2024年中国大型数据中心空间分布及环境属性数据集
2024年中国大型数据中心空间分布及环境属性数据集

数据介绍:
这是一个填补信息空白的重要数据集。由于大型数据中心的具体位置、占地等信息通常不公开,难以准确评估其巨大的能耗和环境影响。本研究通过创新的方法,首次系统性地识别和定位了全国范围内的大型数据中心。
数据集包含哪些核心内容?

数据集主要由两部分构成:
1. 从多源 POI 记录中验证大型数据中心的地理位置;
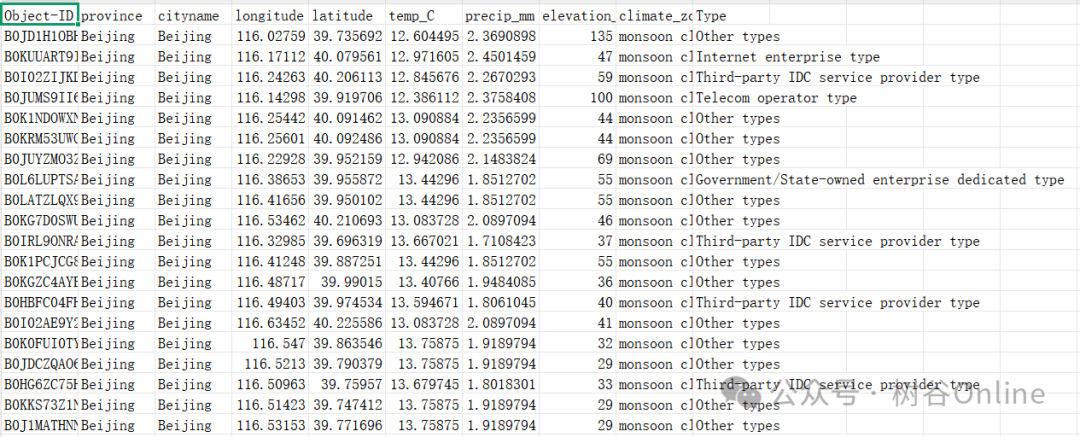
-
数量与精度:包含了 1005个 经过人工核实确认的大型数据中心精确位置(经纬度坐标)。
-
环境属性:每个点位都附带了其所在城市的四项关键环境属性:
-
气候带
-
海拔
-
年平均温度
-
年降水量
-
2. 由随机森林分类模型得出的数据中心分布的空间概率面;

-
内容:这是一张全国范围的栅格地图,每个像素(10米分辨率)的值代表了该位置存在大型数据中心的相对可能性(概率),而非简单的“是或否”。
-
价值:这张图可以揭示那些未公开登记、但具有类似选址特征的数据中心潜在分布区域,是对已验证点位数据的重要补充。
从 Google 地球获得的数据中心屋顶的代表性卫星图像,其中为每个省剪取了一张典型图像,包含以下省。

例:安徽

数据是如何构建的?
研究采用了“POI验证 + 遥感特征 + 机器学习”的综合方法:
-
数据收集与验证:
-
初始数据:从高德地图(Amap)抓取所有标注为“数据中心”的兴趣点(POI)。
-
人工核验:研究人员逐一核对,剔除重复、误标(如小型机房、IT办公室)的记录,并借助高分辨率卫星影像确认其是否为大型工业建筑,最终得到1005个可靠的正样本。
-
-
构建遥感特征库:
-
Sentinel-2光谱波段(可见光、近红外、短波红外)。
-
光谱指数:如归一化植被指数(NDVI)、归一化建筑指数(NDBI),用于区分植被、建筑、水体。
-
纹理特征:从影像中计算对比度、熵等指标,捕捉大型工业建筑规则、均一的屋顶结构。
-
夜间灯光数据:作为人类活动和工业强度的指示器,帮助区分高能耗的数据中心与其他类似建筑。
-
围绕每个点位,从多种遥感数据源中提取了16维特征,用于描述其光谱和空间结构,包括:
-
-
机器学习建模:
-
模型:采用随机森林(Random Forest)模型。
-
训练:以1005个已验证的数据中心作为正样本,另采集2010个涵盖植被、水体、裸地、其他工业设施等的负样本进行训练。
-
策略:考虑到中国不同省份数据中心的外观和周边环境差异巨大,研究没有使用单一的全国模型,而是为10个主要省级行政区分别训练了独立的区域模型,以提高识别精度。
-
产出:模型最终输出的是每个像素属于数据中心的概率值,从而生成了全国范围的“空间概率表面”。
-
数据格式:TIF、CSV
数据容量:85.0GB
数据获取:数据资源:2024年中国大型数据中心空间分布及环境属性数据集

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)