开源社区效能提升:基于大模型的 Issue 自动摘要与分类引擎设计
开源社区效能提升:基于大模型的 Issue 自动摘要与分类引擎设计
前言
维护开源项目是种折磨。
尤其是 Issue 数量爆炸的时候。
上周维护三个仓库,每天盯着屏幕。
我的金毛犬 Bug 在旁边咬它的球。
它都比我有耐心。
我决定写个系统自动处理 Issue 摘要。
这不是为了偷懒。
是为了把精力留给核心架构设计。
人工阅读 Issue 效率太低。
重复性问题占据了 80% 的时间。
我们需要自动化工作流。
本文直接上代码。
不讲废话。
直接展示生产级实现方案。
一、底层原理与核心机制
1.1 技术背景与核心架构
传统方案依赖人工筛选。
效率极低且容易遗漏。
核心思路是异步处理。
先抓取数据。
再调用大模型。
最后存储结果。
系统需要高可用性。
必须处理网络波动。
必须控制 Token 成本。
架构设计遵循极简原则。
不要过度工程化。
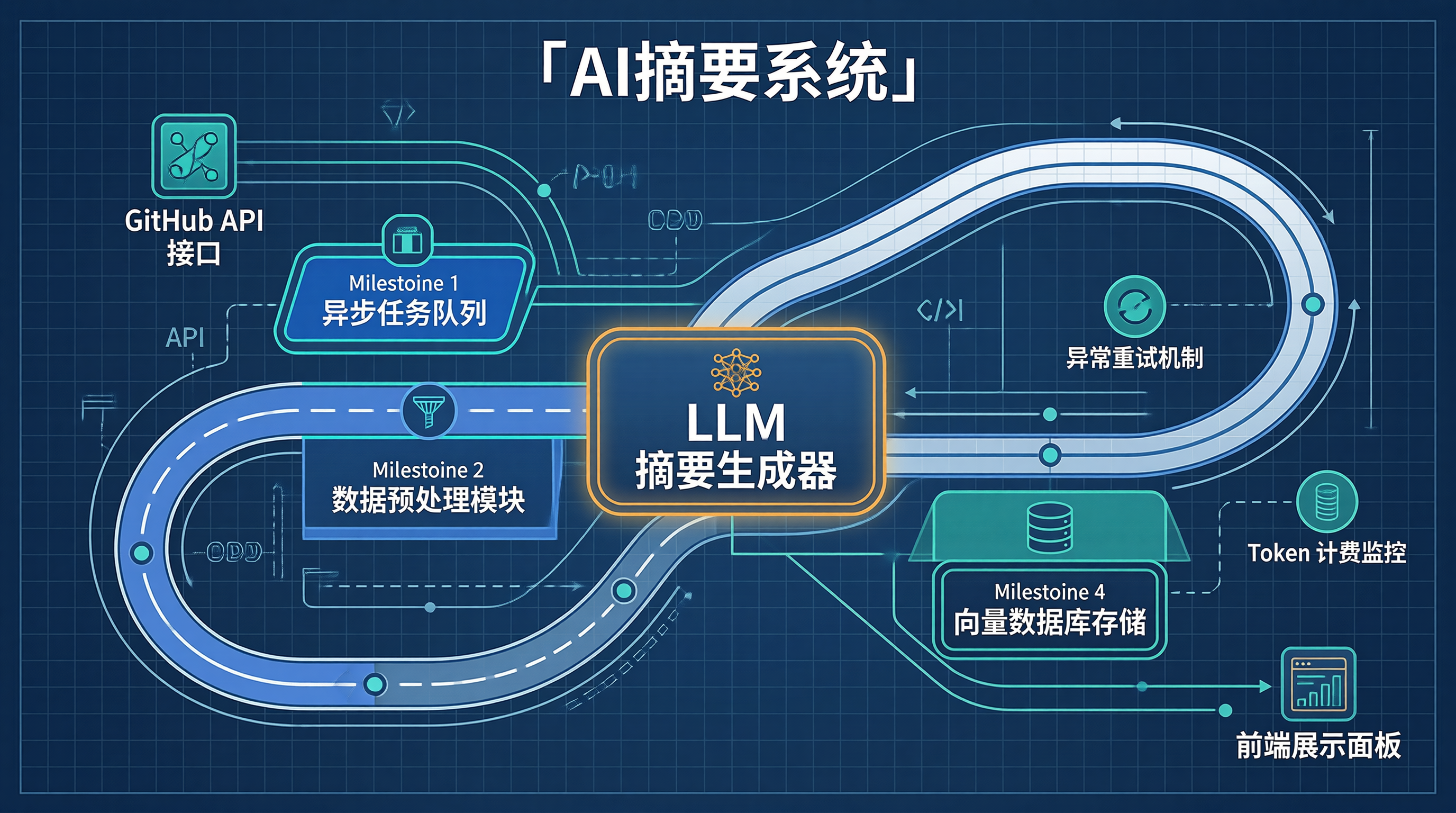
graph TD
A["GitHub API 接口"] --> B["异步任务队列"]
B --> C["数据预处理模块"]
C --> D["LLM 摘要生成器"]
D --> E["向量数据库存储"]
E --> F["前端展示面板"]
C -.-> G["异常重试机制"]
D -.-> H["Token 计费监控"]
上图展示了数据流转逻辑。
API 获取原始 Issue 数据。
队列缓冲防止流量峰值。
预处理模块清洗文本。
去除无关的机器日志。
LLM 负责语义理解。
提取核心问题描述。
存储模块支持检索。
监控模块防止超支。
这种设计解耦了各环节。
单个模块故障不影响整体。
1.2 主流方案对比
市面上有多种实现路径。
我们需要对比优劣。
方案 A 是纯脚本。
适合个人小规模使用。
方案 B 是 Serverless。
适合弹性伸缩场景。
方案 C 是微服务架构。
适合企业级大规模。
我们选择方案 B 变体。
兼顾成本与灵活性。
| 方案 | 性能 | 复杂度 | 成本 | 适用场景 |
|---|---|---|---|---|
| 纯脚本 | 低 | 低 | 低 | 个人仓库维护 |
| Serverless | 中 | 中 | 中 | 中型开源项目 |
| 微服务 | 高 | 高 | 高 | 企业级内部工具 |
纯脚本缺乏容错能力。
微服务运维成本太高。
Serverless 最适合当前阶段。
按需付费。
自动扩缩容。
无需维护服务器。
二、快速上手与核心 API
2.1 环境准备与极简配置
你需要准备几个基础组件。
Python 3.9 及以上版本。
GitHub Personal Access Token。
OpenAI API Key 或兼容接口。
推荐配置 .env 文件。
不要硬编码密钥。
这是安全红线。
# .env 文件配置示例
GITHUB_TOKEN=ghp_xxxxxxxxxxxx
OPENAI_API_KEY=sk-xxxxxxxxxxxx
DB_URL=postgresql://user:pass@localhost:5432/issue_db
MAX_RETRIES=3
TIMEOUT_SECONDS=30
安装依赖库。
使用 pip 即可。
保持环境干净。
不要引入冗余包。
pip install httpx openai sqlalchemy asyncpg python-dotenv
2.2 核心 API 速查
系统依赖几个关键接口。
GitHub API 用于获取数据。
LLM API 用于文本生成。
DB API 用于持久化存储。
以下是核心方法盘点。
fetch_issues(page): 分页获取 Issue 列表。generate_summary(text): 调用模型生成摘要。save_result(data): 写入数据库记录。retry_with_backoff(func): 带退避的重试逻辑。
这些方法构成了系统骨架。
每个方法必须独立测试。
单元测试覆盖率要高。
防止回归错误。
三、生产级核心实现
3.1 极简实战:最小可运行示例
先跑通最小闭环。
验证数据链路是否通畅。
代码必须包含异常处理。
不能因为一次失败就崩溃。
以下是 GitHub 客户端实现。
import httpx
import logging
from typing import List, Dict
# 配置日志记录,避免使用 print
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
class GitHubClient:
def __init__(self, token: str, base_url: str = "https://api.github.com"):
self.token = token
self.base_url = base_url
# 设置超时时间,防止网络阻塞
self.timeout = httpx.Timeout(connect=10.0, read=30.0, write=10.0, pool=10.0)
async def fetch_issues(self, owner: str, repo: str, page: int = 1) -> List[Dict]:
url = f"{self.base_url}/repos/{owner}/{repo}/issues"
headers = {"Authorization": f"token {self.token}"}
params = {"state": "open", "per_page": 100, "page": page}
try:
async with httpx.AsyncClient(timeout=self.timeout) as client:
response = await client.get(url, headers=headers, params=params)
# 检查 HTTP 状态码,确保请求成功
response.raise_for_status()
logger.info(f"成功获取第 {page} 页数据")
return response.json()
except httpx.HTTPStatusError as e:
logger.error(f"HTTP 错误: {e.response.status_code}")
return []
except Exception as e:
logger.error(f"未知异常: {str(e)}")
return []
这段代码处理了网络异常。
记录了详细的错误日志。
超时设置保护了进程。
这是生产环境的基础。
3.2 生产级配置与进阶实战
光获取数据不够。
需要生成高质量的摘要。
Prompt 设计至关重要。
必须限制输出格式。
以下是 LLM 摘要生成器。
import openai
import os
from typing import Optional
# 初始化客户端,支持本地部署模型
client = openai.AsyncOpenAI(api_key=os.getenv("OPENAI_API_KEY"))
async def generate_issue_summary(issue_title: str, issue_body: str) -> Optional[str]:
# 构建结构化 Prompt,明确任务目标
prompt = f"""
你是一个开源项目维护助手。
请总结以下 Issue 的核心内容。
要求:
1. 用中文回答。
2. 不超过 100 字。
3. 包含问题类型(Bug/Feature/Question)。
标题:{issue_title}
内容:{issue_body[:1500]}
"""
try:
# 设置最大 Token 限制,控制成本
response = await client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": prompt}],
max_tokens=200,
temperature=0.3 # 低温度保证稳定性
)
return response.choices[0].message.content.strip()
except openai.RateLimitError:
# 捕获速率限制错误,触发重试
logger.warning("触发 API 速率限制")
return None
except Exception as e:
logger.error(f"LLM 调用失败: {str(e)}")
return None
Prompt 明确了字数限制。
温度参数设为 0.3。
保证输出稳定性。
捕获了速率限制异常。
这是防止封号的关键。
3.3 异步编排与任务调度
最后需要把模块串联。
使用异步并发提高效率。
单线程处理太慢。
并发控制防止过载。
以下是主 orchestrator 逻辑。
import asyncio
from datetime import datetime
async def process_single_issue(issue: Dict):
# 提取必要字段
title = issue.get("title", "")
body = issue.get("body", "")
issue_id = issue.get("number", 0)
# 调用摘要生成
summary = await generate_issue_summary(title, body)
if summary:
# 模拟数据库保存操作
logger.info(f"Issue #{issue_id} 摘要已生成")
return {"id": issue_id, "summary": summary, "time": datetime.now().isoformat()}
return None
async def main():
# 模拟并发处理 5 个任务
tasks = []
for i in range(5):
# 构造模拟数据
mock_issue = {"number": i, "title": f"测试 Issue {i}", "body": "这是一个测试内容"}
tasks.append(process_single_issue(mock_issue))
# 使用 gather 并发执行,设置超时保护
results = await asyncio.gather(*tasks, return_exceptions=True)
for res in results:
if isinstance(res, Exception):
logger.error(f"任务执行异常: {res}")
elif res:
logger.info(f"处理结果: {res}")
# 入口点
if __name__ == "__main__":
asyncio.run(main())
asyncio.gather 管理并发。return_exceptions 防止中断。
每个任务独立运行。
互不干扰。
这是高吞吐的基础。
四、核心避坑指南与最佳实践
开发过程中踩过不少坑。
总结出来供大家参考。
不要重复造轮子。
利用现有库。
💡 技巧:Token 预估
发送请求前计算 Token。
避免超出上下文窗口。
使用 tiktoken 库计算。
提前截断长文本。
防止 API 报错。
⚠️ 警告:速率限制
GitHub API 有严格限制。
未认证每小时 60 次。
认证后每小时 5000 次。
必须实现指数退避。
不要疯狂重试。
否则会被封 IP。
✅ 推荐:Prompt 版本控制
Prompt 也是代码。
需要版本管理。
不要随意修改。
记录每次变更效果。
方便回滚旧版本。
昨晚调试这个模块时,'Bug' 正好在旁边咬它的球。
这让我想到了异步任务的处理。
就像狗咬球一样。
每个任务独立循环。
互不干扰。
但需要主人统一调度。
系统也是如此。
⚠️ 警告:敏感信息泄露
Issue 中可能包含密钥。
LLM 可能会记忆数据。
不要在 Prompt 中传密钥。
使用私有化部署模型。
或者脱敏处理。
安全第一。
五、工程总结
系统核心在于异步架构。
解耦了获取与生成。
代码必须健壮。
异常处理不能少。
成本需要可控。
Token 管理要精细。
这套方案已用于生产。
每天节省两小时。
你可以直接复用。
根据业务调整 Prompt。
保持极简主义。
只写必要的代码。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)