Crun深度体验:多模态 API 转发站与中转平台,一站式多模态模型统一 API 接入与管理工具
这两年随着多模态大模型的井喷,无论是做独立开发、UI 设计还是电商海外投放,团队里每个人都要同时调度七八个大模型的图像和视频能力。但在实际的生产环境中,频繁充值各类大模型的 Plus 订阅会员或者单独去接不同供应商的底层 API,很快就会让团队陷入极大的被动。
首先是费用与资产用量黑洞:有些视频模型单次生成的成本极高,如果给团队每个人都配独立账号,月末的账单基本处于失控状态,完全无法看清每个具体项目的 Token 消耗明细。
其次是网络波动与延迟灾难:国内直连不同海外供应商的 API 时,常常会遇到高达数秒的延迟,或者因为偶发的并发限制直接导致整个交付链路崩溃。
最后是适配器负担:每一个模型的 Request 封装、鉴权协议和异步 Webhook 回调风格都截然不同,技术团队每天都在写臃肿的 if-else 来兼容这些接口差异,系统熵值迅速爆炸。
在尝试过手搓本地代理和咸鱼代充等一系列极不稳定的临时方案后,我们决定将多模型看作“可调度的资源”,对市面上的头部中转和聚合方案进行了一次彻底的横向工程选型。
目录
一、 头部方案横评:OpenRouter vs 本地代理方案 vs 聚合基座
二、 Crun 核心功能实测体验
三、 为什么说 Crun 值得一试?
四、 适合哪些人使用?
五、 使用建议与注意事项
六、 总结
一、 头部方案横评:OpenRouter vs 本地代理方案 vs 聚合基座
在选型过程中,我们主要对比了以下几种主流路线:
- 头部竞品 OpenRouter:
优势:作为海外老牌聚合商,模型库非常全,经常有最新的免费测试模型。
劣势:在国内使用时网络延迟依然普遍大于 300ms,不支持国内本地化的便捷支付方式(如支付宝),企业团队进行统一采购和给员工分配 Token 额度、监控明细时后台极其简陋。 - 手搓本地代理方案:
优势:完全白嫖某些免费测试模型的 Token,适合个人 Demo 阶段试错。
劣势:模型供应商一旦更新字段或更新并发阈值,本地脚本就会大面积报错。由于缺少自带的队列和状态管理机,长链路的视频生成任务在生成到 99% 时由于网络波动丢失回调信号是常有的事,生产环境根本无法商用。 - 多模态一站式聚合基座(以 Crun 为代表):
优势:国内直连延迟明显优化,100% 兼容 OpenAI 协议。最核心的改变在于它引入了“标准任务(Task)编排”的概念,将长链路媒体文件的收敛、流控、重试和用量分析全部下沉到后台控制台。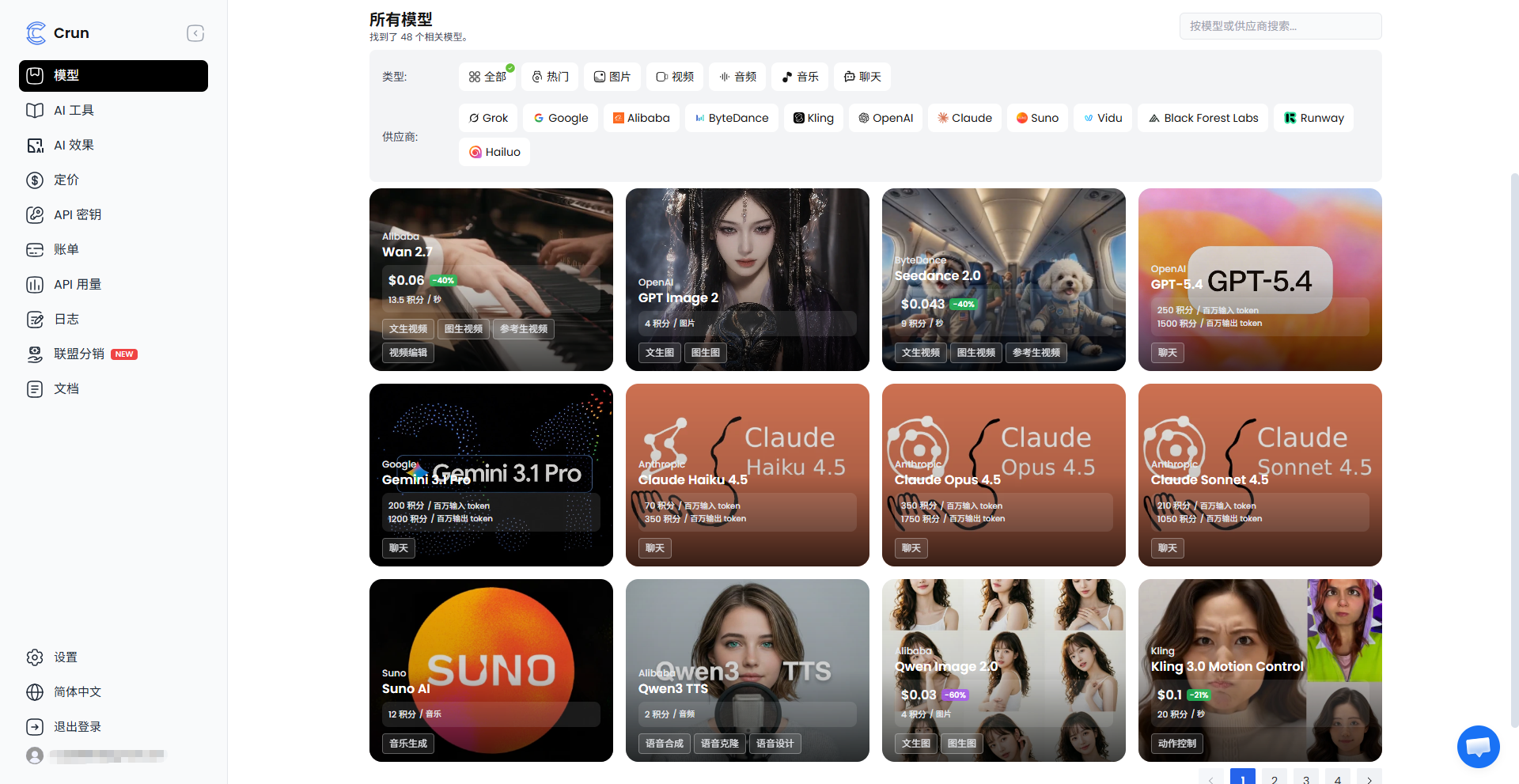
二、 Crun 核心功能实测体验
通过数周的压力测试,我们最终选择将团队的底层基础设施迁移到了 Crun 上。
它不是纯粹的接口转发,而是一个面向多模态(图像、视频、音频)开发和自动化物料处理的标准化终点站。
通过高度抽象的任务管理逻辑,将复杂的文本、图像、视频和音频生成模型统一收敛到唯一的标准化 Task 协议下,屏蔽了底层异构 API 的物理差异,帮助开发者将重复劳动从业务层彻底剥离,实现真正的基础设施透明化管理。
从工程实战的角度来看,它主要解决了我们系统架构上的三个顽疾:
- 打破“烟囱式”开发的复杂度爆炸
在以前的拼图模式下,每上线一个新卖点的跑量海报或短视频脚本,技术团队都要针对特定的供应商 SDK 从头去造一遍队列、日志和存储的轮子。而利用 Crun,它在业务系统与异构模型之间建立了一套恒定不变的任务结构。无论后台底座是剛发布的内测版还是稳定的商用版,前端业务只对接一个标准化的 Task API。 - 规避大文件回传的“媒体处理陷阱”
纯文本转向图像和视频开发时,最头疼的就是动辄几十兆的媒体文件交付。以往我们得自己写逻辑去下载模型的临时文件、转存到自己的云存储、再更新数据库。任何一个环节卡死,用户端就是冷冰冰的加载失败。Crun 自带后处理机制,能自动完成大文件的存储对接与回传,让重型基建完全透明化。 - 建立“模型供应链搭配”的自由可插拔能力
在商业生产中,没有哪个模型是全能的。做电商主图我们需要材质还原逼真的 Imagen 4;做视觉海报需要排版精准的 Flux Kontext;而做短视频投放,前 3 秒就需要运镜流畅、动作物理连贯的 Kling 3.0 或 Sora 2。Crun 把不同的模型变成了可随时替换的“插拔变量”。团队可以在统一后台进行小样本的横向赛马,一天之内横向测试几十个脚本在不同基础后端下的动态结果,筛选出最契合当前业务场景的组合,省去了漫无边际的盲目试错成本。
如下是对其核心工程特性进行的实战复盘:
-
统一的 Task 状态控制台与可观测性
传统的硬编码调用让每次 API 报错都散落在不同供应商的控制台里,排查起来像一片黑箱。Crun 将所有长长链路任务强行收拢为标准化的任务流。在它的控制台中,每一次请求、创建、执行状态和结果都会落成独立 task 记录,彻底把状态管理(Pending、Running、Success、Failed)透明化。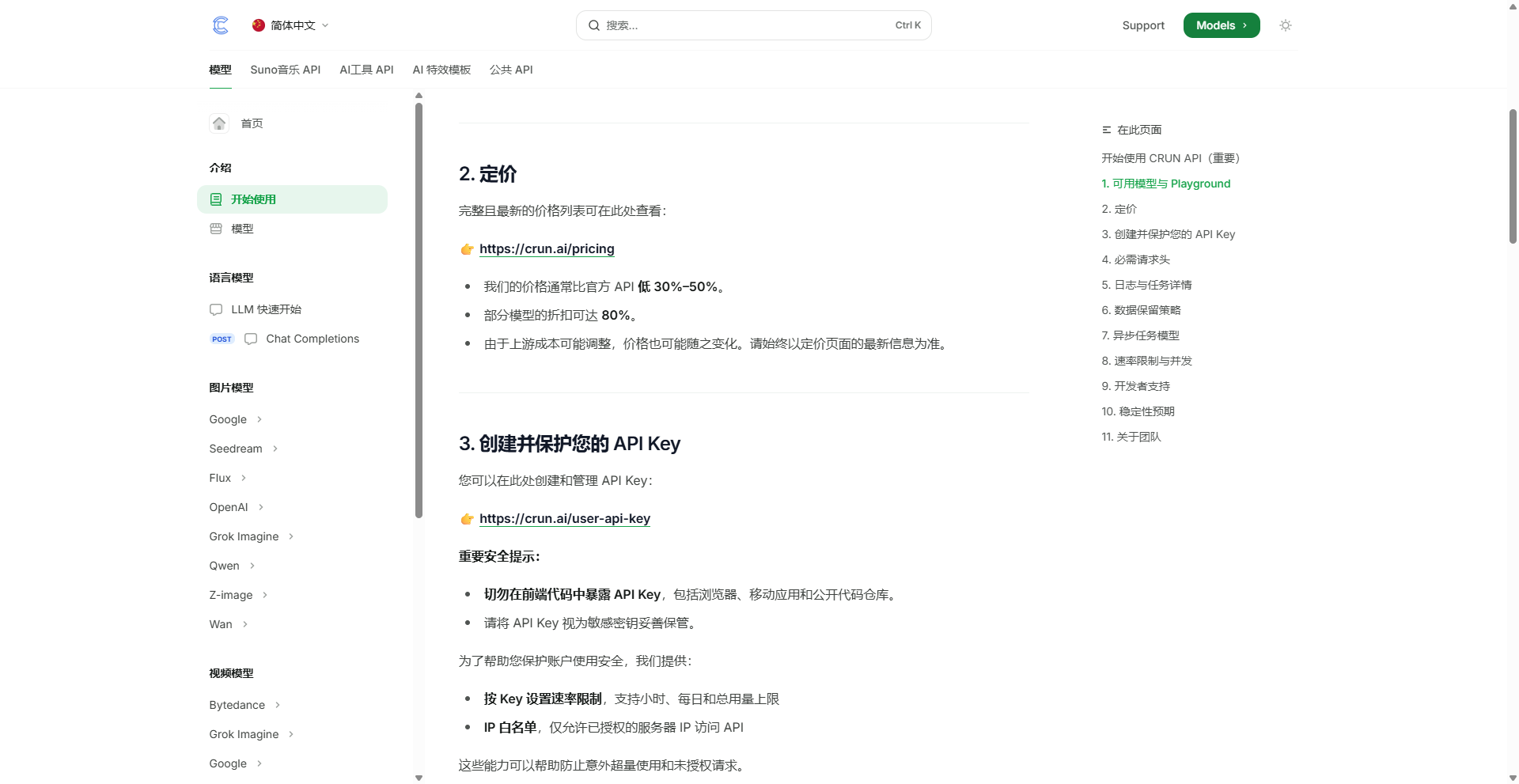
-
多模态视频与图像模型的一键横向对比
多模态生成(如电商海报或短视频脚本测试)具有天然的随机性,单一模型极难包揽全部场景。Crun 允许团队在同一个界面下进行小样本的“横向赛马”。直接并排调度全球顶尖模型(如 Sora 2、Kling 3.0、Veo 3.1、Flux 2 等),在完全相同的提示词下横向对比它们的表现风格,极大缩短了内容团队寻找商业可用素材的盲目试错路径。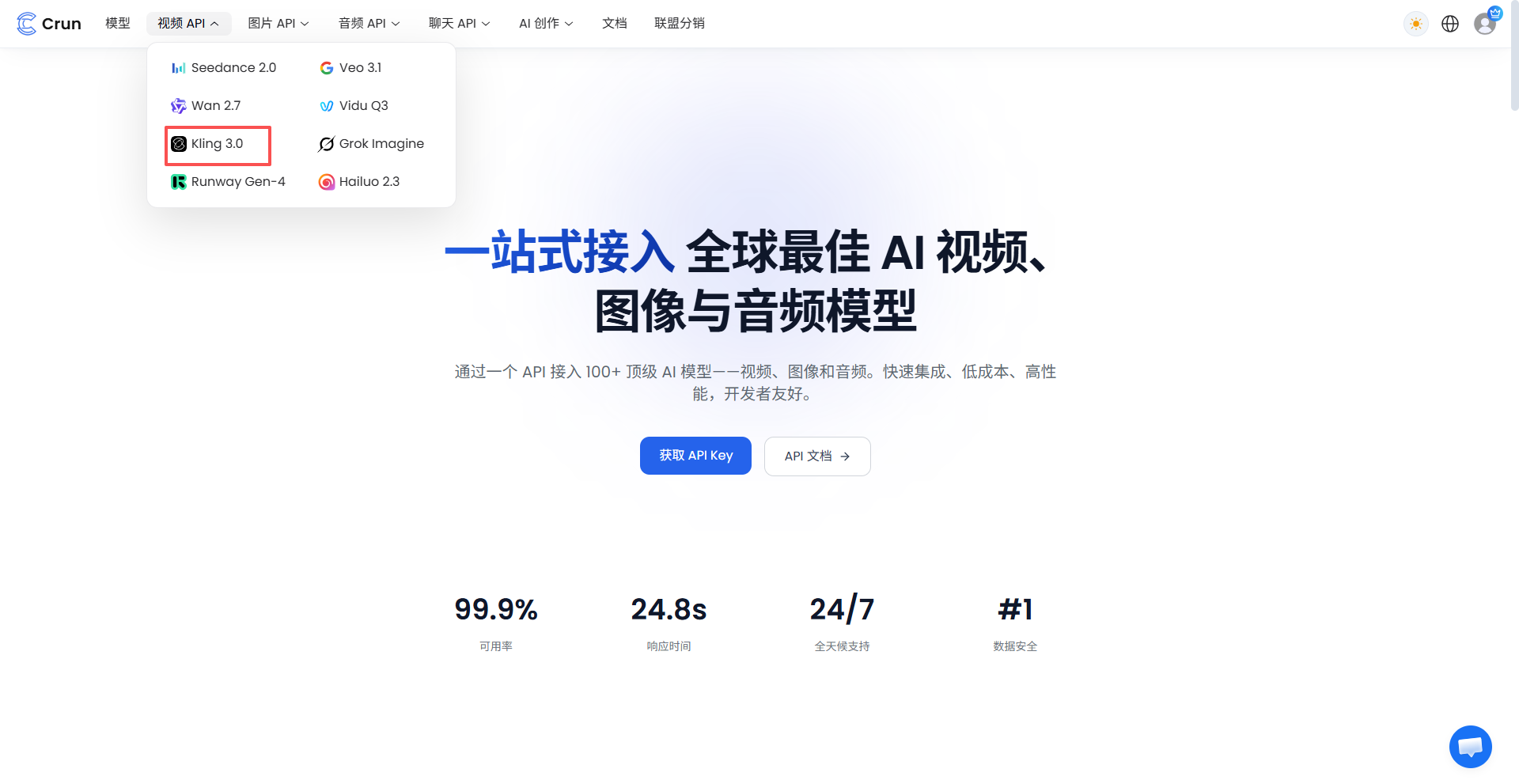
-
开发者文档与极简 SDK 封装
以往每接一个新模型就要去啃几十页怪异的文档。Crun 对国内开发者极为友好,不仅彻底规避了海外账号难注册、支付不便的门槛,而且 100% 兼容 OpenAI 协议。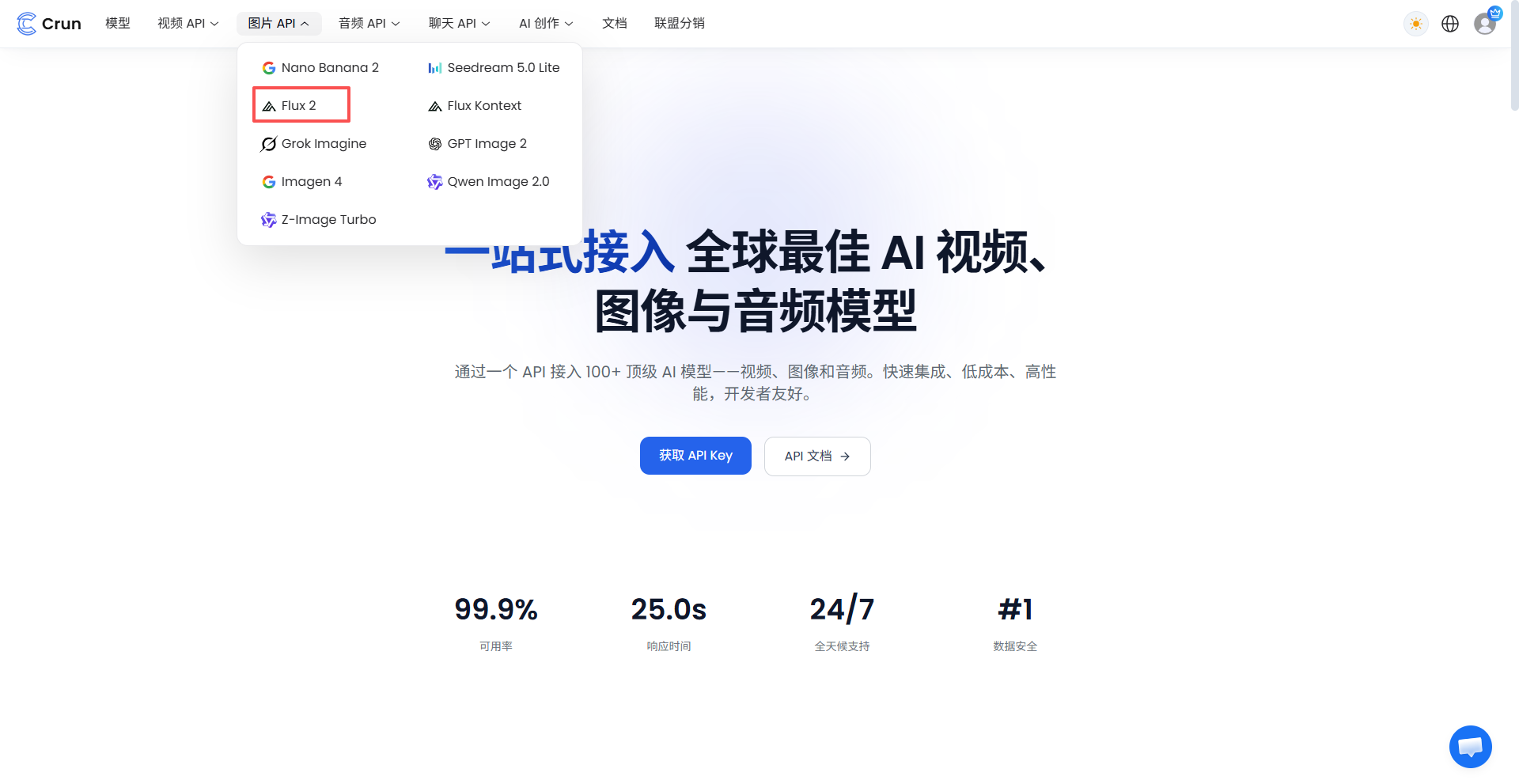
三、 为什么说 Crun 值得一试?
在多模态开发已经进入深水区的 2026 年,Crun 的核心底层价值在于它为系统架构带来了“向前兼容”的确定性与高性价比的财务管控:
- 架构与组件全面解耦:Crun 抹平了模型间的物理差异。无论底层供应商如何涨价、接口如何更迭甚至是突发宕机,由于业务层面对的是恒定不变的任务结构,技术团队只需要在后台一键切换或进行秒级Failover 路由,不需要改动产品核心代码。这就免去了烟囱式开发累积的巨额技术债。
- 透明定价与成本熔断:多模态尤其是视频生成的单价高,如果没有精细化控制很容易烧钱失控。Crun
采取完全透明的按量计费模式(相比独立买高昂的单模型月费,节省达30%-50%),且后台支持实时的成本熔断和用量控制,从根源上消除了大促期间系统努力自己重跑导致月底账单暴击的隐患。
四、 适合哪些人使用?
Crun 的能力矩阵完美覆盖了目前以下几类高产能应用场景:
- 全栈/独立开发者:想要以最快的速度上线自己的多模态 Agent 产品,迫切需要从日志、重试、多渠道鉴权等非核心基建的体力活中抽身出来。
- 高频跑量的内容电商运营团队:需要批量换场景、批量产出商业主图海报、日产十几款带货短视频素材,需要利用多模型供应链进行柔性组合与小样本赛马。
- 动漫及长内容短剧工作室:角色一致性和运镜镜头语言连续性是漫剧核心痛点,需要全链路平台统一处理文本剧本、图生视频、音频克隆配音等复杂的全模块自动化流水线。
五、 使用建议与注意事项
- 善用内置的 Prompt智能扩写器:绝大多数用户出不来理想的成片质感,并不是模型智商不够,而是描述需求过于模糊(例如只写“高级海报”)。Crun 调测台内置了结构化提示词扩写工具,它会自动根据不同模型(如 Flux 2 或 GPT Image)的底层喜好自动翻译并压榨模型性能,使用时可以直接输入想法进行扩写,效率会提高数倍。
- 合理设置超时降级路由:在配置复杂的 Agent 自决策系统时,建议将长任务(如 1080p 视频生成)在 Crun 控制台指定fallback 后端,当主模型偶发过载时,系统能自动降级调用备用线路,确保生产环境 24/7 的高可用性。
六、 总结
在 AI 应用层开发已经进入白热化阶段的 2026 年,技术团队的核心竞争力不再是盲目手搓各个供应商的底层接口,而是谁能以最低的认知负载和最高的工程确定性,把生成结果转化为实际的商业用户体验。通过像 Crun 这样结构化解耦的中间层,让基础设施回归后台,才是小团队在激烈赛道中保持极致灵活性和战斗力的唯一解法。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)