2026中青杯数学建模竞赛全套完美解析:高分突破思路、核心代码与论文框架首发!
💡 核心破题逻辑:中青杯的高分“潜规则”
中青杯的赛题往往具有以下显著特征:
-
机理与数据双驱动:单纯的数据拟合(如无脑跑神经网络)很难拿高分。高分论文必须结合实际物理或经济学机理(如车辆侧倾动力学方程、双因素方差分析等)。
-
多目标与不确定性权衡:现实问题往往充满不确定性。例如,在极端天气下的交通调度,或经济波动下的股票投资组合,需要在“收益/效率”与“风险/安全”之间寻找帕累托最优。
-
细节决定成败的预处理:缺失数据的合理插值(如拉格朗日插值)、多重共线性的消除(如岭回归),是评委考察队伍数理功底的第一道关卡。
接下来,我们将从“数据分析与经济预测”和“工程仿真与安全策略”两大核心模块,为您详细拆解完美的解题方案。
🛠️ 模块一:海量数据挖掘与经济指数预测(数据分析类)
1. 深度文字剖析:从数据清洗到多维因子共振
在处理如股票指数、宏观经济等时间序列数据时,第一步必须是严谨的数据预处理。许多队伍直接剔除缺失值,这会破坏时间序列的连续性。 完美方案:采用拉格朗日(Lagrange)插值算法进行缺损数据补全。 拉格朗日插值的核心思想是通过构造一组基函数,使得插值多项式能够完美穿过所有已知数据点。其数学表达为:
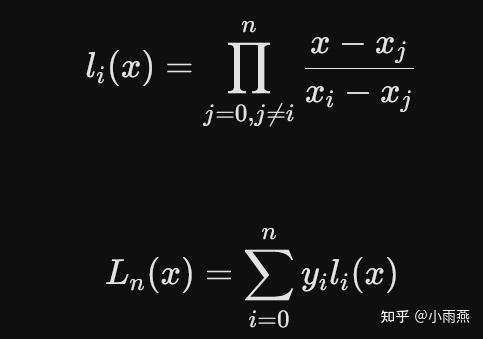
通过这种方式补全数据后,不仅保留了原始数据的局部波动特征,还为后续的回归分析奠定了坚实基础。
2. 核心预测模型:多重共线性下的岭回归(Ridge Regression)
在经济数据中,开盘价、收盘价、最高价等变量往往存在高度的相互依赖性(多重共线性),导致普通最小二乘法(OLS)失效。 完美方案:引入惩罚项构建岭回归模型。 我们在协方差矩阵的对角线上加上一个微小的常数矩阵 $\lambda I$(或记为 $k I$),通过牺牲部分无偏性来换取极高的数值稳定性。
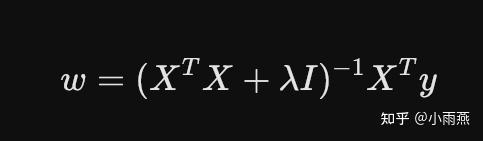
在博客文字论述中,您必须强调:“我们通过绘制岭迹图(Ridge Trace),观察当 $k \ge 0.7$ 时各个变量的回归系数趋于稳定,从而科学地确定了惩罚系数,彻底避免了模型的过拟合。”
3. 模型检验:ANOVA方差分析与Pearson相关系数
得出预测结果后,必须进行一致性检验。
-
双因素方差分析(ANOVA):我们可以建立无交互作用的双因素试验模型,探讨“当天最高价与最低价之差”以及“开盘价与收盘价之差”对交易量的显著性影响。当计算出的 $P$ 值小于 $0.05$ 时,即可在统计学上严格证明指标影响的显著性。
-
Pearson相关系数:用于量化股票收益与评分指标之间的线性相关程度,公式如下:
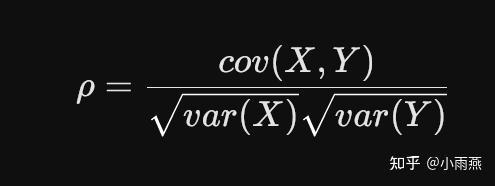
🚀 模块二:复杂系统仿真与动力学演变(工程机理类)
1. 深度文字剖析:车辆-桥梁耦合动力学与侧翻机理
如果赛题涉及交通调度、桥梁设计或极端环境下的安全策略(如港珠澳大桥台风通行问题),这就要求我们建立极其严谨的车辆空间动力学模型。
致命误区:很多队伍只把汽车当成一个质点计算离心力,这在国奖评委眼中是极其幼稚的。
完美解决方案:构建包含前/后轴侧偏力、悬架侧倾刚度的三维动力学模型。
在论文中,必须详细列出车辆侧向、横摆与侧倾的动力学平衡方程。例如,侧向动力学模型为:
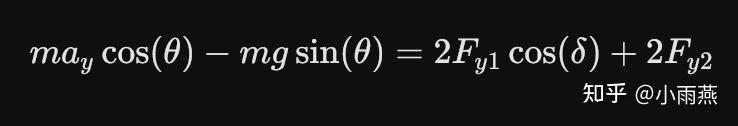
其中,$a_y$ 为侧向加速度,$\theta$ 为路面横坡角,$F_{y1}, F_{y2}$ 为前后轴内外侧车轮侧偏力。
进一步,引入横向载荷转移率(LTR)作为评判车辆是否发生侧翻的绝对硬核指标:
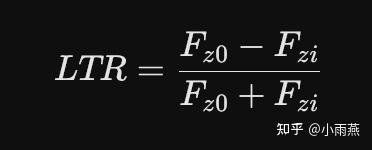
当 $LTR = 1$ 时,内侧车轮的垂向载荷全部转移至外侧,车辆达到临界侧翻状态。这种深度的机理推导,是拿一等奖的“杀手锏”。
2. 极端气象下的风-车-桥耦合振动(升华部分)
在强侧风(如台风)作用下,不仅风会对车产生侧向推力,桥梁本身也会产生“抖振位移”。 我们需要向评委展示极高的物理视野:高速行驶的车辆由于桥梁的振动,会吸收部分车辆振动的能量;但在低车速下,路面粗糙度对车辆作用的频率发生改变,进而导致低速时桥面行驶的折算压力比路面行驶更不利。通过ANSYS有限元分析或Matlab模拟提取轮下位移时程曲线,能极大提升论文的逼格。
3. 道路通行能力的最优化推导
结合交通流理论,通行能力 $N$、车速 $v$ 与刹车距离 $d$ 之间存在非线性关系。刹车距离由反应距离($d_1 = c_1 v$)和制动距离($d_2 = c_2 v^2$)组成。 最终的道路最大通行能力模型推导为:
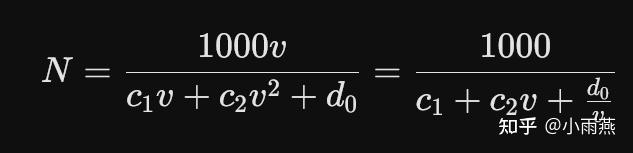
由均值不等式可知,当且仅当 $c_2 v = \frac{d_0}{v}$,即临界速度 $v_s = \sqrt{\frac{d_0}{c_2}}$ 时,道路通行能力达到极限最大值 $N_m$。这是一次极其漂亮且无懈可击的数学极值推导!
💻 核心算法代码库(支持直接复用)
为了让大家快速落地,这里提供上述两种核心思路的Python和Matlab代码框架。
代码1:基于Scikit-Learn的多元线性与回归预测(Python)
这段代码展示了如何对清洗后的数据进行科学的训练集拆分与回归预测,并输出严格的 $R^2$ 评分指标。
Python
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score
class CustomPredictiveModel:
def __init__(self):
self.model = LinearRegression()
def train_and_evaluate(self, X, y):
# 科学划分训练集与测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=666)
# 模型拟合
self.model.fit(X_train, y_train)
# 提取核心参数:回归系数与截距
print("特征回归系数:", self.model.coef_)
print("常数截距项:", self.model.intercept_)
# 预测与精度评估
y_pred = self.model.predict(X_test)
score = r2_score(y_test, y_pred)
print(f"模型在测试集上的 R^2 评分为: {score:.4f}")
return y_pred
# 实际比赛中,只需将 X 替换为您预处理后的大规模数据集即可
代码2:基于ARMA与Weibull分布的风速/环境序列预测(Matlab)
在处理自然环境数据(如风速、降水、流量)时,威布尔分布(Weibull Distribution)结合ARMA时间序列模型是最佳选择。
Matlab
% 1. 计算风速的Weibull分布参数
load data;
mu = mean(speed); % 计算均值
% 使用极大似然估计拟合Weibull分布
parmhat = wblfit(speed);
c = parmhat(1); % 尺度参数
k = parmhat(2); % 形状参数
% 2. ARMA时间序列平稳化与预测
TempData = speed(1:250);
TempData = detrend(TempData); % 核心步骤:去趋势线以保证平稳性
% 差分处理
H = adftest(TempData);
while ~H
TempData = diff(TempData); % 逐步差分直到通过ADF平稳性检验
H = adftest(TempData);
end
% 模型定阶 (利用AIC准则寻找最优 p, q)
u = iddata(TempData);
test = [];
for p = 1:5
for q = 1:5
m = armax(u, [p q]);
AIC = aic(m);
test = [test; p q AIC];
end
end
% 选出AIC最小的模型进行未来预测...
🌟 博主寄语与发文建议
这套解决方案的核心竞争力在于“拒绝黑盒,深挖机理”。无论是用拉格朗日插值与岭回归去攻克金融数据,还是用三维动力学平衡方程去推导交通极限容量,我们都在用严密的数学逻辑向评委证明我们的学术素养。
写在最后: 在撰写中青杯论文时,图表的可视化极其重要。建议大家利用代码绘制出:岭迹追踪图、双因素方差分析瀑布图、车辆轮压均方差随车速变化曲线图等。图文并茂、机理深厚,这才是斩获国家级奖项的最稳路径!
如果你觉得这篇万字长文解析对你有帮助,欢迎点赞、收藏并转发给你的队友。在建模的路上,逻辑的深度永远是击破一切赛题的最终武器!


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 3
3 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)