【多模态实战系列·第 07 篇】音频理解:语音·声音·音乐——从 Whisper 到音频 LLM,全模态 AI 的最后一块拼图
【多模态实战系列·第 07 篇】音频理解:语音·声音·音乐——从 Whisper 到音频 LLM,全模态 AI 的最后一块拼图
系列回顾:第 01-03 篇我们掌握了 CLIP/BLIP-2/LLaVA——视觉+语言的多模态基础。第 04 篇梳理了对齐粒度演进,第 05 篇实现了多模态 RAG,第 06 篇进入视频理解——在空间基础上增加了时间维度。本篇进入多模态的听觉维度:音频理解。人类感知世界有三大通道:视觉(看)、听觉(听)、语言(读/说)。前六篇我们覆盖了视觉和语言,本篇补上听觉——音频是全模态 AI 的最后一块拼图。音频理解不只是"语音识别"——它包含三个独立维度:语音(Speech,语言性音频,有语义)、声音(Sound,非语言性音频,无语义)、音乐(Music,艺术性音频,节奏+旋律+和声)。语音识别(ASR)把语音转文字,但丢失了情感、语气、说话人信息;声音理解需要识别环境声、事件声,没有语言语义可依赖;音乐理解需要理解节奏、旋律、和声的多层结构,主观性极强。从 Whisper 到 CLAP 到 Qwen-Audio/SALMONN,音频大模型经历了从"语音识别"到"音频-语言对齐"到"音频对话推理"的演进。今天,我们从音频信号基础、模型演进到多模态融合与未来,彻底掌握音频理解。
📑 文章目录
🔊 一、音频信号基础:语音·声音·音乐三维度

1.1 音频 ≠ 语音:三个独立维度
很多人把"音频理解"等同于"语音识别",这是一个误解。音频理解包含三个独立维度,每个维度有不同的特征和挑战:
语音(Speech):语言性音频,有明确的语义。语音的核心任务是 ASR(自动语音识别)——把语音转成文字。但 ASR 只提取了语义信息,丢失了情感(开心/悲伤)、语气(疑问/命令)、说话人(谁在说话)、语速/停顿(犹豫/自信)等副语言信息。
声音(Sound):非语言性音频,没有语言语义。声音包括环境声(雨声、风声、交通声)、事件声(玻璃碎裂、狗叫、门铃)、人声非语言(笑声、叹气、咳嗽)。声音理解的核心是音频事件检测(Audio Event Detection)和声景分类(Acoustic Scene Classification)。
音乐(Music):艺术性音频,有节奏、旋律、和声的多层结构。音乐理解包括音乐分类(流派/情绪/乐器)、音乐生成(作曲/编曲)、音乐信息检索(哼唱搜索/相似推荐)。音乐的主观性极强——同一首曲子,不同人有不同感受。
1.2 音频信号表示:从波形到频谱
音频信号是一维时序信号——随时间变化的振幅。但直接处理波形效果不好,通常转换为频域表示:
波形(Waveform):时域表示,横轴时间、纵轴振幅。直接处理波形需要极高的采样率(16kHz-48kHz),计算成本高。
频谱图(Spectrogram):频域表示,通过短时傅里叶变换(STFT)将波形转换为时频图——横轴时间、纵轴频率、颜色深浅表示能量。频谱图是音频处理的"图像"——可以用 2D CNN 或 ViT 处理。
Mel 频谱图(Mel-Spectrogram):模拟人耳感知的频谱图。人耳对低频敏感、高频不敏感,Mel 刻度对频率进行非线性变换,使得低频分辨率高、高频分辨率低。Mel 频谱图是音频深度学习最常用的输入表示。
import torchaudio
import torchaudio.transforms as T
# 加载音频
waveform, sample_rate = torchaudio.load("audio.wav")
# Mel频谱图
mel_transform = T.MelSpectrogram(
sample_rate=sample_rate,
n_fft=1024,
hop_length=512,
n_mels=80
)
mel_spec = mel_transform(waveform) # [1, 80, T]
1.3 语音 vs 声音 vs 音乐:特征对比
| 维度 | 语音 | 声音 | 音乐 |
|---|---|---|---|
| 语义性 | 强(语言) | 弱(无语言) | 中(歌词有语义) |
| 离散性 | 词/音素 | 连续频谱 | 音符离散 |
| 时序依赖 | 强 | 中 | 极强 |
| 多源混合 | 说话人分离 | 鸡尾酒会 | 多乐器 |
| 主观性 | 低 | 低 | 高 |
| 代表模型 | Whisper | CLAP | MusicGen |
语音的语义性最强——ASR 转文字后可以直接用 LLM 处理。声音没有语言语义——不能转文字,必须用专门的音频编码器。音乐介于两者之间——歌词有语义,但旋律/和声没有。
🤖 二、模型演进:从 Whisper 到音频 LLM
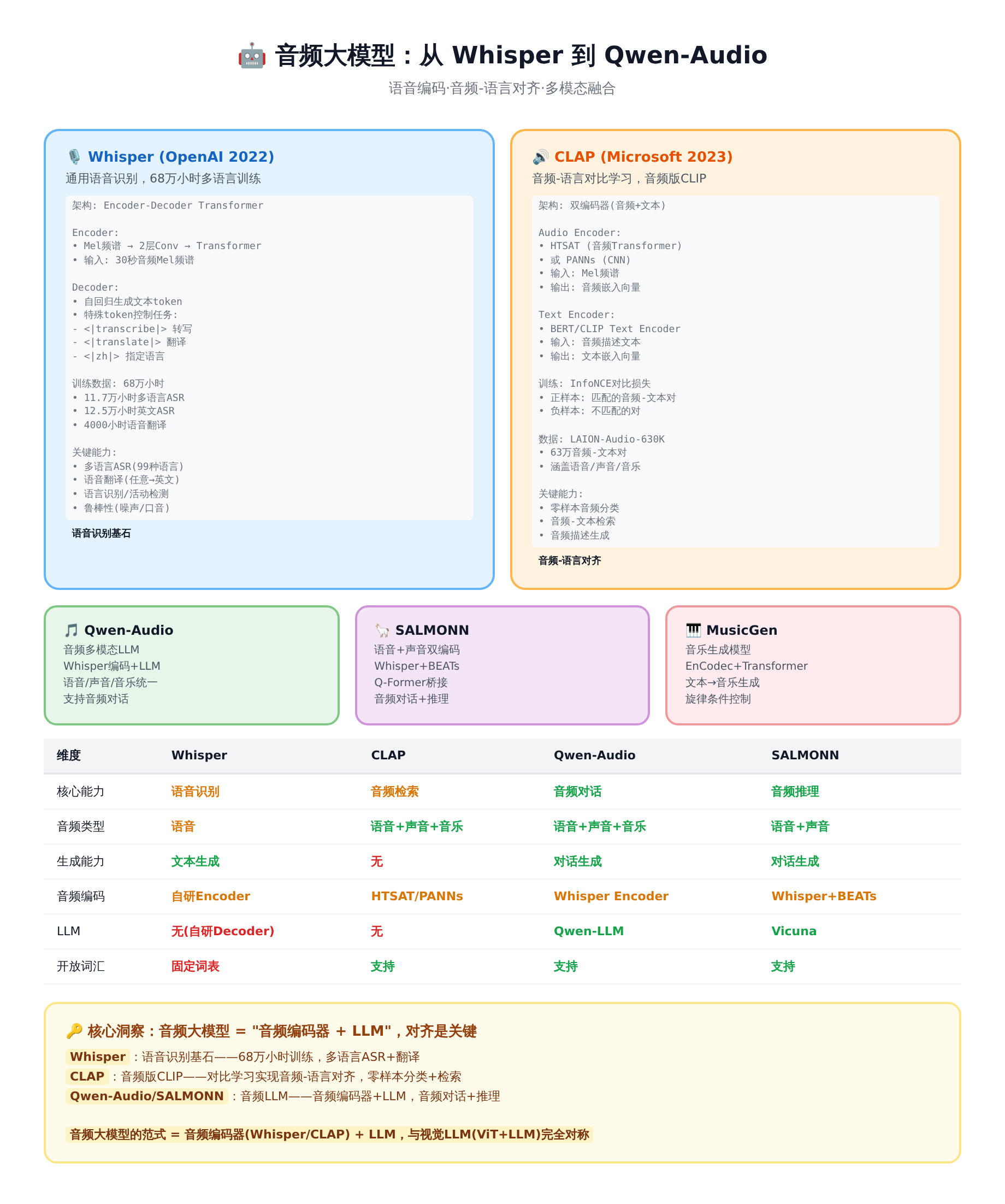
2.1 Whisper:语音识别的基石
Whisper 是 OpenAI 2022 年发布的通用语音识别模型,用 68 万小时多语言音频训练,覆盖 99 种语言。Whisper 的架构是 Encoder-Decoder Transformer——Encoder 编码音频 Mel 频谱图,Decoder 自回归生成文本。
Whisper 的核心能力:
- 多语言 ASR:99 种语言的语音识别,WER(词错率)在英语上低至 5%
- 语音翻译:直接从非英语语音翻译为英语文本,无需先 ASR 再翻译
- 语言识别:自动检测音频中的语言
- 语音活动检测:检测音频中是否有人说话
Whisper 的局限:
- 只处理语音:不能理解环境声、音乐等非语音音频
- 无对话能力:Whisper 是 ASR 模型,不是对话模型——只能转录,不能回答问题
- 实时性:大模型(large)推理速度慢,需要蒸馏或加速
import whisper
# 加载模型
model = whisper.load_model("base")
# 语音识别
result = model.transcribe("audio.mp3")
print(result["text"]) # 转录文本
print(result["language"]) # 检测到的语言
# 语音翻译(非英语→英语)
result = model.transcribe("chinese_audio.mp3", task="translate")
print(result["text"]) # 英文翻译
2.2 CLAP:音频版 CLIP
CLAP(Contrastive Language-Audio Pre-training)是音频版的 CLIP——用对比学习实现音频-语言对齐。CLAP 的架构与 CLIP 完全对称:Audio Encoder + Text Encoder + 对比学习。
Audio Encoder:HTSAT(Hierarchical Token-Semantic Audio Transformer)或 PANNs(Pre-trained Audio Neural Networks)。HTSAT 将 Mel 频谱图切分为 Patch,用 Transformer 编码,输出音频向量。PANNs 用 CNN 处理频谱图,在 AudioSet 上预训练。
Text Encoder:与 CLIP 相同的 Transformer 架构,编码文本描述。
对比学习:与 CLIP 完全相同的 InfoNCE 损失——匹配的音频-文本对拉近,不匹配的推远。训练数据是大规模音频-文本对(如 AudioSet 的类别描述、LAION-Audio 的网络音频-文本对)。
CLAP 的核心能力:
- 零样本音频分类:与 CLIP 的零样本图像分类完全对称——"the sound of a dog barking"就是分类器
- 音频-文本检索:以文搜音、以音搜文
- 音频描述生成:结合 LLM,可以生成音频的自然语言描述
from laion_clap import CLAP_Module
# 加载模型
model = CLAP_Module()
# 零样本音频分类
audio_embeddings = model.get_audio_embedding(["audio.wav"])
text_embeddings = model.get_text_embedding([
"the sound of a dog barking",
"the sound of rain falling",
"the sound of a car engine"
])
similarities = audio_embeddings @ text_embeddings.T
2.3 Qwen-Audio:音频对话 LLM
Qwen-Audio 是阿里云的音频大模型,将 Whisper Encoder 与 Qwen LLM 连接,实现音频对话。Qwen-Audio 的架构与 LLaVA 完全对称:Whisper Encoder + 投影层 + Qwen LLM。
音频编码器:Whisper-large-v3 的 Encoder,冻结。输入 Mel 频谱图,输出音频特征序列。
投影层:将 Whisper Encoder 的音频特征映射到 Qwen LLM 的嵌入空间。Qwen-Audio 使用多层感知机(MLP)作为投影层。
LLM:Qwen-7B/72B,微调。音频 Token 和文本 Token 拼接后一起输入 LLM,LLM 生成文本回答。
Qwen-Audio 的核心能力:
- 语音识别+翻译:继承 Whisper 的 ASR 能力
- 音频问答:对音频内容进行问答——“这段音频里说了什么?”“背景有什么声音?”
- 音频描述:生成音频的自然语言描述
- 情感分析:识别语音中的情感——说话人是开心还是悲伤?
- 声音事件检测:识别环境声——“这段音频中有狗叫和汽车声”
2.4 SALMONN:音频推理 LLM
SALMONN(Speech Audio Language Music Open Neural Network)是清华大学的音频大模型,用 Whisper Encoder + BEATs(音频事件编码器)双编码器连接 Vicuna LLM,实现语音+声音的统一理解。
双音频编码器:Whisper Encoder 处理语音,BEATs 处理声音事件。两个编码器的输出通过 Q-Former 聚合后输入 LLM。这种双编码器设计让 SALMONN 同时理解语音和声音。
SALMONN 的核心能力:
- 语音+声音联合理解:同时处理语音和环境声——“背景有雨声,说话人在讨论天气”
- 音频推理:基于音频内容进行推理——“为什么说话人语气焦虑?因为背景有警报声”
- 跨模态推理:结合音频和文本进行推理
2.5 模型演进总结
| 模型 | 核心能力 | 音频类型 | 生成能力 | LLM |
|---|---|---|---|---|
| Whisper | 语音识别 | 语音 | 文本生成 | 无(自研Decoder) |
| CLAP | 音频检索 | 语音+声音+音乐 | 无 | 无 |
| Qwen-Audio | 音频对话 | 语音+声音+音乐 | 对话生成 | Qwen-LLM |
| SALMONN | 音频推理 | 语音+声音 | 对话生成 | Vicuna |
演进路径:语音识别(Whisper) → 音频-语言对齐(CLAP) → 音频对话(Qwen-Audio) → 音频推理(SALMONN)。与视觉 LLM 的演进路径完全对称:图像分类(ViT) → 图文对齐(CLIP) → 视觉对话(LLaVA) → 视觉推理。
🔗 三、多模态融合与未来方向

3.1 音频+视觉+文本:三模态融合
音频理解的最大价值不在于单独处理音频,而在于与视觉和文本的多模态融合。现实世界的感知是多模态的——我们看视频时同时看画面和听声音,我们对话时同时听语音和看表情。
音视频融合:视频 = 图像 + 音频 + 时间。音视频融合的核心是音画同步——画面和声音在时间上对齐。例如,看到嘴型变化的同时听到语音,看到爆炸画面的同时听到爆炸声。音视频融合的应用包括:视频理解(画面+声音互补)、视听定位(听声辨位)、唇语识别(嘴型+语音)。
音频+文本融合:语音识别(ASR) + LLM 的组合是最常见的音频+文本融合。ASR 把语音转文字,LLM 处理文字生成回答。但这种"级联"方式丢失了副语言信息——更好的方式是端到端融合,让 LLM 直接处理音频特征。
三模态融合:文本+图像+音频的统一模型。GPT-4o 和 Gemini 已经实现了三模态融合——用户可以同时发送图片、音频和文本,模型统一理解并生成回答。开源模型方面,Qwen-VL-Audio 正在向这个方向努力。
3.2 应用场景
会议助手:语音识别 + 说话人分离 + 摘要生成。Whisper 做 ASR,LLM 做摘要和问答。关键挑战是说话人分离(谁说了什么)和长音频处理。
客服质检:语音识别 + 情感分析 + 合规检查。自动检测客服对话中的情绪波动和违规用语。关键挑战是领域适配和实时性。
音乐推荐:音频特征提取 + 用户偏好建模。CLAP 做音频-文本对齐,LLM 做推荐解释。关键挑战是主观性和多样性。
环境监测:声音事件检测 + 异常报警。PANNs/BEATs 做音频事件分类,LLM 做异常推理。关键挑战是低信噪比和罕见事件。
无障碍辅助:实时语音识别 + 手语翻译 + 语音合成。为听障人士提供实时字幕,为视障人士提供环境声描述。
3.3 挑战与未来
音频编码统一:当前语音(Whisper)、声音(CLAP/PANNs)、音乐(MusicGen)使用不同的编码器——未来需要一个统一音频编码器,像 ViT 统一视觉编码一样统一音频编码。
实时音频理解:流式处理 + 低延迟——会议/客服/同传场景需要实时理解。Whisper 的 streaming 模式和 Qwen-Audio 的流式推理正在解决这个问题。
音频+视觉深度对齐:当前音视频融合大多是"各自编码后拼接"——未来需要更深度的对齐,如音画同步、视听定位、跨模态注意力。
全模态大模型:文本+图像+音频+视频+3D 的统一模型。GPT-4o/Gemini 已经开始,开源模型正在追赶。
情感计算:语音情感 + 面部表情 + 文本情感的联合理解。情感是跨模态的——同一个人说"我没事",语音可能透露悲伤,面部可能显示勉强微笑。
音频 Agent:听声音 → 推理 → 行动。例如,听到火灾警报 → 识别警报类型 → 查询应急预案 → 通知相关人员。
多模态实战系列进度
| 篇号 | 主题 | 核心内容 | 状态 |
|---|---|---|---|
| 01 | CLIP原理 | 对比学习/双编码器/零样本迁移 | ✅ |
| 02 | BLIP-2 | Q-Former/视觉-语言桥接/高效预训练 | ✅ |
| 03 | LLaVA | 视觉指令微调/多模态对话/视觉LLM | ✅ |
| 04 | 图文对齐 | 全局→区域→像素对齐演进 | ✅ |
| 05 | 多模态RAG | 图文混合检索/知识增强 | ✅ |
| 06 | 视频理解 | 时序建模/长视频/视频QA | ✅ |
| 07 | 音频理解(本文) | 语音/声音/音乐/音频LLM | ✅ |
| 08 | 工业应用 | 落地实战/端侧部署/业务集成 | ⏳ 下一篇 |
一句话总结
音频理解三大维度:音频信号基础(音频≠语音三个独立维度——语音有语义ASR转文字但丢失情感语气/声音无语义需专门音频编码器/音乐有节奏旋律和声主观性强。音频信号表示——波形→STFT频谱图→Mel频谱图模拟人耳感知。语音vs声音vs音乐=语义性强/弱/中离散性强/弱/中时序依赖强/中/极强。音频理解的核心=语音是入口声音和音乐是完整音频理解的必要补充)、模型演进(Whisper——68万小时多语言训练99种语言ASR+翻译+语言识别/局限=只处理语音无对话能力。CLAP——音频版CLIP对比学习实现音频-语言对齐/零样本音频分类+音频-文本检索。Qwen-Audio——Whisper Encoder+投影+Qwen LLM音频对话/语音识别+音频问答+情感分析+声音事件检测。SALMONN——Whisper+BEATs双编码器+Vicuna LLM/语音+声音联合理解+音频推理。演进=语音识别→音频-语言对齐→音频对话→音频推理与视觉LLM演进完全对称)、多模态融合与未来(音视频融合——音画同步视听定位唇语识别。音频+文本融合——ASR+LLM级联vs端到端。三模态融合——文本+图像+音频统一GPT-4o/Gemini已开始。应用=会议助手/客服质检/音乐推荐/环境监测/无障碍辅助。挑战=音频编码统一/实时理解/音视深度对齐/全模态大模型/情感计算/音频Agent。音频理解的终极目标=让AI不仅能看能读还能听全模态理解)。
参考链接:

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 4
4 0
0- 0



 已为社区贡献282条内容
已为社区贡献282条内容

所有评论(0)