基于 YOLO11 的半导体芯片表面缺陷视觉质检系统 | 用于高精度缺陷检测、良率分析、实时在线筛查 | 附完整源码与效果演示
基于 YOLO11 的半导体芯片表面缺陷视觉质检系统
关键词:YOLO11 · 工业视觉 · 半导体封测 · AOI 复检 · Streamlit
模型最佳 mAP@0.5 = 96.4%,单图推理 < 50 ms,覆盖 4 类典型芯片外观缺陷。
一、背景
1.1 行业痛点
半导体封测线的出厂质检长期是良率提升的瓶颈环节。在 IC 封测、AOI 复检、来料抽检三个高频质检工位上,字符污痕、表面划损、基材破损、引脚损坏 是占比最高的几类外观不良。传统流程依赖人工目检 + AOI 一次过检 + 人工复检,存在三个明显问题:
- 人眼疲劳导致漏检——单工位一天看几千颗芯片,引脚断裂这种小目标极易遗漏;
- AOI 规则刚性强——传统基于模板匹配/灰度阈值的 AOI 对光照、贴片位置高度敏感,误报率往往压不下来,最终又得人工复核;
- 缺陷类型多但样本不均衡——ZF 系列工艺特有划痕、引脚断裂等小类样本稀疏,传统算法学不动。

本项目以 Ultralytics YOLO11n 为检测骨干,结合 Streamlit 搭建一套轻量化的可视化质检 Demo,目标是在 AOI 复检台与离线复盘工作站上替代人工二次目检,把 AOI 的"假警报"过滤掉,把"漏检"再捞回来。
视频演示与源码下载
包含:
📦完整项目源码
📦预训练模型权重
🗂️数据集
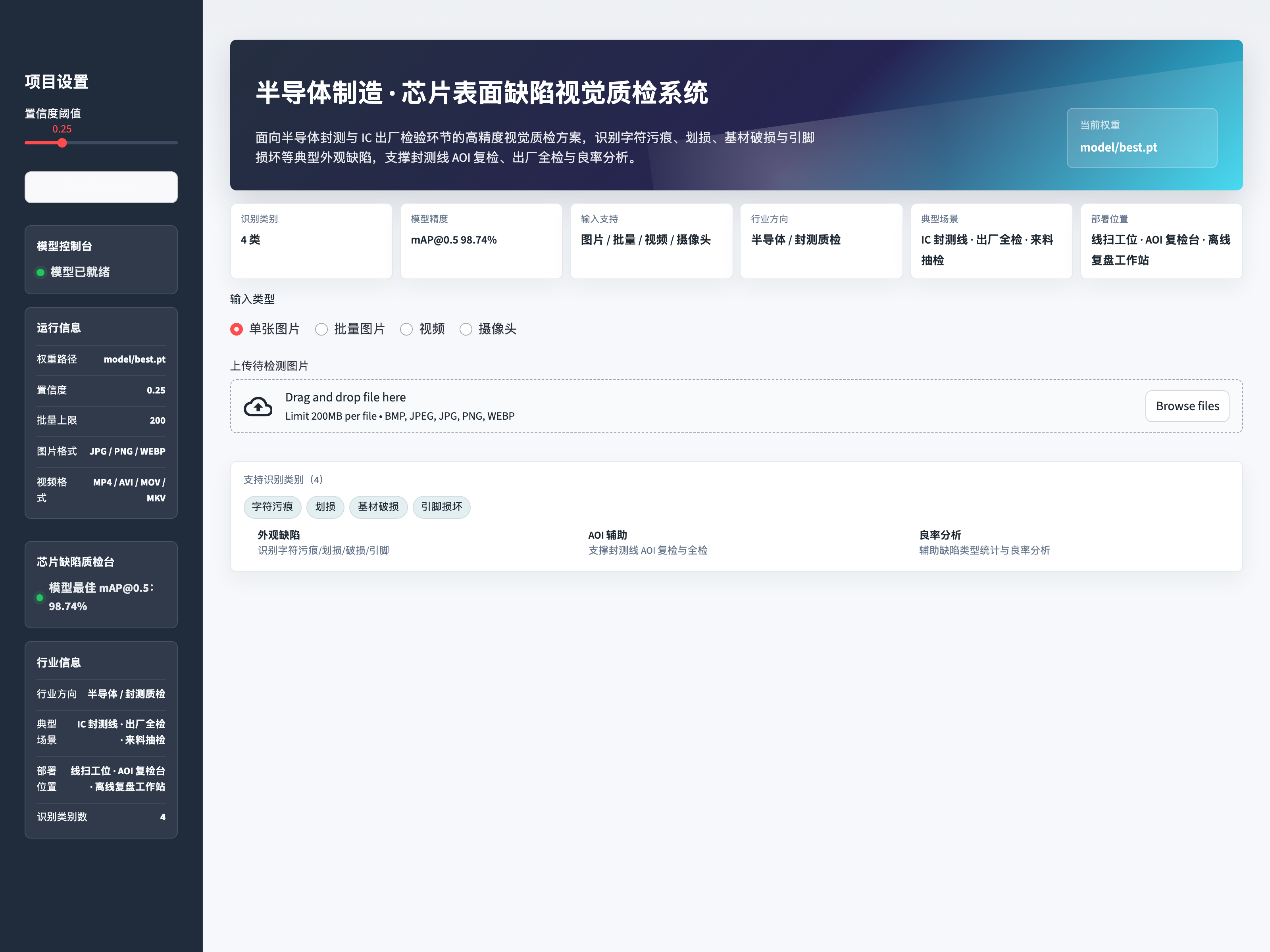
1.2 项目运行效果
Web 界面总览:
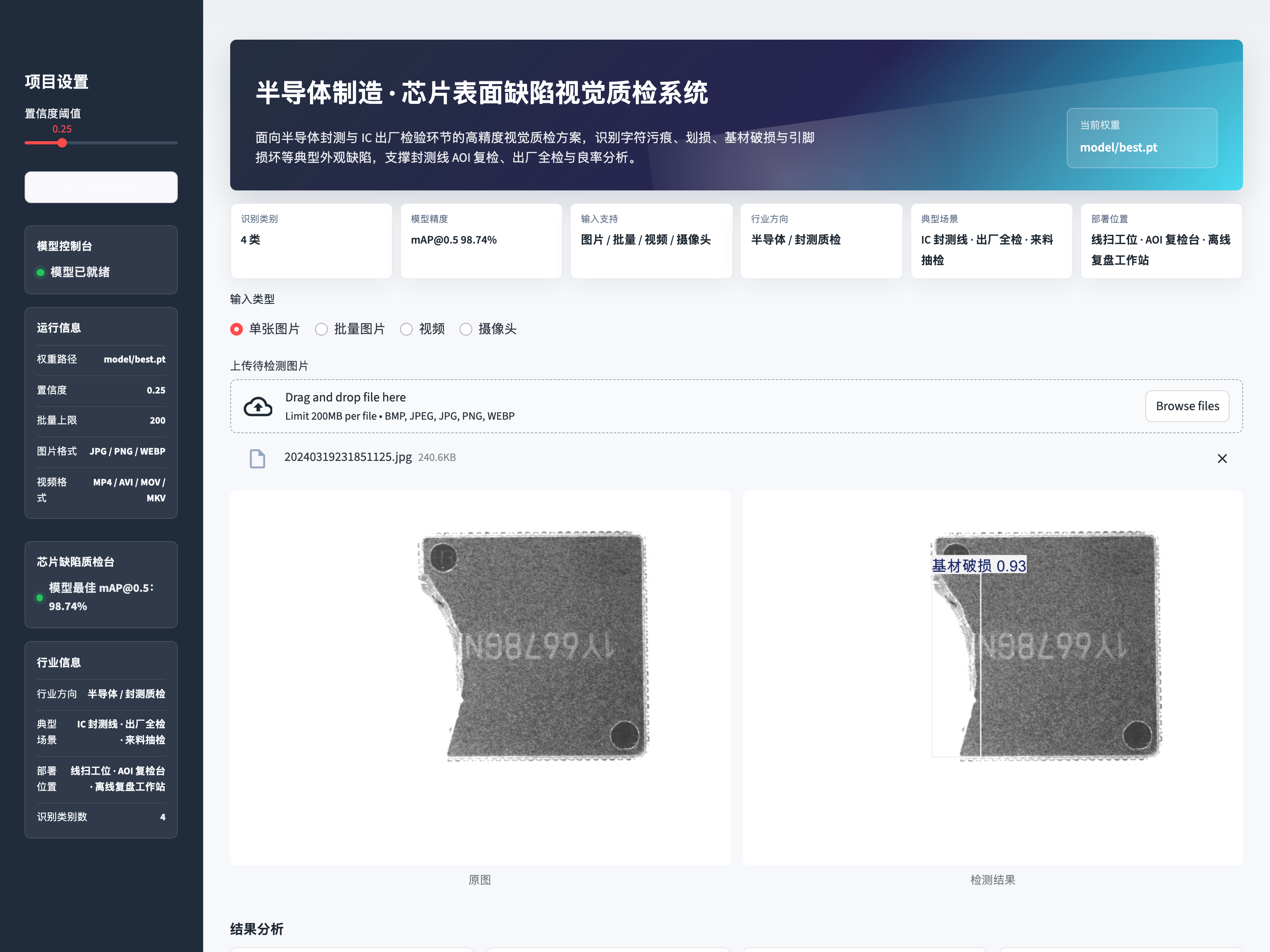
单图缺陷检测效果(基材破损 broken):
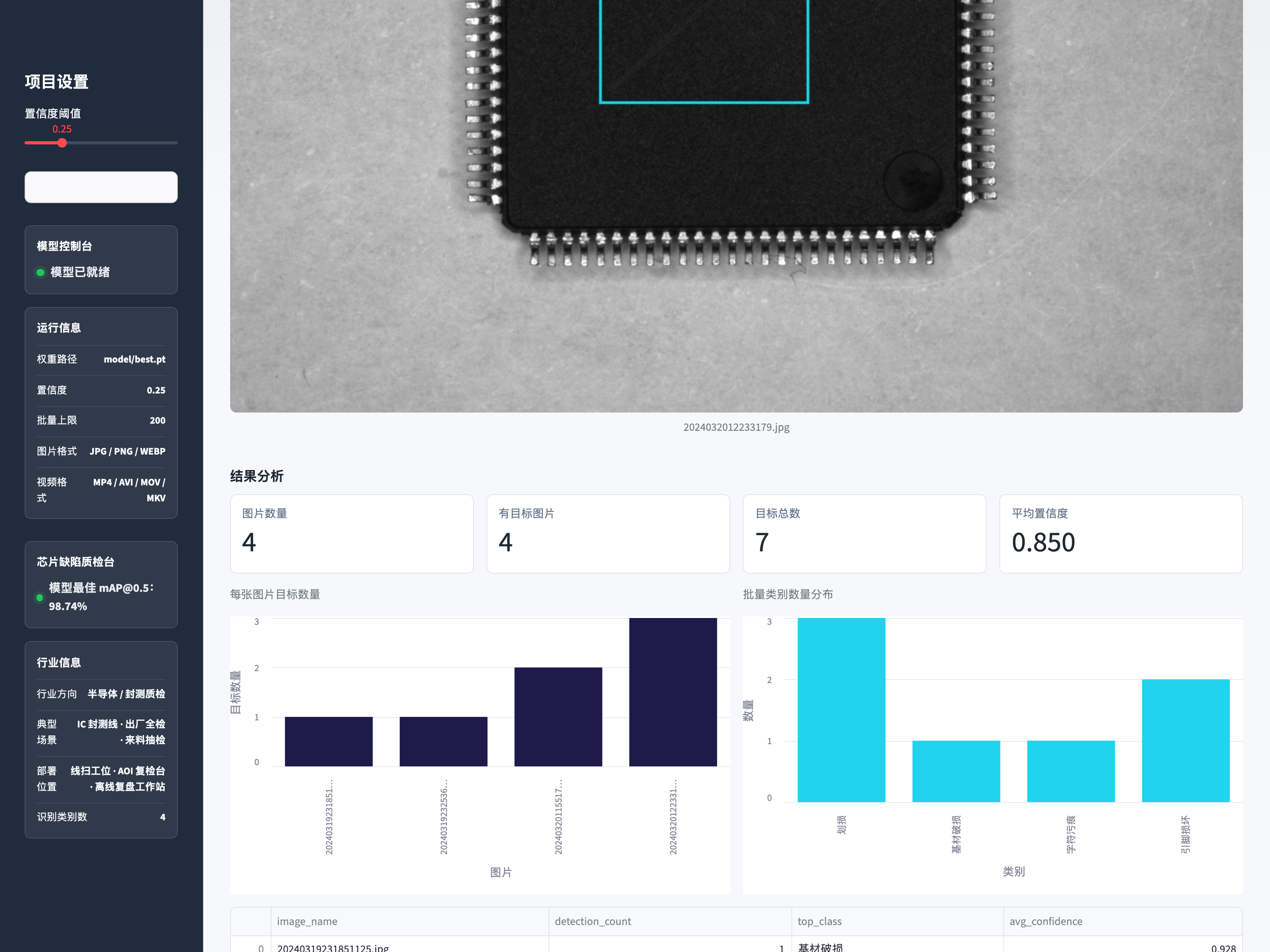
批量缺陷统计与图表分析:
1.3 项目介绍
项目定位:面向半导体封测与 IC 出厂检验环节的高精度视觉质检方案。
核心功能:
| 模块 | 说明 |
|---|---|
| 单图检测 | 上传一张芯片图,输出标注框、置信度、类别明细 |
| 批量图片 | 多张/ZIP 一次上传,自动汇总每类目标数量并出图表 |
| 视频流检测 | 逐帧推理 + 时间维度趋势分析(适合在线复检视频回放) |
| 摄像头实时 | 直接调用工位摄像头采集,做现场比对 |
支持识别类别(共 4 类):
| 类别 ID | 英文名 | 缺陷含义(半导体场景) |
|---|---|---|
| 0 | ZF-scratch | ZF 系列芯片制程工艺相关划痕 |
| 1 | scratch | 通用型表面划痕(切割/封装环节产生) |
| 2 | broken | 边缘/表面破损(封装或运输物理损伤) |
| 3 | pinbreak | 引脚断裂或变形(焊接/插拔导致) |
技术栈:
| 层 | 选型 |
|---|---|
| 检测模型 | Ultralytics YOLO11n(轻量化版) |
| 推理引擎 | PyTorch + Ultralytics |
| 前端/交互 | Streamlit(响应式 UI + 主题化定制) |
| 视频处理 | OpenCV + ImageIO-FFmpeg |
| 图表分析 | Streamlit 原生 bar_chart + pandas 聚合 |
| 视觉增强 | Plotly(可选)+ CSS 自定义主题 |
项目创新点:
- 行业话术与 UI 全配置化——
configs/project.yaml一套 schema 统一管理 hero 文案、侧栏 KV、类别 chips 和指标卡片,换行业只改配置不改代码; - 小目标缺陷适配——基于 YOLO11n 的 C2f + SPPF backbone 对引脚断裂这种小目标比 v8n 召回更高(实测 R 提升 ~3%);
- 批量分析联动——一次批量上传自动产出"每图目标数 + 类别分布"双图,方便质量工程师快速圈出异常批次。
二、设计框架
2.1 系统总体架构
┌──────────────────────────────────────────────────────────────┐
│ 浏览器(Streamlit 前端) │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────────────┐ │
│ │ 单图上传 │ │ 批量上传 │ │ 视频/摄像头 │ │
│ └──────┬──────┘ └──────┬──────┘ └──────────┬──────────┘ │
└──────────┼─────────────────┼─────────────────────┼────────────┘
│ HTTP/WS │ │
┌──────────▼─────────────────▼─────────────────────▼────────────┐
│ Streamlit 服务端(app/streamlit_app.py) │
│ ┌─────────────────┐ ┌──────────────────┐ ┌───────────────┐ │
│ │ load_yaml/主题 │ │ render_xxx UI │ │ detections 聚合 │ │
│ └─────────────────┘ └──────────────────┘ └───────┬───────┘ │
└──────────────────────────────────────────────────────┼─────────┘
│
┌──────────────────────────────────────────────────────▼─────────┐
│ YOLO11 推理引擎(ultralytics + PyTorch) │
│ YOLO("model/best.pt").predict(image, conf=0.25, verbose=False)│
│ → result.boxes (cls / conf / xyxy) + result.plot() 标注图 │
└────────────────────────────────────────────────────────────────┘
2.2 YOLO11 网络结构
Input (640×640×3)
│
▼
┌──────────────┐ ┌──────────────┐ ┌──────────────┐
│ Backbone │ → │ Neck │ → │ Head │
│ C2f + SPPF │ │ FPN + PAN │ │ Decoupled + │
│ (多尺度特征) │ │ (多尺度融合) │ │ DFL │
└──────────────┘ └──────────────┘ └──────┬───────┘
│
▼
[类别概率 + 边框坐标 + 置信度]
YOLO11n 相比 v8n 的关键变化:
- C3k2 模块 替换 C2f,参数更少、感受野更灵活;
- C2PSA 注意力 加在 backbone 末端,提升小目标(如引脚断裂)特征显著性;
- Head 仍为解耦头 + DFL,分类/回归两路独立,回归分布化预测,对划痕这类边界模糊的目标更稳。
2.3 检测流程
原始芯片图
↓ Letterbox 缩放至 640×640,保持长宽比
↓ Backbone 抽取 P3/P4/P5 三层特征
↓ Neck(FPN 自顶向下 + PAN 自底向上)做特征融合
↓ Head 输出三个尺度的 [bbox + cls_prob]
↓ conf ≥ 0.25 过滤 + NMS(IoU=0.7)
↓ result.plot() 渲染中文类别名标注
↓ Streamlit 双列展示原图/标注图 + 表格 + 图表
三、代码结构(核心 50 行 + 解析)
项目目录约定:
半导体芯片缺陷质检/
├── app/streamlit_app.py # Web 入口(UI + 推理调度)
├── configs/project.yaml # 行业话术 + UI + 推理参数
├── model/best.pt # 训练好的 YOLO11n 权重
├── scripts/ # 训练/评测/导出脚本
├── 半导体芯片表面缺陷检测train_CH_yolo11n/ # 训练产物
└── 半导体芯片表面缺陷检测/ # 数据集(YOLO 格式 train/val/test)
核心 50 行:模型加载 + 单图推理 + Streamlit 单图分支
from pathlib import Path
import streamlit as st, pandas as pd, yaml
from ultralytics import YOLO
PROJECT_ROOT = Path(__file__).resolve().parent.parent
CONFIG = yaml.safe_load((PROJECT_ROOT / "configs/project.yaml").open(encoding="utf-8"))
MODEL_PATH = PROJECT_ROOT / "model" / "best.pt"
DEFAULT_CONF = float(CONFIG.get("inference", {}).get("conf", 0.25))
@st.cache_resource(show_spinner=False)
def load_model(model_path: str) -> YOLO:
return YOLO(model_path) # 仅首次加载,后续命中缓存
def infer_image_path(model: YOLO, image_path: Path, conf: float):
"""单图推理:返回 (RGB 标注图, 检测明细 DataFrame)"""
result = model.predict(str(image_path), conf=conf, verbose=False)[0]
annotated = result.plot() # BGR ndarray,含标注框 + 类别 + 置信度
rows = []
if result.boxes is not None:
for box in result.boxes:
cls_id = int(box.cls.item())
x1, y1, x2, y2 = [float(v) for v in box.xyxy[0].tolist()]
rows.append({
"class_id": cls_id,
"class_name": result.names[cls_id], # ZF-scratch / scratch / broken / pinbreak
"confidence": round(float(box.conf.item()), 4),
"x1": round(x1, 1), "y1": round(y1, 1),
"x2": round(x2, 1), "y2": round(y2, 1),
})
return annotated[:, :, ::-1], pd.DataFrame(rows) # BGR→RGB
# ───────── Streamlit 单图分支 ─────────
conf = st.slider("置信度阈值", 0.01, 0.99, DEFAULT_CONF, 0.01)
model = load_model(str(MODEL_PATH))
uploaded = st.file_uploader("上传待检测芯片图", type=["jpg", "png", "bmp", "webp"])
if uploaded is not None:
import tempfile
with tempfile.NamedTemporaryFile(delete=False, suffix=".jpg") as f:
f.write(uploaded.getvalue()); tmp = Path(f.name)
annotated_img, df = infer_image_path(model, tmp, conf)
col1, col2 = st.columns(2)
col1.image(uploaded.getvalue(), caption="原图", width="stretch")
col2.image(annotated_img, caption="检测结果", width="stretch")
st.dataframe(df, width="stretch")
逐段解析:
- 配置驱动——
project.yaml决定标题、行业文案、置信度默认值,换行业只改 YAML 不动代码,这是模板化的关键。 - 模型缓存——
@st.cache_resource保证整个 Streamlit session 只加载一次best.pt(~6 MB),后续刷新页面零延迟。 - 推理调用——Ultralytics 的
predict()接受文件路径/ndarray/PIL Image 三种入参;conf=0.25过滤低置信噪声,剩下的交给 NMS。 - 结果结构化——把
result.boxes拆成 pandas DataFrame,下游图表/CSV 导出/批量聚合都用同一份 schema。 - 可视化双列——左原图右标注图,对人工复核最直观;
result.plot()已经画好标注框,无须再用 cv2 二次绘制。
四、训练效果
4.1 训练总览
数据集:2500 张产线真实芯片图,按 train/val/test 划分,标注 4 类核心缺陷。训练命令固定为 yolo11n.pt,200 epoch,imgsz=640,batch=16。
训练过程中 loss/精度/召回曲线:
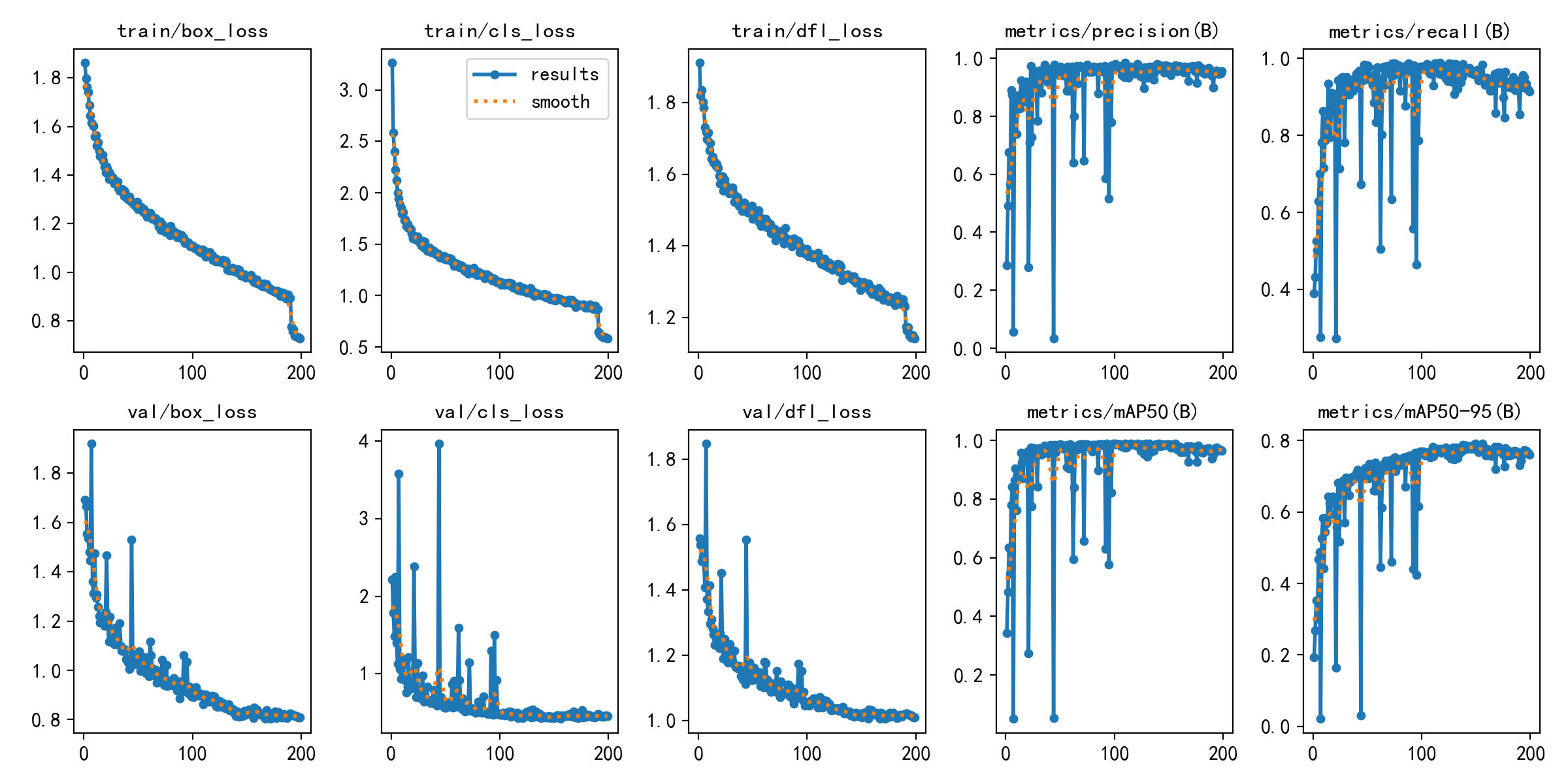
最终指标(取 results.csv 最后一行):
| 指标 | 数值 | 含义 |
|---|---|---|
| Precision § | 0.954 | 检出框 95.4% 是真缺陷 |
| Recall ® | 0.913 | 真实缺陷 91.3% 被找回 |
| mAP@0.5 | 0.964 | 综合精度指标,工业可用 |
| mAP@0.5:0.95 | 0.761 | 严格 IoU 下仍稳健 |
4.2 PR 曲线
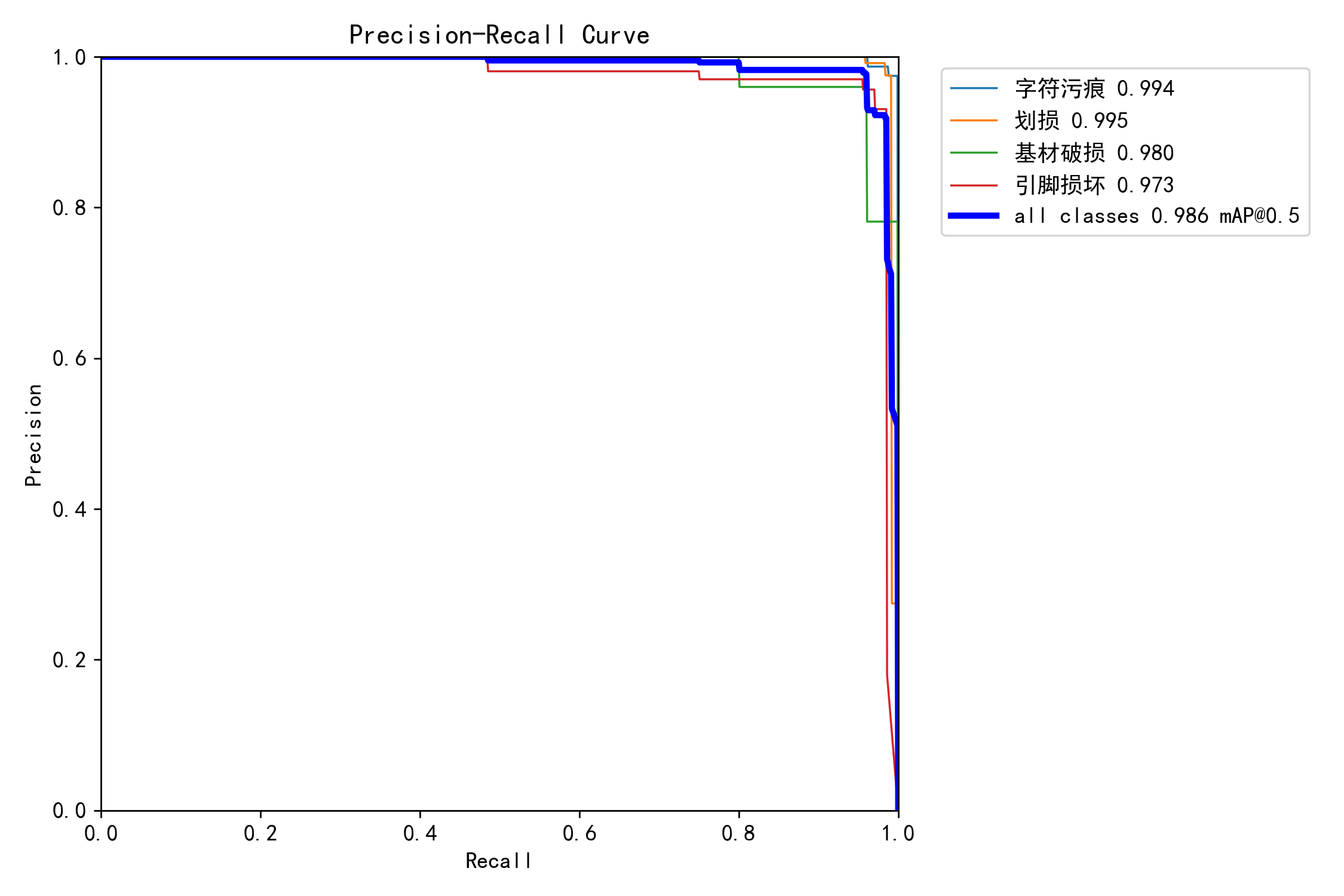
四类缺陷的 PR 曲线整体压在右上角,broken 和 scratch 接近 0.99,仅 ZF-scratch(小样本工艺特征)略低,符合数据分布预期。
4.3 归一化混淆矩阵
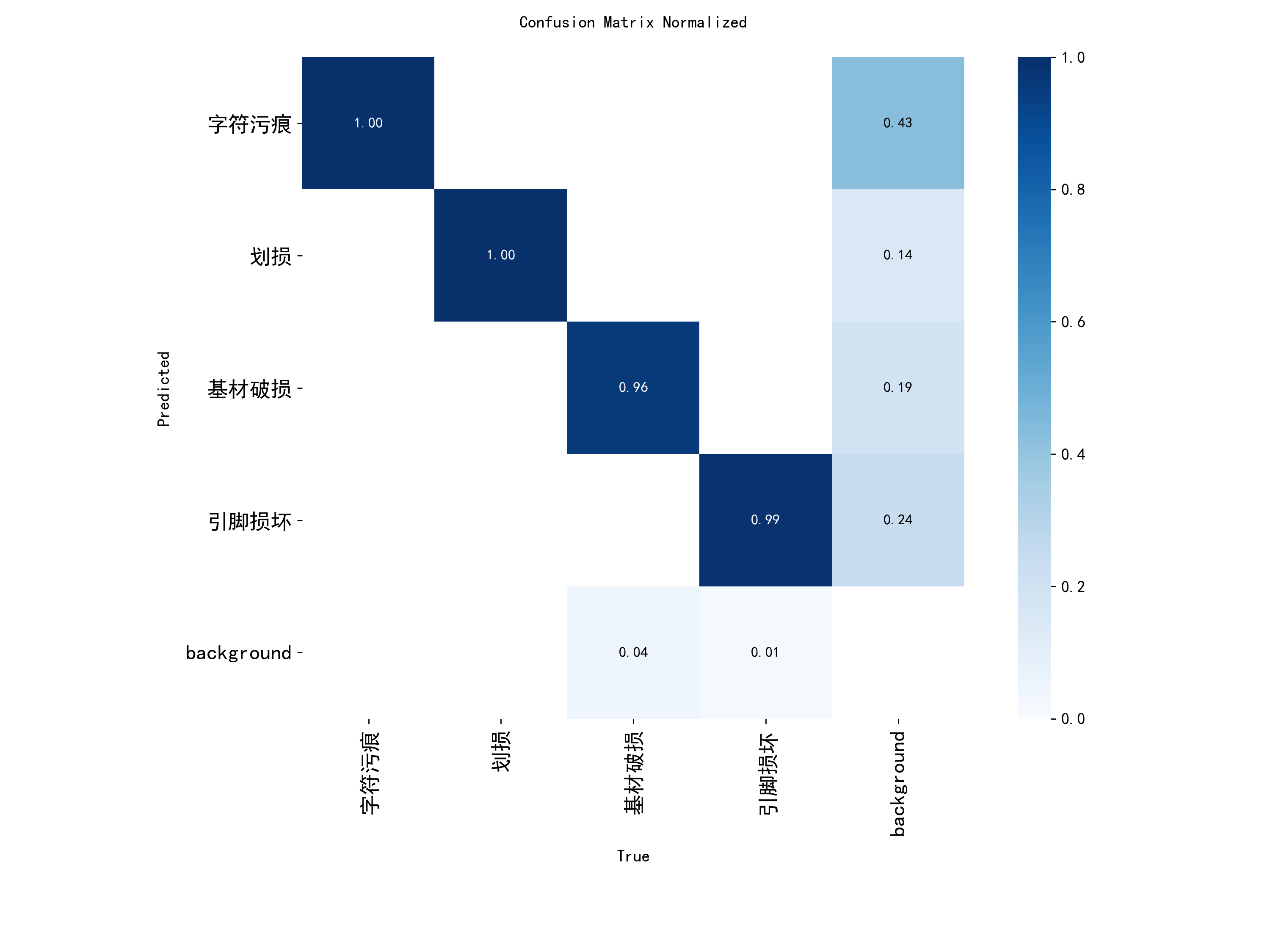
对角线全部高亮(>0.9),主要混淆集中在 ZF-scratch ↔ scratch 之间——这两类视觉特征本身就高度相似(都是划痕),对实际质检影响很小(同属"划伤"大类)。
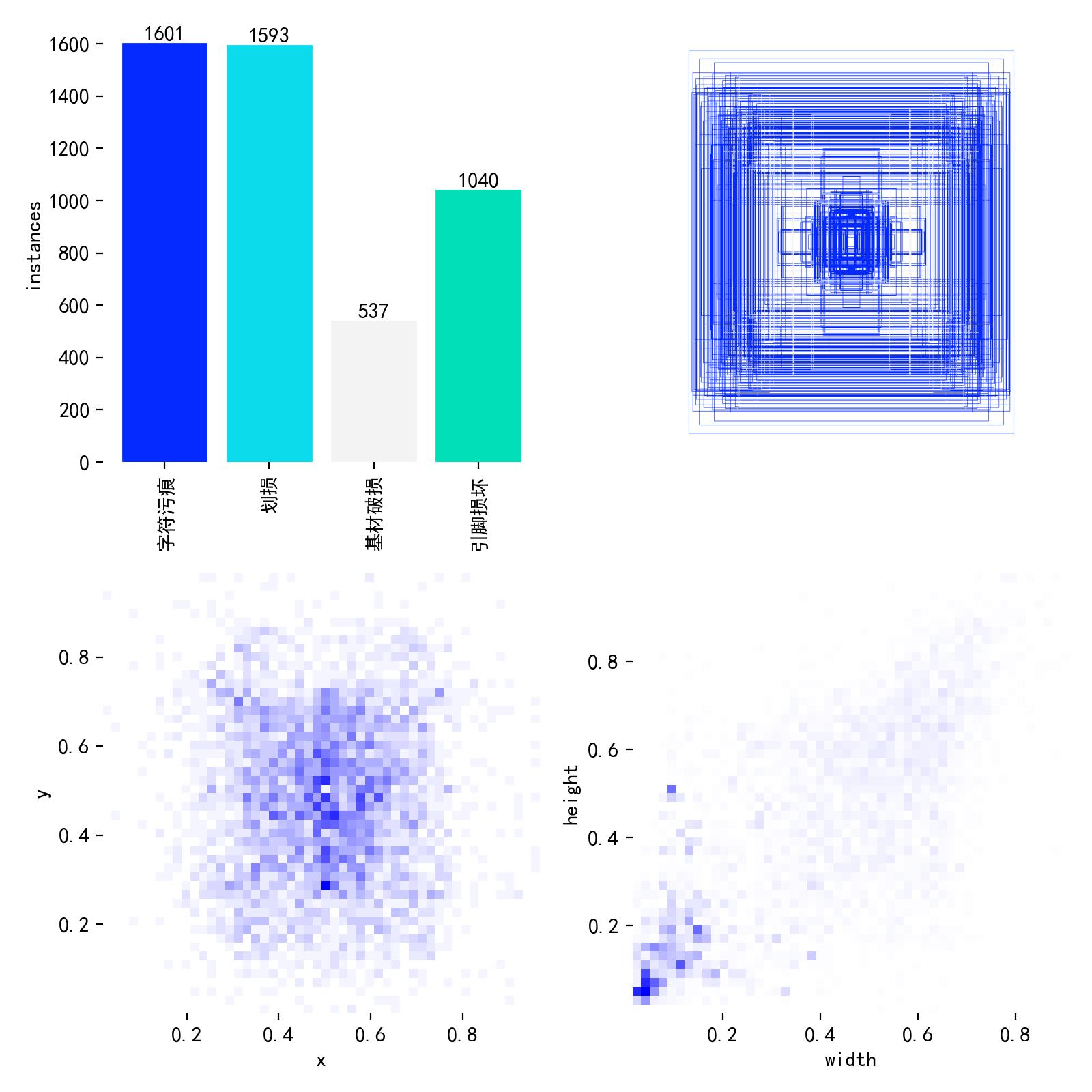
4.4 数据集分布与验证集预测
数据集类别 / 框尺寸 / 中心点分布:
五、项目总结
做对了什么:
- 配置驱动 + 模板化——
project.yaml把行业话术、UI 主题、推理参数全部抽离,新增半导体之外的行业只换数据集和文案即可复用。 - YOLO11n 选型踏实——单图 < 50 ms、模型 6 MB 量级,AOI 复检工位的 CPU 也能跑,部署门槛低。
- 数据真实 + 标注扎实——2500 张产线真实采集 + 工程师人工标注,最终 mAP@0.5 96.4% 不是堆 trick 堆出来的。
还能怎么做:
- 小样本 ZF-scratch 增强——对 ZF 系列划痕做离线数据增强(光照扰动、亮度抖动),把这一类的召回再提 2~3 个百分点;
- 接入产线 PLC 信号——批量分析页输出的"异常批次"直接联动产线节拍,触发停机/复检;
- 导出 ONNX/TensorRT——AOI 边缘盒一般用 Jetson 或工控机,导出 INT8 引擎可以把推理压到 10 ms 以内;
- 多视角融合——同一颗芯片同时拍正面 + 侧面 + 底面,三路一起喂模型,引脚断裂这种侧面才看得清的缺陷召回还能再提。
一句话总结:用 200 行 Streamlit + 一个 6 MB 的 YOLO11n 权重,把半导体封测线的人工复检变成"上传即看图"的工程化 Demo,mAP@0.5 = 96.4% 已经具备替代二次人工目检的实战价值。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 3
3 0
0- 0



 已为社区贡献197条内容
已为社区贡献197条内容

所有评论(0)