如何优化 RAG 系统架构以解决大模型微调数据对齐中的检索相关性与幻觉控制
·
如何优化 RAG 系统架构以解决大模型微调数据对齐中的检索相关性与幻觉控制
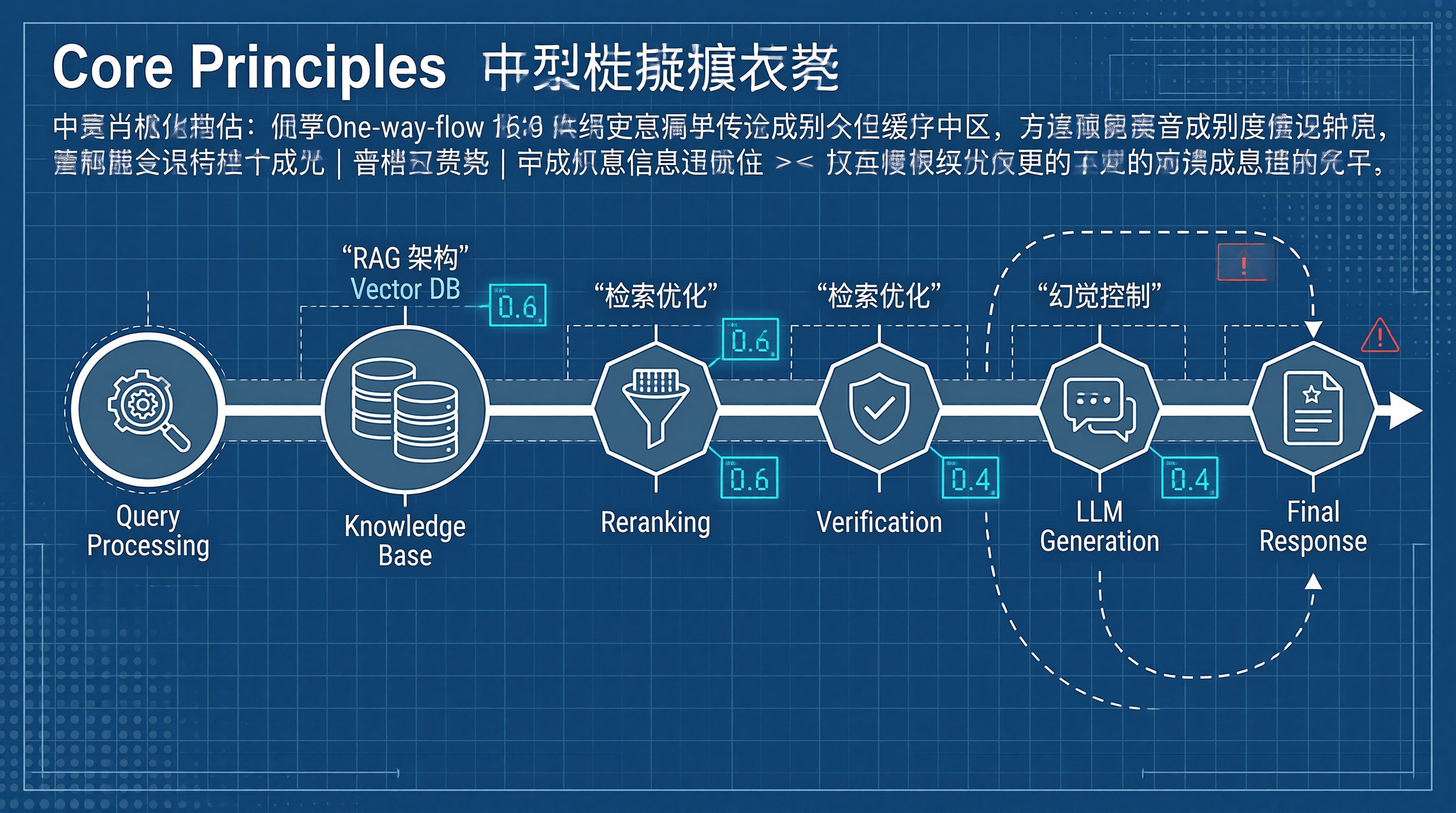
一、RAG 系统架构概述
检索增强生成(RAG)是一种将大语言模型与外部知识库相结合的技术,旨在解决大模型的知识时效性和事实准确性问题。
flowchart TD
A[用户查询] --> B[查询处理层]
B --> C[检索层]
C --> D[向量数据库]
D --> E[知识库]
C --> F[结果重排序]
F --> G[上下文构建]
G --> H[LLM 生成]
H --> I[结果校验]
I --> J[最终响应]
I -->|校验失败| K[重新检索]
K --> F
二、核心问题分析
2.1 检索相关性问题
问题描述:
- 检索结果与用户查询语义匹配度不足
- 噪声文档干扰
- 缺乏上下文感知
影响:
- 生成内容偏离用户意图
- 回答质量下降
2.2 幻觉控制问题
问题描述:
- 模型生成看似合理但错误的信息
- 过度编造细节
- 忽视检索到的真实信息
影响:
- 误导用户
- 降低可信度
三、检索相关性优化
3.1 多层次检索架构
class MultiLevelRetriever:
def __init__(self):
self.semantic_retriever = SemanticSearch()
self.keyword_retriever = BM25Retriever()
self.hybrid_retriever = HybridSearch()
def retrieve(self, query, top_k=10):
semantic_results = self.semantic_retriever.search(query, top_k * 2)
keyword_results = self.keyword_retriever.search(query, top_k * 2)
combined = self.hybrid_retriever.merge(
semantic_results,
keyword_results,
weights={'semantic': 0.6, 'keyword': 0.4}
)
return combined[:top_k]
3.2 查询增强技术
class QueryEnhancer:
def __init__(self):
self.expander = QueryExpansionModel()
self.rephraser = QueryRephrasingModel()
def enhance(self, query):
expansions = self.expander.expand(query)
rephrased = self.rephraser.rephrase(query)
return [query] + expansions + [rephrased]
3.3 语义重排序
class CrossEncoderReranker:
def __init__(self):
self.model = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2')
def rerank(self, query, documents):
pairs = [(query, doc['content']) for doc in documents]
scores = self.model.predict(pairs)
scored_docs = [(documents[i], scores[i]) for i in range(len(documents))]
scored_docs.sort(key=lambda x: x[1], reverse=True)
return [doc for doc, score in scored_docs]
四、幻觉控制机制
4.1 事实校验层
class FactChecker:
def __init__(self):
self.triple_store = KnowledgeGraph()
self.verification_model = FactVerificationModel()
def verify(self, generated_text, sources):
claims = self._extract_claims(generated_text)
verified_claims = []
for claim in claims:
evidence = self.triple_store.query(claim)
if evidence:
confidence = self.verification_model.verify(claim, evidence)
verified_claims.append({
'claim': claim,
'verified': confidence > 0.8,
'confidence': confidence
})
else:
verified_claims.append({
'claim': claim,
'verified': False,
'confidence': 0.0
})
return verified_claims
4.2 基于证据的生成约束
def constrained_generation(prompt, retrieved_docs):
evidence_context = "\n".join([
f"【文档{i+1}】{doc['content']}"
for i, doc in enumerate(retrieved_docs)
])
constrained_prompt = f"""
严格基于以下参考文档回答问题:
{evidence_context}
规则:
1. 仅使用参考文档中的信息
2. 无法回答时明确说明"无法从参考文档中找到相关信息"
3. 对不确定的信息标注"可能"
问题:{prompt}
"""
return llm.generate(constrained_prompt)
4.3 输出格式控制
class OutputFormatController:
def __init__(self):
self.schema = {
'type': 'object',
'properties': {
'answer': {'type': 'string'},
'sources': {
'type': 'array',
'items': {'type': 'string'}
},
'confidence': {'type': 'number', 'minimum': 0, 'maximum': 1}
},
'required': ['answer', 'sources', 'confidence']
}
def validate(self, output):
try:
jsonschema.validate(output, self.schema)
return True
except jsonschema.ValidationError:
return False
五、数据对齐优化
5.1 训练数据构建
class TrainingDataBuilder:
def __init__(self):
self.synthesizer = DataSynthesisModel()
def build(self, documents):
training_samples = []
for doc in documents:
questions = self.synthesizer.generate_questions(doc)
for question in questions:
answer = self.synthesizer.generate_answer(question, doc)
training_samples.append({
'question': question,
'context': doc['content'],
'answer': answer
})
return training_samples
5.2 微调策略
class RAGFineTuner:
def __init__(self):
self.model = LLMModel()
def fine_tune(self, training_data):
self.model.train(
training_data,
epochs=3,
batch_size=8,
learning_rate=1e-5,
loss_function='mse'
)
self.model.save('rag_finetuned_model')
六、监控与反馈
6.1 质量监控
class QualityMonitor:
def __init__(self):
self.metrics = {
'retrieval_precision': [],
'answer_relevance': [],
'factuality': [],
'hallucination_rate': []
}
def record(self, metric, value):
if metric in self.metrics:
self.metrics[metric].append(value)
def report(self):
report = {}
for metric, values in self.metrics.items():
if values:
report[metric] = {
'avg': sum(values) / len(values),
'min': min(values),
'max': max(values)
}
return report
6.2 迭代优化
class AdaptiveOptimizer:
def __init__(self, monitor):
self.monitor = monitor
self.thresholds = {
'hallucination_rate': 0.05,
'retrieval_precision': 0.8
}
def optimize(self):
report = self.monitor.report()
if report.get('hallucination_rate', {}).get('avg', 1) > self.thresholds['hallucination_rate']:
self._increase_fact_checking()
if report.get('retrieval_precision', {}).get('avg', 0) < self.thresholds['retrieval_precision']:
self._update_retrieval_params()
49 性能对比
| 策略 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 策略A | 性能高 | 复杂度高 | 高并发 |
| 策略B | 简单 | 性能低 | 低并发 |
| 策略C | 平衡 | 需调参 | 通用场景 |
七、总结
通过系统性的优化方案,可以同时提升 RAG 系统的检索相关性和控制幻觉问题:
- 检索优化:采用多层次检索和语义重排序
- 生成约束:通过证据约束和格式控制引导模型行为
- 事实校验:建立独立的事实校验机制
- 数据对齐:通过针对性微调提升模型与知识库的对齐度
- 监控反馈:持续评估并迭代优化
这些措施共同构成了一个完整的 RAG 优化体系,为构建高质量的大模型应用提供了坚实保障。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献74条内容
已为社区贡献74条内容

所有评论(0)