AI核心知识——蒸馏
一、从班里的“学霸”说起
我们可以先想想班里的那种“真·学霸”。大家有没有发现,真正厉害的学霸,往往不是最会死记硬背标准答案的人。他们厉害在哪?
-
他们知道为什么这么做;
-
他们知道哪些题容易挖坑;
-
他们甚至知道:“这个答案虽然错了,但思路已经很接近了”。
而普通学生通常只能学到:“哦,这道题选C”。
那么问题来了:如果想让一个普通学生,快速拥有学霸的能力,该怎么办?让他把学霸的错题本抄一遍?没用。他需要学习的是学霸的 “思考方式”。
现在的大模型(比如 GPT-4、Claude、DeepSeek-R1)就是那个“由上百位博士组成的超级学霸”。它们能力极强,但有一个致命问题:太贵了! 需要超大显卡、海量显存,普通电脑和手机根本跑不动。
于是,AI行业开始思考:能不能把这种“超级大脑”浓缩一下?就像浓缩咖啡、压缩电影一样。 这就是“AI蒸馏”诞生的原因:用更少的资源,保留最多的能力。
二、 核心理论:蒸馏到底在蒸馏什么?(约10分钟)
很多人一听“蒸馏”,以为小模型是在“抄大模型的答案”。错!大模型最值钱的,从来不是答案本身,而是三个核心概念:
1. 暗知识(Dark Knowledge):事物之间的“隐藏关系”
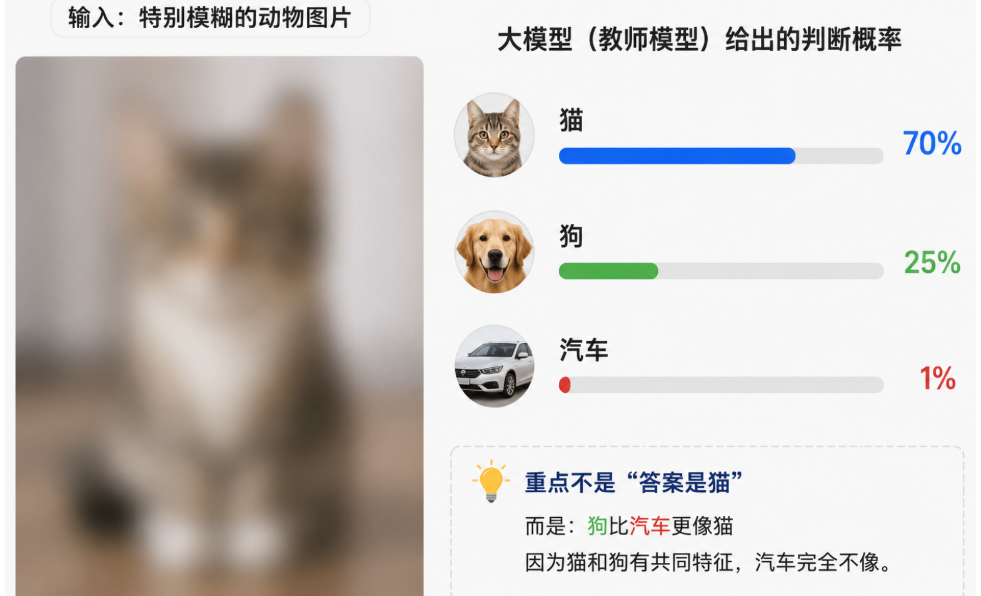
有一张特别模糊的动物图片。 大模型(教师模型)给出的判断概率是:猫 70%,狗 25%,汽车 1%。 普通人只看“猫是正确答案”。但大模型真正想传递的隐藏信息是:“狗比汽车更像猫”。 为什么?因为猫和狗共享“毛发、四肢、生物结构”等特征;而汽车是金属几何体,跟它们完全无关。 这种 “语义距离”和“隐藏的结构信息”,学术界称之为暗知识。它不是玄学,而是大模型在海量数据中总结出的规律。
别小看这些暗知识,它赋予了小模型三大超能力:
-
泛化能力(举一反三):小模型学到了“动物应该长什么样”,遇到没见过的新品种也能猜个八九不离十。
-
抗噪能力(不怕错题):如果老师不小心把“狼”标成了“狗”,小模型因为知道“狼和狗长得很像”,就不会被这个错误标签带偏。
-
可解释性(知道为什么):我们可以通过看暗知识,知道模型到底学到了什么规律。
2. 相对置信度(Relative Confidence):暗知识的“数值载体”
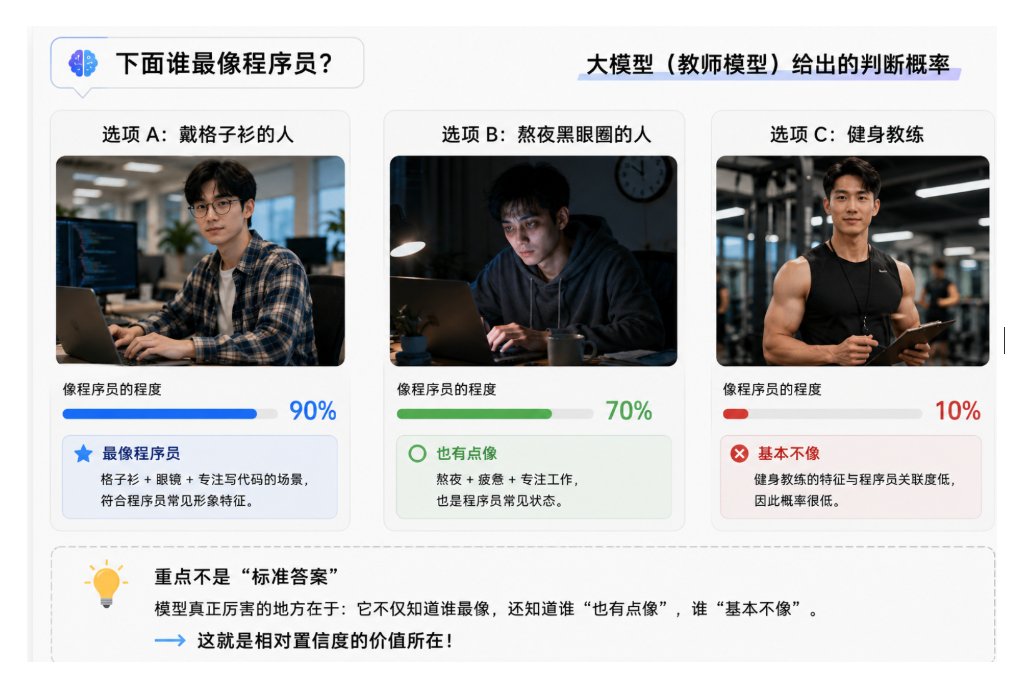
别被名字吓到,它很简单。就是模型认为 “类别A比类别B更像正确答案”的程度。 比如问:“下面谁最像程序员?”
-
戴格子衫的人:90%
-
熬夜黑眼圈的人:70%
-
健身教练:10% 重要的不是“格子衫是标准答案”,而是模型知道:熬夜的人“也有点像”,健身教练“基本不像”。
总结一句话:相对置信度是暗知识的“外在表现”,暗知识是相对置信度的“内在灵魂”。 它们一个是表,一个是里。
3. 温度(Temperature):AI的“自信调节器”
怎么把暗知识提取出来呢?这就需要调节“温度(T)”。
-
低温(T < 1):模型特别自信,“答案只有A!”其他选项概率几乎为0。这时候学生只能学到“非黑即白”的标准答案,暗知识被抹杀了。
-
高温(T > 1):模型变得“犹豫”,“A最可能,B也有一点可能,C基本不可能”。这时候,更多隐藏信息就暴露出来了。
打个比方:低温模型像“只给答案的老师”;高温模型像“会讲解思路、告诉你为什么选A不选B的老师”。蒸馏,就是要调高温度,学习老师的思考方式。
三、 核心案例 Demo:如果把“马斯克”进行蒸馏会怎样?
理论有点抽象?我们来做一个有趣的脑洞 Demo。结合目前主流的 5大蒸馏技术变体,看看我们怎么把一个“超级马斯克”浓缩成“小马斯克”。
【背景设定】 我们有一个“超级马斯克AI”(教师模型),它掌握了SpaceX工程、特斯拉商业思维、第一性原理和马斯克独特的表达风格。但它太大了,运行一次需要8张4090显卡和巨额电费。 于是,我们决定蒸馏一个“小马斯克”(学生模型),让它能跑在普通人的手机上。小马斯克是怎么学习的呢?
1. Logits 蒸馏(学“老师怎么打分/用词”)
-
原理:对齐每个词的生成概率分布。
-
马斯克Demo:当被问到“未来交通”时,超级马斯克内心对词汇的打分是:“第一性原理(90%)” > “颠覆性(80%)” > “也许/大概(5%)”。小马斯克通过模仿这套“打分逻辑”,学会了马斯克那种笃定、极客式的用词偏好,而不是只会说“我觉得未来交通很好”。
2. 注意力蒸馏(学“老师看哪里”)
-
原理:模仿教师模型在处理输入时,注意力聚焦在哪些关键词上。
-
马斯克Demo:看一份百页的商业计划书时,超级马斯克的“注意力”会死死盯住“单位成本”、“物理极限”和“量产时间表”,而自动忽略华丽的PPT排版。小马斯克学会了这种“信息筛选机制”,一眼就能抓住核心。知道“什么信息最重要,什么可以直接跳过”。
3. 推理轨迹蒸馏(学“老师怎么思考”,目前最火🔥)
-
原理:不仅学最终答案,还学习解决复杂问题时的中间思考步骤(CoT)。
-
马斯克Demo:当火箭发射失败时,超级马斯克不会直接说“失败了”,它的思考轨迹是:“① 拆解问题 → ② 定位是阀门故障还是软件bug → ③ 评估修复成本 → ④ 快速迭代测试”。小马斯克继承的不是“火箭会爆炸”这个结果,而是这套 “工程师排错逻辑”。遇到新问题,它也会先拆解、再找本质。
4. 偏好分布蒸馏(学“什么该说,什么不该说”)
-
原理:迁移大模型经过人类反馈(RLHF)后学到的安全边界和分寸感。
-
马斯克Demo:超级马斯克知道,虽然自己说话犀利,但面对“如何制造危险物品”或“恶意攻击竞争对手”的问题时,必须触发“拒答”或“幽默化解”的机制。小马斯克通过偏好蒸馏,继承了这种“有分寸的幽默感”,既有趣又不越界。
5. 自蒸馏(自己教自己)
-
原理:没有外部老师时,模型利用自己早期版本生成的优质答案,不断“生成→筛选→学习”。
-
马斯克Demo:小马斯克在独立运行后,会像学霸整理错题本一样,复盘自己过去的回答,剔除废话,保留高质量逻辑,实现自我进化。
【Demo 总结】 经过这一套组合拳,小马斯克虽然参数量只有原来的十分之一,但它依然保留了“马斯克味儿”:能用第一性原理思考,有工程师逻辑,且说话风趣有分寸。它继承的不是数据,而是思维结构。
四、 行业趋势:为什么现在全行业都在搞蒸馏?
到了2024-2026年,AI行业真正的问题,已经不是“能不能做出强模型”,而是 “能不能让它便宜地运行”。
目前蒸馏技术有四大关键趋势:
-
推理能力蒸馏成为标配:不再只蒸馏答案,而是蒸馏“慢思考”过程(CoT轨迹 + 自我反思),让小模型也能具备逻辑推理能力,不再只是“鹦鹉学舌”。
-
自动化蒸馏管线成熟:以前调温度、配权重像“玄学”,现在有了 AutoDistill 等工具,变成了“标准化工程”,一键生成。
-
对齐蒸馏专业化:专门针对“安全拒答”、“指令遵循”进行蒸馏,让小模型既聪明又听话,不会变成“毒舌AI”。
-
压缩组合拳落地:蒸馏 + 量化(把精度从32位降到4位)+ 剪枝。这套组合拳打下来,未来7B(70亿参数)级别的模型,完全可以流畅运行在大家的消费级显卡甚至高端手机上。
-
在线/课程蒸馏(因材施教):(新增亮点) 以前的蒸馏是“一刀切”,现在的蒸馏是“因材施教”。遇到简单的题(比如1+1=2),直接给硬标签(标准答案);遇到复杂的题(比如微积分),就调高温度,给详细的软标签(思考过程)。这让学习效率大幅提升!
五、怎么去实现蒸馏

六、 结尾总结
AI蒸馏,不是简单地“复制答案”,而是“把聪明,压缩成可以传播的能力”。
真正被传递的,从来不是冰冷的数据,而是大模型在海量计算中凝结出的 “思考方式本身”。
未来,当我们手机里的AI助手,能够用极低的电量,展现出媲美顶级大模型的逻辑与温度时,请记住,这背后一定有“知识蒸馏”在默默发力。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)