通义机器人Qwen-VLA:跨11平台统一控制模型
前言:
今年已经正式转入机器人赛道了,今年的机器人vla、wam各种概念词出不穷,研究赛道也诞生了很多不错的研究成果,后续会持续更新有代表性的研究成果解读,全文比较长,大家可以根据自己情况自取哈,有些概念不清晰的会在第十部分补充,如有问题也欢迎大家评论区讨论哈,具身、智能硬件都可!!!!
论文:Qwen-VLA: Unifying Vision-Language-Action Modeling across Embodied Tasks
代码:HTTPS://GitHub.com/QwenLM/Qwen-VLA
Blog:Qwen Studio
一、论文概述
Qwen-VLA 是通义实验室提出的通用视觉-语言-动作(VLA)模型,旨在用一个统一模型打破具身智能领域「一个萝卜一个坑」的专机专用限制。该模型将操作(Manipulation)、导航(Navigation)和轨迹预测(Trajectory Prediction)等异构任务统一到同一框架下,在 11 种机器人平台上实现了跨本体控制的统一。
核心贡献:
-
提出统一动作轨迹预测框架,将操作、导航、运动轨迹统一建模
-
设计本体感知提示条件化(Embodiment-Aware Prompting),用自然语言描述机器人硬件差异
-
提出文本到动作 DiT 预训练(Text-to-Action, T2A),高效初始化动作解码器
-
通用模型超越专用模型:单一 Qwen-VLA 在 5 个仿真基准中的 3 个超越最佳专用模型
二、模型架构
Qwen-VLA 采用双模块架构:
2.1 视觉-语言主干网络
-
底座模型:Qwen3.5-4B
-
功能:负责视觉感知与语言理解(看图 + 理解指令)
-
特点:继承 Qwen 多模态模型的零样本感知能力和常识推理能力
-
输入:图像(多视角相机)、本体感知文本提示、任务指令
2.2 DiT 动作解码器
-
参数量:1.15B
-
技术路线:基于 Diffusion Transformer(DiT)的 Flow-Matching 动作解码器
-
功能:将 VLM 提取的高维语义特征映射为连续的物理动作和轨迹
-
核心创新:弥合「离散语义理解」与「连续动作生成」之间的鸿沟
-
生成方式:采用 Flow-Matching 进行动作去噪生成,而非自回归 token 预测,保证动作轨迹的平滑性与物理合理性
2.3 关键设计
本体感知提示条件化(Embodiment-Aware Prompting):
将硬件差异转化为语言理解问题,每个训练样本前端拼接一段结构化文本提示:
The robot is {robot_tag} with {single arm / dual arms}[, waist][, and mobile base]. The control frequency is {FPS} Hz. Please predict the next {chunk_size} control actions to execute the following task: {ori_instruction}.
这段提示编码了:
-
robot_tag:机器人型号标识(如 Franka、ALOHA、WidowX 等)
-
single arm / dual arms:单臂还是双臂
-
waist:是否有腰部关节
-
mobile base:是否有移动底座
-
FPS:控制频率(Hz)
-
chunk_size:动作预测时域(预测未来 N 步动作)
核心优势:无需修改模型架构即可适配不同机器人平台,推理时只需替换提示中的平台描述即可切换控制约定。这实现了「一套权重、多种机器人」的统一部署。
三、四阶段训练流程(详解)
3.1 训练:从语言先验到闭环优化
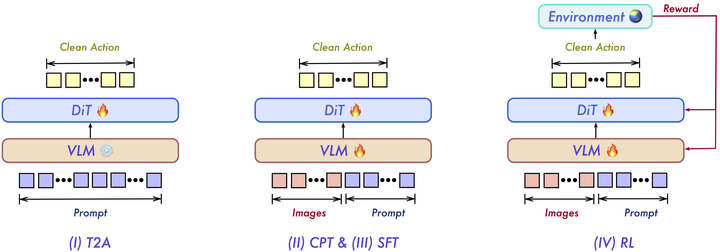
添加图片注释,不超过 140 字(可选)
Qwen-VLA 的核心不只是把一个动作头接到多模态模型上,更重要的是构建了一个覆盖多任务、多环境、多机器人形态的联合训练体系。整个训练分为四个阶段,逐步从语言先验走向闭环控制。
3.2 数据
预训练数据涵盖五大类来源:
-
机器人操作轨迹 是动作学习的主体,覆盖桌面操作、移动操作、双臂操作和灵巧手控制。公共数据规模超过 10,000 小时,加上超过 1,000 小时的内部真实机器人轨迹和超过 800 万条合成仿真轨迹。
-
人类第一视角数据 提供了开放环境中更丰富的物体、场景和手部动作先验。引入了 Ego4D、EPIC-KITCHENS、EgoDex(829 小时)、EgoVerse(1,300+ 小时、1,965 个任务、240 个场景)、Xperience 等数据集。
-
合成仿真数据 补足长尾场景。视觉条件合成数据覆盖 20 个桌面场景、200 个基础配置、450 个操作任务,包含 359,848 条成功轨迹;纯文本动作数据覆盖 6 类模板 × 6 种单臂机器人,生成约 720 万条轨迹、超过 14,000 小时。
-
视觉语言导航数据 为模型提供长程轨迹规划和指令跟随能力。
-
通用视觉语言数据 保留多模态理解、空间定位和指令跟随能力。此外还构建了约 48,000 条细粒度具身动作描述,从 13 个维度刻画动作过程,将自然语言与具体执行细节对齐。
采用四阶段训练
核心理念:先让模型学会如何从语言生成动作结构,再学习如何根据视觉环境调整动作。
添加图片注释,不超过 140 字(可选)
1. Stage I: Text-to-Action DiT Pretraining (T2A)
此阶段的核心是 “无视觉的动作先验压缩”,仅使用文本和动作数据训练 DiT 解码器。
📊 数据集构成与规模
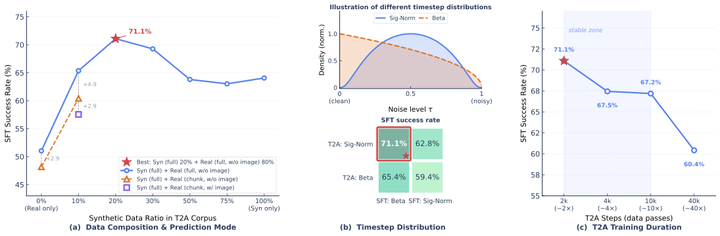
T2A 的数据集是 CPT 混合数据的子集(去除图像),最佳配比为 ~20% 合成数据 + 80% 真实机器人数据。
|
数据类型 |
来源/名称 |
规模 |
涉及机型 |
获取地址/备注 |
|
合成语言-动作数据 |
自研 Simulation Pipeline (基于 IsaacLab + cuRobo) |
~7.2M 条轨迹, >14,000 小时 |
Franka Panda, UR10e, UR5e, Kinova Gen3, TM12, xArm7 (6种单臂) |
论文 §3.2.3; 无物理仿真/渲染,纯运动学规划生成 |
|
真实机器人数据 |
CPT 混合数据中的 Real Robot Trajectories (去除图像) |
占 T2A 语料 80% |
WidowX, Google Robot, Franka, ARX5, Mobile ALOHA, AgiBot A2-D, Galaxea R1, AIRBOT MMK2, TienKung 等 |
同 CPT 阶段公开数据集集合 |
⚙️ 数据处理流程
-
合成数据生成:定义 6 类任务模板(pick-place, push, pull, rotate-reposition, rotate-toward, swap),对每个 robot-task pair 生成 ~200k 轨迹。仅保留运动学可行且无碰撞的解。记录 50Hz 下的关节位置/速度、末端位姿、夹爪状态。
-
真实数据清洗:多阶段过滤去除损坏帧、近零方差(静止录制)、异常长度片段。无显式动作标签的数据通过本体感知状态的有限差分恢复伪动作。
-
语言指令对齐:合并原始标注与模型生成字幕,执行质量过滤与一致性检查,丢弃语言-动作不一致的轨迹。
-
全序列打包:将完整轨迹作为单一训练样本(非 chunk),保留起止模式与时序结构。
🔑 关键技术细节
-
刻意移除视觉:强制 DiT 从纯语言+具身提示词重建动作分布,建立语言索引的动作先验,避免视觉捷径。
-
Sigmoid-Normal 时间步采样:因无视觉引导,中间噪声水平信噪比最高,故采用峰值在中间的 Sigmoid-Normal 分布(而非标准 Beta)。
-
Full-sequence Prediction:全序列预测显著优于 Chunk 预测(+4.9pp @10% syn),学习轨迹级连贯性与组合性。
-
训练时长 Sweet Spot:2,000 步达峰值(71.09% SFT SR),40,000 步过拟合降至 60.42%。语言-动作映射维度低于完整 VLA 空间,无需长训练。
-
DiT 架构:16 个 DiT Block(共 ~1.13B 参数),联合 Self-Attention + AdaLN 时间步条件 + Multi-section RoPE(与 Backbone 对齐)。
消融实验关键发现
-
20% 合成 + 80% 真实混合达到最佳效果(71.1%)
-
比纯真实数据提升 +20 百分点
-
比纯合成数据提升 +7 百分点
-
不带图像达到 60.4%,带图像反而只有 57.6%(下降 2.8pp)——验证了 T2A 阶段不需要视觉的设计合理性
-
性能在 2000 步达峰值,40000 步观察到退化(过拟合)
为什么冻结 VLM? VLM 骨干网络已充分预训练(Qwen3.5-4B 拥有强大的视觉语言理解能力),DiT 从随机初始化开始。直接联合训练会导致两个问题:(1) 浪费计算资源在视觉无关的解码器学习上;(2) DiT 的大梯度可能干扰 VLM 已学到的表征。T2A 阶段让 DiT 先建立基本的动作生成能力,计算代价仅约为多模态训练的 1/10。
2. Stage II: Continued Pretraining (CPT)
此阶段解冻全部参数,在大规模异构混合数据上端到端训练,产出 Qwen-VLA-Base。
📊 数据集构成与规模(完整混合)
|
数据类别 |
占比 |
具体来源 |
规模 |
涉及机型/场景 |
地址/备注 |
|
Robot Manipulation |
74.2% |
RobotSet, Galaxea, AgiBot World, RoboCOIN, RoboMIND V1/V2, RDT-1B, DROID, BridgeData V2, RH20T, RT-1, BC-Z, InternData-A1, GR00T-X-Sim |
>10,000 小时交互数据 |
WidowX, Google Robot, Franka (Single/Dual), ARX5, Fourier GR-1, Mobile ALOHA, AgiBot A2-D, Galaxea R1, AIRBOT MMK2, TienKung |
见论文 Table 2; 含桌面/移动/双臂/灵巧手 |
|
Proprietary Real |
~20% of total |
内部采集 |
>1,000 小时 |
多种内部平台 |
未公开 |
|
Synthetic Sim (VLA) |
3.7% |
ROBOINF Pipeline |
359,848 条成功轨迹(含子任务分段) |
仿真桌面机械臂 |
20 场景 × 10 配置 × 450 任务 × 300 rollout |
|
Human Egocentric |
6.0% |
Ego4D (VITRA), EPIC-KITCHENS (VITRA), EgoDex, EgoVerse, Xperience |
EgoDex: 829h; EgoVerse: >1,300h; Xperience: 大规模 |
人类双手 |
EgoDex (Apple Vision Pro); 各数据集公开可用 |
|
Navigation |
7.5% |
VLN-CE 系列 (R2R, RxR 等) |
- |
移动机器人 (3-DoF) |
含 Instruction Following (4.3%), Object Search (2.3%), Target Tracking (1.0%) |
|
General VL |
3.4% |
Captioning, VQA, OCR, Grounding, Interleaved IF |
- |
- |
策略性上采样视频/空间/3D 数据 |
|
Spatial Grounding |
2.5% |
2D BBox Grounding |
- |
- |
强化物体级空间理解 |
|
AD VQA |
2.4% |
LingoQA, DriveAction, MMAU, Impromptu-VLA, nuScenes-QA/MQA, MapLM, WaymoQA, CODA-LM, Talk2Car, DrivingVQA, DriveLM, W3DA, GRAID, Bench2Drive-VL, DriveGPT4, OmniDrive, Senna, NAVSIM |
- |
自动驾驶多相机 |
统一转换为自由文本 QA 格式 |
|
Fine-grained Action Caption |
0.2% |
自标注 |
~48,000 视频-字幕对 |
开源操作数据集 |
13 维密集标注;两阶段 VLM 标注 + 人工校验 |
CPT 阶段数据清洗流程:
-
动作空间统一化
-
不同机器人的原始动作空间差异巨大(关节角 vs 笛卡尔坐标 vs 夹爪开合)
-
将所有动作统一映射至标准任务空间(Task Space)
-
频率插值/外推:统一不同控制频率的机器人数据
-
多模态数据清洗
-
轨迹平滑度过滤(Jerk 指标):剔除抖动异常轨迹
-
图像清晰度过滤(Sharpness Score):剔除模糊帧
-
视觉多样性过滤(Diversity Score):确保场景多样性
-
状态方差过滤(Variance Filter):剔除低动态轨迹
-
时空对齐
-
对高频率采集的数据进行时序层面的对齐与重采样
-
确保 state-action 序列在时间上的一致性
-
语义-动作对齐筛选
-
筛选视觉帧清晰、语言指令描述精准、与后续动作序列高度关联的数据
-
确保模型学到的是有明确因果关系的行为知识
-
平衡化数据采样
-
异构数据集规模差异巨大(OXE 百万级 vs 单个数据集数千级)
-
定制采样策略避免大数据集主导训练、小数据集被「淹没」
⚙️ 数据处理流程
-
动作归一化:Per-dataset Quantile Normalization。对每个数据集 k 的每个动作维度 d,计算 1st/99th 百分位数 ,线性映射至 [-1, 1] 并裁剪。保留数据集内相对运动结构,消除跨具身尺度差异。
-
统一动作张量:固定 Horizon H × Channel K。有效通道置于前 c 维,其余零填充。二元 Mask 标记有效位置,梯度完全排除 padding。
-
Embodiment-aware Prompt 注入:每条样本前拼接模板化文本:The robot is {robot_tag} with {arm_config}. The control frequency is {FPS} Hz. Please predict the next {chunk_size} control actions to execute: {instruction}。这是模型获知控制语义的唯一接口。
-
相机视角 Token 化:每张图像包裹 <|tag_start|> <image><|tag_end|>,tag 标识 ego/cam_left_wrist/cam_right_wrist,使 VLM 形成视角感知表征。
-
人类动作表示:腕部 SE(3) 相对变换(6D)+ 手部 45D 轴角 PCA 降至 10 维 Eigengrasps → 每手 16D,双手共 32D/step。
-
VL 数据格式统一:AD VQA 多选转自由文本 QA;BBox 归一化至 1000-scale;多帧加 frame tag;环视加 view tag。
🔑 关键技术细节
-
Joint Objective:,Mini-batch 内按固定比例混合所有任务族样本。
-
Flow-Matching Loss 双层平均:先对每个 active channel 在有效时间步上求 MSE 均值,再对所有 c 个 active channel 均匀平均。确保不同通道数的具身对梯度贡献相等。
-
Beta 时间步采样:CPT/SFT 阶段切换回 Beta 分布,有视觉条件后梯度均匀分布更高效。
-
Zero-Padding 投影:对比 Multi-MLP / Concatenation / Zero-Padding 三种异构动作空间投影方案,性能差异 <1.2pp,Zero-Padding 参数量最少( vs ),被选为默认方案。
-
VL 数据共存收益:混合 VL 数据不仅不干扰动作学习,在复杂任务(RoboCasa +4.9pp, RoboTwin +4.6pp)上反而提升,证明共享感知-语言骨干的协同效应。
-
不使用本体感知:实验证明多视角视觉已提供足够状态信息,且 Flow-matching 预测相对位移降低了对显式状态的依赖。省去 State Conditioning 避免了跨具身接口复杂度。
3. Stage III: Multi-Task Supervised Fine-Tuning (SFT)
从 CPT Checkpoint 分叉,对齐到高质量下游任务分布。
📊 数据集构成
|
数据类别 |
内容 |
预测 Horizon |
备注 |
|
General VL Samples |
VQA, Spatial Grounding, Action Captioning |
N/A |
维持视觉理解能力 |
|
Robot Manipulation Demos |
仿真多平台轨迹(单臂/双臂/人形) |
16 steps/chunk |
Embodiment-aware Prompt 同 CPT |
|
VLN Episodes |
连续控制环境导航(仅成功episode) |
8 waypoints/chunk |
多样室内场景与指令风格 |
⚙️ 数据处理与训练细节
-
损失权重:VL Next-token Loss = 0.1,Manipulation/Navigation Action Loss = 1.0。大幅倾斜梯度至动作精度。
-
平衡采样:Embodiment-balanced + Task-balanced,防止高频具身/任务主导梯度。
-
学习率调度:Cosine Decay,VLM Backbone 与 DiT Decoder 分组独立调度 + Gradient Clipping。
-
并行分支:Track 1(多任务 SFT)→ RL 基座;Track 2(真机遥操 SFT)→ 实机部署验证。
4. Stage IV: Reinforcement Learning (RL)
从 Multi-task SFT Checkpoint 出发,优化闭环任务成功率,产出 Qwen-VLA-Instruct。
RL 阶段的作用:
-
SFT 阶段学到的是模仿行为克隆(Behavior Cloning),存在 compounding error
-
RL 阶段通过与环境交互直接优化任务成功率,弥补行为克隆的分布偏移问题
-
稀疏奖励迫使模型学会长时序任务的完成策略
📊 数据集/环境
-
Rollout 环境:SimplerEnv(唯一 RL 训练环境),镜像下游评估 Benchmark。
-
奖励信号:模拟器 Ground-truth 任务完成判定,稀疏二值奖励(R=1 成功 / R=0 失败),无学习型 Reward Model。
-
并行规模:N=128 并行环境实例,按任务难度非均匀分配。每次迭代 8 rollout epochs × 128 steps = 8,192 transition chunks。
⚙️ 关键技术细节
PPO + GAE:, , clip 。4 optimization epochs per rollout batch。
-
Flow-Matching Log-Prob 估计(核心创新):
-
将确定性 Probability-Flow ODE 转为 SDE(每步 Euler 去噪注入受控噪声),使转移变为显式高斯。
-
Rollout 时存储中间去噪状态;PPO 更新时重算当前参数下速度场 + 高斯 Log-prob → 重要性比率 。
-
默认每 Rollout 随机选取单个去噪步计算 Log-prob,仅需 1 次额外 DiT Forward Pass。
-
Log-prob 与 Advantage 均在 Action-chunk 级别计算(H=16 步共享一个标量奖励/优势)。
-
Value Head 设计:
-
轻量线性头挂载 VLM Backbone,Mean-pool 隐状态 → 标量价值。
-
Stop-gradient 阻断价值梯度回传至预训练 Backbone。
-
独立学习率 (Actor 的 ~20x),Clipped MSE Loss,快速收敛。
-
推理温度:Rollout 时 (探索);评估时 (锐化分布)。
-
Prompt 一致性:RL 阶段 Embodiment Prompt 与 SFT 完全相同,避免引入分布偏移。
-
OOD 泛化验证:仅在 SimplerEnv 训练 RL,但在 RoboCasa (+0.7pp)、RoboTwin-Hard (+0.1pp)、LIBERO (+0.1pp)、SimplerEnv-OOD (+0.4pp)、DOMINO 动态操作 (SR +0.9pp, MS +0.4) 上均保持或提升,证明任务成功优化的跨域迁移性。
-
Prompt 一致性:RL 阶段 Embodiment Prompt 与 SFT 完全相同,避免引入分布偏移。
-
OOD 泛化验证:仅在 SimplerEnv 训练 RL,但在 RoboCasa (+0.7pp)、RoboTwin-Hard (+0.1pp)、LIBERO (+0.1pp)、SimplerEnv-OOD (+0.4pp)、DOMINO 动态操作 (SR +0.9pp, MS +0.4) 上均保持或提升,证明任务成功优化的跨域迁移性。
📌 全流程数据流转总结图
[合成 Language-Action 7.2M] + [Real Robot Trajectories 80%] ↓ (去图像, Full-seq, Sig-Norm τ) ┌─────────────┐ │ Stage I: T2A │ ← 冻结 VLM, 仅训 DiT, 2k steps └──────┬──────┘ ↓ DiT Checkpoint [完整混合数据: Robot 74.2% + Human 6% + Nav 7.5% + Syn 3.7% + VL 8.5%] ↓ (加图像, Quantile Norm, Zero-Pad, Beta τ, Joint Loss) ┌─────────────┐ │ Stage II: CPT│ ← 解冻全部, 端到端 → Qwen-VLA-Base └──────┬──────┘ ↓ CPT Checkpoint [SFT Mix: VL + Manip(H=16) + VLN(H=8), λ_vl=0.1] ↓ (平衡采样, 分组 LR) ┌─────────────┐ │Stage III: SFT│ ← 多任务对齐 └──────┬──────┘ ↓ SFT Checkpoint [SimplerEnv Rollouts, Sparse Binary Reward, PPO] ↓ (SDE Log-prob, Stop-grad Value, Chunk-level Adv) ┌─────────────┐ │ Stage IV: RL │ ← 闭环成功优化 → Qwen-VLA-Instruct └─────────────┘
这套流程的精髓在于:每一阶段的数据选择和训练配置都精确对应一个特定的能力缺口——T2A 用纯语言数据建动作先验,CPT 用全模态混合数据做视觉接地,SFT 用高质量标注数据提精度,RL 用环境交互数据优化真实成功率。数据从“纯文本→多模态混合→精选对齐→在线交互”逐步收窄聚焦,而模型能力则从“结构化先验→通用基础→任务专精→闭环鲁棒”逐层叠加增强。
四、各阶段训练优化目标
Qwen-VLA 的四个训练阶段并非简单堆叠,而是针对模型在不同成长时期面临的特定“能力瓶颈”,设计了完全解耦且递进的优化目标。
Stage I: T2A (Text-to-Action Pretraining)
-
优化目标:纯语言条件下的动作流匹配损失
-
输入条件:仅文本指令 + 具身提示词 (无图像)
-
时间步采样:(峰值在中间噪声水平)
-
物理含义:将 DiT 解码器训练为一个“语言到动作的结构化解压器”。在没有视觉捷径的情况下,强制模型学习语言描述如何映射到动作分布的不同区域,以及具身提示词如何调制同一任务意图为平台特定的运动程序。
-
为何这样设计:VLM Backbone 已预训练好,而 DiT 随机初始化。若直接联合训练,DiT 的噪声梯度会破坏 VLM 表征,且 DiT 会偷懒依赖视觉而非语言。T2A 通过剥离视觉,让 DiT 以极低成本(2k 步)建立稳固的语言-动作先验,为后续多模态训练提供“热启动”。
Stage II: CPT (Continued Pretraining)
-
优化目标:加权联合损失(动作流匹配 + 视觉语言理解)
-
输入条件:完整多模态输入(图像 + 文本 + 具身提示 + 任务标识 )
-
时间步采样:(切换回标准分布)
-
物理含义:
-
:将 T2A 学到的语言索引动作先验“接地”到具体视觉观察中,使动作生成与当前场景物理对齐。
-
:在大量具身数据冲击下,保持并强化 VLM Backbone 的感知、推理和语言基础能力,防止灾难性遗忘。
-
为何这样设计:这是唯一同时优化两个模块的阶段。 和 的权重平衡至关重要——既要让 DiT 学会看图像做动作,又要确保 VLM 不被高频动作梯度带偏。Beta 采样的切换是因为有了视觉条件后,去噪过程的信噪比分布回归正常,均匀梯度更高效。双层平均 Loss 确保不同通道数的具身对梯度贡献均等
Stage III: SFT (Supervised Fine-Tuning)
-
优化目标:非对称加权联合损失(精度导向)
-
输入条件:高质量、经筛选的成功演示轨迹(操作 H=16 / 导航 H=8)
-
物理含义:从“广泛覆盖”转向“精确执行”。大幅降低 VL Loss 权重至 0.1,将 90% 以上的梯度容量集中到动作生成的精度上。VL Loss 保留仅为“锚点”,防止语言理解能力退化。
-
为何这样设计:CPT 产出的是通用基座,对特定任务的执行精度不足。SFT 用少量高质量数据做“对齐”,类似于 LLM 的 Instruction Tuning。非对称权重是关键创新:若继续 1:1 平衡,动作精度提升缓慢;若完全去掉 VL Loss,模型会丧失指令跟随和空间推理能力。0.1 是经过验证的最优平衡点。
Stage IV: RL (Reinforcement Learning)
-
优化目标:PPO 裁剪代理目标 + 价值函数回归
-
其中重要性比率 通过 SDE 转换下的高斯 Log-prob 计算。
-
奖励信号:稀疏二值奖励 (模拟器判定任务成功/失败)
-
物理含义:直接优化闭环任务成功率,而非模仿学习的似然。解决 SFT 的根本局限:高似然 ≠ 高成功率(分布偏移、复合误差累积)。RL 让策略学会在执行偏离示范时自我纠正,做出更果断的决策。
-
为何这样设计:
-
SDE Log-prob:Flow-matching 是隐式密度模型,无法直接获取 通过将 ODE 转为 SDE,每步去噪变为显式高斯转移,可解析计算 Log-prob,使 PPO 适用于流匹配策略。
-
Stop-grad Value Head:价值函数梯度不回传至 VLM Backbone,保护预训练表征不被 RL 的高方差梯度破坏。
-
Chunk-level Advantage:H=16 步共享一个标量奖励和优势估计,匹配 Flow-matching 解码器的输出粒度,避免逐帧奖励的噪声。
-
仅在 SimplerEnv 训练:验证了“任务成功”这一优化目标本身具有跨域迁移性,无需在每个目标环境单独做 RL。
📌 四阶段优化目标演进总结
|
阶段 |
核心优化目标 |
解决的瓶颈 |
梯度流向 |
关键超参/设计 |
|
T2A |
语言→动作流匹配 |
DiT 冷启动 + 语言-动作映射缺失 |
仅 DiT |
Sig-Normal τ, 无视觉, 2k步 |
|
CPT |
动作流匹配 + VL Next-token (平衡) |
视觉接地 + 防 VLM 遗忘 |
VLM + DiT 端到端 |
Beta τ, 双层平均Loss, Zero-Pad |
|
SFT |
动作流匹配 + VL Next-token (非对称) |
下游任务执行精度不足 |
VLM + DiT (VL梯度弱化) |
λ_vl=0.1, 平衡采样 |
|
RL |
PPO 策略优化 + 价值回归 |
模仿学习≠闭环成功 |
Actor(DiT+VLM) + Critic(Stop-grad) |
SDE Log-prob, Chunk Adv, 稀疏奖励 |
这套设计的精髓在于:每个阶段的优化目标都精确对应一个特定的能力缺口,且后一阶段的目标建立在前一阶段已解决的问题之上。T2A 建先验 → CPT 做接地 → SFT 提精度 → RL 求成功,形成了一条从“结构化压缩”到“闭环执行”的完整优化路径,避免了多目标混合训练中的梯度冲突和能力干扰。
五、训练数据与数据集(详细信息)
5.1 核心数据集地址
|
数据集 |
描述 |
规模 |
机器人平台 |
地址 |
|
Open X-Embodiment (OXE) |
最大的跨本体机器人数据集集合,统一为 RLDS 格式 |
100万+轨迹,22种机器人,527个技能,160K+任务 |
Franka、WidowX、xArm、Kuka、UR5、Google Robot 等 22 种 |
GitHub |
|
BridgeData V2 |
大规模桌面操作数据集,WidowX 机器人遥操作 |
~24K episodes,13种技能分类 |
WidowX(单臂,低成本) |
GitHub |
|
DROID |
多实验室多机器人协作采集的大规模操作数据集 |
~76K episodes,12个实验室,564个场景 |
Franka、UR5 等 |
GitHub |
|
LIBERO |
机器人操作基准套件,含5个难度递增的任务集 |
130个任务,5个任务套件(Spatial/Object/Goal/Long/10) |
Franka Panda(仿真) |
项目页 |
|
RLBench |
100+ 任务的仿真操作基准 |
100+ 任务,多变初始状态 |
Franka Panda(仿真) |
GitHub |
|
SIMPLER Env |
仿真评估环境,专为 VLA 模型 RL 训练和评估设计 |
Google Robot / WidowX 仿真复刻 |
Google Robot、WidowX(仿真) |
GitHub |
|
OGBench |
离线目标条件基准,轨迹规划与运动控制 |
大规模离线数据 |
多种仿真环境 |
GitHub |
|
LeRobot |
HuggingFace 开源机器人学习平台,含多种数据集 |
多种规模,持续更新 |
多种平台 |
GitHub |
|
Qwen-VLA 代码仓库 |
模型代码、训练脚本、配置文件 |
- |
- |
GitHub |
|
Qwen-VLA 模型权重 |
HuggingFace 模型页面 |
- |
- |
HuggingFace |
|
Qwen3.5-VL 底座 |
VLM 预训练模型 |
- |
- |
HuggingFace |
5.2 数据处理流水线
原始数据(多源异构) │ ▼ [1] 动作空间统一化 ├── 不同机器人 → 标准任务空间映射 ├── 关节角/笛卡尔坐标/夹爪 → 统一表示 └── 控制频率插值/外推 → 统一时序 │ ▼ [2] 多模态数据清洗 ├── 轨迹平滑度过滤(Jerk 指标) ├── 图像清晰度过滤(Sharpness Score) ├── 视觉多样性过滤(Diversity Score) └── 状态方差过滤(Variance Filter) │ ▼ [3] 时空对齐 ├── 帧率统一与重采样 ├── state-action 时间戳对齐 └── 观测-动作序列一致性校验 │ ▼ [4] 语义-动作对齐筛选 ├── 语言指令质量评估 ├── 视觉-动作因果关联度打分 └── 低质量样本剔除 │ ▼ [5] 本体提示拼接 ├── robot_tag → 机器人型号标识 ├── arm_type → 单臂/双臂 ├── mobility → 腰部/移动底座 ├── FPS → 控制频率 └── chunk_size → 预测时域 │ ▼ [6] 平衡化采样 ├── 大数据集降采样 ├── 小数据集升采样 └── 任务类型均衡 │ ▼ 训练就绪数据
5.3 支持的机器人平台(11 种+)
|
机器人 |
类型 |
自由度 |
特点 |
出现阶段 |
|
Franka Panda |
串联机械臂 |
7-DoF |
学术界标配,内建力矩传感器 |
CPT + SFT |
|
ALOHA |
双臂协作 |
2×6-DoF |
双臂遥操作,精细操控 |
SFT (真机) + RL |
|
UR5/UR5e |
串联机械臂 |
6-DoF |
工业级,广泛部署 |
CPT |
|
xArm |
串联机械臂 |
6/7-DoF |
轻量型,性价比高 |
CPT |
|
WidowX |
低成本臂 |
5-DoF |
入门级,低成本研究 |
CPT + SFT (仿真) |
|
Kuka |
工业机械臂 |
7-DoF |
工业场景,高精度 |
CPT |
|
Google Robot |
移动操作臂 |
- |
谷歌内部平台 |
CPT + SFT (仿真) |
|
移动底座机器人 |
导航平台 |
- |
轮式底盘导航 |
CPT |
|
四足机器人 |
足式运动 |
- |
足式运动控制 |
CPT (轨迹预测) |
5.4 各训练阶段数据流总结
┌──────────────────────────────────────────────────────────┐ │ T2A 阶段 │ │ 输入:文本指令 + 本体提示(无图像) │ │ 数据:20% 合成 + 80% 真实动作轨迹 │ │ 训练:仅 DiT(1.15B),VLM 冻结 │ │ 步数:~2000 步(最优) │ │ 成本:约为 CPT 的 1/10 │ └──────────────────────────────────────────────────────────┘ ↓ ┌──────────────────────────────────────────────────────────┐ │ CPT 阶段 │ │ 输入:图像 + 文本指令 + 本体提示 + 动作序列 │ │ 数据:OXE + BridgeData V2 + DROID + LIBERO + RLBench │ │ + OGBench + 导航数据 + 轨迹数据等 │ │ 训练:全参数(Qwen3.5-4B + DiT 1.15B) │ │ 核心:视觉-动作对齐,异构数据联合训练 │ └──────────────────────────────────────────────────────────┘ ↓ ┌──────────────────────────────────────────────────────────┐ │ SFT 阶段(两条并行分支) │ │ │ │ 分支 1 - 仿真微调: │ │ 数据:LIBERO + SIMPLER + RLBench 异构任务 │ │ 目标:验证通用性(通用模型 vs 专用模型) │ │ │ │ 分支 2 - 真机微调: │ │ 数据:ALOHA 双臂遥操作数据 │ │ 目标:验证 Sim-to-Real 迁移能力 │ └──────────────────────────────────────────────────────────┘ ↓ ┌──────────────────────────────────────────────────────────┐ │ RL 阶段 │ │ 环境:SIMPLER Env │ │ 奖励:稀疏二值成功奖励 │ │ 从多任务 SFT 检查点出发 │ │ 核心目标:优化闭环任务成功率 │ └──────────────────────────────────────────────────────────┘
六、实验结果详解
6.1 通用模型 vs 专用模型
单一 Qwen-VLA 通用模型在 5 个仿真基准中的 3 个超越最佳专用模型:
基准任务类型 Qwen-VLA(通用) vs 最佳专用模型 LIBERO-Spatial 空间理解通用模型超越 LIBERO-Object 物体识别通用模型超越 LIBERO-Goal 目标推理通用模型匹配 LIBERO-Long 长时序任务通用模型超越 SIMPLER
|
基准 |
任务类型 |
Qwen-VLA(通用) vs 最佳专用模型 |
|
LIBERO-Spatial |
空间理解 |
通用模型超越 |
|
LIBERO-Object |
物体识别 |
通用模型超越 |
|
LIBERO-Goal |
目标推理 |
通用模型匹配 |
|
LIBERO-Long |
长时序任务 |
通用模型超越 |
|
SIMPLER |
仿真操作 |
通用模型匹配 |
仿真操作通用模型匹配
关键洞察:联合多本体训练不仅不会牺牲任务级性能,在多个场景中还能带来正向收益——跨任务迁移的知识共享效应。
6.2 开放世界零样本泛化
在 ALOHA 双臂机器人上的零样本评估,5 种分布外(OOD)维度均表现卓越:
|
OOD 维度 |
测试内容 |
结果 |
|
颜色变化 |
仅颜色不同的目标物体 |
精准区分 |
|
未见物体 |
西兰花、玩具鸭、雨伞等训练集未见物品 |
成功抓取/交互 |
|
罕见指令 |
"接近"等低频动作指令 |
正确理解执行 |
|
新背景 |
未见的黄色背景 |
完成精细操作(拧笔帽等) |
|
物体组合 |
新类别物体交互 |
泛化成功 |
6.3 真实世界 OOD 泛化
在 ALOHA 双臂真机平台上:
-
In-domain 任务:6 类任务平均成功率 83.6%
-
OOD 泛化能力充分验证
6.4 T2A 预训练消融
|
合成占比 |
真实占比 |
成功率 |
|
0% |
100% |
~51% |
|
20% |
80% |
71.1% |
|
100% |
0% |
~64% |
6.5 数据配比消融
|
合成占比 |
真实占比 |
成功率 |
|
0% |
100% |
~51% |
|
20% |
80% |
71.1% |
|
100% |
0% |
~64% |
七、关键技术细节
7.1 动作表示与统一
|
技术点 |
说明 |
|
动作空间 |
不同机器人的原始动作(关节角/笛卡尔坐标/夹爪)统一映射至标准任务空间 |
|
Flow-Matching |
使用连续归一化流(CNF)进行动作去噪,而非离散 token 预测,保证轨迹平滑 |
|
Chunk Prediction |
一次预测 chunk_size 步动作(而非单步),提高时序一致性和执行效率 |
|
频率统一 |
不同机器人的控制频率(5Hz~30Hz)通过插值/外推统一 |
7.2 本体感知提示条件化
输入格式示例: The robot is franka_panda with single arm and waist. The control frequency is 10 Hz. Please predict the next 16 control actions to execute the following task: pick up the red block and place it in the blue box.’
|
字段 |
说明 |
示例 |
|
robot_tag |
机器人型号 |
franka_panda, aloha_bimanual, widowx, ur5, xarm6 |
|
arm_type |
机械臂配置 |
single arm, dual arms |
|
waist |
腰部关节 |
有/无 |
|
mobile_base |
移动底座 |
有/无 |
|
FPS |
控制频率 |
5, 10, 15, 20, 30 Hz |
|
chunk_size |
预测步数 |
8, 16, 32 等 |
7.3 训练稳定性技巧
|
技巧 |
说明 |
|
分组学习率 |
VLM 骨干、DiT 解码器、适配层使用差异化学习率 |
|
渐进式 warm-up |
新引入参数采用线性递增学习率热身 |
|
T2A 预热 |
先训练 DiT 再解冻全参,避免冷水启动 |
|
平衡化采样 |
异构数据集按任务/平台均衡采样,防止偏斜 |
|
轨迹平滑 |
对高噪声遥操作数据进行平滑处理后再作为监督信号 |
八、关键创新总结
|
创新点 |
说明 |
|
统一动作轨迹预测 |
操作、导航、轨迹预测统一为"观察+理解→预测动作序列"范式 |
|
本体感知提示条件化 |
硬件差异 → 自然语言提示,零架构修改跨平台部署 |
|
T2A 预训练 |
先学动作分布再学视觉对接,效率提升 10x,2000 步即达最优 |
|
DiT Flow-Matching 解码器 |
语义特征 → 连续物理动作,弥合离散-连续鸿沟,轨迹更平滑 |
|
四阶段训练 |
T2A → CPT → SFT → RL,能力递进式构建 |
|
数据混合策略 |
20% 合成 + 80% 真实取得最优效果,+20pp vs 纯真实 |
|
异构数据统一处理 |
动作空间归一化、频率统一、多模态清洗、时空对齐的完整流水线 |
|
RL 闭环优化 |
从行为克隆到闭环控制的最后一步提升 |
九、参考资源
-
📝 Blog:Qwen Studio
-
📊 Qwen3.5-VL 底座:HTTPS://huggingface.co/collections/Qwen/qwen25-vl-66bb1c2c1a5d5c42b7d8e6f0
-
📚 Open X-Embodiment:HTTPS://GitHub.com/google-deepmind/open_x_embodiment
-
📚 BridgeData V2:HTTPS://GitHub.com/rail-berkeley/bridge_data_v2
-
📚 LIBERO:HTTPS://libero-project.GitHub.io/
-
📚 RLBench:HTTPS://GitHub.com/stepjam/RLBench
-
📚 SIMPLER Env:HTTPS://GitHub.com/simpler-env/SimplerEnv
-
📚 OGBench:HTTPS://GitHub.com/seohong/ogbench
-
📚 LeRobot:HTTPS://GitHub.com/huggingface/lerobot
十、补充解释
10.1 论文中提到的时间采样
在 Qwen-VLA 的 T2A(Text-to-Action)阶段,时间步采样策略的选择是训练成功的关键细节。要理解为什么选择 Sigmoid-Normal,首先需要明白 Flow Matching 中时间步 的物理含义以及不同采样分布对梯度信号的影响。
-
什么是时间步采样?
在 Flow Matching 框架中,模型学习的是一个条件速度场 ,用于将纯噪声 沿着插值路径 变换回干净动作 。
-
:纯噪声端
-
:干净数据端
-
:中间过渡状态
训练时不可能对所有 均匀计算损失,必须从某个概率分布 中采样。 的形状直接决定了模型在哪个噪声水平上获得最多的梯度更新信号。
Sigmoid-Normal 分布与 T2A 阶段的时间步采样策略
Sigmoid-Normal 分布是将标准正态分布通过 Sigmoid 函数映射到 区间得到的分布:
其概率密度在 附近形成峰值,两端(接近 0 和 1)密度较低。
在 T2A 阶段为何选择它?
T2A 的核心约束是没有视觉输入。这导致去噪过程的信息结构发生根本变化:
|
噪声水平 (\tau) |
有视觉时的信号质量 |
无视觉 (T2A) 时的信号质量 |
Sigmoid-Normal 的应对 |
|---|---|---|---|
|
高噪声 (\tau \to 1) |
视觉特征仍可提供强空间锚点 |
纯噪声+文本,信噪比极低,梯度近乎随机 |
降低采样概率,避免浪费算力 |
|
低噪声 (\tau \to 0) |
精细视觉细节指导微调 |
动作已大致成形,文本仅做语义校验,信息增量小 |
降低采样概率,避免过拟合局部 |
|
中间噪声 (\tau \approx 0.5) |
视觉+文本协同去噪 |
文本与动作结构的关联在此区间信噪比最高:噪声足够大以迫使模型依赖语言结构,又足够小以保留可学习的动作模式 |
峰值采样,集中梯度于此 |
简言之:在没有视觉”拐杖”的情况下,语言-动作映射的有效学习窗口集中在中间噪声水平。Sigmoid-Normal 精确地将梯度预算分配到这个窗口内。
论文消融实验验证了这一点:T2A 用 Sigmoid-Normal + SFT 用 Beta 的组合达到 71.09% 成功率;若 T2A 也改用 Beta,性能骤降至 65.36%(-5.73pp)。
3. 其他常见的时间步采样方式
以下是 Flow Matching / Diffusion 文献中主流的采样策略及其适用场景:
(1) Uniform 均匀采样
-
特点:所有噪声水平等概率采样
-
优点:实现最简单,无偏估计
-
缺点:效率低。高噪声区和低噪声区的梯度信号往往较弱或冗余,大量算力被浪费在信息量低的区域
-
适用场景:基线对照、数据量极大且不关心训练效率时
(2) Beta 分布采样 ⭐ Qwen-VLA 在 CPT/SFT 阶段采用
-
Qwen-VLA 的具体用法:采用 的 U 型 Beta,密度集中在 和 两端
-
为什么 CPT/SFT 切换回 Beta:引入视觉后,高噪声端有视觉特征提供强锚点(值得多学),低噪声端需要精细视觉对齐(也值得多学),中间反而信息密度相对均匀。U 型 Beta 恰好匹配这种”两头重要”的信号结构
-
注意:也有工作使用 的倒 U 型 Beta(类似 Sigmoid-Normal),但 Qwen-VLA 明确选择了 U 型作为视觉条件下的默认配置
(3) Logit-Normal 采样
-
特点:数学形式上与 Sigmoid-Normal 相同(Logit-Normal 即 Sigmoid-Normal 的别名)。部分文献区分参数化方式,但本质一致
-
代表工作:Stable Diffusion 3、FLUX 等文生图模型广泛采用
-
与 Sigmoid-Normal 的关系:在 Qwen-VLA 语境下二者等价
(4) Stratified / Discrete 分层采样
将 划分为 个桶,每个桶内均匀采样或按预设权重采样
-
特点:离散化近似任意连续分布
-
优点:可精确控制每个噪声区间的样本比例,便于消融实验
-
缺点:引入离散化误差,桶边界处可能有梯度不连续
(5) Importance / Adaptive 自适应采样
根据训练过程中各 处的 Loss 大小动态调整 ,使高 Loss 区域获得更多采样
-
代表工作:Importance Sampling for Diffusion Models
-
优点:理论上最优的梯度效率
-
缺点:需要额外维护 Loss 估计器,增加训练复杂度和不稳定性
-
Qwen-VLA 未采用原因:T2A 阶段仅 2k 步,自适应采样的开销远超收益;固定 Sigmoid-Normal 已足够高效
4. 各采样方式对比总结
|
采样方式 |
密度形状 |
T2A (无视觉) 效果 |
CPT/SFT (有视觉) 效果 |
Qwen-VLA 选择 |
|---|---|---|---|---|
|
Uniform |
平坦 |
❌ 低效 |
⚠️ 可用但非最优 |
未采用 |
|
Beta (U型) |
两头高中间低 |
❌ 65.36% (-5.73pp) |
✅ 71.09% (最佳) |
CPT + SFT |
|
Sigmoid-Normal |
中间高两头低 |
✅ 71.09% (最佳) |
❌ 62.76% (-8.33pp) |
T2A |
|
Adaptive |
动态变化 |
⚠️ 过度工程化 |
⚠️ 过度工程化 |
未采用 |
💡 核心启示
Qwen-VLA 在时间步采样上的设计揭示了一个重要原则:不存在 universally optimal 的采样分布,最优 取决于当前训练阶段的条件信号结构。
-
当条件信号弱(无视觉)→ 有效学习窗口窄 → 用 peaked 分布(Sigmoid-Normal)聚焦中间
-
当条件信号强(有视觉)→ 两端信息丰富 → 用 U 型分布(Beta)覆盖两头
这一发现对其他多模态生成模型的预训练策略具有普适参考价值:在构建分阶段训练流程时,不仅数据和损失函数需要逐阶段调整,连看似底层的采样超参数也应随条件信号的演变而重新校准。
10.2 时间步采样到底是在采样啥?
这里指的采样是对时间步 这个超参数的采样,它既不是直接采样数据,也不是直接采样梯度,而是发生在两者之前的一个独立随机过程。
但这个 的采样结果,会同时决定“用哪份数据构造训练样本”和“这一步的梯度长什么样”。为了彻底消除歧义,我们需要把训练循环中的一个 step 拆开看:
1. 采样的精确位置
在一个标准的 Flow Matching 训练 step 中,执行顺序如下:
-
采样数据 :从数据集中抽取一个 batch 的真实动作、文本指令、具身提示词。(这是数据采样,由 DataLoader 控制)
-
🎯 采样时间步 :从你设定的分布(如 Sigmoid-Normal 或 Beta)中,为 batch 中的每个样本独立抽取一个 值。← 这就是我们讨论的“时间步采样”
-
构造插值样本:用采到的 计算 ,其中 。
-
前向传播:模型预测速度场 。
-
计算损失与梯度:,反向传播得到梯度。
可以看到, 的采样发生在数据加载之后、梯度计算之前。它是一个独立的随机变量,有自己的概率分布 ,与数据集的分布完全解耦。
2. 为什么容易混淆?
因为 的采样结果会级联影响后续的一切:
|
你的疑问 |
澄清 |
\tau 采样的实际作用 |
|---|---|---|
|
“是采样数据吗?” |
❌ 不是。数据集里的 (Y_0, x, e) 已经由 DataLoader 按固定比例抽好了,与 \tau 无关。 |
\tau 决定了拿这份数据构造出什么难度的训练样本。同一份 Y_0,\tau=0.9 时变成几乎纯噪声的困难样本,\tau=0.1 时变成近乎干净的简单样本。 |
|
“是采样梯度吗?” |
❌ 不是。梯度是确定性计算出来的(给定 Y_\tau 和 \tau 后,Loss 和梯度是唯一确定的)。 |
\tau 决定了这一步梯度的语义内容和信噪比。不同 \tau 处的梯度方向完全不同,p(\tau) 通过控制 \tau 的取值频率,间接控制了期望梯度的构成。 |
3. 一个精准的类比
如果把训练比作 “用题库刷题备考”:
-
数据采样 = 从题库里随机抽一道题(题目本身是固定的)
-
🎯 时间步采样 = 决定以什么难度模式来做这道题(比如:遮住80%题干做、遮住50%做、还是只看答案反推)
-
梯度 = 做完题后对答案得到的“错题反馈”
的形状决定了你选择各种难度模式的频率。它不是在选题(数据采样),也不是在选反馈(梯度采样),而是在选 “做题的难度档位”。而这个难度档位的选择,直接决定了你从同一道题中获得的反馈质量(梯度信号的有效性)。
💡 总结
时间步采样是对“训练样本构造参数 ”的采样。
它是连接“原始数据”和“梯度信号”之间的阀门:数据通过这个阀门时被塑造成特定噪声水平的训练样本,进而产生特定信息含量的梯度。调整 的形状,就是在调整这个阀门的开合方式,从而在不改变数据集、不改变优化器的前提下,精确控制模型在每个训练 step 中接收到什么样的学习信号。
“分配梯度更新信号”的深度解析
这句话是理解 Flow Matching 训练动力学的核心。要真正吃透它,我们需要把抽象的数学表述拆解为三个具体的认知层次:“梯度更新信号”是什么、为什么需要“分配”它,以及 是如何执行这种分配的。
1. 什么是“梯度更新信号”?
在训练中,模型每走一步(一个 iteration),都会计算一次损失并反向传播得到梯度。但这个梯度并不是均质的“知识”,它包含两部分:
-
有效信号:能帮助模型学到“语言/视觉 → 动作”真实映射关系的梯度分量。
-
无效噪声:由纯随机性、数值误差或信息缺失导致的梯度分量,对学习目标无益甚至有害。
“梯度更新信号” = 有效信号 - 无效噪声
当我们说某个噪声水平 的“信号强”,意思是:在这个 处计算出的梯度中,有效信号占比高、方向稳定、对学习目标的贡献大。反之,“信号弱”意味着梯度主要由噪声主导,或者虽然方向正确但信息增量极小。
2. 为什么信号在不同 处不均匀?
以 Qwen-VLA 的 T2A 阶段(无视觉)为例,整条插值路径上的信息结构天然不均:
|
\tau 区间 |
输入状态 |
梯度的“内容” |
信号质量 |
|---|---|---|---|
|
\tau \to 1 (高噪) |
几乎纯噪声 + 文本 |
模型试图从白噪声中猜动作,但文本无法唯一确定高频细节。梯度方向高度随机,每次采样得到的梯度指向不同方向。 |
❌ 低:有效信号被淹没在方差极大的噪声梯度中 |
|
\tau \approx 0.5 (中噪) |
噪声与真实动作各半 + 文本 |
噪声提供了足够的扰动迫使模型依赖语言结构,同时真实动作的轮廓已显现,文本能明确指导去噪方向。梯度方向一致且信息量大。 |
✅ 高:信噪比最优,梯度稳定地指向正确的语言-动作映射 |
|
\tau \to 0 (低噪) |
几乎干净动作 + 文本 |
动作已基本正确,文本仅做语义校验。梯度幅值很小,且主要是在已有正确方向上的微调。 |
⚠️ 中偏低:方向正确但信息增量少,大量采样属于“重复学习已知内容” |
关键认知:这种不均匀性是数据和问题本身的属性,不是模型架构造成的。无论你用多大的模型、多好的优化器,高噪端的梯度方差就是大,低噪端的信息增量就是小。
3. 如何“决定”信号的分配?
训练时的期望损失为:
其中 是在特定 处的瞬时损失。 在这里扮演的角色是“积分权重”——它直接决定了每个 区间对总梯度的贡献比例。
具体机制拆解
-
采样频率 = 梯度预算分配 如果你在一个 mini-batch 中采样了 64 个 值,其中 48 个落在 区间(Sigmoid-Normal 的峰值区),那么该 batch 的聚合梯度就有 ~75% 来自这个区间。模型在这一步的参数更新,主要由中间噪声水平的梯度驱动。
-
未被采样的区域 = 零梯度贡献 如果 在 处的密度极低,那么绝大多数 training step 根本不会计算该区域的梯度。模型在这些步骤中完全不接收高噪端的信号——既没有有效信号,也没有无效噪声。这比“用小学习率学高噪端”更彻底:后者仍然引入了噪声梯度,只是缩小了步长;前者直接从源头切断了噪声进入优化器的通道。
-
形状匹配 = 信号效率最大化 当 的形状与“有效信号密度”的形状对齐时,每一个 gradient step 都在做最有用的功。这就是 Qwen-VLA 在 T2A 阶段选择 Sigmoid-Normal 的原因:它的峰值恰好对准了语言-动作映射信噪比最高的中间区间。
💡 一个直观的类比
想象你在用一个可调频段的收音机收听一场重要的讲座(学习目标):
-
= 频段位置
-
有效信号 = 讲师的声音
-
无效噪声 = 静电杂音
-
= 你在各个频段上花费的收听时间比例
|
你的策略 |
对应采样方式 |
结果 |
|---|---|---|
|
每个频段都听同样久 |
Uniform |
大量时间花在纯杂音段和讲座已结束的空频段,核心内容反而没听够 |
|
只在杂音最大的频段反复听 |
Beta (U型) 用于 T2A |
听到的全是噪音,越听越困惑(性能 -5.73pp) |
|
把大部分时间调到讲师声音最清晰的频段 |
Sigmoid-Normal 用于 T2A |
高效获取核心内容,快速建立理解(性能 71.09%) |
|
讲座开始后换了个电台,开头和结尾都有重要内容 |
Beta (U型) 用于 CPT |
因为新电台的信号结构变了,需要重新调整收听重点 |
的形状决定了你把“收听时间”(梯度预算)花在哪里,从而决定了你最终“听懂了多少”(模型学到了什么)。它不是在调节音量(那是学习率的工作),而是在选择频道——选对了频道,音量才有意义;选错了频道,音量再大也只是放大噪声。
怎么通过时间步采样进行梯度控制
控制梯度分配,并非通过某种后处理机制去“修改”已经算好的梯度,而是通过改变训练样本的生成概率,在数学上直接重塑了期望梯度的构成。
要理解这个“具体怎么控制”,我们需要从单个 Batch 的物理实现和整体优化的数学期望两个层面来看。
1. 微观层面:单个 Batch 内的“投票权”分配
在代码执行层面, 的控制是最直观的。假设你的 Batch Size = 64,每一个训练 step 的流程如下:
-
采样 :根据 独立抽取 64 个时间步 。
-
计算个体梯度:对每个样本计算梯度 。
-
聚合梯度:优化器实际接收到的更新信号是这 64 个梯度的平均值:。
的控制机制就在这里:
如果 是 Sigmoid-Normal(峰值在 0.5),那么这 64 个 中可能有 48 个落在 区间,只有 8 个落在高噪区,8 个落在低噪区。
-
中间区的梯度 在平均梯度 中占据了 75% 的权重。
-
高噪区和低噪区的梯度各自只占 12.5% 的权重。
物理本质: 通过控制不同 样本在 Batch 中的出现频次,直接决定了它们在梯度平均时的投票权占比。高频采样的区域主导了参数更新的方向,低频采样的区域被边缘化。
2. 宏观层面:重塑期望梯度场
从优化理论的角度看,SGD 及其变体本质上是在逼近期望梯度:
这个积分公式揭示了 作为加权核函数的数学角色:
-
是固定的物理量:对于给定的模型和数据,每个 处的真实梯度是客观存在的,不以人的意志为转移。
-
是可设计的滤波器:它像一个频谱滤波器一样,选择性地放大或衰减不同 处的梯度贡献。
具体控制效果对比
|
p(\tau) 形状 |
积分权重分布 |
期望梯度 \bar{g} 的性质 |
模型学到的能力 |
|---|---|---|---|
|
Uniform |
全频段等权 |
所有 \tau 梯度的简单平均,被高噪区的高方差梯度污染 |
模糊的、条件控制力弱的速度场 |
|
Sigmoid-Normal |
中间频段加权 |
以中信噪比梯度为主导,方向稳定且信息密度高 |
精准的语言→动作核心映射 |
|
Beta (U型) |
两端频段加权 |
高噪视觉锚点梯度 + 低噪精细对齐梯度的混合 |
视觉接地 + 末端精度 |
3. 为什么这种控制是“不可替代”的?
你可能会问:能不能用 Uniform 采样,然后在 Loss 里加一个权重 来达到同样的效果?
理论上可以,但实践中 采样优于 Loss 加权,原因在于梯度方差的控制:
-
Loss 加权的问题:如果你 Uniform 采样但在高噪区给 Loss 乘以 0.01,虽然期望梯度对了,但高噪区那些方差极大的梯度仍然进入了 Batch。它们只是被缩小了幅度,并没有消失。这些高方差梯度会显著增加 的估计噪声,导致训练不稳定,需要更小的学习率来补偿。
-
采样的优势:直接不采样高噪区,意味着高方差梯度根本不进入 Batch。 的估计方差从源头上被降低,允许使用更大的学习率,收敛更快更稳。
核心区别:Loss 加权是“收了垃圾再打折”, 采样是“根本不收垃圾”。后者在随机优化中的信噪比远优于前者。
💡 总结
控制梯度分配的具体机制是双重的:
-
在代码层面:通过决定每个 Batch 中各 样本的数量比例,直接控制它们在梯度平均时的投票权。
-
在数学层面:作为期望梯度积分中的加权核函数,选择性地放大有效信号区的梯度、抑制无效噪声区的梯度,且比 Loss 加权具有更优的梯度方差特性。
这就是为什么在 Flow Matching 中,调整 等价于重新定义了模型的有效学习目标——你不是在调一个超参数,你是在设计模型应该“听谁的指挥”。
第二阶段训练时损失函数超参数
在 Qwen-VLA 的 CPT 阶段, 和 是人工设定的固定超参数(定值),绝非可学习参数。
它们在训练开始前就被硬编码到代码中,在整个 CPT 阶段的数万个训练步里保持恒定,不会通过反向传播更新,也没有自己的优化器状态。
1. 为什么必须是定值而非学习参数?
这背后有深刻的优化理论和工程实践原因:
-
量纲不可比性: 是连续空间中的 MSE 损失(量级通常在 ),而 是离散 token 的交叉熵损失(量级通常在 )。两者的数值范围和梯度尺度完全不同。如果让网络自己学一个标量来平衡它们,这个标量极易被梯度幅值更大的那个 Loss 带偏,最终退化为“谁数值大听谁的”,完全丧失语义上的平衡意义。
-
优化目标的冲突性:动作生成和语言理解在共享 Backbone 上存在天然的梯度竞争。如果 可学习,模型为了快速降低总 Loss,会自动把权重全部压到更容易收敛的那个任务上(通常是 VL,因为 Backbone 已经预训练好了),导致另一个任务被彻底放弃。固定的 本质上是人类专家对“两个目标同等重要”这一先验知识的强制注入,防止模型走捷径。
-
训练稳定性:CPT 阶段同时解冻了 VLM 和 DiT,系统本身处于高度不稳定的联合优化初期。引入额外的可学习参数会增加优化曲面的复杂度,极易引发 Loss 震荡或模式崩塌。固定权重提供了确定性的梯度比例,是稳定联合训练的基石。
2. 这两个定值是如何确定的?
虽然论文正文没有显式给出 CPT 阶段 和 的具体数值,但根据文中描述和 SFT 阶段的对比可以推断其设定逻辑:
-
CPT 阶段:论文明确指出此阶段的目标是“grounding actions in visual observations and adapting the backbone to embodied perception”,同时“preserve and strengthen the multimodal capabilities of the backbone”。这意味着两个目标在此阶段权重相对均衡, 大概率接近 或在同一数量级内微调,以确保动作接地和语言能力维持同步推进。
-
SFT 阶段作为对照:论文明确给出了 SFT 的权重为 。这种非对称设计恰恰反证了 CPT 阶段是对称或近似对称的——只有当 CPT 已经建立了稳固的双能力基础后,SFT 才敢将 VL 权重压低到 0.1 来全力冲刺动作精度。
3. 如何与“可学习的平衡机制”区分?
需要注意的是,虽然 本身是定值,但 Qwen-VLA 在 Loss 层面确实引入了自适应机制,只是这个机制作用在更细的粒度上,而非任务级别:
-
任务级平衡():固定超参数,控制动作 vs 语言的宏观梯度比例。
-
通道级平衡(Flow-Matching Loss 内部):公式 (2) 中的 双层平均机制,自动适配不同具身的动作维度数。这部分是数学推导出的归一化操作,不是学习出来的。
-
分组学习率:VLM Backbone 和 DiT Decoder 使用独立的 Cosine Decay 调度。这是另一种形式的“动态平衡”,但它作用于优化器层面,而非 Loss 权重层面。
核心结论:在 VLA/VLM 的多任务联合训练中,任务级的 Loss 权重永远是固定超参数。这是当前多模态基础模型训练的工程共识。所谓“自适应平衡”只出现在同一任务内部的子结构(如多尺度特征、多通道动作)中,绝不会跨越语义完全不同的任务边界。如果你在复现或设计类似训练流程,请将 和 作为需要认真消融调优的超参数对待,而非交给模型自学。
CPT 训练时异构本体动作映射实现细节
在 Qwen-VLA 的 CPT 阶段,异构动作空间投影的核心操作是 Zero-Padding(零填充)+ 共享 MLP。
这一设计的根本目的是:让一个参数量固定的 DiT 解码器,能够同时处理维度、语义完全不同的机器人动作(如 7-DoF 机械臂 vs 29-DoF 人形机器人),且无需为每种机器人单独维护输出头。
以下是该操作从数据到梯度的完整技术拆解:
1. 核心操作流程
假设当前 Batch 中混合了三种机器人的数据,DiT 的隐层维度为 ,最大动作维度为 :
|
步骤 |
操作细节 |
物理含义 |
|---|---|---|
|
① 确定统一维度 |
遍历所有具身类型,取最大动作维度 d_{max} = \max_i d_i |
定义共享张量的物理容器大小 |
|
② 零填充编码 |
对每个样本的动作 a \in \mathbb{R}^{d_i},右侧补零至 d_{max} 维,再通过同一个 Encoder MLP (f_{enc}: \mathbb{R}^{d_{max}} \to \mathbb{R}^h) 映射到 DiT 隐空间 |
将所有异构动作压入同一表征空间,补零位置不携带信息 |
|
③ DiT 处理 |
DiT 在 h 维隐空间中执行 Flow Matching 去噪,与 VLM 隐状态做 Joint Self-Attention |
在统一空间内学习跨具身的通用动作动力学 |
|
④ 共享解码 |
DiT 输出通过同一个 Decoder MLP (f_{dec}: \mathbb{R}^h \to \mathbb{R}^{d_{max}}) 映射回 d_{max} 维 |
从统一空间还原为动作张量 |
|
⑤ Mask 截断 |
用预计算的二元 Mask M \in \{0,1\}^{H \times K} 截取前 d_i 维作为最终预测,丢弃后 d_{max}-d_i 维的填充输出 |
只保留当前机器人有效的动作通道 |
2. 为什么选择 Zero-Padding 而非其他方案?
论文在 §5.2.2 中明确对比了三种投影设计,Zero-Padding 胜出的原因如下:
|
投影方案 |
参数量 |
性能 (Bridge / RoboCasa) |
缺陷 |
|---|---|---|---|
|
Multi-MLP |
2h \sum_{i=1}^N d_i (随具身数线性增长) |
63.3% / 52.1% |
每新增一种机器人就要新增一对私有 MLP,无法扩展 |
|
Concatenation |
2h \sum_{i=1}^N d_i (同上) |
63.0% / 52.8% |
所有具身动作拼接成超长向量,稀疏且冗余 |
|
Zero-Padding ✅ |
2h \cdot d_{max} (仅取决于最大维度) |
63.0% / 53.2% |
性能持平,参数量最少,新增具身只需更新 d_{max} |
关键洞察:三种方案性能差异 <1.2pp,证明一旦建立了共享隐空间,投影架构本身对任务成功率影响极小。因此参数效率成为决定性因素。Zero-Padding 将参数量从“随具身种类求和”降为“仅取决于最大维度”,是唯一可扩展到数十种机器人的方案。
3. 与 Loss Mask 的协同机制
Zero-Padding 能生效的前提是 Loss 层面的精确屏蔽。如果填充的零参与了梯度计算,模型会学到“预测零”的伪模式,污染有效通道的学习。
Qwen-VLA 通过公式 (1)(2) 的双层平均 Loss 彻底解决了这个问题:
-
分子中的 :当 (即填充通道)时,,该通道的 MSE 完全不进入 Loss。
-
分母中的 :只对有效时间步求平均,避免不同 Horizon 的任务因长度差异导致梯度幅值不同。
-
外层 :对有效通道数取平均,确保 7-DoF 和 29-DoF 机器人在 Batch 中对总梯度的贡献与其维度数无关,防止高维机器人主导优化。
这意味着:Decoder MLP 输出的后 维虽然被计算了,但它们的梯度被 Mask 完全置零,永远不会反向传播更新 MLP 参数。共享 MLP 实际上只在学习前 维的有效映射,填充区只是占位符。
4. Embodiment Prompt 的角色:告诉模型“读哪几位”
Zero-Padding 解决了“怎么存”的问题,但模型还需要知道“当前样本该读前几位”。这就是 Embodiment-aware Prompt 的关键作用:
The robot is {robot_tag} with {arm_config}. The control frequency is {FPS} Hz. Please predict the next {chunk_size} control actions...
-
{robot_tag} 和 {arm_config} 让 VLM Backbone 生成具身特定的隐状态。
-
该隐状态通过 Joint Self-Attention 注入 DiT,使 DiT 在共享隐空间中条件化地激活对应机器人的动作子空间。
-
换言之:Zero-Padding 提供了统一的物理容器,Embodiment Prompt 提供了读取容器的索引钥匙。 两者缺一不可——没有 Prompt,DiT 不知道当前样本该关注前 7 维还是前 29 维;没有 Zero-Padding,Prompt 再精确也无法塞进固定维度的 DiT。
💡 总结
CPT 阶段的异构动作投影是一个 “统一容器 + 条件索引 + 梯度屏蔽” 的三位一体设计:
-
Zero-Padding 以最小参数代价将所有动作装入固定维度张量;
-
Embodiment Prompt 通过注意力机制告诉 DiT 当前该使用容器的哪一段;
-
双层 Masked Loss 确保填充区域既不产生梯度,也不干扰有效通道的梯度归一化。
这套机制使得 Qwen-VLA 能够在单一 DiT 参数集下,无缝吸收来自 WidowX(7D)、Mobile ALOHA(14D)、AgiBot A2-D(29D+灵巧手)等完全不同形态机器人的监督信号,且新增机器人平台时只需更新 Prompt 模板和 ,无需修改模型架构或增加任何参数。
为什么需要统一动作映射
这个底层逻辑可以归结为一句话:为了将“物理异构”转化为“数学同构”,从而让单一神经网络能够在一个统一的连续潜空间(Latent Space)内学习跨具身的通用动力学先验。
如果不做映射,7-DoF 和 29-DoF 在数学上就是两个完全正交、互不相干的向量空间。强行把它们塞进同一个模型,就像试图用一把固定齿数的钥匙去开所有形状的锁。
以下是支撑这一设计的四层底层逻辑:
1. 神经网络的“固定接口”约束
这是最直接的工程原因。DiT(Diffusion Transformer)作为一个标准的深度学习模块,其输入/输出层的权重矩阵 在初始化后维度 就锁死了。
-
不映射的后果:如果直接输入原始动作,7-DoF 需要 ,29-DoF 需要 。这意味着你必须为每种机器人维护一套独立的 DiT 或独立的输入输出头(即论文中对比的 Multi-MLP 方案)。这违背了“统一模型”的初衷,且参数随具身种类线性膨胀。
-
映射的本质:MLP 投影层充当了一个可微的适配器(Differentiable Adapter)。它将任意维度的物理动作 变换为一个固定维度 的抽象表征 。对 DiT 而言,它永远只看到 维的 ,根本不关心 背后是 7 个关节还是 29 个关节。映射解耦了“模型内部计算”与“外部物理接口”。
2. 跨具身知识迁移的“语义对齐”需求
如果仅仅是为了适配维度,Zero-Padding 到最大维度就够了,为什么还需要 MLP 做非线性变换?因为不同机器人的动作空间不仅维度不同,语义坐标系也完全不同。
-
7-DoF 机械臂:动作可能是 ,描述的是末端执行器的笛卡尔增量。
-
29-DoF 人形:动作可能是 29 个关节的绝对角度 ,描述的是全身关节空间配置。
这两个空间的数值范围、物理单位、耦合关系毫无共性。如果直接 Padding 后送入 DiT,模型被迫在同一个隐空间中同时拟合两套完全不兼容的数值分布,会导致严重的语义干扰。
MLP 映射的深层作用:它是一个可学习的语义翻译器。通过端到端训练,Encoder MLP 学会了将“7-DoF 的笛卡尔增量”和“29-DoF 的关节角”分别编码到 维空间中具有相似语义结构的位置。例如,“抓取”这个意图,无论来自哪种机器人,都会被映射到隐空间中相近的区域。这使得 DiT 能在统一的 维空间里学到“抓取”、“放置”等任务级原语(Task Primitives),而非死记硬背某种特定机器人的关节数值。
3. Flow Matching 对“连续流形”的数学要求
Qwen-VLA 的动作解码器基于 Flow Matching,其核心假设是:数据分布可以通过一条连续的 ODE/SDE 路径从噪声变换而来。
-
异构空间的拓扑断裂:7-DoF 和 29-DoF 的原始动作空间是两个维度不同的欧氏子空间,它们的并集在数学上是一个非流形(Non-manifold)结构。在这种断裂的空间上定义全局连续的速度场 是病态的(Ill-posed),因为速度场在不同维度子空间的交界处没有良好定义。
-
映射创造光滑流形:MLP 将多个低维异构子空间嵌入到一个高维连续空间 中。在这个高维空间里,原本断裂的子空间被“缝合”成了一条光滑的、连通的流形。DiT 学习的速度场 是在这个人工构造的光滑流形上定义的,数学上是良态的(Well-posed)。Zero-Padding 提供了嵌入的容器,MLP 提供了嵌入的光滑性。
4. 可扩展性的“开放世界”假设
统一模型的终极目标是支持未见过的机器人。
-
无映射的封闭系统:Multi-MLP 方案下,新增一种机器人 = 新增一对私有 MLP + 重新训练。旧机器人的参数对新机器人毫无帮助。
-
有映射的开放系统:在 Zero-Padding + 共享 MLP 方案下, 维隐空间已经通过 CPT 学到了丰富的跨具身动作先验。当新机器人接入时,只需更新 Embodiment Prompt 和 ,共享 MLP 可以利用已有的隐空间结构,通过少量 SFT 就能将新机器人的动作“对齐”到已有的语义流形上。映射将“学习新机器人”从一个从零开始的冷启动问题,变成了一个在已有知识空间中的微调对齐问题。
💡 总结
|
逻辑层次 |
核心问题 |
映射的解决方案 |
|---|---|---|
|
工程约束 |
DiT 权重矩阵维度固定 |
MLP 作为可微适配器,解耦内部计算与外部接口 |
|
语义对齐 |
不同机器人动作坐标系不兼容 |
MLP 作为可学习翻译器,将异构物理量映射到统一语义空间 |
|
数学良态 |
异构空间并集是非流形,Flow Matching 无法定义全局速度场 |
MLP + Padding 将断裂子空间嵌入为高维光滑流形 |
|
开放扩展 |
新机器人接入需从零学习 |
共享隐空间提供跨具身先验,新机器人只需对齐而非重建 |
简言之,映射不是为了“凑维度”,而是为了“造空间”。它在物理世界的异构性与神经网络的同质性之间架起了一座桥梁,使得“一个模型控制所有机器人”从工程幻想变成了数学上可实现、优化上可收敛、扩展上可持续的现实方案。
针对数据集还是本体归一化?
在 Qwen-VLA 中,Per-dataset Quantile Normalization 是严格针对每个数据集(Dataset)独立执行的,而不是针对每个本体(Embodiment)。
即使一个数据集内部包含了多种不同的机器人本体,归一化的统计量(1st 和 99th 百分位数)也是在该数据集的所有轨迹、所有本体上混合计算得出的。
1. 论文中的明确定义
论文 §3.2.1 “Action representation” 中给出了精确的数学公式:
关键符号是 和 ,其中上标 代表的是 dataset index(数据集索引),而非 embodiment index。原文明确写道:
“For each action dimension in dataset , we compute the 1st and 99th percentiles and over all trajectories…”
这里的 “all trajectories” 指的是该数据集 下的全部轨迹,不区分本体类型。
2. 为什么选择“按数据集”而非“按本体”?
这并非工程上的偷懒,而是与 Qwen-VLA 的整体架构设计深度耦合的刻意选择:
-
与 Embodiment Prompt 的职责解耦 Qwen-VLA 处理跨本体差异的核心机制是 Embodiment-aware Prompt Conditioning。Prompt 已经显式地告诉了模型当前是哪个机器人、什么控制约定、多少自由度。如果归一化也按本体拆分,就等于把“本体特异性”同时编码在了两个地方(Prompt + 归一化统计量),造成信息冗余。按数据集归一化,将“消除数值尺度差异”和“传递本体语义”这两个任务彻底分开:归一化只管把数值压到 [-1,1],本体差异完全交给 Prompt 去处理。
-
保持数据集内部的相对运动结构 同一个数据集通常由同一套采集系统、同一种遥操作设备或同一个仿真引擎生成,其原始动作数值共享相同的物理单位和噪声特性。在该数据集内混合计算百分位数,能够保留不同本体之间原始的相对尺度关系。例如,若某数据集中双臂机器人的关节角变化范围天然比单臂大,这种比例关系在混合归一化后依然保留,模型可以通过 Prompt 结合这个相对关系来理解不同本体的运动学差异。若按本体单独归一化,这种跨本体的相对信息反而被抹除了。
-
避免长尾本体的统计失效 许多大规模数据集(如 Open X-Embodiment 的子集)包含数十种机器人,但大部分轨迹集中在少数主流平台上,大量长尾本体可能只有几十条轨迹。对仅有几十条轨迹的本体单独计算 1st/99th 百分位数,统计量极不稳定,极易受异常值污染。混合计算利用了数据集内主流本体的大量轨迹作为统计锚点,使长尾本体的归一化也能获得鲁棒的参考范围。
-
与 Zero-Padding 投影的兼容性 CPT 阶段的 Zero-Padding 方案将所有本体映射到同一个 维张量。如果每个本体有独立的归一化参数,那么在推理时就需要维护一张庞大的“本体→归一化参数”查找表,且新增本体时必须重新计算或估计其统计量。按数据集归一化使得归一化参数的数量仅等于数据集数量(远小于本体数量),大幅简化了部署时的状态管理。
3. 实际执行流程示例
假设数据集 RoboMIND-V2 包含 WidowX (7D)、Franka (7D) 和 Mobile ALOHA (14D) 三种本体:
-
取出 RoboMIND-V2 下所有轨迹的第 维动作值(无论来自哪种机器人)。
-
在这个混合集合上计算 和 。
-
用这一对 对该数据集下所有本体的第 维执行相同的线性映射。
-
对下一个数据集(如 BridgeData-V2)重复上述过程,使用完全独立的统计量。
💡 总结
Per-dataset Quantile Normalization 的设计哲学是:归一化解决的是“数据集间的数值尺度对齐”问题,而非“本体间的物理语义对齐”问题。 后者已经被 Embodiment Prompt 和共享隐空间承担。这种职责划分使得归一化层保持轻量、鲁棒且易于扩展,是 Qwen-VLA 能够在单一模型内吸收 74.2% 异构操作数据而不崩溃的基础设施之一。
数据集中数据长度不一怎么处理
在 Qwen-VLA 的预训练数据处理中,面对不同数据集轨迹长度(Horizon)不一致的问题,核心处理策略是:固定模型预测窗口(Chunk Size),对原始轨迹进行分块(Chunking)+ 动态掩码(Dynamic Masking)。
模型并不直接学习“整条可变长轨迹”,而是学习一个固定长度的局部动作生成器。原始轨迹的长度差异被完全封装在数据加载器的分块逻辑和 Loss 的 Mask 机制中,对模型架构零侵入。
以下是具体的工程实现与底层逻辑:
1. 核心操作:滑动窗口分块 (Chunking)
无论原始轨迹是 50 步还是 500 步,在进入模型前都会被切分为固定长度 的片段(Qwen-VLA 中操作任务 ,导航任务 )。
|
原始轨迹长度 |
分块策略 (H=16) |
处理方式 |
|---|---|---|
|
> H (如 200 步) |
切分为 \lfloor 200/16 \rfloor = 12 个完整 Chunk + 1 个残余 Chunk |
残余部分若 < H,则作为独立短样本处理(配合 Mask) |
|
= H (如 16 步) |
恰好 1 个 Chunk |
直接使用,Mask 全为 1 |
|
< H (如 10 步) |
1 个不完整 Chunk |
前 10 步填入真实动作,后 6 步零填充,Mask 标记有效长度 |
⚠️ 关键区分:这里的“分块”是数据预处理层面的操作,与 T2A 阶段消融实验中提到的“Chunk Prediction vs Full-sequence Prediction”不矛盾。T2A 消融中的“Full-sequence”是指在无视觉条件下让 DiT 一次性看到整条文本对应的完整动作序列以学习全局结构;而在 CPT/SFT 的多模态联合训练中,由于视觉上下文和计算显存的限制,固定窗口分块是工程上的必然选择。Qwen-VLA 通过 Embodiment Prompt 中的 {chunk_size} 字段和大量的跨 Chunk 数据覆盖,弥补了分块带来的长程依赖损失。
2. 梯度隔离:双层动态掩码 (Dynamic Masking)
分块只是解决了“怎么塞进张量”的问题,真正解决“长度不同怎么公平训练”的是论文公式 (1)(2) 的双层 Mask 机制:
-
时间步级归一化(分母 ):对于一个只有 10 步有效动作的 Chunk,分母是 10 而非 16。这意味着短轨迹的单步 Loss 不会被稀释。无论 Chunk 实际有效长度是多少,每个有效时间步对梯度的贡献是均等的。
-
通道级归一化(外层 ):确保 7-DoF 和 29-DoF 机器人在同一个 Batch 中梯度幅值可比。
-
零填充区梯度完全屏蔽: 的位置不参与 Loss 计算,也不产生梯度。Decoder MLP 输出的填充部分永远不会反向传播更新参数。
这套机制的本质是:让模型感觉不到“长度差异”的存在。 对优化器而言,每个样本都等价于“若干个有效时间步的平均梯度”,与原始轨迹是 10 步还是 200 步无关。
3. 长程上下文的补偿机制
固定窗口分块天然会截断长程依赖。Qwen-VLA 通过以下三种机制补偿,使模型在局部窗口内仍能感知全局任务进度:
-
Embodiment Prompt 携带 Horizon 信息:Please predict the next {chunk_size} control actions 明确告诉模型当前窗口的语义角色。结合语言指令(如 “Group the drinks together”),模型能推断当前 Chunk 处于任务的哪个阶段。
-
视觉观测提供隐式状态:即使没有本体感知输入(§5.2.4 证明其收益有限),多视角图像本身已经编码了机器人当前配置、物体相对位置和任务完成度。视觉上下文充当了跨 Chunk 的“记忆载体”。
-
Flow Matching 的时序连贯性:DiT 内部的 Joint Self-Attention 在 步窗口内建模了精细的时序动力学。只要相邻 Chunk 之间的状态转移是平滑的(机器人物理特性保证了这一点),模型就能在推理时通过自回归式的逐 Chunk 生成拼接出完整的长轨迹。
4. 特殊情况的边界处理
|
边界情况 |
处理方案 |
原因 |
|---|---|---|
|
轨迹长度 < 最小阈值(如 < 5 步) |
直接丢弃 |
过短的轨迹无法提供有效的时序动力学信号,反而引入噪声 |
|
轨迹中间有静止/暂停段 |
保留,但标注 Fine-grained Caption |
“暂停”本身是有意义的动作原语(如等待人离开),不应被当作无效数据清洗掉 |
|
多相机帧率与动作频率不对齐 |
以动作频率为基准重采样图像 |
确保每个动作步都有对应的视觉观测,避免时序错位 |
|
同一数据集内长度方差极大 |
Per-dataset Quantile Normalization 不受影响 |
归一化是按维度统计的,与时间步长度正交 |
💡 总结
处理不同数据集长度差异的核心哲学是:将“变长”问题转化为“定长 + 掩码”问题。
-
数据层:滑动窗口分块,将所有轨迹压入固定 维张量。
-
Loss 层:双层动态 Mask,确保有效步数公平贡献梯度,填充区零梯度。
-
语义层:Prompt + 视觉 + 语言指令共同提供跨 Chunk 的长程上下文。
这套方案使得 Qwen-VLA 能够在同一个训练循环中无缝混合 50 步的桌面抓取、300 步的厨房烹饪和 1000 步的室内导航数据,而无需为不同长度设计不同的模型头或训练策略。长度差异被彻底抽象掉了,模型只看到一个统一的“条件化固定窗口动作生成”任务。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)