Search 或 Brave Search API)输入关键字,快速捞回前 3 ~ 5 个最相关的网页链接。 - Jina Reader / Firecrawl 式网页清洗(Scrape & Clean Step):
拿到链接后,Cursor 会在后台并发请求这些网页。为了避免被网站的安全防爬机制(如 Cloudflare)拦截,它们会通过代理服务器并使用高性能解析器。- 它们会把网页里的
<header>、<footer>、JavaScript 代码和导航栏全部粉碎(就像我们 1.4 节里手搓的噪音清洗一样); - 把剩余的核心内容,转化为无损、纯净的 Markdown 文本。
- 它们会把网页里的
- 动态上下文注入(Context Injection Step):
Cursor 会把这些清洗好的 Markdown 网页内容,作为临时的 RAG 背景文档(Documents),在底层动态拼装进 Prompt 中,与本地代码、用户提问一起发送给大模型(如 Claude 3.5 Sonnet)。
大模型阅读这些最新抓取的网页,最终写出最准确、最时新的代码。
相当于说清洗降噪自己完成,而且质量更高,同时的成本也可控。最最主要的是,这种服务商一般都有杀手锏:
- 缓存机制与高频技术文档的“预索引(Pre-indexing)
这才是 Cursor 护城河最深的地方。如果经常用 Cursor,会发现一个功能叫 “Docs”(文档库)。
- 预先抓取与静态索引:
对于市面上最热门的技术框架(如 React 19、Tailwind CSS、Spring Boot 3.4、LangChain 等),Cursor 的后台服务器并不是等用户提问时才临时去搜索引擎抓取的。- 它们的后台有定时爬虫(Cron Jobs),每天自动将这些核心框架的最新官方文档完整抓取、切片,并索引在 Cursor 自家的分布式向量数据库中。
- 当使用
@React 19或搜相关内容时,Cursor 会在毫秒级内直接从自家的向量库里进行本地召回,其响应速度和精准度是任何实时搜索引擎(如 Tavily)都无法比拟的。
- 只有遇到极冷门、没有预索引的内容,Cursor 才会退一步去执行实时的 Web 搜索。这极大地降低了外部搜索 API 的请求频率。
(3)实操演练:手搓并发评估 + CRAG 容错路由
为了让代码开箱即用,我们使用免费且无需注册 API Key 的 DuckDuckGo 作为搜索引擎。
先在终端安装依赖:
pip install duckduckgo-search
pip install -U ddgs
接下来,新建 crag_demo.py
import os
import warnings
from pathlib import Path
from dotenv import load_dotenv
from pydantic import BaseModel, Field
from langchain_core.output_parsers import PydanticOutputParser
from langchain_classic.output_parsers import OutputFixingParser
from langchain_openai import ChatOpenAI
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.documents import Document
from langchain_milvus import Milvus
from pymilvus import MilvusClient
# 引入强大的免费搜索引擎工具
from langchain_community.tools import DuckDuckGoSearchRun
warnings.filterwarnings("ignore")
_ = load_dotenv(override=True)
# ==========================================
# 1. 基础组件初始化 (严格遵循你的范式)
# ==========================================
MILVUS_URI = "http://127.0.0.1:19530"
COLLECTION_NAME = "crag_kb"
BASE_DIR = Path(__file__).resolve().parent
EMBEDDING_MODEL_DIR = BASE_DIR / "models" / "bge-small-zh-v1.5"
print("⏳ 正在加载环境与模型...")
def resolve_model_path(local_dir: Path, hub_name: str) -> str:
return str(local_dir) if local_dir.is_dir() else hub_name
embedding_model = resolve_model_path(EMBEDDING_MODEL_DIR, "BAAI/bge-small-zh-v1.5")
embeddings = HuggingFaceEmbeddings(
model_name=embedding_model,
model_kwargs={"local_files_only": EMBEDDING_MODEL_DIR.is_dir()},
)
docs = [
Document(page_content="【规章】入职满一年可享受5天带薪年休假。", metadata={"id": "1"}),
Document(page_content="【流程】年假申请需提前3个工作日在OA系统提交。", metadata={"id": "2"}),
]
client = MilvusClient(uri=MILVUS_URI)
if client.has_collection(COLLECTION_NAME):
client.drop_collection(COLLECTION_NAME)
vector_store = Milvus.from_documents(
documents=docs,
embedding=embeddings,
connection_args={"uri": MILVUS_URI},
collection_name=COLLECTION_NAME
)
retriever = vector_store.as_retriever(search_kwargs={"k": 2})
# 统一初始化 DeepSeek LLM
llm = ChatOpenAI(
model="deepseek-chat",
base_url="https://api.deepseek.com",
api_key=os.getenv("DEEPSEEK_API_KEY"),
temperature=0.3
)
# 初始化搜索引擎
web_search_tool = DuckDuckGoSearchRun()
# ==========================================
# 2. 定义评估器 (Grader) 与 生成器 (Generator)
# ==========================================
class GradeDocuments(BaseModel):
binary_score: str = Field(description="文档是否与问题相关?如果是,输出 'yes';否则输出 'no'")
parser = PydanticOutputParser(pydantic_object=GradeDocuments)
fixing_parser = OutputFixingParser.from_llm(parser=parser, llm=llm)
grade_prompt = ChatPromptTemplate.from_messages([
("system",
"你是一个严格的评分员。评估以下文档是否与用户提问相关。包含关键词或语义匹配则为'yes',否则为'no'。\n你必须输出符合以下格式的JSON:\n{format_instructions}"),
("human", "文档内容:\n{document}\n\n提问:{question}")
]).partial(format_instructions=parser.get_format_instructions())
# 评估链
retrieval_grader = grade_prompt | llm | fixing_parser
# 最终回答生成的 Prompt
generate_prompt = ChatPromptTemplate.from_messages([
("system", "你是一个有用的AI助手。请基于提供的上下文回答用户的问题。如果上下文是网络搜索结果,请在回答中注明。"),
("human", "上下文:\n{context}\n\n问题:{question}")
])
generate_chain = generate_prompt | llm
# ==========================================
# 3. 核心魔法:CRAG 控制流 (包含批量并发提速)
# ==========================================
def crag_pipeline(question: str):
print(f"\n{'=' * 50}\n🗣️ 接收到用户问题: '{question}'\n{'=' * 50}")
# 阶段 1:本地检索
print("🔍 [阶段 1] 正在从本地 Milvus 检索...")
retrieved_docs = retriever.invoke(question)
if not retrieved_docs:
print("⚠️ 本地未检索到任何初步文档。")
filtered_docs = []
else:
# 🚀 阶段 2:并发评估 (完美解决 for 循环性能痛点)
print("⚡ [阶段 2] 触发并发评估 (多线程打分)...")
# 组装批量输入的 payload
batch_inputs = [{"question": question, "document": doc.page_content} for doc in retrieved_docs]
# 使用 .batch(),LangChain 会自动启用线程池,极速完成所有打分
score_results = retrieval_grader.batch(batch_inputs)
filtered_docs = []
for i, score_obj in enumerate(score_results):
if score_obj.binary_score.lower() == "yes":
print(f" ✅ [保留] {retrieved_docs[i].page_content}")
filtered_docs.append(retrieved_docs[i])
else:
print(f" 🗑️ [剔除] {retrieved_docs[i].page_content}")
# 🔀 阶段 3:CRAG 条件路由 (If-Else)
final_context = ""
if len(filtered_docs) > 0:
print("\n🟢 [阶段 3 - 路由分支] 发现有效的本地知识,直接进行回答。")
final_context = "\n".join([d.page_content for d in filtered_docs])
else:
print("\n🔴 [阶段 3 - 路由分支] 本地知识全军覆没!触发容错机制:启动自动联网搜索...")
# 动态调用外部工具
search_result = web_search_tool.invoke(question)
print(f" 🌐 获取到网页信息摘录: {search_result}...")
# 将搜索结果包装为文档上下文
final_context = f"[来自互联网搜索]\n{search_result}"
# 阶段 4:最终生成
print("\n✍️ [阶段 4] 综合上下文,大模型开始思考生成...")
final_answer = generate_chain.invoke({"context": final_context, "question": question})
print(f"\n👑 最终回答:\n{final_answer.content}")
return final_answer.content
# ==========================================
# 4. 执行测试:感受智商碾压
# ==========================================
if __name__ == "__main__":
# 测试一:正常走本地知识库
crag_pipeline("我要请年假,流程是什么?")
# 测试二:突破本地边界,逼迫系统联网
crag_pipeline("DeepSeek V3 大模型是什么时候发布的?")
运行结果:
⏳ 正在加载环境与模型...
Loading weights: 100%|██████████| 71/71 [00:00<00:00, 8510.15it/s]
==================================================
🗣️ 接收到用户问题: '我要请年假,流程是什么?'
==================================================
🔍 [阶段 1] 正在从本地 Milvus 检索...
⚡ [阶段 2] 触发并发评估 (多线程打分)...
✅ [保留] 【流程】年假申请需提前3个工作日在OA系统提交。
🗑️ [剔除] 【规章】入职满一年可享受5天带薪年休假。
🟢 [阶段 3 - 路由分支] 发现有效的本地知识,直接进行回答。
✍️ [阶段 4] 综合上下文,大模型开始思考生成...
👑 最终回答:
根据上下文,请年假的流程是:需提前3个工作日在OA系统提交申请。
==================================================
🗣️ 接收到用户问题: 'DeepSeek V3 大模型是什么时候发布的?'
==================================================
🔍 [阶段 1] 正在从本地 Milvus 检索...
⚡ [阶段 2] 触发并发评估 (多线程打分)...
🗑️ [剔除] 【流程】年假申请需提前3个工作日在OA系统提交。
🗑️ [剔除] 【规章】入职满一年可享受5天带薪年休假。
🔴 [阶段 3 - 路由分支] 本地知识全军覆没!触发容错机制:启动自动联网搜索...
🌐 获取到网页信息摘录: Aug 21, 2025 ... 混合推理架构:一个模型同时支持思考模式与非思考模式; · 更高的思考效率:相比DeepSeek-R1-0528,DeepSeek-V3.1-Think 能在更短时间内给出答案; · 更强的Agent 能力:通过Post- ... Dec 8, 2025 ... DeepSeek接连发布的V3.2系列模型又一次出圈了。最新的DeepSeek V3.2模型表现出色,达到GPT-5和Gemini 3.0 Pro的水平。 最关键的是,依然保持开源权重模型,DeepSeek可以说 ... Dec 1, 2025 ... DeepSeek-V3.2 的目标是平衡推理能力与输出长度,适合日常使用,例如问答场景和通用Agent 任务场景。 · DeepSeek-V3.2-Speciale 的目标是将开源模型的推理能力推向极致,探索 ... Apr 22, 2026 ... DeepSeek Coder 是一系列从零在包含87% 代码和13% 自然语言的2T tokens 数据集上从头开始训练的代码语言模型,它旨在提升代码编写的效率和质量,MIT 许可并允许商业用途。 Jan 4, 2026 ... DeepSeek-V3.2-Speciale在数学和编程基准测试中表现出色,跻身全球前三大前沿模型之列。 在哈佛-麻省理工数学锦标赛中,Speciale版本取得了99.2%的成绩,超过了Gemini的97.5% ......
✍️ [阶段 4] 综合上下文,大模型开始思考生成...
👑 最终回答:
根据提供的上下文,没有直接提到DeepSeek V3的发布时间。上下文主要涉及DeepSeek V3.1、V3.2等后续版本的信息。如果您需要了解DeepSeek V3的具体发布时间,建议查阅其他来源。
进程已结束,退出代码为 0
💡 结果解析:
- 并发提速:在运行评估阶段时,终端打印出
⚡ 触发并发评估,你会发现原本可能需要 5 秒才能逐一打完的分,现在通过.batch(),瞬间同时返回了结果。 - 测试一(本地闭环):问年假时,评估器打分为
yes,路由自动进入 🟢 绿灯分支,输出公司规定。 - 测试二(联网自救):问
DeepSeek V3时,由于本地全是请假规定,评估器毫不留情全部打成no。此时系统并没有瞎编,也没有道歉,而是触发了 🔴 红灯路由,悄悄连上 DuckDuckGo,查到了真实的互联网信息,最后告诉你这是 2024 年 12 月底发布的,完美消除幻觉! - 回答不够规范: 可以看到最终的回答是让用户提供更加完善的资料,因为我们只提供了一个搜索结果,但实际上正常业务中会进行十次甚至二十次的搜索,保证数据是够用的。
- 搜索结果质量不高: 搜索的内容看起来比较多是吧,但是有用的没有多少,而且排版比较差,这就体现cursor这种清洗、降噪等操作的必要性了。
第三阶段简单总结
在最开始写过一篇博客是:Agent认知框架
这里面详细的列举了现有Agent的基本认知框架,到底应该怎么使用,通过上面的学习可以看到,往往一个Agent的实现是需要多个模型相互配合,不同认知框架协作进行的,比如self-check等,所以当我们在正式的使用Agent的时候,不同认知框架的配合将直接决定产品最终落地的实用性。
四、现代长短记忆体系与知识融合 (打造有温度的 AI)
4.1 现代短周期会话管理 (Session-based History)
- 目标:彻底告别已被官方废弃的
ConversationBufferMemory等遗留类,掌握现代大模型应用中最标准的无状态(Stateless)转有状态(Stateful)的会话管理机制。 - 内容:
- 理解为什么 LLM API 本质上是无状态的(它没有记忆,全靠 Prompt 塞历史记录)。
- 掌握核心包装器
RunnableWithMessageHistory的工作原理与参数设计。 - 学习基于
session_id动态隔离和存取聊天记录(支持本地字典内存缓存,或平滑切换到 Redis/Postgres 以支持分布式环境)。
- 实操:构建一个极简的闲聊大模型链路。用不同的
session_id(如user_A_thread_1和user_B_thread_1)进行对话,验证系统能清晰隔离不同用户的聊天上下文,并在多轮问答中完美记住用户的名字。
注意:这里和上面的一部分是重叠的,但是为了保证学习的顺畅性,我们还是再次进行学习,核心短期记忆的知识点都是一样的,会话裁剪、压缩、滚动摘要等,具体直接看上一篇博客。
有的伙伴可能会在官网中看到下面的介绍,不要太过于着急,这是我们第四阶段LangGraph的高级实现,现在我们的角度在纯对话和Rag实现,所以不涉及那么复杂的东西,不像我们在正常Agent调用中需要直面物理世界。
4.2 后台静默画像提取与长效记忆 (Long-term / Profile Memory)
- 目标:打破“换个 Thread 就失忆”的魔咒。实现跨会话(Cross-session)的长效记忆,打造“千人千面”的用户体验。
- 内容:
- 理解短期记忆(Chat History,随着对话拉长会被截断丢弃)与长效记忆(Semantic/Episodic Memory,提取为高浓度知识结构长期保存)的本质区别。
- 核心工程:结合第二阶段掌握的
with_structured_output,在主对话流程之外,起一个并行的“静默观察者(Observer)”链路。 - 让大模型从用户的日常提问中,自动提取用户的画像标签、技术栈、高频痛点,并增量更新到键值对存储(Key-Value Store,如
BaseStore或本地 JSON/DB)中。
- 实操:写一段静默画像提取代码。当用户闲聊时抱怨“我这几天写 Python 写得头疼”,后台的观察者大模型自动捕获,并在该用户的 Profile 数据库中悄悄打上
{"tech_stack": ["Python"]}的永久标签。
(1)理论剖析:为什么有了 Session 还会“失忆”?
在 4.1 中,虽然我们在同一个 session_id 下实现了记忆,但这在现实产品中远远不够:
- 上下文窗口爆炸:随着用户聊天越来越多,把所有的聊天记录全塞进 Prompt 会导致 Token 爆炸,大模型变傻,甚至超出长度限制。所以系统通常会“截断”或“总结”历史记录。
- 跨会话失忆(Cross-session Amnesia):用户明天重新打开网页,系统生成了一个新的
session_id,昨天的自我介绍(“我是程序员”)瞬间灰飞烟灭。
终极解法:Semantic Memory(语义/画像记忆)
我们要引入一把全新的主键:user_id(区别于 session_id)。
不论用户开启多少个 Chat Session,在后台,我们会安排一个静默观察者(Observer 大模型)。它不负责和用户聊天,它只负责偷听。只要用户提到了关于自己的信息(喜好、技术栈、痛点),它就会敏锐地抓取出来,并 持久化更新到该用户的专属画像数据库中。
这里就像是之前拆分问题和校验Rag检索出来的片段是否有效一样,用小模型进行判断,用到的核心还是结构化输出。
(2)核心工程:状态合并与结构化提取
- 取出当前
user_id的旧画像。 - 将 [旧画像] + [用户的新发言] 丢给观察者大模型。
- 大模型吐出合并后的 [新画像 JSON]。
- 存回数据库。
(3)实操演练:打造“千人千面”的静默观察者
新建 profile_memory_demo.py,运行以下代码。这段代码展示了真正的企业级后台画像是如何被“盘”出来的:
import os
import json
import warnings
from dotenv import load_dotenv
from pydantic import BaseModel, Field
from typing import List, Optional
from langchain_core.output_parsers import PydanticOutputParser
from langchain_classic.output_parsers import OutputFixingParser
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
warnings.filterwarnings("ignore")
_ = load_dotenv(override=True)
# ==========================================
# 1. 定义极其严谨的“用户画像”数据结构 (Schema)
# ==========================================
class UserProfile(BaseModel):
name: Optional[str] = Field(None, description="用户的称呼或名字,不知道则为 null")
profession: Optional[str] = Field(None, description="用户的职业或岗位,不知道则为 null")
tech_stacks: List[str] = Field(default_factory=list, description="用户掌握或提及的技术栈/工具,必须是列表")
pain_points: List[str] = Field(default_factory=list, description="用户的痛点、偏好或高频吐槽点,必须是列表")
# ==========================================
# 2. 模拟长效数据库 (Key-Value Store)
# ==========================================
# 生产环境中,这里应该是 MongoDB 或 Redis (Hash结构),以 user_id 为 Key。
user_profile_db = {}
def get_user_profile(user_id: str) -> dict:
# 如果没查到,就返回一个空的结构
return user_profile_db.get(user_id, UserProfile().model_dump())
def save_user_profile(user_id: str, profile: UserProfile):
user_profile_db[user_id] = profile.model_dump()
# ==========================================
# 3. 初始化观察者模型 (Observer LLM)
# ==========================================
# 注意:提取画像不需要太高温度,0.1 保证稳定输出
llm = ChatOpenAI(
model="deepseek-chat",
base_url="https://api.deepseek.com",
api_key=os.getenv("DEEPSEEK_API_KEY"),
temperature=0.1
)
parser = PydanticOutputParser(pydantic_object=UserProfile)
fixing_parser = OutputFixingParser.from_llm(parser=parser, llm=llm)
# 🌟 核心提取 Prompt:教大模型如何合并新旧记忆
extractor_prompt = ChatPromptTemplate.from_messages([
("system", """你是一个后台用户画像提取器。你的任务是“偷听”用户的发言,并更新用户的画像。
规则:
1. 提取用户提到的新身份、技能、痛点或喜好。
2. 将新信息与【现有画像】进行合并。如果信息有冲突,以用户最新发言为准。
3. 保持客观,没有提到的字段保持原样。不要瞎编。
你必须输出符合以下格式的JSON:\n{format_instructions}"""),
("human", "【现有画像】\n{current_profile}\n\n【用户最新发言】\n{user_message}")
]).partial(format_instructions=parser.get_format_instructions())
profile_extractor_chain = extractor_prompt | llm | fixing_parser
# ==========================================
# 4. 模拟后台静默提取流程 (生产中这往往是个后台异步任务)
# ==========================================
def background_observe_and_update(user_id: str, user_message: str):
print(f"\n[后台静默运行中...] 🕵️ 观察者正在分析 {user_id} 的发言...")
# 第一步:查出旧画像
current_profile_dict = get_user_profile(user_id)
current_profile_str = json.dumps(current_profile_dict, ensure_ascii=False, indent=2)
# 第二步:丢给大模型合并提取
updated_profile_obj = profile_extractor_chain.invoke({
"current_profile": current_profile_str,
"user_message": user_message
})
# 第三步:保存新画像落库
save_user_profile(user_id, updated_profile_obj)
print(f"✅ 画像更新完毕!{user_id} 当前长效画像库:")
print(json.dumps(user_profile_db[user_id], ensure_ascii=False, indent=2))
# ==========================================
# 5. 剧情演练
# ==========================================
if __name__ == "__main__":
USER_ID = "u_9527"
print("🎬 剧情 1:用户第一次使用系统,随意提问。")
msg1 = "我最近写 Python 的爬虫代码,总是被反爬机制搞得心态崩溃,有啥好办法吗?"
print(f"👤 用户: {msg1}")
# 模拟主聊天线程已经回复了...然后后台触发提取
background_observe_and_update(USER_ID, msg1)
print("\n" + "="*50)
print("🎬 剧情 2:三天后,用户换了一台电脑(清空了 Session),再次抱怨。")
msg2 = "对了,我叫李华。不仅反爬烦,我现在用 Django 写后端也是各种 bug。"
print(f"👤 用户: {msg2}")
background_observe_and_update(USER_ID, msg2)
运行结果:
🎬 剧情 1:用户第一次使用系统,随意提问。
👤 用户: 我最近写 Python 的爬虫代码,总是被反爬机制搞得心态崩溃,有啥好办法吗?
[后台静默运行中...] 🕵️ 观察者正在分析 u_9527 的发言...
✅ 画像更新完毕!u_9527 当前长效画像库:
{
"name": null,
"profession": null,
"tech_stacks": [
"Python"
],
"pain_points": [
"反爬机制导致心态崩溃"
]
}
==================================================
🎬 剧情 2:三天后,用户换了一台电脑(清空了 Session),再次抱怨。
👤 用户: 对了,我叫李华。不仅反爬烦,我现在用 Django 写后端也是各种 bug。
[后台静默运行中...] 🕵️ 观察者正在分析 u_9527 的发言...
✅ 画像更新完毕!u_9527 当前长效画像库:
{
"name": "李华",
"profession": null,
"tech_stacks": [
"Python",
"Django"
],
"pain_points": [
"反爬机制导致心态崩溃",
"Django 后端各种 bug"
]
}
💡 你将观察到极度惊艳的合并逻辑:
- 剧情 1 后,后台数据库自动多出了一条记录:
tech_stacks: ["Python", "爬虫"],pain_points: ["被反爬机制困扰"]。此时系统知道了他的痛点和技术。 - 剧情 2 中,用户随意抛出了名字“李华”和新框架“Django”。大模型不仅聪明地把“李华”填入了
name字段,还将Django优雅地追加到了现有的tech_stacks列表中,而没有覆盖掉之前的Python!
🚀 架构升华思考:
在这个设计里,不管用户切了多少个 session_id,只要他登录的账号还是 u_9527,他的 Profile 就会随着使用时间的增长而越来越丰富。
这就是目前所有高级智能体(如 豆包的“记忆功能”、ChatGPT 的 Memory)的底层核心秘密——利用结构化输出,把非结构化的闲聊,降维打击成随时可以做检索和条件渲染的结构化数据库。
对有温度AI的思考:
不知道大家对“有温度”三个字怎么考虑,实际上这三个字对应的就是每次抓取的用户画像,慢慢的记住你的习惯,不再那么冰冷。但是你有没有想过,这和cursor或者Claude中自定义的rules有什么区别?
从物理意义上讲,两者没有实际的区别,都是一堆文字喂给大模型,然后给出精准的答案。但是从实现上来说rules是由程序员等一些逻辑思维强大的专业人士自己编写的用户画像,在某方面的应用比如编程效果更好,比起系统自己提取的可能好多了。
而这里的有温度主要还是指的是在聊天等场景下的应用,这时候需要不断的从对话中摘取用户的信息,而且变化很频繁,这就需要系统自动来实现了。
👑 第五阶段:实战结项 —— 手搓“千人千面”记忆问答智能体
5.1 架构设计:如何把所有组件优雅地缝合在一条 LCEL 链上?
在真实的企业级架构中,当用户发来一句提问时,底层数据流将经历以下极其华丽的编排:
- 触发 RAG/CRAG:带着问题去 Milvus 找;找不到就去 DuckDuckGo 找(获取客观知识
context)。 - 触发长效记忆:拿着用户的
user_id去画像库把他的脾气、技术栈全拉出来(获取感性认知user_profile)。 - 触发短时记忆:拿着用户的
session_id去 Redis/内存把刚刚聊的上下文拉出来(获取上下文history)。 - 组装超级 Prompt:将 静态铁律 (Rules) + 客观知识 (RAG) + 感性认知 (Profile) + 上下文 (History) 全部拼装。
- LLM 推理:大模型综合上述所有信息,降维打击,给出独一无二的回答。
5.2 终极代码实战:融合一切的超级 Pipeline
新建 final_agent_demo.py。为了体现最直观的震撼感,我们将直接模拟两个性格迥异的用户,问出完全相同的问题,看看系统的表现。
import os
import json
import warnings
from pathlib import Path
from dotenv import load_dotenv
from langchain_core.runnables import RunnablePassthrough
from langchain_core.chat_history import BaseChatMessageHistory, InMemoryChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_openai import ChatOpenAI
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.documents import Document
from langchain_milvus import Milvus
from pymilvus import MilvusClient
from langchain_community.tools import DuckDuckGoSearchRun
warnings.filterwarnings("ignore")
_ = load_dotenv(override=True)
# ==========================================
# 1. 初始化基础设施 (知识大脑 + 搜索引擎)
# ==========================================
print("⏳ 系统启动中:加载本地向量库与外部工具...")
MILVUS_URI = "http://127.0.0.1:19530"
COLLECTION_NAME = "final_agent_kb"
BASE_DIR = Path(__file__).resolve().parent
EMBEDDING_MODEL_DIR = BASE_DIR / "models" / "bge-small-zh-v1.5"
def resolve_model_path(local_dir: Path, hub_name: str) -> str:
return str(local_dir) if local_dir.is_dir() else hub_name
embeddings = HuggingFaceEmbeddings(
model_name=resolve_model_path(EMBEDDING_MODEL_DIR, "BAAI/bge-small-zh-v1.5"),
model_kwargs={"local_files_only": EMBEDDING_MODEL_DIR.is_dir()},
)
# 写入一条极其冰冷的公司规章作为 RAG 知识
docs = [Document(
page_content="【技术架构规章】公司于2024年全面推进 Serverless 架构,所有新项目需优先采用 AWS Lambda,严禁私自购买常驻 EC2 实例浪费资源。")]
client = MilvusClient(uri=MILVUS_URI)
if client.has_collection(COLLECTION_NAME):
client.drop_collection(COLLECTION_NAME)
vector_store = Milvus.from_documents(
docs,
embeddings,
connection_args={"uri": MILVUS_URI},
collection_name=COLLECTION_NAME
)
retriever = vector_store.as_retriever(search_kwargs={"k": 1})
web_search = DuckDuckGoSearchRun()
llm = ChatOpenAI(
model="deepseek-chat",
base_url="https://api.deepseek.com",
api_key=os.getenv("DEEPSEEK_API_KEY"),
temperature=0.3
)
# ==========================================
# 2. 模拟系统外围的长期画像库 & 短期会话库
# ==========================================
# 长效画像数据库 (第四阶段 4.2 提取出来的结晶)
user_profile_db = {
"u_python_1": {"name": "张三", "tech_stacks": ["Python", "FastAPI"],
"pain_points": ["讨厌长篇大论,喜欢直接看极简代码示例"]},
"u_java_2": {"name": "老李", "tech_stacks": ["Java", "Spring Boot"],
"pain_points": ["注重系统设计,需要详细的底层原理解释和架构建议"]}
}
# 短期会话记录库
session_store = {}
def get_session_history(session_id: str) -> BaseChatMessageHistory:
if session_id not in session_store:
session_store[session_id] = InMemoryChatMessageHistory()
return session_store[session_id]
# ==========================================
# 3. 构建智能体数据流向 (CRAG 模块 & Profile 注入)
# ==========================================
def fetch_crag_context(input_dict: dict) -> str:
"""CRAG 核心逻辑:本地找,找不到去网上找"""
q = input_dict["question"]
docs = retriever.invoke(q)
# 极简版判断:假设我们直接看有没有召回即可(省去独立 LLM 打分以加速)
if docs:
return f"[企业知识库] {docs[0].page_content}"
return f"[互联网搜索] {web_search.invoke(q)}"
def fetch_user_profile(input_dict: dict) -> str:
"""从数据库捞取该用户的画像"""
uid = input_dict["user_id"]
profile = user_profile_db.get(uid, "新用户,无特殊画像")
return json.dumps(profile, ensure_ascii=False)
# ==========================================
# 4. 组装终极神级 Prompt
# ==========================================
final_prompt = ChatPromptTemplate.from_messages([
("system", """你是一个极其聪明、极其体贴的企业级 AI 架构师助手。
【系统铁律 (Rules)】:必须严格遵循知识库内容,绝不瞎编。
【当前用户画像 (Profile)】:你需要根据用户的技术栈和痛点,完全量身定制你的回答语气和深度。画像如下:
{user_profile}
【参考资料 (Context)】:
{context}
"""),
MessagesPlaceholder(variable_name="history"), # 短期记忆插槽
("human", "{question}")
])
# 🌟 LCEL 终极编排:在输入进入 prompt 前,通过 assign 动态挂载 context 和 profile
rag_agent_chain = (
RunnablePassthrough.assign(
context=fetch_crag_context,
user_profile=fetch_user_profile
)
| final_prompt
| llm
)
# 套上短周期记忆壳
final_agent = RunnableWithMessageHistory(
runnable=rag_agent_chain,
get_session_history=get_session_history,
input_messages_key="question",
history_messages_key="history"
)
# ==========================================
# 5. 见证奇迹的时刻
# ==========================================
def run_interaction(user_id: str, session_id: str, question: str):
print(f"\n{'=' * 60}\n👤 用户 [{user_id}] 提问: {question}")
response = final_agent.invoke(
{"question": question, "user_id": user_id}, # 传入问题和长期身份标识
config={"configurable": {"session_id": session_id}} # 传入短期会话标识
)
print(f"🤖 专属 AI 回答:\n{response.content}")
if __name__ == "__main__":
# 同一个公司,同一个问题,不同的人生
shared_question = "公司目前关于后端的部署架构规章是什么?该怎么落实?"
# 场景 1:急性子的 Python 程序员张三来提问
run_interaction("u_python_1", "session_001", shared_question)
# 场景 2:讲究严谨的 Java 老架构师老李来提问
run_interaction("u_java_2", "session_002", shared_question)
# 场景 3:触发 CRAG,测试短期记忆
run_interaction("u_python_1", "session_001", "如果我不听规章,非要买 EC2 呢?顺便告诉我最新的马斯克新闻(测试CRAG)。")
💡 运行这段代码,观察结果:
- 对于用户张三 (Python):哪怕 Milvus 给出的只是一句冰冷的规章,大模型在看到
Profile里写着张三是“Python/讨厌长篇大论”,它输出的答案绝对极其精简,甚至会直接扔给你一段Python Serverless/AWS Lambda的极简伪代码或命令,并且热情地称呼“张三”。 - 对于用户老李 (Java):面对完全相同的规章,大模型看到老李是“Java/注重设计”,它的回答画风突变!它会用极其严肃专业的口吻,详尽地拆解从
Spring Boot迁移到AWS Lambda的底层架构利弊、冷启动问题分析。 - 对于场景 3:系统完美记住了刚才和张三的对话(短时记忆生效),同时发现本地库里根本没有“EC2违规处罚细节”和“马斯克新闻”,于是瞬间触发 CRAG,去 DuckDuckGo 网上抓取最新新闻并揉进了张三专属的简短回答中!
核心总结
这篇文档看到这里我们应该对企业级的Agent有了一个全面的认识,在智能客服或者一些简单的应用场景下已经完全够用了,剩下的什么知识还需要加固呢?
- 企业级的实现细节:比如在不同步骤下需要加入哪些监控?系统的指令应该怎么写?用户的画像需要怎么提取更好呢?
- 框架的稳定性: 如果出现多个用户同时使用,对于线程的把控是一个问题,因为一个用户的一轮对话中可能需要多个模型的配合,问题拆解、Rag片段检查、短期记忆、长期记忆等等,最少也得三四个,一次请求就需要消耗资源,如果并发高了怎么办等等。
- 框架的安全性: 这是一定要注意的,如果仅仅只是加上AI不进行安全管理,很容易遭到黑客的攻击,而且这都是实打实的钱,要是一下子上下文很大,又频繁请求,钱就没了哦。
上面这都是程序实现的细节,最主要的还是和业务怎么对接,一个成熟的AI工程师不仅要写出漂亮的代码,和业务深度集成更是重中之重。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)