机器学习笔记_西瓜书_05(神经网络)
神经网络
神经网络的研究始于对生物神经系统的抽象,而神经元模型是其核心基础单元,感知机则是基于神经元模型构建的最简单神经网络。本文严格遵循《周志华·机器学习》(西瓜书)的推导逻辑,从生物启发出发,依次讲解神经元模型的数学实现、感知机的结构与工作原理、感知机的学习策略与权重更新算法,并基于西瓜书的0/1标记体系,完整推导损失函数与权重更新规则。
一、神经元模型:从生物抽象到数学实现
神经网络的本质是“由具有适应性的简单单元(神经元)组成的广泛并行互连网络”(Kohonen,1988),神经元模型的设计灵感源于生物神经元的工作机制,是构建所有复杂神经网络的基础。
1.1 生物启发背景
在生物神经系统中,每个神经元通过突触与其他神经元相连。当神经元被激活时,会向相连神经元发送化学信号,改变其内部电位;若电位超过某个阈值,该神经元会被激活(兴奋),进而向其他神经元传递信号。
1943年,[McCulloch and Pitts,1943]将这一生物过程抽象为M-P神经元模型,这是目前仍在广泛使用的经典神经元模型。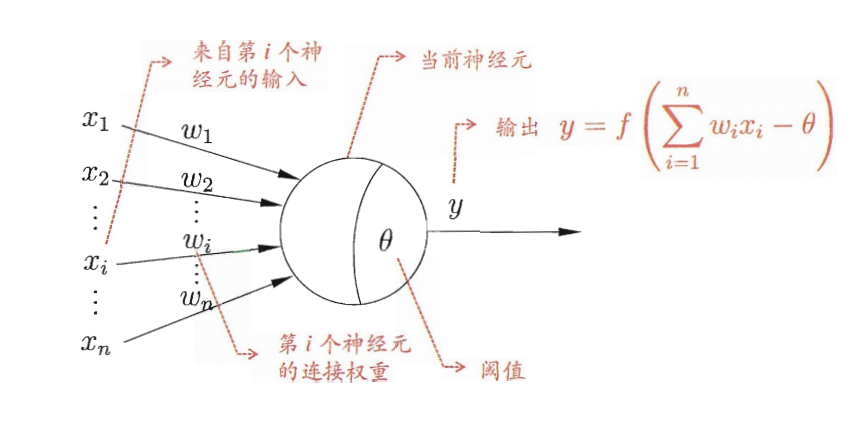
1.2 M-P神经元模型的核心结构与数学表达
M-P神经元模型通过“输入-加权-阈值比较-激活输出”四步流程,模拟生物神经元的信号处理过程,其输入输出关系可表示为:
y = f ( ∑ i = 1 n w i x i − θ ) = f ( w T x − θ ) y = f\left( \sum_{i=1}^n w_i x_i - \theta \right) = f\left( w^T x - \theta \right) y=f(i=1∑nwixi−θ)=f(wTx−θ)
其中各符号的定义如下:
- 输入信号: x 1 , x 2 , . . . , x n x_1, x_2, ..., x_n x1,x2,...,xn(或向量形式 x ∈ R n x \in \mathbb{R}^n x∈Rn),对应生物神经元的突触输入,来自其他 n n n个神经元的输出;
- 连接权重: w 1 , w 2 , . . . , w n w_1, w_2, ..., w_n w1,w2,...,wn(或向量形式 w ∈ R n w \in \mathbb{R}^n w∈Rn),表示每个输入信号的重要性系数,权重越大,对应输入对当前神经元输出的影响越强;
- 阈值: θ \theta θ,也称为偏置,是神经元被激活的电位门槛,对应生物神经元的激活阈值;
- 激活函数: f ( ⋅ ) f(\cdot) f(⋅),对“净输入” w T x − θ w^T x - \theta wTx−θ进行非线性转换,输出神经元的最终状态(兴奋/抑制),是神经元模型实现非线性表达能力的关键。
1.3 激活函数的选择:理想与现实的平衡
激活函数的核心作用是将神经元的净输入转换为输出状态,其选择需平衡生物合理性与数学可计算性,文档中主要介绍了两种激活函数。
1.3.1 理想激活函数:单位阶跃函数
单位阶跃函数完美模拟生物神经元“超过阈值则激活,否则抑制”的离散特性,其定义为:
f ( z ) = { 1 z > 0 ( 神经元兴奋 ) 0.5 z = 0 ( 临界状态 ) 0 z < 0 ( 神经元抑制 ) f(z) = \begin{cases} 1 & z > 0 \quad (\text{神经元兴奋}) \\ 0.5 & z = 0 \quad (\text{临界状态}) \\ 0 & z < 0 \quad (\text{神经元抑制}) \end{cases} f(z)=⎩
⎨
⎧10.50z>0(神经元兴奋)z=0(临界状态)z<0(神经元抑制)
其中 z = w T x − θ z = w^T x - \theta z=wTx−θ为净输入。
缺陷:函数不连续、不可微。而神经网络的训练(如BP算法)依赖梯度下降优化参数,阶跃函数的不可微性会导致梯度无法计算,因此无法直接用于多层网络训练。
1.3.2 实际常用激活函数:Sigmoid函数
为解决阶跃函数的数学缺陷,实际中常用Sigmoid函数,其定义为:
f ( z ) = 1 1 + e − z f(z) = \frac{1}{1 + e^{-z}} f(z)=1+e−z1
核心特点:
- 连续性与可微性:函数在全体实数域连续且任意阶可导,满足梯度下降优化的数学需求;
- 挤压特性:将任意范围的输入 z z z映射到 ( 0 , 1 ) (0,1) (0,1)区间,输出值可理解为“神经元兴奋的概率”;
- 非线性:Sigmoid函数的非线性是神经网络能拟合复杂数据分布的基础——若使用线性激活函数,多层网络将退化为单层线性模型。
延伸:文档后续提到的“对数几率函数”是Sigmoid函数的重要特例,其输出可直接关联到类别后验概率,为神经网络的概率解释提供了支撑。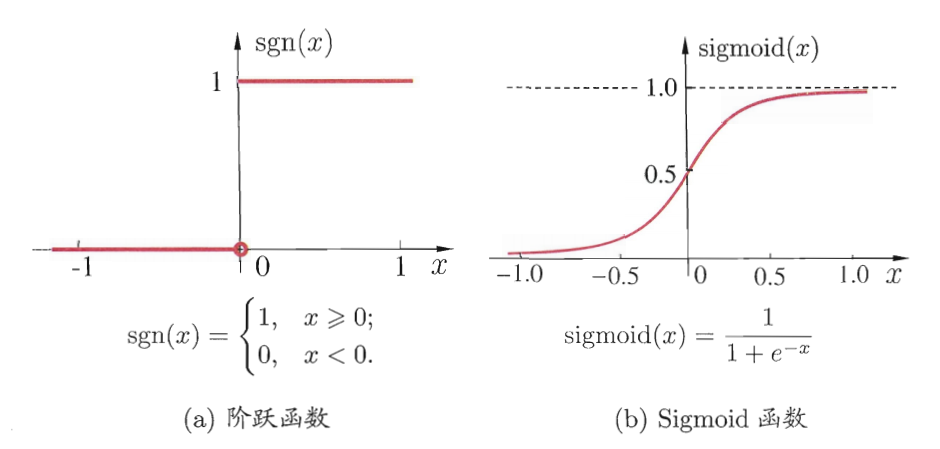
1.4 从单一神经元到神经网络
单一神经元的表达能力有限,仅能实现线性可分问题的分类。但将多个神经元按层次结构连接,即可构成神经网络。例如多层前馈网络由“输入层-隐层-输出层”组成,输入层接收外界数据,隐层与输出层由M-P神经元构成,层间全互连、层内无连接。
从本质上看,神经网络是包含大量参数(连接权重 w w w、阈值 θ \theta θ)的数学模型,其学习过程就是通过训练数据优化这些参数,而激活函数则是实现复杂函数拟合的核心组件。
二、感知机:最简单的神经网络模型
感知机是基于M-P神经元模型构建的两层神经网络,是理解神经网络学习机制的关键起点。西瓜书第五章第二节明确其核心定义:感知机由两层神经元组成,输入层接收外界输入信号后传递给输出层,输出层是M-P神经元(阈值逻辑单元)。
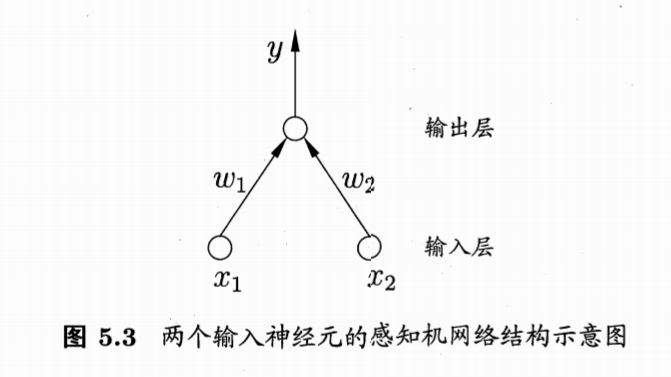
2.1 感知机的核心结构
感知机的结构严格遵循“输入层-输出层”的两层架构,无隐藏层,两层神经元的功能分工明确。
2.1.1 输入层
- 作用:仅负责接收外界输入信号,不进行任何函数处理(无激活函数)。例如处理“与/或/非”逻辑任务时,输入层接收逻辑变量的取值(0或1);处理西瓜分类任务时,输入层接收“色泽、根蒂”等样本特征的属性值。
- 神经元数量:由输入信号的维度(样本的维度)决定。例如二元逻辑任务的输入层包含2个神经元,3维特征样本的输入层包含3个神经元。
2.1.2 输出层
- 核心身份:输出层是感知机的计算核心,本质是一个使用单位阶跃函数作为激活函数的M-P神经元,也称为“阈值逻辑单元”。
- 作用:对输入层传递的信号执行“加权求和-阈值比较-激活输出”的完整处理,输出仅为0(抑制)或1(激活),对应分类任务的结果(如1表示“好瓜”,0表示“坏瓜”)。
2.2 感知机的工作原理
感知机的工作过程完全继承M-P神经元的信号处理逻辑,以二元输入的逻辑运算为例,其工作流程可拆解为四步:
- 信号输入:输入层接收外界信号(如 x 1 = 1 , x 2 = 1 x_1=1, x_2=1 x1=1,x2=1),并直接传递给输出层;
- 加权求和:输出层计算所有输入的加权和,即 w T x = ∑ i = 1 n w i x i w^T x = \sum_{i=1}^n w_i x_i wTx=∑i=1nwixi;
- 阈值比较:将加权和与阈值 θ \theta θ对比,得到净输入 z = w T x − θ z = w^T x - \theta z=wTx−θ;
- 激活输出:通过单位阶跃函数转换净输入,得到最终输出:
y ^ = { 1 z > 0 ( 激活,对应正结果 ) 0 z ≤ 0 ( 抑制,对应负结果 ) \hat{y} = \begin{cases} 1 & z > 0 \quad (\text{激活,对应正结果}) \\ 0 & z \leq 0 \quad (\text{抑制,对应负结果}) \end{cases} y^={10z>0(激活,对应正结果)z≤0(抑制,对应负结果)
2.3 感知机的功能边界
感知机的功能存在明确的局限性,其核心能力与局限均源于“仅有一层功能神经元(输出层)”的结构。
2.3.1 可实现功能:处理线性可分问题
感知机能够实现基础的逻辑运算(与、或、非),证明其可处理线性可分问题(存在线性超平面可划分两类样本)。文档中给出的典型案例如下:
- 与运算:设 w 1 = 1 , w 2 = 1 , θ = 2 w_1=1, w_2=1, \theta=2 w1=1,w2=1,θ=2,仅当 x 1 = x 2 = 1 x_1=x_2=1 x1=x2=1时, z = 1 × 1 + 1 × 1 − 2 = 0 z=1×1+1×1-2=0 z=1×1+1×1−2=0,输出1;其他情况输出0;
- 或运算:设 w 1 = 1 , w 2 = 1 , θ = 0.5 w_1=1, w_2=1, \theta=0.5 w1=1,w2=1,θ=0.5, x 1 x_1 x1或 x 2 x_2 x2为1时, z > 0 z>0 z>0,输出1;
- 非运算:设 w 1 = − 0.6 , w 2 = 0 , θ = − 0.5 w_1=-0.6, w_2=0, \theta=-0.5 w1=−0.6,w2=0,θ=−0.5, x 1 = 1 x_1=1 x1=1时 z < 0 z<0 z<0,输出0; x 1 = 0 x_1=0 x1=0时 z > 0 z>0 z>0,输出1。
2.3.2 核心局限:无法处理非线性可分问题
感知机的致命缺陷是无法解决“异或问题”。异或运算的样本( ( 0 , 0 ) → 0 , ( 0 , 1 ) → 1 , ( 1 , 0 ) → 1 , ( 1 , 1 ) → 0 (0,0)→0, (0,1)→1, (1,0)→1, (1,1)→0 (0,0)→0,(0,1)→1,(1,0)→1,(1,1)→0)在二维空间中无法用一条直线划分,感知机的学习过程会陷入振荡——权重反复调整却无法收敛到稳定解。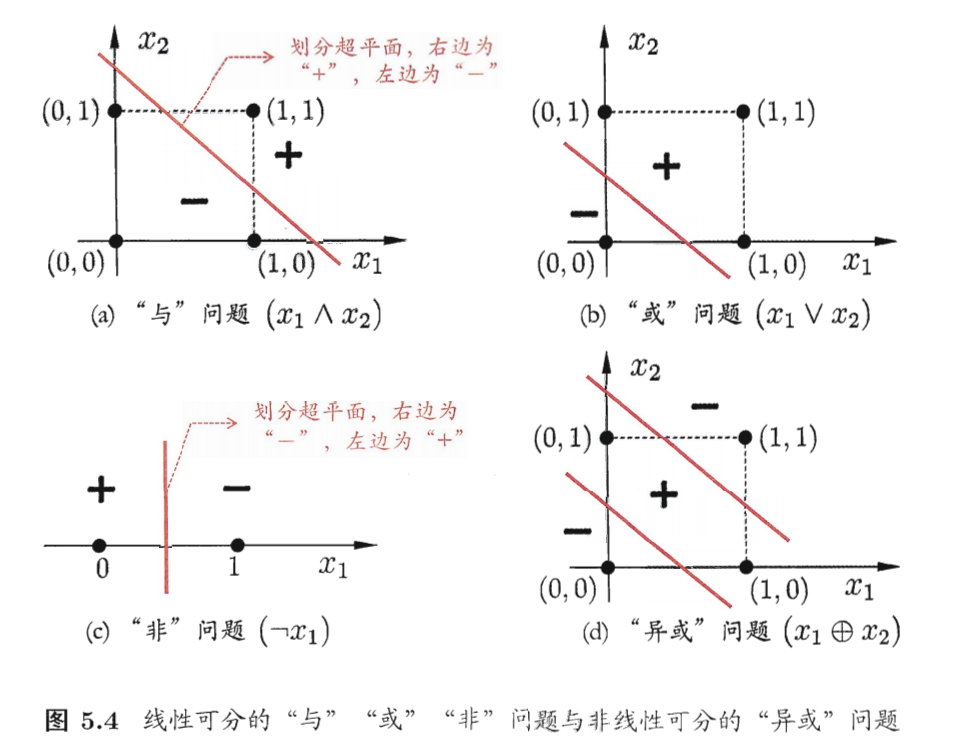
这一局限直接导致20世纪60年代神经网络研究进入“冰河期”,也催生了后续“多层网络”(加入隐藏层)的研究:两层感知机(输入层+隐藏层+输出层)可轻松解决异或问题。
三、感知机的学习策略:损失函数设计与权重更新
感知机的核心价值在于“可学习”——通过训练样本调整连接权重 w i w_i wi和阈值 θ \theta θ,使预测输出 y ^ \hat{y} y^匹配真实标记 y y y( y ∈ { 0 , 1 } y\in\{0,1\} y∈{0,1})。西瓜书从误分类的定义出发,严谨推导了损失函数与权重更新规则,以下内容完全对齐书本推导。
3.1 模型统一:将阈值融入权重(哑结点技巧)
感知机的原始模型包含权重 w i w_i wi和阈值 θ \theta θ两个参数,为简化学习过程,西瓜书提出“哑结点”技巧,将阈值统一为权重的一部分。
3.1.1 原始模型
感知机的原始输出公式为:
y ^ = f ( w T x − θ ) \hat{y} = f\left( w^T x - \theta \right) y^=f(wTx−θ)
对应的超平面方程为:
w T x − θ = 0 w^T x - \theta = 0 wTx−θ=0
3.1.2 统一模型:引入哑结点
- 新增一个虚拟输入 x n + 1 = − 1 x_{n+1} = -1 xn+1=−1(称为哑结点,输入值固定为-1,不随样本变化);
- 新增一个对应权重 w n + 1 = θ w_{n+1} = \theta wn+1=θ(将阈值 θ \theta θ转化为哑结点的连接权重)。
此时,输入向量扩展为 x = ( x 1 , x 2 , . . . , x n , x n + 1 ) x=(x_1,x_2,...,x_n, x_{n+1}) x=(x1,x2,...,xn,xn+1)( n + 1 n+1 n+1维),权重向量扩展为 w = ( w 1 , w 2 , . . . , w n , w n + 1 ) w=(w_1,w_2,...,w_n, w_{n+1}) w=(w1,w2,...,wn,wn+1)( n + 1 n+1 n+1维),感知机模型可统一为:
- 输出公式: y ^ = f ( w T x ) \hat{y} = f\left( w^T x \right) y^=f(wTx)( w T x w^T x wTx为 n + 1 n+1 n+1维向量的内积);
- 超平面方程: w T x = 0 w^T x = 0 wTx=0。
核心优势:权重和阈值的学习被统一为权重 w 1 . . . w n + 1 w_1...w_{n+1} w1...wn+1的学习,无需单独处理阈值,简化了后续的梯度下降推导。
3.2 损失函数设计:基于误分类的量化
学习策略的核心是定义损失函数——损失函数需满足“非负性”(错误越大,损失越大)和“连续性与可导性”(支持梯度下降优化)两个条件。
3.2.1 误分类的量化: ( y ^ − y ) ( w T x − θ ) ≥ 0 (\hat{y} - y)(w^T x - \theta) \ge 0 (y^−y)(wTx−θ)≥0
西瓜书从0/1标记的误分类定义出发,证明了关键结论:
对于感知机的预测输出 y ^ ∈ { 0 , 1 } \hat{y}\in\{0,1\} y^∈{0,1}和真实标记 y ∈ { 0 , 1 } y\in\{0,1\} y∈{0,1},误分类时:
( y ^ − y ) ( w T x − θ ) ≥ 0 (\hat{y} - y)(w^T x - \theta) \ge 0 (y^−y)(wTx−θ)≥0
正确分类时:
( y ^ − y ) ( w T x − θ ) = 0 (\hat{y} - y)(w^T x - \theta) = 0 (y^−y)(wTx−θ)=0
分场景验证(与西瓜书完全一致):
| 真实标记 y y y | 应满足的超平面条件 | 预测输出 y ^ \hat{y} y^ | 实际超平面条件 | y ^ − y \hat{y} - y y^−y | w T x − θ w^T x - \theta wTx−θ 符号 | 乘积 ( y ^ − y ) ( w T x − θ ) (\hat{y} - y)(w^T x - \theta) (y^−y)(wTx−θ) |
|---|---|---|---|---|---|---|
| 1(正类) | w T x − θ > 0 w^T x - \theta > 0 wTx−θ>0 | 0(错误) | w T x − θ ≤ 0 w^T x - \theta \le 0 wTx−θ≤0 | -1 | 负 | ( − 1 ) × ( 负 ) = 正 (-1) \times (\text{负}) = \text{正} (−1)×(负)=正 |
| 0(负类) | w T x − θ ≤ 0 w^T x - \theta \le 0 wTx−θ≤0 | 1(错误) | w T x − θ > 0 w^T x - \theta > 0 wTx−θ>0 | 1 | 正 | 1 × ( 正 ) = 正 1 \times (\text{正}) = \text{正} 1×(正)=正 |
| 正确分类 | 任意 | y ^ = y \hat{y} = y y^=y | 任意 | 0 | 任意 | 0 |
这一结论的核心价值是:用连续的非负乘积量化离散的分类错误,解决了“以错误率为目标函数时,错误率不可导”的问题。
3.2.2 损失函数的定义
基于上述结论,西瓜书直接将所有误分类点的乘积之和作为损失函数:
L ( w , θ ) = ∑ x ∈ M ( y ^ − y ) ( w T x − θ ) L(w,\theta) = \sum_{x \in M} (\hat{y} - y)(w^T x - \theta) L(w,θ)=x∈M∑(y^−y)(wTx−θ)
其中 M M M是误分类点的集合。
损失函数的性质:
- 非负性:误分类时乘积为正,正确分类时为0,损失函数值始终非负;
- 连续性与可导性:函数关于 w w w和 θ \theta θ连续且可导,支持梯度下降优化;
- 物理意义明确:乘积的大小反映了误分类点离超平面的“远近”—— w T x − θ w^T x - \theta wTx−θ的绝对值越大,点离超平面越远,错误越严重,损失也越大。
3.2.3 统一损失函数(结合哑结点)
通过哑结点技巧,阈值 θ \theta θ被统一为权重 w n + 1 w_{n+1} wn+1,超平面方程简化为 w T x = 0 w^T x = 0 wTx=0,损失函数可进一步统一为:
L ( w ) = ∑ x ∈ M ( y ^ − y ) w T x L(w) = \sum_{x \in M} (\hat{y} - y) w^T x L(w)=x∈M∑(y^−y)wTx
其中 x x x为扩展后的 n + 1 n+1 n+1维输入向量。
3.3 学习算法:梯度下降推导权重更新规则
感知机的学习算法是梯度下降法——沿着损失函数的负梯度方向调整参数,使损失最小化。西瓜书基于统一后的损失函数,推导了权重更新的具体规则。
要理解感知机损失函数的梯度推导,我们需要从标量对向量的求导定义、基本运算规则和线性性质入手,一步步拆解核心逻辑,搞懂向量求导与梯度的本质。
核心概念:标量对向量的导数 = 梯度
在机器学习模型(如感知机)中,损失函数通常是标量(单个数值),而模型参数(如权重)通常是向量,这就涉及到「标量对向量的求导」,其结果就是我们常说的梯度。假设我们有两个核心元素:
- 标量函数 f ( w ) f(w) f(w):输出为单个数值,比如感知机的损失函数 L ( w ) L(w) L(w);
- 输入向量 w = [ w 1 , w 2 , … , w d ] T w = [w_1, w_2, \dots, w_d]^T w=[w1,w2,…,wd]T:比如感知机的权重向量,维度为 d d d(包含所有权重及统一后的阈值)。
- 梯度的严格定义:标量函数对向量的每个分量分别求偏导,再将这些偏导数按原向量的维度顺序组成一个新的向量,数学表达式为:
∇ w f ( w ) = [ ∂ f ∂ w 1 , ∂ f ∂ w 2 , … , ∂ f ∂ w d ] T \nabla_w f(w) = \left[ \frac{\partial f}{\partial w_1},\ \frac{\partial f}{\partial w_2},\ \dots,\ \frac{\partial f}{\partial w_d} \right]^T ∇wf(w)=[∂w1∂f, ∂w2∂f, …, ∂wd∂f]T
需要重点记住的是,梯度本身是一个向量,而非标量,其方向是标量函数值上升最快的方向,模长(向量长度)是该方向上的变化率;在感知机中,损失 L ( w ) L(w) L(w) 是标量(所有误分类样本的距离之和),权重 w w w 是向量,因此 ∇ w L ( w ) \nabla_w L(w) ∇wL(w) 就是「标量对向量的导数」,也就是损失函数关于权重向量的梯度;「向量求梯度」本质就是「标量对向量求导」,这两个说法在该场景下是等价的(梯度是标量对向量求导的专属结果名称)。
关键规则:点积的梯度(感知机推导的核心)
感知机损失函数中最核心的运算就是向量点积 w T x w^T x wTx,搞懂这个点积对权重向量 w w w 的梯度,就掌握了感知机梯度推导的关键钥匙。首先做前提设定:
设标量函数 f ( w ) = w T x f(w) = w^T x f(w)=wTx,其中 w = [ w 1 , w 2 , … , w d ] T w = [w_1, w_2, \dots, w_d]^T w=[w1,w2,…,wd]T 是待求导的权重向量(变量), x = [ x 1 , x 2 , … , x d ] T x = [x_1, x_2, \dots, x_d]^T x=[x1,x2,…,xd]T 是固定的输入样本向量(看作常数,感知机中为单个样本的特征及哑结点 1 1 1)。接下来分步推导:
- 展开点积:将向量点积转化为标量求和形式,更易理解偏导计算,公式为:
f ( w ) = w T x = w 1 x 1 + w 2 x 2 + ⋯ + w d x d = ∑ i = 1 d w i x i f(w) = w^T x = w_1 x_1 + w_2 x_2 + \dots + w_d x_d = \sum_{i=1}^d w_i x_i f(w)=wTx=w1x1+w2x2+⋯+wdxd=i=1∑dwixi - 对单个权重分量求偏导:取权重向量的第 i i i 个分量 w i w_i wi,对其求偏导 ∂ f ∂ w i \frac{\partial f}{\partial w_i} ∂wi∂f,求和式中只有 w i x i w_i x_i wixi 这一项包含变量 w i w_i wi,其余项均与 w i w_i wi 无关(导数为 0 0 0),因此计算结果为:
∂ f ∂ w i = x i \frac{\partial f}{\partial w_i} = x_i ∂wi∂f=xi - 组装梯度向量:将所有单个分量的偏导数,按权重向量的维度顺序组成新向量,即为点积函数的梯度,公式为:
∇ w f ( w ) = [ x 1 , x 2 , … , x d ] T = x \nabla_w f(w) = [x_1,\ x_2,\ \dots,\ x_d]^T = x ∇wf(w)=[x1, x2, …, xd]T=x
这里有一个核心结论:
向量点积 w T x w^T x wTx 对权重向量 w w w 的梯度,等于输入向量 x x x 本身,即 ∇ w ( w T x ) = x \nabla_w (w^T x) = x ∇w(wTx)=x,这是感知机、线性回归等线性模型梯度推导的核心公式,直接决定了后续损失函数的梯度结果。
感知机损失函数的梯度推导(完整步骤)
有了核心概念和点积梯度规则,我们可以完整推导感知机损失函数的梯度,对应实际模型的应用场景。首先回顾感知机统一损失函数:感知机的损失函数定义为误分类样本到超平面的距离之和,经过哑结点统一阈值后,损失函数公式为:
L ( w ) = ∑ x ∈ M ( y ^ − y ) w T x L(w) = \sum_{x \in M} (\hat{y} - y) w^T x L(w)=x∈M∑(y^−y)wTx
其中各参数说明: M M M 是误分类样本集合(仅分类错误的样本计入损失,提高学习效率); y ^ \hat{y} y^ 是感知机预测标签(取值 + 1 +1 +1 或 − 1 -1 −1); y y y 是样本真实标签(取值 + 1 +1 +1 或 − 1 -1 −1); ( y ^ − y ) (\hat{y} - y) (y^−y) 对固定样本而言,是已知常数(预测值和真实值均确定)。接下来分两步进行梯度推导:第一步,单个误分类样本的损失项梯度,取集合 M M M 中的一个单个误分类样本 x x x,对应的单个损失项为:
L single ( w ) = ( y ^ − y ) ⋅ w T x L_{\text{single}}(w) = (\hat{y} - y) \cdot w^T x Lsingle(w)=(y^−y)⋅wTx
根据导数的线性性质(常数倍数性质):若 f ( w ) = c ⋅ g ( w ) f(w) = c \cdot g(w) f(w)=c⋅g(w)( c c c 为常数),则 ∇ w f ( w ) = c ⋅ ∇ w g ( w ) \nabla_w f(w) = c \cdot \nabla_w g(w) ∇wf(w)=c⋅∇wg(w),结合之前的核心结论 ∇ w ( w T x ) = x \nabla_w (w^T x) = x ∇w(wTx)=x,可得单个样本损失项的梯度:
∇ w L single ( w ) = ( y ^ − y ) ⋅ ∇ w ( w T x ) = ( y ^ − y ) ⋅ x \nabla_w L_{\text{single}}(w) = (\hat{y} - y) \cdot \nabla_w (w^T x) = (\hat{y} - y) \cdot x ∇wLsingle(w)=(y^−y)⋅∇w(wTx)=(y^−y)⋅x
第二步,所有误分类样本的损失函数梯度,感知机的总损失是所有误分类样本损失项的求和,根据导数的线性性质(加法性质):若 f ( w ) = ∑ k g k ( w ) f(w) = \sum_{k} g_k(w) f(w)=∑kgk(w),则 ∇ w f ( w ) = ∑ k ∇ w g k ( w ) \nabla_w f(w) = \sum_{k} \nabla_w g_k(w) ∇wf(w)=∑k∇wgk(w)(和的导数 = 导数的和),将单个样本的梯度结果代入求和式,可得总损失函数的梯度(核心结果):
∇ w L ( w ) = ∑ x ∈ M ∇ w L single ( w ) = ∑ x ∈ M ( y ^ − y ) x \nabla_w L(w) = \sum_{x \in M} \nabla_w L_{\text{single}}(w) = \sum_{x \in M} (\hat{y} - y) x ∇wL(w)=x∈M∑∇wLsingle(w)=x∈M∑(y^−y)x
至此,我们就完成了感知机损失函数关于权重向量 w w w 的梯度推导,这也是感知机权重更新规则的核心依据。
单个权重的偏导数(梯度的分量本质)
很多同学会疑惑「向量梯度」和「单个权重偏导数」的关系,其实梯度向量的每个分量,就是标量函数对对应单个向量分量的偏导数。对于感知机损失函数 L ( w ) L(w) L(w),其梯度 ∇ w L ( w ) \nabla_w L(w) ∇wL(w) 的第 i i i 个分量,就是损失函数对单个权重 w i w_i wi 的偏导数,数学对应关系为:
∂ L ( w ) ∂ w i = 梯度 ∇ w L ( w ) 的第 i 个分量 = ∑ x ∈ M ( y ^ − y ) x i \frac{\partial L(w)}{\partial w_i} = \text{梯度}\nabla_w L(w)\text{的第}i\text{个分量} = \sum_{x \in M} (\hat{y} - y) x_i ∂wi∂L(w)=梯度∇wL(w)的第i个分量=x∈M∑(y^−y)xi
其中 x i x_i xi 是输入向量 x x x 的第 i i i 个分量(对应样本的第 i i i 个特征,或哑结点的 1 1 1),该偏导数反映了:损失函数 L ( w ) L(w) L(w) 随单个权重 w i w_i wi 变化的速率和方向,正为上升、负为下降,而感知机的权重更新,本质就是对每个 w i w_i wi 沿偏导数的负方向调整(梯度下降的分量体现)。
向量求导的核心性质(感知机推导的基础)
感知机的梯度推导之所以简洁,核心依赖向量求导的两个线性性质,这也是所有线性模型(线性回归、SVM 等)梯度推导的通用基础。
性质1:常数倍数性质,若 f ( w ) = c ⋅ g ( w ) f(w) = c \cdot g(w) f(w)=c⋅g(w),其中 c c c 为与向量 w w w 无关的常数, g ( w ) g(w) g(w) 为标量对向量的函数,则:
∇ w f ( w ) = c ⋅ ∇ w g ( w ) \nabla_w f(w) = c \cdot \nabla_w g(w) ∇wf(w)=c⋅∇wg(w)
在感知机中的应用是: ( y ^ − y ) (\hat{y} - y) (y^−y) 作为常数,提取到梯度运算外部。
性质2:加法(求和)性质,若 f ( w ) = g ( w ) + h ( w ) f(w) = g(w) + h(w) f(w)=g(w)+h(w),或 f ( w ) = ∑ k = 1 n g k ( w ) f(w) = \sum_{k=1}^n g_k(w) f(w)=∑k=1ngk(w),则:
∇ w f ( w ) = ∇ w g ( w ) + ∇ w h ( w ) (二元和) \nabla_w f(w) = \nabla_w g(w) + \nabla_w h(w) \quad \text{(二元和)} ∇wf(w)=∇wg(w)+∇wh(w)(二元和)
∇ w f ( w ) = ∑ k = 1 n ∇ w g k ( w ) (多元和) \nabla_w f(w) = \sum_{k=1}^n \nabla_w g_k(w) \quad \text{(多元和)} ∇wf(w)=k=1∑n∇wgk(w)(多元和)
在感知机中的应用是:将所有误分类样本的损失项梯度求和,得到总损失的梯度。
感知机梯度的实际意义(延伸总结)
理解向量求导和梯度的原理,最终是为了支撑模型的训练,感知机梯度的核心意义有3点:
- 梯度方向是损失函数上升最快的方向,因此梯度下降算法沿负梯度方向更新权重,实现损失最小化;
- 权重更新规则 w ← w − η ∇ w L ( w ) w \leftarrow w - \eta \nabla_w L(w) w←w−η∇wL(w) 中, η \eta η 为学习率(步长),控制每次更新的幅度,避免震荡或收敛过慢;
- 梯度仅依赖误分类样本集合 M M M,无需遍历所有样本,保证了感知机学习的效率和针对性。
3.3.1 梯度计算
对统一后的损失函数 L ( w ) L(w) L(w)关于权重 w i w_i wi求偏导:
∇ w L ( w ) = ∑ x ∈ M ( y ^ − y ) x \nabla_w L(w) = \sum_{x \in M} (\hat{y} - y) x ∇wL(w)=x∈M∑(y^−y)x
展开到单个权重 w i w_i wi,偏导数为:
∂ L ( w ) ∂ w i = ∑ x ∈ M ( y ^ − y ) x i \frac{\partial L(w)}{\partial w_i} = \sum_{x \in M} (\hat{y} - y) x_i ∂wi∂L(w)=x∈M∑(y^−y)xi
3.3.2 权重更新规则
梯度下降的参数更新规则为:
w i ← w i − η ⋅ ∂ L ( w ) ∂ w i w_i \leftarrow w_i - \eta \cdot \frac{\partial L(w)}{\partial w_i} wi←wi−η⋅∂wi∂L(w)
代入偏导数结果,得:
w i ← w i − η ∑ x ∈ M ( y ^ − y ) x i w_i \leftarrow w_i - \eta \sum_{x \in M} (\hat{y} - y) x_i wi←wi−ηx∈M∑(y^−y)xi
在在线学习(单样本更新)场景下,每次仅处理一个训练样本,若当前样本误分类,则权重更新规则简化为西瓜书的核心公式:
w i ← w i + η ( y − y ^ ) x i (5.2) w_i \leftarrow w_i + \eta (y - \hat{y}) x_i \tag{5.2} wi←wi+η(y−y^)xi(5.2)
(注: y − y ^ = − ( y ^ − y ) y - \hat{y} = -(\hat{y} - y) y−y^=−(y^−y),因此该式与梯度下降规则完全等价)
3.3.3 分场景验证更新方向
感知机的核心规则是仅误分类时更新权重,基于0/1标记分场景验证:
-
场景1:分类正确( y ^ = y \hat{y}=y y^=y)
此时 y − y ^ = 0 y - \hat{y}=0 y−y^=0,权重更新量 Δ w i = 0 \Delta w_i=0 Δwi=0,权重保持不变,符合“分类正确则感知机不变化”的规则。 -
场景2:误分类( y = 1 , y ^ = 0 y=1,\hat{y}=0 y=1,y^=0)
此时 y − y ^ = 1 y - \hat{y}=1 y−y^=1,更新量 Δ w i = η × 1 × x i = η x i \Delta w_i=\eta \times 1 \times x_i=\eta x_i Δwi=η×1×xi=ηxi。
若 x i > 0 x_i>0 xi>0,则权重增大,使得 w T x − θ w^T x - \theta wTx−θ的值增大,向超平面正侧( y = 1 y=1 y=1对应区域)靠近,修正误分类。 -
场景3:误分类( y = 0 , y ^ = 1 y=0,\hat{y}=1 y=0,y^=1)
此时 y − y ^ = − 1 y - \hat{y}=-1 y−y^=−1,更新量 Δ w i = η × ( − 1 ) × x i = − η x i \Delta w_i=\eta \times (-1) \times x_i=-\eta x_i Δwi=η×(−1)×xi=−ηxi。
若 x i > 0 x_i>0 xi>0,则权重减小,使得 w T x − θ w^T x - \theta wTx−θ的值减小,向超平面负侧( y = 0 y=0 y=0对应区域)靠近,修正误分类。
3.3.4 统一更新阈值(结合哑结点)
根据哑结点技巧,阈值 θ = w n + 1 \theta=w_{n+1} θ=wn+1,哑结点输入 x n + 1 = − 1 x_{n+1}=-1 xn+1=−1,因此阈值的更新规则可统一到权重更新中:
Δ w n + 1 = η ( y − y ^ ) x n + 1 = η ( y − y ^ ) × ( − 1 ) \Delta w_{n+1} = \eta (y - \hat{y}) x_{n+1} = \eta (y - \hat{y}) \times (-1) Δwn+1=η(y−y^)xn+1=η(y−y^)×(−1)
这验证了西瓜书的结论:权重和阈值的学习可统一为权重的学习。
3.4 感知机的完整学习流程
感知机的学习是一个迭代优化过程,完整流程如下:
- 初始化参数:随机初始化权重向量 w w w和阈值 θ \theta θ(或统一初始化扩展权重 w 1 . . . w n + 1 w_1...w_{n+1} w1...wn+1);
- 遍历训练样本:对每个训练样例 ( x , y ) (x,y) (x,y):
a. 计算预测输出: y ^ = f ( w T x − θ ) \hat{y} = f\left( w^T x - \theta \right) y^=f(wTx−θ);
b. 若 y ^ = y \hat{y} = y y^=y(预测正确):权重和阈值不更新;
c. 若 y ^ ≠ y \hat{y} ≠ y y^=y(预测错误):按规则更新权重和阈值:
w i ← w i + η ( y − y ^ ) x i w_i \leftarrow w_i + \eta (y - \hat{y}) x_i wi←wi+η(y−y^)xi - 终止条件:遍历所有训练样本后,若没有误分类点,则停止学习;否则重复步骤2。
3.5 实例验证:与运算的权重更新过程
以二元与运算为例,演示感知机的学习过程,直观理解权重更新的效果。
3.5.1 初始化参数
- 输入维度 n = 2 n=2 n=2,引入哑结点 x 3 = − 1 x_3=-1 x3=−1,权重初始化为 w 1 = 0 , w 2 = 0 , w 3 = 0 w_1=0, w_2=0, w_3=0 w1=0,w2=0,w3=0(即初始阈值 θ = 0 \theta=0 θ=0);
- 学习率 η = 0.5 \eta=0.5 η=0.5;
- 训练样本: ( x 1 = 0 , x 2 = 0 , y = 0 ) (x_1=0,x_2=0,y=0) (x1=0,x2=0,y=0)、 ( x 1 = 0 , x 2 = 1 , y = 0 ) (x_1=0,x_2=1,y=0) (x1=0,x2=1,y=0)、 ( x 1 = 1 , x 2 = 0 , y = 0 ) (x_1=1,x_2=0,y=0) (x1=1,x2=0,y=0)、 ( x 1 = 1 , x 2 = 1 , y = 1 ) (x_1=1,x_2=1,y=1) (x1=1,x2=1,y=1)( y y y用0/1标记)。
3.5.2 第一次遍历样本
- 样本1: ( 0 , 0 , − 1 , 0 ) (0,0,-1,0) (0,0,−1,0),预测 y ^ = f ( 0 + 0 − 0 ) = 0 \hat{y}=f(0+0-0)=0 y^=f(0+0−0)=0,正确,不更新;
- 样本2: ( 0 , 1 , − 1 , 0 ) (0,1,-1,0) (0,1,−1,0),预测 y ^ = f ( 0 + 0 − 0 ) = 0 \hat{y}=f(0+0-0)=0 y^=f(0+0−0)=0,正确,不更新;
- 样本3: ( 1 , 0 , − 1 , 0 ) (1,0,-1,0) (1,0,−1,0),预测 y ^ = f ( 0 + 0 − 0 ) = 0 \hat{y}=f(0+0-0)=0 y^=f(0+0−0)=0,正确,不更新;
- 样本4: ( 1 , 1 , − 1 , 1 ) (1,1,-1,1) (1,1,−1,1),预测 y ^ = f ( 0 + 0 − 0 ) = 0 \hat{y}=f(0+0-0)=0 y^=f(0+0−0)=0,错误,触发更新:
w 1 = 0 + 0.5 × ( 1 − 0 ) × 1 = 0.5 w_1 = 0 + 0.5×(1-0)×1 = 0.5 w1=0+0.5×(1−0)×1=0.5
w 2 = 0 + 0.5 × ( 1 − 0 ) × 1 = 0.5 w_2 = 0 + 0.5×(1-0)×1 = 0.5 w2=0+0.5×(1−0)×1=0.5
w 3 = 0 + 0.5 × ( 1 − 0 ) × ( − 1 ) = − 0.5 w_3 = 0 + 0.5×(1-0)×(-1) = -0.5 w3=0+0.5×(1−0)×(−1)=−0.5
3.5.3 第二次遍历样本
更新后的权重为 w 1 = 0.5 , w 2 = 0.5 , w 3 = − 0.5 w_1=0.5,w_2=0.5,w_3=-0.5 w1=0.5,w2=0.5,w3=−0.5,超平面方程为 0.5 x 1 + 0.5 x 2 − 0.5 = 0 0.5x_1+0.5x_2-0.5=0 0.5x1+0.5x2−0.5=0(即 x 1 + x 2 = 1 x_1+x_2=1 x1+x2=1)。
- 样本1: 0 + 0 − 0.5 = − 0.5 ≤ 0 0+0-0.5=-0.5 ≤0 0+0−0.5=−0.5≤0, y ^ = 0 \hat{y}=0 y^=0,正确;
- 样本2: 0 + 0.5 − 0.5 = 0 ≤ 0 0+0.5-0.5=0 ≤0 0+0.5−0.5=0≤0, y ^ = 0 \hat{y}=0 y^=0,正确;
- 样本3: 0.5 + 0 − 0.5 = 0 ≤ 0 0.5+0-0.5=0 ≤0 0.5+0−0.5=0≤0, y ^ = 0 \hat{y}=0 y^=0,正确;
- 样本4: 0.5 + 0.5 − 0.5 = 0.5 > 0 0.5+0.5-0.5=0.5 >0 0.5+0.5−0.5=0.5>0, y ^ = 1 \hat{y}=1 y^=1,正确。
所有样本分类正确,学习停止。最终超平面 x 1 + x 2 = 1 x_1+x_2=1 x1+x2=1成功划分与运算样本,验证了学习算法的有效性。
四、反向传播(BP)算法:多层前馈网络的训练核心
感知机仅能处理线性可分问题,而多层前馈网络通过引入隐藏层突破了这一局限,反向传播(Back Propagation, BP)算法正是训练这类网络的核心方法。本小节严格遵循选中内容的符号与逻辑,从算法目标出发,按“前向传播→反向传播→参数更新”的完整流程推导,所有公式与步骤均与选中内容完全对齐。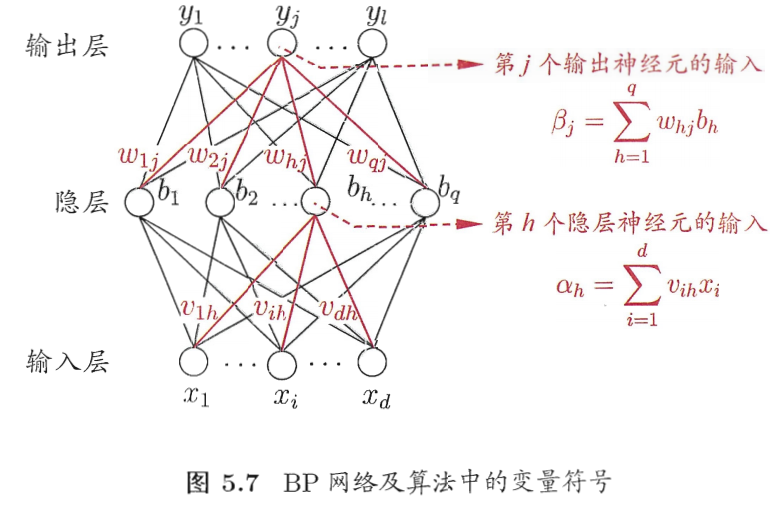
4.1 BP算法的核心目标
给定训练集 D = { ( x 1 , y 1 ) , . . . , ( x m , y m ) } D=\{(x_1,y_1),...,(x_m,y_m)\} D={(x1,y1),...,(xm,ym)},其中输入 x i ∈ R d x_i \in \mathbb{R}^d xi∈Rd( d d d维特征向量)、输出 y i ∈ R l y_i \in \mathbb{R}^l yi∈Rl( l l l维实值标记,对应多输出回归或多分类概率)。
BP算法的目标是:调整网络中的连接权(输入→隐层的 v i h v_{ih} vih、隐层→输出的 w h j w_{hj} whj)和阈值(隐层神经元的 γ h \gamma_h γh、输出层神经元的 θ j \theta_j θj),最小化网络预测输出 y ^ \hat{y} y^ 与真实标记 y y y 的均方误差。
对单个训练样本 ( x k , y k ) (x_k,y_k) (xk,yk),误差定义为:
E k = 1 2 ∑ j = 1 l ( y k , j − y ^ k , j ) 2 E_k = \frac{1}{2} \sum_{j=1}^l \left( y_{k,j} - \hat{y}_{k,j} \right)^2 Ek=21j=1∑l(yk,j−y^k,j)2
其中 y k , j y_{k,j} yk,j 是样本 k k k 的第 j j j 个真实输出, y ^ k , j \hat{y}_{k,j} y^k,j 是网络对第 j j j 个输出神经元的预测值。
4.2 第一步:前向传播——计算网络输出
前向传播是“输入层→隐层→输出层”的信号计算过程,核心是利用选中内容定义的输入/输出符号,并通过Sigmoid激活函数实现非线性转换(Sigmoid的可导性是BP反向求导的关键)。
4.2.1 隐层神经元的输入与输出
设网络包含 q q q 个隐层神经元,对输入样本 x k = ( x k , 1 , x k , 2 , . . . , x k , d ) x_k=(x_{k,1},x_{k,2},...,x_{k,d}) xk=(xk,1,xk,2,...,xk,d):
- 隐层输入:第 h h h 个隐层神经元的输入为输入层的加权和:
α h = ∑ i = 1 d v i h x k , i \alpha_h = \sum_{i=1}^d v_{ih} x_{k,i} αh=i=1∑dvihxk,i - 隐层净输入:输入减去自身阈值 γ h \gamma_h γh(激活门槛):
α h − γ h \alpha_h - \gamma_h αh−γh - 隐层输出:通过Sigmoid激活函数处理净输入:
b h = f ( α h − γ h ) = 1 1 + e − ( α h − γ h ) b_h = f(\alpha_h - \gamma_h) = \frac{1}{1 + e^{-(\alpha_h - \gamma_h)}} bh=f(αh−γh)=1+e−(αh−γh)1
其中 f ( z ) f(z) f(z) 为Sigmoid函数, b h b_h bh 将作为输出层的输入。
4.2.2 输出层神经元的输入与输出
设网络包含 l l l 个输出层神经元:
- 输出层输入:第 j j j 个输出层神经元的输入为隐层的加权和:
β j = ∑ h = 1 q w h j b h \beta_j = \sum_{h=1}^q w_{hj} b_h βj=h=1∑qwhjbh - 输出层净输入:输入减去自身阈值 θ j \theta_j θj:
β j − θ j \beta_j - \theta_j βj−θj - 输出层预测:通过Sigmoid激活函数得到最终预测:
y ^ k , j = f ( β j − θ j ) = 1 1 + e − ( β j − θ j ) \hat{y}_{k,j} = f(\beta_j - \theta_j) = \frac{1}{1 + e^{-(\beta_j - \theta_j)}} y^k,j=f(βj−θj)=1+e−(βj−θj)1
前向传播完成后,得到样本 k k k 的预测输出 y ^ k \hat{y}_k y^k,接下来通过反向传播计算误差梯度,指导参数更新。
4.3 第二步:反向传播——计算误差梯度(核心是链式法则)
反向传播的本质是误差逆传:从输出层(有真实标记,误差可直接计算)向隐层(无直接标记,误差由输出层传递而来)反向计算每个参数对误差 E k E_k Ek 的梯度,为参数更新提供依据。整个过程的核心是链式法则的层层拆解,而Sigmoid函数的导数性质是简化计算的关键。
4.3.1 关键预备:Sigmoid函数的导数性质(BP简化核心)
反向传播需要对激活函数求导,Sigmoid函数 f ( z ) = 1 1 + e − z f(z)=\frac{1}{1+e^{-z}} f(z)=1+e−z1 的导数有一个极其重要的简化性质,这是BP算法能高效计算的前提,推导结果如下(核心公式加粗):
f ′ ( z ) = f ( z ) ⋅ ( 1 − f ( z ) ) f'(z)=f(z)\cdot(1-f(z)) f′(z)=f(z)⋅(1−f(z))
完整推导过程验证(辅助理解,无需死记):
f ′ ( z ) = d d z ( 1 1 + e − z ) = e − z ( 1 + e − z ) 2 f'(z)=\frac{d}{dz}\left(\frac{1}{1+e^{-z}}\right)=\frac{e^{-z}}{(1+e^{-z})^2} f′(z)=dzd(1+e−z1)=(1+e−z)2e−z
由于 f ( z ) = 1 1 + e − z f(z)=\frac{1}{1+e^{-z}} f(z)=1+e−z1, 1 − f ( z ) = e − z 1 + e − z 1-f(z)=\frac{e^{-z}}{1+e^{-z}} 1−f(z)=1+e−ze−z,因此可化简为上述加粗核心公式。
这个性质的意义在于:求导结果可以直接用Sigmoid的输出值表示,无需额外计算指数,大幅降低了梯度计算的复杂度,后续所有梯度推导都会直接套用该结论。
4.3.2 输出层的误差梯度(针对 w h j w_{hj} whj 和 θ j \theta_j θj)
输出层是反向传播的起点,因为输出层神经元有真实标记 y j y_j yj,可以直接计算预测值 y ^ j \hat{y}_j y^j 与真实值的误差,进而求出损失函数对输出层参数(连接权 w h j w_{hj} whj、阈值 θ j \theta_j θj)的梯度。
4.3.2.1 定义输出层误差项 g j g_j gj
误差项的本质是损失函数 E k E_k Ek 对输出层神经元净输入的偏导的相反数,净输入指激活函数的输入(即 β j − θ j \beta_j - \theta_j βj−θj),其定义式(加粗核心公式):
g j = − ∂ E k ∂ ( β j − θ j ) g_j = -\frac{\partial E_k}{\partial (\beta_j - \theta_j)} gj=−∂(βj−θj)∂Ek
定义该误差项的核心目的是:通过链式法则串联“损失→预测值→净输入”的导数链条,简化后续参数梯度的计算。
接下来展开链式法则拆解,损失 E k E_k Ek 对净输入 β j − θ j \beta_j - \theta_j βj−θj 的偏导,等于 E k E_k Ek 对 y ^ j \hat{y}_j y^j 的偏导乘以 y ^ j \hat{y}_j y^j 对 β j − θ j \beta_j - \theta_j βj−θj 的偏导,公式:
∂ E k ∂ ( β j − θ j ) = ∂ E k ∂ y ^ j ⋅ ∂ y ^ j ∂ ( β j − θ j ) \frac{\partial E_k}{\partial (\beta_j - \theta_j)}=\frac{\partial E_k}{\partial \hat{y}_j} \cdot \frac{\partial \hat{y}_j}{\partial (\beta_j - \theta_j)} ∂(βj−θj)∂Ek=∂y^j∂Ek⋅∂(βj−θj)∂y^j
分别计算等式右侧两个偏导项:
- 计算 ∂ E k ∂ y ^ j \frac{\partial E_k}{\partial \hat{y}_j} ∂y^j∂Ek:单个样本的损失函数是均方误差 E k = 1 2 ∑ j = 1 l ( y k , j − y ^ k , j ) 2 E_k = \frac{1}{2} \sum_{j=1}^l \left( y_{k,j} - \hat{y}_{k,j} \right)^2 Ek=21∑j=1l(yk,j−y^k,j)2,对 y ^ j \hat{y}_j y^j 求偏导时仅第 j j j 项有贡献,结果:
∂ E k ∂ y ^ j = − ( y j − y ^ j ) \frac{\partial E_k}{\partial \hat{y}_j} = - (y_j - \hat{y}_j) ∂y^j∂Ek=−(yj−y^j) - 计算 ∂ y ^ j ∂ ( β j − θ j ) \frac{\partial \hat{y}_j}{\partial (\beta_j - \theta_j)} ∂(βj−θj)∂y^j: y ^ j = f ( β j − θ j ) \hat{y}_j=f(\beta_j - \theta_j) y^j=f(βj−θj),套用Sigmoid导数性质,结果:
∂ y ^ j ∂ ( β j − θ j ) = y ^ j ( 1 − y ^ j ) \frac{\partial \hat{y}_j}{\partial (\beta_j - \theta_j)} = \hat{y}_j(1 - \hat{y}_j) ∂(βj−θj)∂y^j=y^j(1−y^j)
将两个结果代入链式法则公式,结合误差项 g j g_j gj 的定义化简,最终得到输出层误差项(加粗核心公式):
g j = ( y j − y ^ j ) ⋅ y ^ j ( 1 − y ^ j ) g_j = (y_j - \hat{y}_j) \cdot \hat{y}_j (1 - \hat{y}_j) gj=(yj−y^j)⋅y^j(1−y^j)
该误差项的物理意义是:输出层神经元的净输入变化对损失函数的影响程度。
4.3.2.2 深入理解:误差项的本质(通俗拆解)
要理解“误差项的本质是损失函数 E k E_k Ek 对输出层神经元净输入的偏导的相反数”,核心是拆解“误差项定义”与“净输入、损失函数的关联”,用通俗逻辑简化如下:
(1)先明确两个基础概念
- 净输入:对输出层神经元而言,“净输入”是权重与前层输出的加权和(含偏置),记为 z k z_k zk(比如 z k = ∑ w i k x i + b z_k = \sum w_{ik}x_i + b zk=∑wikxi+b),它是神经元激活前的“原始信号”。
- 损失函数 E k E_k Ek:衡量单个样本(或批次)的预测误差(如均方误差 E k = 1 2 ( y k − y ^ k ) 2 E_k = \frac{1}{2}(y_k - \hat{y}_k)^2 Ek=21(yk−y^k)2,交叉熵损失等),其中 y k y_k yk 是真实标签, y ^ k \hat{y}_k y^k 是输出层神经元的激活输出(而 y ^ k \hat{y}_k y^k 由净输入 z k z_k zk 通过激活函数得到,即 y ^ k = σ ( z k ) \hat{y}_k = \sigma(z_k) y^k=σ(zk), σ \sigma σ 如Sigmoid、ReLU)。
(2)误差项的“本质诉求”
误差项(常见于反向传播,如BP算法中的 δ k \delta_k δk)的核心作用是:量化“净输入 z k z_k zk 的变化对损失 E k E_k Ek 的影响”——因为反向传播的本质是“从损失反向求参数(权重、偏置)的梯度”,而参数的梯度需先通过“净输入的梯度”传递(链式法则)。
(3)为什么是“偏导的相反数”?
根据链式法则,损失 E k E_k Ek 对净输入 z k z_k zk 的偏导为:
∂ E k ∂ z k = ∂ E k ∂ y ^ k ⋅ ∂ y ^ k ∂ z k \frac{\partial E_k}{\partial z_k} = \frac{\partial E_k}{\partial \hat{y}_k} \cdot \frac{\partial \hat{y}_k}{\partial z_k} ∂zk∂Ek=∂y^k∂Ek⋅∂zk∂y^k
(先求损失对输出 y ^ k \hat{y}_k y^k 的偏导,再乘输出对净输入 z k z_k zk 的偏导——激活函数的导数)。
而误差项 δ k \delta_k δk 的定义通常设为:
δ k = − ∂ E k ∂ z k \delta_k = -\frac{\partial E_k}{\partial z_k} δk=−∂zk∂Ek
取“相反数”的核心原因是:梯度是函数增大最快的方向,所以梯度下降的“负梯度方向”是损失减小的方向——后续求参数(如权重 w i k w_{ik} wik)的梯度时, ∂ E k ∂ w i k = δ k ⋅ x i \frac{\partial E_k}{\partial w_{ik}} = \delta_k \cdot x_i ∂wik∂Ek=δk⋅xi(或类似形式),直接用 δ k \delta_k δk 可快速得到“参数更新的方向”,避免每次计算都额外加负号,本质是为了简化反向传播的计算逻辑。
(4)总结
误差项的本质是:用“损失对净输入的偏导的相反数”,直接量化“净输入对损失的影响方向”,为反向传播中参数梯度的计算提供“中间桥梁”——它不是凭空定义,而是为了契合梯度下降的优化逻辑,让误差从输出层反向传递到前层时更简洁高效。
4.3.2.3 计算输出层连接权 w h j w_{hj} whj 的梯度
输出层连接权 w h j w_{hj} whj 是隐层 h h h 到输出层 j j j 的连接权,其梯度为损失函数 E k E_k Ek 对 w h j w_{hj} whj 的偏导 ∂ E k ∂ w h j \frac{\partial E_k}{\partial w_{hj}} ∂whj∂Ek,通过链式法则拆解为(加粗核心公式):
∂ E k ∂ w h j = ∂ E k ∂ β j ⋅ ∂ β j ∂ w h j \frac{\partial E_k}{\partial w_{hj}} = \frac{\partial E_k}{\partial \beta_j} \cdot \frac{\partial \beta_j}{\partial w_{hj}} ∂whj∂Ek=∂βj∂Ek⋅∂whj∂βj
分别计算两个偏导项:
- 计算 ∂ β j ∂ w h j \frac{\partial \beta_j}{\partial w_{hj}} ∂whj∂βj: β j = ∑ h = 1 q w h j b h \beta_j = \sum_{h=1}^q w_{hj}b_h βj=∑h=1qwhjbh,对 w h j w_{hj} whj 求偏导结果为对应隐层输出 b h b_h bh,即:
∂ β j ∂ w h j = b h \frac{\partial \beta_j}{\partial w_{hj}} = b_h ∂whj∂βj=bh - 计算 ∂ E k ∂ β j \frac{\partial E_k}{\partial \beta_j} ∂βj∂Ek: β j \beta_j βj 是净输入 β j − θ j \beta_j - \theta_j βj−θj 的一部分,因此 ∂ E k ∂ β j = − g j \frac{\partial E_k}{\partial \beta_j} = -g_j ∂βj∂Ek=−gj(根据输出层误差项 g j g_j gj 定义)。
代入化简后得到输出层连接权 w h j w_{hj} whj 的梯度(加粗核心公式):
∂ E k ∂ w h j = − g j ⋅ b h \frac{\partial E_k}{\partial w_{hj}} = -g_j \cdot b_h ∂whj∂Ek=−gj⋅bh
4.3.2.4 计算输出层阈值 θ j \theta_j θj 的梯度
输出层阈值 θ j \theta_j θj 的梯度为损失函数 E k E_k Ek 对 θ j \theta_j θj 的偏导 ∂ E k ∂ θ j \frac{\partial E_k}{\partial \theta_j} ∂θj∂Ek,通过链式法则拆解为(加粗核心公式):
∂ E k ∂ θ j = ∂ E k ∂ ( β j − θ j ) ⋅ ∂ ( β j − θ j ) ∂ θ j \frac{\partial E_k}{\partial \theta_j} = \frac{\partial E_k}{\partial (\beta_j - \theta_j)} \cdot \frac{\partial (\beta_j - \theta_j)}{\partial \theta_j} ∂θj∂Ek=∂(βj−θj)∂Ek⋅∂θj∂(βj−θj)
分别计算两个偏导项:
- ∂ E k ∂ ( β j − θ j ) = − g j \frac{\partial E_k}{\partial (\beta_j - \theta_j)} = -g_j ∂(βj−θj)∂Ek=−gj(输出层误差项定义);
- ∂ ( β j − θ j ) ∂ θ j = − 1 \frac{\partial (\beta_j - \theta_j)}{\partial \theta_j} = -1 ∂θj∂(βj−θj)=−1( θ j \theta_j θj 前为负号,求导结果为-1)。
代入化简后得到输出层阈值 θ j \theta_j θj 的梯度(加粗核心公式):
∂ E k ∂ θ j = g j \frac{\partial E_k}{\partial \theta_j} = g_j ∂θj∂Ek=gj
4.3.3 隐层的误差梯度(针对 v i h v_{ih} vih 和 γ h \gamma_h γh)
隐层没有直接的真实标记,误差需通过隐层与输出层的连接权 w h j w_{hj} whj 反向传递,步骤与输出层一致:定义隐层误差项 → 计算输入-隐层连接权梯度 → 计算隐层阈值梯度。
4.3.3.1 定义隐层误差项 e h e_h eh
隐层误差项的定义逻辑与输出层一致,是损失函数 E k E_k Ek 对隐层神经元净输入的偏导的相反数,隐层净输入为 α h − γ h \alpha_h - \gamma_h αh−γh,定义式(加粗核心公式):
e h = − ∂ E k ∂ ( α h − γ h ) e_h = -\frac{\partial E_k}{\partial (\alpha_h - \gamma_h)} eh=−∂(αh−γh)∂Ek
由于隐层神经元连接所有输出层神经元,链式法则拆解需对所有输出层神经元 j j j 求和,展开式(加粗核心公式):
e h = − ∑ j = 1 l ( ∂ E k ∂ β j ⋅ ∂ β j ∂ b h ) ⋅ ∂ b h ∂ ( α h − γ h ) e_h = -\sum_{j=1}^l \left( \frac{\partial E_k}{\partial \beta_j} \cdot \frac{\partial \beta_j}{\partial b_h} \right) \cdot \frac{\partial b_h}{\partial (\alpha_h - \gamma_h)} eh=−j=1∑l(∂βj∂Ek⋅∂bh∂βj)⋅∂(αh−γh)∂bh
分别计算三个偏导项:
- ∂ E k ∂ β j = − g j \frac{\partial E_k}{\partial \beta_j} = -g_j ∂βj∂Ek=−gj(输出层误差项已推导);
- ∂ β j ∂ b h = w h j \frac{\partial \beta_j}{\partial b_h} = w_{hj} ∂bh∂βj=whj(由 β j = ∑ h = 1 q w h j b h \beta_j = \sum_{h=1}^q w_{hj}b_h βj=∑h=1qwhjbh 求导可得);
- ∂ b h ∂ ( α h − γ h ) = b h ( 1 − b h ) \frac{\partial b_h}{\partial (\alpha_h - \gamma_h)} = b_h(1 - b_h) ∂(αh−γh)∂bh=bh(1−bh)(套用Sigmoid导数性质)。
代入化简后得到隐层误差项(加粗核心公式):
e h = ( ∑ j = 1 l g j ⋅ w h j ) ⋅ b h ( 1 − b h ) e_h = \left( \sum_{j=1}^l g_j \cdot w_{hj} \right) \cdot b_h (1 - b_h) eh=(j=1∑lgj⋅whj)⋅bh(1−bh)
该误差项的物理意义是:隐层神经元的误差,是所有输出层神经元的误差 g j g_j gj 按照连接权 w h j w_{hj} whj 加权求和后,再乘以隐层输出的Sigmoid导数。
4.3.3.2 计算输入-隐层连接权 v i h v_{ih} vih 的梯度
输入-隐层连接权 v i h v_{ih} vih 是输入 i i i 到隐层 h h h 的连接权,其梯度通过链式法则拆解为(加粗核心公式):
∂ E k ∂ v i h = ∂ E k ∂ α h ⋅ ∂ α h ∂ v i h \frac{\partial E_k}{\partial v_{ih}} = \frac{\partial E_k}{\partial \alpha_h} \cdot \frac{\partial \alpha_h}{\partial v_{ih}} ∂vih∂Ek=∂αh∂Ek⋅∂vih∂αh
分别计算两个偏导项:
- ∂ α h ∂ v i h = x i \frac{\partial \alpha_h}{\partial v_{ih}} = x_i ∂vih∂αh=xi(由 α h = ∑ i = 1 d v i h x k , i \alpha_h = \sum_{i=1}^d v_{ih}x_{k,i} αh=∑i=1dvihxk,i 求导可得);
- ∂ E k ∂ α h = − e h \frac{\partial E_k}{\partial \alpha_h} = -e_h ∂αh∂Ek=−eh(根据隐层误差项 e h e_h eh 定义)。
代入化简后得到输入-隐层连接权 v i h v_{ih} vih 的梯度(加粗核心公式):
∂ E k ∂ v i h = − e h ⋅ x i \frac{\partial E_k}{\partial v_{ih}} = -e_h \cdot x_i ∂vih∂Ek=−eh⋅xi
4.3.3.3 计算隐层阈值 γ h \gamma_h γh 的梯度
隐层阈值 γ h \gamma_h γh 的梯度通过链式法则拆解为(加粗核心公式):
∂ E k ∂ γ h = ∂ E k ∂ ( α h − γ h ) ⋅ ∂ ( α h − γ h ) ∂ γ h \frac{\partial E_k}{\partial \gamma_h} = \frac{\partial E_k}{\partial (\alpha_h - \gamma_h)} \cdot \frac{\partial (\alpha_h - \gamma_h)}{\partial \gamma_h} ∂γh∂Ek=∂(αh−γh)∂Ek⋅∂γh∂(αh−γh)
分别计算两个偏导项:
- ∂ E k ∂ ( α h − γ h ) = − e h \frac{\partial E_k}{\partial (\alpha_h - \gamma_h)} = -e_h ∂(αh−γh)∂Ek=−eh(隐层误差项定义);
- ∂ ( α h − γ h ) ∂ γ h = − 1 \frac{\partial (\alpha_h - \gamma_h)}{\partial \gamma_h} = -1 ∂γh∂(αh−γh)=−1( γ h \gamma_h γh 前为负号,求导结果为-1)。
代入化简后得到隐层阈值 γ h \gamma_h γh 的梯度(加粗核心公式):
∂ E k ∂ γ h = e h \frac{\partial E_k}{\partial \gamma_h} = e_h ∂γh∂Ek=eh
4.3.4 反向传播梯度计算的核心总结
BP算法反向传播梯度计算的本质是链式法则的层层拆解 + 误差项的反向传递,所有参数的梯度可归纳为统一规律(加粗重点):
- 对连接权( w h j w_{hj} whj 或 v i h v_{ih} vih):梯度 = − 当前层误差项 × 上一层输出 - \text{当前层误差项} \times \text{上一层输出} −当前层误差项×上一层输出;
- 对阈值( θ j \theta_j θj 或 γ h \gamma_h γh):梯度 = 当前层误差项 \text{当前层误差项} 当前层误差项。
误差项的计算规律(加粗重点):
- 输出层误差项:由真实标签与预测值的差值和输出层Sigmoid导数决定;
- 隐层误差项:由输出层误差项的加权和和隐层Sigmoid导数决定。
该规律可推广到任意多层神经网络,这也是BP算法能适用于深层网络的核心原因。
4.4 第三步:参数更新(基于梯度下降)
BP算法通过梯度下降法沿误差减少的方向(负梯度方向)更新所有参数,学习率 η ∈ ( 0 , 1 ) \eta \in (0,1) η∈(0,1) 控制调整步长(步长过大会导致振荡,过小会导致收敛缓慢)。
结合梯度计算结果,参数更新公式如下(完全对齐选中内容):
| 参数类型 | 符号 | 更新公式(负梯度方向) | 核心含义 |
|---|---|---|---|
| 隐层-输出连接权 | w h j w_{hj} whj | w h j ← w h j + η ⋅ g j ⋅ b h w_{hj} \leftarrow w_{hj} + \eta \cdot g_j \cdot b_h whj←whj+η⋅gj⋅bh | 输出层误差 g j g_j gj 越大、隐层输出 b h b_h bh 越大,权值调整幅度越大 |
| 输出层阈值 | θ j \theta_j θj | θ j ← θ j − η ⋅ g j \theta_j \leftarrow \theta_j - \eta \cdot g_j θj←θj−η⋅gj | 输出层误差 g j g_j gj 越大,阈值调整幅度越大 |
| 输入-隐层连接权 | v i h v_{ih} vih | v i h ← v i h + η ⋅ e h ⋅ x i v_{ih} \leftarrow v_{ih} + \eta \cdot e_h \cdot x_i vih←vih+η⋅eh⋅xi | 隐层误差 e h e_h eh 越大、输入 x i x_i xi 越大,权值调整幅度越大 |
| 隐层阈值 | γ h \gamma_h γh | γ h ← γ h − η ⋅ e h \gamma_h \leftarrow \gamma_h - \eta \cdot e_h γh←γh−η⋅eh | 隐层误差 e h e_h eh 越大,阈值调整幅度越大 |
4.5 BP算法的完整流程
上面看不懂可以看这里,具体算了一遍反向传播:换一种方法演示反向传播
- 初始化参数:随机初始化所有连接权( v i h , w h j v_{ih}, w_{hj} vih,whj)和阈值( γ h , θ j \gamma_h, \theta_j γh,θj),通常取值范围为 ( 0 , 1 ) (0,1) (0,1);
- 遍历训练样本:对每个样本 ( x k , y k ) (x_k, y_k) (xk,yk):
- 前向传播:计算隐层输入 α h → \alpha_h \rightarrow αh→ 隐层输出 b h → b_h \rightarrow bh→ 输出层输入 β j → \beta_j \rightarrow βj→ 预测输出 y ^ j \hat{y}_j y^j;
- 反向传播:先计算输出层误差 g j g_j gj,再计算隐层误差 e h e_h eh,得到所有参数的梯度;
- 参数更新:按上述公式调整连接权和阈值;
- 终止条件:当训练集的总均方误差小于预设阈值,或迭代次数达到上限时停止。
4.6 关键总结:BP的“反向”本质
BP算法的“反向”体现在误差传播方向与信号前向传播方向相反:
- 前向传播:输入层→隐层→输出层(计算预测输出);
- 反向传播:输出层→隐层(计算误差梯度)。
通过“误差逆传+梯度下降”的机制,BP算法解决了多层前馈网络的训练难题,使网络能够拟合复杂的非线性函数,为后续深度学习模型的发展奠定了基础。
五、BP 神经网络的过拟合缓解策略
BP 神经网络具有强大的表示能力,在训练过程中易出现过拟合现象 —— 训练误差持续降低,但测试误差显著上升,本质是模型过度记忆训练集的噪声而非学习普遍规律。本节详细讲解两种经典的缓解策略:早停与正则化。
5.1 早停(Early Stopping):过程控制,掐断过拟合起点
早停是通过控制训练迭代次数,在模型开始记忆训练集噪声前停止训练,核心是利用验证集误差的变化拐点作为停止信号。
5.1.1 核心原理
BP 神经网络过拟合的典型误差变化规律:
- 训练集误差:随训练轮次增加持续降低,因为模型不断拟合训练数据(包括噪声);
- 验证集误差:先降低(模型学习到普遍规律,泛化能力提升),后上升(模型过度拟合噪声,泛化能力下降)。
早停的本质是捕捉验证集误差的最小值点—— 在验证集误差由降转升的拐点处停止训练,此时模型保留对普遍规律的学习,未陷入噪声记忆,泛化性能最优。
5.1.2 具体操作步骤
- 数据划分
将原始数据集拆分为两个独立子集:
- 训练集:用于 BP 算法的梯度计算与参数更新,是模型学习的核心数据;
- 验证集:不参与参数更新,仅用于每轮训练后评估模型误差,作为早停判断的依据。
示例:1000 个样本按 7:3 划分为 700 个训练样本和 300 个验证样本。
- 训练与监控流程
按 BP 算法的常规流程迭代训练,每轮训练后执行以下操作:
- 用训练集计算梯度,更新连接权 v i h 、 w h j v_{ih}、w_{hj} vih、whj 和阈值 γ h 、 θ j \gamma_h、\theta_j γh、θj;
- 用验证集计算当前模型的均方误差,记录误差值;
- 对比当前验证集误差与历史最小验证集误差:
- 若当前误差更小:更新历史最小误差,并保存此时的所有参数(这是泛化最优的参数组合);
- 若当前误差更大,且连续多轮(如 5~10 轮)未刷新历史最小值:触发早停,停止训练,加载保存的最优参数作为最终模型。
5.1.3 防过拟合逻辑
BP 神经网络的表示能力强,若无限制训练,参数会持续调整以 “完美拟合训练集”,包括拟合训练样本中的噪声和异常值。早停通过 “在过拟合发生前终止训练”,避免参数过度适应训练集的特殊情况,保留模型对数据普遍规律的学习能力,从而缓解过拟合。
5.2 正则化(Regularization):目标约束,惩罚复杂模型
正则化是通过修改 BP 算法的误差目标函数,在最小化训练误差的同时增加模型复杂度的惩罚项,迫使模型选择更简单的参数结构,核心是平衡 “训练误差” 与 “模型复杂度”。
5.2.1 核心原理
BP 算法的原始目标函数仅关注训练误差的最小化:
E o r i g i n a l = 1 2 ∑ k = 1 m ∑ j = 1 l ( y k , j − y ^ k , j ) 2 E_{original}=\frac{1}{2}\sum_{k=1}^m\sum_{j=1}^l(y_{k,j}-\hat{y}_{k,j})^2 Eoriginal=21k=1∑mj=1∑l(yk,j−y^k,j)2
其中 m m m 为训练样本数, l l l 为输出维度。
过拟合时,模型为降低训练误差会形成复杂结构,表现为部分连接权的绝对值极大(对应对个别训练样本的过度适应)。正则化通过在目标函数中加入正则化项,将目标函数改造为:
E r e g u l a r i z e d = E o r i g i n a l + λ ⋅ R ( w ) E_{regularized}=E_{original}+\lambda\cdot R(w) Eregularized=Eoriginal+λ⋅R(w)
其中关键参数与项的定义:
- λ ∈ ( 0 , 1 ) \lambda\in(0,1) λ∈(0,1):正则化系数,控制惩罚力度。 λ \lambda λ 越大,对复杂模型的惩罚越重; λ = 0 \lambda=0 λ=0 退化为原始目标函数;
- R ( w ) R(w) R(w):正则化项,用于描述模型的复杂度,通常采用连接权的范数,常见形式有两种:
- L2 正则化(权重衰减): R ( w ) = ∑ w 2 R(w)=\sum w^2 R(w)=∑w2,惩罚绝对值大的权重,迫使所有权重尽可能小;
- L1 正则化: R ( w ) = ∑ ∣ w ∣ R(w)=\sum |w| R(w)=∑∣w∣,惩罚绝对值大的权重,还可能使部分权重变为 0,实现特征选择。
5.2.2 操作流程与梯度更新
正则化的核心是修改梯度计算与参数更新规则,以下以L2 正则化为例详细说明:
- 梯度计算的修改
对改造后的目标函数 E r e g u l a r i z e d E_{regularized} Eregularized 求参数的偏导,以隐层 - 输出层连接权 w h j w_{hj} whj 为例:
∂ E r e g u l a r i z e d ∂ w h j = ∂ E o r i g i n a l ∂ w h j + ∂ ( λ ⋅ R ( w ) ) ∂ w h j \frac{\partial E_{regularized}}{\partial w_{hj}}=\frac{\partial E_{original}}{\partial w_{hj}}+\frac{\partial (\lambda\cdot R(w))}{\partial w_{hj}} ∂whj∂Eregularized=∂whj∂Eoriginal+∂whj∂(λ⋅R(w))
- 原始梯度项: ∂ E o r i g i n a l ∂ w h j = − g j ⋅ b h \frac{\partial E_{original}}{\partial w_{hj}}=-g_j\cdot b_h ∂whj∂Eoriginal=−gj⋅bh(来自 BP 反向传播推导);
- 正则化项的梯度: ∂ ( λ ⋅ ∑ w 2 ) ∂ w h j = 2 λ w h j \frac{\partial (\lambda\cdot \sum w^2)}{\partial w_{hj}}=2\lambda w_{hj} ∂whj∂(λ⋅∑w2)=2λwhj。
因此,加入 L2 正则化后的梯度为:
∂ E r e g u l a r i z e d ∂ w h j = − g j ⋅ b h + 2 λ w h j \frac{\partial E_{regularized}}{\partial w_{hj}}=-g_j\cdot b_h+2\lambda w_{hj} ∂whj∂Eregularized=−gj⋅bh+2λwhj
- 参数更新规则的修改
代入梯度下降的参数更新公式,得到:
w h j ← w h j − η ⋅ ( − g j ⋅ b h + 2 λ w h j ) w_{hj}\leftarrow w_{hj}-\eta\cdot(-g_j\cdot b_h+2\lambda w_{hj}) whj←whj−η⋅(−gj⋅bh+2λwhj)
展开后为:
w h j ← w h j ( 1 − 2 η λ ) + η ⋅ g j ⋅ b h w_{hj}\leftarrow w_{hj}(1-2\eta\lambda)+\eta\cdot g_j\cdot b_h whj←whj(1−2ηλ)+η⋅gj⋅bh
可以看到,权重更新时会额外乘以系数 ( 1 − 2 η λ ) (1-2\eta\lambda) (1−2ηλ),这一系数小于 1,因此每次更新都会让权重衰减—— 绝对值大的权重衰减幅度更大,从而迫使权重保持较小的数值。
5.2.3 防过拟合逻辑
模型的复杂度与连接权的绝对值正相关:权重越大,模型对输入的变化越敏感,越容易拟合训练集的噪声;权重越小,模型越简单,对噪声的敏感度越低。
正则化通过 “惩罚大权重”,让模型在 “降低训练误差” 和 “保持权重较小” 之间寻找平衡:
- 若模型试图用大权重拟合训练集噪声,正则化项会显著增大目标函数,导致无法最小化;
- 只有当模型用较小的权重拟合训练集的普遍规律时,目标函数才能取得最小值。
这种平衡限制了 BP 网络表示能力的滥用,避免模型陷入过拟合。
5.3 两种策略的核心差异与共性
| 维度 | 早停(Early Stopping) | 正则化(Regularization) |
|---|---|---|
| 干预层面 | 训练过程(控制迭代轮次) | 目标函数(改造优化目标) |
| 核心逻辑 | 捕捉验证集误差拐点,停止过拟合进程 | 惩罚复杂模型,平衡训练误差与复杂度 |
| 操作重点 | 数据划分(训练 / 验证集)、误差跟踪 | 正则化项选择(L1/L2)、 λ \lambda λ调参 |
| 对 BP 的影响 | 不改变梯度计算,仅停止参数更新 | 改变梯度计算,影响权值更新方向 |
共性:两种策略均针对 BP 网络 “表示能力强易过拟合” 的痛点,通过 “限制模型过度学习” 保留泛化能力 —— 早停是从 “时间” 维度停止过拟合,正则化是从 “结构” 维度约束模型复杂度,实际应用中可结合使用以进一步提升效果。
六、全局最小与局部极小:BP 的参数寻优困境
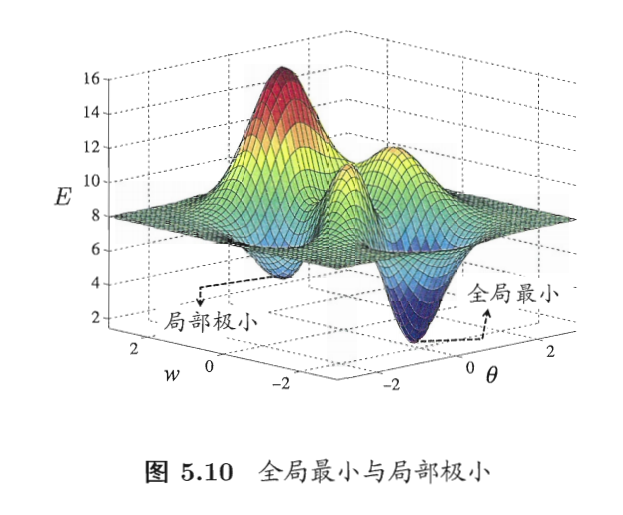
BP 神经网络的训练本质是高维参数空间的寻优问题,由于误差函数的非凸性,梯度下降算法易陷入局部极小点,无法达到全局最小点。本节详解全局最小与局部极小的概念、成因及应对策略。
6.1 核心概念:参数空间的误差低谷
设 BP 网络的所有参数(连接权 v i h , w h j v_{ih},w_{hj} vih,whj + 阈值 γ h , θ j \gamma_h,\theta_j γh,θj)构成参数向量 Θ = ( w ; v ; γ ; θ ) \Theta=(w;v;\gamma;\theta) Θ=(w;v;γ;θ),误差函数 E ( Θ ) E(\Theta) E(Θ) 表示参数为 Θ \Theta Θ 时的训练误差或泛化误差。全局最小与局部极小是参数空间中误差函数的两种极小值点。
6.1.1 数学定义
-
局部极小(Local Minimum)
存在一个小范围 ϵ > 0 \epsilon>0 ϵ>0,对该范围内所有参数 Θ ′ \Theta' Θ′(满足 ∥ Θ ′ − Θ ∗ ∥ ≤ ϵ \|\Theta'-\Theta^*\|≤\epsilon ∥Θ′−Θ∗∥≤ϵ),都有:
E ( Θ ′ ) ≥ E ( Θ ∗ ) E(\Theta')≥E(\Theta^*) E(Θ′)≥E(Θ∗)
直观理解:参数空间中的一个 “小山谷”,山谷底部的误差低于周围区域,但不一定是整个参数空间的最低点。 -
全局最小(Global Minimum)
对参数空间中所有可能的参数组合 Θ \Theta Θ,都有:
E ( Θ ) ≥ E ( Θ ∗ ) E(\Theta)≥E(\Theta^*) E(Θ)≥E(Θ∗)
直观理解:参数空间中的 “最深山谷”,是误差函数的全局最低点,对应模型的最优参数。
6.1.2 关键关系
- 全局最小一定是局部极小,但局部极小不一定是全局最小;
- BP 神经网络的误差函数 E ( Θ ) E(\Theta) E(Θ) 是高维非凸函数。原因有二:一是参数维度高(数百甚至数千维),二是激活函数(如 Sigmoid)的非线性导致误差函数呈现多峰结构。非凸函数必然存在多个局部极小点,这是 BP 算法易陷入局部极小的根本原因。
6.2 BP 易陷入局部极小的根源:梯度下降的先天局限
BP 算法依赖梯度下降法更新参数,其核心逻辑是 “沿负梯度方向调整参数,直到梯度为零”。但梯度为零的点存在三种可能:全局最小点、局部极小点、鞍点(梯度为零但非极小值点),梯度下降无法区分这三类点,这是导致寻优失败的关键。
具体过程如下:
- 梯度下降的停止条件:当 ∇ E ( Θ ) = 0 \nabla E(\Theta)=0 ∇E(Θ)=0 时,参数更新量 Δ Θ = − η ⋅ ∇ E ( Θ ) = 0 \Delta\Theta=-\eta\cdot\nabla E(\Theta)=0 ΔΘ=−η⋅∇E(Θ)=0,训练停止;
- 陷入局部极小的过程:若训练中参数落入某个局部极小点 Θ l o c a l \Theta_{local} Θlocal,此时该点的梯度为零,梯度下降会误以为找到最优解而停止;
- 后果:模型的训练误差无法继续降低,或降低到一定程度后停滞,即使训练误差较低,泛化性能也会因参数未达全局最优而变差。
6.3 跳出局部极小的实用策略
针对梯度下降的局限,文档提出三类启发式策略,核心是 “打破梯度为零的停滞状态”,帮助参数向全局最小点靠近。
6.3.1 多组不同初始参数(最常用)
-
原理
误差函数的局部极小点位置与初始参数 Θ 0 \Theta_0 Θ0 密切相关 —— 不同的初始参数对应梯度下降的不同下降路径,最终可能收敛到不同的局部极小点。通过尝试多组初始参数,增加找到全局最小点附近局部极小点的概率。 -
BP 中的应用
- 生成 5~10 组不同的初始参数,取值范围通常为 ( − 0.5 , 0.5 ) (-0.5,0.5) (−0.5,0.5) 或 ( 0 , 1 ) (0,1) (0,1);
- 用每组初始参数独立训练 BP 网络至收敛;
- 在验证集上评估所有收敛模型的误差,选择误差最小的模型作为最终结果。
- 优势
简单易实现,无需修改 BP 算法的梯度计算逻辑,在小规模 BP 网络中效果显著。
6.3.2 模拟退火(Simulated Annealing)
- 原理
借鉴物理中 “金属退火” 的过程 —— 高温时金属原子可自由移动(接受能量较高的状态),低温时原子逐渐稳定(仅接受能量更低的状态)。对应到 BP 参数寻优:
- 训练初期(高温阶段):允许参数向误差略高的次优解调整,即接受 E ( Θ n e w ) > E ( Θ o l d ) E(\Theta_{new})>E(\Theta_{old}) E(Θnew)>E(Θold) 的更新,帮助参数跳出局部极小点;
- 训练后期(低温阶段):逐渐降低接受次优解的概率,让参数稳定在误差较低的点。
- BP 中的应用
在梯度下降的参数更新中引入接受概率:
P = e x p ( − E ( Θ n e w ) − E ( Θ o l d ) T ) P=exp\left(-\frac{E(\Theta_{new})-E(\Theta_{old})}{T}\right) P=exp(−TE(Θnew)−E(Θold))
其中 T T T 为 “温度”,随训练轮次单调降低。参数更新规则为:
- 若 E ( Θ n e w ) < E ( Θ o l d ) E(\Theta_{new})<E(\Theta_{old}) E(Θnew)<E(Θold):直接接受更新;
- 若 E ( Θ n e w ) > E ( Θ o l d ) E(\Theta_{new})>E(\Theta_{old}) E(Θnew)>E(Θold):生成 0~1 的随机数,若随机数小于 P P P,则接受更新,否则拒绝。
- 优势
能主动跳出局部极小点,但需调整温度下降速率等参数,调优过程较复杂。
6.3.3 随机梯度下降(Stochastic Gradient Descent, SGD)
-
原理
标准 BP 算法采用批量梯度下降,用全量训练样本计算梯度,梯度值精确但易陷入局部极小;随机梯度下降则每次用 1 个样本计算梯度,梯度值带有随机噪声 —— 即使在局部极小点,随机梯度也可能不为零,从而打破停滞状态。 -
BP 中的应用
- 标准 BP 的梯度计算: ∇ E = 1 m ∑ k = 1 m ∇ E k \nabla E=\frac{1}{m}\sum_{k=1}^m\nabla E_k ∇E=m1∑k=1m∇Ek( m m m 为批量样本数);
- 随机梯度下降的梯度计算: ∇ E ≈ ∇ E k \nabla E≈\nabla E_k ∇E≈∇Ek(仅用第 k k k 个样本的梯度近似全局梯度);
- 每次参数更新都引入随机波动,避免梯度长期为零,帮助参数跳出局部极小。
- 优势
无需额外调参,天然引入随机性,收敛速度快于批量梯度下降,是工业界训练深层 BP 网络的常用方法。
6.4 与 BP 过拟合的关联
过拟合与局部极小是 BP 网络训练的两类不同问题,需明确两者的区别与联系:
- 区别:过拟合是 “模型学太好”(训练误差低、测试误差高,源于记忆噪声);局部极小是 “模型没学好”(训练误差降不下去,源于参数未达最优);
- 联系:若 BP 陷入局部极小,训练误差未充分降低,模型的拟合能力未完全发挥,反而不易过拟合(但模型性能差);若模型接近全局最小点,拟合能力达到最优,此时更需通过早停、正则化等策略防止过拟合。
七、整体总结
本文从生物神经元的抽象出发,系统讲解了 M-P 神经元模型的结构与激活函数选择,基于神经元模型构建感知机并推导其学习策略,延伸到多层前馈网络的 BP 训练算法,最后补充 BP 网络的过拟合缓解策略与参数寻优困境,完整覆盖《周志华・机器学习》第五章的核心内容。
核心逻辑链可总结为:
- 模型抽象:将生物神经元信号处理过程抽象为 M-P 模型,通过激活函数解决非线性问题,为神经网络奠定基础;
- 感知机局限:两层感知机仅能处理线性可分问题,无法解决异或问题,催生多层网络与 BP 算法;
- BP 算法突破:通过 “前向传播算输出、反向传播算梯度、梯度下降更参数” 的逻辑,解决多层网络的训练难题,实现复杂非线性函数拟合;
- 过拟合缓解:早停从训练过程控制迭代次数,正则化从目标函数惩罚复杂模型,两者从不同维度解决 BP 过拟合问题;
- 参数寻优困境:BP 误差函数的非凸性导致梯度下降易陷入局部极小,多初始参数、模拟退火、随机梯度下降等策略可有效缓解这一问题。
理解从神经元到感知机再到 BP 算法的完整演进逻辑,掌握过拟合与参数寻优的应对策略,是深入学习神经网络与深度学习的关键前提。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)