GPU Operator 是什么?和 NVIDIA Device Plugin 是什么关系?
一、为什么 Kubernetes 需要额外支持 GPU?
在 Kubernetes 里,CPU 和内存是最基础的资源。平时写 Pod 的时候,经常会这样配置:
resources:
requests:
cpu: "1"
memory: "1Gi"
limits:
cpu: "2"
memory: "2Gi"
CPU 和内存是 Kubernetes 原生就能识别和调度的资源。kubelet 可以知道当前节点有多少 CPU、有多少内存,scheduler 也可以根据这些资源把 Pod 调度到合适的节点上。
但是 GPU 不一样。GPU 属于特殊硬件资源,Kubernetes 本身不会直接内置 NVIDIA、AMD、Intel 等所有硬件厂商的设备管理逻辑。因为不同厂商的设备发现方式、驱动方式、容器挂载方式都不一样,如果 Kubernetes 核心代码把这些逻辑全部写进去,维护成本会非常高。Kubernetes 的设计思路是:
Kubernetes 不直接内置具体硬件厂商的 GPU 管理逻辑
↓
Kubernetes 提供 Device Plugin 机制
↓
硬件厂商实现自己的 Device Plugin
↓
Device Plugin 把设备注册给 kubelet
↓
节点上出现对应的扩展资源
↓
Pod 通过 resources.limits 申请这些资源
对于 NVIDIA GPU 来说,这个插件就是 NVIDIA Device Plugin。
安装并运行 NVIDIA Device Plugin 之后,节点上才会出现类似下面的资源:
nvidia.com/gpu
Pod 才能通过下面这种方式申请 GPU:
resources:
limits:
nvidia.com/gpu: 1
也就是说,在 Kubernetes 里使用 NVIDIA GPU,不能只看宿主机上有没有驱动,还要看 Kubernetes 能不能识别和调度这个 GPU 资源。
为了更好理解这件事,把 GPU 使用场景拆成三层:物理机环境、容器环境、Kubernetes 环境。
1. 物理机环境:核心是 NVIDIA Driver
在物理机上使用 NVIDIA GPU,最核心的是 NVIDIA Driver。Driver 的作用是让操作系统能够识别和驱动 NVIDIA GPU。驱动安装正常后,通常可以通过下面命令查看 GPU:
nvidia-smi
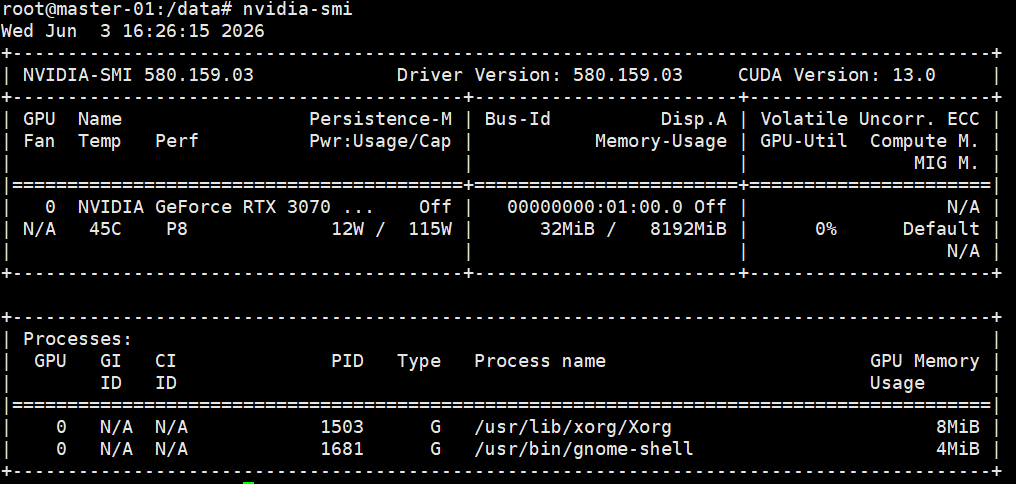
如果能正常输出 GPU 型号、Driver Version、CUDA Version、显存使用情况等信息,说明宿主机层面的 NVIDIA Driver 基本是正常的。nvidia-smi 输出里的 CUDA Version,表示当前 Driver 支持的 CUDA 运行时能力上限。如果只是运行已经打包好的 CUDA 应用,通常重点是保证 Driver 版本满足应用或容器内 CUDA Runtime 的兼容要求。
如果要在宿主机上编译、开发 CUDA 程序,比如使用 nvcc 编译 CUDA 代码,那还需要安装 CUDA Toolkit。CUDA Toolkit 里包含编译器、头文件、库文件、调试工具等开发组件。
所以物理机环境可以简单理解为:
NVIDIA GPU 硬件
↓
NVIDIA Driver
↓
nvidia-smi / CUDA 程序
这一层解决的问题是:操作系统能不能识别和驱动 GPU。
2. 容器环境:核心是 NVIDIA Container Toolkit
到了 Docker 或 containerd 环境,只安装 NVIDIA Driver 还不够。因为容器默认是隔离的。宿主机上有 GPU,不代表容器里天然能看到 GPU。容器要使用 GPU,需要解决几个问题:
-
GPU 设备文件怎么暴露给容器;
-
NVIDIA 驱动相关库怎么挂载进容器;
-
容器运行时怎么知道这个容器需要 GPU;
-
容器启动时应该注入哪些 NVIDIA 相关能力。
这时候就需要 NVIDIA Container Toolkit。NVIDIA Container Toolkit 的作用可以简单理解为:让 Docker、containerd、CRI-O 等容器运行时具备启动 GPU 容器的能力。
容器环境中的关系大概是:
宿主机 NVIDIA Driver
↓
NVIDIA Container Toolkit
↓
Docker / containerd / CRI-O
↓
容器内可以使用 GPU
如果宿主机执行 nvidia-smi 正常,但是容器里执行 nvidia-smi 失败,通常就要重点排查 NVIDIA Container Toolkit 和容器运行时配置。例如 Docker 环境下,常见验证方式是:
docker run --rm --gpus all nvidia/cuda:12.4.1-base-ubuntu22.04 nvidia-smi
如果这个命令能正常输出 GPU 信息,说明容器运行时访问 GPU 的链路基本打通了。
这一层解决的问题是:容器能不能使用宿主机 GPU。
3. Kubernetes 环境:核心是 NVIDIA Device Plugin
到了 Kubernetes 环境,事情又多了一层。Kubernetes 不是简单启动一个容器,它还要负责调度。Kubernetes 必须先知道哪些节点有 GPU、每个节点有几张 GPU、GPU 是否还能被分配,然后 scheduler 才能把需要 GPU 的 Pod 调度过去。在 Kubernetes 中,完整链路至少包含这些步骤:
kubelet 需要知道本节点有几张 GPU
scheduler 需要知道哪些节点有 GPU 资源
Pod 需要声明自己要申请几张 GPU
容器启动时需要真正拿到 GPU 设备
这些事情不是 NVIDIA Driver 自己能完成的,也不是 NVIDIA Container Toolkit 自己能完成的。
Driver 负责宿主机识别 GPU。
Container Toolkit 负责容器运行时使用 GPU。
Device Plugin 负责把 GPU 注册给 Kubernetes,让 Kubernetes 能调度 GPU。
所以 Kubernetes 环境中的关系可以理解为:
NVIDIA Driver
↓
NVIDIA Container Toolkit
↓
NVIDIA Device Plugin
↓
kubelet 注册 nvidia.com/gpu
↓
scheduler 根据 nvidia.com/gpu 调度 Pod
↓
GPU Pod 启动后使用 GPU
这就是 Kubernetes 需要额外支持 GPU 的原因。简单总结:
物理机:Driver 让宿主机识别 GPU
容器:Container Toolkit 让容器能使用 GPU
Kubernetes:Device Plugin 让 Kubernetes 能调度 GPU
二、NVIDIA Device Plugin 是什么?
NVIDIA Device Plugin 是 NVIDIA 提供的 Kubernetes Device Plugin 实现。它通常以 DaemonSet 的形式运行在每个 GPU 节点上。它最核心的作用有三个:
第一,发现当前节点上的 NVIDIA GPU
第二,把 GPU 注册给 kubelet
第三,让 Pod 可以通过 nvidia.com/gpu 申请 GPU
可以把它理解成 Kubernetes 和 NVIDIA GPU 之间的“设备注册员”。没有它,宿主机可能有 GPU,容器运行时也可能配置好了,但是 Kubernetes scheduler 不知道这个节点有 GPU,也就没法基于 GPU 资源进行调度。
1. Kubernetes 默认不认识 NVIDIA GPU
Kubernetes 默认知道 CPU 和内存,但不会天然知道 NVIDIA GPU。在没有 NVIDIA Device Plugin 的情况下,即使宿主机上执行 nvidia-smi 正常,kubectl describe node 里通常也不会出现 nvidia.com/gpu 资源。可以通过下面命令查看节点资源:
kubectl describe node <node-name>
如果 NVIDIA Device Plugin 正常工作,应该能看到类似内容:
Capacity:
cpu: 16
memory: 32780000Ki
nvidia.com/gpu: 1
Allocatable:
cpu: 16
memory: 32780000Ki
nvidia.com/gpu: 1
这里有两个字段需要注意:
-
Capacity:节点总资源; -
Allocatable:节点可分配给 Pod 的资源。
如果这里没有 nvidia.com/gpu,说明 Kubernetes 还没有识别出可调度的 NVIDIA GPU 资源。
2. Device Plugin 负责把 GPU 注册成 nvidia.com/gpu
NVIDIA Device Plugin 会和 kubelet 通信,把节点上的 NVIDIA GPU 注册成 Kubernetes 扩展资源。这个资源名通常是:
nvidia.com/gpu
这不是随便写的名字,而是 NVIDIA Device Plugin 注册出来的资源名。所以 Pod 里申请 GPU 时,应该这样写:
resources:
limits:
nvidia.com/gpu: 1
3. Pod 如何申请 GPU
一个最简单的 GPU Pod 可以这样写:
apiVersion: v1
kind: Pod
metadata:
name: gpu-test
spec:
restartPolicy: OnFailure
containers:
- name: cuda
image: nvidia/cuda:12.4.1-base-ubuntu22.04
command: ["nvidia-smi"]
resources:
limits:
nvidia.com/gpu: 1
这里最关键的是:
resources:
limits:
nvidia.com/gpu: 1
这表示这个容器需要申请 1 张 NVIDIA GPU。Kubernetes 对 GPU 这类设备资源有一个特点:GPU 通常写在 limits 里。如果同时写 requests 和 limits,两个值需要保持一致。实际使用中,很多场景只写 limits.nvidia.com/gpu 即可。
当这个 Pod 创建后,scheduler 会寻找满足条件的节点:
节点上必须有 nvidia.com/gpu 资源
节点剩余可分配 GPU 数量要大于等于 1
节点还要满足 CPU、内存、亲和性、污点容忍等其它调度条件
如果这些条件都满足,Pod 才能调度到对应 GPU 节点。
三、GPU Operator 是什么?
NVIDIA Device Plugin 解决的是 Kubernetes 识别和调度 GPU 的问题。但是在生产环境里,只解决这个问题是不够的。一个完整的 Kubernetes NVIDIA GPU 节点,通常还需要:
NVIDIA Driver
NVIDIA Container Toolkit
NVIDIA Device Plugin
Node Feature Discovery
GPU Feature Discovery
DCGM
DCGM Exporter
MIG Manager
Validator
如果这些组件全部手工安装和维护,会有很多问题。比如:
每个 GPU 节点的 Driver 版本可能不一致
有的节点安装了 Toolkit,有的节点没安装
containerd 配置不统一
Device Plugin 版本和驱动版本不匹配
新增 GPU 节点时需要人工初始化
DCGM Exporter 需要单独部署
GPU 节点标签需要手工维护
MIG 配置需要单独处理
组件异常时排查链路很长
GPU Operator 的目标就是简化这些事情。它通过 Kubernetes Operator 的方式,把 NVIDIA GPU 软件栈纳入 Kubernetes 的声明式管理中。简单理解:
以前:
手工安装 Driver
手工安装 Toolkit
手工部署 Device Plugin
手工部署 GFD
手工部署 DCGM Exporter
手工做监控和排障
现在:
安装 GPU Operator
配置 ClusterPolicy
由 Operator 自动部署和维护 GPU 软件栈
1. Operator 的作用
Operator 可以理解为 Kubernetes 里的自动化运维控制器。平时我们创建 Deployment,只需要声明期望状态,比如副本数是 3:
spec:
replicas: 3
Deployment Controller 会持续检查实际状态。如果当前只有 2 个 Pod,它会自动再创建 1 个 Pod,让实际状态接近期望状态。
Operator 的思想也类似,只不过它管理的不是普通业务 Pod,而是一套复杂的软件系统。
GPU Operator 管理的就是 NVIDIA GPU 软件栈。整体逻辑是:
用户通过 Helm 安装 GPU Operator
↓
集群中创建 ClusterPolicy 这个自定义资源
↓
GPU Operator 监听 ClusterPolicy 中声明的期望配置
↓
GPU Operator 根据 ClusterPolicy 部署和维护 Driver、Toolkit、Device Plugin、GFD、DCGM Exporter 等组件安装 GPU Operator 后,集群中会出现一个名为 ClusterPolicy 的自定义资源。ClusterPolicy 可以理解为 GPU Operator 的核心配置对象,用来声明 NVIDIA GPU 软件栈的期望状态,例如是否安装 Driver、是否部署 Container Toolkit、是否启用 Device Plugin、是否启用 DCGM Exporter、是否启用 MIG Manager 等。GPU Operator 会监听 ClusterPolicy,并根据其中的配置去创建和维护对应的 DaemonSet、Deployment、Service 等 Kubernetes 资源。
2. GPU Operator 管理哪些组件
GPU Operator 管理的组件比较多,常见核心组件包括:
NVIDIA Driver
NVIDIA Container Toolkit
NVIDIA Device Plugin
Node Feature Discovery
GPU Feature Discovery
DCGM / DCGM Exporter
MIG Manager
Operator Validator
这些组件不是简单堆在一起的,而是有依赖关系。可以画成下面这条链路:
GPU 硬件
↓
NFD 发现节点硬件特征
↓
NVIDIA Driver 驱动 GPU
↓
NVIDIA Container Toolkit 配置容器运行时
↓
NVIDIA Device Plugin 注册 nvidia.com/gpu
↓
GFD 生成 NVIDIA GPU 相关节点标签
↓
DCGM / DCGM Exporter 采集 GPU 指标
↓
Validator 校验 GPU 软件栈是否可用
上面这张图主要用于理解组件之间的职责关系,不代表 GPU Operator 内部所有 Pod 的严格启动顺序。实际部署顺序和 Pod 名称可能会随着 GPU Operator 版本变化。
3. 为什么生产环境更倾向用 GPU Operator
生产环境更倾向用 GPU Operator,不是因为 NVIDIA Device Plugin 不重要,而是因为生产环境不只是要求“能跑一个 GPU Pod”。生产环境还要关注:
GPU 节点初始化是否标准
Driver 是否统一
容器运行时配置是否一致
Device Plugin 是否稳定运行
GPU 节点标签是否完整
监控指标是否自动暴露
MIG 配置是否可管理
组件异常后是否方便排查
后续升级是否可控
如果只部署 NVIDIA Device Plugin,很多事情还是要手工维护。比如:
手工安装 NVIDIA Driver
手工安装 NVIDIA Container Toolkit
手工配置 containerd 或 Docker
手工部署 GFD
手工部署 DCGM Exporter
手工维护版本兼容关系
手工处理不同节点的差异
这些事情在单节点实验环境里问题不大,但到了生产集群就很容易失控。比如一个集群有 10 台 GPU 节点:
A 节点 Driver 是 535
B 节点 Driver 是 550
C 节点 containerd 没配 NVIDIA runtime
D 节点 Device Plugin 没起来
E 节点没有 GFD 标签
F 节点 DCGM Exporter 没有指标
这类问题排查起来非常麻烦。GPU Operator 的价值就是把这些组件纳入统一管理,让 GPU 节点的软件栈更标准、更一致,也更容易排障。可以这样总结:
NVIDIA Device Plugin:
解决 Kubernetes 识别和调度 GPU 的问题
GPU Operator:
解决 Kubernetes GPU 软件栈统一部署、管理、校验、监控的问题
四、GPU Operator 里的核心组件
1. NVIDIA Driver
NVIDIA Driver 是最底层的组件。
没有 Driver,操作系统无法正常驱动 NVIDIA GPU,nvidia-smi 通常也无法正常工作。
GPU Operator 默认可以通过 Driver DaemonSet 在 GPU 节点上安装或管理 NVIDIA Driver。
但是如果宿主机已经提前安装好了 NVIDIA Driver,就可以在安装 GPU Operator 时关闭 Operator 的驱动安装能力:
--set driver.enabled=false
driver.enabled=false 适合宿主机已经提前安装好 NVIDIA Driver 的场景。设置这个参数后,GPU Operator 不再负责给节点安装 NVIDIA Driver,而是使用宿主机已有的驱动。
2. NVIDIA Container Toolkit
NVIDIA Container Toolkit 负责让容器运行时支持 NVIDIA GPU。
在 Kubernetes 中,Pod 最终还是由 containerd、CRI-O 或 Docker 这类容器运行时启动。
即使宿主机上 Driver 正常,如果容器运行时没有配置好,容器里也可能无法访问 GPU。
NVIDIA Container Toolkit 的作用可以理解为:
把宿主机 GPU 设备和 NVIDIA 驱动能力正确注入到容器中
GPU Operator 可以部署 toolkit 组件,自动配置容器运行时。
如果宿主机已经提前安装并配置好了 NVIDIA Container Toolkit,也可以关闭:
--set toolkit.enabled=false
但是这个参数不要随便关。只有在确认宿主机上的 NVIDIA Container Toolkit 已经安装好,并且容器运行时已经正确配置时,才适合关闭。
3. NVIDIA Device Plugin
NVIDIA Device Plugin 是 GPU Operator 管理的核心组件之一。
它的作用是把 NVIDIA GPU 注册给 kubelet,让节点暴露出:
nvidia.com/gpu
如果 Device Plugin 正常,查看节点时应该能看到:
kubectl describe node <node-name>
输出中会出现:
Capacity:
nvidia.com/gpu: 1
Allocatable:
nvidia.com/gpu: 1
如果没有这个资源,Pod 写了下面配置也没有用:
resources:
limits:
nvidia.com/gpu: 1
因为 scheduler 根本找不到满足 nvidia.com/gpu 的节点。
4. Node Feature Discovery
Node Feature Discovery,简称 NFD。
它的作用是发现节点上的硬件和系统特征,并把这些特征写成 Kubernetes Node Label。
GPU Operator 默认会通过节点标签识别哪些节点是 NVIDIA GPU 节点。常见标签类似:
feature.node.kubernetes.io/pci-10de.present=true
其中 10de 是 NVIDIA 的 PCI Vendor ID。这个标签的意思是:当前节点存在 NVIDIA PCI 设备。
有了这个标签,GPU Operator 才能判断哪些节点是 GPU 节点,然后只在这些节点上部署相关组件。NFD 的价值在于自动化发现节点能力。如果没有 NFD,你可能需要手工给 GPU 节点打标签。节点少的时候还能接受,节点多的时候很容易出错。
5. GPU Feature Discovery
GPU Feature Discovery,简称 GFD。NFD 更偏通用硬件发现,而 GFD 更关注 NVIDIA GPU 自身的信息。GFD 会基于 NVIDIA GPU 信息给节点生成更细的标签,例如:
nvidia.com/gpu.present=true
nvidia.com/gpu.count=1
nvidia.com/gpu.product=...
nvidia.com/cuda.driver.major=...
nvidia.com/cuda.runtime.major=...
不同 GPU、不同驱动、不同 GPU Operator 版本下,具体标签可能会有差异。GFD 的作用主要是方便调度和运维。例如集群里有多种 GPU:
RTX 3070
A10
A30
A100
H100
如果某个业务只想运行在指定型号的 GPU 节点上,就可以结合 GFD 生成的标签,通过 nodeSelector 或 nodeAffinity 做调度约束。示例:
nodeSelector:
nvidia.com/gpu.product: NVIDIA-GeForce-RTX-3070
6. DCGM / DCGM Exporter
DCGM 是 NVIDIA Data Center GPU Manager,用于 GPU 管理和监控。
DCGM Exporter 则负责把 GPU 指标转换成 Prometheus 可以抓取的 metrics。
它会暴露类似下面的 HTTP 接口:
/metrics
Prometheus 抓取这些指标后,就可以在 Grafana 中展示 GPU 监控面板。常见 GPU 指标包括:
GPU 利用率
显存使用量
显存剩余量
GPU 温度
GPU 功耗
XID 错误
GPU 进程或 Pod 相关指标
7. Operator Validator
Operator Validator 用于校验 GPU Operator 部署出来的组件是否真的可用。
在 GPU Operator 安装完成后,经常能看到类似 Pod:
nvidia-operator-validator
nvidia-cuda-validator
Validator 会检查一些关键链路,例如:
Driver 是否正常
Container Toolkit 是否正常
CUDA 容器是否能运行
Device Plugin 是否正常
GPU 资源是否能被 Kubernetes 使用
例如 GPU Operator 相关 Pod 都起来了,但是 GPU Pod 还是无法运行,就可以优先看 validator 相关 Pod 的状态和日志:
kubectl get pod -n gpu-operator
kubectl logs -n gpu-operator <validator-pod-name>
如果 validator 报错,通常说明 GPU 软件栈某个环节还没有打通。
8. MIG Manager
MIG 是 Multi-Instance GPU 的缩写,主要用于支持 MIG 的 NVIDIA GPU,例如 A100、H100 等。
MIG 可以把一张物理 GPU 切分成多个 GPU 实例,不同实例之间具备更强的隔离能力。
MIG Manager 的作用是管理 MIG 配置。它可以根据节点标签调整 MIG 切分方式。例如通过给节点打标签触发 MIG 配置:
kubectl label nodes <node-name> nvidia.com/mig.config=all-1g.10gb --overwrite
五、GPU Operator 和 NVIDIA Device Plugin 的关系
1. Device Plugin 可以单独部署
NVIDIA Device Plugin 可以不依赖 GPU Operator,单独以 DaemonSet 的方式部署到 Kubernetes 集群中。如果只是想让 Kubernetes 能够识别 GPU,并让 Pod 通过 nvidia.com/gpu 申请 GPU,那么理论上单独部署 NVIDIA Device Plugin 就可以。但是前提是:
宿主机已经安装 NVIDIA Driver
宿主机已经安装 NVIDIA Container Toolkit
容器运行时已经正确配置
GPU 节点环境比较统一
你自己负责 GFD、DCGM Exporter、监控、升级和排障
也就是说,单独部署 Device Plugin 更适合比较简单的环境,例如:
单节点实验环境
临时测试环境
已经手工维护好 GPU 软件栈的环境
只想验证 Kubernetes 是否能调度 GPU Pod 的场景
它的优点是简单、轻量、组件少。
缺点是生产维护能力弱,很多事情都要自己做。
2. GPU Operator 会自动部署 Device Plugin
GPU Operator 不是替代 NVIDIA Device Plugin,而是会自动部署和管理 NVIDIA Device Plugin。
可以这样理解:NVIDIA Device Plugin 是一个具体组件,GPU Operator 是管理整套 NVIDIA GPU 软件栈的 Operator。它们之间的关系类似:
GPU Operator
├── NVIDIA Driver
├── NVIDIA Container Toolkit
├── NVIDIA Device Plugin
├── Node Feature Discovery
├── GPU Feature Discovery
├── DCGM / DCGM Exporter
├── MIG Manager
└── Validator
所以 Device Plugin 是 GPU Operator 管理对象中的一个核心组件。如果把 Kubernetes GPU 能力拆开看:
Driver 负责让宿主机识别 GPU
Container Toolkit 负责让容器能使用 GPU
Device Plugin 负责让 Kubernetes 能调度 GPU
GFD 负责生成 GPU 节点标签
DCGM Exporter 负责让 Prometheus 监控 GPU
Validator 负责校验 GPU 软件栈是否正常
GPU Operator 负责统一管理上述组件
3. 生产环境为什么更推荐 Operator 方式
生产环境里更推荐 GPU Operator,主要原因是它降低了 GPU 节点运维复杂度。
如果只装 NVIDIA Device Plugin,整个链路大概是这样:
手工安装 Driver
手工安装 Toolkit
手工配置 containerd
手工部署 Device Plugin
手工部署 GFD
手工部署 DCGM Exporter
手工接入 Prometheus
手工处理版本兼容
手工排查组件异常
如果使用 GPU Operator,链路变成:
安装 GPU Operator
配置 ClusterPolicy
由 Operator 统一部署和维护 GPU 软件栈
这对生产环境很重要。尤其是 GPU 节点比较多的时候,手工维护很容易出现问题。GPU Operator 的价值就是把这些组件纳入 Kubernetes 的声明式管理中,让 GPU 软件栈更标准、更统一、更容易排障。
总结
从底层到上层,可以这样理解:
NVIDIA Driver
↓
让宿主机识别和驱动 GPU
NVIDIA Container Toolkit
↓
让容器运行时可以启动 GPU 容器
NVIDIA Device Plugin
↓
让 Kubernetes 可以识别和调度 GPU
GPU Feature Discovery
↓
给 GPU 节点生成更细的标签
DCGM Exporter
↓
暴露 GPU 监控指标给 Prometheus
GPU Operator
↓
统一部署、管理、校验和监控 NVIDIA GPU 软件栈
NVIDIA Device Plugin 很重要,但它只解决 GPU 资源注册和调度问题。
GPU Operator 则站在更高一层,负责管理完整的 NVIDIA GPU 软件栈。
所以它们不是替代关系,而是包含关系:
GPU Operator 会管理 NVIDIA Device Plugin;
NVIDIA Device Plugin 是 GPU Operator 管理的核心组件之一。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 22
22 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)