教育数据进阶!基于13维加权矩阵与过程归因模型的高中班级学风诊断与分层治理模型实践
#商业数据分析 #助睿数智能 #大数据 #校园数据分析 #高中管理决策
一、背景与目的:为什么要做这件事
在学校管理工作中,我们时常遇到这样的困惑:两个平均分几乎一样的班级,一个班主任带得游刃有余,另一个却问题层出不穷;有的班级成绩不错,但学生的精神面貌和日常行为已经出现了明显的滑坡苗头,等到期中考试成绩出来才被发现,往往错过了最佳干预时机。
问题的根源在于,传统的班级评价方式过于依赖“平均分”这一单一指标。这种方式有三个明显缺陷:
- 滞后性:考试结果反映的是过去一个阶段的学习效果,而学风问题的积累早在考试之前就已经开始;
- 结构性盲区:平均分掩盖了班级内部的分化程度——一个“平均分不错”的班级,可能一半学生名列前茅,另一半早已跟不上进度;
- 维度缺失:成绩只能反映学业表现,而纪律考勤、师资稳定性、学生保留率等影响学风的因素完全被忽视。
基于这些考虑,我们尝试搭建一套基于日常管理数据的分析系统,把评价的视角从期末成绩扩展到整个学期的多个维度,将分析结果做成可供校长、年级组长和班主任直接使用的交互式看板。这篇文章按照实际的开发流程,从数据整合、指标构建、综合评分、可视化呈现到分析结论,把整个思路和方法梳理一遍,同时,借助助睿平台进行数据整合可视化,实现更进一步的数据分析与成果展示。
二、分析框架:从原始数据到可操作结论
整个分析流程可以概括为五个阶段:
数据整合 → 指标聚合 → 综合评分 → 可视化呈现 → 分层诊断。
每个阶段解决一个具体问题,最终串成一条完整的分析链条。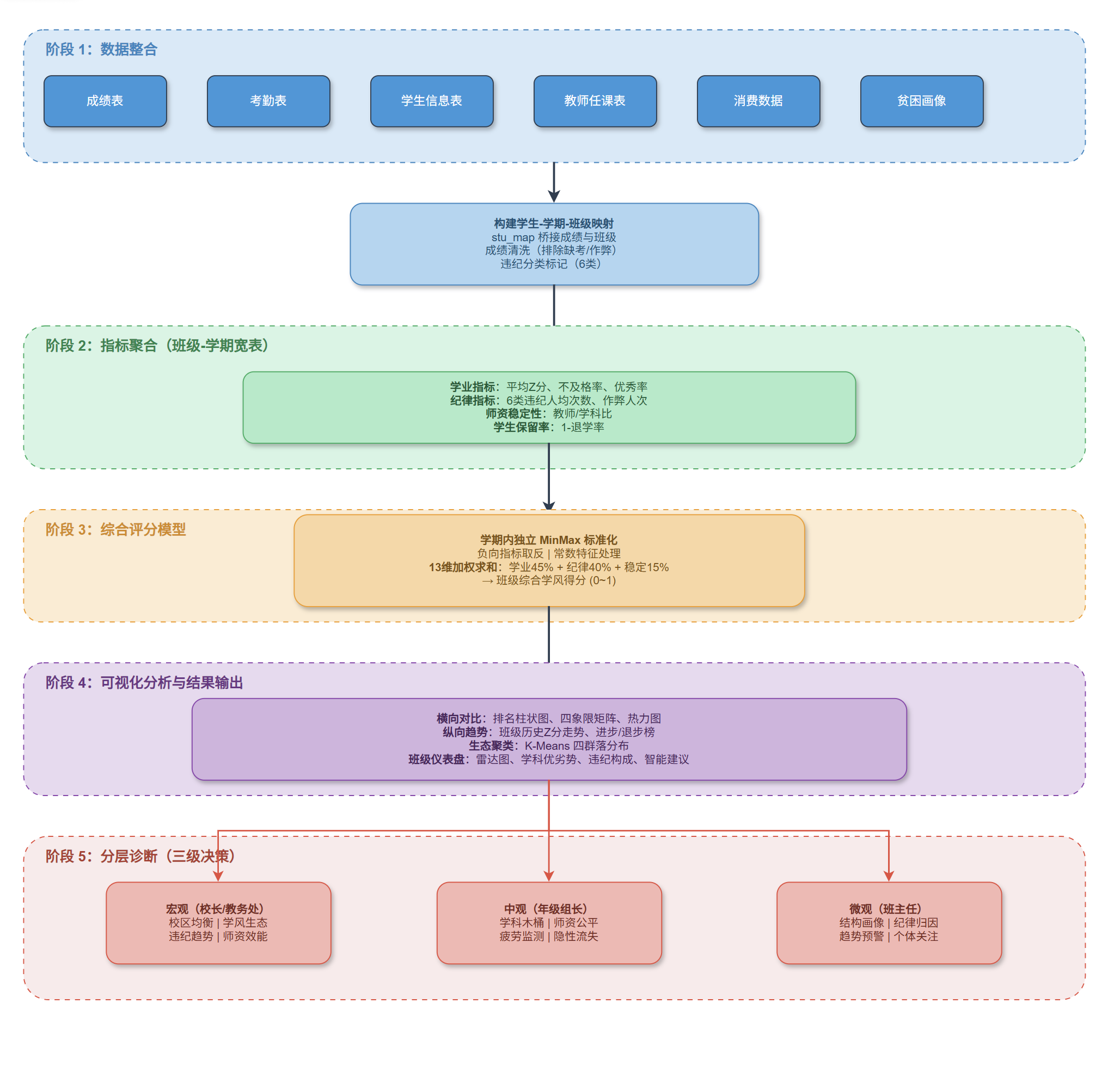
2.1 数据整合:把分散的“数据孤岛”连起来
学校的数据散落在多个独立系统中:成绩表存储考试分数,考勤表记录每天的迟到和违纪,学生信息表包含班级归属和住宿状态,教师任课表反映师资配置。这些表之间缺少直接的外键关联——最典型的问题是成绩表只有学号和学期,没有班级ID,无法直接按班级汇总。
我们首先需要建立数据之间的桥梁。具体做法是从考勤表中提取每个学生在每个学期所属的班级,形成一张“学生‑学期‑班级”的映射表:
# 从考勤表提取映射关系,去重后作为桥梁
stu_map = df_kaoqin[['bf_studentID', 'qj_term', 'bf_classid']].drop_duplicates()
stu_map['qj_term'] = stu_map['qj_term'].astype(str).str.strip()
stu_map = stu_map[~stu_map['qj_term'].isin(['', 'nan', 'None'])]
然后,成绩表通过学号和学期与该映射做左连接,补上班级ID。同时进行数据清洗:保留有效成绩(分数≥0,排除作弊-1、缺考-2、免考-3),并对作弊记录单独标记。
# 分离有效成绩和作弊记录
df_chengji_clean = df_chengji[df_chengji['mes_Score'] >= 0].copy()
df_chengji['is_cheat'] = (df_chengji['mes_Score'] == -1).astype(int)
# 通过映射表给成绩补充班级ID
temp_clean = temp_clean.merge(stu_map,
left_on=['mes_StudentID', 'exam_term'],
right_on=['bf_studentID', 'qj_term'], how='left')
违纪数据同样需要结构化处理。原始考勤表中违纪类型用ID编码(如100100代表早上迟到,200100代表校服违规),我们预先定义六种常见场景,用isin逐条打上布尔标记,并汇总总违纪次数。
# 为六种违规类型逐条打标记
for col, ids in violation_config.items():
df_kaoqin[f'is_{col}'] = df_kaoqin['control_task_order_id'].isin(ids).astype(int)
# 汇总所有违规类型得到单条记录的总违纪次数
df_kaoqin['is_violation'] = df_kaoqin[violation_col_names].sum(axis=1)
经过这一阶段,原本分散的四张表被整合成后续分析所需的结构化宽表,匹配率达到90%以上,覆盖198个班级学期样本。
2.2 指标聚合:从明细到班级-学期粒度
整合后的数据仍然是大量的明细记录,需要按“班级‑学期”粒度聚合为可对比的统计指标。这一阶段我们拆分为四个子模块分别计算:
学业指标:按班级‑学期分组,计算三个核心字段:
| 指标 | 计算方式 | 说明 |
|---|---|---|
| 平均Z分 | groupby.mean(mes_Z_Score) |
Z分是标准化后的成绩,均值为0,可跨学科比较 |
| 不及格率 | groupby.mean(is_fail) |
按学科区分及格线:语数英90分(满分150),其余60分(满分100) |
| 优秀率 | groupby.mean(Z>1) |
Z分超过1个标准差的视为优秀 |
# 按学科设定不同的及格线
temp_clean['full_score'] = temp_clean['mes_sub_name'].map(subject_full_score).fillna(100)
temp_clean['pass_line'] = temp_clean['full_score'] * 0.6
temp_clean['is_fail'] = (temp_clean['mes_Score'] < temp_clean['pass_line']).astype(int)
纪律指标:按班级‑学期分组,统计总违纪次数和各类型违纪次数,再除以班级人数得到人均值。这里用字典推导自动展开六个聚合字段,避免逐行写出。
term_violation = df_kaoqin_clean.groupby(['bf_classid', 'qj_term']).agg(
total_violations=('is_violation', 'sum'),
**{f'{c}_cnt': (f'is_{c}', 'sum') for c in violation_config.keys()}
).reset_index()
# 计算人均违纪次数
for col in cnt_cols:
term_discipline[col + '_per'] = term_discipline[col] / term_discipline['student_count']
师资稳定性:计算每个班级的教师数与学科数的比值。理想值为1(每位教师只教一门课),比值偏离1越大,说明一个教师兼跨多学科或频繁更换教师。
学生保留率:1减去退学人数占总人数的比例。退学数据来自学生信息表的bf_leaveSchool字段。
最后,用四次merge操作将所有指标合并为一张面板宽表,缺失值按规则填充(违纪填0,师资比填1,保留率填1)。
2.3 综合评分:13维加权矩阵
如果只看单一维度,很难全面评估一个班级的学风状况。我们设计了13维加权指标体系,将四大类指标整合为一个0到1之间的综合得分。
权重分配如下:
| 维度 | 指标 | 权重 | 分类占比 |
|---|---|---|---|
| 学业水平 | 平均Z分 | 0.20 | 45% |
| 学业水平 | 优秀率 | 0.15 | |
| 学业水平 | 不及格率 | 0.10 | |
| 纪律考勤 | 总违纪人均 | 0.10 | 40% |
| 纪律考勤 | 早上迟到人均 | 0.04 | |
| 纪律考勤 | 晚到学校人均 | 0.04 | |
| 纪律考勤 | 移动迟到人均 | 0.04 | |
| 纪律考勤 | 早退人均 | 0.04 | |
| 纪律考勤 | 校服校徽人均 | 0.04 | |
| 纪律考勤 | 移动校服人均 | 0.04 | |
| 纪律考勤 | 作弊得分 | 0.06 | |
| 学生稳定性 | 保留率 | 0.10 | 10% |
| 师资稳定性 | 教师学科比 | 0.05 | 5% |
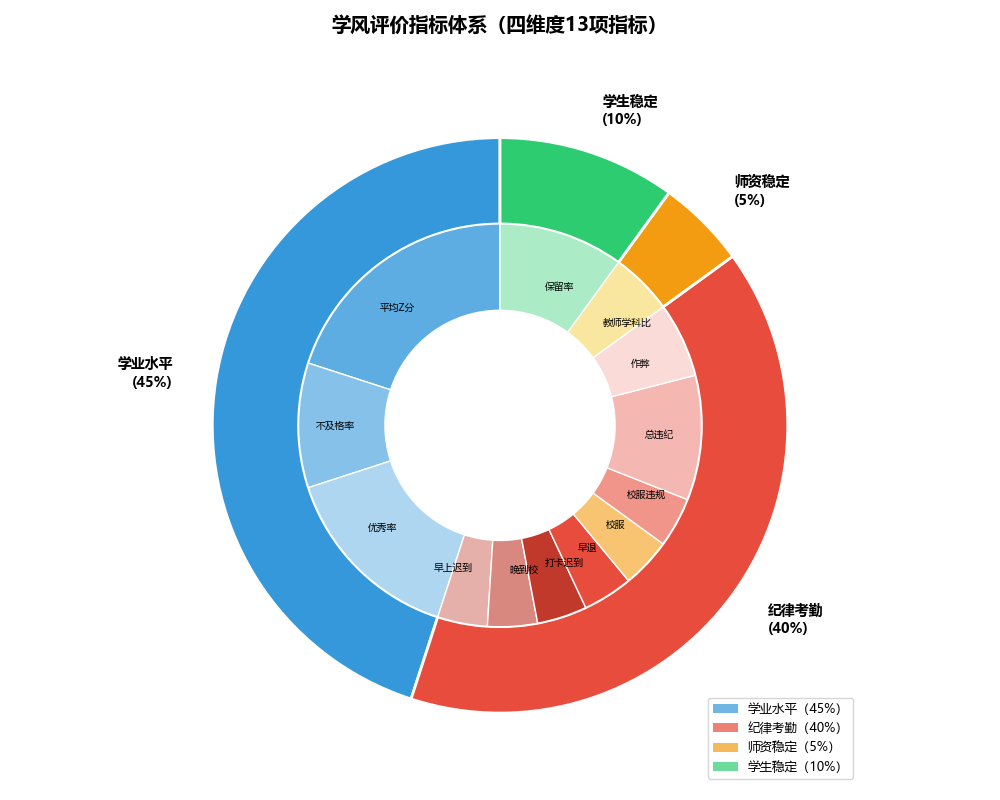
权重的设定反映了管理导向:学业占比最高(45%),但纪律同样重要(40%)。一个班级即便成绩突出,如果违纪扩散严重,综合得分也会被拉低,这促使班主任不能只抓学习而忽视日常行为规范。
标准化处理是关键步骤。我们采用学期内独立的Min‑Max标准化,每个学期内的所有班级放在一起归一化到[0,1]区间。这样做的好处是避免了不同学期间整体水平波动的影响。对于负向指标(不及格率、违纪次数),先取反再标准化。常数特征(所有班级取值相同)直接赋0,避免除零错误。
for term, group in panel.groupby('exam_term'):
scaler = MinMaxScaler()
# 负向指标取反
X = group[pos_cols + neg_cols].copy()
for col in neg_cols:
X[col] = -X[col]
# 逐列标准化,常数特征直接置0
for col in X.columns:
if X[col].nunique() <= 1:
X_scaled[col] = 0.0
else:
X_scaled[col] = scaler.fit_transform(X[[col]]).flatten()
# 加权求和
group['total_score'] = sum(group[col] * w for col, w in score_weights.items())
标准化前后的对比可以通过直方图直观看到:原始平均Z分呈偏态分布,标准化后均匀映射到[0,1]区间,所有班级在每个维度上都有了可比较的相对位置。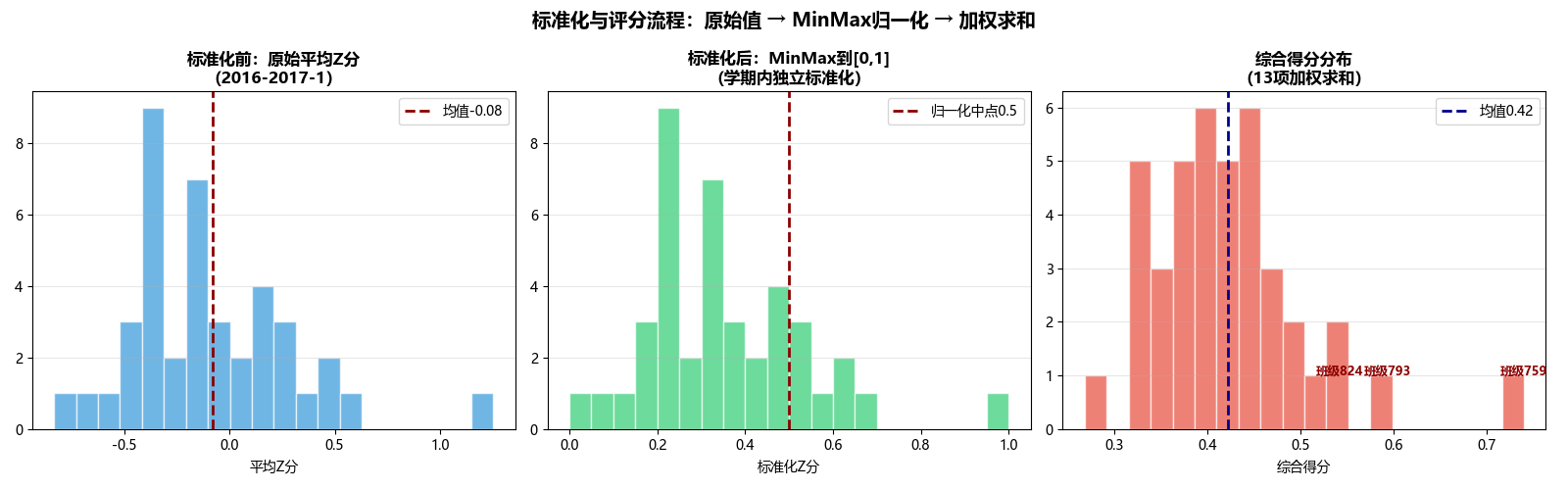
2.4 多角度可视化:从宏观到微观
综合得分计算完成后,我们不再停留于表格数字,而是生成了一系列可视化图表,让数据自己“说话”。
横向对比部分包括四个主要图表:
-
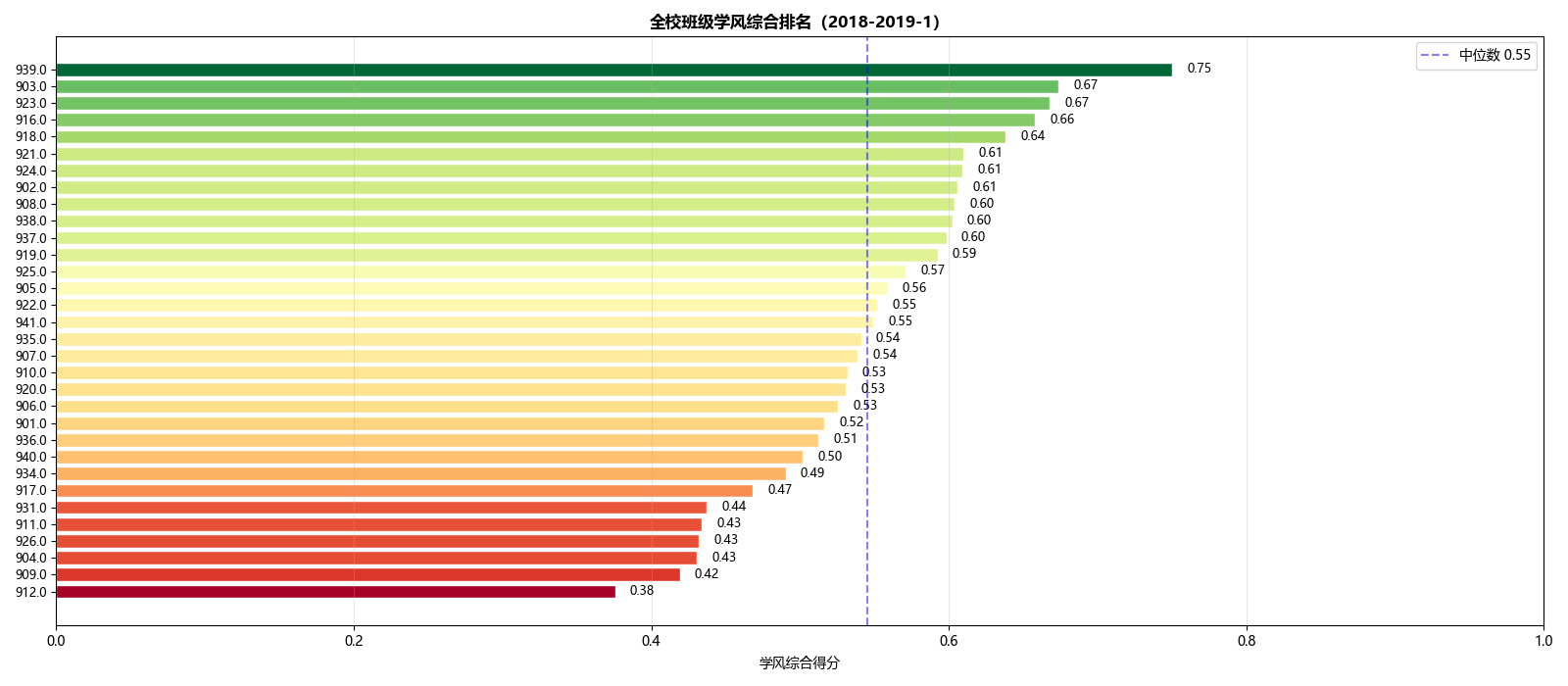
Top10与末尾5柱状图:绿红两色区分,中位数线标注全校平均水平;
-
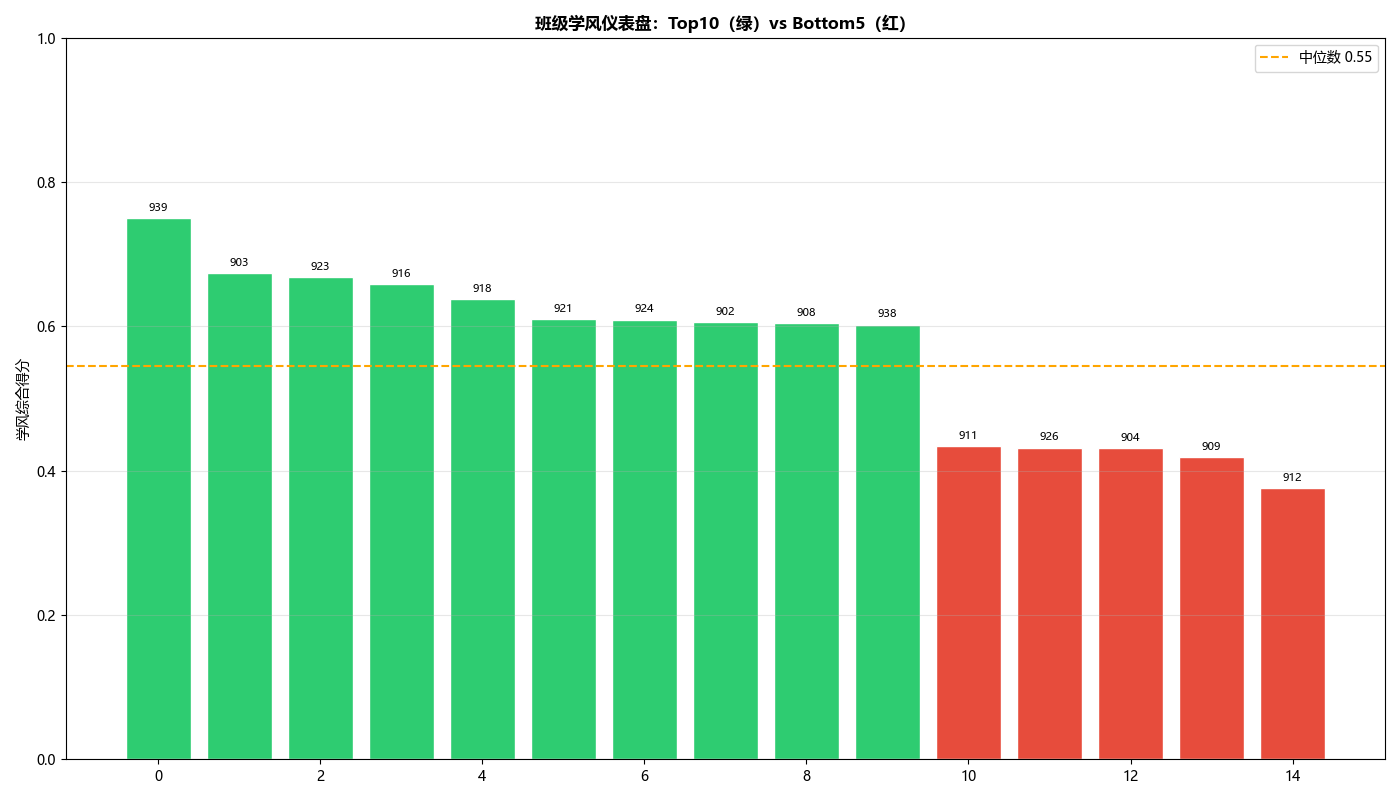
-
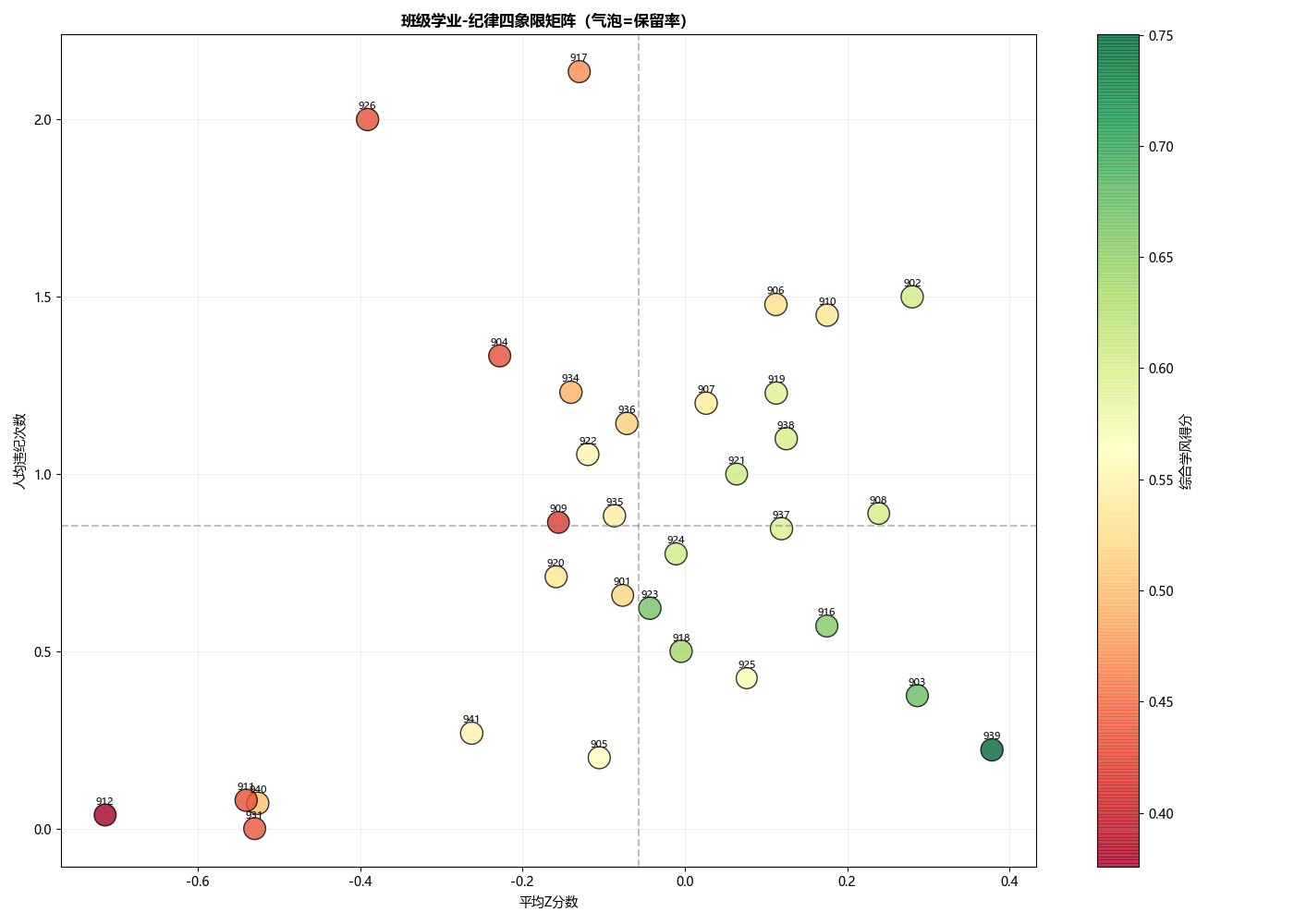
学业‑纪律四象限矩阵:横轴为平均Z分,纵轴为人均违纪次数,中位数线将画面分为四个区域。每个班级的标签直接标在图上,气泡大小反映保留率,颜色反映综合得分;
-
-
全校排名瀑布图:将所有班级按得分从低到高排列,颜色渐变从红到绿,每个班的具体得分标在旁边;
-
-
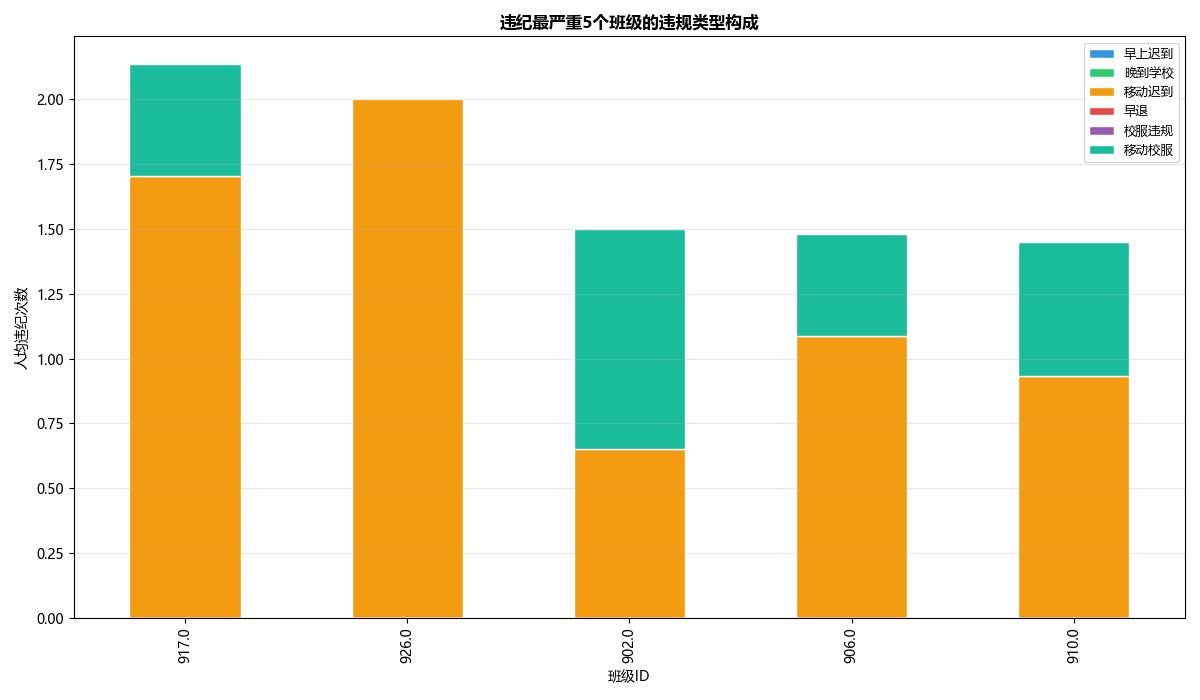
违纪类型堆叠图:取违纪最严重的5个班级,用堆叠柱状图展示不同类型违纪的构成。
纵向趋势部分主要看两个内容:
-
典型班级历史趋势线:选取当前排名前3和末3的班级,回溯其近三个学期的平均Z分变化,观察走势是上升还是下滑;
-
-
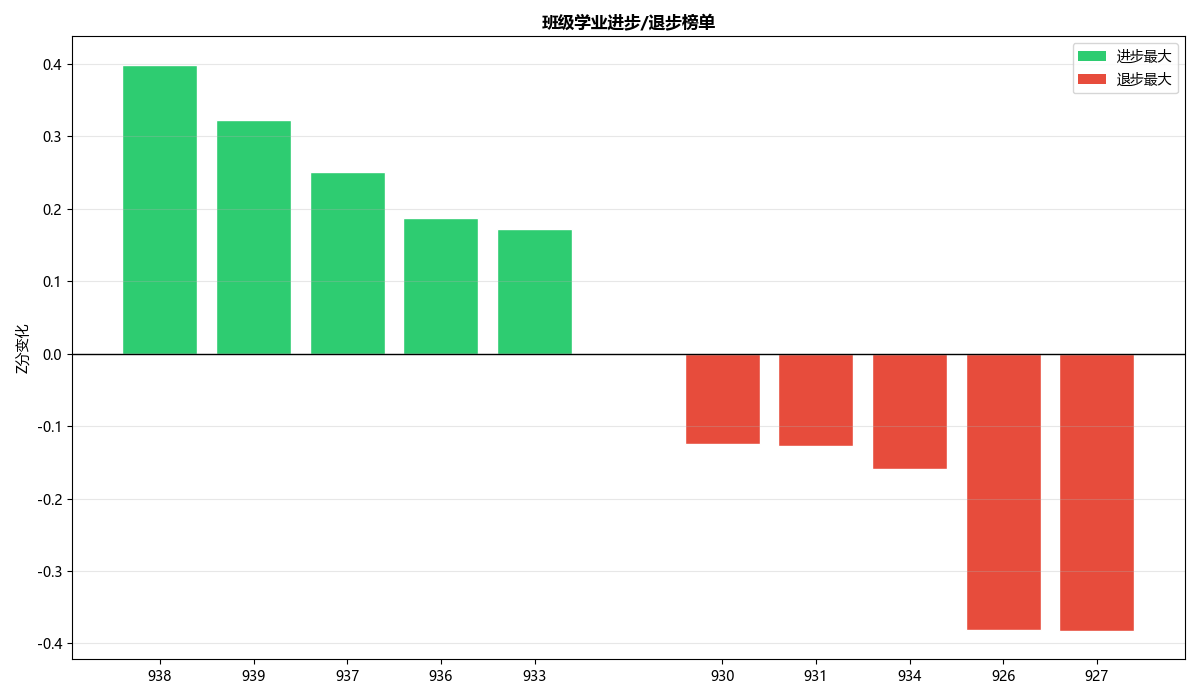
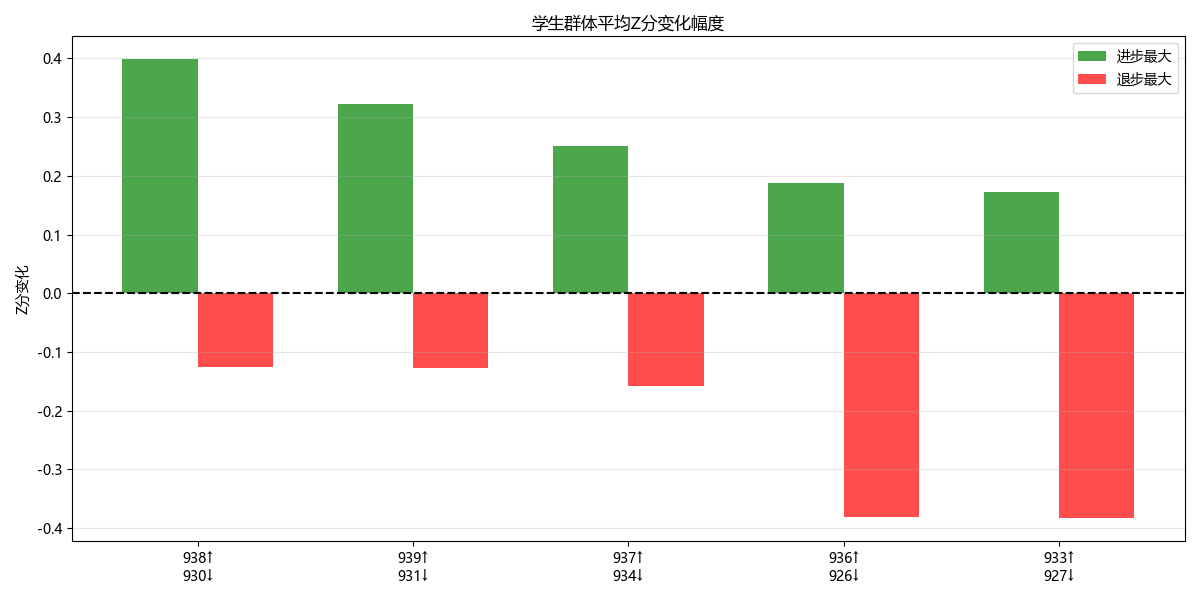
进步退步榜单:计算每个班级首末学期的Z分变化值,排出进步最大和退步最大的各5个班,用双向柱状图对比。
深入分析模块还包括五个专项:
- 模块A:班级学科优劣势——每班最强和最弱学科,导出CSV;
- 模块B:班级内部学业分化——标准差、四分位距、气泡散点图;
- 模块C:违纪时段趋势——各类型违纪人均次数的学期变化折线图;
- 模块D和E:教师成效和成绩波动性。
2.5 班级学风面板:班主任的一站式工作台
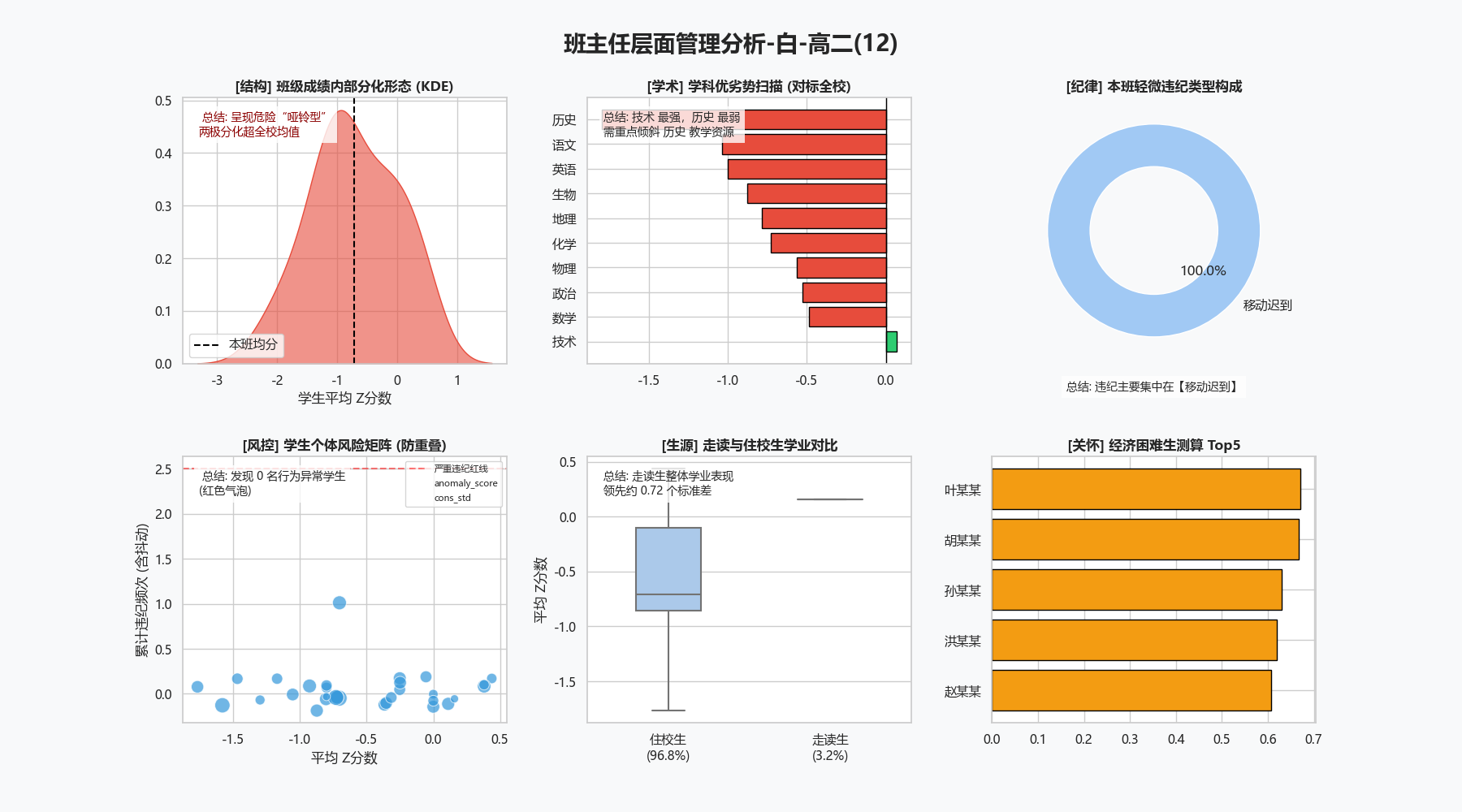
为了让数据分析有实际意义,我还为不同层级的校园管理者设计了不同面板分析,这里以为班主任设计的交互式班级仪表盘为例分析一下,页面会呈现八个模块的诊断报告。整个布局经过两次迭代优化,最终版如下:
| 模块 | 位置 | 内容 | 用途 |
|---|---|---|---|
| 顶部信息栏 | 顶端横条 | 班级名称+六项关键指标一行展示 | 一目了然的核心数据 |
| 六维雷达图 | 左上 | 平均Z分、优秀率、均衡度、低不及格、低违纪、师资稳定vs全校均值 | 快速识别优劣势维度 |
| 综合得分卡 | 中上 | 综合得分、等级(A~D)、校内排名 | 总体定位 |
| 智能建议条 | 右上角横条 | 基于阈值规则自动生成2-3条建议 | 给出具体行动方向 |
| 违纪类型饼图 | 右中 | 六类违纪占比,仅显示有数据的类型 | 定位违纪的主要来源 |
| 学科Z分条形图 | 左下 | 各学科平均Z分横向柱状图,红绿分色 | 发现最强和最弱学科 |
| 历史学业趋势 | 中下 | 近三学期班级均分折线图,标注变化量 | 判断走势是进步还是下滑 |
| 核心指标对比 | 右下 | 六个指标班级值vs全校均值并排条形图 | 直观对比差距 |
# 智能建议的生成逻辑——根据阈值逐条判断
if class_data['avg_z'] < 0:
advices.append('学业低于均值,加强薄弱学科辅导')
if class_data['fail_rate'] > 0.5:
advices.append('不及格率偏高,需关注学困生')
if balance < 0.5:
advices.append('班内分化较大,建议分层教学')
这个面板的核心价值在于:所有图表和数据都是实时从面板中提取的,不需要班主任手动做任何图,各年级负责人可交互查看,管理效率大幅提升。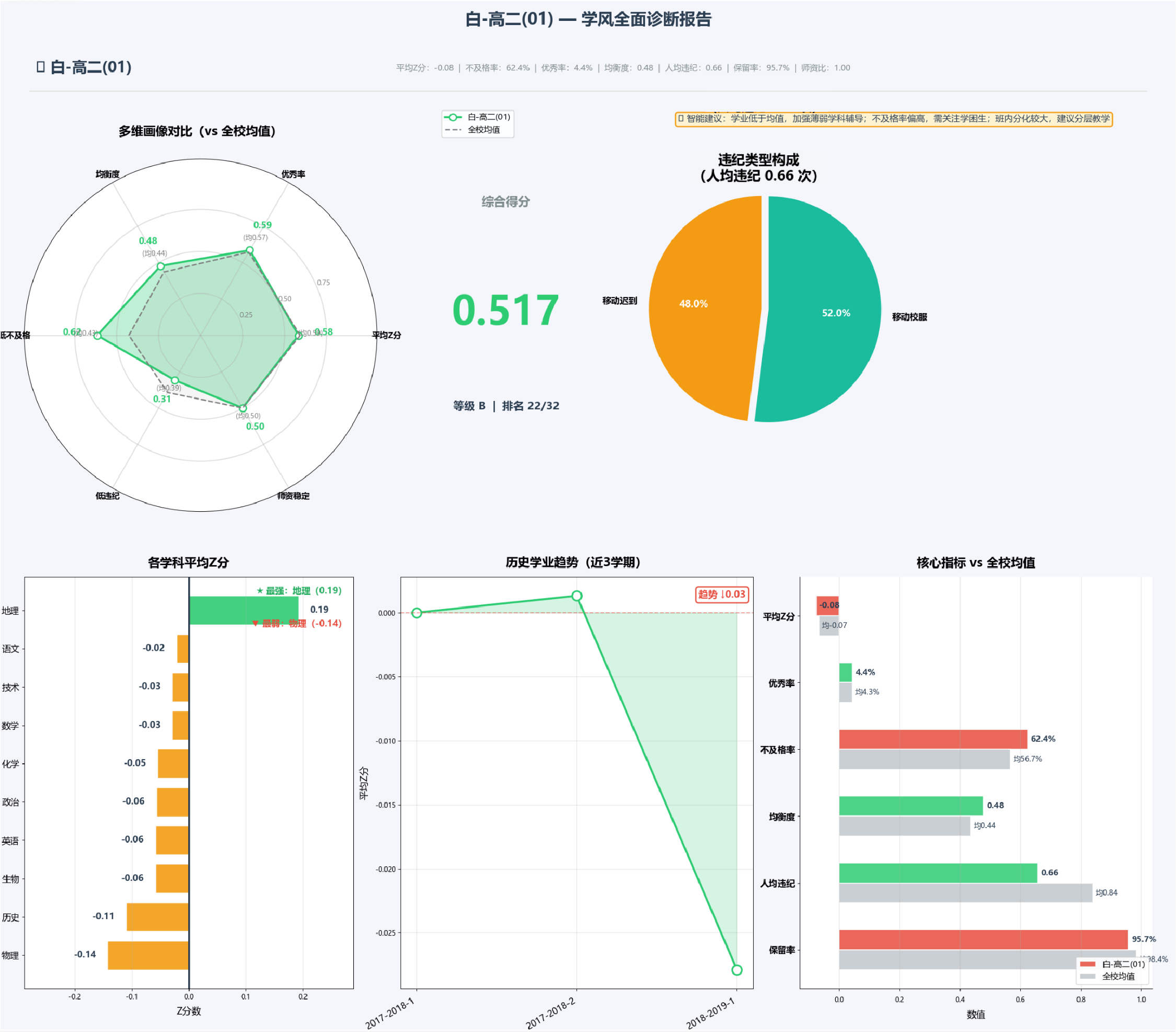
三、分析结果:数据告诉了我们什么
完成上述分析流程后,我们从班级面板中得到了几个值得关注的结果。
3.1 班级分化:两个典型形态
校内班级的成绩分布大致呈现两种形态:
“橄榄型”班级:大部分学生的Z分集中在均值附近,标准差小。这种班级整体稳定,任课教师按统一进度上课即可,但优秀率和不及格率都偏低,存在“中间大、两头小”的问题。
“哑铃型”班级:学生成绩高度分化,Z分标准差超过1.3(全校均值约0.8),两头重、中间空。典型代表是912班,平均Z分为-0.71,内部标准差却高达1.31。这种班级的统一教学难度最大——进度快了,尾部学生跟不上;进度慢了,头部学生吃不饱。气泡散点图上,这类班级显眼地落在右侧区域。
学科诊断模块进一步印证了分化现象。部分班级的单科极差超过2.5个标准差,如某班英语Z分+0.8、地理-1.7。这种情况如果长期存在,容易导致学生群体性地回避弱势学科,形成“越不学越差、越差越不学”的循环。
3.2 违纪与疲劳:高压管理的隐性代价
违纪扩散率(参与违纪的学生比例)与学业均分之间存在一种值得注意的关系。数据显示,有几个违纪扩散率超过0.65的班级,学业均分仍然维持在正值。这提示了一个可能的问题:这些班级的成绩是依靠压缩学生休息时间、加大作业量等“疲劳战术”维持的。学生长期处于疲劳状态,次日出现大面积迟到或早退,违纪数据的升高其实是身体和心理发出的抗议信号。
相比之下,另一些违纪扩散率高且学业均分为负的班级,属于“双困型”——纪律和学业同时出现问题,往往需要从班风建设最基础的环节开始整顿。
3.3 纵向追踪:进步和退步都有迹可循
通过纵向趋势分析,我们计算了每个班级当前学生群体的历史Z分变化。进步最大的班级在三个学期内平均Z分提升了0.5以上,而退步最显著的班级则从正值降至-0.8左右。将这些班级列入进步和退步榜单后,教务处可以针对性地研究进步班级的教学管理经验,同时对退步班级启动专项诊断——比如查看其师资稳定性是否偏低、违纪趋势是否在上升、是否存在学科极差异常。
3.4 面板诊断示例
以912班为例,系统生成的班主任面板显示:
- 均衡度得分仅0.35(满分1),雷达图上这一维度明显凹陷,说明内部学业分化严重;
- 违纪构成中,“校服违规”和“移动迟到”占比超过60%,可能指向经济条件或作息管理问题,而非单纯的态度松散;
- 历史学业趋势显示近两学期持续下滑,与违纪扩散率的上升几乎同步;
- 智能建议模块自动生成三条提示:“班内分化较大,建议分层教学”“违纪高于中位数,加强纪律管理”“近3学期成绩下滑,建议启动专项诊断”。
这些信息汇总到一个页面上,班主任不需要翻阅多张报表,就能对班级的整体状况和各维度细节有一个完整的把握。
四、三个层面的分析维度和侧重点
分析结果最终要服务于不同层级的管理者。校长关注的是资源配置和整体趋势,年级组长需要统筹年级内部的均衡性,班主任则聚焦于自己班级的具体问题。三个层面的分析维度和侧重点有明显差异。
4.1 宏观层面:校长与教务处的资源配置罗盘
宏观层面的分析围绕“结构”和“趋势”两个关键词展开,目的是帮助学校决策者看清全校的学风格局,发现系统性偏差。
| 分析维度 | 核心指标 | 侧重点 |
|---|---|---|
| 校区均衡 | 校区平均Z分、违纪扩散率对比 | 识别校区间的系统性差距,判断是否需要调整骨干师资分布或统一德育管理标尺 |
| 学风生态 | 四大群落(标杆/稳健/内耗/破窗)的班级数量与占比 | 判断学校处于整体向好还是风险蔓延阶段,决定是否启动学风重塑专项 |
| 违纪趋势 | 各类型违纪人均次数的多学期变化 | 判断哪种违纪在加速扩散,评估现有惩戒措施是否有效 |
| 师资效能 | VAM教师增值排名 | 打破排课惯性,将真正能提升学生成绩的教师靶向输送到薄弱班级 |
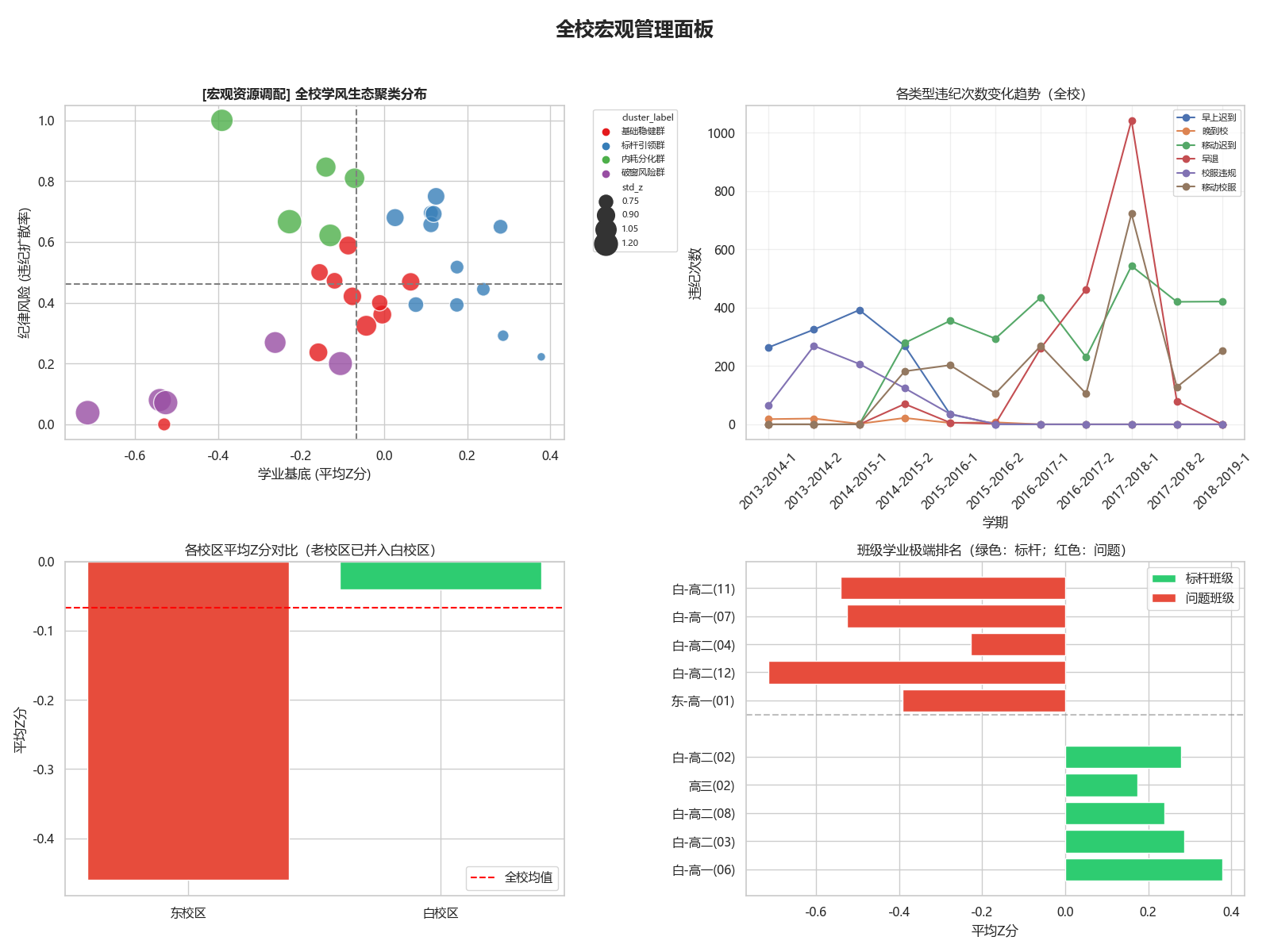
宏观层面不看单个班级的平均分,而是看结构——哪个群落在扩大?哪个校区在掉队?哪类违纪正以什么速度蔓延?这些问题的答案直接关系到校级资源的调配决策。
4.2 中观层面:年级组长的过程管控清单
年级组长承担着协调和统筹的职责,分析侧重点在于发现年级内部的“短板”和“洼地”,并进行精准补位。
| 分析维度 | 核心指标 | 侧重点 |
|---|---|---|
| 学科木桶 | 各班学科极差、年级内弱势学科集中度 | 识别群体性偏科现象,协调晚自习时间和学科攻坚计划 |
| 师资公平性 | 班级平均VAM、师资稳定性指数 | 发现师资洼地班级(处于年级后20%),安排教研组驻班帮扶 |
| 疲劳度监测 | 违纪扩散率与学业均分的交叉分析 | 区分“高压低效型”和“双困型”班级,前者减负增效,后者先抓习惯再提成绩 |
| 隐性流失 | 退学/休学人数按班级分布 | 即便只有三五人,也需要排查是否存在校园欺凌、家庭经济困难或心理危机 |
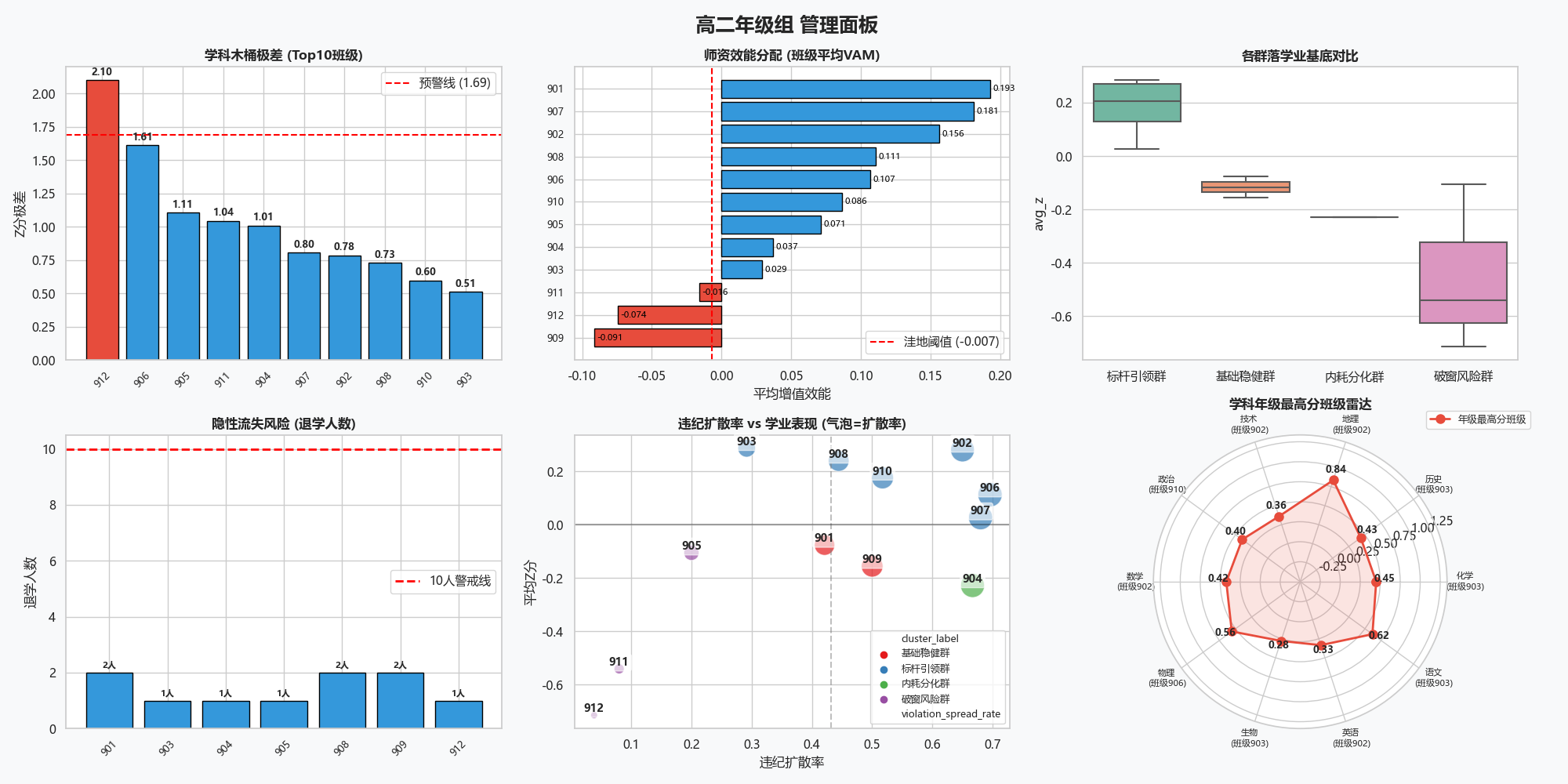
中观层面的逻辑是从“管纪律”转向“调结构”——调学科短板、调师资搭配、调作业总量。年级组拿到诊断报告后,可以有针对性地发起学科联席会、作业负担调查或心理普测。
4.3 微观层面:班主任的个体诊断工具
班主任面对的是具体的学生和每天的事务,分析侧重在于快速了解班级整体画像,并精准定位需要关注的学生。
| 分析维度 | 核心指标 | 侧重点 |
|---|---|---|
| 结构画像 | 成绩KDE分布形态、学科雷达图 | 一眼判断班级是“橄榄型”还是“哑铃型”,决定是否需要分层教学 |
| 纪律归因 | 违纪类型构成、违纪学生重复率 | 区分纪律问题的性质——是普遍松散还是个别学生频繁违规,或是客观困难导致 |
| 趋势预警 | 近三学期班级均分变化、违纪扩散率变化 | 判断班级在走上坡路还是下坡路,趋势比绝对值更有参考价值 |
| 个体关注 | 成绩波动大、持续垫底、行为异常等特殊学生 | 从智能建议中获取提示,将精力聚焦到最需要帮扶的学生身上 |
微观层面的核心价值在于“看见每一个人”。不是泛泛地说“要加强管理”,而是指出“某学科是短板”“某几个学生成绩波动剧烈”“违纪主要集中在早上迟到”——这些具体的指向让班主任的工作有了明确的抓手。
五、进一步可视化扩展
为了更好的展现整体数据可视化,我们还借助助睿数智平台,对数据进行了整体的梳理与处理,并借助助睿BI实现了可交互的仪表盘,主要流程如下:
在助睿BI中,创建数据源连接,配置好自己的数据库
然后新建数据集,选择需要展示的表
然后在工作表模块新建分组,并创建相应工作表,通过选择图表类型,拖拽相应维度数据即可
最后新建仪表盘,将前面的工作表拖拽并调整相应位置即可。
最终完成的仪表盘如下: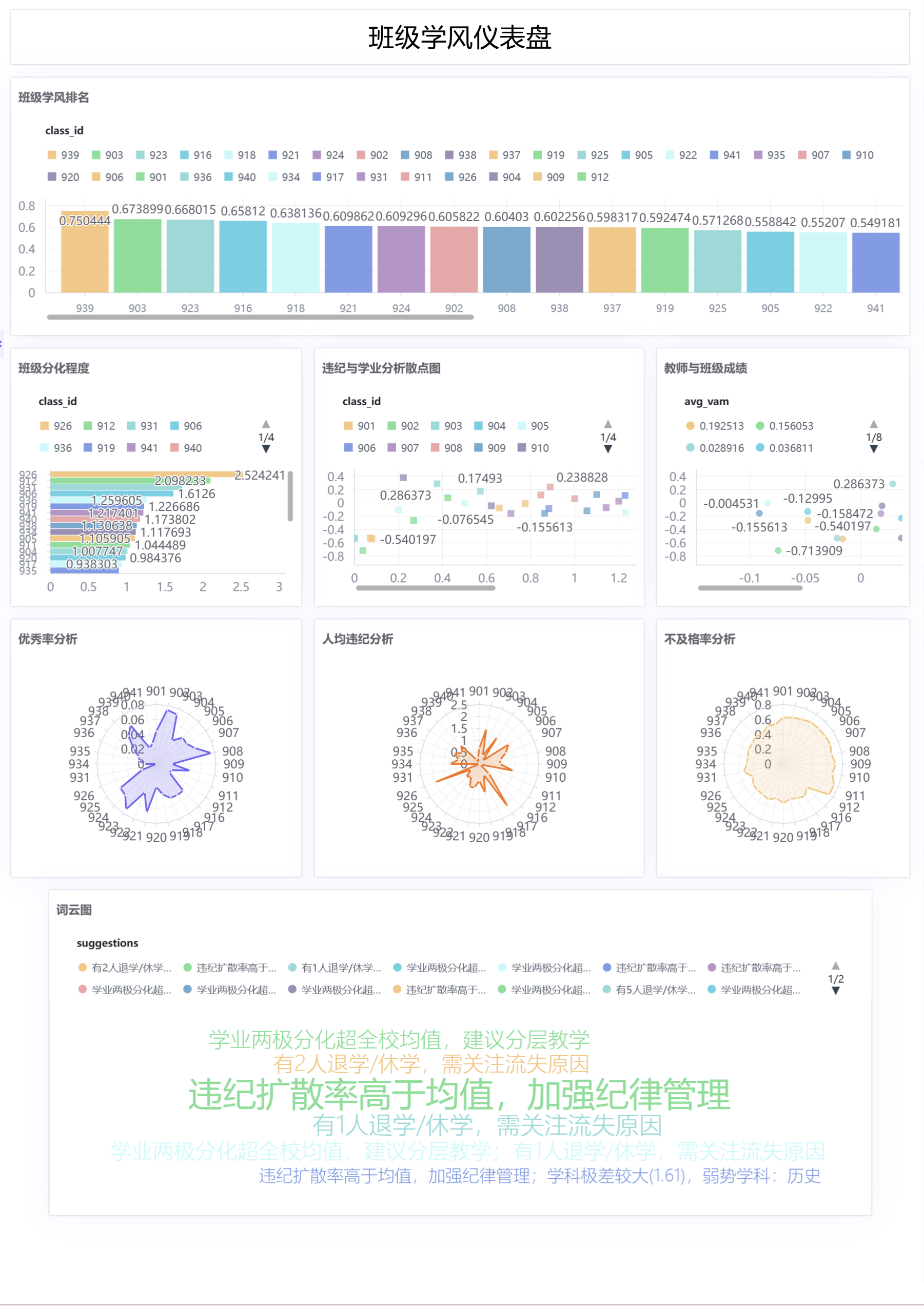
六、结语与展望
这套分析系统的搭建过程并不复杂,核心工作在于三个方面:梳理数据关联(建立成绩与班级的映射)、定义指标权重(13维加权矩阵的设计)、封装可视化函数(从一次性绘图到可复用的仪表盘模板)。但它带来的管理变化是实实在在的:从“凭感觉说某个班最近风气不行”到“用数据指出违纪扩散率连续两学期上升”,从“只说成绩退步了”到“定位到某学科极差过大,建议补弱”,管理决策的依据更加清晰。
目前系统仍有扩展空间。下一步可以尝试的方向包括:将孤立森林算法识别出的行为异常学生直接嵌入班级面板的预警名单;融合学生消费数据,更早发现经济困难带来的隐性影响;将分析周期缩短到月考甚至周测,实现更及时的动态跟踪。这些都需要在数据权限和隐私保护的框架下审慎推进。
教育数据挖掘的最终目的,不是排名和考核,而是让管理者看见那些容易被忽视的问题,并给出有依据、有针对性的应对措施。希望这篇分享能为有类似需求的同行提供一些可参考的思路。
如果对你有帮助的话请点赞收藏关注,后续我也会继续分享商业数据分析的相关学习经验心得
^ - ^

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)