AI-Qoder:掌握Qoder / 智能体编程Agentic Coding / 协同开发者 / 数字员工 / AI同事
一、Qoder简介
1.1、核心定位与理念
| 维度 | 具体内容 |
|---|---|
| 核心理念 | 智能体编程(Agentic Coding) |
| 目标 | 将AI从“辅助工具”升级为“协同开发者”,解决传统AI编程工具上下文不足的痛点 |
| 定位 | 开发者的“AI同事”/“数字员工”,覆盖从需求分析到部署的完整开发流程 |
| 发布时间 | 2025年8月首次发布,2026年5月发布1.0版本(正式升级为智能体自主开发工作台) |
1.2、主要功能与特点
| 功能模块 | 具体描述 | 核心特点 |
|---|---|---|
| 仓库级理解 | 索引整个代码库(支持10万+文件),通过Repo Wiki显性化隐性知识(架构、模块关系等) | 降低新成员上手成本,解决传统AI仅关注当前文件的痛点 |
| 多模式智能体协同 | - Ask Mode:代码解释、技术选型咨询 - Agent Mode:监督下自主编码(重构、Bug修复) - Quest Mode:自然语言描述需求,自主完成任务拆解、编码、测试 |
覆盖日常开发全场景,从“辅助”到“自主执行” |
| 长期记忆与自适应 | 学习开发者编码风格、项目规范,通过.qoder/rules适配团队规则 |
越用越懂用户,减少重复沟通成本 |
| 上下文工程与模型路由 | 支持多模态输入(代码、图片、日志等),智能选择模型(轻量模型补全/顶尖模型架构设计) | 平衡效果与成本,避免“大材小用”或“小材大用” |
1.3、产品形态与适用场景
| 形态 | 说明 | 适用场景 |
|---|---|---|
| Qoder IDE | 基于VS Code的桌面客户端,主开发环境 | 日常编码、智能体协同开发 |
| Qoder CLI | 命令行工具 | 终端集成、自动化脚本 |
| JetBrains插件 | 适配IntelliJ IDEA、PyCharm等 | Java/Python等语言开发者 |
| Qoder移动端 | 远程操作桌面端,监控Agent工作流 | 移动办公、实时任务跟进 |
| QoderWork/QoderWake | 企业级“数字员工” | 承担软件工程师、运营等岗位部分工作 |
| Cloud Agents | 全托管AI Agent运行平台 | 企业快速构建、部署智能体 |
1.4、核心优势与价值
| 优势维度 | 具体表现 | 用户价值 |
|---|---|---|
| 上下文深度 | 仓库级理解+Repo Wiki | 解决复杂项目中AI“断片”问题,提升开发连贯性 |
| 智能体自主性 | Quest Mode自主完成全流程 | 减少开发者重复劳动,聚焦需求定义与架构设计 |
| 团队协同 | 知识沉淀(Repo Wiki)+规则适配(.qoder/rules) | 降低团队沟通成本,统一开发规范 |
| 成本优化 | 模型路由+轻量/顶尖模型按需选择 | 避免资源浪费,平衡效果与成本 |
1.5、总结与定位
| 总结点 | 详细说明 |
|---|---|
| 本质 | AI原生开发平台,通过智能体技术重塑软件开发范式 |
| 核心价值 | 提升个体开发者效率,同时通过知识沉淀与团队协同,帮助企业提升工程化水平 |
| 行业定位 | AI编程领域功能全面、定位清晰的有力竞争者,覆盖从个人到企业的全场景需求 |
二、Qoder三种模式区别
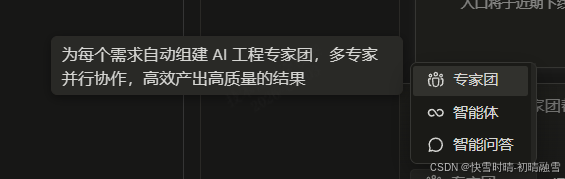
专家团:为每个需求自动组件AI工程专家团,多专家并行协作,高效产出高质量的结果
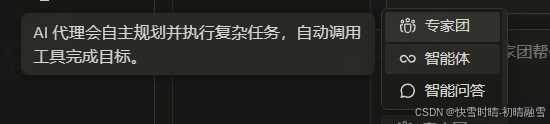
智能体:AI代理会自主规划并执行复杂任务,自动调用工具完成目标
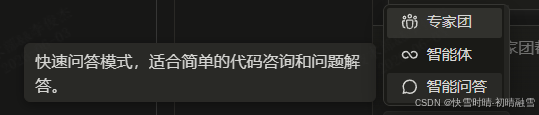
智能问答:快速问答模式,适合简单的代码咨询和问题解答
2.1、三种模式概念总览
| 模式 | 英文名 | 入口位置 | 核心理念 |
|---|---|---|---|
| 智能问答 | Ask Mode | Chat 面板 | “先想后改”——只读理解,不修改代码 |
| 智能体 | Agent Mode | Chat 面板 / Quest 工作区 | “单个智能体自主决策、端到端完成任务” |
| 专家团 | Experts Mode | Quest 工作区 | “多智能体协作,你定义目标,AI 专家团队交付结果” |
2.2. 智能问答(Ask Mode)
概念:Ask 是一种只读问答模式,基于项目上下文回答编程问题、提供方案建议、解释权衡取舍,并可以给出可复制粘贴的代码片段,但不会自主修改代码或工作区文件。
核心特点:
🔒 只读不写:不自动重写工作区代码,与 Agent 模式最大的区别就是不会自主应用更改
📄 上下文理解:基于代码仓库的只读理解,解释代码逻辑、提供建议
✂️可复制片段:可以建议代码片段供你手动粘贴
💡 仍可优化代码:虽然不自动修改,但仍可以评论和优化代码、建议修复、帮助排查构建错误
适用场景
| 场景 | 示例 |
|---|---|
| 设计评审 | 讨论 API 设计方案的利弊 |
| 技术学习 | 了解某个框架/库的用法 |
| 小示例获取 | 获取可运行的代码片段 |
| 重构规划 | 规划代码重构方案但不急于执行 |
| 代码解释 | 高亮代码后让 AI 解释逻辑 |
| 错误排查 | 提供错误信息让 AI 分析原因 |
使用提示
明确目标:说明要解决的问题和期望的回答形式
说明约束:语言/运行时版本、性能/安全边界
附加上下文:使用 @ 引用文件或发送选中代码
分步进行:逐步验证每一步
2.3、智能体(Agent Mode)
概念:Agent Mode 是一种自主编码模式,具备自主决策、环境感知和工具使用能力。它能利用项目搜索、规划、文件编辑和终端操作等工具,端到端地完成编码任务。
核心特点:
🧠 自主决策:无需你持续确认,Agent 可自主应用代码变更
📁 项目级修改:自主拆解任务,修改多个代码文件
📋 计划制定:自动为复杂任务生成逐步执行计划供你审核
🔍 环境感知:自动检测项目框架、技术栈、所需代码文件和错误信息
🛠️ 工具利用:自主使用内置工具(文件读写、代码查询、目录遍历、语义符号检索等),也支持 MCP 工具
命令执行:自主决定并执行终端命令
🔄 多轮迭代:通过多轮对话优化代码,支持 Revert 回滚
适用场景:
| 场景 | 示例 |
|---|---|
| 功能开发与重构 | 开发新功能、修复 Bug、重构代码 |
| 快速原型验证 | 从零构建 Demo 原型,快速验证产品想法 |
| 自动化工具构建 | 编写批处理脚本、数据清洗工具、CLI 脚本 |
| 快速迭代优化 | 先让 Agent 交付 MVP 版本,再通过自然语言迭代优化 |
子场景选择(Quest 中):
Spec-driven(规格驱动):适用于需要明确技术方案的复杂任务,先生成结构化规格文档再编码
Prototype exploration(原型探索):跳过规格,直接编码
Tool creation(工具创建):自动评估环境并选择合适的技术栈
使用提示
清晰描述任务目标、偏好技术栈和验收标准
使用 @ 引用相关文件
先让 Agent 完成 MVP,再逐步迭代优化
可配置命令自动执行白名单,减少手动确认
2.4、专家团(Experts Mode)
概念:Experts Mode 是 Qoder 的多智能体协作功能,专为复杂开发任务设计。你只需陈述需求,系统自动拆解任务、组建专家团队,并行执行设计、实现、测试和质量保障,交付生产级工程结果。
核心特点
👥 多智能体协作:由 Lead Agent(主管智能体)统一协调多个专家并行工作
📋 自主任务拆解:Lead Agent 自动理解目标、创建计划、动态调度专家
⚡ 并行执行:专家之间互不阻塞,并行执行任务
🔄 实时协调:Lead Agent 实时对齐,确保所有产出整合为一体
📊 可视化管理:Expert Team Canvas(专家团画布)实时可视化每个专家的任务进度
🚀 自我进化:内置双进化机制——专家技能(个体进化)+ 团队技能(团队进化)
专家角色分工
| 角色 | 职责 |
|---|---|
| Lead Agent(主管) | 理解需求、拆解任务、协调调度、保障质量 |
| Researcher(研究员) | 研究分析、代码定位、依赖映射、环境检查 |
| Full-Stack Engineer(全栈工程师) | 实现和修改前后端代码、跨栈编码任务 |
| QA(测试工程师) | 运行测试和构建、收集验证证据 |
| Code Reviewer(代码审查员) | 审查代码、识别潜在风险、提供改进建议 |
| UI Operator(UI 操作员) | 浏览器和 UI 端到端验证、视觉 Bug 复现 |
适用场景
| 场景 | 示例 | 专家团如何帮助 |
|---|---|---|
| 全栈开发 | 开发用户管理模块(注册、登录、信息管理) | Lead Agent 生成计划,全栈工程师实现前后端,QA 并行测试,代码审查员保障质量 |
| 复杂问题诊断与修复 | 涉及多个微服务的生产环境性能瓶颈 | Lead Agent 组建研究员和全栈工程师,分析日志、追踪调用链、定位并修复问题 |
| 技术方案调研 | 评估 GraphQL 替代 RESTful API | 研究员收集资料,全栈工程师评估技术栈影响,交付可操作的研究报告 |
自定义专家
可为内置专家添加 Skills 和 MCP 扩展能力
可选择每个内置专家使用的模型
可创建自定义子智能体(Sub-agent)扩展专家团队
2.5、三种模式核心差异对比
2.5.1、能力维度对比
| 维度 | 智能问答(Ask) | 智能体(Agent) | 专家团(Experts) |
|---|---|---|---|
| 修改代码 | ❌ 不修改 | ✅ 自主修改 | ✅ 自主修改 |
| 执行终端命令 | ❌ | ✅ | ✅ |
| 使用工具 | ❌ 仅读取上下文 | ✅ 内置工具 + MCP | ✅ 内置工具 + MCP |
| 任务拆解 | ❌ | ✅ 自动规划 | ✅ 自动规划 + 分派给不同专家 |
| 并行执行 | ❌ | ❌ 单智能体 | ✅ 多专家并行 |
| 环境感知 | 部分 | ✅ 自动检测 | ✅ 自动检测 |
| 质量保障 | ❌ | 需手动审查 | ✅ 内置 Code Reviewer + QA |
| 终端自动执行 | N/A | 需确认(可配置白名单) | 自动执行(危险命令进沙箱) |
| 代码回滚(Revert) | N/A | ✅ 支持 | ❌ 暂不支持 |
| 自我进化 | ❌ | ❌ | ✅ 专家技能 + 团队技能双进化 |
2.5.2、交互方式对比
| 维度 | 智能问答(Ask) | 智能体(Agent) | 专家团(Experts) |
|---|---|---|---|
| 交互风格 | 你问→AI答 | 你说→AI做→你审 | 你定目标→AI团队交付→你审结果 |
| 人工干预 | 每步都由你驱动 | 可中途调整,支持回滚 | 可随时介入纠正方向、添加需求 |
| 输出形式 | 文本回答 + 代码片段 | 代码变更 + 终端输出 | 代码变更 + 测试报告 + 审查建议 |
2.5.3、复杂度与效率对比
| 维度 | 智能问答(Ask) | 智能体(Agent) | 专家团(Experts) |
|---|---|---|---|
| 适合任务复杂度 | 低 ~ 中 | 中 | 中 ~ 高 |
| 执行速度 | ⚡ 最快 | ⚡ 快 | 🐌 较慢(但质量更高) |
| 代码质量 | 依赖人工粘贴 | 中等 | 🏆 高(内部测试约提升 67% 质量) |
| Credits 消耗 | 💰 最低 | 💰💰 中等 | 💰💰💰 最高 |
2.5.4、入口位置对比
| 模式 | 入口 |
|---|---|
| 智能问答 | Chat 面板(快捷键 Ctrl+L 打开),下拉选择 Ask |
| 智能体 | Chat 面板(下拉选择 Agent)或 Quest 工作区(选择 Agent 模式) |
| 专家团 | 仅 Quest 工作区(右上角 Open Quest 进入,选择 Experts 模式) |
2.6、如何选择合适的模式
2.6.1、任务分类对应模式
只是问问题、了解代码、获取建议(不需要修改代码)→ 智能问答(Ask)
需要自动修改代码,任务相对明确(单文件修改、小功能开发、Bug修复)→ 智能体(Agent)
复杂全栈任务、需要多人协作质量保障(多文件跨栈开发、复杂调试、技术调研)→ 专家团(Experts)
2.6.2、简单决策口诀
只想问 → Ask:问问题、看方案、学知识
想让它做 → Agent:写代码、改代码、跑命令
想让它团队做 → Experts:全栈开发、复杂修复、高质量交付
2.6.3、重要提示
在 Quest 中选择模式后,无法在任务进行中切换模式,请在启动任务前确认好场景选择。
三、切换语言为简体中文
四、提问时可上传/伴随图片
五、Qoder 的模型层级选择器
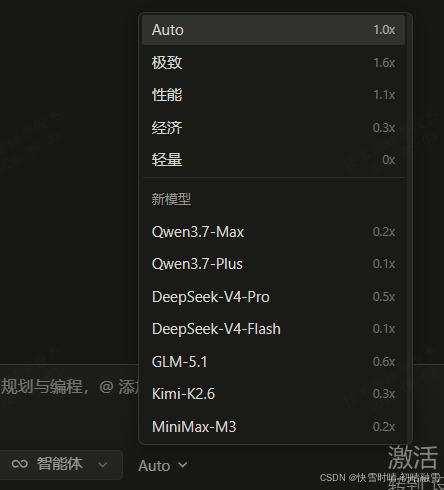
| 层级 | 说明 | 适用场景 | 积分消耗 |
|---|---|---|---|
| Auto | 智能路由,自动选择最合适的模型 | 日常开发,推荐默认 | ~1.0× |
| 极致 | 最强推理能力,深度思考 | 复杂架构设计、疑难bug排查 | ~1.6× |
| 性能 | 高级推理,高质量输出 | 核心功能实现、代码重构 | ~1.1× |
| 经济 | 标准推理,高性价比 | 基础代码生成、单元测试、日常问答 | ~0.3× |
| 轻量 | 基本推理,完全免费 | 快速验证、简单问答 | 免费 |
日常开发 → 选 Auto,省心省力
难题攻坚 → 切换 极致,获得最强推理
批量简单任务 → 用 经济,节省时间
积分不足/快速验证 → 用 轻量,完全免费
六、指定模型
| 模型名称 | 提供商 | 积分倍率 | 特点与适用场景 |
|---|---|---|---|
| Qwen3.7-Max | 阿里云(通义千问) | 0.5× | 旗舰模型,Agent场景专精,长链推理、跨文件理解强,Code Arena 全球第二 |
| Qwen3.6-Plus | 阿里云(通义千问) | 0.2× | 推理与效率全面飞跃,性价比高 |
| DeepSeek-V4-Pro | DeepSeek | 0.5× | 擅长复杂推理、代码生成和工程任务 |
| DeepSeek-V4-Flash | DeepSeek | 0.1× | 快速推理、低成本、能力均衡 |
| GLM-5.1 | 智谱 AI | 0.6× | 擅长复杂系统工程和长期任务 |
| Kimi-K2.6 | Moonshot(月之暗面) | 0.3× | 擅长多模态理解和复杂任务处理 |
| MiniMax-M2.7 | MiniMax | 0.2× | 速度、性能和成本效率兼顾的 Agent 模型 |
七、自定义模型(BYOK,自带 API Key,不消耗积分)
| 提供商 | API Key 获取地址 |
|---|---|
| 阿里云百炼 | bailian.console.aliyun.com |
| DeepSeek | platform.deepseek.com |
| 智谱 AI | open.bigmodel.cn |
| Kimi(Moonshot) | platform.moonshot.cn |
| MiniMax | platform.minimaxi.com |
| 小米 MIMO | platform.xiaomimimo.com |
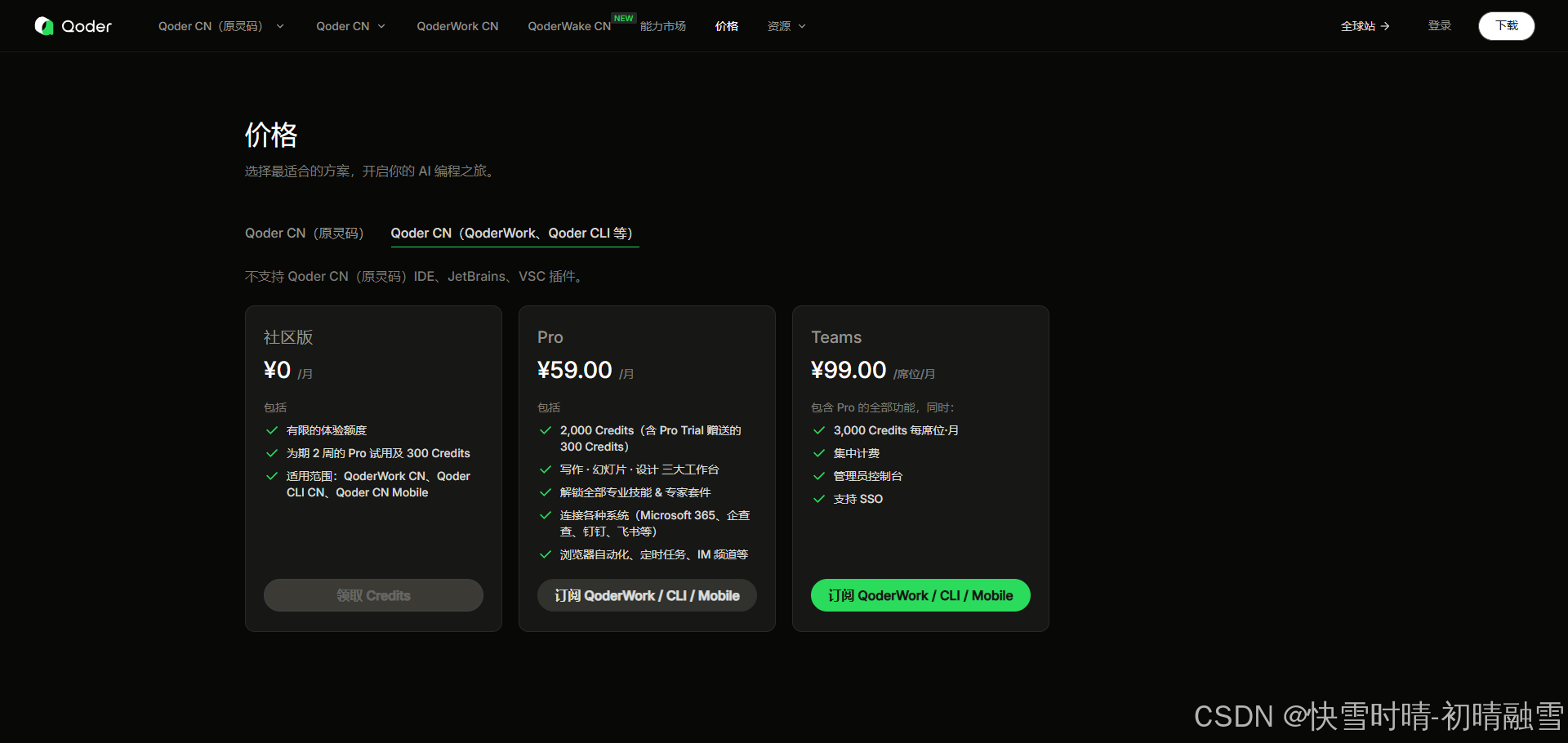
八、Credits 是什么?
Credits是Qoder CN系列产品调用AI模型的计量单位,按任务复杂度和模型扣费,优先消耗最先到期资源,支持多渠道查看用量与日志记录。-Qoder CN 系列(Lingma)-阿里云帮助中心
8.1、Credits 是什么?
Credits 是 Qoder 的计费单位,类似于“积分”或“代币”,用于衡量你使用 AI 模型时的资源消耗。
| 项目 | 数值 |
|---|---|
| 套餐总额度 | 2850 Credits |
| 已使用 | 296 Credits(11%) |
| 剩余 | 2554 Credits |
8.2、Credits 消耗规则
不同模型/模式消耗的 Credits 不同,以倍率计算:
| 模型/层级 | 消耗倍率 | 示例 |
|---|---|---|
| 轻量(Lite) | 🆓 免费 | 0 Credits |
| 经济(Efficient) | ~0.3x | 约 3 Credits |
| Auto | ~1.0x(基准) | 约 10 Credits |
| 性能(Performance) | ~1.1x | 约 11 Credits |
| 极致(Ultimate) | ~1.6x | 约 16 Credits |
倍率越高,单次对话消耗的 Credits 越多;实际消耗还会受任务复杂度、对话长度、上下文窗口大小等因素影响。
8.3、Credits 关键要点
每月重置:套餐内 Credits 按计费周期(通常为月)重置
用完怎么办:Credits 耗尽后,只能使用免费的轻量 (Lite) 模式
共享资源包:截图中的“共享资源包”是额外的 Credits 充值包,可跨周期使用
节省技巧:简单任务用“经济”或“轻量”模式,复杂任务再用“性能”或“极致”,合理分配 Credits
8.4、简单理解
Credits = Qoder 的“话费”,用 AI 模型就扣,不同模型扣费不同,月底清零。
九、Token 是什么
Token 是 AI 大语言模型处理文本的基本单位。模型不直接理解“字”或“词”,而是将文本切分为 Token 进行处理。
Token 估算规则
1 个英文单词 ≈ 1~2 个 Token
1 个中文字 ≈ 1~3 个 Token
一次 AI 对话请求中的 Token 分类
| Token 类型 | 含义 |
|---|---|
| 输入 Token(Input) | 用户发送给模型的提示词、上下文、代码等 |
| 缓存 Token(Cached) | 输入中命中缓存的部分(如对话历史中已处理过的上下文),价格远低于普通输入 |
| 输出 Token(Output) | 模型生成返回的回复、代码等 |
十、Credits
Credits 是什么
Credits 是 Qoder 的资源计量单位,用于衡量 AI 执行任务时消耗的计算资源配额。
关键要点:
计费逻辑:Credits ≠ 请求次数,基于实际 Token 消耗换算,而非简单按提问次数扣减。
消耗场景:
Editor:Inline Chat、Ask 模式、Agent 模式
Quest:Agent 模式、Experts 模式
知识引擎:RepoWiki、知识卡片
失败处理:模型调用失败时不扣减 Credits,仅在调用成功时计费。
版本差异:Qoder 国际版与 Qoder CN(原灵码)的 Credits 不等价、不可互通。
十一、Credits 和 token 的关系
Token是基础:模型处理的文本量(如输入/输出长度、任务复杂度)直接决定计算资源消耗。
Credits是折算:不同模型/层级的Token处理效率不同,通过“消耗倍率”将Token消耗转化为用户可理解的计费单位。
动态影响:实际Credits消耗还受任务复杂度(如多文件开发需处理更多Token)、对话长度(上下文窗口越大,Token越多)等因素影响。
十二、skills
十三、repowiki 生成项目文档
十四、打开Quest / 探索 模式
十五、在指定位置打开对话框
CTRL + I 在指定位置打开对话框

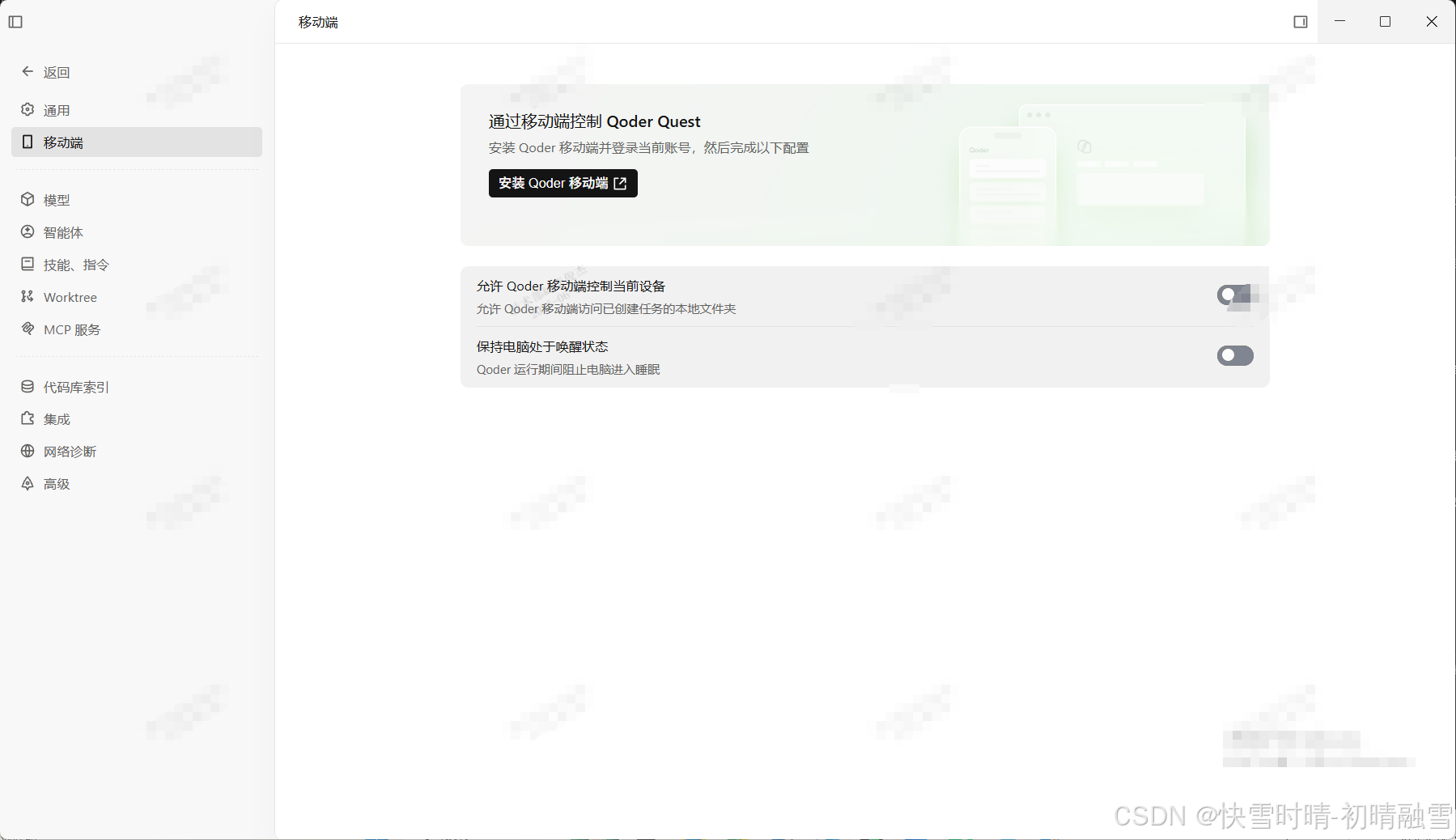
十六、移动端控制
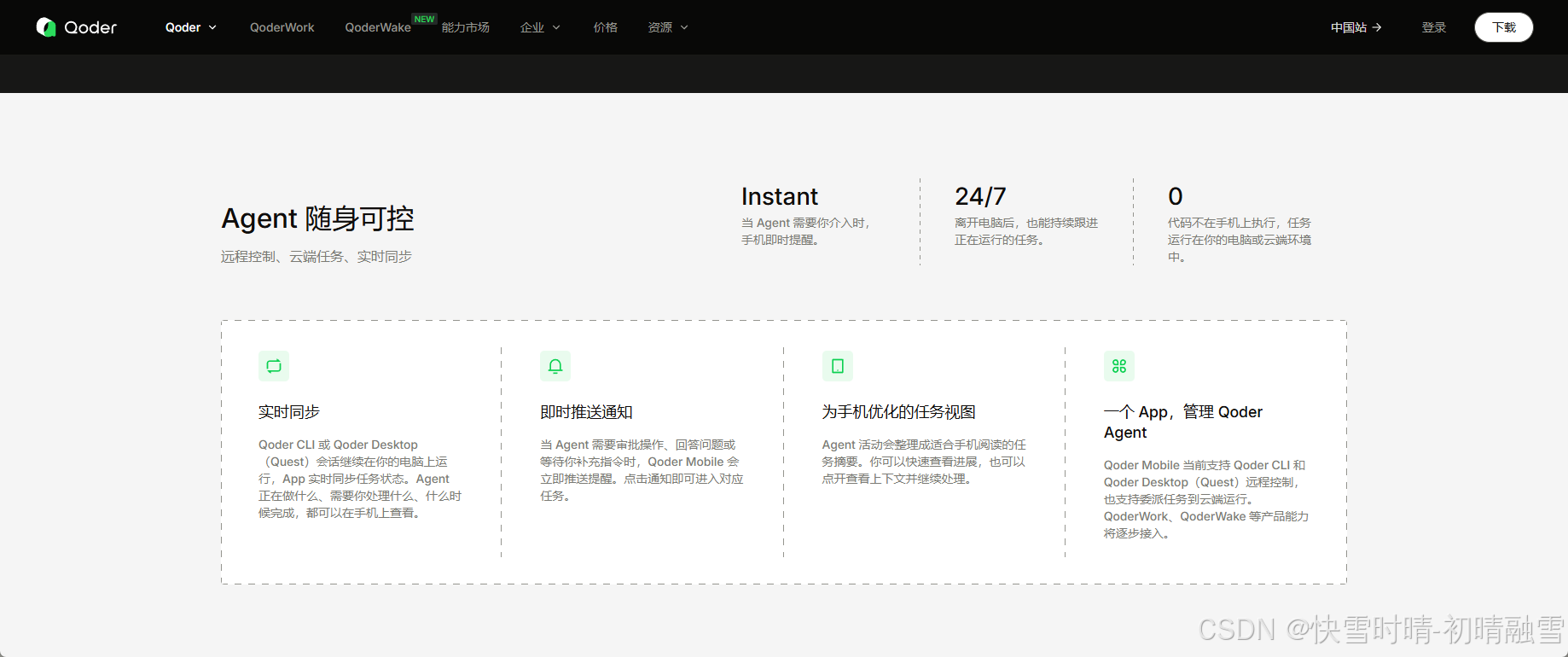
十七、Quest Mode 委托式开发(AI 辅助编程 X , AI 替你编程 V)
你用自然语言说"要做什么",AI 智能体自主完成"怎么做"——从需求分析 → 方案设计 → 编码 → 测试 → 交付,全链路端到端执行,你只在关键节点做决策。
核心理念就一句话:Define the goal. Review the result.(你定义目标,AI 交付结果。)
| Ask Mode(问答模式) | Agent Mode(代理模式) | Quest Mode(委托模式) | |
|---|---|---|---|
| 定位 | 即时问答,代码建议 | 结对编程,你盯着它写 | 全流程委托,你不用盯 |
| 你的角色 | 提问者 | 监工 | 产品经理 / 架构师 |
| AI 的角色 | 顾问 | 助手 | 全栈工程师 |
| 适合场景 | 语法问题、技术选型 | 快速重构、修 Bug | 复杂功能开发、深层 Bug 修复、代码重构 |
| 你需要盯屏吗? | 需要 | 需要 | 不需要,异步执行 |
第1步:你输入自然语言需求
↓
第2步:AI 主动澄清(多选题形式问你细节)
↓
第3步:AI 生成 Spec 设计文档
(需求描述 + 设计方案 + 任务拆解 + 验收标准)
↓
第4步:你确认/修改 Spec ← 人类做决策的关键环节
↓
第5步:AI 自主执行,全程可视化监控
(你可以去开会,回来代码已写好)
↓
第6步:AI 生成任务报告,你审查结果
Local → Accept/Reject
Remote → Create PR
人类只在两个节点介入:确认意图(Spec)、审查结果。中间所有脏活累活,全部交给 AI。
Quest Mode 的本质是:把开发者从"代码执行者"升级为"需求定义者 + 质量验收官"。你不再一行一行告诉 AI 怎么写,你只需要说清楚要什么,AI 负责把事情做完。这不是 AI 辅助编程,这是 AI 替你编程。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 14
14 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)