计算机毕业设计之基于LDA模型的电影票房的情感分析系统的设计与实现
本研究设计并实现了一个基于LDA模型的电影票房情感分析系统。该系统通过爬取互联网上的电影评论数据,利用LDA模型进行主题建模和情感分析,旨在揭示观众情感倾向与电影票房之间的关系。系统首先对原始数据进行预处理,包括分词、去除停用词等,然后通过LDA模型识别出评论中的潜在主题,并结合情感词典和机器学习算法对每个主题下的关键词进行情感打分,从而判断整个文本的情感倾向。此外,系统还实现了数据可视化面板,展示了年度统计、地区统计、电影总数、评分人数统计、评论统计以及评分统计等多个功能模块,为用户提供了全面的数据分析视角。
摘要: 系统的设计与实现过程中,注重了技术可行性、经济合理性和法律合规性,确保了系统的稳定运行和有效应用。技术层面上,LDA模型作为成熟的自然语言处理技术,为系统提供了坚实的分析基础;经济层面上,系统的开发和使用成本控制在合理范围内,具有较高的性价比;法律层面上,系统严格遵守数据隐私保护法规,确保了数据的合法使用。通过实证分析,该系统在电影票房情感分析方面表现出较高的准确性和实用性,为电影行业的相关人员提供了有价值的决策支持,推动了自然语言处理技术在电影领域的应用和发展。
系统使用收集年份统计,地区统计,豆瓣电影信息,评论统计,评分人数统计,评分统计等豆瓣的公开数据集,来构建电影票房的数据分析。用户可以通过查询条件的方式,让系统实现对相关数据的筛选和查询,并将查询结果在前端以图表的可视化方式展示出来,进而帮助用户理解数据。系统通过对用户数据的分析与挖掘,实现了对于用户评论的解析和分类,系统提供了直观的豆瓣电影票房数据展示界面,查看到相应的分析结果。
数据采集功能实现对豆瓣平台公共数据的采集,识别数据来源、区分数据类型,并进行数据完整性的验证,确保数据的准确性以及可靠性。分布式存储功能实现对已经处理过的数据进行分布式存储,采用MySQL、HDFS进行对数据的存储,以及支持异构端存储和具备高容错性,高可用性以及易扩展性。数据分析功能基于Spark分布式计算框架,实现对存储的数据进行了数据分析和挖掘。
数据可视化功能使用ECharts、Vue、BootStrap等前端技术,对数据分析结果进行了可视化展示,以图表等可视化方式将数据展示,方便了用户分析和观察。系统功能模块图如图3-1所示。
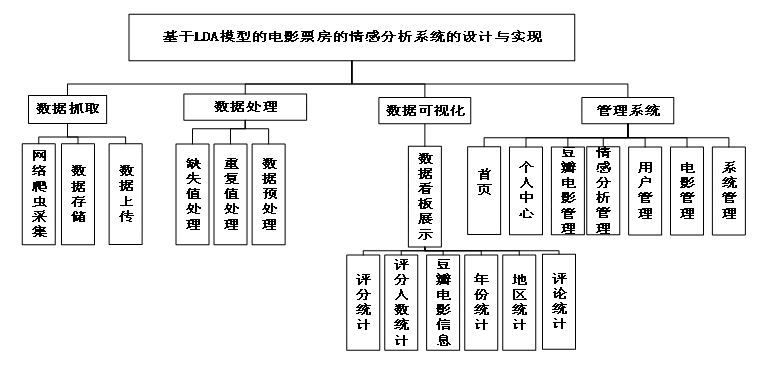
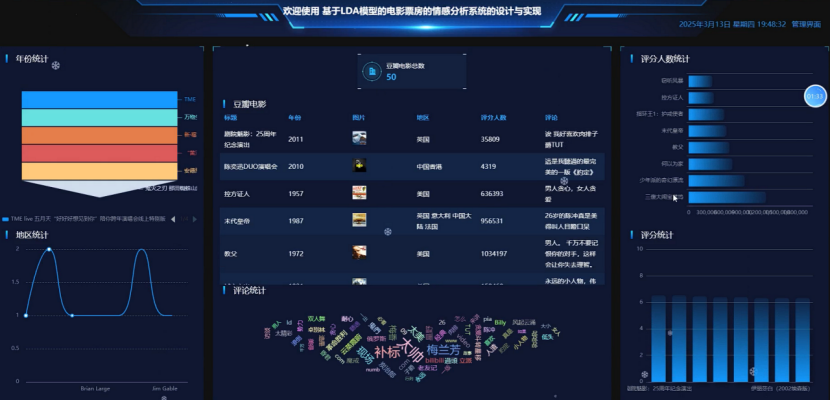
在数据可视化面板界面可以查看到所有数据的详情。数据看板集成了多个功能模块,为用户提供直观的数据展示和分析能力。数据可视化模块的实现依赖于多种技术的协同工作,使用Python编写的爬虫程序负责从豆瓣网站上抓取海量电影票房和评论数据,将这些非结构化数据导入到Hadoop分布式文件系统中进行存储和管理,利用Spark框架对这些大规模数据进行快速的计算和分析,将处理后的结果存入MySQL数据库中以方便后续查询和检索,后端采用Django框架搭建Web应用服务器,前端则使用Vue.js库来创建交互式界面,并通过Echarts图表库绘制各种可视化图形。
该数据可视化面板实现了多个功能模块,包括年度统计、地区统计、豆瓣电影总数、评分人数统计、评论统计以及评分统计。年度统计模块展示了不同年份的电影数量分布,帮助用户了解电影市场的年度变化趋势。地区统计模块通过折线图的形式呈现了各地区电影数量的波动情况,有助于分析地域差异对电影市场的影响。豆瓣电影总数模块显示了当前数据库中收录的电影总数,为用户提供了一个整体的数量概览。评分人数统计模块按照不同的评分区间展示了参与评价的用户数量,反映了观众对不同电影的兴趣程度。评论统计模块收集并分析了用户对电影的评论内容,通过词云图的形式突出了高频词汇,揭示了观众关注的焦点话题。评分统计模块则以柱状图的方式展示了各分数段的分布情况,直观地展现了电影的整体口碑水平。这些功能模块共同构成了一个全面的数据分析平台,为电影行业的相关人员提供了决策支持。可视化效果图如下所示:

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 3
3 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)