使用ClaudeCode用时5分钟写完你一天的java代码
1.安装
参考上面链接
2.搜索火山引擎,配置coding plan
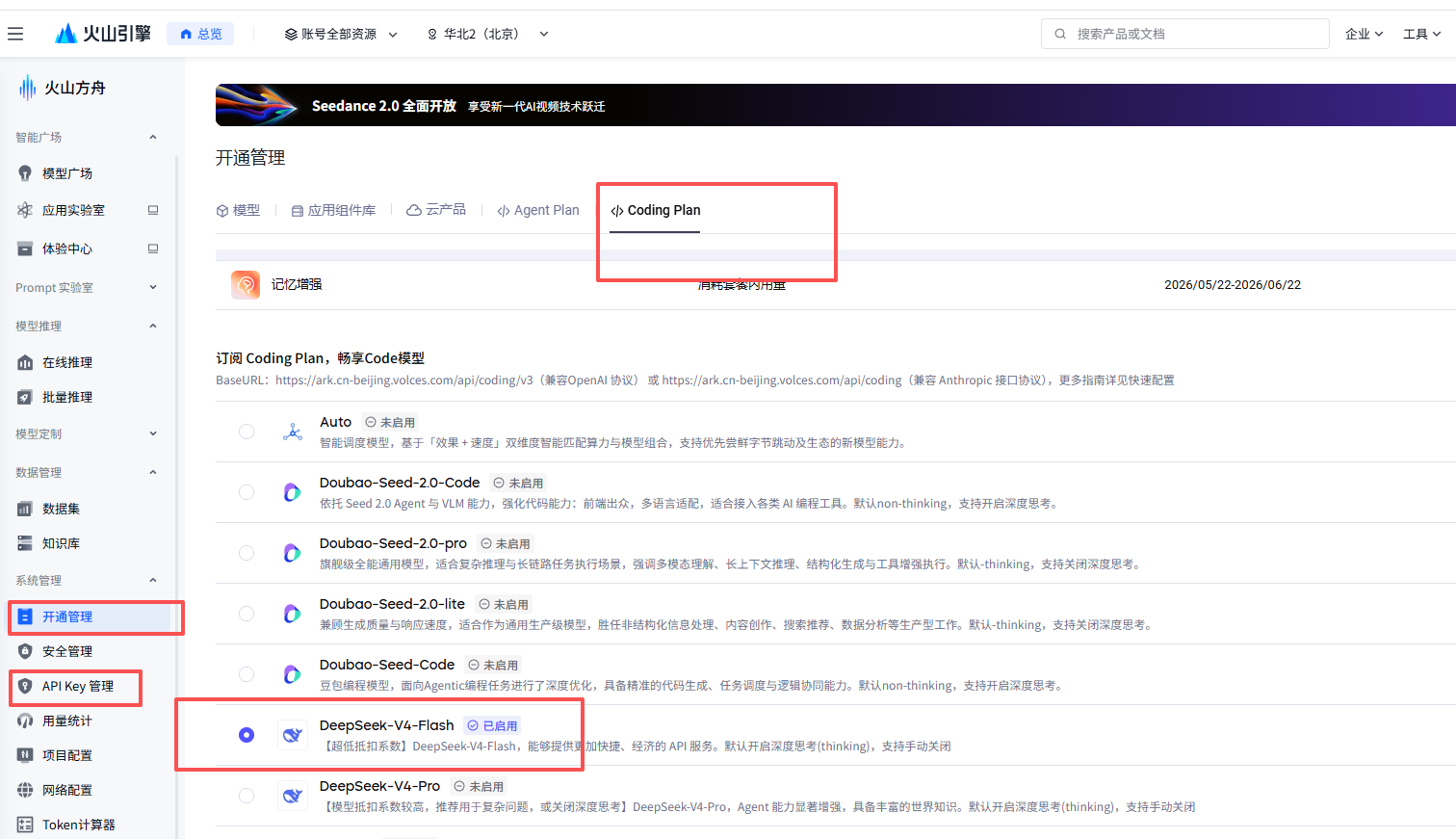
3.claude code配置模型
我用模型: DeepSeek-V4-Flash 给你们测试
找到你的claudecode 配置路径,一般都在c盘下面
C:\Users\sunsi_mhi3ibb.claude
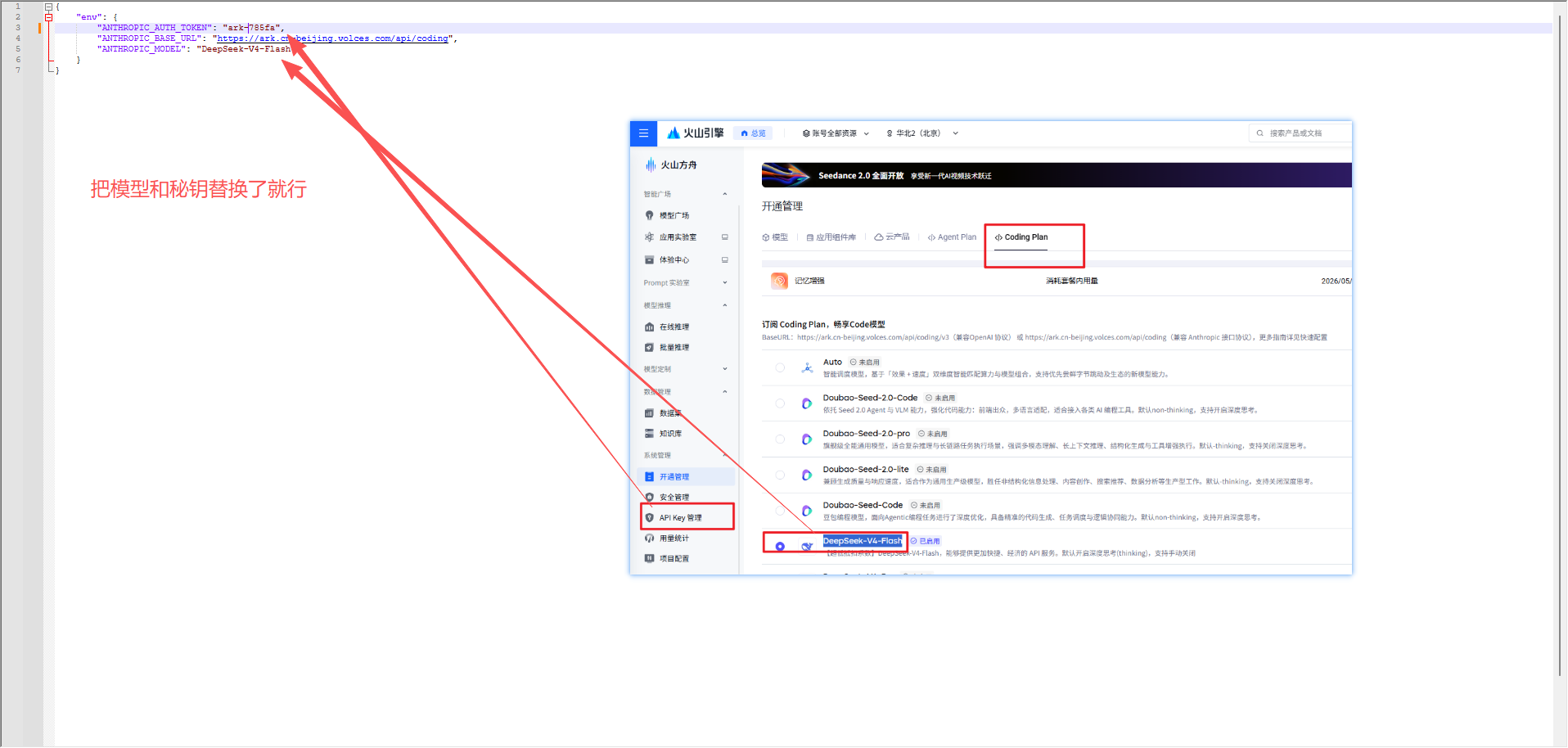
{
"env": {
"ANTHROPIC_AUTH_TOKEN": "ark-785fa",
"ANTHROPIC_BASE_URL": "https://ark.cn-beijing.volces.com/api/coding",
"ANTHROPIC_MODEL": "DeepSeek-V4-Flash"
}
}
4.在idea里面运行claudeCode
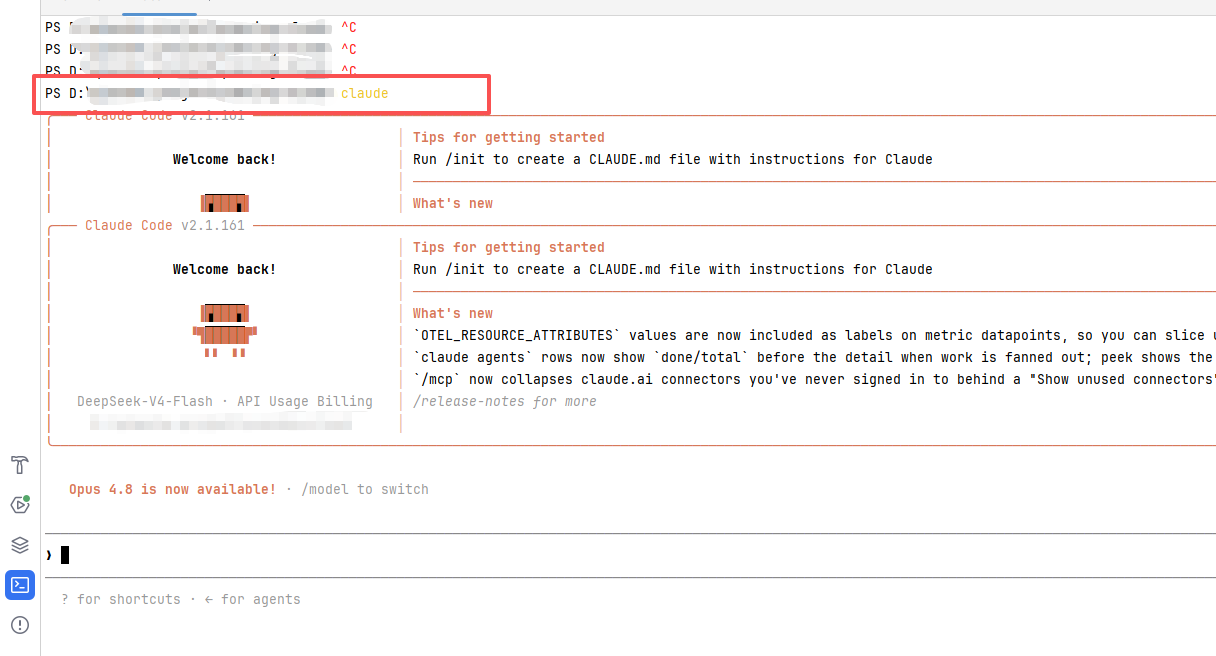
比如分析功能代码
开始分析了:
一直在消耗你的token

流程图设计
flowchart TD
A[开始: fixedSalaryCalculate
dto: customerId, billDate] --> B[格式化 billDate 为 yyyy-MM-dd]
B --> C[Redis Pending 去重
trySet pendingKey TTL=2min]
C -- 已存在 --> D[设置 retrigger 标记 TTL=5min<br/>ACK 跳过, return]
C -- 成功获取 --> E{循环开始}
E --> F[checkAllCustomersFinished]
F -- 未完成 --> G[shouldReleasePending=false<br/>保留 pending 标记<br/>等待 TTL 过期后触发]
F -- 全部完成 --> H[获取分布式锁<br/>tryLock 30s]
H -- 锁失败 --> I[抛 ServiceException<br/>进入异常处理]
H -- 获取成功 --> J[executeCalculation]
J --> J1[selectGlobalFixedSalaryData<br/>全局聚合: 总业绩, 总出库单量]
J1 -- 单量为0或业绩为0 --> J2[返回 null<br/>无需计算]
J1 -- 有数据 --> J3[全局固薪总额 = 总单量 × 0.5元]
J3 --> J4[selectGroupedFixedSalaryData<br/>按货主+仓库分组查询]
J4 --> J5[Java 内存计算<br/>货主固薪 = 货主业绩÷全局业绩×全局固薪总额<br/>单价固薪 = 货主固薪÷货主单量]
J5 --> J6[多线程并行批量更新<br/>keyset pagination, 每批2000条]
J6 --> J7[返回计算结果字符串]
J --> K{计算是否成功?}
K -- 成功 --> L{检查 retrigger 标记<br/>是否存在并删除?}
K -- 异常 --> M[retryCount++<br/>设置 retrigger 标记<br/>发送钉钉告警]
M --> N{retryCount > MAX_RETRY?}
N -- 否 --> O[取 RETRY_DELAY 等待<br/>2min/5min/10min<br/>重新循环]
N -- 是 --> P[保留 retrigger<br/>等待 MQ 重新投递<br/>跳出循环]
L -- 有 retrigger --> O
L -- 无 retrigger --> Q[正常结束, 跳出循环]
O --> E
P --> R
Q --> R[finally 块]
G --> R
R -- shouldReleasePending=true --> S[删除 pending 标记]
R -- shouldReleasePending=false --> T[保留 pending 标记<br/>等待TTL过期]
核心流程步骤
┌──────┬────────────────┬─────────────────────────────────────────────────────────┐
│ 步骤 │ 名称 │ 关键机制 │
├──────┼────────────────┼─────────────────────────────────────────────────────────┤
│ ① │ Pending 去重 │ Redis trySet + TTL 2min,同一账期只允许一个消息进入 │
├──────┼────────────────┼─────────────────────────────────────────────────────────┤
│ ② │ Retrigger 兜底 │ 计算中收到新消息则设 retrigger 标记,计算完成后重新执行 │
├──────┼────────────────┼─────────────────────────────────────────────────────────┤
│ ③ │ 等待货主完成 │ 查询有报价的活跃货主,检查所有账单是否 FINISHED │
├──────┼────────────────┼─────────────────────────────────────────────────────────┤
│ ④ │ 分布式锁 │ Redisson tryLock(30s),防止多实例并发计算 │
├──────┼────────────────┼─────────────────────────────────────────────────────────┤
│ ⑤ │ 全局聚合查询 │ 查询当天所有货主的总业绩和总出库单量 │
├──────┼────────────────┼─────────────────────────────────────────────────────────┤
│ ⑥ │ 内存分摊计算 │ 货主固薪 = 货主业绩 / 全局业绩 × 全局固薪总额 │
├──────┼────────────────┼─────────────────────────────────────────────────────────┤
│ ⑦ │ 并行批量更新 │ keyset pagination(每批2000条),货主间多线程并行 │
├──────┼────────────────┼─────────────────────────────────────────────────────────┤
│ ⑧ │ 异常重试 │ 最多3次,间隔 2min → 5min → 10min │
├──────┼────────────────┼─────────────────────────────────────────────────────────┤
│ ⑨ │ 收尾清理 │ 正常结束删 pending;异常保留 pending 等待 TTL 过期 │
└──────┴────────────────┴─────────────────────────────────────────────────────────┘
优化建议
- 🐛 潜在 Bug:checkAllCustomersFinished 中无账单货主被跳过
问题位置: checkAllCustomersFinished 第261-264行
if (header == null) {
continue; // 货主无账单直接跳过
}
如果一个有效货主在该账期尚未生成任何账单(bill_task_header 表中无记录),该方法会将其视为"已完成"直接跳过。如果此时其他货主已完成,则计算会提前触发,导致该货主的固薪数据缺失。
建议:
- 确认业务场景:如果"无账单"意味着该货主当天无出库业务,则跳过合理
- 如果"无账单"可能意味着账单尚未生成,应改为 return false 等待其生成
- ⚠️ 重试计数器作用域问题
问题位置: 第118-191行
int retryCount = 0;
// …
// 第174行:needRetrigger 为 true 但 retryCount == 0(未抛异常)
if (retryCount > MAX_RETRY_COUNT) { … } // 不会触发
retryCount 仅在 catch 块中递增。如果计算成功执行但外部并发设置了 retrigger 标记,retryCount 保持为0,此时理论上会无限循环(虽然实际概率低,因为 retrigger 需要外部 MQ 重复投递)。
建议:
// 方案1:在 retrigger 分支也递增一个计数器
int loopCount = 0;
// 在 needRetrigger 分支
loopCount++;
if (loopCount > MAX_RETRY_COUNT) { break; }
- 🔒 锁超时时间可能过短
问题位置: 第140行
boolean isLocked = lock.tryLock(30, TimeUnit.SECONDS);
- 如果全局数据量大,executeCalculation 中的全局查询 + 分组查询 + 批量更新可能超过30秒
- 特别是 CompletableFuture.allOf().join() 等待所有货主更新完成,如果某个货主数据量大(keyset 分页循环),耗时可能较长
建议: 评估历史执行耗时,适当延长等待时间(如60秒),或改用 lock() 阻塞等待
- 🔄 CompletableFuture 缺少错误隔离
问题位置: 第332-343行
CompletableFuture future = CompletableFuture.runAsync(
() -> batchUpdateFixedSalary(…), billSummaryExecutor);
futures.add(future);
// …
CompletableFuture.allOf(futures.toArray(new CompletableFuture[0])).join();
如果某一个货主的批量更新抛出异常,整个 allOf().join() 都会抛异常,导致所有其他货主的更新结果也一同回滚(或至少被标记为失败)。
建议:
// 方案:每个 future 单独处理异常,记录失败的货主
List<CompletableFuture> futures = customerList.stream()
.filter(item -> item.getSingleFixedSalary() != null)
.map(item -> CompletableFuture.supplyAsync(() -> {
try {
batchUpdateFixedSalary(billDate, item.getCustomerId(), item.getWarehouseId(), item.getSingleFixedSalary());
return null; // 成功
} catch (Exception e) {
log.error(“货主{}仓库{}更新失败”, item.getCustomerId(), item.getWarehouseId(), e);
return item.getCustomerId() + “-” + item.getWarehouseId(); // 返回失败标识
}
}, billSummaryExecutor))
.toList();
List failures = futures.stream()
.map(CompletableFuture::join)
.filter(Objects::nonNull)
.toList();
if (!failures.isEmpty()) {
log.error(“以下货主更新失败: {}”, failures);
throw new ServiceException("部分货主固薪更新失败: " + failures);
}
- 🚦 Pending TTL 与重试等待不协调
问题位置: PENDING_TTL_SECONDS = 120秒,但重试等待最长10分钟
当第3次重试等待10分钟时,pending key 的 TTL 早已过期(2分钟)。此时如果有新消息进来,会同时启动另一个计算实例(双重计算),虽然分布式锁提供了兜底保护,但会造成资源浪费。
建议:
// 在重试前刷新 pending TTL
pendingBucket.expire(PENDING_TTL_SECONDS, TimeUnit.SECONDS);
或者在重试等待期间不释放 pending(目前 finally 中会删除),但确保 pending 的 TTL 足够覆盖整个重试周期。
- 📊 大数据量内存风险
selectGlobalFixedSalaryData 和 selectGroupedFixedSalaryData 会查询该账期所有数据到内存。如果货主数量多或数据量大,customerList 可能占用大量内存。
建议:
- 评估 customerList 的大小,确认在可接受范围内
- 或对分组查询加分页/限流机制
- 🔍 customerId 字段未用于业务逻辑
问题位置: DTO 中的 customerId 仅用于日志
B2cFixedSalaryCalculateDto 中的 customerId 只在日志中打印,不参与任何业务过滤或计算逻辑。说明该字段可能是个冗余参数,或者设计上应该按货主维度触发但实际未实现。
建议: 确认是否应该按货主粒度过滤,或者移除该字段避免误导
- 📋 钉钉告警信息中堆栈信息过大
问题位置: 第164-165行
String message = “B2C账期” + billDateStr + “固薪计算异常=” + e;
SendDingdingMessageUtils.sendTextMessageAtAll(DingdingWebHookUrlEnum.TESTYWP, message);
e.toString() 可能包含完整堆栈,钉钉消息长度有限,可能会截断或发送失败。
建议: 只发送异常摘要信息,详细堆栈记录在日志中
总体评价
该实现整体质量较高,体现了以下优秀设计:
┌──────────────────────┬──────────────────────────────────────────┐
│ 设计点 │ 说明 │
├──────────────────────┼──────────────────────────────────────────┤
│ ✅ Redis 去重 │ 基于 trySet 的 pending 机制防止重复触发 │
├──────────────────────┼──────────────────────────────────────────┤
│ ✅ Retrigger 兜底 │ 计算中收到新消息自动重新计算 │
├──────────────────────┼──────────────────────────────────────────┤
┌──────────────────────┬──────────────────────────────────────────┐
│ 设计点 │ 说明 │
├──────────────────────┼──────────────────────────────────────────┤
│ ✅ Redis 去重 │ 基于 trySet 的 pending 机制防止重复触发 │
├──────────────────────┼──────────────────────────────────────────┤
│ ✅ Retrigger 兜底 │ 计算中收到新消息自动重新计算 │
├──────────────────────┼──────────────────────────────────────────┤
│ ✅ 分布式锁 │ 多实例环境下的最终一致性保障 │
├──────────────────────┼──────────────────────────────────────────┤
│ ✅ Keyset Pagination │ 避免 OFFSET 性能衰减,适合大表 │
├──────────────────────┼──────────────────────────────────────────┤
│ ✅ 货主间并行 │ 各货主独立线程更新,提升吞吐 │
├──────────────────────┼──────────────────────────────────────────┤
│ ✅ 异常重试 │ 指数递增等待,避免雪崩 │
├──────────────────────┼──────────────────────────────────────────┤
│ ✅ 多阶段等待 │ 等待所有货主完成后再计算,保证数据完整性 │
└──────────────────────┴──────────────────────────────────────────┘
主要风险集中在 无账单货主的跳过逻辑(#1)和 并行更新的错误隔离(#4),建议优先评估这两个场景是否在你的业务中会发生。
其实AI分析的已经非常到位了,大家平时可以多试试ai的各种场景,确实可以 事半功倍

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)