Codex 实战:把论文实验交给 AI Agent,它能跑出结果并写报告吗?
摘要:论文实验能不能交给智能体做?它能不能不只写几段代码,而是自己读配置、拆任务、生成实验脚本、跑模型、画结果图,最后整理出能放进论文或课程设计报告里的实验分析?本文用 Codex 做一次完整测试:基于 UCI Student Performance 数学成绩数据,搭建学生成绩回归实验闭环。项目运行
python main.py后可复现 395 条样本的训练评估过程,最佳模型为 RandomForest,测试集 RMSE 为 1.6285、R2 为 0.8849。
关键词: Codex 实战、AI Agent、论文实验自动化、实验工作流、UCI Student Performance、机器学习回归、结果图表、项目报告
把论文实验交给智能体,先问它能做到哪一步
写论文或课程设计时,真正拖慢进度的往往不是某一段模型代码,而是整条实验链路:数据从哪里来,特征怎么选,模型怎么对比,指标怎么计算,图表怎么生成,报告里的结论是否和真实运行结果一致。既然 Codex 已经能在仓库里读文件、改代码、运行命令,那能不能把一部分论文实验也交给它?
这个问题不能靠演示截图回答,只能靠一次可复现的运行来判断。因为“让智能体帮我写论文实验”听起来很省事,实际最怕三件事:代码看起来完整,但没有真正跑过;指标写得漂亮,却找不到来源;报告里说的最佳模型,和 CSV 里的结果对不上。
因此我把问题压到一个可复现项目里:不只看 Codex 会不会补代码,而是看它能否接住一个完整论文实验任务:
给它数据和配置,让它拆任务。
让它生成可运行的实验脚本。
让它真实训练模型并保存指标。
让它根据运行结果绘制图表。
让它把指标、图表和实验设计整理成报告。
最后用文件和命令验收,而不是只看文字回复。
最终验收只看真实文件:python main.py 是否能运行,指标是否来自 outputs/metrics.csv,图表是否由本次运行生成,reports/project_report.md 是否和指标一致。只有这些都对上,才算智能体真的参与了实验开发,而不是只写了一段说明。
这次选择一个适合写进论文实验章节的小型任务:预测学生数学课程最终成绩 G3。项目内置 data/student_performance_math.csv,样本数为 395 条,字段来自 UCI Student Performance 数据集。原始数据包含学校、性别、家庭背景、学习时间、缺勤次数、阶段成绩等字段;本项目选择 15 个数值特征进入模型:
age, Medu, Fedu, traveltime, studytime, failures,
famrel, freetime, goout, Dalc, Walc, health,
absences, G1, G2
G3 的取值范围是 0 到 20,其中 0 分样本有 38 条。这个细节会影响 MAPE 的计算,因此代码在计算百分比误差时跳过真实值为 0 的测试样本,避免除零和百分比失真。
如果把它当成“让 Codex 帮我写论文实验”的测试,交付物不能只是一份代码。它至少要留下这些可复查文件:
generated_experiment/experiment_pipeline.py 生成的实验脚本
outputs/metrics.csv 三个模型的评价指标
outputs/predictions.csv 测试集逐样本预测结果
outputs/feature_importance.csv 随机森林特征重要性
outputs/experiment_summary.json 本次运行摘要
reports/project_report.md 自动生成的实验报告
images/results/*.png 指标图、预测图、残差图、摘要图
项目架构如下。main.py 只负责调度,实验逻辑由生成脚本执行,报告从结果文件读取指标。
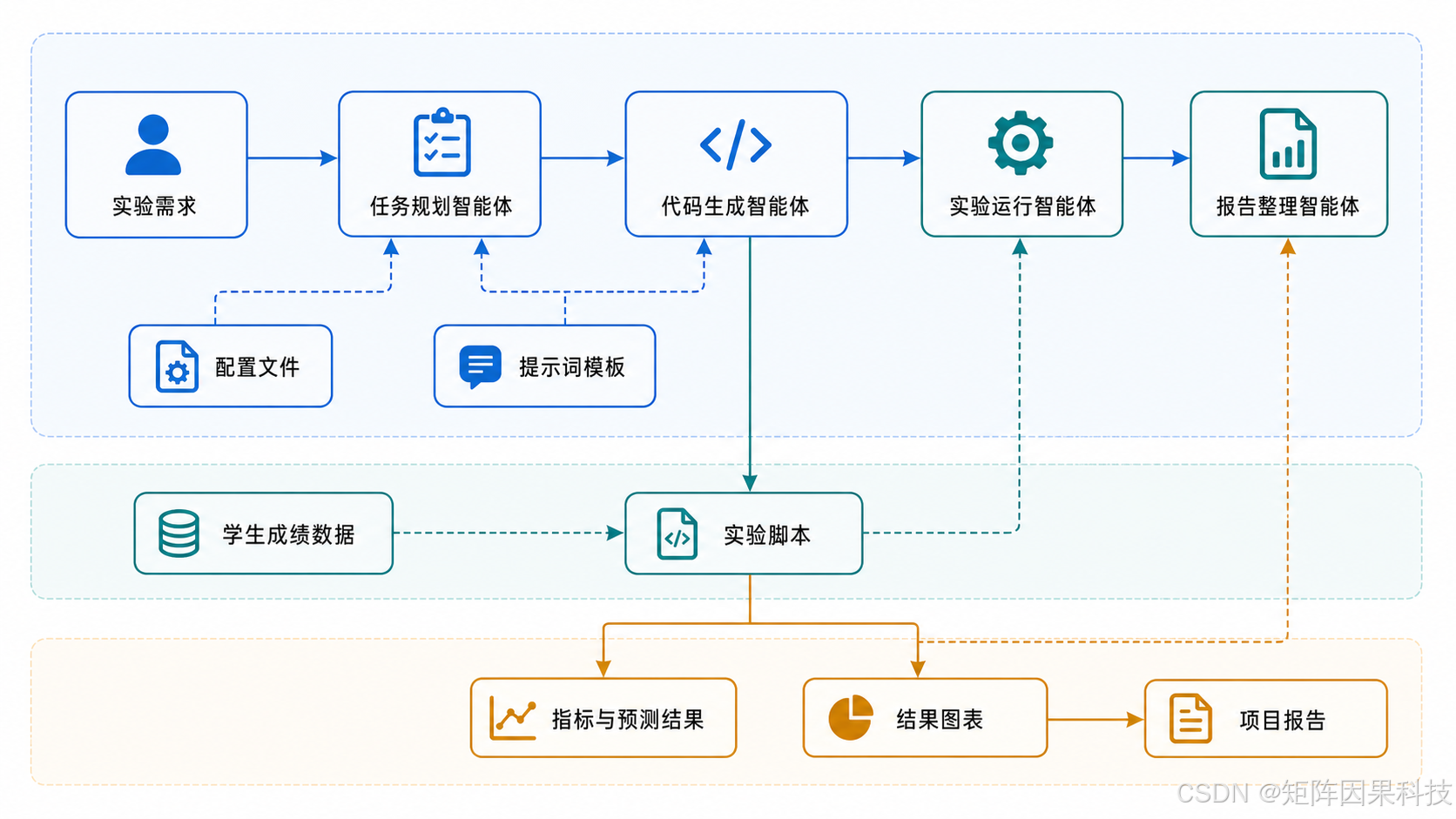
给 Codex 准备可执行上下文
Codex 接手仓库前,先准备三个关键输入:仓库规则、实验配置和任务提示词。这样做的目的很简单:让 Codex 少猜测,多按文件执行。
AGENTS.md 写仓库级规则,重点放在验收条件上:
Python 文件必须可以通过 python main.py 直接运行。
不要引入远程下载数据、训练大模型或调用付费 API 的硬依赖。
所有实验输出必须保存到 outputs/、reports/、images/results/。
图表中的结果必须来自实际运行结果,不允许手写虚假指标。
修改代码后请运行 python main.py 验证。
configs/experiment_config.yaml 写实验参数。数据路径、目标列、特征列、模型参数和输出路径都放在配置里,Codex 不需要从文章描述中猜:
project:
random_state: 42
data:
path: data/student_performance_math.csv
target: G3
test_size: 0.25
models:
ridge_regression:
alpha: 1.0
random_forest:
n_estimators: 160
max_depth: 8
prompts/codex_experiment_prompt.md 是交给 Codex 的主任务单。它不只写“帮我做实验”,而是指定 Codex 先读哪些文件、检查哪些输出、失败后如何处理。实际使用时,在项目根目录启动:
codex
然后粘贴主提示词。提示词里最重要的是这几条:
先检查 configs/experiment_config.yaml 中的 data.path、data.target 和 features 是否能在 CSV 中找到。
检查 generated_experiment/experiment_pipeline.py 是否真实读取 CSV,并训练 LinearRegression / RidgeRegression / RandomForest。
运行 python main.py,不要只做静态分析。
读取 logs/run.log、outputs/metrics.csv、outputs/experiment_summary.json 和 images/results/,确认结果是新生成的。
不要手写或编造指标,所有指标必须来自 outputs/metrics.csv。
主提示词预览如下。这里能看到上下文文件、约束和 Done when 都已经写进任务单。

从任务计划到实验脚本
项目没有让 Codex 直接从空白目录写完整工程,而是先生成任务计划,再生成实验脚本。这个顺序更适合实验类项目,因为指标、模型和输出文件都可以提前对齐。
TaskPlanner 根据配置生成 outputs/task_plan.md。计划里明确五件事:
| 项目 | 内容 |
|---|---|
| 数据 | data/student_performance_math.csv |
| 目标 | 最终成绩 G3 |
| 模型 | LinearRegression、RidgeRegression、RandomForest |
| 指标 | RMSE、MAE、R2、MAPE |
| 交付物 | 实验脚本、CSV 指标、预测结果、特征重要性、图表、报告 |
这份计划不是给读者看的装饰文档,而是后续验收依据。比如实验脚本如果漏了 RandomForest,或者报告里没有引用 outputs/metrics.csv,就能回到任务计划中定位遗漏。

实验脚本由 CodeAgent 写入 generated_experiment/experiment_pipeline.py。资源包中使用本地模板生成脚本,保证不配置 API Key 也能运行;如果接入真实 Codex,可以让 Codex 修改模板或直接修改生成脚本。
生成脚本的核心流程如下:
读取配置和 CSV
选择 15 个数值特征
按 random_state=42 切分训练集和测试集
训练 LinearRegression、RidgeRegression、RandomForest
逐模型计算 RMSE、MAE、R2、MAPE
保存模型、指标、预测结果和特征重要性
绘制指标对比、预测散点、残差分布和特征重要性图
写入 experiment_summary.json
其中 LinearRegression 和 RidgeRegression 会先做 StandardScaler 标准化;RandomForest 使用 n_estimators=160、max_depth=8,并固定随机种子。所有模型使用同一份训练集和测试集,保证指标可比较。
运行和验收结果
项目主入口只有一个:
python main.py
运行时 main.py 会依次完成目录检查、数据检查、任务计划生成、实验脚本生成、脚本执行、报告生成和图片预览生成。一次成功运行后,终端输出中应出现:
[OK] Auto-generated experiment finished.
[OK] Best model: RandomForest
[OK] Metrics saved to: outputs\metrics.csv
[OK] Images saved to: images\results
同时检查这些文件是否存在:
outputs/metrics.csv
outputs/predictions.csv
outputs/feature_importance.csv
outputs/experiment_summary.json
reports/project_report.md
images/results/metrics_comparison.png
images/results/prediction_scatter.png
images/results/residual_distribution.png
images/results/feature_importance.png
images/results/run_summary.png
如果运行失败,先看 logs/run.log。排查顺序建议是:配置里的数据路径是否存在,CSV 是否包含 G3 和全部特征列,依赖是否安装完整,生成脚本是否仍然使用项目相对路径。不要先改报告,也不要在文章里补手写指标。
项目生成的运行摘要图如下。它把关键输出集中在一张图里,适合放在博客或课程设计附件中说明运行结果。

指标、图表和结果解释
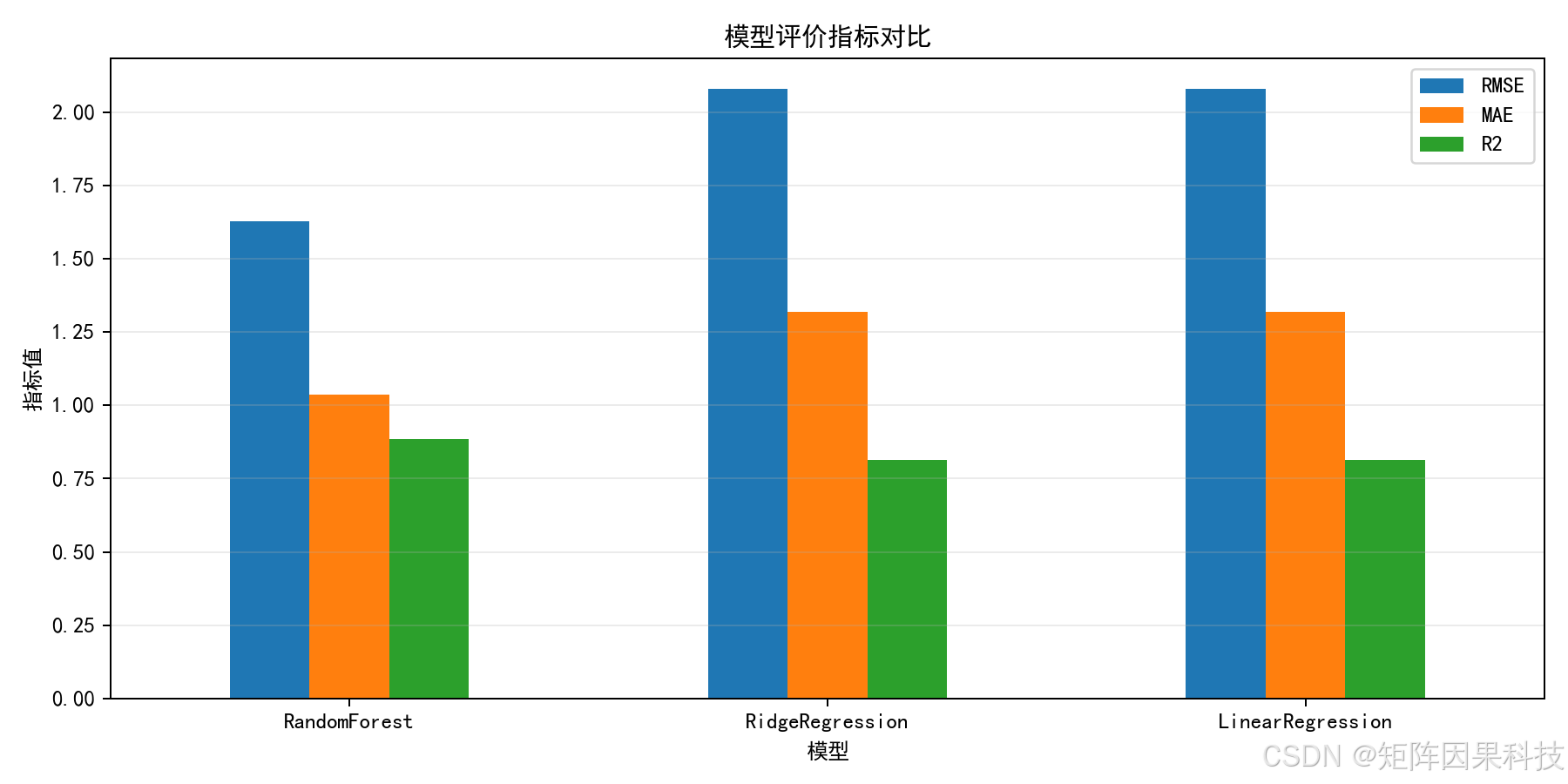
本次运行使用 296 条样本训练、99 条样本测试。outputs/metrics.csv 中三个模型结果如下:
| 模型 | RMSE | MAE | R2 | MAPE |
|---|---|---|---|---|
| RandomForest | 1.6285 | 1.0367 | 0.8849 | 8.55% |
| RidgeRegression | 2.0795 | 1.3202 | 0.8123 | 9.60% |
| LinearRegression | 2.0795 | 1.3199 | 0.8123 | 9.60% |
RandomForest 的 RMSE 和 MAE 最低,R2 最高,因此被选为最佳模型。RidgeRegression 与 LinearRegression 的结果非常接近,说明在当前特征组合下,线性模型能抓住一部分规律,但对非线性关系和异常样本的处理不如随机森林。
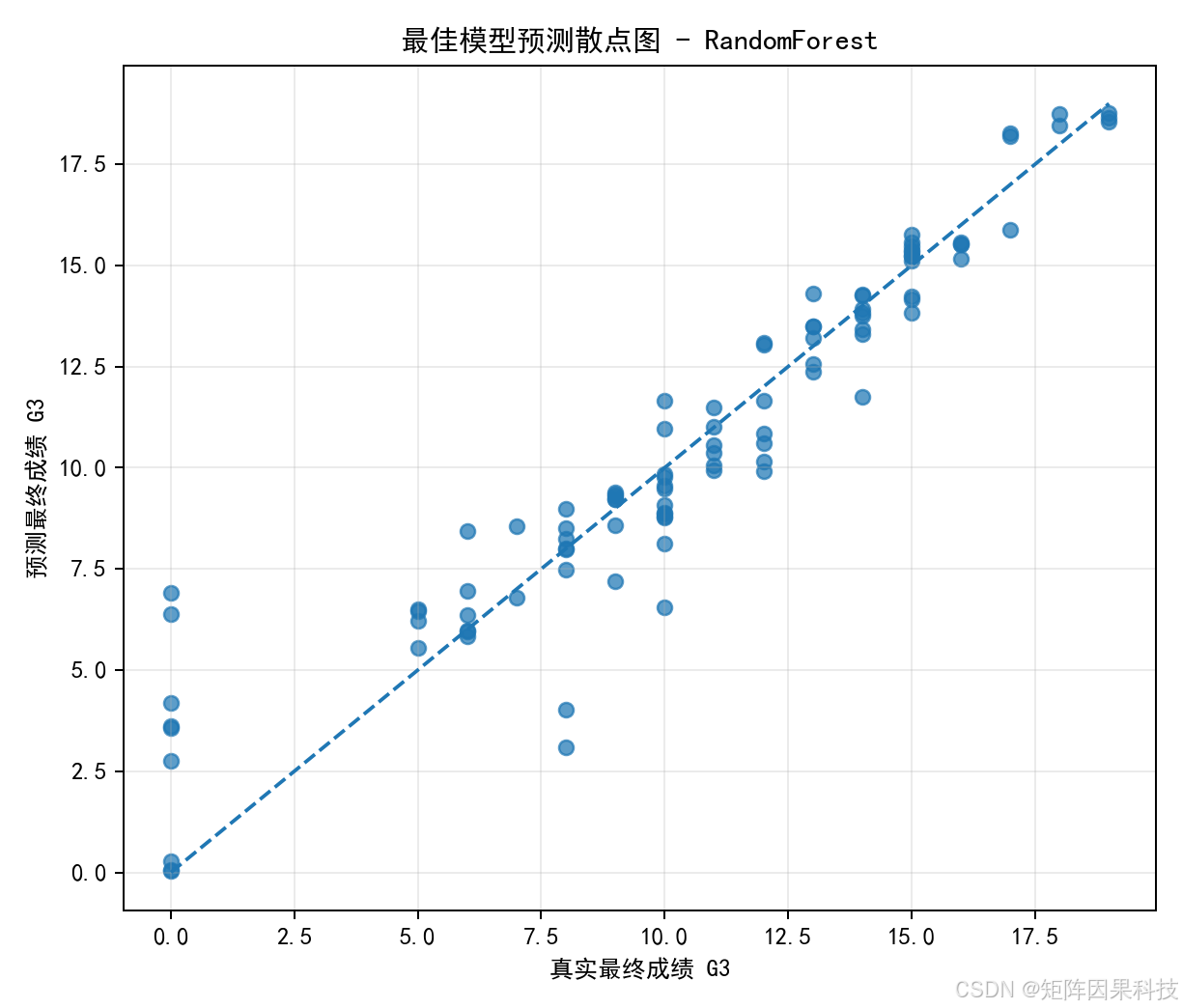
预测散点图用于观察真实 G3 与预测 G3 的关系。大多数点靠近对角线,说明模型能较好利用 G1、G2 等阶段成绩预测最终成绩。偏离较大的样本主要集中在低分区域,这类样本通常更适合进一步做误差样本分析,而不是只看平均指标。
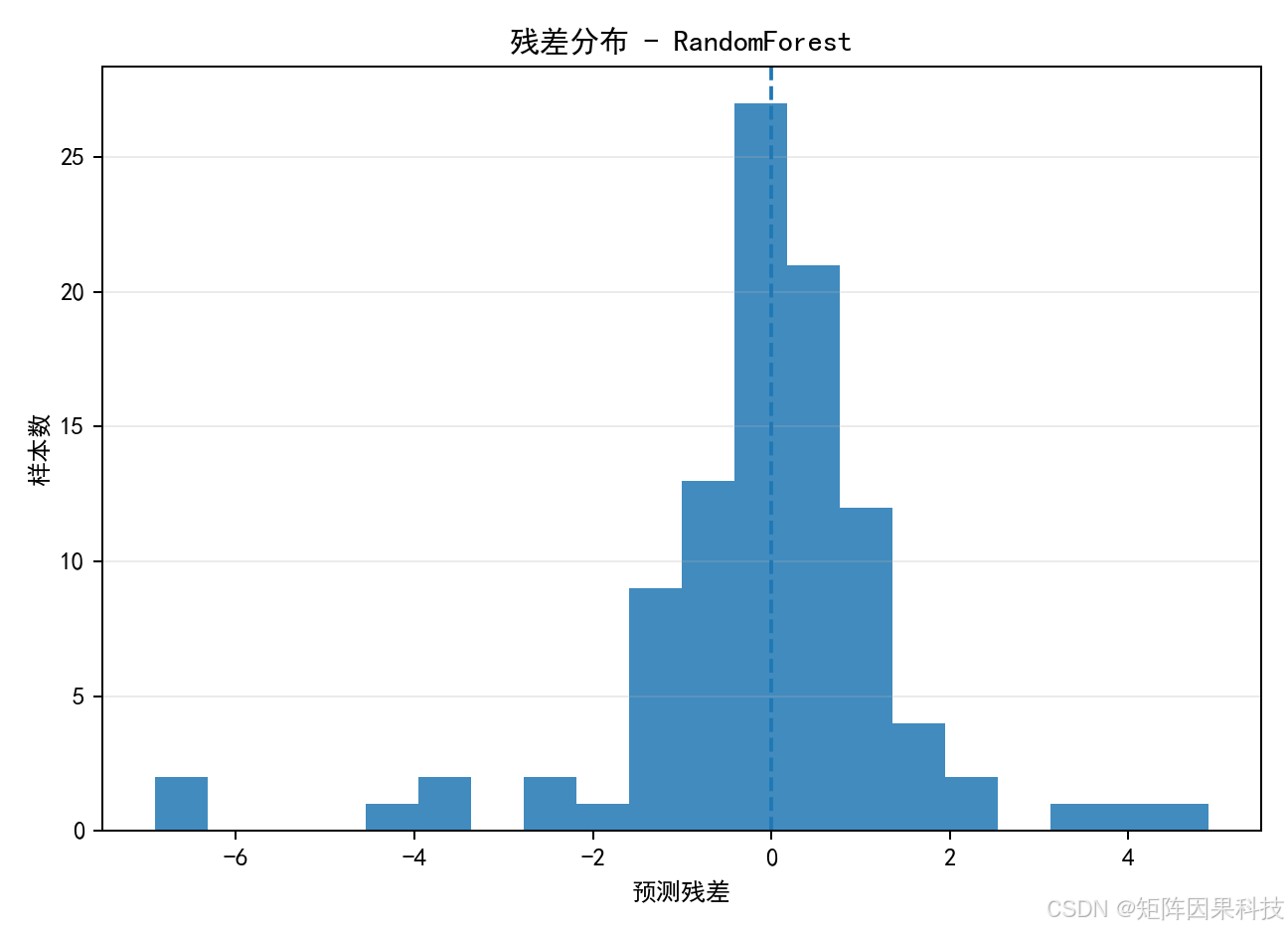
残差分布图检查误差是否集中在 0 附近。本次结果中,多数残差处于较小范围,少量样本出现较大偏差。这个图可以放在论文实验章节中解释模型稳定性。
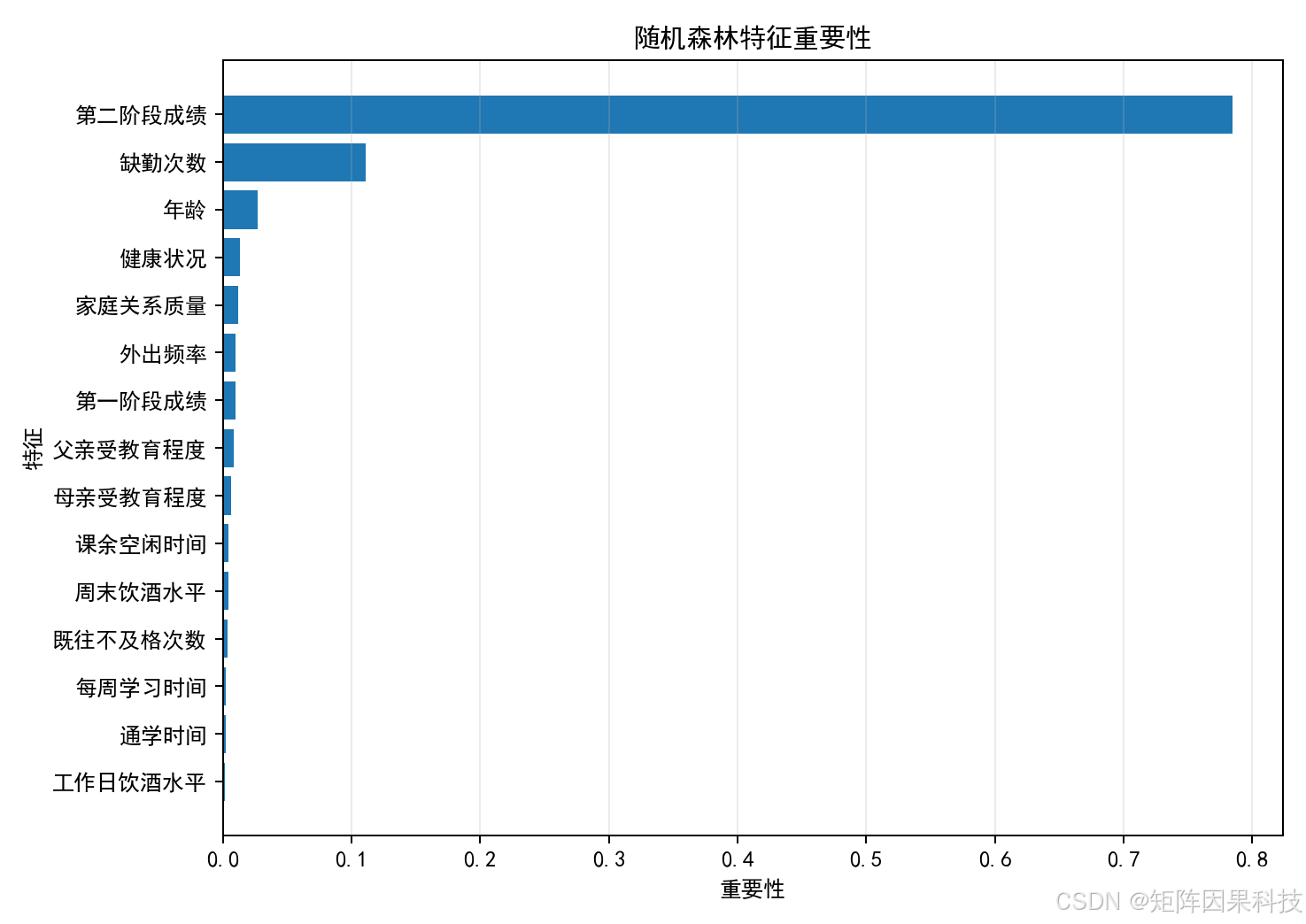
随机森林特征重要性显示,G2 的重要性最高,当前运行中约为 0.7848;absences 约为 0.1108,随后是 age、health、famrel、goout 和 G1。这个结果符合常识:第二阶段成绩与最终成绩关联最强,缺勤和学习行为特征提供额外信息。
报告生成和多智能体验收
实验报告由 ReportAgent 生成,不手工复制指标。它读取:
outputs/metrics.csv
outputs/experiment_summary.json
然后写入 reports/project_report.md。报告包括摘要、实验设计、模型与指标、结果分析、图表说明、可复现说明和扩展方向。因为报告从 CSV 和 JSON 读取数据,所以最佳模型、样本数量、训练集/测试集规模和核心指标能与运行结果保持一致。

如果 Codex 客户端支持子智能体,可以把同一个实验拆成四个角色执行:
| 子任务 | 读取内容 | 输出结论 |
|---|---|---|
| 数据与配置检查 | 配置文件、CSV | 目标列、特征列、样本数、零分样本是否正确 |
| 实验代码检查 | 模板脚本、生成脚本 | 三个模型、四个指标、MAPE 处理是否实现 |
| 运行验证 | 主命令、日志、输出目录 | 命令是否成功、最佳模型和关键指标是多少 |
| 报告写作 | 指标 CSV、摘要 JSON、报告 MD | 报告是否和真实运行结果一致 |
项目中的 prompts/codex_subagents_prompt.md 已经按这四个角色写好。使用时可以让 Codex 分别处理,再由主会话合并结论。这样做能减少常见问题:数据字段没检查、模型漏跑、指标口径不一致、报告里写了旧结果。

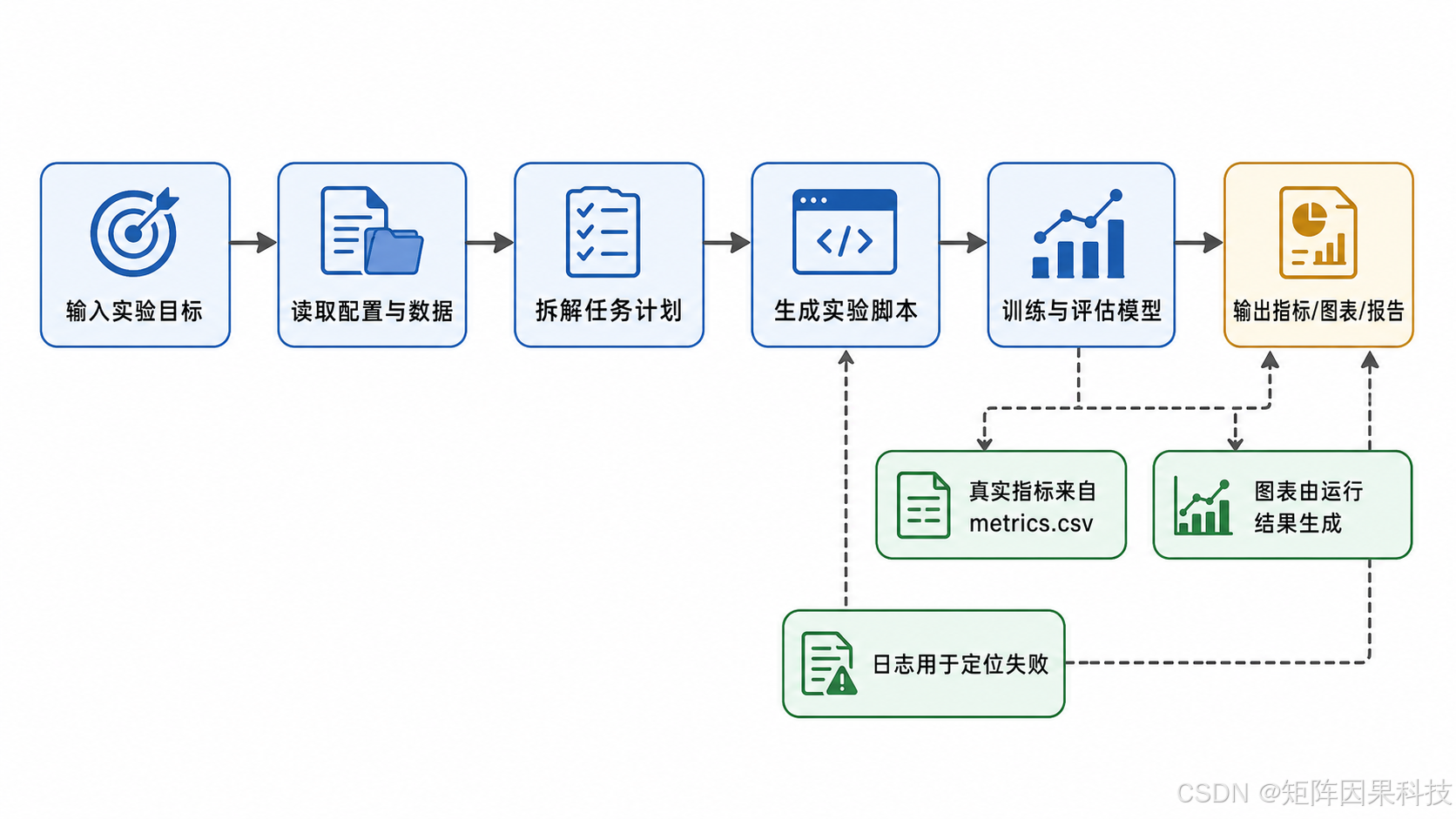
完整流程可以概括为下面这条链路:
复现、结论和扩展方向
源码包的复现命令如下:
pip install -r requirements.txt
python main.py
Windows 用户可以运行:
run.bat
如果要让真实 Codex 继续扩展项目,在项目根目录启动 Codex 后粘贴 prompts/codex_experiment_prompt.md。可以追加下面这段验收要求:
修改后必须运行 python main.py。
最终回复请列出 outputs/metrics.csv 中的最佳模型和关键指标,
并确认 images/results/ 下的结果图已经生成。
后续扩展可以继续保持同样的验收方式:
- 增加 KFold 交叉验证,减少单次划分带来的偶然性。
- 增加参数搜索,比较 RandomForest 不同树数量和深度下的指标变化。
- 做特征消融实验,例如移除
G2或absences后重新训练,观察 RMSE 和 R2 的变化。 - 导出 LaTeX 表格或 Word 报告,减少论文实验章节的手工整理。
- 封装成 Web 页面,让用户上传 CSV 后自动生成指标、图表和报告。
这次测试的结论比较明确:论文实验可以交给智能体参与,但不能只交给一句“帮我写实验”。更可靠的方式是把目标、数据、输出路径、评价指标和完成标准先写进仓库,再让 Codex 在这些边界内生成代码、运行命令、读取结果文件并更新报告。智能体负责加速实验链路,人仍然要用命令、CSV、图表和报告一致性做最后验收。
不管扩展哪一项,都保留同一个原则:先写清目标和输出路径,再让 Codex 改代码,最后用 python main.py 和真实结果文件验收。
参考资料
- OpenAI Codex 官方页面:https://openai.com/codex/
- Codex CLI 官方文档:https://developers.openai.com/codex/cli
- Codex Cloud 官方文档:https://developers.openai.com/codex/cloud
- Codex Best Practices:https://developers.openai.com/codex/learn/best-practices
- Codex Agent Skills:https://developers.openai.com/codex/skills
- Codex Subagents:https://developers.openai.com/codex/subagents
- UCI Student Performance 数据集:https://archive.ics.uci.edu/dataset/320/student+performance

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献78条内容
已为社区贡献78条内容

所有评论(0)