AIOps 故障排查:大模型辅助线上故障根因分析方法与生产实践
·
AIOps 故障排查:大模型辅助线上故障根因分析方法与生产实践
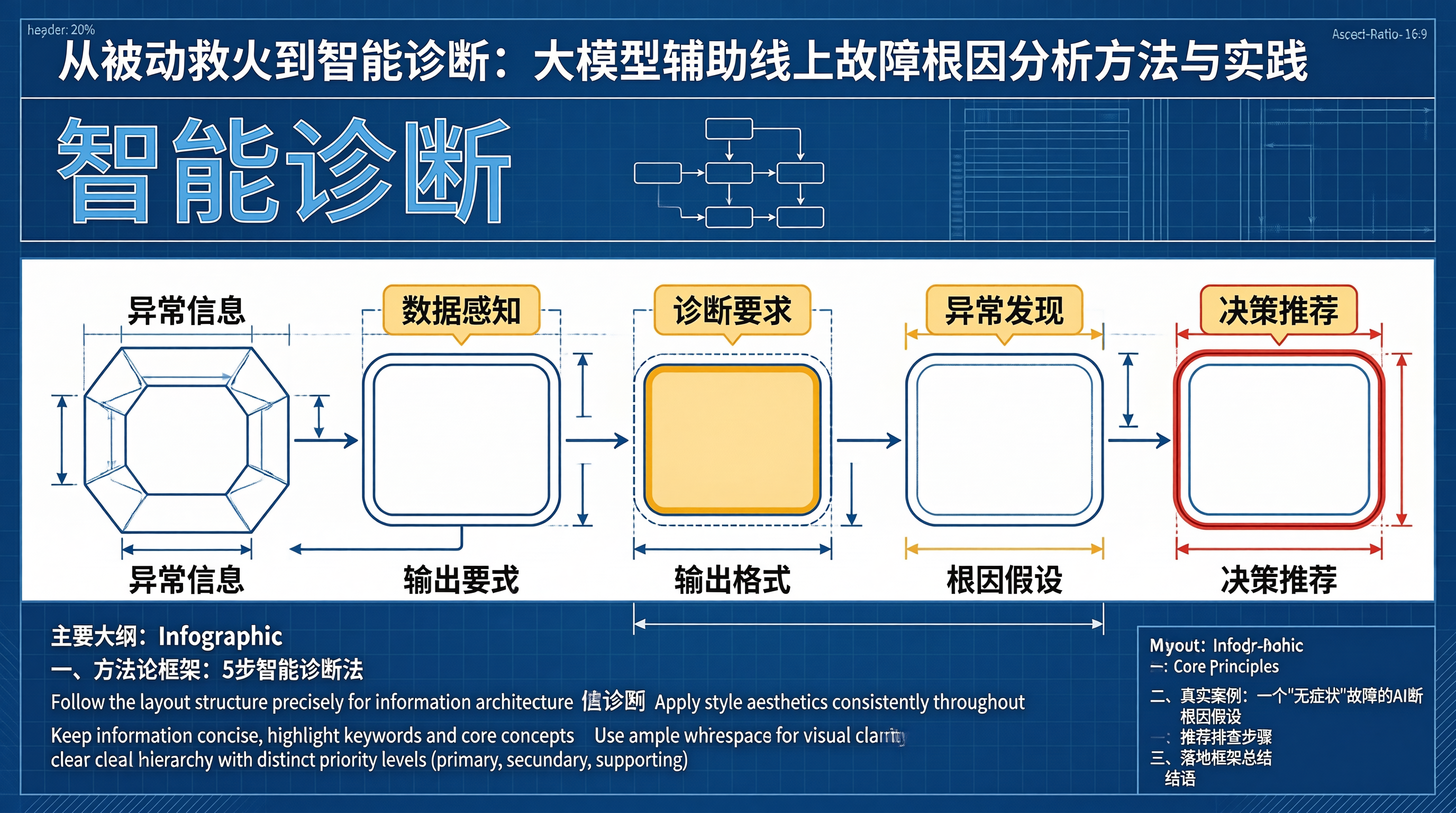
一、方法论框架:5步智能诊断法
我们在实践中总结了一套"5步智能诊断法":
flowchart TD
A["Step 1: 数据感知"] --> B["自动收集告警/指标/日志"]
B --> C["Step 2: 异常发现"]
C --> D["多维度异常检测"]
D --> E["Step 3: 根因假设"]
E --> F["AI生成Top N假设"]
F --> G["Step 4: 证据验证"]
G --> H["自动验证每个假设"]
H --> I["Step 5: 决策推荐"]
I --> J["输出排查路线图"]
1.1 Step 1:数据感知
传统的"数据收集"依赖告警触发,但很多故障根本不会触发告警。我们的做法是主动感知——持续监控指标的变化率,而不是绝对值:
# anomaly_perception.py — 主动异常感知
class ProactiveAnomalyPerception:
"""主动异常感知器"""
def analyze_rate_of_change(self, service: str) -> dict:
"""分析所有指标的环比变化率"""
metrics = self._get_all_metrics(service)
alerts = []
for name, data in metrics.items():
current_avg = data[-5:].mean() # 最近5分钟均值
previous_avg = data[-30:-5].mean() # 之前25分钟均值
if previous_avg == 0:
continue
change_rate = (current_avg - previous_avg) / previous_avg * 100
# 变化率超过20%就标记为异常(即使绝对值在阈值内)
if abs(change_rate) > 20:
alerts.append({
'metric': name,
'change_rate': f"{change_rate:+.1f}%",
'current': float(current_avg),
'previous': float(previous_avg),
'severity': 'high' if abs(change_rate) > 50 else 'medium'
})
return alerts
这个方法的精妙之处在于:它不关心阈值是多少,只关心变化有多大。一个指标从10涨到12,变化率20%——在传统阈值体系里很可能被忽略,但在我们的感知器里已经是"medium"级别的异常了。
1.2 Step 2:多维异常发现
单指标异常分析有局限性。我们把异常分为三个维度:
# multidimensional_anomaly.py — 多维异常发现
class MultidimensionalAnomalyDetector:
"""多维异常发现"""
def detect(self, service: str) -> dict:
anomalies = {
'point_anomalies': [], # 点异常:单指标突变
'trend_anomalies': [], # 趋势异常:持续偏离
'correlation_anomalies': [] # 相关异常:指标间关系破坏
}
# 1. 点异常检测(3-sigma)
for metric, series in self.metrics.items():
is_anomaly, score = self._point_anomaly(series)
if is_anomaly:
anomalies['point_anomalies'].append({
'metric': metric,
'score': score,
'type': 'sudden_spike' if score > 0 else 'sudden_drop'
})
# 2. 趋势异常检测(Prophet)
for metric, series in self.metrics.items():
is_anomaly = self._trend_anomaly(series)
if is_anomaly:
anomalies['trend_anomalies'].append({
'metric': metric,
'type': 'gradual_increase' if is_anomaly == 'up' else 'gradual_decrease'
})
# 3. 相关性异常检测
# 例如:正常情况下"请求量↑ → CPU↑ → 延迟↑"是联动的
# 如果"请求量↑但CPU不↑"或"请求量不变但延迟↑",说明有异常
cpu_vs_qps = self._correlation_analysis('cpu', 'qps')
if abs(cpu_vs_qps) < 0.5: # 相关系数低于0.5,关联关系被破坏
anomalies['correlation_anomalies'].append({
'pair': ('cpu', 'qps'),
'correlation': cpu_vs_qps,
'message': '请求量和CPU的关联关系被破坏'
})
return anomalies
1.3 Step 3-5:AI推理引擎
# ai_reasoning_engine.py — AI推理引擎
class AIReasoningEngine:
"""AI推理引擎"""
def diagnose(self, service: str, anomalies: dict) -> str:
"""执行诊断推理"""
context = self._build_context(service, anomalies)
prompt = f"""你是一个SRE工程师,正在诊断{service}的异常。
## 二、异常信息
### 2.1 点异常(突变)
{json.dumps(anomalies['point_anomalies'], indent=2, ensure_ascii=False)}
### 2.2 趋势异常(持续性)
{json.dumps(anomalies['trend_anomalies'], indent=2, ensure_ascii=False)}
### 2.3 相关性异常(关联破坏)
{json.dumps(anomalies['correlation_anomalies'], indent=2, ensure_ascii=False)}
## 三、诊断要求
请按以下步骤分析:
1. 对每种异常类型,判断其可能的原因
2. 找出所有异常中最早出现的那个(极可能是根因)
3. 分析异常之间的级联关系
4. 排除那些是"果"而非"因"的异常
5. 给出Top 3根因假设,每个假设附带:
- 证据支持强度(高/中/低)
- 对应的证据编号
- 建议的验证方法
## 四、输出格式
### 4.1 根因假设1: [名称]
- 证据强度: [高/中/低]
- 支持证据: [引用异常点]
- 反对证据: [如果有]
- 验证方法: [具体的命令或查询]
- 置信度: [%]
### 4.2 根因假设2: ...
"""
return self._call_llm(prompt)
五、真实案例:一个"无症状"故障的AI诊断
5.1 故障现象
用户投诉支付页面加载慢,但所有基础指标都在阈值内:
| 指标 | 值 | 阈值 | 状态 |
|---|---|---|---|
| CPU | 32% | >90%告警 | 正常 |
| 内存 | 45% | >90%告警 | 正常 |
| P99延迟 | 3.2s | >3s告警 | 刚触发 |
| 错误率 | 0.5% | >1%告警 | 正常 |
传统告警只有"延迟超阈值"一条,但AI感知器发现了更多异常:
【变化率分析】
1. active_threads: 20→180 (+800%) ← 关键线索
2. task_queue_depth: 0→350 ← 关键线索
3. db_connection_pool_usage: 40%→72% ← 伴随异常
4. cpu: 28%→32% (+14%) ← 正常波动
5. memory: 42%→45% (+7%) ← 正常波动
【时间线】
16:30:00 active_threads 开始上升
16:31:30 task_queue_depth 开始上升
16:32:00 P99延迟开始上升
16:33:00 开始出现用户投诉
5.2 AI诊断输出
## 六、根因假设
### 6.1 假设1: 线程池配置不足(置信度:85%)
- 证据:active_threads从20飙升至180(+800%),但CPU仅从28%升至32%
- 推理:线程池在频繁上下文切换而非真正计算
- 验证:jstack看线程状态,检查是否有大量BLOCKED线程
### 6.2 假设2: 下游服务响应变慢(置信度:10%)
- 证据:db_connection_pool_usage从40%升至72%
- 推理:数据库查询变慢导致连接被长期占用,线程等待DB响应
- 验证:检查数据库慢查询和连接池状态
### 6.3 假设3: 上游突发流量(置信度:5%)
- 证据:无入口流量指标异常
- 推理:如果流量突增,CPU应该同步上升,但CPU变化很小
- 排除原因:流量不是主要因素
## 七、推荐排查步骤
1. jstack -F <pid> > thread_dump.txt # 检查线程状态
2. grep -c "BLOCKED\|WAITING" thread_dump.txt # 统计阻塞线程数
3. 检查数据库连接池和慢查询
7.1 实际根因
通过jstack发现,80%的线程处于WAITING状态,都在等待一个Redis分布式锁。进一步排查发现,凌晨上线的代码中引入了一个未设置超时的Redisson.tryLock()调用。在正常业务量下没问题,但高峰期线程争抢锁导致大量线程阻塞。
修复方案:为tryLock()增加超时参数,并在业务逻辑中添加熔断降级。
八、落地框架总结
# ai-ops-framework.yaml
version: v1
components:
perception:
methods:
- rate_of_change # 变化率分析
- trend_detection # 趋势异常
- correlation_break # 相关性破坏
analysis:
depth: 3 # 最多追踪3层因果链
min_evidence: 2 # 每个假设至少2条证据
llm:
temperature: 0.1 # 低温度,高确定性
model: qwen2-72b
action:
auto_remediation: false # 默认不自动修复
notification:
- channel: dingtalk
template: diagnosis
结语
大模型辅助根因分析的核心价值不在于"替代工程师做判断",而在于扩展工程师的感知范围——发现那些人类容易忽视的"弱信号"。
线程数从20涨到180,这个变化率+800%的数据,人眼在几百个指标中很难注意到。但AI可以。它不是比人聪明,只是比人更擅长处理大规模、多维度的数据。
把你从"数据中翻找线索"的体力活中解放出来,让你专注于"判断和决策"——这才是AI辅助根因分析的真正价值。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)