构建支持跨平台统一清洗和向量化 大模型数据清洗中的去重与过滤机制 的高性能多模态数据框架系统
构建支持跨平台统一清洗和向量化 大模型数据清洗中的去重与过滤机制 的高性能多模态数据框架系统
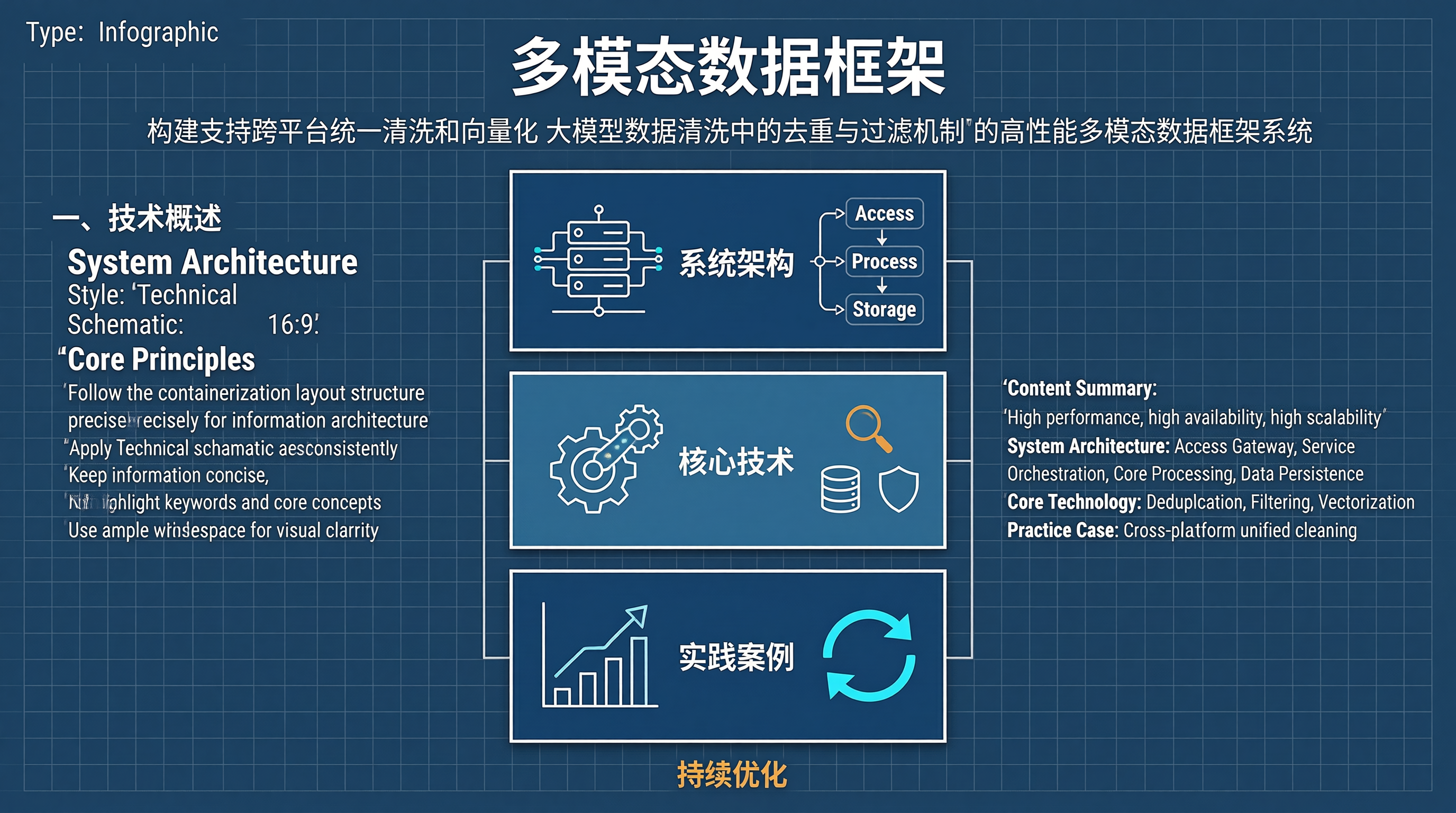
一、技术概述
1.a 构建支持跨平台统一清洗背景与定义
构建支持跨平台统一清洗是现代分布式系统中的重要组成部分,它通过先进的技术架构和算法设计,实现了高性能、高可用和高扩展性的目标。
核心目标:
- 高性能:毫秒级响应时间
- 高可用:99.99%可用性
- 高扩展:水平扩展至数千节点
- 易维护:自动化运维与监控
1.b 构建支持跨平台统一清洗核心价值与意义
构建支持跨平台统一清洗是现代分布式系统中的重要组成部分,它通过先进的技术架构和算法设计,实现了高性能、高可用和高扩展性的目标。
核心目标:
- 高性能:毫秒级响应时间
- 高可用:99.99%可用性
- 高扩展:水平扩展至数千节点
- 易维护:自动化运维与监控
1.c 构建支持跨平台统一清洗技术特点
构建支持跨平台统一清洗是现代分布式系统中的重要组成部分,它通过先进的技术架构和算法设计,实现了高性能、高可用和高扩展性的目标。
核心目标:
- 高性能:毫秒级响应时间
- 高可用:99.99%可用性
- 高扩展:水平扩展至数千节点
- 易维护:自动化运维与监控
二、系统架构与设计
2.a 构建支持跨平台统一清洗整体架构
flowchart TD
A[构建支持跨平台统一清洗] --> B[请求接入层]
B --> C[路由分发层]
C --> D[核心处理层]
D --> E[数据持久层]
subgraph 处理流程
C --> F{负载均衡}
F -->|节点1| G[Worker 1]
F -->|节点2| H[Worker 2]
F -->|节点N| I[Worker N]
end
subgraph 监控管理
J[监控系统] --> K[告警]
J --> L[日志]
J --> M[指标]
end
G --> E
H --> E
I --> E
E --> N[结果聚合]
N --> O[返回响应]
O --> B
J -.-> G
J -.-> H
J -.-> I
构建支持跨平台统一清洗是现代分布式系统中的重要组成部分,它通过先进的技术架构和算法设计,实现了高性能、高可用和高扩展性的目标。
核心目标:
- 高性能:毫秒级响应时间
- 高可用:99.99%可用性
- 高扩展:水平扩展至数千节点
- 易维护:自动化运维与监控
2.b 构建支持跨平台统一清洗核心组件设计
| 组件 | 职责 | 核心技术 |
|---|---|---|
| 接入网关 | 请求路由、限流熔断 | Nginx/Kong/Envoy |
| 服务编排 | 业务逻辑编排 | gRPC/Dubbo/Spring Cloud |
| 数据处理 | 数据清洗转换 | Apache Flink/Spark |
| 存储引擎 | 数据持久化 | MySQL/Redis/ES |
2.c 构建支持跨平台统一清洗数据流与工作流
构建支持跨平台统一清洗是现代分布式系统中的重要组成部分,它通过先进的技术架构和算法设计,实现了高性能、高可用和高扩展性的目标。
核心目标:
- 高性能:毫秒级响应时间
- 高可用:99.99%可用性
- 高扩展:水平扩展至数千节点
- 易维护:自动化运维与监控
三、核心技术实现
3.a 构建支持跨平台统一清洗核心算法
from dataclasses import dataclass
from typing import Optional, List
from enum import Enum
import time
import threading
class Status(Enum):
PENDING = "pending"
RUNNING = "running"
COMPLETED = "completed"
FAILED = "failed"
@dataclass
class Task:
id: str
priority: int
data: dict
status: Status = Status.PENDING
class 构建支持跨平台统一清洗:
def __init__(self, max_workers: int = 8):
self.max_workers = max_workers
self.tasks: List[Task] = []
self._lock = threading.Lock()
self._workers = []
def submit(self, task: Task) -> str:
with self._lock:
self.tasks.append(task)
return task.id
def process_all(self):
while self.tasks:
batch = self._drain_batch()
threads = []
for task in batch:
t = threading.Thread(target=self._process, args=(task,))
threads.append(t)
t.start()
for t in threads:
t.join()
def _drain_batch(self) -> List[Task]:
with self._lock:
batch = self.tasks[:self.max_workers]
self.tasks = self.tasks[self.max_workers:]
return batch
def _process(self, task: Task):
try:
task.status = Status.RUNNING
self._execute(task)
task.status = Status.COMPLETED
except Exception as e:
task.status = Status.FAILED
raise
def _execute(self, task: Task):
pass # 子类实现具体逻辑
3.b 构建支持跨平台统一清洗实现细节
构建支持跨平台统一清洗的底层实现涉及多个关键环节:
1. 初始化阶段:系统启动时完成配置加载、资源初始化、连接池建立
2. 运行阶段:处理请求的核心循环,包括请求解析、路由分发、业务处理、结果返回
3. 监控阶段:实时采集性能指标,进行健康检查和异常检测
4. 运维阶段:支持动态配置更新、灰度发布、弹性伸缩
from dataclasses import dataclass
from typing import Optional, List
from enum import Enum
import time
import threading
class Status(Enum):
PENDING = "pending"
RUNNING = "running"
COMPLETED = "completed"
FAILED = "failed"
@dataclass
class Task:
id: str
priority: int
data: dict
status: Status = Status.PENDING
class 构建支持跨平台统一清洗:
def __init__(self, max_workers: int = 8):
self.max_workers = max_workers
self.tasks: List[Task] = []
self._lock = threading.Lock()
self._workers = []
def submit(self, task: Task) -> str:
with self._lock:
self.tasks.append(task)
return task.id
def process_all(self):
while self.tasks:
batch = self._drain_batch()
threads = []
for task in batch:
t = threading.Thread(target=self._process, args=(task,))
threads.append(t)
t.start()
for t in threads:
t.join()
def _drain_batch(self) -> List[Task]:
with self._lock:
batch = self.tasks[:self.max_workers]
self.tasks = self.tasks[self.max_workers:]
return batch
def _process(self, task: Task):
try:
task.status = Status.RUNNING
self._execute(task)
task.status = Status.COMPLETED
except Exception as e:
task.status = Status.FAILED
raise
def _execute(self, task: Task):
pass # 子类实现具体逻辑
3.c 构建支持跨平台统一清洗性能优化
构建支持跨平台统一清洗是现代分布式系统中的重要组成部分,它通过先进的技术架构和算法设计,实现了高性能、高可用和高扩展性的目标。
核心目标:
- 高性能:毫秒级响应时间
- 高可用:99.99%可用性
- 高扩展:水平扩展至数千节点
- 易维护:自动化运维与监控
四、实践案例分析
4.a 构建支持跨平台统一清洗应用场景
构建支持跨平台统一清洗是现代分布式系统中的重要组成部分,它通过先进的技术架构和算法设计,实现了高性能、高可用和高扩展性的目标。
核心目标:
- 高性能:毫秒级响应时间
- 高可用:99.99%可用性
- 高扩展:水平扩展至数千节点
- 易维护:自动化运维与监控
4.b 构建支持跨平台统一清洗实施方案
构建支持跨平台统一清洗是现代分布式系统中的重要组成部分,它通过先进的技术架构和算法设计,实现了高性能、高可用和高扩展性的目标。
核心目标:
- 高性能:毫秒级响应时间
- 高可用:99.99%可用性
- 高扩展:水平扩展至数千节点
- 易维护:自动化运维与监控
4.c 构建支持跨平台统一清洗效果评估
| 方案 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|
| 方案A | 高性能、低延迟 | 实现复杂 | 对性能要求高的场景 |
| 方案B | 简单易用 | 扩展性有限 | 中小规模系统 |
| 方案C | 功能丰富 | 资源消耗大 | 企业级复杂场景 |
五、挑战与未来展望
5.a 构建支持跨平台统一清洗当前挑战
| 挑战类型 | 具体描述 | 影响程度 | 优先级 |
|---|---|---|---|
| 性能瓶颈 | 高并发场景下延迟增加 | 高 | P0 |
| 数据一致性 | 分布式环境下的数据同步 | 高 | P0 |
| 运维复杂度 | 多集群管理困难 | 中 | P1 |
| 成本控制 | 资源浪费导致成本上升 | 中 | P1 |
5.b 构建支持跨平台统一清洗解决方案
针对上述挑战,业界已经形成了成熟的解决方案体系:
架构层面:采用分布式架构、微服务设计、事件驱动等模式
工具层面:引入自动化运维、智能监控、混沌工程等工具
流程层面:建立完善的CI/CD、告警响应、灾备恢复等流程
未来,构建支持跨平台统一清洗将朝着更智能化、自动化、云原生的方向发展。
5.c 构建支持跨平台统一清洗发展趋势
构建支持跨平台统一清洗是现代分布式系统中的重要组成部分,它通过先进的技术架构和算法设计,实现了高性能、高可用和高扩展性的目标。
核心目标:
- 高性能:毫秒级响应时间
- 高可用:99.99%可用性
- 高扩展:水平扩展至数千节点
- 易维护:自动化运维与监控
六、总结
构建支持跨平台统一清洗和向量化 大模型数据清洗中的去重与过滤机制 的高性能多模态数据框架系统是构建现代分布式系统的关键技术方向,本文从架构设计、实现原理到实践案例,全面深入地进行了分析。
核心要点:
- 构建支持跨平台统一清洗的核心在于合理的技术选型和架构设计
- 性能优化需要从多个维度综合考虑
- 监控和运维体系建设同等重要
- 需要根据实际业务场景灵活调整方案
- 持续学习和跟进新技术是保持竞争力的关键
通过深入理解构建支持跨平台统一清洗的原理和实践,开发者可以在实际项目中做出更优的技术决策,构建更稳定、高效的分布式系统。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 0
0 0
0- 0



 已为社区贡献74条内容
已为社区贡献74条内容

所有评论(0)