技术拆解(十):为什么你的大模型又慢又贵?搞懂量化原理、精度损失和 GPTQ/AWQ,推理成本直接砍半
一大模型中的精度
1.概念
精度在深度学习中通常指数值表示的类型(bit 数、指数/尾数分配)及其对模型效果的影响。主要分为 浮点类(用于训练和推理)和 整数类(主要用于推理量化)。
2.常见分类
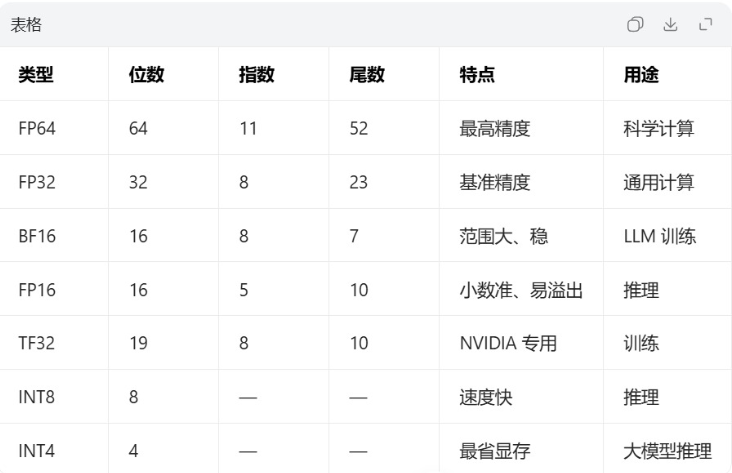
3.大模型训练各部分精度
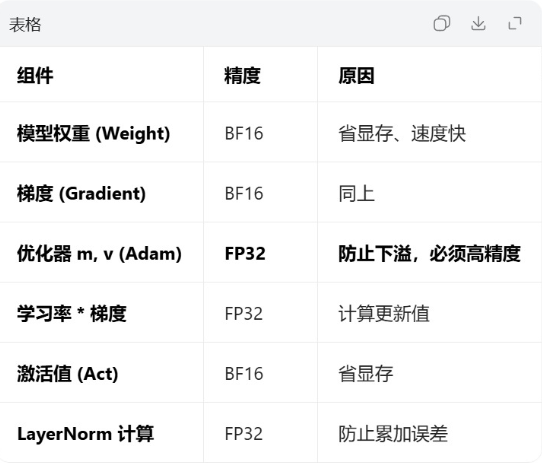
4. 浮点类(FP)—— 大模型训练的主力
浮点数能表示小数,动态范围广,适合梯度更新和权重累积。
4-1.FP32 (单精度)
结构:1位符号位 + 8位指数位 + 23位尾数位
特点:曾经的训练标准。数值范围广,精度高。
现状:在大模型训练中几乎不再单独使用。因为显存占用太大(4字节/参数),且现代硬件(如NVIDIA A100/H100)对FP16/BF16的算力远高于FP32。现在主要用于损失缩放(Loss Scaling)或模型副本的存储。
4-2.FP16 (半精度)
结构:1位符号位 + 5位指数位 + 10位尾数位。
特点:显存占用小(2字节/参数),算力高。
痛点:容易溢出。因为只有5位指数,数值范围较小(约 6.5×10−86.5×10−8 到 6.5×1046.5×104)。在训练大模型时,梯度一旦小于范围下限,就会下溢出变成0,导致训练失败。
现状:曾是混合精度训练的主流,现在正被BF16取代。
4-3.BF16 (Brain Floating Point) —— 当前训练的主流
结构:1位符号位 + 8位指数位 + 7位尾数位。
特点:指数位与FP32完全相同。
优势:它牺牲了精度(尾数少),但保留了与FP32相同的数值范围。这意味着在训练中,BF16不会像FP16那样容易溢出,且与FP32之间的转换几乎是无损的(范围上)。
现状:大模型预训练的首选精度。配合A100/H100等GPU,BF16混合精度训练既节省了显存(相比FP32减半),又保证了训练的稳定性。
选择BF16的原因
大模型训练时,梯度值经常非常小(如 1e-6 甚至更小),FP16 的最小可表示正数约 6×10⁻⁸,很容易 下溢出变成 0,导致模型无法收敛。BF16 牺牲了精度换来了与 FP32 同等的数值范围,从而避免了溢出问题,成为大模型训练的主流格式。
4-4.FP8 —— 新硬件的宠儿
结构:主要有两种变体——E4M3(4位指数,3位尾数,动态范围较小但精度较高)和E5M2(5位指数,2位尾数,动态范围较大但精度较低)。
现状:随着NVIDIA H100(Hopper架构)及Blackwell架构的普及,FP8开始用于大规模预训练和推理。它能让显存占用再减半,算力翻倍,但需要非常精细的缩放(Scaling)算法来防止精度丢失
4-5.FP4 / 更低精度
现状:主要用于推理。FP4是Blackwell架构(如GB200)主推的特性,用于在极低显存下运行超大模型(如405B参数模型),但训练阶段几乎不用,因为精度损失太大。
5.整数类(INT)—— 大模型推理(部署)的主力
整数只能表示整数,没有指数位,因此动态范围非常有限。它们通常用于量化(Quantization)。
5-1INT8
特点:范围 -128 到 127。
现状:成熟的推理精度。经过大量实践验证,将模型权重从FP16量化为INT8(W8A8,即权重8位、激活8位),在大部分任务上精度损失极小(约1%以内),但显存占用减半,吞吐量大幅提升。是目前云端部署的主流精度之一。
5-2 INT4
特点:范围 -8 到 7。
现状:消费级显卡和个人部署的首选。通过QLoRA(量化低秩适配器)等技术,甚至可以在24GB显存的显卡(如RTX 3090/4090)上运行130亿到700亿参数量的模型。
代表技术:GPTQ、AWQ、GGUF(ollama/llama.cpp常用)。虽然输出质量相比FP16有所下降(特别是逻辑推理能力),但对于聊天和文本生成场景性价比极高。
5-3INT2 / INT1 (二值化/三值化)
现状:处于学术研究阶段。将权重限制在 -1, 0, +1 或 0, 1。
瓶颈:虽然理论上能实现极高的压缩比(32倍/64倍),但目前在大规模商用大模型上精度坍塌严重,尚不成熟。
二量化
1.数学本质
一种有损压缩技术,将高精度浮点数(如 FP16、FP32)映射到低精度整数(如 INT8、INT4),从而降低显存占用、提高计算速度。
2.核心公式(以非对称量化为例):
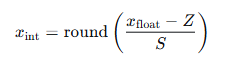
S(缩放因子):浮点数与整数之间的比例关系。
Z(零点):用于对齐数据分布的中心,非对称量化时 Z 不为 0;对称量化时 Z = 0。
3.分组量化(Group-wise Quantization)
为避免全局量化精度过低,将张量按某个维度切分(常见为 每组 128 个元素),每组独立分配一个缩放因子 S 和零点 Z。这样可以在精度与性能之间取得较好平衡。
4.大模型中的特殊问题——激活值离群点:
当模型参数规模超过某个阈值(如 6B、13B),激活值中会出现 大幅值的离群点(outliers)。若采用全局量化(基于整个张量的 min/max),这些离群点会拉大量化范围,导致其余正常激活值被压缩到极少几个整数(甚至 0 或 1),模型能力瞬间崩塌。解决思路:保护离群点。例如GPTQ、AWQ
三常见的量化方式
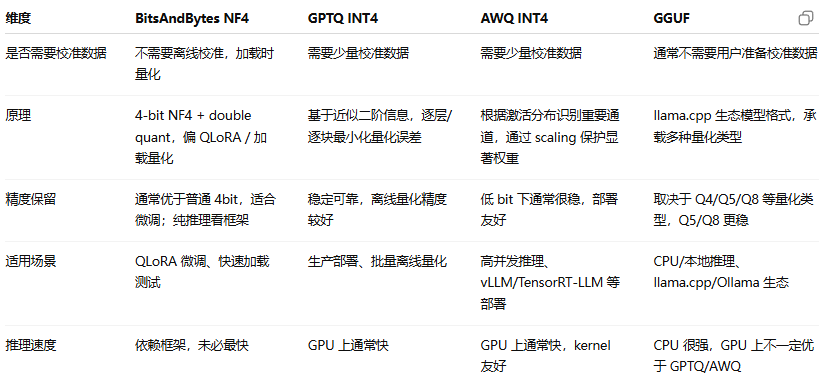
1.BitsAndBytes (NF4)
1-1核心原理:两阶段处理。先解决激活值中的"离群值"问题,再对权重进行高效压缩。
- 解决离群值 (LLM.int8()):研究发现大模型中存在少量但数值极大的离群激活值。若统一量化,会严重压缩其他激活值。LLM.int8() 采用混合精度分解法:在矩阵乘法前,算法会自动识别并分离出这些离群通道(通常 < 1%)以FP16高精度计算,其余正常通道则做INT8量化计算,最后将结果合并。从而在保证模型效果的同时大幅节省显存。
- 压缩权重 (NF4):对权重参数进行4-bit压缩。它观察到神经网络权重的分布近似于正态分布,中心密集、两端稀疏。传统的4-bit量化(如INT4)是均匀切分,造成中间精度浪费、两端精度不够。NF4正是为高能效的信息保真而生,它能精准地将更多的数值表示能力分配给权重最集中的区域,从而用最少的bit实现更高精度的压缩。
1-2优缺点
- 优点:开箱即用,集成简单;显存节省效果显著;是进行QLoRA微调的首选方案。
- 缺点:混合精度计算带来额外开销,推理速度通常慢于GPTQ/AWQ;在长上下文等复杂任务上精度损失可能更明显。
1-3适用场景:个人开发者/研究人员在消费级GPU上进行模型微调(QLoRA)。
2.GPTQ
2-1核心原理:"逐层量化 + 误差补偿",实现高精度的后训练量化。
【量化当前列时产生的误差,通过更新其他未量化的列来补偿,从而最小化整层输出的变化。】
- 逐列处理:将待量化层的权重矩阵视作列集合,并按列依次量化。
- 误差补偿:假设正在量化某一列,量化会产生误差。GPTQ会计算该误差,并将其补偿到该层中尚未被量化的其余权重列上。通过重构该层的输出,使整个量化过程对最终输出的影响最小化。
2-2优缺点
- 优点:应用范围最广,长期被验证,稳定性与可靠性极高;数学原理严谨,支持2-4 bit等低比特量化。
- 缺点:计算复杂,量化速度慢(量化70亿参数模型可能耗时35分钟以上),且对GPU显存需求高;对高质量校准数据要求较高。
2-3适用场景:对模型精度和稳定性要求极高的生产环境。批量进行模型量化任务,可接受较长时间的处理等待。
3.AWQ
3-1核心原理:"激活感知"+"重要权重保护"。【利用激活值分布识别并保护关键权重】
- 发现并非所有权重对模型性能都同等重要。它仅凭少量样本的激活值分布,就能判断出关键权重(仅占约1%)。这些关键权重承载着模型大部分输出,不适宜粗暴压缩。
- 因此量化时,会对关键权重进行"重点保护"(如保留为FP16),而对其他权重进行低比特量化。兼顾了压缩比和模型性能。
3-2优缺点
- 优点:精度保留效果优秀;推理速度快;对校准数据质量和数量要求不高。
- 缺点:作为较新的方法,其生态系统和框架支持度可能不如GPTQ成熟。
3-3适用场景:追求高精度与高效率平衡的高并发推理服务(尤其配合vLLM推理引擎)。难以获取高质量校准数据,或希望快速实现高性能部署的场景。
4.GGUF
4-1核心原理:一种综合性的模型文件格式,而非单一的量化算法。
GGUF 与其底层核心量化技术进行了深度集成,共同实现高效的模型压缩和执行。其核心策略是混合精度与分层量化。它会智能识别模型中的关键部分(如注意力层)分配更高精度,对非关键部分(如偏置项)采用低精度甚至极低精度。
4-2优缺点
- 优点:极佳的硬件兼容性,尤其对纯CPU运行进行了深度优化;提供丰富的量化等级(如2-8bit)供用户灵活选择。
- 缺点:在GPU上的性能通常不如GPTQ/AWQ等专门优化方案;主要应用在llama.cpp及其周边生态,通用性有限。
4-3适用场景:CPU推理和硬件资源严重受限的环境,如低配个人电脑、树莓派等边缘设备。llama.cpp、Ollama等本地大模型部署框架的原生格式。
5.对比总结
哲学视角
——“量化不是让模型遗忘世界,而是让模型学会用更少的符号保留世界。”
量化不是对智能的削弱,而是对“什么值得被保留”的一次判断:FP32 试图完整记录世界,BF16 学会在效率与稳定之间折中,INT4/INT8 则进一步承认——理解并不等于复刻全部细节。真正的智能,不在于用无限精度保存每一个数值,而在于能否在误差、压缩和丢失之中,仍然抓住世界最核心的结构。量化的哲学意义正在这里:少一点表示,不一定少一点理解;更低的精度,也可能是更高层次的抽象。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 33
33 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)