【扩散模型原理】(四)Diffusion Models Today: Score SDE Framework(2)
《扩散模型原理:从起源到发展》:第四章 扩散模型的今天:Score SDE 框架
专著:The Principles of Diffusion Models
上一章:【扩散模型原理】(四)Diffusion Models Today: Score SDE Framework(1)
4.3 随机微分方程的实例化(Instantiations of SDEs)
Song 等人依据演化过程中方差的变化特性,将正向随机微分方程中的漂移项 f ( x , t ) \mathbf{f}(\mathbf{x},t) f(x,t) 与扩散项 g ( t ) g(t) g(t) 划分为三类。本文重点介绍两种常用类型:方差爆炸型(Variance Explosion, VE)随机微分方程与方差保持型(Variance Preserving, VP)随机微分方程。尽管可自定义噪声调度器,但其设计会显著影响模型的实际性能。表 4.1 总结了这两种随机微分方程的具体形式。
Table 4.1 | 前向随机微分方程汇总:
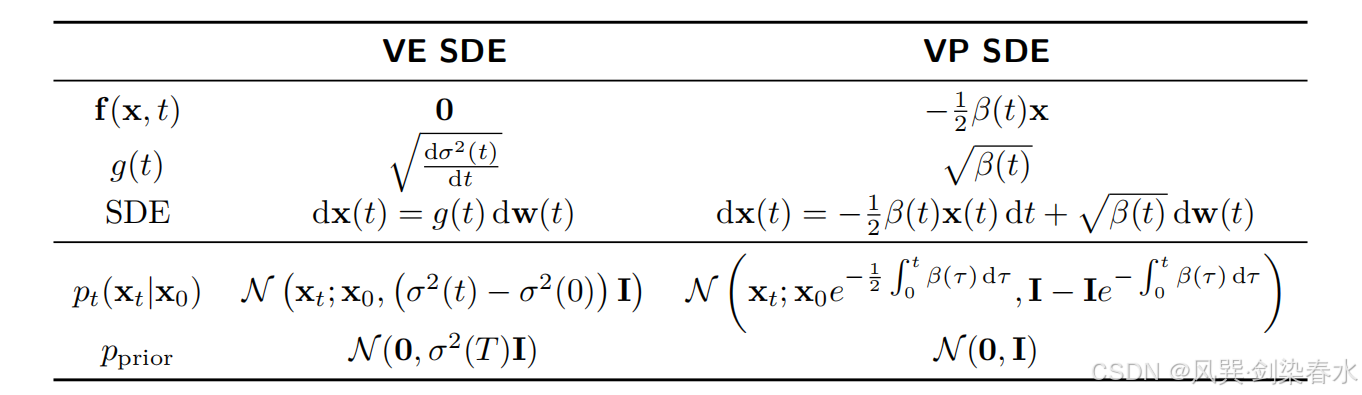
4.3.1 方差爆炸型随机微分方程(VE SDE)
方差爆炸型(VE)随机微分方程的构成如下:
(1)漂移项: 零漂移项, f = 0. \mathbf{f}=\mathbf{0}. f=0.
(2)扩散项: 对于函数 σ ( t ) \sigma(t) σ(t),满足 g ( t ) = d σ 2 ( t ) d t . g(t)=\sqrt{\frac{\mathrm{d}\sigma^2(t)}{\mathrm{d}t}}. g(t)=dtdσ2(t).
由此,正向随机微分方程可写为:
d x ( t ) = d σ 2 ( t ) d t d w ( t ) . (4.3.1) \mathrm{d}\mathbf{x}(t)=\sqrt{\frac{\mathrm{d}\sigma^2(t)}{\mathrm{d}t}}\mathrm{d}\mathbf{w}(t).\tag{4.3.1} dx(t)=dtdσ2(t)dw(t).(4.3.1)同理,4.3.3 节的结论给出了方差爆炸型随机微分方程的扰动核,并给出先验分布的选取方式:
(1)扰动核: p t ( x t ∣ x 0 ) = N ( x t ; x 0 , ( σ 2 ( t ) − σ 2 ( 0 ) ) I ) p_t(\mathbf{x}_t|\mathbf{x}_0)=\mathcal{N}\big(\mathbf{x}_t;\mathbf{x}_0,\big(\sigma^2(t)-\sigma^2(0)\big)\mathbf{I}\big) pt(xt∣x0)=N(xt;x0,(σ2(t)−σ2(0))I)
(2)先验分布: 设 σ ( t ) \sigma(t) σ(t) 为 t ∈ [ 0 , T ] t\in[0,T] t∈[0,T] 上的增函数,且满足 σ 2 ( T ) ≫ σ 2 ( 0 ) \sigma^2(T)\gg\sigma^2(0) σ2(T)≫σ2(0),则先验分布为:
p prior : = N ( 0 , σ 2 ( T ) I ) . p_{\text{prior}}:=\mathcal{N}\big(\mathbf{0},\sigma^2(T)\mathbf{I}\big). pprior:=N(0,σ2(T)I).
方差爆炸型(VE)随机微分方程的典型实现为 NCSN 模型,其设计形式如下:
σ ( t ) : = σ min ( σ max σ min ) t , t ∈ ( 0 , 1 ] , \sigma(t):=\sigma_{\min}\left(\frac{\sigma_{\max}}{\sigma_{\min}}\right)^t,\quad t\in(0,1], σ(t):=σmin(σminσmax)t,t∈(0,1],其中 σ min \sigma_{\min} σmin 与 σ max \sigma_{\max} σmax 为预设常数。该方差序列为等比数列,因此如 4.1.1 节所述,NCSN 可视为方差爆炸型随机微分方程的离散化版本。
4.3.2 方差保持型随机微分方程(VP SDE)
设 β : [ 0 , T ] → R ≥ 0 \beta: [0,T] \to \mathbb{R}_{\ge 0} β:[0,T]→R≥0 为 t t t 的非负函数。方差保持型(VP)随机微分方程的定义包含以下部分:
(1)漂移项: 线性漂移项,形式为 f ( x , t ) = − 1 2 β ( t ) x . \boldsymbol{f}(\mathbf{x},t) = -\frac{1}{2}\beta(t)\mathbf{x}. f(x,t)=−21β(t)x.
(2)扩散项: g ( t ) = β ( t ) . g(t) = \sqrt{\beta(t)}. g(t)=β(t).
由此,正向随机微分方程可写为:
d x ( t ) = − 1 2 β ( t ) x ( t ) d t + β ( t ) d w ( t ) . (4.3.2) \mathrm{d}\mathbf{x}(t) = -\frac{1}{2}\beta(t)\mathbf{x}(t)\,\mathrm{d}t + \sqrt{\beta(t)}\,\mathrm{d}\mathbf{w}(t). \tag{4.3.2} dx(t)=−21β(t)x(t)dt+β(t)dw(t).(4.3.2) 利用第 4.3.3 节的结论,可推导方差保持型随机微分方程的扰动核,并选取合适的先验分布:
(1)扰动核: p t ( x t ∣ x 0 ) = N ( x t ; x 0 e − 1 2 ∫ 0 t β ( τ ) d τ , I − I e − ∫ 0 t β ( τ ) d τ ) . p_t(\mathbf{x}_t|\mathbf{x}_0) = \mathcal{N}\left(\mathbf{x}_t;\ \mathbf{x}_0 e^{-\frac{1}{2}\int_0^t \beta(\tau)\,\mathrm{d}\tau},\ \mathbf{I} - \mathbf{I}e^{-\int_0^t \beta(\tau)\,\mathrm{d}\tau}\right). pt(xt∣x0)=N(xt; x0e−21∫0tβ(τ)dτ, I−Ie−∫0tβ(τ)dτ).
(2)先验分布: p prior : = N ( 0 , I ) . p_{\text{prior}} := \mathcal{N}(\mathbf{0},\mathbf{I}). pprior:=N(0,I).
由于该扰动核为均值与协方差均已知的高斯分布,可通过式 (D.2.5) 计算其得分函数。
方差保持型(VP)随机微分方程的经典实例为 DDPM 模型,其噪声调度函数 β ( t ) \beta(t) β(t) 定义为:
β ( t ) : = β min + t ( β max − β min ) , ∀ t ∈ [ 0 , 1 ] . \beta(t) := \beta_{\min} + t(\beta_{\max} - \beta_{\min}), \quad \forall t \in [0,1]. β(t):=βmin+t(βmax−βmin),∀t∈[0,1].其中 β min \beta_{\min} βmin 与 β max \beta_{\max} βmax 为预设常数。如 4.1.1 节所述,在此设定下,DDPM 可被理解为该方差保持型随机微分方程的离散化形式。
4.3.3 (可选)扰动核 p t ( x t ∣ x 0 ) p_t(\mathbf{x}_t|\mathbf{x}_0) pt(xt∣x0) 如何推导?((Optional) How Is the Perturbation Kernel p t ( x t ∣ x 0 ) p_t(\mathbf{x}_t|\mathbf{x}_0) pt(xt∣x0) Derived?)
若正向随机微分方程(式 (4.1.3))中的漂移项关于 x \mathbf{x} x 为线性,即满足形式:
f ( x , t ) = f ( t ) x , \mathbf{f}(\mathbf{x},t) = f(t)\mathbf{x}, f(x,t)=f(t)x,其中 f ( t ) ∈ R f(t)\in\mathbb{R} f(t)∈R 为标量值时变函数,则式 (4.1.3) 退化为线性随机微分方程:
d x ( t ) = f ( t ) x ( t ) d t + g ( t ) d w ( t ) . \mathrm{d}\mathbf{x}(t) = f(t)\mathbf{x}(t)\mathrm{d}t + g(t)\mathrm{d}\mathbf{w}(t). dx(t)=f(t)x(t)dt+g(t)dw(t). 即使初始分布 p data p_{\text{data}} pdata 非高斯,漂移项的线性特性仍可保证条件过程始终为高斯分布。特别地,对于 t > 0 t>0 t>0,其转移核具有如下形式:
p t ( x t ∣ x 0 ) = N ( x t ; m ( t ) , P ( t ) I D ) , p_t(\mathbf{x}_t|\mathbf{x}_0) = \mathcal{N}\big(\mathbf{x}_t; \mathbf{m}(t), P(t)\mathbf{I}_D\big), pt(xt∣x0)=N(xt;m(t),P(t)ID),其中 x 0 ∼ p data \mathbf{x}_0\sim p_{\text{data}} x0∼pdata, m ( t ) ∈ R D \mathbf{m}(t)\in\mathbb{R}^D m(t)∈RD 与 P ( t ) ∈ R ≥ 0 P(t)\in\mathbb{R}_{\ge0} P(t)∈R≥0 分别表示给定 x 0 \mathbf{x}_0 x0 时的条件均值与(标量)方差,定义为:
m ( t ) = E [ x t ∣ x ( 0 ) = x 0 ] , P ( t ) I D = C o v [ x t ∣ x ( 0 ) = x 0 ] . \mathbf{m}(t) = \mathbb{E}\left[\mathbf{x}_t \,\big|\, \mathbf{x}(0)=\mathbf{x}_0\right], \quad P(t)\mathbf{I}_D = \mathrm{Cov}\left[\mathbf{x}_t \,\big|\, \mathbf{x}(0)=\mathbf{x}_0\right]. m(t)=E[xt
x(0)=x0],P(t)ID=Cov[xt
x(0)=x0].
线性漂移保证了前向过程是 “确定性线性演化” 与 “高斯噪声卷积” 的叠加,而高斯分布在线性运算下具有封闭性,因此条件转移核永远保持高斯形态,与真实数据的初始分布形态无关。
根据 Särkkä 与 Solin(2019)的结论,上述一阶与二阶矩满足如下常微分方程(初始均值 m ( 0 ) \mathbf{m}(0) m(0) 与方差 P ( 0 ) P(0) P(0) 有限时成立):
{ d m ( t ) d t = f ( t ) m ( t ) , d P ( t ) d t = 2 f ( t ) P ( t ) + g 2 ( t ) , (4.3.3) \begin{cases} \displaystyle \frac{\mathrm{d}\mathbf{m}(t)}{\mathrm{d}t} = f(t)\mathbf{m}(t), \\[1.5ex] \displaystyle \frac{\mathrm{d}P(t)}{\mathrm{d}t} = 2f(t)P(t) + g^2(t), \end{cases} \tag{4.3.3} ⎩
⎨
⎧dtdm(t)=f(t)m(t),dtdP(t)=2f(t)P(t)+g2(t),(4.3.3)
由于两个常微分方程均为线性,可通过积分因子法求得闭式解。给定初始条件 x 0 \mathbf{x}_0 x0,均值与方差的演化形式为:
m ( t ) = E ( 0 → t ) x 0 , P ( t ) = ∫ 0 t E 2 ( s → t ) g ( s ) 2 d s , (4.3.4) \mathbf{m}(t) = \mathcal{E}(0 \to t)\mathbf{x}_0,\quad P(t) = \int_0^t \mathcal{E}^2(s \to t)g(s)^2\,\mathrm{d}s, \tag{4.3.4} m(t)=E(0→t)x0,P(t)=∫0tE2(s→t)g(s)2ds,(4.3.4)其中 m ( 0 ) = x 0 \mathbf{m}(0)=\mathbf{x}_0 m(0)=x0, P ( 0 ) = 0 P(0)=0 P(0)=0。此处 E ( s → t ) \mathcal{E}(s\to t) E(s→t) 为指数积分因子,定义为:
E ( s → t ) : = exp ( ∫ s t f ( u ) d u ) , \mathcal{E}(s \to t) := \exp\left(\int_s^t f(u)\,\mathrm{d}u\right), E(s→t):=exp(∫stf(u)du),其物理意义为漂移项从时刻 s s s 到 t t t 的累积效应。由此,转移核 p t ( x t ∣ x 0 ) p_t(\mathbf{x}_t|\mathbf{x}_0) pt(xt∣x0) 也存在闭式表达式。

在具有独立分量且扩散矩阵为 g ( t ) I D g(t)\mathbf{I}_D g(t)ID 的 D D D 维维纳过程下,条件分布 p t ( x t ∣ x 0 ) p_t(\mathbf{x}_t|\mathbf{x}_0) pt(xt∣x0) 的条件协方差具有各向同性(即 C o v [ x t ∣ x 0 ] = P ( t ) I D \mathrm{Cov}[\mathbf{x}_t|\mathbf{x}_0] = P(t)\mathbf{I}_D Cov[xt∣x0]=P(t)ID),以及式 (4.3.3) 的推导过程均依赖伊藤积分,相关证明将在 C.1.5 节给出。
示例:方差爆炸型(VE)SDE 的转移核
在方差爆炸型(VE)随机微分方程的特殊情形下:漂移项 f ≡ 0 \mathbf{f} \equiv \mathbf{0} f≡0,扩散项 g ( t ) = d σ 2 ( t ) d t g(t) = \sqrt{\frac{\mathrm{d}\sigma^2(t)}{\mathrm{d}t}} g(t)=dtdσ2(t),其解的均值与协方差演化如下:
均值:
d m ( t ) d t = 0 , m ( 0 ) = x 0 ⟹ m ( t ) = x 0 . \frac{\mathrm{d}\mathbf{m}(t)}{\mathrm{d}t} = \mathbf{0}, \quad \mathbf{m}(0) = \mathbf{x}_0 \implies \mathbf{m}(t) = \mathbf{x}_0. dtdm(t)=0,m(0)=x0⟹m(t)=x0. 方差:
d P ( t ) d t = d σ 2 ( t ) d t , P ( 0 ) = 0 ⟹ P ( t ) = σ 2 ( t ) − σ 2 ( 0 ) . \frac{\mathrm{d}P(t)}{\mathrm{d}t} = \frac{\mathrm{d}\sigma^2(t)}{\mathrm{d}t}, \quad P(0) = 0 \implies P(t) = \sigma^2(t) - \sigma^2(0). dtdP(t)=dtdσ2(t),P(0)=0⟹P(t)=σ2(t)−σ2(0).因此,转移核为:
p t ( x t ∣ x 0 ) = N ( x t ; x 0 , ( σ 2 ( t ) − σ 2 ( 0 ) ) I D ) . p_t(\mathbf{x}_t|\mathbf{x}_0) = \mathcal{N}\left(\mathbf{x}_t; \mathbf{x}_0, \left(\sigma^2(t) - \sigma^2(0)\right)\mathbf{I}_D\right). pt(xt∣x0)=N(xt;x0,(σ2(t)−σ2(0))ID).
示例:方差保持型(VP)SDE 的转移核
在方差保持型(VP)随机微分方程中,漂移项为 f ( x , t ) = − 1 2 β ( t ) x \mathbf{f}(\mathbf{x},t) = -\frac{1}{2}\beta(t)\mathbf{x} f(x,t)=−21β(t)x,扩散项为 g ( t ) = β ( t ) g(t) = \sqrt{\beta(t)} g(t)=β(t):
均值 m ( t ) \mathbf{m}(t) m(t):
d m d t = − 1 2 β ( t ) m ( t ) , B ( t ) : = ∫ 0 t β ( s ) d s , m ( t ) = e − 1 2 B ( t ) x 0 . \frac{\mathrm{d}\mathbf{m}}{\mathrm{d}t} = -\frac{1}{2}\beta(t)\mathbf{m}(t), \quad B(t) := \int_0^t \beta(s)\,\mathrm{d}s, \quad \mathbf{m}(t) = e^{-\frac{1}{2}B(t)}\mathbf{x}_0. dtdm=−21β(t)m(t),B(t):=∫0tβ(s)ds,m(t)=e−21B(t)x0.方差 P ( t ) P(t) P(t):
方差满足方程
d P d t = − β ( t ) P ( t ) + β ( t ) . \frac{\mathrm{d}P}{\mathrm{d}t} = -\beta(t)P(t) + \beta(t). dtdP=−β(t)P(t)+β(t).利用积分因子 e B ( t ) e^{B(t)} eB(t)(其中 B ( t ) = ∫ 0 t β ( s ) d s B(t) = \int_0^t \beta(s)\,\mathrm{d}s B(t)=∫0tβ(s)ds),可得:
d d t [ P ( t ) e B ( t ) ] = β ( t ) e B ( t ) . \frac{\mathrm{d}}{\mathrm{d}t}\left[P(t)e^{B(t)}\right] = \beta(t)e^{B(t)}. dtd[P(t)eB(t)]=β(t)eB(t).对两边积分,解得:
P ( t ) = 1 − e − B ( t ) . P(t) = 1 - e^{-B(t)}. P(t)=1−e−B(t).因此,协方差为各向同性,形式为:
P ( t ) = P ( t ) I D = ( 1 − e − B ( t ) ) I D . \mathbf{P}(t) = P(t)\mathbf{I}_D = \left(1 - e^{-B(t)}\right)\mathbf{I}_D. P(t)=P(t)ID=(1−e−B(t))ID. 最终闭式转移核:
p t ( x t ∣ x 0 ) = N ( x t ; e − 1 2 B ( t ) x 0 ⏟ m ( t ) , ( 1 − e − B ( t ) ) I D ⏟ P ( t ) I D ) , B ( t ) = ∫ 0 t β ( s ) d s . p_t(\mathbf{x}_t \mid \mathbf{x}_0) = \mathcal{N}\left(\mathbf{x}_t; \underbrace{e^{-\frac{1}{2}B(t)}\mathbf{x}_0}_{\mathbf{m}(t)}, \underbrace{\left(1 - e^{-B(t)}\right)\mathbf{I}_D}_{P(t)\mathbf{I}_D}\right), \quad B(t) = \int_0^t \beta(s)\,\mathrm{d}s. pt(xt∣x0)=N
xt;m(t)
e−21B(t)x0,P(t)ID
(1−e−B(t))ID
,B(t)=∫0tβ(s)ds.
均值按指数衰减(记忆褪色),方差从 0 增长到 1(噪声接管),两者共同构成了一个完全可解析计算的、随时间变化的高斯分布,这就是 VP SDE 的转移核。
4.4 (可选)重新思考基于得分与变分扩散模型中的前向核((Optional) Rethinking Forward Kernels in Score-Based and Variational Diffusion Models)
DDPM 与 Score SDE 通常通过正向转移核 p ( x t ∣ x t − Δ t ) p(\mathbf{x}_t|\mathbf{x}_{t-\Delta t}) p(xt∣xt−Δt) 引入:其中 DDPM 采用离散定义形式,而 Score SDE 采用连续时间随机微分方程形式。但在实际应用中,尤其是二者的损失函数(式 (2.2.8) 与式 (4.2.1))中,真正关键的是从原始数据累积得到的转移核 p t ( x t ∣ x 0 ) p_t(\mathbf{x}_t|\mathbf{x}_0) pt(xt∣x0)。两种框架最终均依赖该转移核,其中 DDPM 通过递归计算实现,而得分随机微分方程则如 4.3.3 节所述,通过求解常微分方程得到。
本节将首先定义连续时间下的 p t ( x t ∣ x 0 ) p_t(\mathbf{x}_t|\mathbf{x}_0) pt(xt∣x0),以提供更简洁、直接的视角。总体而言,尽管 p ( x t ∣ x t − Δ t ) p(\mathbf{x}_t|\mathbf{x}_{t-\Delta t}) p(xt∣xt−Δt) 与 p t ( x t ∣ x 0 ) p_t(\mathbf{x}_t|\mathbf{x}_0) pt(xt∣x0) 在理论上等价,但定义后者往往能得到更清晰、更具可解释性的形式。特别地, p t ( x t ∣ x 0 ) p_t(\mathbf{x}_t|\mathbf{x}_0) pt(xt∣x0) 可直接揭示 t → T t\to T t→T 时的先验分布特性,且与实际损失函数的设计天然契合。
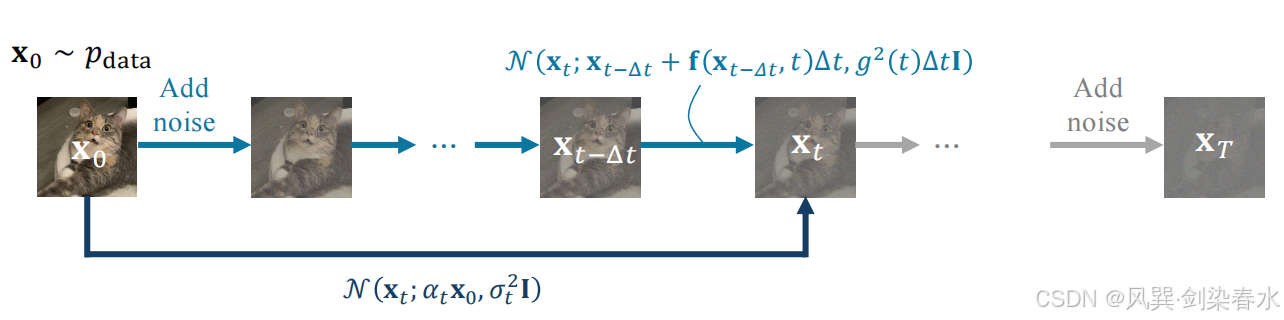
Figure 4.6 | 引理 4.4.1 示意图:当步长 Δ t → 0 \Delta t \to 0 Δt→0 时,基于连续时间随机微分方程的增量式噪声注入,与式 (4.4.1) 中的直接扰动在数学上等价。
4.4.1 一般仿射前向过程 p t ( x t ∣ x 0 ) p_t(\mathbf{x}_t|\mathbf{x}_0) pt(xt∣x0)(A General Affine Forward Process p t ( x t ∣ x 0 ) p_t(\mathbf{x}_t|\mathbf{x}_0) pt(xt∣x0))
首先定义一般形式的正向扰动核:
p t ( x t ∣ x 0 ) : = N ( x t ; α t x 0 , σ t 2 I ) , (4.4.1) p_t(\mathbf{x}_t|\mathbf{x}_0) := \mathcal{N}(\mathbf{x}_t; \alpha_t \mathbf{x}_0, \sigma_t^2 \mathbf{I}), \tag{4.4.1} pt(xt∣x0):=N(xt;αtx0,σt2I),(4.4.1)其中 x 0 ∼ p data \mathbf{x}_0 \sim p_{\text{data}} x0∼pdata, α t \alpha_t αt、 σ t \sigma_t σt 为 t ∈ [ 0 , T ] t \in [0,T] t∈[0,T] 的非负标量函数,满足:
(i) 对所有 t ∈ ( 0 , 1 ] t \in (0,1] t∈(0,1], α t > 0 \alpha_t > 0 αt>0 且 σ t > 0 \sigma_t > 0 σt>0(允许 σ 0 = 0 \sigma_0 = 0 σ0=0);
(ii) 通常取 α 0 = 1 \alpha_0 = 1 α0=1 且 σ 0 = 0 \sigma_0 = 0 σ0=0。
也就是说,从 p t ( x t ∣ x 0 ) p_t(\mathbf{x}_t|\mathbf{x}_0) pt(xt∣x0) 中采样得到的 x t \mathbf{x}_t xt 可表示为:
x t = α t x 0 + σ t ϵ , ϵ ∼ N ( 0 , I ) . \textcolor{dodgerblue}{\mathbf{x}_t = \alpha_t \mathbf{x}_0 + \sigma_t \boldsymbol{\epsilon}, \quad \boldsymbol{\epsilon} \sim \mathcal{N}(\mathbf{0}, \mathbf{I}).} xt=αtx0+σtϵ,ϵ∼N(0,I). 该框架涵盖了多种经典模型,包括:方差爆炸型(VE,如 NCSN)、方差保持型(VP,如 DDPM)以及流匹配(FM)正向核(Lipman 等人,2022;Liu, 2022),后者通过在 x 0 \mathbf{x}_0 x0 与 ϵ \boldsymbol{\epsilon} ϵ 间进行线性插值实现(详见第 5.2 节)。
方差爆炸型(NCSN)核: α t ≡ 1 \alpha_t \equiv 1 αt≡1,且 σ T ≫ 1 \sigma_T \gg 1 σT≫1;
方差保持型(DDPM)核:定义 α t : = 1 − σ t 2 \alpha_t := \sqrt{1-\sigma_t^2} αt:=1−σt2,满足 α t 2 + σ t 2 = 1 \alpha_t^2 + \sigma_t^2 = 1 αt2+σt2=1;
流匹配(FM)核: α t = 1 − t \alpha_t = 1-t αt=1−t, σ t = t \sigma_t = t σt=t。
4.4.2 与得分随机微分方程的联系(Connection to Score SDE)
对于 Score SDE,将 p t ( x t ∣ x 0 ) p_t(\mathbf{x}_t|\mathbf{x}_0) pt(xt∣x0) 指定为线性形式,可自然导出具有仿射系数的随机微分方程。这为研究提供了一种比 “从漂移项和扩散项出发、求解矩的常微分方程” 更直观的替代方案(详见 4.3.3 节)。
给定式 (4.4.1) 中的正向扰动核,对应的正向随机微分方程具有如式 (4.3.2) 所示的关于 x \mathbf{x} x 的线性形式:
d x ( t ) = f ( t ) x ( t ) ⏟ f ( x ( t ) , t ) d t + g ( t ) d w ( t ) , \mathrm{d}\mathbf{x}(t) = \underbrace{f(t)\mathbf{x}(t)}_{\mathbf{f}(\mathbf{x}(t),t)} \mathrm{d}t + g(t)\mathrm{d}\mathbf{w}(t), dx(t)=f(x(t),t)
f(t)x(t)dt+g(t)dw(t),其中 f , g : [ 0 , T ] → R f,g: [0,T] \to \mathbb{R} f,g:[0,T]→R 为时间的实值函数。系数 f ( t ) f(t) f(t) 和 g ( t ) g(t) g(t) 可通过 α t \alpha_t αt 和 σ t \sigma_t σt 解析表达,具体形式将在以下引理中给出。

若要在终止时刻精确匹配高斯先验分布,演化过程需要完全消除对初值 x 0 \mathbf{x}_0 x0 的依赖并收敛至目标方差;该条件等价于 α T = 0 \alpha_T=0 αT=0,且 σ T 2 \sigma_T^2 σT2 与先验方差相等。在随机微分方程体系中,系数满足: α t = exp ( ∫ 0 t f ( u ) d u ) \alpha_t = \exp\left(\int_0^t f(u)\,\mathrm{d}u\right) αt=exp(∫0tf(u)du) 因此在有限终止时刻 T T T 强制约束 α T = 0 \alpha_T=0 αT=0,则要求
∫ 0 T f ( u ) d u = − ∞ \int_0^T f(u)\,\mathrm{d}u = -\infty ∫0Tf(u)du=−∞意味着当 t → T t\to T t→T 时,漂移项需要以无穷快的速率做收缩变换。与此同时,为维持既定方差,扩散项必须趋于发散,对应关系式: g 2 ( t ) = σ t 2 ′ − 2 α t ′ α t σ t 2 → ∞ , t → T g^2(t) = \sigma_t^{2\prime} - 2\frac{\alpha_t'}{\alpha_t}\sigma_t^2 \to \infty,\quad t\to T g2(t)=σt2′−2αtαt′σt2→∞,t→T 倘若 f , g f,g f,g 在区间 [ 0 , T ] [0,T] [0,T] 上有界,则必然满足 α T > 0 \alpha_T>0 αT>0,过程会残存对初值 x 0 \mathbf{x}_0 x0 的依赖。此种情形下,模型仅能渐近逼近高斯先验:要么在 t → T t\to T t→T 的极限下无限靠近(无法严格取到),要么通过时间重参数化令 T → ∞ T\to\infty T→∞,在无穷时间尺度上精确收敛至目标先验。
要在有限时间内精确得到纯高斯噪声,需要过程在终点瞬间“狂暴”到无穷大,这不可能;所以实际扩散模型要么近似达到,要么用无穷长时间慢慢逼近。
由上述引理可得:通过含系数 f ( t ) f(t) f(t)、 g ( t ) g(t) g(t) 的线性随机微分方程定义增量式噪声注入,与利用参数 α t \alpha_t αt、 σ t \sigma_t σt 构造扰动核在数学上完全等价。在扩散模型相关文献中,这两种建模视角可互换使用。据此得到结论:
结论 4.4.1
定义扰动核 p t ( x t ∣ x 0 ) p_t(\mathbf{x}_t|\mathbf{x}_0) pt(xt∣x0),等价于确定线性随机微分方程的系数 f ( t ) f(t) f(t) 与 g ( t ) g(t) g(t)。
4.4.3 与基于变分的扩散模型的联系(Connection to Variational-Based Diffusion Model)
本节回顾由贝叶斯公式推导得到的 DDPM 核心恒等式:
p ( x t − Δ t ∣ x t , x ) = p ( x t ∣ x t − Δ t ) ⋅ p t − Δ t ( x t − Δ t ∣ x ) p t ( x t ∣ x ) , (4.4.3) p(\mathbf{x}_{t-\Delta t}|\mathbf{x}_t,\mathbf{x}) = p(\mathbf{x}_t|\mathbf{x}_{t-\Delta t})\cdot \frac{p_{t-\Delta t}(\mathbf{x}_{t-\Delta t}|\mathbf{x})}{p_t(\mathbf{x}_t|\mathbf{x})}, \tag{4.4.3} p(xt−Δt∣xt,x)=p(xt∣xt−Δt)⋅pt(xt∣x)pt−Δt(xt−Δt∣x),(4.4.3)该式对任意 x \mathbf{x} x(通常满足 x ∼ p data \mathbf{x}\sim p_{\text{data}} x∼pdata)成立。反向条件分布 p ( x t − Δ t ∣ x t , x ) p(\mathbf{x}_{t-\Delta t}|\mathbf{x}_t,\mathbf{x}) p(xt−Δt∣xt,x) 是建模的关键,既可构造易求解的训练目标,也能实现高效采样。
DDPM 一般先定义增量转移核 p ( x t ∣ x t − Δ t ) p(\mathbf{x}_t|\mathbf{x}_{t-\Delta t}) p(xt∣xt−Δt),但累积形式转移核 p t ( x t ∣ x 0 ) p_t(\mathbf{x}_t|\mathbf{x}_0) pt(xt∣x0) 的表达式具备更好的可解释性与实用性,在先验构造、损失函数设计中优势尤为突出。
转移核推导
下面将结论拓展至连续时间框架。设 0 ≤ t < s ≤ T 0\le t<s\le T 0≤t<s≤T 为两个连续时刻,在已知扰动核 p t ( x t ∣ x 0 ) p_t(\mathbf{x}_t|\mathbf{x}_0) pt(xt∣x0) 的前提下,以正向转移核 p ( x s ∣ x t ) p(\mathbf{x}_s|\mathbf{x}_t) p(xs∣xt) 作为中间项、套用式 (4.4.3),即可对任意 x \mathbf{x} x 求解反向条件分布 p ( x t ∣ x s , x ) p(\mathbf{x}_t|\mathbf{x}_s,\mathbf{x}) p(xt∣xs,x)。下述引理归纳该推导过程,它在不附加约束 α t 2 + σ t 2 = 1 \alpha_t^2+\sigma_t^2=1 αt2+σt2=1 的条件下对引理 2.2.2 做了推广。
尽管分步转移核 p ( x t + Δ t ∣ x t ) p(\mathbf{x}_{t+\Delta t}|\mathbf{x}_t) p(xt+Δt∣xt) 与累积转移核 p t ( x t ∣ x 0 ) p_t(\mathbf{x}_t|\mathbf{x}_0) pt(xt∣x0) 在理论上等价,但 p t ( x t ∣ x 0 ) p_t(\mathbf{x}_t|\mathbf{x}_0) pt(xt∣x0) 通常占据更核心的地位。式 (4.4.5) 中的分步转移主要用于推导反向核的闭式表达式。因此,近年相关研究(Kingma 等人,2021)出于表达式简洁、可解释性更强的考量,倾向于直接定义累积转移核 p t ( x t ∣ x 0 ) p_t(\mathbf{x}_t|\mathbf{x}_0) pt(xt∣x0)。
反向过程建模、训练与采样
第 2.2 节给出的训练目标(式 (2.2.13) 的证据下界 ELBO)与建模框架在本节广义设定下依旧成立。为行文清晰,参照 Kingma 等人 (2021) 的工作,采用原数据 x \mathbf{x} x 预测范式,网络记为 x ϕ ( x s , s ) \mathbf{x}_\phi(\mathbf{x}_s,s) xϕ(xs,s);依托式 (2.2.12) 的变换关系,与之等价的噪声 ϵ \boldsymbol{\epsilon} ϵ 预测范式(网络 ϵ ϕ ( x s , s ) \boldsymbol{\epsilon}_\phi(\mathbf{x}_s,s) ϵϕ(xs,s) )同样可行,满足:
x s = α s x ϕ ( x s , s ) + σ s ϵ ϕ ( x s , s ) , x s ∼ q s \mathbf{x}_s = \alpha_s \mathbf{x}_\phi(\mathbf{x}_s,s) + \sigma_s \boldsymbol{\epsilon}_\phi(\mathbf{x}_s,s),\quad \mathbf{x}_s\sim q_s xs=αsxϕ(xs,s)+σsϵϕ(xs,s),xs∼qs
建模与扩散损失 L diffusion \mathcal{L}_{\text{diffusion}} Ldiffusion。 与 DDPM 思路一致,依托式 (4.4.4) 的条件分布 p ( x t ∣ x s , x ) p(\mathbf{x}_t|\mathbf{x}_s,\mathbf{x}) p(xt∣xs,x),我们用可学习预测网络 x ϕ ( x s , s ) \mathbf{x}_\phi(\mathbf{x}_s,s) xϕ(xs,s) 替代原始干净信号 x \mathbf{x} x,得到参数化反向模型:
p ϕ ( x t ∣ x s ) : = N ( x t ; μ ϕ ( x s , s , t ) , σ 2 ( s , t ) I ) , (4.4.6) p_\phi(\mathbf{x}_t|\mathbf{x}_s):=\mathcal{N}\big(\mathbf{x}_t;\boldsymbol{\mu}_\phi(\mathbf{x}_s,s,t),\sigma^2(s,t)\mathbf{I}\big), \tag{4.4.6} pϕ(xt∣xs):=N(xt;μϕ(xs,s,t),σ2(s,t)I),(4.4.6)其中均值项参数化形式为:
μ ϕ ( x s , s , t ) = α s ∣ t σ t 2 σ s 2 x s + α t σ s ∣ t 2 σ s 2 x ϕ ( x s , s ) . \boldsymbol{\mu}_\phi(\mathbf{x}_s,s,t)=\frac{\alpha_{s|t}\sigma_t^2}{\sigma_s^2}\mathbf{x}_s+\frac{\alpha_t\sigma_{s|t}^2}{\sigma_s^2}\mathbf{x}_\phi(\mathbf{x}_s,s). μϕ(xs,s,t)=σs2αs∣tσt2xs+σs2αtσs∣t2xϕ(xs,s).结合式 (4.4.1) 正向扰动核,扩散损失 L diffusion ( x ; ϕ ) \mathcal{L}_{\text{diffusion}}(\mathbf{x};\phi) Ldiffusion(x;ϕ) 中的 KL 散度可化简为加权回归损失:
D K L ( p ( x t ∣ x s , x 0 ) ∥ p ϕ ( x t ∣ x s ) ) = 1 2 σ 2 ( s , t ) ∥ μ ( x s , x 0 ; s , t ) − μ ϕ ( x s , s , t ) ∥ 2 2 = 1 2 ( S N R ( t ) − S N R ( s ) ) ∥ x 0 − x ϕ ( x s , s ) ∥ 2 2 (4.4.7) \begin{aligned} \mathcal{D}_\mathrm{KL}\big(p(\mathbf{x}_t|\mathbf{x}_s,\mathbf{x}_0)\parallel p_\phi(\mathbf{x}_t|\mathbf{x}_s)\big) &=\frac{1}{2\sigma^2(s,t)}\big\|\boldsymbol{\mu}(\mathbf{x}_s,\mathbf{x}_0;s,t)-\boldsymbol{\mu}_\phi(\mathbf{x}_s,s,t)\big\|_2^2\\ &=\frac12\big(\mathrm{SNR}(t)-\mathrm{SNR}(s)\big)\big\|\mathbf{x}_0-\mathbf{x}_\phi(\mathbf{x}_s,s)\big\|_2^2\tag{4.4.7} \end{aligned} DKL(p(xt∣xs,x0)∥pϕ(xt∣xs))=2σ2(s,t)1
μ(xs,x0;s,t)−μϕ(xs,s,t)
22=21(SNR(t)−SNR(s))
x0−xϕ(xs,s)
22(4.4.7)式中 x s = α s x 0 + σ s ϵ \mathbf{x}_s=\alpha_s\mathbf{x}_0+\sigma_s\boldsymbol{\epsilon} xs=αsx0+σsϵ, x 0 ∼ p d a t a , ϵ ∼ N ( 0 , I ) \mathbf{x}_0\sim p_\mathrm{data},\boldsymbol{\epsilon}\sim\mathcal{N}(\mathbf 0,\mathbf I) x0∼pdata,ϵ∼N(0,I); S N R ( s ) : = α s 2 / σ s 2 \mathrm{SNR}(s):=\alpha_s^2/\sigma_s^2 SNR(s):=αs2/σs2 代表时刻 s s s 处的信噪比。
Kingma 等人(2021)研究了式 (4.4.7) 在 t → s t\to s t→s 下的连续时间极限,得到:
L V D M ∞ ( x 0 ) = − 1 2 E s , ϵ ∼ N ( 0 , I ) [ S N R ′ ( s ) ∥ x 0 − x ϕ ( x s , s ) ∥ 2 2 ] \mathcal{L}_\mathrm{VDM}^\infty(\mathbf{x}_0) = -\frac12 \mathbb{E}_{s,\boldsymbol{\epsilon}\sim\mathcal{N}(\mathbf 0,\mathbf I)}\big[\mathrm{SNR}'(s)\big\|\mathbf{x}_0-\mathbf{x}_\phi(\mathbf{x}_s,s)\big\|_2^2\big] LVDM∞(x0)=−21Es,ϵ∼N(0,I)[SNR′(s) x0−xϕ(xs,s) 22]该框架引入了可学习噪声调度方案,模型可拓展至连续型数据以外的场景,但相关拓展内容不在本文的讨论范围内。
采样。 依托式 (4.4.6) 的参数化条件分布,采样流程与 DDPM 保持一致:
x t = α s ∣ t σ t 2 σ s 2 x s + α t σ s ∣ t 2 σ s 2 x ϕ × ( x s , s ) ⏟ μ ϕ × ( x s , t , s ) + σ s ∣ t σ t σ s ϵ s , ϵ s ∼ N ( 0 , I ) (4.4.8) \mathbf{x}_t = \underbrace{\frac{\alpha_{s|t}\sigma_t^2}{\sigma_s^2}\mathbf{x}_s + \frac{\alpha_t\sigma_{s|t}^2}{\sigma_s^2}\mathbf{x}_{\phi\times}(\mathbf{x}_s,s)}_{\boldsymbol{\mu}_{\phi\times}(\mathbf{x}_s,t,s)} +\sigma_{s|t}\frac{\sigma_t}{\sigma_s}\boldsymbol{\epsilon}_s,\quad \boldsymbol{\epsilon}_s\sim\mathcal{N}(\mathbf 0,\mathbf I)\tag{4.4.8} xt=μϕ×(xs,t,s)
σs2αs∣tσt2xs+σs2αtσs∣t2xϕ×(xs,s)+σs∣tσsσtϵs,ϵs∼N(0,I)(4.4.8)
4.5 (可选)福克-普朗克方程与通过边缘化和贝叶斯法则推导反向时间随机微分方程((Optional) Fokker–Planck Equation and Reverse-Time SDEs via Marginalization and Bayes’ Rule)
本节从概率视角介绍福克–普朗克方程与逆向随机微分方程的结构。依托边缘化技巧、贝叶斯公式等基础工具,阐明随机过程的概率表述与对应微分方程之间的内在关联。
需要说明:本节给出的推导并非严格数学证明,仅为启发性推导,用于直观阐述内在逻辑关系。
4.5.1 从转移核的边缘化导出福克-普朗克方程(Fokker-Planck Equation from the Marginalization of Transition Kernels)
已知式 (4.1.2) 给出的正向转移概率:
p ( x t + Δ t ∣ x t ) = N ( x t + Δ t ; x t + f ( x t , t ) Δ t , g 2 ( t ) Δ t I ) , p(\mathbf{x}_{t+\Delta t}|\mathbf{x}_t) = \mathcal{N}\big(\mathbf{x}_{t+\Delta t};\mathbf{x}_t+\mathbf{f}(\mathbf{x}_t,t)\Delta t,\,g^2(t)\Delta t\,\mathbf{I}\big), p(xt+Δt∣xt)=N(xt+Δt;xt+f(xt,t)Δt,g2(t)ΔtI),以及边缘分布
p t ( x t ) , p t + Δ t ( x t + Δ t ) p_t(\mathbf{x}_t),\quad p_{t+\Delta t}(\mathbf{x}_{t+\Delta t}) pt(xt),pt+Δt(xt+Δt)本节将推导刻画边缘分布 p t p_t pt 随时间演化规律的福克–普朗克方程。
变量代换。 由马尔可夫性, t + Δ t t+\Delta t t+Δt 时刻的边缘分布可表示为对前一时刻状态 x t \mathbf{x}_t xt 的积分,即查普曼–科尔莫戈罗夫方程:
p t + Δ t ( x ) = ∫ N ( x ; y + f ( y , t ) Δ t , g 2 ( t ) Δ t I ) p t ( y ) d y p_{t+\Delta t}(\mathbf{x}) = \int \mathcal{N}\big(\mathbf{x};\mathbf y+\mathbf f(\mathbf y,t)\Delta t,\,g^2(t)\Delta t\mathbf I\big)\,p_t(\mathbf y)\,\mathrm{d}\mathbf y pt+Δt(x)=∫N(x;y+f(y,t)Δt,g2(t)ΔtI)pt(y)dy引入新变量:
u : = y + f ( y , t ) Δ t , \mathbf u := \mathbf y + \mathbf f(\mathbf y,t)\Delta t, u:=y+f(y,t)Δt,此时高斯分布的均值中心变为 u \mathbf u u。当 Δ t \Delta t Δt 充分小时,该变换可逆,展开为:
y = u − f ( u , t ) Δ t + O ( Δ t 2 ) , ∣ det ∂ y ∂ u ∣ = 1 − ( ∇ u ⋅ f ) ( u , t ) Δ t + O ( Δ t 2 ) . \mathbf y = \mathbf u - \mathbf f(\mathbf u,t)\Delta t + \mathcal O(\Delta t^2),\quad \left|\det\frac{\partial \mathbf y}{\partial \mathbf u}\right|=1-\big(\nabla_{\mathbf u}\cdot\mathbf f\big)(\mathbf u,t)\Delta t+\mathcal O(\Delta t^2). y=u−f(u,t)Δt+O(Δt2),
det∂u∂y
=1−(∇u⋅f)(u,t)Δt+O(Δt2).依托变量代换积分公式可得:
p t + Δ t ( x ) = ∫ N ( x ; u , g 2 ( t ) Δ t I ) ⋅ [ p t ( u ) − Δ t f ( u , t ) ⋅ ∇ u p t ( u ) − Δ t ( ∇ u ⋅ f ) ( u , t ) p t ( u ) ] d u + O ( Δ t 2 ) \begin{aligned} p_{t+\Delta t}(\mathbf{x}) &= \int \mathcal{N}\big(\mathbf{x};\mathbf u,g^2(t)\Delta t\mathbf I\big)\cdot\\ &\quad\Big[p_t(\mathbf u)-\Delta t\,\mathbf f(\mathbf u,t)\cdot\nabla_{\mathbf u}p_t(\mathbf u)-\Delta t\big(\nabla_{\mathbf u}\cdot\mathbf f\big)(\mathbf u,t)\,p_t(\mathbf u)\Big]\mathrm{d}\mathbf u+\mathcal O(\Delta t^2) \end{aligned} pt+Δt(x)=∫N(x;u,g2(t)ΔtI)⋅[pt(u)−Δtf(u,t)⋅∇upt(u)−Δt(∇u⋅f)(u,t)pt(u)]du+O(Δt2)
泰勒展开。 对任意光滑函数 ϕ : R D → R \phi:\mathbb R^D\to\mathbb R ϕ:RD→R、尺度参数 σ > 0 \sigma>0 σ>0,若 z ∼ N ( 0 , I ) \mathbf z\sim\mathcal{N}(\mathbf 0,\mathbf I) z∼N(0,I),成立泰勒–高斯光滑公式:
∫ N ( x ; u , σ 2 I ) ϕ ( u ) d u = E [ ϕ ( x + σ z ) ] = ϕ ( x ) + σ 2 2 Δ x ϕ ( x ) + O ( σ 4 ) \int \mathcal{N}(\mathbf{x};\mathbf u,\sigma^2\mathbf I)\phi(\mathbf u)\mathrm{d}\mathbf u =\mathbb{E}\big[\phi(\mathbf{x}+\sigma\mathbf z)\big] =\phi(\mathbf{x})+\frac{\sigma^2}{2}\Delta_{\mathbf x}\phi(\mathbf{x})+\mathcal O(\sigma^4) ∫N(x;u,σ2I)ϕ(u)du=E[ϕ(x+σz)]=ϕ(x)+2σ2Δxϕ(x)+O(σ4)该式由泰勒展开推导:
ϕ ( x + σ z ) = ϕ ( x ) + σ ∇ x ϕ ( x ) ⋅ z + σ 2 2 z ⊤ ∇ x 2 ϕ ( x ) z + O ( σ 3 ) \phi(\mathbf{x}+\sigma\mathbf z)=\phi(\mathbf{x})+\sigma\nabla_{\mathbf x}\phi(\mathbf{x})\cdot\mathbf z+\frac{\sigma^2}{2}\mathbf z^\top\nabla_{\mathbf x}^2\phi(\mathbf{x})\mathbf z+\mathcal O(\sigma^3) ϕ(x+σz)=ϕ(x)+σ∇xϕ(x)⋅z+2σ2z⊤∇x2ϕ(x)z+O(σ3)结合矩条件 E [ z ] = 0 , E [ z z ⊤ ] = I \mathbb E[\mathbf z]=\mathbf 0,\;\mathbb E[\mathbf z\mathbf z^\top]=\mathbf I E[z]=0,E[zz⊤]=I 即可证得。
依次取 ϕ = p t \phi=p_t ϕ=pt、 ϕ = f ⋅ ∇ u p t \phi=\mathbf f\cdot\nabla_{\mathbf u}p_t ϕ=f⋅∇upt、 ϕ = ( ∇ u ⋅ f ) p t \phi=(\nabla_{\mathbf u}\cdot\mathbf f)p_t ϕ=(∇u⋅f)pt,并令 σ 2 = g 2 ( t ) Δ t \sigma^2=g^2(t)\Delta t σ2=g2(t)Δt,代入后:
p t + Δ t ( x ) − p t ( x ) = − Δ t f ( x , t ) ⋅ ∇ x p t ( x ) − Δ t ( ∇ x ⋅ f ) ( x , t ) p t ( x ) + g 2 ( t ) 2 Δ t Δ x p t ( x ) + O ( Δ t 2 ) = − Δ t ∇ x ⋅ ( f ( x , t ) p t ( x ) ) + g 2 ( t ) 2 Δ t Δ x p t ( x ) + O ( Δ t 2 ) \begin{aligned} p_{t+\Delta t}(\mathbf{x})-p_t(\mathbf{x}) &=-\Delta t\,\mathbf{f}(\mathbf{x},t)\cdot\nabla_{\mathbf x}p_t(\mathbf{x}) -\Delta t(\nabla_{\mathbf x}\cdot\mathbf{f})(\mathbf{x},t)\,p_t(\mathbf{x}) +\frac{g^2(t)}{2}\Delta t\,\Delta_{\mathbf x}p_t(\mathbf{x})+\mathcal O(\Delta t^2)\\ &=-\Delta t\nabla_{\mathbf x}\cdot\big(\mathbf{f}(\mathbf{x},t)\,p_t(\mathbf{x})\big) +\frac{g^2(t)}{2}\Delta t\,\Delta_{\mathbf x}p_t(\mathbf{x})+\mathcal O(\Delta t^2) \end{aligned} pt+Δt(x)−pt(x)=−Δtf(x,t)⋅∇xpt(x)−Δt(∇x⋅f)(x,t)pt(x)+2g2(t)ΔtΔxpt(x)+O(Δt2)=−Δt∇x⋅(f(x,t)pt(x))+2g2(t)ΔtΔxpt(x)+O(Δt2)两边除以 Δ t \Delta t Δt 并取极限 Δ t → 0 \Delta t\to0 Δt→0,即可得到福克–普朗克方程。
附录 C.1.4 将基于伊藤公式给出推导,作为上述离散视角的补充。
4.5.2 为什么反向时间随机微分方程会呈现这种形式?(Why Does Reverse-Time SDE Take The Form?)
逆向随机微分方程的严格推导涉及繁杂的福克–普朗克方程理论。借助贝叶斯定理可直观理解逆时 SDE 的构造形式,本节采用启发性推导,阐明得分函数为何会出现在式 (4.1.6) 中。
基于贝叶斯定理做过程逆推。我们先在离散时间框架下求解逆时转移核
p ( x t ∣ x t + Δ t ) , p(\mathbf{x}_t|\mathbf{x}_{t+\Delta t}), p(xt∣xt+Δt),再令 Δ t → 0 \Delta t\to0 Δt→0 过渡到连续时间形式。由贝叶斯公式:
p ( x t ∣ x t + Δ t ) = p ( x t + Δ t ∣ x t ) p t ( x t ) p t + Δ t ( x t + Δ t ) = p ( x t + Δ t ∣ x t ) exp ( log p t ( x t ) − log p t + Δ t ( x t + Δ t ) ) . (4.5.1) \begin{aligned} p(\mathbf{x}_t|\mathbf{x}_{t+\Delta t}) &= p(\mathbf{x}_{t+\Delta t}|\mathbf{x}_t)\,\frac{p_t(\mathbf{x}_t)}{p_{t+\Delta t}(\mathbf{x}_{t+\Delta t})}\\ &= p(\mathbf{x}_{t+\Delta t}|\mathbf{x}_t)\exp\big(\log p_t(\mathbf{x}_t)-\log p_{t+\Delta t}(\mathbf{x}_{t+\Delta t})\big). \tag{4.5.1} \end{aligned} p(xt∣xt+Δt)=p(xt+Δt∣xt)pt+Δt(xt+Δt)pt(xt)=p(xt+Δt∣xt)exp(logpt(xt)−logpt+Δt(xt+Δt)).(4.5.1) 其中正向转移核沿用式 (4.1.2) 的高斯形式:
p ( x t + Δ t ∣ x t ) = N ( x t + Δ t ; x t + f ( x t , t ) Δ t , g 2 ( t ) Δ t I ) p(\mathbf{x}_{t+\Delta t}|\mathbf{x}_t)=\mathcal{N}\big(\mathbf{x}_{t+\Delta t};\mathbf{x}_t+\mathbf{f}(\mathbf{x}_t,t)\Delta t,\,g^2(t)\Delta t\,\mathbf I\big) p(xt+Δt∣xt)=N(xt+Δt;xt+f(xt,t)Δt,g2(t)ΔtI)
泰勒展开。为处理指数项,对时空变量在 ( x t , t ) (\mathbf{x}_t,t) (xt,t) 处做一阶泰勒展开:
log p t + Δ t ( x t + Δ t ) = log p t ( x t ) + ∇ x log p t ( x t ) ⋅ ( x t + Δ t − x t ) + ∂ log p t ( x t ) ∂ t Δ t + O ( ∥ h ∥ 2 2 ) \begin{aligned} \log p_{t+\Delta t}(\mathbf{x}_{t+\Delta t}) =&\log p_t(\mathbf{x}_t)+\nabla_\mathbf{x}\log p_t(\mathbf{x}_t)\cdot(\mathbf{x}_{t+\Delta t}-\mathbf{x}_t)\\ &+\frac{\partial \log p_t(\mathbf{x}_t)}{\partial t}\Delta t+\mathcal O\big(\|\mathbf h\|_2^2\big) \end{aligned} logpt+Δt(xt+Δt)=logpt(xt)+∇xlogpt(xt)⋅(xt+Δt−xt)+∂t∂logpt(xt)Δt+O(∥h∥22)其中 h : = ( x t + Δ t − x t , Δ t ) \mathbf h:=(\mathbf{x}_{t+\Delta t}-\mathbf{x}_t,\Delta t) h:=(xt+Δt−xt,Δt)。整理可得:
log p t ( x t ) − log p t + Δ t ( x t + Δ t ) = − ∇ x log p t ( x t ) ⋅ ( x t + Δ t − x t ) − ∂ log p t ( x t ) ∂ t Δ t + O ( ∥ h ∥ 2 2 ) (4.5.2) \begin{aligned} \log p_t(\mathbf{x}_t)-\log p_{t+\Delta t}(\mathbf{x}_{t+\Delta t}) =&-\nabla_\mathbf{x}\log p_t(\mathbf{x}_t)\cdot(\mathbf{x}_{t+\Delta t}-\mathbf{x}_t)\\ &-\frac{\partial \log p_t(\mathbf{x}_t)}{\partial t}\Delta t+\mathcal O\big(\|\mathbf h\|_2^2\big)\tag{4.5.2} \end{aligned} logpt(xt)−logpt+Δt(xt+Δt)=−∇xlogpt(xt)⋅(xt+Δt−xt)−∂t∂logpt(xt)Δt+O(∥h∥22)(4.5.2)对漂移、扩散系数均有界的正向过程,满足 E [ ∥ x t + Δ t − x t ∥ 2 2 ] = O ( Δ t ) \mathbb E\big[\|\mathbf{x}_{t+\Delta t}-\mathbf{x}_t\|_2^2\big]=\mathcal O(\Delta t) E[∥xt+Δt−xt∥22]=O(Δt),因此余项在期望意义下满足 O ( ( Δ t ) 2 ) \mathcal O\big((\Delta t)^2\big) O((Δt)2)。
代入反向转移表达式。将式 (4.1.2)、式 (4.5.2) 一并代入式 (4.5.1):
p ( x t ∣ x t + Δ t ) = 1 ( 2 π g 2 ( t ) Δ t ) D / 2 exp ( − ∥ x t + Δ t − x t − f ( x t , t ) Δ t ∥ 2 2 2 g 2 ( t ) Δ t ) ⋅ exp ( − ∇ x log p t ( x t ) ⋅ ( x t + Δ t − x t ) − ∂ log p t ( x t ) ∂ t Δ t + O ( ( Δ t ) 2 ) ) \begin{aligned} p(\mathbf{x}_t|\mathbf{x}_{t+\Delta t}) =&\frac{1}{\big(2\pi g^2(t)\Delta t\big)^{D/2}} \exp\left(-\frac{\big\|\mathbf{x}_{t+\Delta t}-\mathbf{x}_t-\mathbf{f}(\mathbf{x}_t,t)\Delta t\big\|_2^2}{2g^2(t)\Delta t}\right)\\ &\cdot\exp\left(-\nabla_\mathbf{x}\log p_t(\mathbf{x}_t)\cdot(\mathbf{x}_{t+\Delta t}-\mathbf{x}_t) -\frac{\partial\log p_t(\mathbf{x}_t)}{\partial t}\Delta t+\mathcal O\big((\Delta t)^2\big)\right) \end{aligned} p(xt∣xt+Δt)=(2πg2(t)Δt)D/21exp(−2g2(t)Δt
xt+Δt−xt−f(xt,t)Δt
22)⋅exp(−∇xlogpt(xt)⋅(xt+Δt−xt)−∂t∂logpt(xt)Δt+O((Δt)2))
代数变形。核心步骤为对指数部分配平方:
− ∥ x t + Δ t − x t − f ( x t , t ) Δ t ∥ 2 2 2 g 2 ( t ) Δ t − ∇ x log p t ( x t ) ⋅ ( x t + Δ t − x t ) = − ∥ x t + Δ t − x t − f ( x t , t ) Δ t ∥ 2 2 + 2 g 2 ( t ) Δ t ∇ x log p t ( x t ) ⋅ ( x t + Δ t − x t ) 2 g 2 ( t ) Δ t \begin{aligned} &-\frac{\big\|\mathbf{x}_{t+\Delta t}-\mathbf{x}_t-\mathbf{f}(\mathbf{x}_t,t)\Delta t\big\|_2^2}{2g^2(t)\Delta t} -\nabla_\mathbf{x}\log p_t(\mathbf{x}_t)\cdot(\mathbf{x}_{t+\Delta t}-\mathbf{x}_t)\\ =&-\frac{\big\|\mathbf{x}_{t+\Delta t}-\mathbf{x}_t-\mathbf{f}(\mathbf{x}_t,t)\Delta t\big\|_2^2 +2g^2(t)\Delta t\,\nabla_\mathbf{x}\log p_t(\mathbf{x}_t)\cdot(\mathbf{x}_{t+\Delta t}-\mathbf{x}_t)}{2g^2(t)\Delta t} \end{aligned} =−2g2(t)Δt
xt+Δt−xt−f(xt,t)Δt
22−∇xlogpt(xt)⋅(xt+Δt−xt)−2g2(t)Δt
xt+Δt−xt−f(xt,t)Δt
22+2g2(t)Δt∇xlogpt(xt)⋅(xt+Δt−xt)
记 δ : = x t + Δ t − x t \boldsymbol\delta := \mathbf{x}_{t+\Delta t}-\mathbf{x}_t δ:=xt+Δt−xt, μ : = f ( x t , t ) Δ t \boldsymbol\mu:=\mathbf{f}(\mathbf{x}_t,t)\Delta t μ:=f(xt,t)Δt,则:
∥ δ − μ ∥ 2 2 + 2 g 2 ( t ) Δ t ∇ x log p t ( x t ) ⋅ δ = ∥ δ ∥ 2 2 − 2 δ ⋅ μ + ∥ μ ∥ 2 2 + 2 g 2 ( t ) Δ t ∇ x log p t ( x t ) ⋅ δ = ∥ δ ∥ 2 2 − 2 δ ⋅ [ μ − g 2 ( t ) Δ t ∇ x log p t ( x t ) ] + ∥ μ ∥ 2 2 = ∥ δ − [ μ − g 2 ( t ) Δ t ∇ x log p t ( x t ) ] ∥ 2 2 − ∥ g 2 ( t ) Δ t ∇ x log p t ( x t ) ∥ 2 2 \begin{aligned} &\|\boldsymbol\delta-\boldsymbol\mu\|_2^2 + 2g^2(t)\Delta t\,\nabla_\mathbf{x}\log p_t(\mathbf{x}_t)\cdot\boldsymbol\delta \\ =&\|\boldsymbol\delta\|_2^2 - 2\boldsymbol\delta\cdot\boldsymbol\mu+\|\boldsymbol\mu\|_2^2+2g^2(t)\Delta t\,\nabla_\mathbf{x}\log p_t(\mathbf{x}_t)\cdot\boldsymbol\delta \\ =&\|\boldsymbol\delta\|_2^2 - 2\boldsymbol\delta\cdot\big[\boldsymbol\mu-g^2(t)\Delta t\nabla_\mathbf{x}\log p_t(\mathbf{x}_t)\big]+\|\boldsymbol\mu\|_2^2 \\ =&\Big\|\boldsymbol\delta-\big[\boldsymbol\mu-g^2(t)\Delta t\nabla_\mathbf{x}\log p_t(\mathbf{x}_t)\big]\Big\|_2^2-\big\|g^2(t)\Delta t\nabla_\mathbf{x}\log p_t(\mathbf{x}_t)\big\|_2^2 \end{aligned} ===∥δ−μ∥22+2g2(t)Δt∇xlogpt(xt)⋅δ∥δ∥22−2δ⋅μ+∥μ∥22+2g2(t)Δt∇xlogpt(xt)⋅δ∥δ∥22−2δ⋅[μ−g2(t)Δt∇xlogpt(xt)]+∥μ∥22
δ−[μ−g2(t)Δt∇xlogpt(xt)]
22−
g2(t)Δt∇xlogpt(xt)
22回代变量可得:
∥ δ − [ f ( x t , t ) Δ t − g 2 ( t ) Δ t ∇ x log p t ( x t ) ] ∥ 2 2 = ∥ x t + Δ t − x t − [ f ( x t , t ) − g 2 ( t ) ∇ x log p t ( x t ) ] Δ t ∥ 2 2 \begin{aligned} &\Big\|\boldsymbol\delta-\big[\mathbf{f}(\mathbf{x}_t,t)\Delta t-g^2(t)\Delta t\nabla_\mathbf{x}\log p_t(\mathbf{x}_t)\big]\Big\|_2^2 \\ =&\Big\|\mathbf{x}_{t+\Delta t}-\mathbf{x}_t-\big[\mathbf{f}(\mathbf{x}_t,t)-g^2(t)\nabla_\mathbf{x}\log p_t(\mathbf{x}_t)\big]\Delta t\Big\|_2^2 \end{aligned} =
δ−[f(xt,t)Δt−g2(t)Δt∇xlogpt(xt)]
22
xt+Δt−xt−[f(xt,t)−g2(t)∇xlogpt(xt)]Δt
22综上可得:
p ( x t ∣ x t + Δ t ) = 1 ( 2 π g 2 ( t ) Δ t ) D / 2 ⋅ exp ( − ∥ x t + Δ t − x t − [ f ( x t , t ) − g 2 ( t ) ∇ x log p t ( x t ) ] Δ t ∥ 2 2 2 g 2 ( t ) Δ t ) ⋅ exp ( O ( Δ t ) ) = N ( x t ; x t + Δ t − [ f ( x t , t ) − g 2 ( t ) ∇ x log p t ( x t ) ] Δ t , g 2 ( t ) Δ t I ) ⋅ ( 1 + O ( Δ t ) ) \begin{aligned} p(\mathbf{x}_t|\mathbf{x}_{t+\Delta t}) =&\frac{1}{\big(2\pi g^2(t)\Delta t\big)^{D/2}} \cdot\exp\left(-\frac{\big\|\mathbf{x}_{t+\Delta t}-\mathbf{x}_t-\big[\mathbf{f}(\mathbf{x}_t,t)-g^2(t)\nabla_\mathbf{x}\log p_t(\mathbf{x}_t)\big]\Delta t\big\|_2^2}{2g^2(t)\Delta t}\right)\\ &\cdot\exp\big(\mathcal O(\Delta t)\big)\\ =&\mathcal{N}\Big(\mathbf{x}_t;\mathbf{x}_{t+\Delta t}-\big[\mathbf{f}(\mathbf{x}_t,t)-g^2(t)\nabla_\mathbf{x}\log p_t(\mathbf{x}_t)\big]\Delta t,\,g^2(t)\Delta t\,\mathbf I\Big) \cdot\big(1+\mathcal O(\Delta t)\big) \end{aligned} p(xt∣xt+Δt)==(2πg2(t)Δt)D/21⋅exp(−2g2(t)Δt
xt+Δt−xt−[f(xt,t)−g2(t)∇xlogpt(xt)]Δt
22)⋅exp(O(Δt))N(xt;xt+Δt−[f(xt,t)−g2(t)∇xlogpt(xt)]Δt,g2(t)ΔtI)⋅(1+O(Δt))
配平方产生的余项 ∥ g 2 ( t ) Δ t ∇ x log p t ( x t ) ∥ 2 2 \big\|g^2(t)\Delta t\nabla_\mathbf{x}\log p_t(\mathbf{x}_t)\big\|_2^2
g2(t)Δt∇xlogpt(xt)
22 为 O ( ( Δ t ) 2 ) \mathcal O((\Delta t)^2) O((Δt)2),可归入误差项;同理,时间导数项 ∂ log p t ( x t ) ∂ t Δ t \frac{\partial\log p_t(\mathbf{x}_t)}{\partial t}\Delta t ∂t∂logpt(xt)Δt 是 O ( Δ t ) \mathcal O(\Delta t) O(Δt),在连续极限下趋于零。
取极限 Δ t → 0 \boldsymbol{\Delta t\to0} Δt→0。在函数光滑的前提假设下,当 Δ t → 0 \Delta t\to0 Δt→0 时有如下近似:
f ( x t , t ) ≈ f ( x t + Δ t , t + Δ t ) , g ( t ) ≈ g ( t + Δ t ) , ∇ x log p t ( x t ) ≈ ∇ x log p t + Δ t ( x t + Δ t ) = s ( x t + Δ t , t + Δ t ) . \begin{aligned} \mathbf{f}(\mathbf{x}_t,t) &\approx \mathbf{f}(\mathbf{x}_{t+\Delta t},t+\Delta t),\\ g(t) &\approx g(t+\Delta t),\\ \nabla_\mathbf{x}\log p_t(\mathbf{x}_t) &\approx \nabla_\mathbf{x}\log p_{t+\Delta t}(\mathbf{x}_{t+\Delta t})=\mathbf{s}(\mathbf{x}_{t+\Delta t},t+\Delta t). \end{aligned} f(xt,t)g(t)∇xlogpt(xt)≈f(xt+Δt,t+Δt),≈g(t+Δt),≈∇xlogpt+Δt(xt+Δt)=s(xt+Δt,t+Δt).借助上述近似并整理式子,可得:
p ( x t ∣ x t + Δ t ) ≈ 1 ( 2 π g 2 ( t ) Δ t ) D / 2 exp ( − ∥ x t − ( x t + Δ t − [ f ( x t + Δ t , t + Δ t ) − g 2 ( t + Δ t ) s ( x t + Δ t , t + Δ t ) ] Δ t ) ∥ 2 2 2 g 2 ( t + Δ t ) Δ t ) \begin{aligned} p(\mathbf{x}_t|\mathbf{x}_{t+\Delta t}) \approx \frac{1}{\big(2\pi g^2(t)\Delta t\big)^{D/2}} \exp\left( -\frac{\big\|\mathbf{x}_t-\big(\mathbf{x}_{t+\Delta t}-\big[\mathbf{f}(\mathbf{x}_{t+\Delta t},t+\Delta t)-g^2(t+\Delta t)\mathbf{s}(\mathbf{x}_{t+\Delta t},t+\Delta t)\big]\Delta t\big)\big\|_2^2}{2g^2(t+\Delta t)\Delta t} \right) \end{aligned} p(xt∣xt+Δt)≈(2πg2(t)Δt)D/21exp(−2g2(t+Δt)Δt
xt−(xt+Δt−[f(xt+Δt,t+Δt)−g2(t+Δt)s(xt+Δt,t+Δt)]Δt)
22)由此可知 p ( x t ∣ x t + Δ t ) p(\mathbf{x}_t|\mathbf{x}_{t+\Delta t}) p(xt∣xt+Δt) 近似服从高斯分布:
均值: x t + Δ t − [ f ( x t + Δ t , t + Δ t ) − g 2 ( t + Δ t ) s ( x t + Δ t , t + Δ t ) ] Δ t , 协方差: g 2 ( t + Δ t ) Δ t I \begin{aligned} &\textbf{均值:}\ \mathbf{x}_{t+\Delta t}-\big[\mathbf{f}(\mathbf{x}_{t+\Delta t},t+\Delta t)-g^2(t+\Delta t)\mathbf{s}(\mathbf{x}_{t+\Delta t},t+\Delta t)\big]\Delta t,\\ &\textbf{协方差:}\ g^2(t+\Delta t)\Delta t\,\mathbf I \end{aligned} 均值: xt+Δt−[f(xt+Δt,t+Δt)−g2(t+Δt)s(xt+Δt,t+Δt)]Δt,协方差: g2(t+Δt)ΔtI令 Δ t → 0 \Delta t\to0 Δt→0 取极限,即可得到式 (4.1.6) 的连续逆向随机微分方程。
4.6 结语(Closing Remarks)
本章是全书理论体系的关键节点,从变分视角与得分匹配视角出发,将离散时间扩散过程统一至一套简洁完备的连续时间理论框架。文中证明,DDPM 与 NCSN 均可看作随机微分方程(SDE)在选取不同漂移、扩散系数下的离散化形式。
本框架的核心是逆向随机微分方程,该方程从数学上定义了能够还原噪声污染的生成过程。关键结论为:逆过程的漂移项仅由一个未知量决定,即各时刻边缘分布对应的得分函数 ∇ x log p t ( x ) \nabla_\mathbf{x}\log p_t(\mathbf{x}) ∇xlogpt(x)。该结论确立了得分函数在生成建模里的核心地位。
除此之外,本章引入确定性对偶模型:概率流常微分方程(PF-ODE),其演化轨迹与随机微分方程共享同一套边缘概率密度 { p t } \{p_t\} {pt},该一致性由福克–普朗克方程严格保证。由此可得到重要推论:复杂的生成任务本质等价于求解微分方程;模型训练转化为学习刻画方程向量场的得分函数,采样则变为常微分方程数值积分问题。
PF-ODE 这类确定性流模型搭建起衔接扩散模型第三种理论视角的关键桥梁。学习由速度场控制的确定性变换,是当下一大主流生成模型的核心思想。下一章内容安排如下:
(1)从归一化流、神经常微分方程的理论源头出发,展开介绍基于流的建模思路;
(2)推导该思路衍生出的现代流匹配框架,该方法直接学习速度场,实现样本在不同分布间的变换。
最终我们将发现:由随机理论推导得到的确定性 PF-ODE,完全可以从这套截然不同的流建模思路重新构造与拓展,从而完善扩散建模的大一统理论体系。
下一章:【扩散模型原理】(五)Flow-Based Perspective : From NFs to Flow Matching

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)