【3D 场景生成】TIMI: Training-Free Image-to-3D Multi-Instance Generation with Spatial Fidelity
TIMI:面向空间保真度的免训练图像转多实例三维生成
原文链接:https://arxiv.org/pdf/2603.01371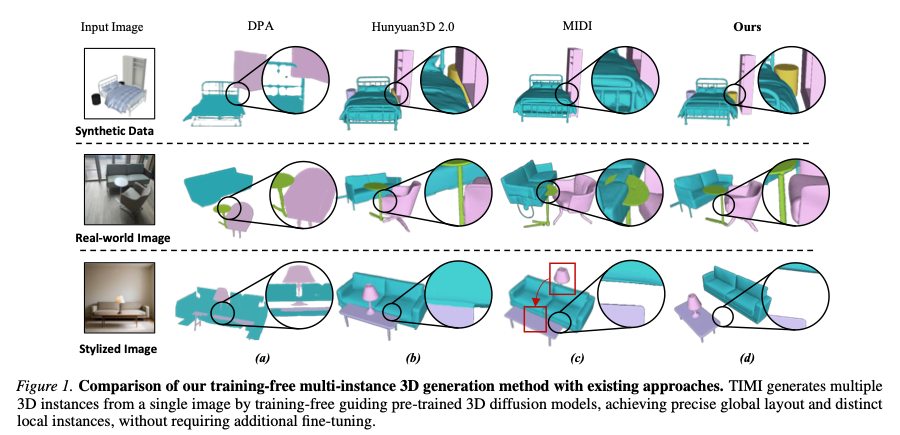
图1 本文所提免训练多实例三维生成方法与现有方法对比。TIMI依托预训练三维扩散模型,以无微调的引导方式从单张图像生成多个三维实例,在实现精准全局布局的同时保证局部实例边界清晰。
摘要
在图像转三维多实例生成任务中,精准的空间保真度是落地各类实际下游应用的关键。现有相关研究大多通过在多实例数据集上微调预训练图像转三维(I23D)模型来解决该问题,但这类方案不仅会带来高昂的训练成本,还难以保障生成结果的空间保真效果。本文观察发现:预训练图像转三维模型本身已经蕴含有效的空间先验信息,只是受实例粘连问题制约,该先验未能得到充分利用。受此启发,本文提出TIMI——一款面向图像转多实例三维生成的全新免训练框架,可实现高空间保真度生成。具体而言:首先设计实例感知分离引导(ISG)模块,在扩散早期去噪阶段实现实例解耦;其次为稳定ISG引入的梯度引导约束,提出空间稳态几何自适应更新(SGU)模块,在保留实例几何特征的同时维持实例间相对空间位置关系。大量实验表明:相较于现有多实例生成算法,本文方法无需额外训练、推理速度更快,在全局布局与局部实例区分度两项指标上均取得更优效果。
1 引言
图像转三维多实例(I2MI)生成旨在从单张输入图像合成包含多个物体实例的三维场景,是工业设计、产品研发以及创意产业的技术基础(Huang等人,2025;Nie等人,2020;Zhou等人,2024)。与单实例三维生成领域的快速发展形成鲜明对比(Liu等人,2024;Voleti等人,2024;Shuang等人,2025;Liang等人,2024;Wang等人,2023),图像转三维多实例生成受制于严苛的空间保真约束(既要全局空间布局准确,又要各个局部实例边界相互独立),相关研究仍存在大量难点、探索尚不充分。
扩散模型领域的突破性进展(Peebles & Xie,2023)极大推动了图像转三维(I23D)生成技术发展,预训练模型具备强大三维先验,能够依托单张图像生成高质量几何模型。基于上述进展,早期多实例生成方法普遍采用组合式生成思路(Chen等人,2024;Zhou等人,2024;Tang等人,2025):利用预训练图像转三维模型逐个生成独立实例,再通过额外优化或布局微调,将多个实例拼装至同一个三维场景。该多阶段方案逻辑简洁,但极易产生误差累积,最终出现全局布局错乱、物体空间偏移、实例穿插碰撞等问题,如图1(a)所示。为克服上述缺陷,以MIDI(Huang等人,2025)为代表的后续算法选择在预训练I23D模型基础上引入定制注意力机制并微调,在三维生成过程中直接建模实例间空间关联。
尽管微调类方案效果有所提升,但训练过程开销巨大,且依旧无法完全保证空间保真度,常出现布局错位、物体相互融合粘连的问题,见图1©。值得注意的是,我们发现预训练I23D模型本身已携带可用的空间先验:如图1(b)中混元3D 2.0(Team,2025)可以大致维持实例间相对位置,仅存在实例粘连缺陷。据此引出核心研究问题:能否在不微调模型的前提下,挖掘并解耦预训练I23D模型内置的空间先验,实现高保真多实例三维生成?
基于上述思考,本文提出免训练多实例三维生成框架TIMI。首先,实例感知分离引导(ISG)模块通过实例感知注意力锚定操作,将浅层交叉注意力与图像实例区域对齐,并借助实例一致性分离损失实现实例解耦;其次,空间稳态几何自适应更新(SGU)模块对分离梯度做空间平滑正则,搭配几何自适应缩放控制梯度更新幅度,在去噪过程中兼顾几何结构完整性与场景整体布局。在多类数据集上的海量实验证明:相较现有I2MI算法,TIMI无需额外训练即可生成全局布局精准、局部实例边界清晰的三维场景(图1(d)),同时推理效率更高(表1)。本文主要贡献分为三点:
- 提出TIMI免训练框架,实现高空间保真度的图像转三维多实例生成;
- 设计ISG与SGU两大模块,协同完成局部实例分离与全局布局保全;
- 多组实验验证TIMI优越性:在零额外训练的条件下,全局布局对齐度与实例区分度达到当前最优水准。
2 相关工作
2.1 单实例三维生成
单实例三维生成的技术演进呈现出从优化流水线向原生三维生成过渡的清晰脉络。早期方法大多依靠得分蒸馏采样(SDS)(Poole等人,2023;Lin等人,2023;Chen等人,2023)将二维先验知识蒸馏至三维表征空间,但普遍存在优化缓慢、几何歧义严重的缺陷。为提升生成效率与结果一致性,后续研究陆续探索多视图扩散(Liu等人,2023;Shi等人,2023;Yan等人,2024)与前馈重建架构(Tang等人,2024a;Xu等人,2024;Zou等人,2024)。近期,基于扩散Transformer(DiT)(Peebles & Xie,2023)的原生三维生成方案成为主流,3DTopia-XL(Chen等人,2025)、Trellis(Xiang等人,2025)、混元3D(Team,2025)等模型在几何与纹理生成保真度上表现优异。但上述算法仅聚焦孤立单体物体,若不经过额外微调,很难适配多实例生成场景。
2.2 多实例三维生成
多实例三维生成技术由传统三维重建(Chu等人,2023;Liu等人,2022;Paschalidou等人,2021)、检索式生成(Gao等人,2024;Gümeli等人,2022;Kuo等人,2021)逐步发展为现阶段的生成式框架。现有主流方案可划分为组合生成法与基于训练的生成法两类。
组合式方法(Tang等人,2024b;Zhou等人,2024;Rahamim等人,2024)遵循“拆分-生成-拼接”范式:逐个生成独立实例后,依托深度图、布局信息、标准对齐等辅助线索将物体组装为完整场景(Ardelean等人,2025;Tang等人,2025;Han等人,2025;Yao等人,2025)。该方案灵活度高,但多阶段运算成本高昂,且因缺少全局场景建模容易造成误差累积。与之相对,以微调为核心的训练类方法(Huang等人,2025)采用端到端思路,通过在多实例注意力约束下微调I23D模型,显式学习实例间空间交互关系。尽管效果有所提升,但模型微调带来巨大算力开销,还可能破坏模型原本学习到的空间先验。针对以上不足,本文依托免训练实例感知引导策略,充分挖掘预训练I23D模型内置先验,实现高空间保真的多实例三维生成。
3 预备知识:三维物体生成模型
本文工作基于大规模图像转三维生成框架(Team,2025;Xiang等人,2025)开展。此类模型通常由三大核心组件构成:
- 三维变分自编码器(3D VAE):包含编码器 ε \varepsilon ε 和解码器 D D D,能够将三维几何表征压缩至低维隐空间,得到隐变量 z 0 ∈ R L × d z_0 \in \mathbb{R}^{L\times d} z0∈RL×d,其中 L L L 代表序列长度, d d d 为特征维度。
- 条件编码器:依托CLIP(Radford等人,2021)、DINOv2(Caron等人,2021)等预训练视觉模型,从参考图像 I I I中提取语义特征序列 c ∈ R M × d c\in\mathbb{R}^{M\times d} c∈RM×d。
- 去噪Transformer ϵ θ \epsilon_\theta ϵθ:经过训练,可从高斯噪声 z T ∼ N ( 0 , I ) z_T \sim N(0,I) zT∼N(0,I) 中逐步还原出原始隐变量 z 0 z_0 z0。
统一联合注意力机制
现代DiT架构借助联合注意力机制实现多模态信息交互。设 z t z_t zt 为三维隐编码Token, c c c 为图像条件Token,将二者拼接得到联合序列 U = [ c ; z t ] ∈ R ( M + L ) × d U=[c;z_t]\in\mathbb{R}^{(M+L)\times d} U=[c;zt]∈R(M+L)×d,全局自注意力矩阵 A g l o b a l A_{global} Aglobal 用于建模模态交互,可拆分为分块子矩阵:
A g l o b a l = S o f t m a x ( Q U K U ⊤ d ) = [ A c c A c z A z c A z z ] (1) A_{global}=Softmax\left(\frac{Q_{U}K_{U}^{\top}}{\sqrt{d}}\right) =\left[ \begin{array} {ll}{A_{cc}}&{A_{cz}}\\ {A_{zc}}&{A_{zz}}\end{array} \right] \tag{1} Aglobal=Softmax(dQUKU⊤)=[AccAzcAczAzz](1)
式中,左下角子矩阵 A z c ∈ R L × M A_{zc}\in\mathbb{R}^{L\times M} Azc∈RL×M 为三维到图像交叉注意力,控制三维几何Token从二维参考图像中查询语义信息,也是本文方法的优化核心。
4 方法
本节详细介绍免训练图像转三维多实例生成框架TIMI,整体由**实例感知分离引导(ISG,4.1节)与空间稳态几何自适应更新(SGU,4.2节)**两个模块组成,整体架构如图2所示。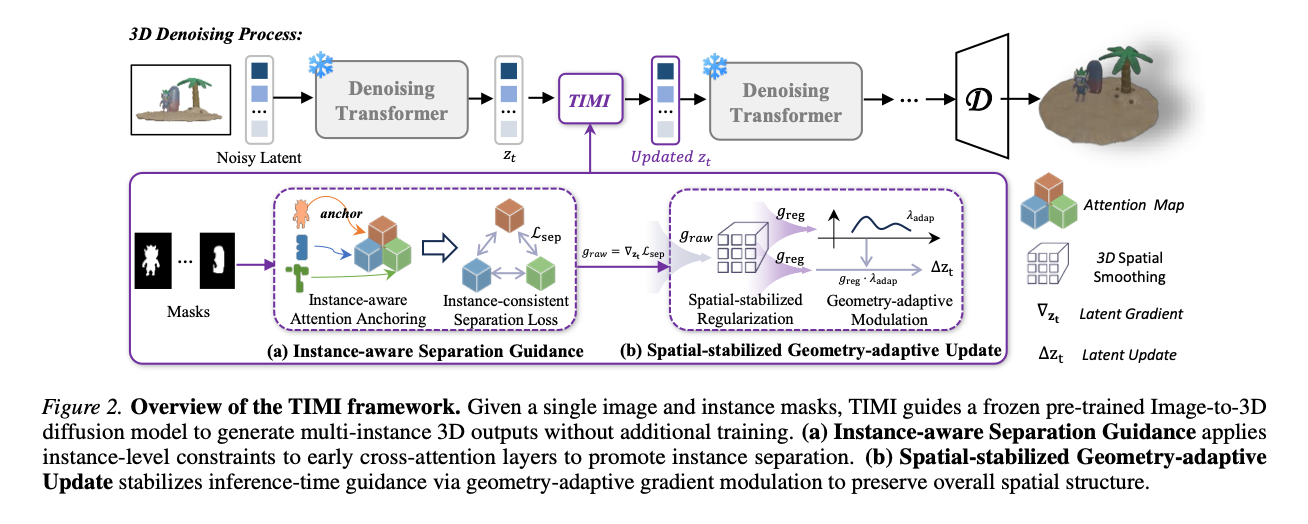
图2 TIMI框架整体结构图。输入单张图像与实例掩码后,TIMI以冻结预训练图像转三维扩散模型的方式实现免训练多实例三维生成。(a)实例感知分离引导在浅层交叉注意力层施加实例约束,促进实例相互分离;(b)空间稳态几何自适应更新通过几何自适应梯度调制稳定推理阶段引导,保留整体空间结构。
4.1 实例感知分离引导
为缓解实例粘连问题,本文提出实例感知分离引导模块,在去噪前期阶段引导模型完成实例级解耦。
实例感知注意力锚定
为在图像转三维去噪过程中显式确定实例层级的空间分配关系,本模块作用于浅层交叉注意力图(该阶段初步建立二维-三维位置对应关系),重点处理三维到图像交叉注意力矩阵 A z c A_{zc} Azc。该矩阵编码三维隐编码Token与二维图像特征间的密集空间对齐关系,但原始注意力不区分实例,在多实例画面(图像存在物体空间重叠)中容易出现匹配模糊。
为消除匹配歧义,引入实例感知注意力锚定操作,将注意力分布映射至离散语义实例。设从参考图像中提取一组实例掩码集合 M = { M k } k = 1 K M=\{M_k\}_{k=1}^K M={Mk}k=1K,通过计算实例概率图 P ∈ R L × K P\in\mathbb{R}^{L\times K} P∈RL×K,把 A z c A_{zc} Azc映射到实例表征空间:
P ⋅ , k = A z c ⋅ M k ⊤ (2) P_{\cdot,k}=A_{zc}\cdot M_{k}^{\top} \tag{2} P⋅,k=Azc⋅Mk⊤(2)
其中 P v , k P_{v,k} Pv,k代表第 v v v个三维隐编码Token与第 k k k个实例的关联程度。该映射得到基于实例对齐的三维Token表征,作为后续实例层级分离优化的基础。
实例一致性分离损失
依托实例感知表征 P P P,优化目标为在三维隐空间中引导去噪过程实现稳定的实例分离。若简单约束单个三维Token仅关联单一实例,容易出现注意力坍缩在实例中心点附近的退化问题,破坏物体局部结构完整性。
针对该缺陷,本文引入融合结构感知空间权重的实例一致性分离损失。首先基于掩码注意力分布求解空间权重矩阵 W W W,用以表征单个Token在对应实例中的相对空间支撑范围:
W v , k = A z c , v ⋅ M k ∑ v ′ ( A z c , v ′ ⋅ M k ) + ϵ (3) W_{v, k}=\frac{A_{z c, v} \cdot M_{k}}{\sum_{v'}\left(A_{z c, v'} \cdot M_{k}\right)+\epsilon} \tag{3} Wv,k=∑v′(Azc,v′⋅Mk)+ϵAzc,v⋅Mk(3)
权重 W v , k W_{v,k} Wv,k用来突出和实例结构强相关的Token,使优化聚焦在有效空间区域。结合实例感知权重,构造带空间加权的负对数似然分离损失:
L s e p = − ∑ k = 1 K ∑ v = 1 L W v , k l o g ( P v , k + ϵ ) (4) \mathcal{L}_{sep }=-\sum_{k=1}^{K} \sum_{v=1}^{L} W_{v, k} log \left(P_{v, k}+\epsilon\right) \tag{4} Lsep=−k=1∑Kv=1∑LWv,klog(Pv,k+ϵ)(4)
该损失既推动不同实例之间相互分离,又保证单个实例内部特征一致性,在去噪早期实现平稳的实例解耦。
依托实例掩码,将 2D-3D 交叉注意力从像素匹配转为实例归属概率,通过加权分离损失在推理阶段引导注意力重分配,让每个 3D 隐 Token 只绑定所属物体的图像特征,从注意力源头解决多实例粘连,全程零模型微调。
Q:为什么可以在推理阶段运用损失?
A:推理阶段不用损失训模型,而是用 L s e p \mathcal{L}_{sep} Lsep衡量物体粘连程度,借助损失对隐变量 z t z_t zt的梯度,在扩散去噪早期迭代优化3D隐编码,间接修正交叉注意力 A z c A_{zc} Azc的匹配关系,实现多实例解耦。
4.2 空间稳态几何自适应更新
为在实例感知引导生效的同时保证空间结构连贯,本文设计空间稳态几何自适应更新模块。
空间稳态正则化(SR)
未经处理的分离损失梯度 ∇ z L s e p \nabla_{z}\mathcal{L}_{sep} ∇zLsep处于高维隐空间内,分布稀疏且高频分量占比高,直接使用该梯度更新会破坏空间连续性,造成布局紊乱、几何体碎裂。为此对分离梯度施加三维高斯平滑实现空间稳态正则:
g r e g = K σ ∗ ∇ z L s e p (5) g_{reg }=\mathcal{K}_{\sigma} * \nabla_{z} \mathcal{L}_{sep } \tag{5} greg=Kσ∗∇zLsep(5)
式中 z ∈ R C × D × H × W z\in\mathbb{R}^{C\times D\times H\times W} z∈RC×D×H×W代表三维隐特征(特征通道、深度、高度、宽度), ∗ * ∗为三维卷积算子, K σ \mathcal{K}_{\sigma} Kσ是标准差为 σ \sigma σ的高斯核。该操作抑制梯度高频扰动,保证梯度在连续隐特征区域平滑传播,优化过程中维持局部几何连续性。
几何自适应调制(GM)
不同实例在隐空间中的几何敏感度差异较大,统一的更新缩放系数会导致薄型结构形变过度、大型实例优化不足。本文基于峰值归一化设计几何自适应梯度调制策略。在第 t t t步去噪时,先求解正则化梯度的最大幅值 μ m a x ( t ) = m a x ∣ g r e g ( t ) ∣ \mu_{max}^{(t)}=max |g_{reg}^{(t)}| μmax(t)=max∣greg(t)∣,结合当前隐特征分布统计量计算自适应缩放系数 λ a d a p \lambda_{adap} λadap:
λ a d a p = α ⋅ σ z t μ m a x ( t ) + ϵ (6) \lambda_{adap }=\frac{\alpha \cdot \sigma_{z_{t}}}{\mu_{max }^{(t)}+\epsilon } \tag{6} λadap=μmax(t)+ϵα⋅σzt(6)
σ z t \sigma_{z_t} σzt为当前隐特征 z t z_t zt的标准差(小物体标准差小), ϵ = 1 e − 6 \epsilon=1\mathrm{e}{-6} ϵ=1e−6用于防止除零, α \alpha α控制最大更新幅度相对于隐特征尺度的比例。
最终隐变量更新量写作 Δ z t = λ a d a p ⋅ g r e g ( t ) \Delta z_{t}=\lambda_{adap }\cdot g_{reg }^{(t)} Δzt=λadap⋅greg(t)。该约束控制梯度峰值更新幅度,均衡不同几何形态物体的优化力度,避免高梯度区域几何体坍缩、其余区域分离力度不足。
为进一步平滑时序优化轨迹、减少震荡,引入动量式更新规则:
{ m t = β m t − 1 + ( 1 − β ) Δ z t , z t ← z t − m t , \begin{cases} m_{t}=\beta m_{t-1}+(1-\beta) \Delta z_{t}, \\ z_{t} \leftarrow z_{t}-m_{t}, \end{cases} {mt=βmt−1+(1−β)Δzt,zt←zt−mt,
动量系数 β \beta β固定为 0.9 0.9 0.9。
综上,空间稳态几何自适应更新将原始分离梯度转化为可控、适配几何体形态的隐变量更新量,在去噪全程稳定实现局部实例分离,同时保全全局场景布局。
1.空间稳态几何自适应更新(SGU)的设计动机是:ISG经由实例分离损失求出的原始梯度存在单点尖峰突出、空间分布离散突兀、固定更新尺度无法适配大小几何体的弊端,直接使用该梯度更新隐变量会出现细小结构断裂、大件物体分离力度不足、全局布局错乱等问题;
2.该模块依次通过三层处理优化梯度:先借助三维高斯平滑的空间稳态正则(SR)抹平梯度局部突变毛刺,让梯度在三维空间连续平滑分布,规避单点大幅改动造成的几何体破损,再基于当前隐特征全局标准差与梯度最大值求解自适应缩放系数(GM),依靠场景整体特征波动动态确定全局梯度缩放倍率,结合粘连区域本身梯度幅值的局部差异,天然实现大件实体更新幅度偏大、细小薄壁结构更新幅度偏小的差异化优化,最后引入动量公式,用历史更新量 m t − 1 m_{t-1} mt−1加权平滑单步原始更新量 Δ z t \Delta z_t Δzt得到最终迭代量 m t m_t mt,抑制去噪时序上的更新震荡;
3.整体作用是将ISG输出的不可靠梯度转化为平稳合理的修正量,在顺利分离粘连实例的同时完整保留物体原生几何形态,守住原图的场景空间布局约束,与ISG模块配合落地免训练的多实例三维生成。
Q1:为什么梯度稀疏、局部高频尖峰、单点突变
原始 ∇ z t L s e p \nabla_{z_t}\mathcal{L}_{sep} ∇ztLsep(ISG直接算出的梯度):
- 稀疏:三维空间里绝大部分体素梯度≈0,只有桌椅粘连交界那一小片区域才有非0梯度,大片区域没更新信号;
- 高频尖峰:粘连边界个别点位梯度数值极大(尖峰突起),旁边相邻体素梯度瞬间跌到接近0。
举例:椅子腿和桌子粘在一起,只有接缝处几个像素梯度超大,周围椅身、桌面梯度几乎为0。
直接拿这个梯度改 z t z_t zt:只猛改接缝几个点→椅腿局部被硬生生拽歪、断裂,整张桌子不动,几何破损。
SR高斯平滑就是抹平尖峰,把单点梯度分摊到周边相邻空间,梯度变得连续平缓。
Q2:为什么只有桌椅粘连交界那一小片区域才有非0梯度,大片区域没更新信号?
A2:仅粘连交界区域梯度非0的原因(由 L s e p \mathcal{L}_{sep} Lsep损失的约束逻辑决定,并非资产分布缺陷), L s e p \mathcal{L}_{sep} Lsep只惩罚3D隐Token跨实例错配图像注意力:物体内部、远离交界的体素,3D特征正常绑定所属物体的图像掩码区域,实例归属概率 P v , k P_{v,k} Pv,k符合优化目标,该位置损失趋近于0;根据求导规则,损失接近0处对 z t z_t zt的梯度 ∇ z L s e p = 0 \nabla_{z}\mathcal{L}_{sep}=0 ∇zLsep=0。
只有桌椅粘连交界位置:三维特征一边关联桌子图像、一边关联椅子图像, P v , k P_{v,k} Pv,k混乱失衡、分离损失大幅升高,只有这部分点位存在非零损失,反向求导后才生成非零梯度,最终形成“全域大多梯度为0、仅接缝处有梯度尖峰”的稀疏梯度特征。
Q3:为什么命名为空间稳态正则化(SR)?
结合公式: g r e g = K σ ∗ ∇ z L s e p \boldsymbol{g_{reg}=\mathcal{K}_{\sigma} * \nabla_{z}\mathcal{L}_{sep}} greg=Kσ∗∇zLsep
- 空间:式中 ∗ * ∗代表三维空间卷积,高斯核 K σ \mathcal{K}_\sigma Kσ只在隐特征 z ∈ R C × D × H × W z\in\mathbb{R}^{C\times D\times H\times W} z∈RC×D×H×W的 D / H / W D/H/W D/H/W三维空间维度滑动加权,不在特征通道 C C C做卷积,约束作用落地在几何体空间分布上,因此冠以「空间」;
- 稳态:原始 ∇ z L s e p \nabla_{z}\mathcal{L}_{sep} ∇zLsep仅粘连接缝处有尖峰非零梯度、其余区域梯度为0,梯度场剧烈突变;经过高斯邻域平滑后,单点尖峰梯度分摊到相邻空间体素,梯度全域连续平缓,隐变量 z t z_t zt在空间上的更新状态平稳无骤变,实现优化稳态,对应名称里「稳态」;
- 正则化:通过平滑抑制梯度异常极值与高频噪声,约束病态梯度破坏几何结构,本质是在优化空间施加正则约束,故而叫空间稳态正则,输出平滑后的合规梯度 g r e g g_{reg} greg。
Q4:为什么命名为几何自适应调制(GM)?
结合公式: λ a d a p = α ⋅ σ z t μ m a x ( t ) + ϵ , Δ z t = λ a d a p ⋅ g r e g \lambda_{adap}=\frac{\alpha \cdot \sigma_{z_{t}}}{\mu_{max}^{(t)}+\epsilon }, \quad \Delta z_{t}=\lambda_{adap }\cdot g_{reg } λadap=μmax(t)+ϵα⋅σzt,Δzt=λadap⋅greg
- 几何: σ z t \sigma_{z_t} σzt由三维几何体的隐特征 z t z_t zt全局统计得到, σ z t \sigma_{z_t} σzt的大小由场景里物体几何形态(大块实体/细小薄壁构件)决定,特征离散度跟随几何结构变化,和几何体固有属性绑定,所以命名「几何」;
- 自适应: λ a d a p \lambda_{adap} λadap并非人工固定的缩放常数,每一个去噪步 t t t都会依据实时算出的隐特征标准差 σ z t \sigma_{z_t} σzt、梯度全局峰值 μ m a x ( t ) \mu_{max}^{(t)} μmax(t)自动改变取值,随当前场景几何分布动态适配缩放比例,体现「自适应」;
- 调制:使用动态系数 λ a d a p \lambda_{adap} λadap对经过SR处理的梯度 g r e g g_{reg} greg做逐元素缩放,调制梯度更新幅度,最终生成 Δ z t \Delta z_t Δzt,人为调控大件、小件几何体的更新量级,因此称作几何自适应调制。
5 实验
5.1 实验设置
实现细节
本文选用混元3D 2.0(Team,2025)作为基础预训练图像转三维模型,沿用其原生推理流水线与默认配置。实例掩码通过Grounded-SAM(Ren等人,2024)提取。ISG仅在去噪前期( t ≤ 15 t\le15 t≤15)、浅层交叉注意力层( l ≤ 4 l\le4 l≤4)启用;SGU中超参设置:梯度引导强度 α = 0.1 \alpha=0.1 α=0.1,高斯平滑标准差 σ = 1.5 \sigma=1.5 σ=1.5。该组参数在绝大多数场景下均可取得良好效果,体现TIMI方法通用性;微调参数(如增大 α \alpha α)可在特定场景进一步优化效果。
数据集
本文在三类不同领域数据集上完成多实例三维生成评测:
(1) 合成数据集:从3D-Front数据集(Fu等人,2021)随机选取30组测试场景,每组包含两个及以上空间相邻的物体实例;
(2) 真实场景数据集:从Real-Data数据集(Quattoni & Torralba,2009)收集20张实拍图像,用于验证现实场景泛化能力;
(3) 风格化数据集:借助Flux.1 Kontext(Labs等人,2025)生成20张多实例风格化图像,测试跨域鲁棒性。
对比基线
选取主流多实例生成算法作为对比方案:MIDI(Huang等人,2025)是基于微调的训练式方法,通过监督微调实现实例解耦;DPA(Zhou等人,2024)属于组合式生成方法,逐个生成实例后拼接组成场景;同时直接与原生单实例生成模型混元3D 2.0(Team,2025)做对照。
评测指标
从全局、局部空间保真两个维度采用多指标评测。参考已有工作(Nie等人,2020;Huang等人,2025),采用倒角距离(CD)与F分数(FS),分别在场景全局(CD-S、FS-S)和物体局部(CD-O、FS-O)层面计算。额外引入布局一致性距离(LCD)与实例分离成功率(SSR),分别量化布局对齐精度与实例区分效果。各指标详细定义与实现见附录A。
5.2 主要实验结果
5.2.1 定性对比
合成数据上的多实例生成
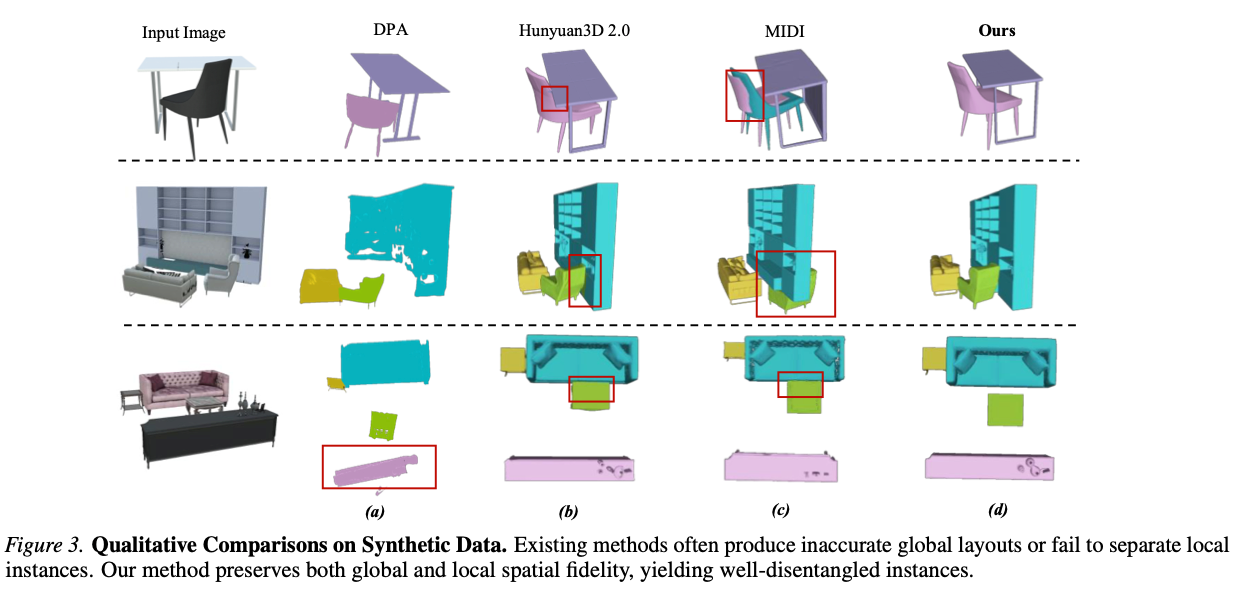
图3 合成数据集定性对比图。现有方法往往全局布局失真或无法分离局部实例,本文方法兼顾全局与局部空间保真,生成的实例边界清晰、相互分离。
如图3所示,TIMI在合成场景中稳定保持全局与局部空间保真特性。
(1) 全局空间保真:TIMI精准还原输入图像的物体空间布局;MIDI存在明显布局偏移,例如沙发与书架空间位置错位(图3©)。
(2) 局部空间保真:TIMI生成的实例结构完整、边界分明,有效解决混元3D 2.0出现的实例融合问题(如图3(b)中沙发与桌面粘连)。
上述结果证明TIMI可同时实现精准全局布局与独立局部实例生成。
真实图像与风格化图像生成
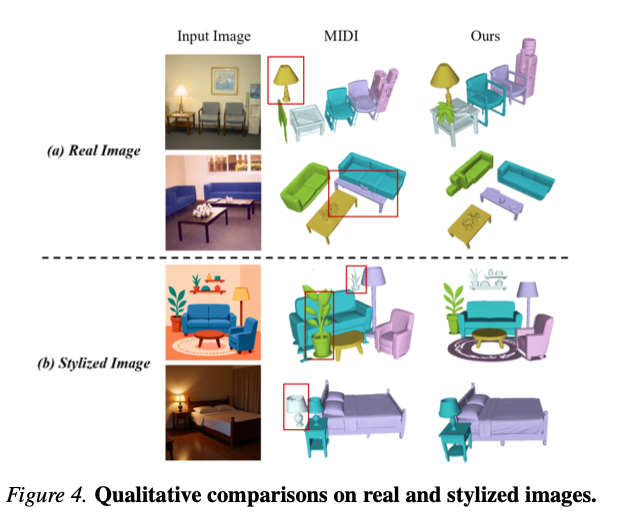
图4 真实图像与风格化图像定性对比图。
在真实场景与风格化图像测试中(图4),TIMI依旧维持高空间保真效果。全局布局方面,MIDI出现严重空间错位(例如绿植错误生成在沙发、桌子前方,图4(b)),而TIMI生成结果和原图布局高度匹配;局部实例层面,MIDI频繁出现桌体与沙发穿插融合(图4(a)),TIMI可保持实例边界分离。实验结果验证本框架在跨领域输入下具备优秀泛化性能。
5.2.2 定量对比
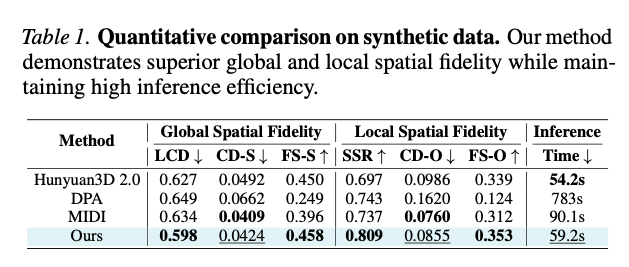
表1 合成数据集定量实验结果。本文方法在全局、局部空间保真指标上表现更优,同时推理效率优异。
定量结果汇总于表1,分析结论如下:
(1) 即便属于免训练方案,TIMI在全局与局部空间保真指标上整体优于需要训练微调的MIDI算法;
(2) 全局空间保真维度上,TIMI取得最优布局一致性距离 LCD = 0.598 \text{LCD}=0.598 LCD=0.598与全局F分数 FS-S = 0.458 \text{FS-S}=0.458 FS-S=0.458。尽管MIDI的全局倒角距离 CD-S \text{CD-S} CD-S数值略低,但 LCD \text{LCD} LCD能够更直观反映布局对齐程度,证明TIMI生成的全局场景布局与原图匹配度更高;
(3) 局部空间保真维度,TIMI大幅领先所有对比基线,实例分离成功率 SSR = 0.809 \text{SSR}=0.809 SSR=0.809、局部F分数 FS-O = 0.353 \text{FS-O}=0.353 FS-O=0.353均为最优值,实例拆分效果突出。MIDI的局部倒角距离 CD-O \text{CD-O} CD-O指标相近,但更低的 SSR \text{SSR} SSR说明其频繁出现物体融合现象,而TIMI生成实例边界独立、区分度更强;
(4) 推理效率方面,TIMI耗时约59.2秒,和原生基准模型混元3D 2.0(54.2s)处在同一量级,远快于训练型MIDI(90.1s)与组合式DPA(783s)。
用户调研
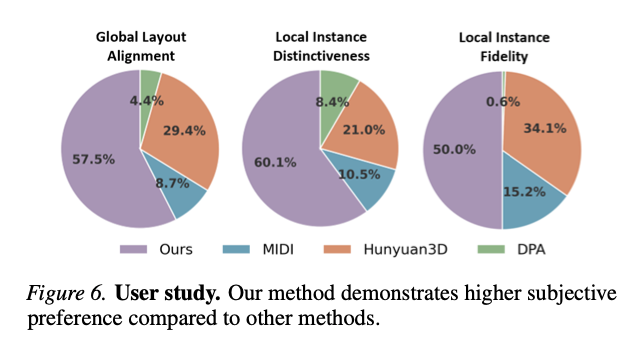
图6 主观用户调研结果统计图。相较于其他算法,本文方案获得更高的人类主观偏好。
开展用户主观评测实验,结果如图6所示:
(1) 在全局布局对齐维度,57.5%的受试者优先选择TIMI生成结果;
(2) 在局部实例区分度上,60.1%用户偏好本文方法,显著优于MIDI与混元3D,说明实例精细化分离的提升在人眼感知层面十分直观;
(3) 实例生成质量维度中,50.0%的受试者选择TIMI,证实本文在优化全局、局部空间保真的同时没有牺牲物体生成品质。
5.3 消融实验
本节通过完备的消融实验逐一验证TIMI各组成模块有效性。首先验证ISG与SGU两大核心模块的必要性,随后在5.3.1小节细化ISG参数消融、5.3.2小节细化SGU各子模块与超参消融。
ISG与SGU模块有效性验证
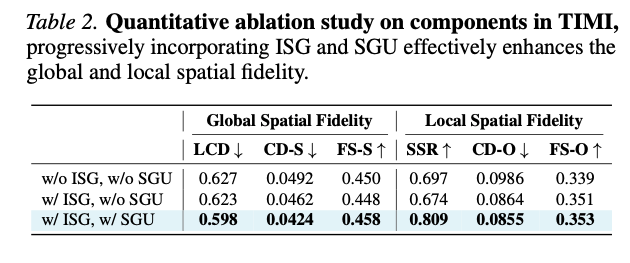
表2 模块消融定量结果。逐步引入ISG、SGU可持续提升全局与局部空间保真性能。
由表2可得:
(1) ISG与SGU两个模块均可正向提升全局、局部空间保真指标;
(2) 仅启用ISG:局部空间保真获得改善, FS-O \text{FS-O} FS-O、 CD-O \text{CD-O} CD-O指标优化;
(3) ISG+SGU共同启用:全局布局指标大幅提升,同时保留局部实例分离优势,全维度指标同步优化。
图5 模块消融定性效果图。逐个增加模块后,布局对齐与实例区分效果逐步提升,全模块组合实现最优空间保真。
结合图5可视化结果:
(1) 无ISG、无SGU:凳子与柜体严重粘连,凳子结构残缺扭曲;
(2) 仅添加ISG、无SGU:实例实现拆分,但几何体出现破损(凳腿缺失),直接梯度优化会破坏结构完整性;
(3) ISG搭配完整SGU:整体布局规整,凳子结构完整、几何形态合理。
已翻译至5.3消融实验前置部分(第6~7页),是否继续?### 5.2.2 定量对比
表1 合成数据集定量实验结果。本文方法在全局、局部空间保真指标上表现更优,同时推理效率优异。
定量结果汇总于表1,分析结论如下:
(1) 即便属于免训练方案,TIMI在全局与局部空间保真指标上整体优于需要训练微调的MIDI算法;
(2) 全局空间保真维度上,TIMI取得最优布局一致性距离 LCD = 0.598 \text{LCD}=0.598 LCD=0.598与全局F分数 FS-S = 0.458 \text{FS-S}=0.458 FS-S=0.458。尽管MIDI的全局倒角距离 CD-S \text{CD-S} CD-S数值略低,但 LCD \text{LCD} LCD能够更直观反映布局对齐程度,证明TIMI生成的全局场景布局与原图匹配度更高;
(3) 局部空间保真维度,TIMI大幅领先所有对比基线,实例分离成功率 SSR = 0.809 \text{SSR}=0.809 SSR=0.809、局部F分数 FS-O = 0.353 \text{FS-O}=0.353 FS-O=0.353均为最优值,实例拆分效果突出。MIDI的局部倒角距离 CD-O \text{CD-O} CD-O指标相近,但更低的 SSR \text{SSR} SSR说明其频繁出现物体融合现象,而TIMI生成实例边界独立、区分度更强;
(4) 推理效率方面,TIMI耗时约59.2秒,和原生基准模型混元3D 2.0(54.2s)处在同一量级,远快于训练型MIDI(90.1s)与组合式DPA(783s)。
用户调研
图6 主观用户调研结果统计图。相较于其他算法,本文方案获得更高的人类主观偏好。
开展用户主观评测实验,结果如图6所示:
(1) 在全局布局对齐维度,57.5%的受试者优先选择TIMI生成结果;
(2) 在局部实例区分度上,60.1%用户偏好本文方法,显著优于MIDI与混元3D,说明实例精细化分离的提升在人眼感知层面十分直观;
(3) 实例生成质量维度中,50.0%的受试者选择TIMI,证实本文在优化全局、局部空间保真的同时没有牺牲物体生成品质。
5.3 消融实验
本节通过完备的消融实验逐一验证TIMI各组成模块有效性。首先验证ISG与SGU两大核心模块的必要性,随后在5.3.1小节细化ISG参数消融、5.3.2小节细化SGU各子模块与超参消融。
ISG与SGU模块有效性验证
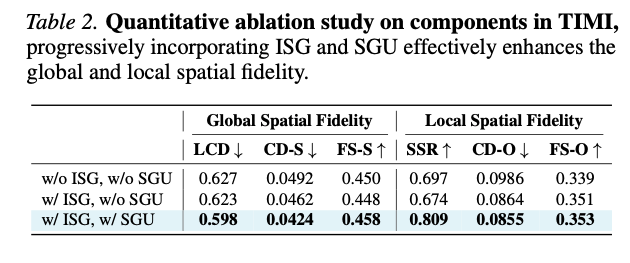
表2 模块消融定量结果。逐步引入ISG、SGU可持续提升全局与局部空间保真性能。
由表2可得:
(1) ISG与SGU两个模块均可正向提升全局、局部空间保真指标;
(2) 仅启用ISG:局部空间保真获得改善, FS-O \text{FS-O} FS-O、 CD-O \text{CD-O} CD-O指标优化;
(3) ISG+SGU共同启用:全局布局指标大幅提升,同时保留局部实例分离优势,全维度指标同步优化。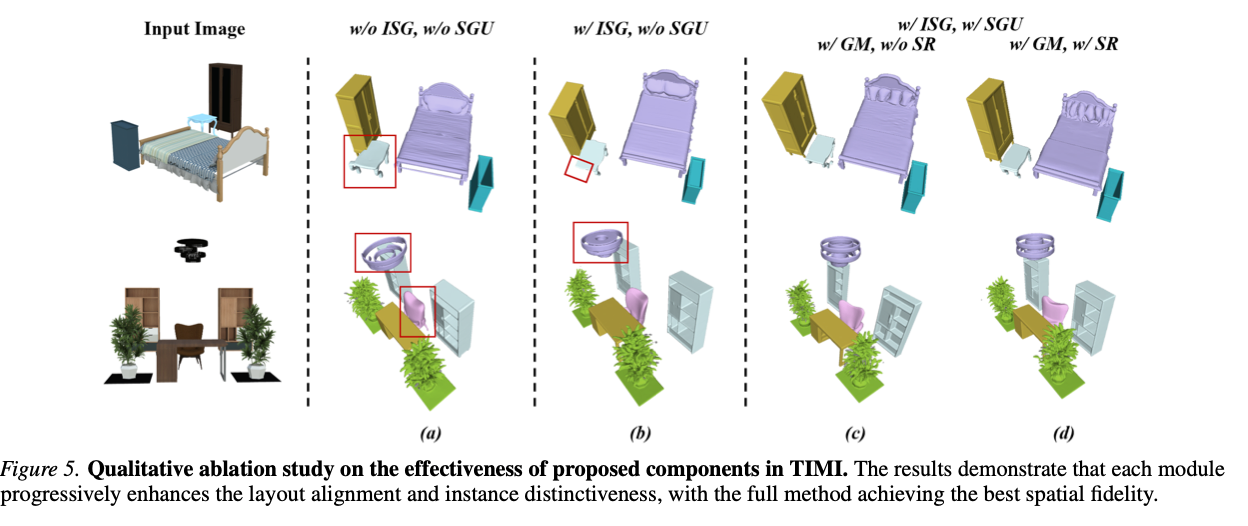
图5 模块消融定性效果图。逐个增加模块后,布局对齐与实例区分效果逐步提升,全模块组合实现最优空间保真。
结合图5可视化结果:
(1) 无ISG、无SGU:凳子与柜体严重粘连,凳子结构残缺扭曲;
(2) 仅添加ISG、无SGU:实例实现拆分,但几何体出现破损(凳腿缺失),直接梯度优化会破坏结构完整性;
(3) ISG搭配完整SGU:整体布局规整,凳子结构完整、几何形态合理。
5.3.1 ISG模块消融分析
针对ISG模块,本文围绕两个关键超参开展消融实验:一是施加引导的交叉注意力层数 l l l,二是启用ISG的早期去噪步数 t t t。
引导层数 l l l的影响
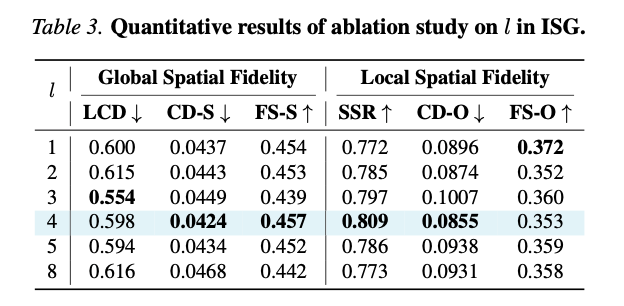
表3 ISG不同引导层数 l l l对应的定量消融结果。
实验结论:
- 对前4层( l ∈ [ 0 , 4 ] l \in [0,4] l∈[0,4])施加引导可实现综合最优性能,全局倒角距离最优、实例分离成功率 SSR \text{SSR} SSR最高;
- 仅限定极浅层( l ≤ 1 l\le1 l≤1)引导虽小幅提升F类指标,但全局布局对齐变差、实例分离能力下降,浅层约束力度不足;
- 引导层数超过第4层(如 l ≤ 8 l\le8 l≤8)后性能不升反降,深层注意力侧重高层语义、纹理与类别信息,不适用于实例空间约束。
上述定量结论在附录B.1可视化结果中得到佐证,前四层引导可均衡实例分离与几何完整性。
去噪步数 t t t的影响
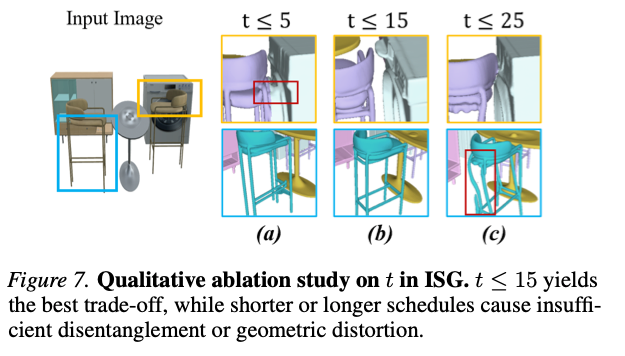
图7 ISG作用步数 t t t定性消融对比图。 t ≤ 15 t\le15 t≤15可以取得最优折中效果,步数过少实例无法分离,步数过多引发几何畸变。
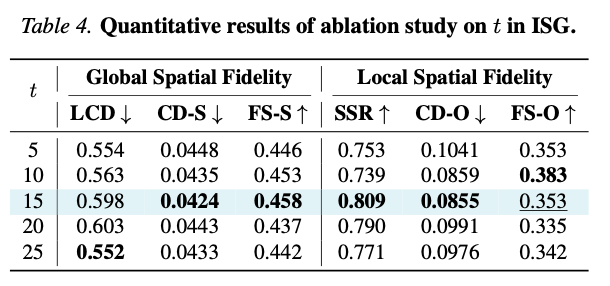
表4 ISG不同作用步数 t t t定量消融结果。
- ISG仅在前15步( t ≤ 15 t\le15 t≤15)生效时综合指标最优,全局布局一致性与局部实例分离度同时达到峰值;
- 约束步数过短( t ≤ 10 t\le10 t≤10):实例解耦不充分, SSR \text{SSR} SSR指标下降;
- 引导周期过长( t ≥ 20 t\ge20 t≥20):无法继续提升空间保真,反而降低 FS-O \text{FS-O} FS-O,几何质量受损。
可视化结果如图7: t ≤ 5 t\le5 t≤5时洗衣机和椅子粘连未分开; t ≤ 25 t\le25 t≤25引导过久造成椅腿畸形。因此默认选用 t = 15 t=15 t=15。
5.3.2 SGU模块消融分析
本小节针对SGU内部组件与超参开展细化实验,分别验证几何自适应调制GM、空间稳态正则SR,以及引导强度 α \alpha α、平滑系数 σ \sigma σ的影响。
GM与SR子模块有效性
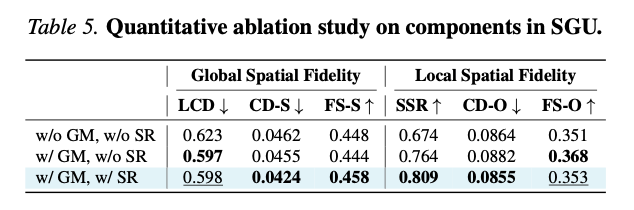
表5 SGU子模块定量消融结果。
- 无GM、无SR:全局布局差、实例分离成功率最低;
- 仅GM生效:全局LCD指标优化明显,但局部实例分离提升有限;
- GM+SR共同启用:全部指标同步最优,兼顾全局布局与局部实例质量。
结合图5可视化:仅使用GM时凳子腿部扭曲变形;叠加SR后畸变消除,布局稳定、实例边界清晰。
引导强度 α \alpha α的影响
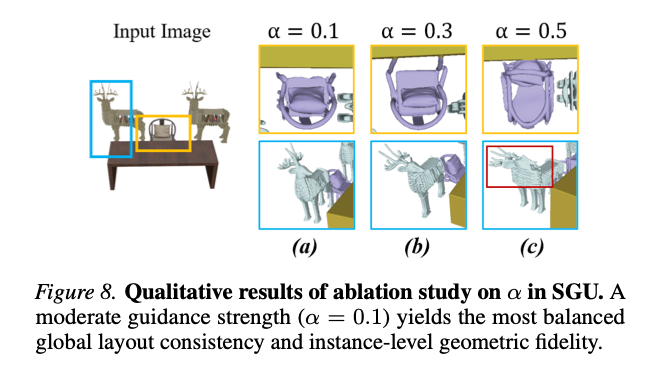
图8 不同 α \alpha α取值定性消融对比。适中的引导强度 α = 0.1 \alpha=0.1 α=0.1能够均衡全局布局与局部几何保真。
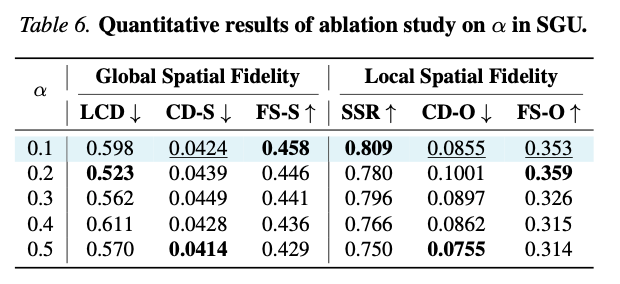
表6 超参 α \alpha α定量消融数据。
- α = 0.1 \alpha=0.1 α=0.1:全局空间保真优异,实例几何完好;
- α \alpha α提升至0.2:全局指标小幅波动,局部倒角距离变差;
- α ≥ 0.3 \alpha\ge0.3 α≥0.3:全局、局部保真性能持续下滑;
- α = 0.5 \alpha=0.5 α=0.5:全局位置对齐尚可,但过度引导破坏几何体结构,F分数显著下降。
直观表现为 α \alpha α越大,物体结构扭曲越严重。
高斯平滑系数 σ \sigma σ的影响
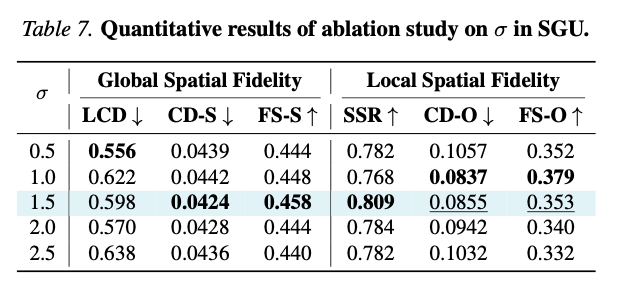
表7 超参 σ \sigma σ定量消融结果。
- σ = 0.5 \sigma=0.5 σ=0.5:平滑力度不足,全局布局差、实例分离不充分;
- σ = 2.5 \sigma=2.5 σ=2.5:平滑过度,物体原生几何被破坏;
- σ = 1.5 \sigma=1.5 σ=1.5为最优取值, CD-S \text{CD-S} CD-S与 SSR \text{SSR} SSR指标最优,在实例分离与几何保存间实现平衡。
相关可视化对比见附录B.2。
6 结论
本文提出了TIMI免训练图像转三维多实例生成框架,依靠实例感知引导策略实现生成优化。通过ISG与SGU两个模块协同作用,在实现局部实例有效解耦的同时,精准保留全局场景布局。各项实验结果表明:在无需额外训练的前提下,TIMI整体性能优于现有方法,为高空间保真多实例三维生成提供了一套切实可行的解决方案。
思考
本文的研究动机是现有预训练图像转三维扩散模型在多实例场景生成时,跨模态交叉注意力缺少实例划分机制,致使不同物体特征错误绑定、几何体相互粘连穿插,而现有改进方案要么依赖全量微调带来高额算力开销,要么采用逐一生成再拼接的方式破坏原图空间布局;
为此论文提出免训练的TIMI多实例三维生成框架作为核心创新,框架由ISG实例感知分离引导与SGU空间稳态几何自适应更新两大模块组成,ISG借助Grounded-SAM提取的实例掩码,基于交叉注意力 A z c A_{zc} Azc计算实例归属概率并构造实例分离损失,在推理阶段仅优化隐变量 z t z_t zt、冻结全部预训练网络权重以实现实例解耦,配套SGU通过三维高斯空间正则平滑梯度尖峰、几何自适应调制动态匹配大小物体更新步长、动量平滑抑制时序更新震荡,同时约束模块仅在去噪前期与浅层交叉注意力生效,避免过度修正打乱空间结构;
该方法的实际作用是在不破坏基础模型原生布局还原先验、无训练成本的前提下,高效消除多实例粘连问题,在全局布局保真与局部实例几何完整度上超越MIDI、DPA等对比基线,适配合成、实景、风格化多种输入图像,有效降低高质量多实例三维资产的生成门槛。
Q1:如何实现精准保留全局场景布局的?
A1:依托原图掩码锚定物体空间位置、SGU 平滑梯度避免拉扯移位、限制引导时段与层数、冻结预训练模型保全原生布局先验,四项机制共同在拆分粘连实例的同时,精准复刻原图全局场景布局。
7 影响说明
本文提出的TIMI框架借助免训练范式推进三维生成建模研究,在省去微调所需高额算力开销的基础上实现高保真多实例三维内容生成。该方案降低了高质量三维内容创作的技术门槛,有望赋能工业设计、虚拟现实、文创产业等领域落地应用。但本方法依赖现成预训练基础模型,生成结果会继承预训练数据集本身隐含的数据偏见。除生成式AI通用的合规使用风险外,本文方案暂未预见其他直接负面社会影响。
附录A 实验相关设定
评测指标
本文采用多维度量化指标,分别从全局与局部两个层面评估多实例生成的空间保真度。
(1) 客观量化指标
参照已有研究(Nie等人,2020;Huang等人,2025),采用倒角距离(CD)与F分数(FS),分别在全局场景维度(CD-S、FS-S)和单个实例维度(CD-O、FS-O)衡量重建质量与空间保真。额外引入两项针对性指标量化布局对齐和实例分离效果:
布局一致性距离(LCD):基于预测实例与真值实例中心点(该实例所有 3D 点坐标的算术平均值)计算双向倒角距离,量化物体摆放准确度:
L C D = 1 ∣ C p r e d ∣ ∑ x ∈ C p r e d m i n y ∈ C g t ∥ x − y ∥ 2 + 1 ∣ C g t ∣ ∑ y ∈ C g t m i n x ∈ C p r e d ∥ y − x ∥ 2 , \begin{aligned} LCD= & \frac{1}{\left|\mathcal{C}_{pred }\right|} \sum_{x \in \mathcal{C}_{pred }} min _{y \in \mathcal{C}_{g t}}\| x-y\| _{2} \\ & +\frac{1}{\left|\mathcal{C}_{g t}\right|} \sum_{y \in \mathcal{C}_{g t}} min _{x \in \mathcal{C}_{pred }}\| y-x\| _{2}, \end{aligned} LCD=∣Cpred∣1x∈Cpred∑miny∈Cgt∥x−y∥2+∣Cgt∣1y∈Cgt∑minx∈Cpred∥y−x∥2,
式中 C p r e d \mathcal{C}_{pred} Cpred、 C g t \mathcal{C}_{gt} Cgt分别代表预测实例中心点集合与真值实例中心点集合, ∥ ⋅ ∥ 2 \|\cdot\|_2 ∥⋅∥2为两点间欧氏距离。第一项约束每个预测物体尽量靠近最近真值物体,第二项保证所有真值实例都能被生成结果覆盖。
实例分离成功率(SSR):通过预测实例数量与真值实例数量的匹配程度衡量实例独立区分能力,与物体形状、具体位置无关:
S S R = m i n ( N p r e d , N g t ) m a x ( N p r e d , N g t ) (10) SSR=\frac {min(N_{pred },N_{gt})}{max(N_{pred },N_{gt})} \tag{10} SSR=max(Npred,Ngt)min(Npred,Ngt)(10)
N p r e d N_{pred} Npred、 N g t N_{gt} Ngt依次为预测得到的实例数目、真实标注实例数目。
(2) 主观评测指标
设计用户调研实验,受试者对随机配对的生成结果进行盲测打分,评测维度包含:全局布局对齐度、局部实例区分度、局部实例保真度。
附录B 补充实验结果
B.1 ISG引导层数 l l l消融定性结果
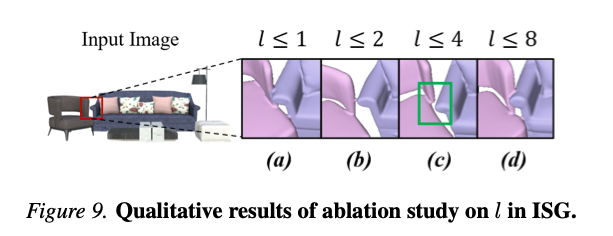
图9 ISG不同引导层数 l l l的消融定性对比图。
- 仅对前四层( l ≤ 4 l\le4 l≤4)施加引导:实例分离效果最优,沙发扶手与椅子边界清晰、完全分离;
- 浅层引导( l ≤ 1 l\le1 l≤1、 l ≤ 2 l\le2 l≤2):实例粘连问题明显,沙发局部结构和椅子相互融合,浅层约束力度不足;
- 引导层数拓展至 l ≤ 8 l\le8 l≤8:虽大体几何无严重崩坏,但物体边界模糊,相邻实例再次出现局部融合。
上述现象说明深层注意力偏向抽象语义信息,不适用于实例空间分离约束;定量与定性实验共同证明,选取前四层作为引导范围是兼顾实例分离与结构完整性的最优选择。
B.2 SGU平滑系数 σ \sigma σ消融定性结果
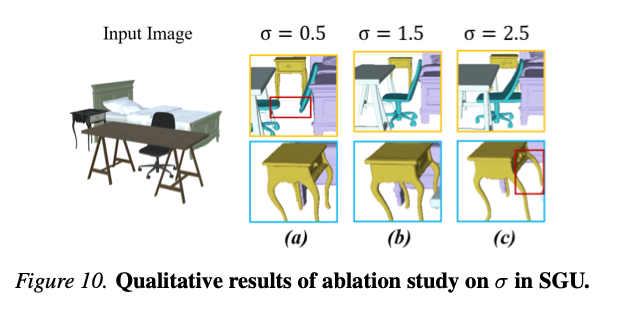
图10 不同 σ \sigma σ取值消融定性对比图。
- σ = 0.5 \sigma=0.5 σ=0.5:平滑约束偏弱,引导不稳定,椅身靠背断裂,椅子和床体粘连未分开;
- σ = 2.5 \sigma=2.5 σ=2.5:平滑强度过大,虽可分开椅子与床,但单个物体原生几何受损,家具支脚出现扭曲形变;
- σ = 1.5 \sigma=1.5 σ=1.5:平衡平滑强度,在实现实例分离的同时保全物体完整几何结构,因此选为默认参数。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)