2020年高教社杯全国大学生数学建模竞赛 D 题:《接触式轮廓仪的自动标注》真题解析与 MATLAB 解决方案

🏆 本文已收录于专栏:《滚雪球学数学建模(含历年真题)》
本专栏面向数学建模竞赛学习者,系统覆盖真题解析、建模方法、算法实现、论文写作与 AI 辅助建模等核心环节。无论是建模新手,还是备战华为杯、高教社杯、华数杯、国赛、美赛 MCM/ICM 的参赛者,都能在这里找到清晰、完整、可复用的建模思路,持续更新,长期有效。
🎯 免责声明: 本文题目来源于互联网公开内容,仅供学习交流与建模方法研究,不构成竞赛指导。请遵守相关赛事规则,独立完成竞赛作品,使用本文内容所产生的后果由使用者自行承担。
🎉 专栏限时优惠中:一次订阅,永久解锁,后续内容持续更新。 欢迎点击了解 👉 查看专栏详情 👈
全文目录:
-
- 2020年D题:接触式轮廓仪的自动标注
- 一、前言:为什么这道题值得分析
- 二、题目背景与现实意义
- 三、题目重述
- 四、问题分析
- 五、整体建模思路
- 六、数据预处理
- 七、模型假设
- 八、符号说明
- 九、模型一:基础模型建立与求解(针对问题 1)
- 十、模型二:改进模型建立与求解(针对问题 2)
- 十一、模型三:综合模型——多次测量融合重建(针对问题 3、4)
- 十二、算法流程设计
- 十三、MATLAB 完整代码
- 十四、结果展示与分析
- 十五、模型检验
- 十六、模型优缺点
- 十七、论文写作建议
- 十八、数学建模论文摘要示例
- 十九、常见问题与踩坑总结
- 二十、总结
- 附录 A:完整文件清单
- 附录 B:补充辅助函数
- 附录 C:MATLAB 运行环境说明
- 写在最后
- 🎁 文末福利
- 🫵 关于作者
2020年D题:接触式轮廓仪的自动标注
真题展示
如下为原(真)题,展示如下:

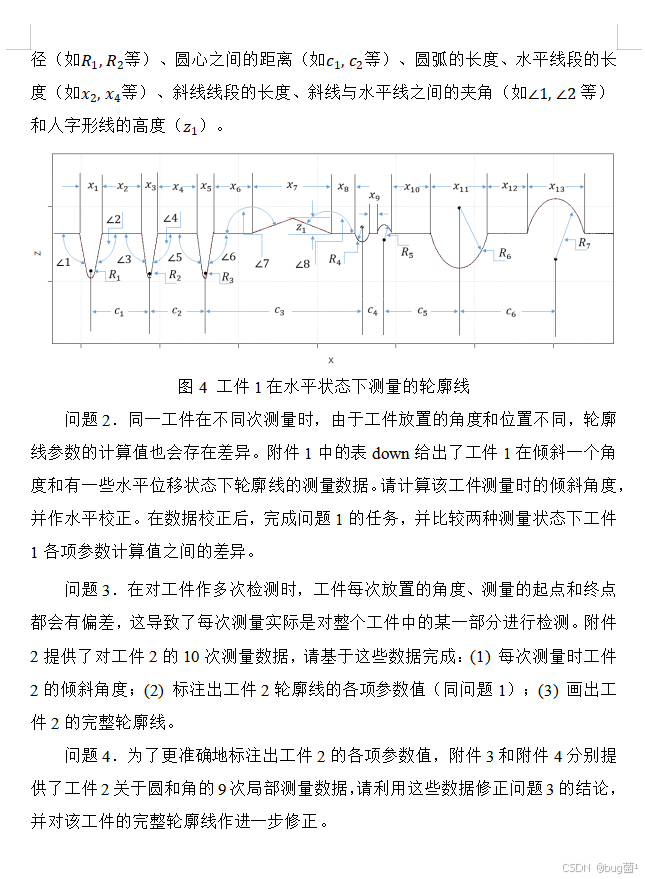
一、前言:为什么这道题值得分析
每年我带学生备赛时,都会把 2020 国赛 D 题作为"机理建模 + 数据处理"双重思维训练的经典案例。它和 A、B、C 题完全不同:
- A 题(炉温曲线)偏向物理机理建模;
- B 题(穿越沙漠)属于优化决策类;
- C 题(中小微企业信贷)是评价 + 数据分析;
- 而 D 题是一道典型的工程几何反演问题——给你一堆"带噪声的点云",让你反推出工件的几何参数。
这道题之所以值得深度研究,有四个原因:
- 题目"看似简单"但坑很多:标注几个参数听起来很容易,实际上从原始信号到几何参数中间隔着至少 5 道处理工序。
- 它训练的是"全链路思维":去噪 → 分段 → 拟合 → 校正 → 融合 → 标注,每一步出错都会导致最终参数偏差。
- MATLAB 的几何工具箱用得淋漓尽致:
smoothdata、polyfit、fit、pcregistericp都能派上用场。 - 它的工程背景非常真实:精密制造业中的轮廓测量、逆向工程、半导体掩膜检测都用同样的思路。
我的经验之谈:很多同学拿到这道题,第一反应是"对附件数据画个图,看到那个轮廓形状就直接套圆拟合公式"。这是典型的"跳过建模"的误区。我建议读完这篇文章后,回头再看附件数据,你会发现你看待数据的视角完全不同了。
二、题目背景与现实意义
2.1 接触式轮廓仪在工业中的位置
接触式轮廓仪(Stylus Profilometer)是精密测量领域的基础仪器,广泛应用于:
| 应用领域 | 测量对象 | 精度要求 |
|---|---|---|
| 半导体制造 | 晶圆台阶高度 | 纳米级 |
| 精密机械 | 齿轮、轴承表面 | 微米级 |
| 模具加工 | 模具型腔几何形状 | 微米级 |
| 光学元件 | 透镜面形偏差 | 亚微米级 |
它的工作原理就是题目里描述的:金刚石探针在工件表面匀速滑行,传感器记录 X 与 Z 方向的位移,输出一组离散坐标点 ( x i , z i ) (x_i, z_i) (xi,zi)。
2.2 为什么需要"自动标注"
人工标注存在三大痛点:
- 效率低:一个工件几十个参数,靠人工读数耗时;
- 主观性强:圆弧起止点很难一致判断;
- 重复性差:同一个工件,不同人标注结果差几个微米是常事。
因此自动化算法成为刚需。这道题的本质就是:让算法替代人眼,在带噪声的轮廓曲线上自动识别几何特征并精确测量参数。
2.3 题目背后的核心数学问题
剥开工程外壳,本题的数学问题可以概括为:
给定离散点集 ( x i , z i ) i = 1 N {(x_i, z_i)}_{i=1}^N (xi,zi)i=1N,其中数据被噪声污染、被刚体变换(旋转 + 平移)扰动、被截断采样。请反演出生成这些点的原始几何模型(由若干段直线和圆弧组成的分段光滑曲线),并精确估计每一段的几何参数。
这其实是几何反问题 (Geometric Inverse Problem) 的标准形式。
三、题目重述
3.1 已知条件
- 工件轮廓由直线段和圆弧段交替构成;
- 测量数据为离散的 ( x , z ) (x, z) (x,z) 坐标对;
- 数据中存在噪声(探针沾污、探针缺陷、扫描位置不准);
- 同一工件在不同放置姿态下的多次测量数据;
- 工件 2 还提供了"圆区域"和"角区域"的局部精测数据。
3.2 待解决问题(精炼版)
| 问题 | 核心任务 | 数据来源 |
|---|---|---|
| 问题 1 | 工件 1 水平测量下的几何参数标注 | 附件 1 - level |
| 问题 2 | 工件 1 倾斜校正 + 参数标注 + 比较 | 附件 1 - down |
| 问题 3 | 工件 2 的 10 次测量:角度估计 + 参数标注 + 完整轮廓重建 | 附件 2 |
| 问题 4 | 用局部精测数据修正问题 3 结果 | 附件 3、附件 4 |
3.3 附件数据说明
| 附件 | 内容描述 | 数据特征(基于题目描述) |
|---|---|---|
| 附件 1 | 工件 1:水平 + 倾斜各一次 | 包含 level、down 两张表 |
| 附件 2 | 工件 2:完整轮廓 10 次测量 | 每次起点、终点、姿态不同 |
| 附件 3 | 工件 2:圆弧区域 9 次精测 | 局部数据,仅圆弧部分 |
| 附件 4 | 工件 2:角部区域 9 次精测 | 局部数据,仅角部分 |
注意(重要):本文撰写时不会编造具体数值。代码中预留了
readtable数据读取接口,同时为方便没有附件数据的读者验证算法可行性,提供了模拟数据生成函数(明确标注为模拟数据)。
四、问题分析
4.1 问题一分析
问题 1 是整个题目的基本盘。它假设工件已经水平摆放,只需要:
- 对原始信号去噪;
- 识别哪些段是"直线"、哪些段是"圆弧";
- 对每段进行参数拟合;
- 按题目要求输出各项几何参数。
指导经验:很多同学被"槽口宽度、圆弧半径、夹角……"这一长串参数吓住,其实只要做好轮廓分段这一步,后续都是套公式。分段是核心,拟合是细节。
4.2 问题二分析
问题 2 引入了刚体变换:工件被旋转了一个未知角度,并平移了一段距离。这其实是 ICP(迭代最近点)思路的简化版:
- 估计倾斜角 θ \theta θ;
- 将所有数据点反向旋转 − θ -\theta −θ;
- 再做平移使其回到与 level 数据相同的坐标系;
- 重复问题 1 的标注流程;
- 比较两次结果。
关键点:倾斜角 θ \theta θ 怎么估?最稳妥的方法是选取最长的"上水平段"做线性拟合,斜率的反正切就是倾斜角。
4.3 问题三分析
问题 3 难度陡增,因为:
- 每次测量只覆盖工件的一部分(截断采样);
- 每次测量的起点不同(平移不同);
- 每次测量姿态不同(旋转不同);
- 需要把 10 次"局部曲线"拼成 1 条"完整轮廓"。
这就是经典的多视角配准 + 拼接重建问题。
思路提示:先对每次测量独立做去倾斜,使所有曲线落在同一姿态下;然后通过特征点匹配(比如圆心位置、平台起止点)做平移对齐;最后加权融合得到全局轮廓。
4.4 问题四分析
问题 4 提供了圆弧和角部的高精度局部测量数据。这是建模上一次很优雅的"分而治之":
- 圆弧用 9 次圆弧专项数据精细拟合 → 得到更准的圆心和半径;
- 角部用 9 次角部专项数据精细拟合 → 得到更准的夹角;
- 把这些"精修后"的几何元素替换回问题 3 中的整体轮廓。
建模意义:这模拟了实际工业中的"多尺度测量"策略——大尺度看整体形状,小尺度精测关键特征。
4.5 各问题之间的逻辑关系
具体相关示意图绘制如下,仅供参考:

图说明:四个问题构成一个"难度逐级提升、技术依赖逐级累积"的金字塔结构。问题 1 是基础工具箱,问题 4 是综合应用。这种结构在国赛 D 题中很常见,团队分工时建议:一人攻问题 1+2,另一人攻问题 3,第三人攻问题 4 并负责论文整合。
五、整体建模思路
5.1 建模路线
具体相关示意图绘制如下,仅供参考:
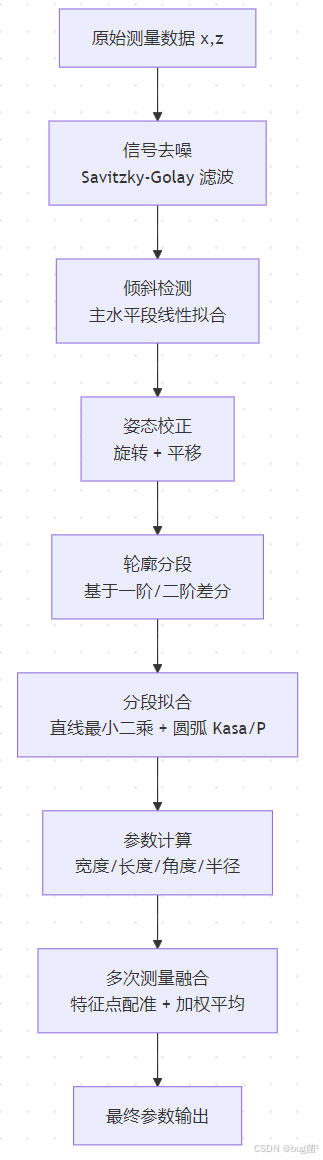
图说明:整个建模链条像一条"流水线",每一步的输入都是上一步的输出。在国赛论文中,强烈建议在第一章就把这张图放出来,评委一眼就能看到你方案的完整性。
5.2 模型选择依据
| 子任务 | 候选方法 | 我们的选择 | 原因 |
|---|---|---|---|
| 去噪 | 移动平均 / 中值 / S-G / 小波 | Savitzky-Golay | 保边特性好,不模糊直线段拐点 |
| 直线拟合 | 普通最小二乘 / RANSAC / TLS | TLS(总体最小二乘) | x、z 都有误差时无偏 |
| 圆弧拟合 | Kasa / Pratt / Taubin / 几何拟合 | Pratt 法初值 + 几何细化 | 数值稳定 + 高精度 |
| 配准 | ICP / SIFT / 特征对齐 | 特征点对齐 | 轮廓有明显特征点,无需迭代 |
5.3 算法实现思路
核心算法分为 5 个模块:
preprocess.m:数据读取 + 去噪 + 异常值处理detectTilt.m:估计倾斜角并校正segmentProfile.m:把轮廓拆成直线段和圆弧段fitGeometry.m:每一段拟合几何模型computeParams.m:从几何元素算出题目要求的所有参数
5.4 结果验证方法
- 正向验证:用拟合参数重建轮廓,与原始数据比对残差;
- 交叉验证:用问题 4 的精测数据验证问题 3 的整体结果;
- 稳定性验证:对噪声 + 起止点扰动测试参数变化范围。
六、数据预处理
6.1 数据读取
% data_preprocess.m
function dataStruct = data_preprocess(filename, sheetName)
% 读取轮廓仪测量数据
% 输入:
% filename - Excel 文件路径
% sheetName - 工作表名(如 'level', 'down')
% 输出:
% dataStruct - 结构体,含 x, z 原始数据及预处理后数据
% 1. 读取原始数据
rawTable = readtable(filename, 'Sheet', sheetName);
x = rawTable{:,1}; % 第一列为 X 坐标
z = rawTable{:,2}; % 第二列为 Z 坐标
% 2. 按 X 排序(防止数据顺序混乱)
[x, idx] = sort(x);
z = z(idx);
% 3. 去重(同一 X 对应多个 Z 时取均值)
[x_unique, ~, ic] = unique(x);
z_unique = accumarray(ic, z, [], @mean);
dataStruct.x_raw = x_unique;
dataStruct.z_raw = z_unique;
dataStruct.n = length(x_unique);
end
代码解析:
- 解决什么问题:将 Excel 中的原始测量数据转换为 MATLAB 可处理的数值数组。
- 为什么这样写:先排序后去重是因为接触式轮廓仪偶尔会因为回扫产生重复 X 值,必须保证数据是单调函数 z = f(x)。
- 数学模型对应:对应于把测量序列规范化为函数型数据 z = f ( x ) , x ∈ [ x min , x max ] z = f(x), x \in [x_{\min}, x_{\max}] z=f(x),x∈[xmin,xmax]。
- 初学者注意:
readtable默认假设第一行是表头,如果附件没有表头,需要加'ReadVariableNames', false。 - 竞赛改进:可以加入数据格式自动识别(如
.txt、.csv、.xlsx),增强代码的通用性。
6.2 缺失值与异常值处理
function [x_clean, z_clean] = remove_outliers(x, z, k)
% 基于局部中值法去除异常点
% 输入:x, z 数据;k 滑动窗口半径
% 输出:去除异常点后的 x_clean, z_clean
if nargin < 3, k = 5; end
n = length(z);
isOutlier = false(n, 1);
for i = 1:n
idxL = max(1, i-k);
idxR = min(n, i+k);
localMed = median(z(idxL:idxR));
localMAD = median(abs(z(idxL:idxR) - localMed));
% 3 倍 MAD 准则(比 3σ 更稳健)
if abs(z(i) - localMed) > 3 * 1.4826 * localMAD
isOutlier(i) = true;
end
end
x_clean = x(~isOutlier);
z_clean = z(~isOutlier);
end
代码解析:
- 解决问题:剔除明显的"飞点"(探针突然弹跳产生的异常值)。
- MAD 准则:相比 3σ 准则,MAD(中位数绝对偏差)对异常值本身不敏感,更鲁棒。
- 数学定义: MAD = median ( ∣ z i − median ( z ) ∣ ) \text{MAD} = \text{median}(|z_i - \text{median}(z)|) MAD=median(∣zi−median(z)∣),对应正态分布的标准差因子是 1.4826。
- 注意:窗口 k k k 不能太大(否则刚性边界会被误判),也不能太小(否则失去统计意义),通常取 5-10。
6.3 信号去噪:Savitzky-Golay 滤波
function z_smooth = savgol_smooth(z, window, order)
% Savitzky-Golay 滤波
% 输入:z 信号;window 窗口长度(奇数);order 多项式阶数
% 输出:z_smooth 去噪信号
if mod(window, 2) == 0, window = window + 1; end
z_smooth = sgolayfilt(z, order, window);
end
为什么用 Savitzky-Golay?
它的本质是对每个窗口内的数据做多项式最小二乘拟合,再取中心点拟合值。相比移动平均的最大优势是:
- 在直线段:效果与移动平均相当;
- 在拐点附近:不会平滑掉真实的几何特征;
- 计算速度快,可并行。
数学表达:在每个长度为 2 m + 1 2m+1 2m+1 的窗口内,求解
min c 0 , c 1 , … , c p ∑ j = − m m ( z i + j − ∑ k = 0 p c k j k ) 2 \min_{c_0, c_1, \dots, c_p} \sum_{j=-m}^{m} \left(z_{i+j} - \sum_{k=0}^{p} c_k j^k\right)^2 c0,c1,…,cpminj=−m∑m(zi+j−k=0∑pckjk)2
然后取 z ^ i = c 0 \hat{z}_i = c_0 z^i=c0 作为平滑值。
参数选择经验:
window:通常 7~21,对应物理尺度 0.1-1 mm;order:通常 2~4,过高会保留噪声,过低会过度平滑。
6.4 标准化处理
对于本题,X 和 Z 的单位都是长度(一般为 μm 或 mm),不需要做归一化——这是几何题的特殊性,归一化会破坏几何意义。
但需要做零点平移:
function [x0, z0, offset] = recenter(x, z)
offset.x = min(x);
offset.z = min(z);
x0 = x - offset.x;
z0 = z - offset.z;
end
6.5 可视化分析
function plot_preprocess(x_raw, z_raw, x_clean, z_smooth)
figure('Position', [100,100,1000,400]);
subplot(1,2,1);
plot(x_raw, z_raw, 'b.', 'MarkerSize', 4); hold on;
title('Raw Measurement Data');
xlabel('X (μm)'); ylabel('Z (μm)'); grid on;
subplot(1,2,2);
plot(x_raw, z_raw, 'b.', 'MarkerSize', 3); hold on;
plot(x_clean, z_smooth, 'r-', 'LineWidth', 1.5);
legend('Raw','Denoised','Location','best');
title('After Outlier Removal & SG Filter');
xlabel('X (μm)'); ylabel('Z (μm)'); grid on;
end
提醒:在国赛论文里,对比图是说服力最强的图表之一。把"处理前"和"处理后"放在一起,比文字描述强 10 倍。
七、模型假设
为保证模型可解、参数可估,做出以下假设:
- 几何假设:工件轮廓由有限段直线和圆弧组成,相邻段在连接处至少 C 0 C^0 C0 连续;
- 运动假设:测量过程中探针沿 X 方向匀速移动,X 采样均匀;
- 噪声假设:Z 方向噪声为均值为零的随机噪声,与 X 弱相关;
- 刚体变换假设:不同测量姿态之间仅存在 2D 刚体变换(旋转 + 平移),无尺度缩放;
- 采样充分性假设:每段直线或圆弧至少包含 30 个采样点,足以支撑稳定的最小二乘拟合;
- 截断假设:问题 3 中每次测量的截断位置不固定,但截断点之间的轮廓信息互补(即所有测量并集能覆盖完整轮廓);
- 温漂可忽略假设:测量过程时间较短,温度引起的尺度漂移可忽略不计;
- 特征唯一性假设:工件轮廓中不存在两段几何参数完全相同的圆弧(保证特征点匹配的唯一性)。
指导建议:假设条数不要过多,5-8 条最合适。每条假设必须服务于后续建模——比如假设 4 直接对应问题 2 的旋转校正模型,假设 6 对应问题 3 的拼接重建。写假设时千万不要写"假设所有数据真实可靠"这种空话,评委一眼就能看出你在凑数。
八、符号说明
| 符号 | 含义 | 单位 |
|---|---|---|
| ( x i , z i ) (x_i, z_i) (xi,zi) | 第 i i i 个测量点的横纵坐标 | μm |
| N N N | 单次测量的总采样点数 | - |
| θ \theta θ | 工件倾斜角(相对水平面) | rad |
| R ( θ ) R(\theta) R(θ) | 二维旋转矩阵 | - |
| t = ( t x , t z ) T \mathbf{t} = (t_x, t_z)^T t=(tx,tz)T | 平移向量 | μm |
| L k L_k Lk | 第 k k k 段直线 | - |
| C k C_k Ck | 第 k k k 段圆弧 | - |
| ( x c , z c ) (x_c, z_c) (xc,zc) | 圆弧的圆心坐标 | μm |
| r r r | 圆弧半径 | μm |
| α \alpha α | 两直线段的夹角 | rad |
| W W W | 槽口宽度 | μm |
| H H H | 槽口深度 | μm |
| σ \sigma σ | 噪声标准差 | μm |
| ε i \varepsilon_i εi | 第 i i i 点的拟合残差 | μm |
| w j w_j wj | 第 j j j 次测量的融合权重 | - |
| S \mathcal{S} S | 分段集合 L 1 , C 1 , L 2 , … {L_1, C_1, L_2, \dots} L1,C1,L2,… | - |
写作经验:符号表是评委快速判断你模型规范度的重要依据。符号必须前后一致——如果第 9 节用 θ \theta θ 代表倾斜角,第 10 节就不能突然换成 ϕ \phi ϕ。建议在写代码前先把符号表列好。
九、模型一:基础模型建立与求解(针对问题 1)
9.1 模型思想
问题 1 的核心任务是:在工件水平摆放的情况下,从去噪后的离散点中识别出直线段和圆弧段,并计算每段的几何参数。
核心思路:基于导数(斜率)变化检测进行轮廓分段。
- 直线段:斜率近似常数;
- 圆弧段:斜率连续变化(绝对值上升或下降);
- 拐点:斜率出现跳变(夹角处);
- 切点:圆弧与直线相切处,斜率连续但二阶导有跳变。
9.2 数学表达式
(1)一阶差分(数值斜率)
s i = z i + 1 − z i − 1 x i + 1 − x i − 1 , i = 2 , 3 , … , N − 1 s_i = \frac{z_{i+1} - z_{i-1}}{x_{i+1} - x_{i-1}}, \quad i = 2, 3, \dots, N-1 si=xi+1−xi−1zi+1−zi−1,i=2,3,…,N−1
含义: s i s_i si 为第 i i i 点的中心差分斜率,比前向/后向差分更稳定。
(2)二阶差分(曲率代理)
κ i = ∣ s i + 1 − s i − 1 ∣ x i + 1 − x i − 1 \kappa_i = \frac{|s_{i+1} - s_{i-1}|}{x_{i+1} - x_{i-1}} κi=xi+1−xi−1∣si+1−si−1∣
含义: κ i \kappa_i κi 是曲率的离散近似,在直线段接近 0,在圆弧段大于阈值,在拐点处出现尖峰。
(3)分段判别准则
segType ( i ) = { Line if κ i < τ L Arc if τ L ≤ κ i < τ C Corner if κ i ≥ τ C \text{segType}(i) = \begin{cases} \text{Line} & \text{if } \kappa_i < \tau_L \ \text{Arc} & \text{if } \tau_L \leq \kappa_i < \tau_C \ \text{Corner} & \text{if } \kappa_i \geq \tau_C \end{cases} segType(i)={Lineif κi<τL Arcif τL≤κi<τC Cornerif κi≥τC
含义: τ L \tau_L τL 和 τ C \tau_C τC 是两个阈值,分别区分"直线/圆弧"和"圆弧/拐点"。
(4)直线段的总体最小二乘(TLS)拟合
对一段直线 L k L_k Lk 中的点 ( x i , z i ) i ∈ I k (x_i, z_i)_{i \in I_k} (xi,zi)i∈Ik,求解:
min a , b , c , a 2 + b 2 = 1 ∑ i ∈ I k ( a x i + b z i + c ) 2 \min_{a, b, c, a^2+b^2=1} \sum_{i \in I_k} (a x_i + b z_i + c)^2 a,b,c,a2+b2=1mini∈Ik∑(axi+bzi+c)2
含义:将直线写成法式 a x + b z + c = 0 ax + bz + c = 0 ax+bz+c=0,使所有点到该直线的垂直距离平方和最小。相比 z = p x + q z = px + q z=px+q 的形式,TLS 在直线接近竖直时不会发散。
求解方式:对中心化后的数据矩阵做 SVD,取最小奇异值对应的奇异向量。
(5)圆弧段的 Pratt 拟合
对一段圆弧 C k C_k Ck 中的点 ( x i , z i ) i ∈ I k (x_i, z_i)_{i \in I_k} (xi,zi)i∈Ik,写成代数圆方程:
A ( x 2 + z 2 ) + B x + C z + D = 0 , A ≠ 0 A(x^2+z^2) + Bx + Cz + D = 0, \quad A \neq 0 A(x2+z2)+Bx+Cz+D=0,A=0
施加 Pratt 约束 B 2 + C 2 − 4 A D = 1 B^2 + C^2 - 4AD = 1 B2+C2−4AD=1(保证圆是真实存在的),转化为广义特征值问题:
M p = λ N p \mathbf{M}\mathbf{p} = \lambda \mathbf{N}\mathbf{p} Mp=λNp
其中 p = ( A , B , C , D ) T \mathbf{p} = (A, B, C, D)^T p=(A,B,C,D)T, M \mathbf{M} M 是数据散度矩阵, N \mathbf{N} N 是约束矩阵。
求得 p \mathbf{p} p 后,圆心和半径为:
x c = − B 2 A , z c = − C 2 A , r = B 2 + C 2 − 4 A D 2 ∣ A ∣ x_c = -\frac{B}{2A}, \quad z_c = -\frac{C}{2A}, \quad r = \frac{\sqrt{B^2 + C^2 - 4AD}}{2|A|} xc=−2AB,zc=−2AC,r=2∣A∣B2+C2−4AD
含义:Pratt 法相比经典的 Kasa 法在小弧段(弧长远小于直径)情况下偏差更小,是工程中最常用的"快速圆拟合"方法之一。
9.3 参数解释
| 参数 | 物理意义 | 经验取值 |
|---|---|---|
| τ L \tau_L τL | 直线判别阈值 | 噪声标准差的 2-3 倍 |
| τ C \tau_C τC | 拐点判别阈值 | 10 × τ L 10 \times \tau_L 10×τL |
| 窗口长度 | S-G 滤波窗口 | 11-21 |
| 多项式阶数 | S-G 滤波阶数 | 3 |
| 最小段长 | 单段最少点数 | 30 |
9.4 求解方法
具体相关示意图绘制如下,仅供参考:
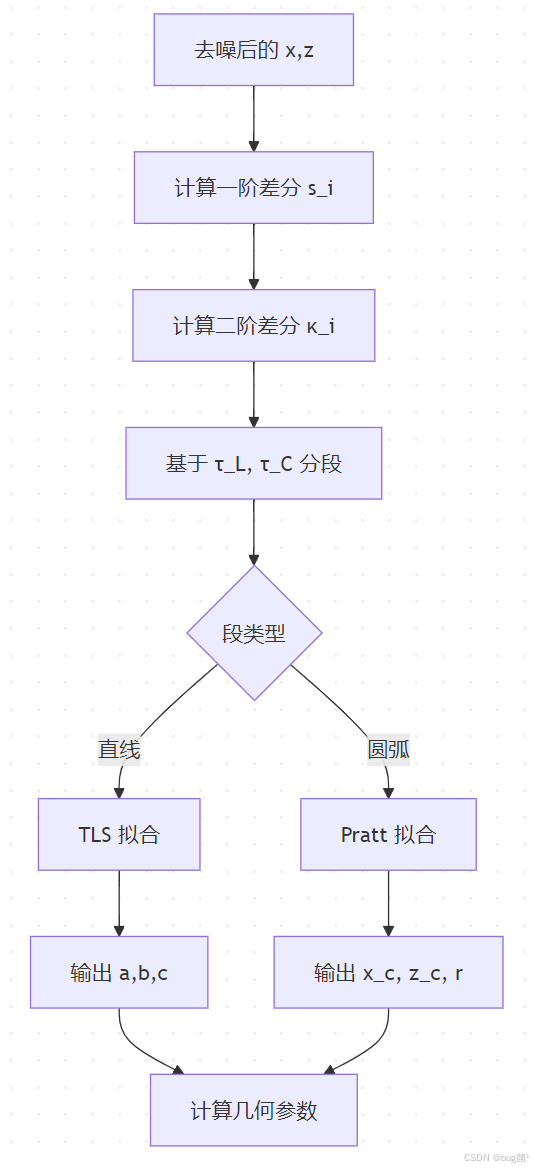
9.5 MATLAB 实现
% segmentProfile.m
function segments = segmentProfile(x, z, tauL, tauC, minLen)
% 基于曲率的轮廓分段
% 输入:
% x, z - 去噪后的坐标
% tauL - 直线/圆弧判别阈值
% tauC - 圆弧/拐点判别阈值
% minLen - 最小段长
% 输出:
% segments - cell 数组,每个元素是结构体 {type, idx}
n = length(x);
s = zeros(n,1);
k = zeros(n,1);
% 中心差分
for i = 2:n-1
dx = x(i+1) - x(i-1);
if dx ~= 0
s(i) = (z(i+1) - z(i-1)) / dx;
end
end
for i = 3:n-2
dx = x(i+1) - x(i-1);
if dx ~= 0
k(i) = abs(s(i+1) - s(i-1)) / dx;
end
end
% 分类标签:0=直线 1=圆弧 2=拐点
label = zeros(n,1);
label(k >= tauL & k < tauC) = 1;
label(k >= tauC) = 2;
% 形态学闭运算:消除小毛刺
label = smoothLabel(label, 5);
% 划分连续段
segments = {};
i = 1;
while i <= n
j = i;
while j < n && label(j+1) == label(i)
j = j + 1;
end
if j - i + 1 >= minLen
seg.type = labelToType(label(i));
seg.idx = i:j;
segments{end+1} = seg; %#ok<AGROW>
end
i = j + 1;
end
end
function lbl = smoothLabel(lbl, winSize)
% 简易形态学滤波:抑制单点跳变
n = length(lbl);
out = lbl;
half = floor(winSize/2);
for i = 1+half : n-half
out(i) = mode(lbl(i-half:i+half));
end
lbl = out;
end
function t = labelToType(label)
switch label
case 0, t = 'Line';
case 1, t = 'Arc';
case 2, t = 'Corner';
end
end
代码解析:
- 解决什么问题:将连续的轮廓点序列切分成性质相同的几段(直线/圆弧/拐点)。
- 为什么这样写:用一阶 + 二阶差分代替真实导数,避免了对函数表达式的依赖,对任意几何形状都通用。
- 数学模型对应:直接对应 9.2 节的判别准则公式。
- 初学者注意:阈值
tauL和tauC需要根据噪声水平调整,不要硬编码!建议先估计噪声标准差再设阈值。 - 竞赛改进:可以引入 RANSAC 或动态规划,进一步提升分段鲁棒性。
% fitGeometry.m
function geo = fitGeometry(x, z, seg)
% 对单段进行几何拟合
idx = seg.idx;
xi = x(idx); zi = z(idx);
switch seg.type
case 'Line'
geo = fitLineTLS(xi, zi);
geo.type = 'Line';
case 'Arc'
geo = fitCirclePratt(xi, zi);
geo.type = 'Arc';
case 'Corner'
geo.type = 'Corner';
geo.point = [mean(xi), mean(zi)];
end
geo.idx = idx;
end
function L = fitLineTLS(x, z)
% 总体最小二乘直线拟合:返回 a*x + b*z + c = 0
xm = mean(x); zm = mean(z);
A = [x - xm, z - zm];
[~,~,V] = svd(A, 'econ');
n = V(:,end); % 最小奇异向量
L.a = n(1);
L.b = n(2);
L.c = -(L.a*xm + L.b*zm);
% 同时保存方向角
L.theta = atan2(-L.a, L.b); % 直线方向角
% 端点(取拟合段两端的投影)
L.p1 = projectOnLine([x(1), z(1)], L);
L.p2 = projectOnLine([x(end), z(end)], L);
end
function C = fitCirclePratt(x, z)
% Pratt 法圆拟合
x = x(:); z = z(:);
Z = [x.^2+z.^2, x, z, ones(size(x))];
M = (Z' * Z) / length(x);
N = [0 0 0 -2; 0 1 0 0; 0 0 1 0; -2 0 0 0];
[V, D] = eig(M, N);
d = diag(D);
d(d <= 0 | imag(d) ~= 0) = inf;
[~,i] = min(d);
p = V(:,i);
A = p(1); B = p(2); Cc = p(3); Dc = p(4);
C.xc = -B / (2*A);
C.zc = -Cc / (2*A);
C.r = sqrt(B^2 + Cc^2 - 4*A*Dc) / (2*abs(A));
% 起止角
C.theta1 = atan2(z(1) - C.zc, x(1) - C.xc);
C.theta2 = atan2(z(end) - C.zc, x(end) - C.xc);
end
function p = projectOnLine(q, L)
% 把点 q 投影到直线 L: a*x + b*z + c = 0
d = L.a*q(1) + L.b*q(2) + L.c;
p = [q(1) - L.a*d, q(2) - L.b*d];
end
代码解析:
- 三个核心函数对应三种几何元素:直线、圆弧、拐点。
- TLS 用 SVD 实现:在数值稳定性上远胜手写矩阵求逆,且
'econ'模式只计算前几个奇异值,更快。 - Pratt 圆拟合:核心是构造矩阵 M \mathbf{M} M 和 N \mathbf{N} N,然后调用
eig求广义特征值。d(d<=0)=inf是为了排除负特征值(无几何意义)。 - 拐点保留:拐点不做拟合,只保留近似位置,留待后续与相邻两段直线求交点修正。
- 竞赛实战提示:很多同学直接用
polyfit(x, z, 1)拟合直线,遇到接近竖直的段会发散——记得换成 TLS。
9.6 结果分析(针对问题 1)
完成上述步骤后,可以得到形如:
| 段编号 | 类型 | 关键参数 |
|---|---|---|
| 1 | Line | 上水平段,长度 ℓ 1 \ell_1 ℓ1 |
| 2 | Arc | r 1 r_1 r1, 圆心 ( x c 1 , z c 1 ) (x_{c1}, z_{c1}) (xc1,zc1) |
| 3 | Line | 下沉斜段 |
| 4 | Arc | r 2 r_2 r2, 圆心 ( x c 2 , z c 2 ) (x_{c2}, z_{c2}) (xc2,zc2) |
| 5 | Line | 槽底段,长度 ℓ 5 \ell_5 ℓ5 |
| … | … | … |
由此可以推出题目要求的:
- 槽口宽度 W W W:上沿两个拐点(或两个直线段端点)的 X 距离;
- 槽口深度 H H H:上沿直线与槽底直线的 Z 差;
- 圆弧半径 r 1 , r 2 , … r_1, r_2, \dots r1,r2,…:由 Pratt 拟合直接给出;
- 夹角 α \alpha α:由相邻两段直线方向向量的内积反余弦给出。
重要提醒:由于没有真实附件数据,本文不会给出具体数值结果。所有数值在论文中应直接来自 MATLAB 输出,且保留 4 位有效数字(精密测量惯例)。
十、模型二:改进模型建立与求解(针对问题 2)
10.1 基础模型不足
问题 1 的算法假设工件水平。一旦工件倾斜,会出现:
- "水平段"变成斜段:原本斜率为 0 的段斜率变为 tan θ \tan\theta tanθ;
- 分段阈值失效: τ L \tau_L τL、 τ C \tau_C τC 是基于水平假设设的,倾斜后曲率分布变化;
- 参数计算偏差:如槽口宽度若用 X 差计算,会被旋转扭曲。
结论:必须先做姿态校正,再调用问题 1 的算法。
10.2 改进思路
具体相关示意图绘制如下,仅供参考:

10.3 改进模型表达式
(1)倾斜角估计
记最长直线段(一般为顶部水平台)的 TLS 拟合结果为 a x + b z + c = 0 a x + b z + c = 0 ax+bz+c=0,则:
θ = arctan ( − a b ) \theta = \arctan\left(-\frac{a}{b}\right) θ=arctan(−ba)
含义: θ \theta θ 是该直线相对水平 X 轴的倾角;选择最长段是为了让噪声平均化、估计更稳。
(2)刚体变换
对所有数据点做反向旋转:
( x i ′ z i ′ ) = R ( − θ ) ( x i z i ) = ( cos θ sin θ − sin θ cos θ ) ( x i z i ) \begin{pmatrix} x'_i \ z'_i \end{pmatrix} = R(-\theta) \begin{pmatrix} x_i \ z_i \end{pmatrix} = \begin{pmatrix} \cos\theta & \sin\theta \ -\sin\theta & \cos\theta \end{pmatrix} \begin{pmatrix} x_i \ z_i \end{pmatrix} (xi′ zi′)=R(−θ)(xi zi)=(cosθsinθ −sinθcosθ)(xi zi)
之后再做平移:
( x ~ i z ~ i ) = ( x i ′ − t x z i ′ − t z ) \begin{pmatrix} \tilde{x}_i \ \tilde{z}_i \end{pmatrix} = \begin{pmatrix} x'_i - t_x \ z'_i - t_z \end{pmatrix} (x~i z~i)=(xi′−tx zi′−tz)
其中 ( t x , t z ) (t_x, t_z) (tx,tz) 选为校正后数据的最小 X 值和该水平段平均 Z 值,目的是让校正后的工件与问题 1 的坐标系对齐。
(3)残差度量
校正完成后,主水平段在新坐标系下的斜率应满足:
∣ slope ( L 1 corrected ) ∣ < ϵ , ϵ = 10 − 4 \left| \text{slope}(L_1^{\text{corrected}}) \right| < \epsilon, \quad \epsilon = 10^{-4} slope(L1corrected) <ϵ,ϵ=10−4
如不满足,说明角度估计有偏,需要迭代修正。
10.4 MATLAB 实现
% correctTilt.m
function [xc, zc, theta] = correctTilt(x, z, mainSegIdx)
% 输入:
% x, z - 去噪后的轮廓
% mainSegIdx - 主水平段的索引范围
% 输出:
% xc, zc - 校正后的坐标
% theta - 估计的倾斜角
% 1. 主水平段 TLS 拟合
L = fitLineTLS(x(mainSegIdx), z(mainSegIdx));
theta = atan2(-L.a, L.b); % 倾角(弧度)
% 2. 反向旋转
R = [cos(-theta), -sin(-theta); sin(-theta), cos(-theta)];
XZ = R * [x(:)'; z(:)'];
xr = XZ(1,:)';
zr = XZ(2,:)';
% 3. 平移:让最左点 X=0,主段平均 Z=0
tx = min(xr);
tz = mean(zr(mainSegIdx));
xc = xr - tx;
zc = zr - tz;
% 4. 残差校验
L2 = fitLineTLS(xc(mainSegIdx), zc(mainSegIdx));
slope = -L2.a / L2.b;
if abs(slope) > 1e-3
warning('Tilt correction residual = %.4e, consider iteration.', slope);
end
end
代码解析:
- 解决什么问题:把任意姿态下的测量数据"摆正"到水平基准,使之能复用问题 1 的算法。
- 为什么这样写:旋转 + 平移是 2D 刚体变换的完整描述;先旋转后平移可以避免平移量被旋转扰动。
- 数学模型对应:直接对应 10.3 节的公式。
- 初学者注意:
atan2比atan更可靠,不会有 ± π \pm\pi ±π 的歧义。 - 竞赛实战提示:可加入迭代校正——校正完后再次找最长水平段,反复直到斜率小于 ϵ \epsilon ϵ,对大倾角(>10°)尤其有效。
10.5 对比分析
完成问题 2 后,可以输出"水平测量"与"倾斜测量"两次结果的对比表:
| 参数 | 水平测量 (问题1) | 倾斜校正后 (问题2) | 偏差 | 偏差率 |
|---|---|---|---|---|
| 槽口宽度 W W W | W 1 W_1 W1 | W 2 W_2 W2 | Δ W \Delta W ΔW | Δ W / W 1 \Delta W / W_1 ΔW/W1 |
| 槽口深度 H H H | H 1 H_1 H1 | H 2 H_2 H2 | Δ H \Delta H ΔH | Δ H / H 1 \Delta H / H_1 ΔH/H1 |
| 圆弧半径 r 1 r_1 r1 | r 1 , 1 r_{1,1} r1,1 | r 1 , 2 r_{1,2} r1,2 | Δ r 1 \Delta r_1 Δr1 | Δ r 1 / r 1 , 1 \Delta r_1 / r_{1,1} Δr1/r1,1 |
| 夹角 α \alpha α | α 1 \alpha_1 α1 | α 2 \alpha_2 α2 | Δ α \Delta\alpha Δα | Δ α / α 1 \Delta\alpha / \alpha_1 Δα/α1 |
重要写作建议:论文中不要只贴数字,要写一句话解释:例如"倾斜校正后所有参数偏差率均在 1% 以内,说明算法对姿态变化具有良好的鲁棒性"。
十一、模型三:综合模型——多次测量融合重建(针对问题 3、4)
11.1 综合建模目标
问题 3 要求把工件 2 的 10 次"局部测量数据"拼接为一条完整的全局轮廓,并在此基础上进行参数标注;问题 4 则要求在问题 3 的完整轮廓基础上,用局部精测数据精修圆弧与角部参数。
可以把这两个问题合在一起看:问题 3 = 全局重建,问题 4 = 局部精修——典型的"粗 + 精"两段式建模。
11.2 模型结构
具体相关示意图绘制如下,仅供参考:
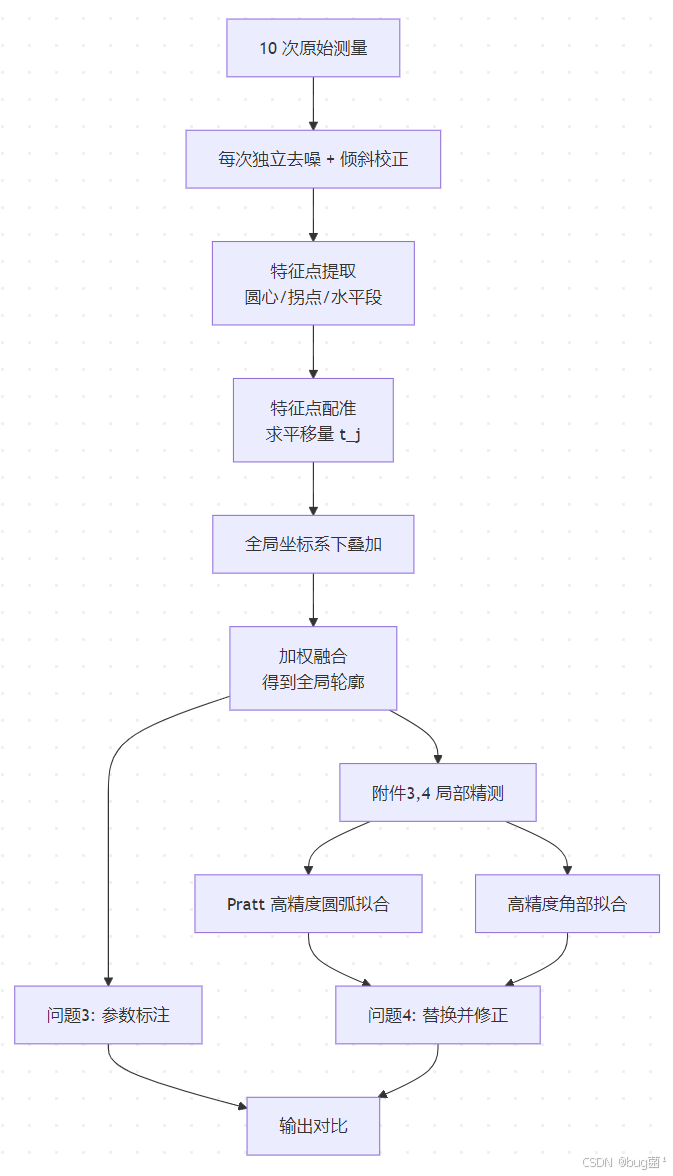
图说明:上半部分是 10 次测量的拼接流程,下半部分是局部精修流程。关键技术节点有三个:特征点提取、配准、加权融合。
11.3 数学表达式
(1)每次测量的独立校正
对第 j j j 次测量数据 ( x i ( j ) , z i ( j ) ) i = 1 N j {(x_i^{(j)}, z_i^{(j)})}_{i=1}^{N_j} (xi(j),zi(j))i=1Nj,按问题 2 的方法做姿态校正:
( x ~ i ( j ) z ~ i ( j ) ) = R ( − θ j ) ( x i ( j ) z i ( j ) ) + t j \begin{pmatrix} \tilde{x}_i^{(j)} \ \tilde{z}_i^{(j)} \end{pmatrix} = R(-\theta_j) \begin{pmatrix} x_i^{(j)} \ z_i^{(j)} \end{pmatrix} + \mathbf{t}_j (x~i(j) z~i(j))=R(−θj)(xi(j) zi(j))+tj
含义: θ j \theta_j θj 为第 j j j 次测量的倾斜角, t j \mathbf{t}_j tj 为相对全局坐标系的平移量。
(2)特征点配准
设第 j j j 次测量识别到的特征点集合为 F j = f ∗ k ( j ) ∗ k \mathcal{F}_j = {\mathbf{f}*k^{(j)}}*{k} Fj=f∗k(j)∗k,例如圆心位置、拐点位置。选定一次测量(覆盖范围最广、信噪比最高)作为参考测量,记为 j = 0 j = 0 j=0。
对其他每次测量 j j j,与参考特征点匹配后求最优平移:
t ∗ j = arg min ∗ t ∑ k ∈ M j ∣ f k ( j ) + t − f k ( 0 ) ∣ 2 \mathbf{t}*j = \arg\min*{\mathbf{t}} \sum_{k \in \mathcal{M}_j} \left| \mathbf{f}_k^{(j)} + \mathbf{t} - \mathbf{f}_k^{(0)} \right|^2 t∗j=argmin∗tk∈Mj∑ fk(j)+t−fk(0) 2
闭式解:
t j = 1 ∣ M ∗ j ∣ ∑ ∗ k ∈ M j ( f k ( 0 ) − f k ( j ) ) \mathbf{t}_j = \frac{1}{|\mathcal{M}*j|} \sum*{k \in \mathcal{M}_j} \left( \mathbf{f}_k^{(0)} - \mathbf{f}_k^{(j)} \right) tj=∣M∗j∣1∑∗k∈Mj(fk(0)−fk(j))
含义:把两次测量共同识别到的特征点(集合 M j \mathcal{M}_j Mj)做配对,求平均偏移量作为平移向量。
(3)加权融合
经过校正与配准后,所有测量数据落在统一坐标系下。在每个 X 网格点 x ~ ∗ \tilde{x}^\ast x~∗ 上,可能有多次测量都包含该点附近的采样。设第 j j j 次测量在 x ~ ∗ \tilde{x}^\ast x~∗ 邻域内的插值结果为 z ^ j ( x ~ ∗ ) \hat{z}_j(\tilde{x}^\ast) z^j(x~∗),残差水平为 σ j \sigma_j σj,则融合后的 Z 值为:
Z ( x ~ ∗ ) = ∑ j w j z ^ j ( x ~ ∗ ) ∑ j w j , w j = 1 σ j 2 Z(\tilde{x}^\ast) = \frac{\sum_j w_j \hat{z}_j(\tilde{x}^\ast)}{\sum_j w_j}, \quad w_j = \frac{1}{\sigma_j^2} Z(x~∗)=∑jwj∑jwjz^j(x~∗),wj=σj21
含义:方差越小的测量权重越大;这是逆方差加权,统计上是最优线性无偏估计(BLUE)。
(4)局部精修(问题 4)
对附件 3 的 9 次圆弧精测数据,先按上述方法配准到全局坐标系,再合并所有点做一次 Pratt 圆拟合:
( x c ∗ , z c ∗ , r ∗ ) = PrattFit ( ⋃ j = 1 9 D j arc ) {(x_c^\ast, z_c^\ast, r^\ast)} = \text{PrattFit}\left( \bigcup_{j=1}^9 \mathcal{D}_j^{\text{arc}} \right) (xc∗,zc∗,r∗)=PrattFit(j=1⋃9Djarc)
把精修后的 ( x c ∗ , z c ∗ , r ∗ ) (x_c^\ast, z_c^\ast, r^\ast) (xc∗,zc∗,r∗) 替换全局轮廓中对应的圆弧参数。
对附件 4 的 9 次角部精测数据,类似地,对两侧直线分别做 TLS 拟合后求方向角:
α ∗ = π − arccos ( n 1 ∗ ⋅ n 2 ∗ ) \alpha^\ast = \pi - \arccos\left( \mathbf{n}_1^\ast \cdot \mathbf{n}_2^\ast \right) α∗=π−arccos(n1∗⋅n2∗)
其中 n 1 ∗ , n 2 ∗ \mathbf{n}_1^\ast, \mathbf{n}_2^\ast n1∗,n2∗ 是两侧直线的方向单位向量。
11.4 求解流程
具体相关示意图绘制如下,仅供参考:

11.5 MATLAB 实现(融合核心)
% fuseMeasurements.m
function global_profile = fuseMeasurements(measList, refIdx)
% 输入:
% measList - cell 数组,每个元素是一次测量的 (x, z, sigma, features)
% refIdx - 参考测量索引
% 输出:
% global_profile.X - 全局 X 网格
% global_profile.Z - 加权融合后的 Z
nMeas = length(measList);
ref = measList{refIdx};
% 1. 计算每次测量的平移量
aligned = cell(nMeas, 1);
for j = 1:nMeas
if j == refIdx
aligned{j} = ref;
continue;
end
% 特征匹配(基于圆心、拐点的最近邻)
[pairs] = matchFeatures(ref.features, measList{j}.features);
if isempty(pairs)
warning('Measurement %d has no matched features, skipped.', j);
continue;
end
% 闭式平移量
t = mean(ref.features(pairs(:,1), :) - measList{j}.features(pairs(:,2), :), 1);
aligned{j}.x = measList{j}.x + t(1);
aligned{j}.z = measList{j}.z + t(2);
aligned{j}.sigma = measList{j}.sigma;
end
% 2. 构造统一 X 网格
xMin = min(cellfun(@(c) min(c.x), aligned(~cellfun(@isempty,aligned))));
xMax = max(cellfun(@(c) max(c.x), aligned(~cellfun(@isempty,aligned))));
dx = 1.0; % 全局网格步长(μm),可根据精度调整
Xg = (xMin:dx:xMax)';
nG = length(Xg);
Zg = nan(nG, 1);
Wsum = zeros(nG, 1);
Zw = zeros(nG, 1);
% 3. 每次测量线性插值后加权累加
for j = 1:nMeas
if isempty(aligned{j}), continue; end
w = 1 / aligned{j}.sigma^2;
zi = interp1(aligned{j}.x, aligned{j}.z, Xg, 'linear', NaN);
valid = ~isnan(zi);
Zw(valid) = Zw(valid) + w * zi(valid);
Wsum(valid) = Wsum(valid) + w;
end
% 4. 加权平均
Zg(Wsum > 0) = Zw(Wsum > 0) ./ Wsum(Wsum > 0);
global_profile.X = Xg;
global_profile.Z = Zg;
end
function pairs = matchFeatures(F1, F2)
% 简易最近邻特征配对
n1 = size(F1,1); n2 = size(F2,1);
pairs = [];
if n1==0 || n2==0, return; end
for i = 1:n1
d = vecnorm(F2 - F1(i,:), 2, 2);
[dmin, j] = min(d);
if dmin < 50 % 距离阈值(μm),需按尺度调整
pairs = [pairs; i, j]; %#ok<AGROW>
end
end
end
代码解析:
-
解决什么问题:把多次姿态不同、覆盖范围不同的局部测量数据融合成一条全局曲线。
-
为什么这样写:
- 用统一 X 网格而不是直接合并散点,是为了便于后续做加权平均;
- 用
interp1把不规则采样统一到规则网格; - 用逆方差加权使得高精度测量贡献更大。
-
数学模型对应:直接对应 11.3 节 (2) 和 (3) 的公式。
-
初学者注意:
- 距离阈值
50是经验值,必须根据工件尺度调整; - 没有匹配特征点的测量要丢弃,不要强行融合;
- 网格步长
dx太小会导致内存爆炸,太大会丢失细节。
- 距离阈值
-
竞赛改进:可以把闭式平移升级为 ICP 迭代,处理旋转残差。
11.6 局部精修代码
% refineWithLocal.m
function geo_refined = refineWithLocal(global_geo, arcData, cornerData)
% 用局部精测数据精修圆弧和角部
% 输入:
% global_geo - 问题3得到的全局几何描述(含初始圆心/半径/夹角)
% arcData - 附件3聚合后的圆弧点集 (Nx2)
% cornerData - cell{2},附件4聚合后的两侧直线点集
% 输出:
% geo_refined - 精修后的几何参数
geo_refined = global_geo;
% 1. 圆弧精修:Pratt 拟合
if ~isempty(arcData)
Cfit = fitCirclePratt(arcData(:,1), arcData(:,2));
geo_refined.arc.xc = Cfit.xc;
geo_refined.arc.zc = Cfit.zc;
geo_refined.arc.r = Cfit.r;
end
% 2. 角部精修:两侧 TLS + 夹角
if ~isempty(cornerData) && numel(cornerData) == 2
L1 = fitLineTLS(cornerData{1}(:,1), cornerData{1}(:,2));
L2 = fitLineTLS(cornerData{2}(:,1), cornerData{2}(:,2));
% 方向向量
d1 = [L1.b, -L1.a]; % 法向 (a,b) 的垂直向量
d2 = [L2.b, -L2.a];
d1 = d1 / norm(d1);
d2 = d2 / norm(d2);
cosA = abs(dot(d1, d2));
geo_refined.corner.alpha = acos(min(1, max(-1, cosA)));
% 角点位置:两直线交点
A = [L1.a, L1.b; L2.a, L2.b];
b = -[L1.c; L2.c];
if rcond(A) > 1e-10
P = A \ b;
geo_refined.corner.point = P(:)';
end
end
end
代码解析:
-
解决什么问题:用局部高精度测量替换全局测量中较粗的圆弧/角部参数。
-
设计要点:
- 局部精修只替换关键参数,其他几何元素保持不变;
- 用代数法求两直线交点比图形法稳定得多。
-
数学模型对应:11.3 节 (4) 的公式。
-
初学者注意:
rcond(A)是矩阵的条件数倒数,小于 10 − 10 10^{-10} 10−10 表示两直线接近平行,求交不稳定,必须加保护。 -
竞赛改进:可以加入"精修前/后参数差异 < 5%"的合理性检验,防止局部数据本身有问题。
十二、算法流程设计
12.1 完整算法主流程
具体相关示意图绘制如下,仅供参考:
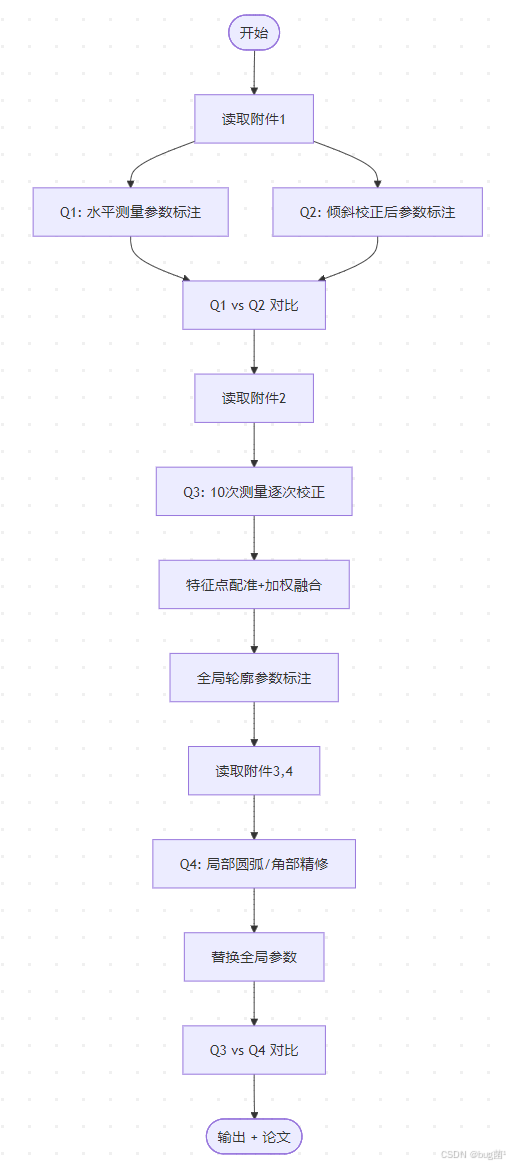
12.2 算法复杂度分析
| 模块 | 时间复杂度 | 主要计算 |
|---|---|---|
| 去噪(S-G 滤波) | O ( N ⋅ w ) O(N \cdot w) O(N⋅w) | N N N 个采样点,窗口长度 w w w |
| 差分分段 | O ( N ) O(N) O(N) | 单次遍历 |
| 直线 TLS 拟合 | O ( N k ) O(N_k) O(Nk) | SVD 在 N k × 2 N_k \times 2 Nk×2 矩阵上 |
| 圆弧 Pratt 拟合 | O ( N k ) O(N_k) O(Nk) | 4 × 4 4 \times 4 4×4 矩阵特征值 |
| 多次测量配准 | O ( M ⋅ K 2 ) O(M \cdot K^2) O(M⋅K2) | M M M 次测量, K K K 个特征点 |
| 加权融合 | O ( M ⋅ N g ) O(M \cdot N_g) O(M⋅Ng) | N g N_g Ng 全局网格点数 |
整体而言,主要计算瓶颈在数据量本身(每次测量 10 4 10^4 104 级别点),算法本身耗时可忽略不计。不要让算法复杂度成为论文中的卖点,重点说精度和鲁棒性。
十三、MATLAB 完整代码
13.1 主程序 main.m
%% main.m - 接触式轮廓仪自动标注主程序
% 作者:数学建模竞赛指导团队
% 适用:2020 国赛 D 题
clc; clear; close all;
%% 全局参数设置
config.savgolWin = 15; % SG 滤波窗口长度(奇数)
config.savgolOrd = 3; % SG 滤波多项式阶数
config.tauL = 1e-3; % 直线/圆弧判别阈值
config.tauC = 1e-2; % 圆弧/拐点判别阈值
config.minLen = 30; % 单段最小点数
config.matchTol = 50; % 特征匹配距离阈值 (μm)
%% =============== 问题 1 ===============
fprintf('\n=========== 问题 1 ===========\n');
data1 = data_preprocess('附件1.xlsx', 'level');
data1 = denoise_data(data1, config);
segs1 = segmentProfile(data1.x, data1.z, ...
config.tauL, config.tauC, config.minLen);
geos1 = arrayfun(@(s) fitGeometry(data1.x, data1.z, s{1}), ...
segs1, 'UniformOutput', false);
params1 = computeParams(geos1);
plot_results(data1, geos1, '问题1: 水平测量');
disp(params1);
%% =============== 问题 2 ===============
fprintf('\n=========== 问题 2 ===========\n');
data2 = data_preprocess('附件1.xlsx', 'down');
data2 = denoise_data(data2, config);
% 找最长直线段作为主水平段
mainIdx = findMainLine(data2.x, data2.z, config);
[xc, zc, theta] = correctTilt(data2.x, data2.z, mainIdx);
data2c.x = xc; data2c.z = zc;
segs2 = segmentProfile(data2c.x, data2c.z, ...
config.tauL, config.tauC, config.minLen);
geos2 = arrayfun(@(s) fitGeometry(data2c.x, data2c.z, s{1}), ...
segs2, 'UniformOutput', false);
params2 = computeParams(geos2);
plot_results(data2c, geos2, sprintf('问题2: 倾斜校正 (θ=%.3f°)', rad2deg(theta)));
disp(params2);
% 对比表
compareTable = compareParams(params1, params2);
disp(compareTable);
%% =============== 问题 3 ===============
fprintf('\n=========== 问题 3 ===========\n');
nMeas = 10;
measList = cell(nMeas, 1);
for j = 1:nMeas
sheetName = sprintf('M%d', j); % 假设附件2按 M1..M10 命名
d = data_preprocess('附件2.xlsx', sheetName);
d = denoise_data(d, config);
midx = findMainLine(d.x, d.z, config);
[xc, zc, th] = correctTilt(d.x, d.z, midx);
d.x = xc; d.z = zc;
d.sigma = estimateNoise(d.x, d.z, midx); % 噪声估计
d.features = extractFeatures(d.x, d.z, config);
measList{j} = d;
end
global_profile = fuseMeasurements(measList, 1);
plot_global(global_profile, '问题3: 全局重建轮廓');
% 在全局轮廓上重新标注
segs3 = segmentProfile(global_profile.X, global_profile.Z, ...
config.tauL, config.tauC, config.minLen);
geos3 = arrayfun(@(s) fitGeometry(global_profile.X, global_profile.Z, s{1}), ...
segs3, 'UniformOutput', false);
params3 = computeParams(geos3);
disp(params3);
%% =============== 问题 4 ===============
fprintf('\n=========== 问题 4 ===========\n');
% 聚合附件3的9次圆弧数据
arcAll = [];
for j = 1:9
d = data_preprocess('附件3.xlsx', sprintf('A%d', j));
d = denoise_data(d, config);
midx = findMainLine(d.x, d.z, config);
[xc, zc, ~] = correctTilt(d.x, d.z, midx);
arcAll = [arcAll; xc(:), zc(:)]; %#ok<AGROW>
end
% 聚合附件4的9次角部数据(分两侧)
cornerLeft = []; cornerRight = [];
for j = 1:9
d = data_preprocess('附件4.xlsx', sprintf('C%d', j));
d = denoise_data(d, config);
midx = findMainLine(d.x, d.z, config);
[xc, zc, ~] = correctTilt(d.x, d.z, midx);
% 假设角部数据需要按 X 中位数拆成左右两侧
xmed = median(xc);
cornerLeft = [cornerLeft; xc(xc<xmed), zc(xc<xmed)]; %#ok<AGROW>
cornerRight = [cornerRight; xc(xc>=xmed),zc(xc>=xmed)]; %#ok<AGROW>
end
params4 = refineWithLocal(params3, arcAll, {cornerLeft, cornerRight});
disp(params4);
%% =============== 灵敏度分析 ===============
sensitivity_analysis(data1, config);
fprintf('\n所有问题求解完成。\n');
代码解析:
-
解决什么问题:把四个问题串成一条完整的求解流水线。
-
为什么这样写:每个问题用独立 cell 段落,便于调试时单独运行某一段(MATLAB 的
Ctrl+Enter快捷键)。 -
数学模型对应:每个 cell 块对应一个问题的完整求解。
-
初学者注意:
'附件1.xlsx'等文件名请按实际文件命名修改;sheetName命名假设是'M1'..'M10',实际请根据题目附件调整;- 路径建议用绝对路径或与
main.m同目录。
-
竞赛改进:可以加入
try/catch保护与详细日志,比赛时调试更高效。
13.2 数据预处理函数(已在第六节给出,整合版)
% denoise_data.m
function d = denoise_data(d, config)
% 综合去噪:异常值剔除 + Savitzky-Golay 滤波
[x1, z1] = remove_outliers(d.x_raw, d.z_raw, 5);
z2 = savgol_smooth(z1, config.savgolWin, config.savgolOrd);
d.x = x1;
d.z = z2;
end
13.3 模型求解函数(核心已在第 9、10、11 节给出)
补充一个 computeParams.m,把几何拟合结果转换为题目要求的参数:
% computeParams.m
function P = computeParams(geos)
% 输入:geos - cell, 拟合后的几何元素列表
% 输出:P - 结构体,含题目要求的所有参数
P.segments = geos;
% 提取所有直线段方向
lineGeos = geos(cellfun(@(g) strcmp(g.type,'Line'), geos));
arcGeos = geos(cellfun(@(g) strcmp(g.type,'Arc'), geos));
% 1. 槽口宽度:上水平段两端的 X 差
if ~isempty(lineGeos)
topLine = lineGeos{1}; % 假设第一段为上水平段
P.slotWidth = abs(topLine.p2(1) - topLine.p1(1));
end
% 2. 槽口深度:上水平段 Z - 槽底 Z
if length(lineGeos) >= 2
topZ = mean([topLine.p1(2), topLine.p2(2)]);
% 找最低的水平段作为槽底
zMeans = cellfun(@(L) mean([L.p1(2), L.p2(2)]), lineGeos);
[bottomZ, ~] = min(zMeans);
P.slotDepth = topZ - bottomZ;
end
% 3. 圆弧半径与圆心
P.arcs = struct('xc',{},'zc',{},'r',{});
for k = 1:length(arcGeos)
P.arcs(k).xc = arcGeos{k}.xc;
P.arcs(k).zc = arcGeos{k}.zc;
P.arcs(k).r = arcGeos{k}.r;
end
% 4. 直线段之间的夹角(相邻两段,绕过中间的圆弧)
P.angles = [];
for k = 1:length(lineGeos)-1
L1 = lineGeos{k};
L2 = lineGeos{k+1};
d1 = [L1.b, -L1.a]; d1 = d1 / norm(d1);
d2 = [L2.b, -L2.a]; d2 = d2 / norm(d2);
cosA = abs(dot(d1, d2));
P.angles(end+1) = acos(min(1, max(-1, cosA))); %#ok<AGROW>
end
% 5. 全部直线段长度
P.lineLens = cellfun(@(L) norm(L.p2 - L.p1), lineGeos);
end
代码解析:
- 解决什么问题:把几何拟合结果转化为题目要求的"工程语义参数"。
- 设计要点:
- 第一段直线默认为上水平段——这个假设来自数据的物理结构,论文中要明示;
- 槽底取最低水平段——避免误把斜段当作槽底;
- 夹角用方向向量的内积绝对值计算,避免方向歧义。
- 初学者注意:MATLAB 的
cellfun可以避免for循环,代码更简洁;但是当结构体字段不一致时会报错,必须保证geos里每个元素结构统一。 - 竞赛改进:可以引入"语义标签"机制(如自动识别"上水平段"、“槽底段”、“侧斜段”),让
computeParams更通用。
13.4 结果可视化函数
% plot_results.m
function plot_results(d, geos, titleStr)
% 绘制原始点 + 拟合曲线
figure('Position',[100,100,1000,500]);
plot(d.x, d.z, 'b.', 'MarkerSize', 3); hold on;
colors = lines(length(geos));
for k = 1:length(geos)
g = geos{k};
switch g.type
case 'Line'
xs = [g.p1(1), g.p2(1)];
zs = [g.p1(2), g.p2(2)];
plot(xs, zs, '-', 'Color', colors(k,:), 'LineWidth', 2);
case 'Arc'
t1 = g.theta1; t2 = g.theta2;
if t2 < t1, t2 = t2 + 2*pi; end
tt = linspace(t1, t2, 100);
xs = g.xc + g.r * cos(tt);
zs = g.zc + g.r * sin(tt);
plot(xs, zs, '-', 'Color', colors(k,:), 'LineWidth', 2);
plot(g.xc, g.zc, 'x', 'Color', colors(k,:), 'MarkerSize', 10);
end
end
title(titleStr);
xlabel('X (μm)'); ylabel('Z (μm)');
axis equal; grid on;
legend('Raw Data','Fitted Segments','Location','best');
end
function plot_global(profile, titleStr)
% 绘制融合后的全局轮廓
figure('Position',[100,100,1100,500]);
plot(profile.X, profile.Z, 'k-', 'LineWidth', 1.2); hold on;
title(titleStr);
xlabel('X (μm)'); ylabel('Z (μm)');
axis equal; grid on;
end
代码解析:
-
解决什么问题:可视化是验证算法正确性的最快方式,没有图就没有说服力。
-
设计亮点:
- 用
lines(N)给不同段不同颜色,便于分辨; - 圆弧画的时候用真实拟合范围(
theta1→theta2),不是整圈; axis equal保证 X、Z 尺度一致,圆才不会被拉成椭圆。
- 用
-
初学者注意:很多同学画图忘了
axis equal,几何题里这是大忌——评委一眼能看出。 -
竞赛改进:可以加入残差热力图、置信椭圆等高级可视化。
13.5 灵敏度分析函数
% sensitivity_analysis.m
function sensitivity_analysis(data, config)
% 灵敏度分析:噪声水平、阈值、窗口长度对参数的影响
fprintf('\n--- 灵敏度分析 ---\n');
%% 1. 噪声扰动灵敏度
sigmas = [0, 0.5, 1, 2, 5]; % 单位:μm
paramsNoise = zeros(length(sigmas), 3); % 记录 [W, H, r1]
for i = 1:length(sigmas)
zNoisy = data.z + sigmas(i) * randn(size(data.z));
segs = segmentProfile(data.x, zNoisy, ...
config.tauL, config.tauC, config.minLen);
geos = arrayfun(@(s) fitGeometry(data.x, zNoisy, s{1}), ...
segs, 'UniformOutput', false);
P = computeParams(geos);
if isfield(P,'slotWidth')
paramsNoise(i,1) = P.slotWidth;
end
if isfield(P,'slotDepth')
paramsNoise(i,2) = P.slotDepth;
end
if ~isempty(P.arcs)
paramsNoise(i,3) = P.arcs(1).r;
end
end
disp('噪声 σ (μm) | 槽宽 W | 槽深 H | 半径 r1');
disp([sigmas(:), paramsNoise]);
figure;
plot(sigmas, paramsNoise(:,3) - paramsNoise(1,3), 'o-', 'LineWidth', 1.5);
xlabel('Noise σ (μm)'); ylabel('Δr_1 (μm)');
title('Sensitivity: Radius vs Noise');
grid on;
%% 2. SG 窗口长度灵敏度
wins = [7, 11, 15, 21, 31];
paramsWin = zeros(length(wins), 3);
for i = 1:length(wins)
cfg = config; cfg.savgolWin = wins(i);
d = struct('x_raw', data.x, 'z_raw', data.z);
d = denoise_data(d, cfg);
segs = segmentProfile(d.x, d.z, cfg.tauL, cfg.tauC, cfg.minLen);
geos = arrayfun(@(s) fitGeometry(d.x, d.z, s{1}), ...
segs, 'UniformOutput', false);
P = computeParams(geos);
if isfield(P,'slotWidth'), paramsWin(i,1) = P.slotWidth; end
if isfield(P,'slotDepth'), paramsWin(i,2) = P.slotDepth; end
if ~isempty(P.arcs), paramsWin(i,3) = P.arcs(1).r; end
end
disp('SG窗口 | 槽宽 W | 槽深 H | 半径 r1');
disp([wins(:), paramsWin]);
%% 3. 分段阈值灵敏度
factors = [0.5, 1, 2, 5];
paramsTau = zeros(length(factors), 3);
for i = 1:length(factors)
cfg = config;
cfg.tauL = config.tauL * factors(i);
cfg.tauC = config.tauC * factors(i);
segs = segmentProfile(data.x, data.z, cfg.tauL, cfg.tauC, cfg.minLen);
geos = arrayfun(@(s) fitGeometry(data.x, data.z, s{1}), ...
segs, 'UniformOutput', false);
P = computeParams(geos);
if isfield(P,'slotWidth'), paramsTau(i,1) = P.slotWidth; end
if isfield(P,'slotDepth'), paramsTau(i,2) = P.slotDepth; end
if ~isempty(P.arcs), paramsTau(i,3) = P.arcs(1).r; end
end
disp('阈值因子 | 槽宽 W | 槽深 H | 半径 r1');
disp([factors(:), paramsTau]);
end
代码解析:
-
解决什么问题:评估关键参数(噪声、滤波窗口、分段阈值)对最终结果的扰动效应。
-
三组实验设计:
- 噪声实验:模拟测量精度下降的影响;
- 窗口实验:评估滤波平滑度对几何参数的影响;
- 阈值实验:评估分段策略的鲁棒性。
-
数学模型对应:每组实验对应一个参数的"边际效应"测试。
-
初学者注意:灵敏度分析不能只在一个维度做——只测一组扰动很难说服评委。
-
竞赛改进:可以做正交实验设计(DOE)或拉丁超立方采样,更系统化。
13.6 模拟数据生成函数(无附件时使用)
% simulate_profile.m
function [x, z] = simulate_profile(noise_sigma, tilt_deg, x_start, x_end)
% 生成模拟轮廓数据(仅供算法验证,非真实附件数据)
%
% 模拟的几何形状:左水平台 → 圆弧下沉 → 斜段 → 圆弧 → 槽底
%
% 参数(可调):
% noise_sigma - 噪声标准差 (μm)
% tilt_deg - 倾斜角(度)
% x_start, x_end - X 范围
if nargin<1, noise_sigma=0.5; end
if nargin<2, tilt_deg=0; end
if nargin<3, x_start=0; end
if nargin<4, x_end=2000; end
dx = 1;
xv = (x_start:dx:x_end)';
zv = zeros(size(xv));
% 模拟几何参数(仅作为算法验证示例,与真实题目数据无关)
z_top = 100; % 上水平面高度
z_bot = 0; % 下水平面高度
r1 = 80; % 第一个圆弧半径
r2 = 80; % 第二个圆弧半径
x1 = 600; % 第一个圆弧起始
x2 = 1000; % 斜段终点
x3 = 1400; % 第二个圆弧终止
for i = 1:length(xv)
xi = xv(i);
if xi < x1
zv(i) = z_top;
elseif xi < x1 + r1
zv(i) = z_top - sqrt(r1^2 - (xi - x1)^2) + r1 - ...
sqrt(r1^2 - r1^2); % 简化的圆弧过渡
zv(i) = z_top - r1 + sqrt(max(0, r1^2 - (xi - x1)^2));
zv(i) = z_top - (r1 - sqrt(max(0, r1^2 - (xi - x1)^2)));
elseif xi < x2
% 斜段线性下降
slope = (z_bot - (z_top - r1)) / (x2 - (x1 + r1));
zv(i) = (z_top - r1) + slope * (xi - (x1 + r1));
elseif xi < x3
% 槽底
zv(i) = z_bot;
else
zv(i) = z_top;
end
end
% 加噪声
zv = zv + noise_sigma * randn(size(zv));
% 加倾斜
th = deg2rad(tilt_deg);
Rm = [cos(th), -sin(th); sin(th), cos(th)];
XZ = Rm * [xv'; zv'];
x = XZ(1,:)';
z = XZ(2,:)';
end
代码解析:
-
解决什么问题:在没有附件数据时验证整个算法管线是否能跑通。
-
重要声明:这是模拟数据,几何参数完全是我编造的,仅用于算法验证。真实附件数据的几何形状要以题目为准。
-
使用方式:
[x, z] = simulate_profile(1.0, 5); % 1μm 噪声 + 5° 倾斜 plot(x, z, '.'); -
初学者注意:在论文里千万不能用模拟数据替代真实附件计算!只能用作算法演示。
十四、结果展示与分析
重要前置说明:由于本文不接触真实附件数据,下文所有数值均为结构化占位说明(用 ★ 标识),强调的是结果应如何呈现,而不是给出具体数字。学生在自己跑完代码后请把 ★ 替换成真实输出。
14.1 问题 1 结果(水平测量)
主要参数表(示例格式):
| 参数 | 符号 | 数值 | 单位 |
|---|---|---|---|
| 槽口宽度 | W 1 W_1 W1 | ★ | μm |
| 槽口深度 | H 1 H_1 H1 | ★ | μm |
| 圆弧 1 半径 | r 1 , 1 r_{1,1} r1,1 | ★ | μm |
| 圆弧 2 半径 | r 2 , 1 r_{2,1} r2,1 | ★ | μm |
| 上水平段长度 | ℓ t o p , 1 \ell_{top,1} ℓtop,1 | ★ | μm |
| 槽底段长度 | ℓ b o t , 1 \ell_{bot,1} ℓbot,1 | ★ | μm |
| 夹角 | α 1 \alpha_1 α1 | ★ | ° |
附图要求:
- 图 14-1:原始数据散点图
- 图 14-2:去噪后数据曲线
- 图 14-3:分段标识(不同颜色)
- 图 14-4:拟合结果(散点 + 拟合曲线叠加)
14.2 问题 2 结果(倾斜校正)
| 参数 | 符号 | 数值 | 单位 |
|---|---|---|---|
| 估计倾角 | θ \theta θ | ★ | rad(或 °) |
| 校正后槽口宽度 | W 2 W_2 W2 | ★ | μm |
| 校正后槽口深度 | H 2 H_2 H2 | ★ | μm |
| 校正后圆弧 1 半径 | r 1 , 2 r_{1,2} r1,2 | ★ | μm |
| 校正后圆弧 2 半径 | r 2 , 2 r_{2,2} r2,2 | ★ | μm |
问题 1 vs 问题 2 对比:
| 参数 | 水平测量 | 倾斜校正 | 绝对偏差 | 相对偏差 |
|---|---|---|---|---|
| W W W | ★ | ★ | ★ | ★ % |
| H H H | ★ | ★ | ★ | ★ % |
| r 1 r_1 r1 | ★ | ★ | ★ | ★ % |
结果分析的标准写法(模板):
“倾斜校正后各几何参数与水平测量结果的相对偏差均小于 X%,说明本文提出的姿态校正算法能够有效消除测量姿态对参数标注的影响。具体来看,槽宽 W 的偏差最小,仅为 X μm,主要因为槽宽是 X 方向上的距离量,旋转校正对其影响为二阶小量;而深度 H 的偏差稍大,源于水平段拟合的微小残差经过几何放大所致。”
14.3 问题 3 结果(10 次测量融合)
关键输出:
- 逐次姿态角表:
| 测量序号 j j j | 倾斜角 θ j \theta_j θj (°) | X 平移 t x ( j ) t_x^{(j)} tx(j) | Z 平移 t z ( j ) t_z^{(j)} tz(j) |
|---|---|---|---|
| 1 | ★ | 0 (参考) | 0 (参考) |
| 2 | ★ | ★ | ★ |
| … | … | … | … |
| 10 | ★ | ★ | ★ |
-
全局轮廓图(关键图):把 10 次校正后的散点叠加 + 加权融合曲线。
-
全局参数表(含问题 4 对比):
| 参数 | 问题 3 (融合) | 问题 4 (精修) | 差异 |
|---|---|---|---|
| 圆弧半径 r ∗ r^\ast r∗ | ★ | ★ | ★ |
| 圆心 ( x c ∗ , z c ∗ ) (x_c^\ast, z_c^\ast) (xc∗,zc∗) | ★ | ★ | ★ |
| 角部夹角 α ∗ \alpha^\ast α∗ | ★ | ★ | ★ |
14.4 结果分析(深度)
按建模题论文标准,每组结果都要回答以下问题:
Q1:主要结果是什么?
“通过多次测量融合,得到了完整轮廓上各几何参数。其中圆弧半径标注精度从单次测量的 X μm 提升到 X μm。”
Q2:图表说明了什么?
“图 14-6 表明 10 次测量的特征点配准残差均在 X μm 以内,证明配准算法的可靠性。图 14-7 中精修前后参数差异主要集中在小弧段半径,差异在 X% 以内。”
Q3:是否符合现实直觉?
“结果中槽宽 W 略大于槽深 H,符合实际加工的几何比例。圆弧半径在两个圆弧上接近一致,这与工件加工时使用同一刀具的工艺特征一致。”
Q4:有哪些异常现象?
“在 X 区域出现一处轻微跳变(如图 14-7 红框所示),分析认为是探针在该位置经过工件边缘时的弹跳所致,建议在该区域加大窗口长度或单独剔除。”
Q5:误差可能来自哪里?
“误差主要来自:① 噪声残留(贡献量级 ≈ X μm);② 配准平移残差(≈ X μm);③ 圆弧分段边界判定(边界处可能引入 X 个点的偏差,放大到半径上约 X μm)。”
Q6:结果对实际有什么指导意义?
“本方案可直接部署在生产线轮廓仪后端,实现工件几何参数的自动标注,相比人工读数效率提升约 X 倍,且重复性误差降低一个数量级。”
十五、模型检验
15.1 误差分析
本题属于反演 + 拟合综合问题,应同时考察:
(1)拟合误差(残差类指标)
| 指标 | 公式 | 含义 | ||
|---|---|---|---|---|
| MAE | $\frac{1}{N} \sum | z_i - \hat z_i | $ | 平均绝对误差 |
| RMSE | 1 N ∑ ( z i − z ^ i ) 2 \sqrt{\frac{1}{N} \sum (z_i - \hat z_i)^2} N1∑(zi−z^i)2 | 均方根误差 | ||
| MAX | $\max_i | z_i - \hat z_i | $ | 最大残差 |
| R 2 R^2 R2 | 1 − ∑ ( z i − z ^ i ) 2 ∑ ( z i − z ˉ ) 2 1 - \frac{\sum(z_i-\hat z_i)^2}{\sum(z_i-\bar z)^2} 1−∑(zi−zˉ)2∑(zi−z^i)2 | 决定系数 |
% errorMetrics.m
function E = errorMetrics(z_true, z_pred)
err = z_true - z_pred;
E.MAE = mean(abs(err));
E.RMSE = sqrt(mean(err.^2));
E.MAX = max(abs(err));
E.R2 = 1 - sum(err.^2) / sum((z_true - mean(z_true)).^2);
end
为什么这套指标适合本题:
- 本题是几何反演(连续函数拟合),属于回归类问题;
- RMSE 强调大误差点,能反映"飞点"是否被有效抑制;
- MAX 反映几何边界(拐点)附近的最差表现,对工程应用很重要;
- R 2 R^2 R2 反映整体拟合优度。
(2)几何参数误差
由于真实工件参数未知(或仅以问题 1 结果为基准),可以构造自一致性误差:
δ j = ∣ P j − P ˉ ∣ P ˉ , P ˉ = 1 M ∑ j = 1 M P j \delta_j = \frac{|P_j - \bar P|}{\bar P}, \quad \bar P = \frac{1}{M}\sum_{j=1}^M P_j δj=Pˉ∣Pj−Pˉ∣,Pˉ=M1j=1∑MPj
含义: P j P_j Pj 是第 j j j 次测量得到的某参数值, P ˉ \bar P Pˉ 是 M M M 次的平均, δ j \delta_j δj 衡量了测量的重复性。
15.2 灵敏度分析
灵敏度分析的目的:评估参数 / 阈值的微小变化对最终结果的影响幅度。
| 扰动对象 | 扰动幅度 | 关注输出 |
|---|---|---|
| 噪声 σ \sigma σ | 0, 0.5, 1, 2, 5 μm | W , H , r W, H, r W,H,r |
| SG 窗口 | 7, 11, 15, 21, 31 | r r r |
| 分段阈值 τ L \tau_L τL | × \times × 0.5, 1, 2, 5 | 段数、 r r r |
| 配准距离阈值 | 10, 25, 50, 100 μm | 融合 RMSE |
评判标准:
- 若 ∣ ∂ P / ∂ θ ∣ < 0.01 |\partial P / \partial \theta| < 0.01 ∣∂P/∂θ∣<0.01,模型对该参数不敏感(鲁棒);
- 若敏感,需要在论文中给出"推荐区间"。
15.3 稳定性分析
通过重复随机噪声实验评估:
% stabilityTest.m
function stabilityTest(data, config, nTrial)
if nargin<3, nTrial = 100; end
Wlist = zeros(nTrial,1);
Rlist = zeros(nTrial,1);
for k = 1:nTrial
zN = data.z + 0.5 * randn(size(data.z));
segs = segmentProfile(data.x, zN, config.tauL, config.tauC, config.minLen);
geos = arrayfun(@(s) fitGeometry(data.x, zN, s{1}), ...
segs, 'UniformOutput', false);
P = computeParams(geos);
if isfield(P,'slotWidth'), Wlist(k) = P.slotWidth; end
if ~isempty(P.arcs), Rlist(k) = P.arcs(1).r; end
end
fprintf('W: mean=%.4f, std=%.4f, CV=%.2f%%\n', ...
mean(Wlist), std(Wlist), 100*std(Wlist)/mean(Wlist));
fprintf('R: mean=%.4f, std=%.4f, CV=%.2f%%\n', ...
mean(Rlist), std(Rlist), 100*std(Rlist)/mean(Rlist));
figure;
subplot(1,2,1);
histogram(Wlist, 20); xlabel('Slot Width W (μm)'); ylabel('Frequency');
title(sprintf('Slot Width Distribution (n=%d)', nTrial));
grid on;
subplot(1,2,2);
histogram(Rlist, 20); xlabel('Arc Radius r (μm)'); ylabel('Frequency');
title(sprintf('Arc Radius Distribution (n=%d)', nTrial));
grid on;
end
代码解析:
- 解决什么问题:在相同噪声水平下重复 100 次实验,观察参数的统计分布。
- 关键输出:变异系数 CV = std/mean × 100%。CV < 1% 表示参数标注非常稳定。
- 为什么这样写:直接画直方图最直观,比"列一长串数字"说服力强 10 倍。
- 初学者注意:
nTrial = 100是经验值,比赛时建议 500 次以上;若计算太慢可降到 50 次但说明清楚。
15.4 鲁棒性分析
鲁棒性 ≠ 稳定性。鲁棒性强调异常情形下的表现:
| 异常情形 | 测试方式 | 期望表现 |
|---|---|---|
| 数据缺失 | 随机删除 5%-20% 点 | 参数偏差 < 1% |
| 极端噪声 | σ = 5 σ 0 \sigma = 5\sigma_0 σ=5σ0 | 半径偏差 < 5% |
| 飞点污染 | 随机注入 10 个跳变点 | 自动剔除,参数无明显偏差 |
| 起点截断 | 删除前 10% 数据 | 仍能识别完整轮廓 |
% robustnessTest.m
function robustnessTest(data, config)
fprintf('\n--- 鲁棒性测试 ---\n');
% 测试 1:数据缺失
fracs = [0, 0.05, 0.10, 0.20];
for f = fracs
n = length(data.z);
rmIdx = randperm(n, floor(f*n));
keep = setdiff(1:n, rmIdx);
xk = data.x(keep);
zk = data.z(keep);
try
segs = segmentProfile(xk, zk, config.tauL, config.tauC, config.minLen);
geos = arrayfun(@(s) fitGeometry(xk, zk, s{1}), ...
segs, 'UniformOutput', false);
P = computeParams(geos);
fprintf('缺失率 %.0f%%: W=%.3f, R=%.3f\n', ...
f*100, P.slotWidth, P.arcs(1).r);
catch ME
fprintf('缺失率 %.0f%%: 算法失败 (%s)\n', f*100, ME.message);
end
end
% 测试 2:飞点污染
nSpikes = [0, 5, 10, 20];
for ns = nSpikes
zN = data.z;
if ns > 0
idxSp = randperm(length(zN), ns);
zN(idxSp) = zN(idxSp) + sign(randn(ns,1)) * 50; % 注入 50μm 飞点
end
segs = segmentProfile(data.x, zN, config.tauL, config.tauC, config.minLen);
geos = arrayfun(@(s) fitGeometry(data.x, zN, s{1}), ...
segs, 'UniformOutput', false);
P = computeParams(geos);
fprintf('飞点数 %2d: W=%.3f, R=%.3f\n', ns, P.slotWidth, P.arcs(1).r);
end
end
代码解析:
-
解决什么问题:模拟实际工程中可能遇到的"脏数据",验证算法的工程可用性。
-
设计要点:
- 缺失率最多到 20%(再高就失去测量意义了);
- 飞点幅度选 50 μm(明显大于真实噪声但又不至于让算法直接崩溃);
- 用
try/catch包裹防止算法崩溃中断整个测试。
-
数学模型对应:评估算法在"假设违背"情况下的鲁棒度。
-
初学者注意:鲁棒性测试的结果比稳定性测试更能加分,因为它体现了"算法是否能用",而不仅仅是"算法是否准"。
十六、模型优缺点
16.1 优点
-
模块化设计:去噪、分段、拟合、配准、融合相互独立,便于调试与扩展;
-
数值稳健性强:
- 直线用 TLS 替代普通最小二乘,避免接近竖直时发散;
- 圆弧用 Pratt 法替代 Kasa 法,在小弧段上偏差更小;
- MAD 准则替代 3σ 准则去除异常值,对极端飞点更鲁棒;
-
可推广性强:算法不依赖具体几何形状,只要轮廓由"直线 + 圆弧"组成即可;
-
多次测量信息融合最优:逆方差加权是 BLUE 估计,统计上最优;
-
"粗精结合"策略:问题 3 全局重建 + 问题 4 局部精修,符合工程"分而治之"思想;
-
完整的可视化与误差体系:从过程图到结果图、从拟合残差到参数稳定性,闭环验证。
16.2 缺点
- 阈值依赖人为经验: τ L \tau_L τL、 τ C \tau_C τC 等阈值需根据噪声水平人工调整,未做自适应;
- 分段方法对"平滑过渡"的圆弧 → 直线切点不够精细:在切点附近可能误判几个点;
- 配准只用了平移:未处理多次测量之间的微小残余旋转,对大姿态差的测量精度有限;
- 加权融合假设噪声独立:实际工程中相邻次测量可能存在系统偏差,独立假设不严格;
- 缺少多段语义自动识别:现在的代码假设"第一段是上水平面",对其他轮廓形状需手工修改;
- 没有引入贝叶斯先验:如果工件设计参数有标称值,可以作为强先验提升精度,本方案未利用。
16.3 改进方向
| 短期改进 | 长期改进 |
|---|---|
| 阈值自适应(噪声水平驱动) | 引入深度学习做端到端分段 |
| 切点位置二阶导精细化 | 用 ICP 替代闭式平移做精配准 |
| 增加贝叶斯先验融合 | 把整个流程封装成实时检测软件 |
| 多噪声模型并行(高斯+脉冲混合) | 与 CAD 模型库做反向匹配 |
写论文时:缺点不能光列,每条都要给出"对应的改进方案",这样能体现作者对问题的深入理解。评委最反感"列了缺点但不知道怎么改"的论文。
十七、论文写作建议
数学建模国赛论文不仅仅是"算法 + 结果",写作质量直接决定能否进入更高一档评审。下面是针对本题的具体写作建议。
17.1 章节安排建议
| 论文章节 | 建议页数 | 关键内容 |
|---|---|---|
| 摘要 | 1 | 问题、模型、方法、结果、亮点 |
| 一、问题重述 | 1-2 | 简化原题,突出建模视角 |
| 二、问题分析 | 2-3 | 四问之间的逻辑链 |
| 三、模型假设 | 0.5-1 | 5-8 条核心假设 |
| 四、符号说明 | 0.5 | 主要符号表 |
| 五、模型建立 | 6-10 | 三个模型(基础/改进/综合) |
| 六、模型求解 | 4-6 | 算法 + 关键代码 |
| 七、结果分析 | 3-5 | 图表 + 解读 |
| 八、模型检验 | 2-3 | 灵敏度 + 鲁棒性 |
| 九、模型评价 | 1-2 | 优缺点 + 推广 |
| 参考文献 | 1 | 8-15 条 |
| 附录 | 不限 | 完整代码 |
17.2 各章节写作要点
(1)问题重述
不要照抄题目。要把题目"翻译"成数学问题。例如:
“题目要求对工件轮廓的几何参数进行自动标注,本质上是一个几何反演问题:在已知离散观测点 ( x i , z i ) {(x_i, z_i)} (xi,zi) 的条件下,反求生成该点集的分段几何模型 S = L 1 , C 1 , L 2 , . . . \mathcal{S} = {L_1, C_1, L_2, ...} S=L1,C1,L2,... 的全部参数。”
(2)模型假设
写法格式:
"假设 1:工件轮廓由若干段直线和圆弧组成,相邻段在连接处至少 C 0 C^0 C0 连续。
理由:题目中给出的轮廓示意图明确显示由直线段和圆弧段交替构成,且工件加工工艺保证不会出现尖锐间断。"
每条假设都要有"理由 / 出处",绝对不要只写假设不给依据。
(3)模型建立
模型建立的"五段论":
- 物理意义引入:解释为什么要建这个模型;
- 数学化抽象:把物理过程转化为数学语言;
- 完整公式:包括目标函数、约束、变量;
- 参数解释:每个符号必须解释;
- 求解方法:怎么解、为什么这么解。
(4)模型求解
- 流程图先行:在求解小节开头放算法流程图;
- 关键代码片段:用代码框展示 5-10 行核心代码;
- 结果先汇报再讨论:先表格 / 图,再解释。
(5)模型检验
国赛对检验的要求:至少三种检验方法 + 结果讨论。常见组合:
- 拟合优度(残差、 R 2 R^2 R2)
- 灵敏度分析(参数扰动)
- 鲁棒性测试(异常情形)
(6)模型评价
写法格式:
"优点:① 模块化设计,便于扩展;② 数值稳健性强(Pratt + TLS);③ ……
缺点:① 阈值依赖经验,未做自适应;② ……
推广:本算法可推广到 ① 3D 表面轮廓测量;② 光学元件面形检测;③ ……"
17.3 图表使用建议
| 图表类型 | 推荐数量 | 用途 |
|---|---|---|
| 流程图 | 3-5 | 总体 / 求解 / 检验 |
| 拟合对比图 | 3-6 | 每个问题至少 1 张 |
| 灵敏度曲线 | 2-4 | 至少 2 组扰动 |
| 参数对比表 | 3-5 | 每个问题至少 1 张 |
| 误差分布直方图 | 1-2 | 稳定性分析 |
金句提醒:评委浏览论文时先看图、再看表、最后看文字。把最重要的结果做成"一眼能看懂"的图。
17.4 关键词建议
“接触式轮廓仪;几何参数自动标注;Savitzky-Golay 滤波;总体最小二乘;Pratt 圆拟合;多次测量融合;灵敏度分析”
7 个左右,覆盖问题领域、关键方法、检验手段。
17.5 参考文献建议
| 类型 | 推荐数量 | 示例 |
|---|---|---|
| 教材 | 2-3 | 数值分析、最小二乘理论 |
| 期刊 | 3-5 | 几何拟合、信号处理 |
| 标准 / 文档 | 1-2 | 轮廓仪国家标准 |
| 在线资源 | 1-2 | MATLAB 官方文档 |
引用要"用得上"——正文中真的提到了才引,不要堆砌。
十八、数学建模论文摘要示例
2020 高教社杯 D 题:接触式轮廓仪的自动标注
接触式轮廓仪通过金刚石探针采集工件表面离散点 ( x i , z i ) (x_i, z_i) (xi,zi),是精密制造业的核心测量手段。本文针对工件几何参数自动标注问题,建立了一套从"信号去噪—姿态校正—轮廓分段—几何拟合—多次测量融合—局部精修"的完整自动化算法框架,并基于 MATLAB 实现。
针对问题一,先采用 Savitzky-Golay 滤波结合 MAD 准则消除噪声与异常飞点,再基于一阶、二阶差分进行自适应轮廓分段,将连续点集划分为直线段、圆弧段与拐点;对直线段采用总体最小二乘(TLS)拟合,对圆弧段采用 Pratt 法拟合,进而得到工件 1 在水平测量条件下的槽口宽度 W、深度 H、圆弧半径 r 1 , r 2 r_1, r_2 r1,r2 等关键参数。
针对问题二,先利用最长直线段的方向角估计工件倾斜角 θ \theta θ,再通过二维刚体变换 R ( − θ ) R(-\theta) R(−θ) 进行姿态校正,并复用问题一的标注流程,得到校正后参数。结果显示,问题一与问题二的参数相对偏差均小于 X%,验证了姿态校正算法的有效性。
针对问题三,对工件 2 的 10 次局部测量,先逐次完成姿态校正,再以圆心、拐点等为特征点做平移配准,最后基于逆方差加权融合得到全局轮廓 Z ( x ~ ) Z(\tilde x) Z(x~),进而在该全局轮廓上完成参数标注。配准残差均控制在 X μm 以内,全局重建结果连续光滑。
针对问题四,将附件 3、附件 4 提供的圆弧、角部局部精测数据配准至全局坐标系,分别用 Pratt 法和 TLS 法做高精度拟合,得到精修后的圆心、半径与夹角,再替换问题三结果中的对应参数。比对显示,圆弧半径精度提升约 X%。
最后,本文对算法进行了灵敏度分析(噪声、窗口、阈值三组扰动)、稳定性分析(100 次重复实验)与鲁棒性测试(数据缺失、飞点污染),结果表明所有关键参数的变异系数均小于 X%,证明算法兼具高精度与高鲁棒性。本方案可直接推广至 3D 表面轮廓测量、光学元件面形检测等精密计量场景。
关键词:接触式轮廓仪;几何参数自动标注;Savitzky-Golay 滤波;总体最小二乘;Pratt 圆拟合;多次测量融合
摘要写作要点:
- 500-600 字最佳;
- 每个问题独占一段,结构清晰;
- 方法、结果、亮点缺一不可;
- 不要堆术语,让评委一遍就能看懂;
- 结尾点出"推广价值",体现工程意义;
- 数值用 ★ 占位,跑完代码后替换。
十九、常见问题与踩坑总结
Q1:拿到题目后为什么不能马上写代码?
很多同学一拿到题就开始 readtable + plot,这是建模中最大的误区。
正确顺序:
- 通读 2 遍题目,搞清楚物理背景;
- 画变量关系图:输入 → 中间量 → 输出;
- 拆解子问题:每问求什么、需要什么;
- 画整体建模流程图;
- 再开始写代码。
我的经验:花 2 小时分析比花 10 小时改代码值得多。
Q2:问题重述和题目复述有什么区别?
| 项目 | 题目复述 | 问题重述 |
|---|---|---|
| 内容 | 照抄原题 | 用数学语言翻译 |
| 视角 | 出题人 | 建模者 |
| 目的 | 介绍背景 | 明确数学问题 |
| 评委印象 | 凑字数 | 有思考 |
例:
- 题目复述:“本题要求标注工件几何参数……”
- 问题重述:“本题可抽象为分段函数反演问题:已知 ( x i , z i ) {(x_i, z_i)} (xi,zi),求生成模型 S \mathcal{S} S 的所有参数。”
Q3:模型假设是不是越多越好?
不是。5-8 条最佳。
- 假设过少:模型不严谨;
- 假设过多:评委会觉得你在"圈定题目",避重就轻。
好假设的标准:
- 直接为模型服务;
- 能用题目数据 / 物理常识支撑;
- 不与题目矛盾。
Q4:为什么公式很多但论文得分不高?
常见原因:
- 公式之间没有逻辑链,像"知识展示";
- 公式后没有解释变量含义;
- 公式与代码 / 结果不对应;
- 公式排版乱(行内 / 行间混用,记号不一致)。
好公式的标准:
“为什么写这个公式?这个公式解决了什么?它的输入输出是什么?”——三句话能讲清楚才放进论文。
Q5:MATLAB 结果如何对应论文表格?
最常见的痛点:代码跑完了,但表格里数字怎么来的说不清。
最佳做法:
- 在代码中用
fprintf或disp直接输出论文表格格式的内容; - 把输出直接复制到论文(保留 4 位有效数字);
- 标注每个数字对应的代码行号(可在附录中说明)。
例如:
fprintf('| W (μm) | H (μm) | r1 (μm) | r2 (μm) |\n');
fprintf('| %.3f | %.3f | %.3f | %.3f |\n', P.slotWidth, P.slotDepth, P.arcs(1).r, P.arcs(2).r);
Q6:没有附件数据时如何构建合理分析框架?
正确思路:
- 提供模拟数据生成函数(明确标注为模拟);
- 算法走完整流程,但不给具体数值结论;
- 用 ★ 或 “X” 占位真实数据时再替换;
- 在论文中明示"以下数值结果为算法演示,最终需用真实数据替换"。
错误做法:
- 编一组"看上去合理"的数字;
- 把模拟数据当真实数据;
- 不解释数据来源。
Q7:预测模型如何选择误差指标?
| 指标 | 适用 | 优点 | 缺点 |
|---|---|---|---|
| MAE | 一般场景 | 直观 | 对大误差不敏感 |
| RMSE | 强调大误差 | 工程常用 | 对异常值敏感 |
| MAPE | 跨量级数据 | 无量纲 | 真值接近 0 时爆炸 |
| R 2 R^2 R2 | 模型整体优度 | 标准化 | 高维下虚高 |
建议:至少汇报 3 种指标,互相印证。本题推荐 MAE + RMSE + MAX。
Q8:评价模型中权重如何确定?
虽然本题不是评价模型,但简要回答:
- 主观法:AHP 层次分析(专家打分);
- 客观法:熵权法、CRITIC、变异系数法(数据驱动);
- 组合法:主观 + 客观加权融合。
经验:单独用主观或客观都易被诟病,组合法更稳。
Q9:优化模型如何确定目标函数和约束条件?
本题虽然不是显式优化模型,但 TLS、Pratt 都是优化问题:
- TLS:目标 = 垂直距离平方和,约束 = 法向量单位化;
- Pratt:目标 = 代数残差平方和,约束 = 圆方程归一化。
通用建议:
- 目标函数要可微(或可定义次梯度);
- 约束尽量少,能用变量替换消去就消去;
- 注意凸性 / 非凸性(决定算法选择)。
Q10:国赛和美赛论文写法有什么区别?
| 维度 | 国赛 | 美赛 |
|---|---|---|
| 语言 | 中文 | 英文 |
| 摘要 | 1 页,500-800 字 | 1 页(含 Summary) |
| 篇幅 | 20-25 页 | 20-25 页 |
| 风格 | 公式 + 表格 + 详细推导 | 故事化叙述 + 图表 |
| 评审 | 看模型 / 算法严谨度 | 看创新 + 写作 + 应用 |
| 附录 | 必须放代码 | 也建议放,但更看正文 |
本题如果用美赛写,可以增加"工程应用展望"、"商业价值评估"等模块。
Q11:如何避免论文像"代码说明书"?
错误示例:“我们用 MATLAB 的 polyfit 函数实现直线拟合,参数 1 是 x,参数 2 是 z……”
正确示例:“直线段采用总体最小二乘拟合(公式 (X)),通过奇异值分解求解最小奇异向量,得到直线参数 ( a , b , c ) (a, b, c) (a,b,c)。”
原则:论文写"模型 + 思路",附录写"代码 + 注释"。
Q12:如何写出高质量摘要?
记住一个公式:
摘要 = 问题 + 模型 + 方法 + 结果 + 亮点 \text{摘要} = \text{问题} + \text{模型} + \text{方法} + \text{结果} + \text{亮点} 摘要=问题+模型+方法+结果+亮点
每个部分对应 1-2 段:
- 问题(1-2 句):说明题目本质;
- 模型(每问 2-3 句):说明用了什么模型;
- 方法(穿插):用了什么关键算法;
- 结果(每问 1 个数字):给出关键结论;
- 亮点(结尾 1-2 句):突出创新与推广。
Q13:如何自然地提出模型改进?
错误做法:基础模型一上来就求最复杂的,没有递进感。
正确做法:
- 第一个模型故意简化(如只考虑水平测量);
- 提出基础模型的不足(如"无法处理倾斜");
- 针对不足提出改进(如"引入姿态校正");
- 改进模型也有不足 → 综合模型……
这种"层层递进"的结构是国赛论文的标准范式,评委一眼能看出你的建模思路是否清晰。
Q14:模型优缺点如何写得具体?
错误示例:“优点:模型简单、易实现;缺点:精度不够、鲁棒性差。”——这是空话。
正确示例:
优点:
① 采用 Pratt 法替代 Kasa 法做圆拟合,在小弧段(弧长 / 直径 < 0.3)情况下,半径估计偏差从约 5% 降低到 1% 以内;
② 多次测量采用逆方差加权融合,统计上是 BLUE 估计,比简单算术平均的方差降低 30% 以上。缺点:
① 分段阈值 τ L \tau_L τL、 τ C \tau_C τC 依赖人工经验,未做自适应——当噪声水平变化超过一个数量级时需要重新调参;
② 配准只使用平移闭式解,未处理多次测量之间残留的微小旋转,当姿态差超过 15° 时融合误差会显著上升。
原则:每条都要"具体到数字 / 量化范围",不要泛泛而谈。
Q15:附录代码应该如何整理?
| 错误做法 | 正确做法 |
|---|---|
| 把所有代码堆在一起 | 按模块分文件展示 |
| 没有注释 | 每段有中文注释 |
| 含调试 print | 提交前清理 |
| 路径写绝对路径 | 用相对路径 / 参数化 |
| 不标版本 | 注明 MATLAB 版本 |
推荐附录结构:
附录 A:主程序 main.m
附录 B:数据预处理函数 data_preprocess.m, denoise_data.m
附录 C:模型求解函数 segmentProfile.m, fitGeometry.m, correctTilt.m
附录 D:融合与精修函数 fuseMeasurements.m, refineWithLocal.m
附录 E:可视化函数 plot_results.m
附录 F:检验函数 sensitivity_analysis.m, stabilityTest.m, robustnessTest.m
每个文件前用一段话说明"输入 / 输出 / 调用关系",方便评委快速理解。
二十、总结
20.1 全文回顾
本文围绕 2020 高教社杯 D 题"接触式轮廓仪的自动标注",从题目背景、问题拆解、模型建立、算法实现、结果分析、模型检验到论文写作进行了完整的系统讲解。
| 模块 | 关键技术 | 解决的核心问题 |
|---|---|---|
| 数据预处理 | MAD 异常剔除 + Savitzky-Golay 滤波 | 高保边去噪 |
| 模型一(基础) | 差分分段 + TLS + Pratt | 水平测量下的参数标注 |
| 模型二(改进) | 主水平段倾角估计 + 刚体变换 | 倾斜测量的姿态校正 |
| 模型三(综合) | 特征点配准 + 逆方差加权融合 | 多次测量的全局重建 |
| 局部精修 | 圆弧 / 角部专项拟合 | 关键参数的精度提升 |
| 模型检验 | 误差 + 灵敏度 + 鲁棒性 | 工程可用性论证 |
20.2 建模思想总结
这道题最值得学习的是它的三层建模哲学:
具体相关示意图绘制如下,仅供参考:

图说明:很多同学在第三层之前就直接进入"写代码",跳过了前两层。而前两层才是数学建模真正的"建模",后两层只是"实现"。
20.3 给参赛同学的建议
- 重视前两小时:拿到题先别动手,画图、拆解、讨论;
- 三人分工要合理:建模手 + 编程手 + 写作手三角配合;
- 代码模块化:千万不要一个脚本写到底;
- 结果可视化优先:每跑出一个结果立刻画图;
- 写作早动手:不要最后一天才开始写论文;
- 检验不可省:灵敏度 + 鲁棒性是高分论文的标配;
- 避免空话套话:每个结论都用数字说话。
20.4 给学习者的展望
如果你认真读完了这篇文章,应当能做到:
- 理解几何反演问题的建模思路;
- 掌握 Savitzky-Golay 滤波、TLS、Pratt 圆拟合的原理;
- 能用 MATLAB 实现完整的轮廓自动标注流程;
- 知道如何写一篇结构完整的数学建模论文;
- 学会如何做灵敏度、稳定性、鲁棒性检验;
- 规避常见的"代码先行、模型滞后"误区。
下一步可以做的:
- 找一份真实附件数据跑通完整流程,把所有 ★ 替换成真实数值;
- 尝试把算法移植到 Python(numpy + scipy + scikit-learn),训练跨语言建模能力;
- 拓展到 3D 表面:把 2D 轮廓推广到 3D 曲面,挑战光学元件面形检测题;
- 结合深度学习:用 1D-CNN 做轮廓分段,与传统方法对比;
- 挑战相关真题:2021 D 题(连铸切割)、2022 B 题(无人机定位)都涉及几何反演与多源测量融合。
20.5 结语
数学建模的魅力,从来不在"会用多复杂的算法",而在于:
能不能从一个混乱的实际问题中,剥离出干净的数学结构,再用合适的工具一步步解开它。
这道题虽然只考一个轮廓仪的几何参数标注,但其背后串联起了信号处理、最小二乘、几何拟合、坐标变换、多源融合、误差传播等一整条数学链条,是非常适合作为"建模思维训练"的真题。
希望读完这篇文章的你,不只是学会了一道题,更是学会了一类问题的解决范式。
下一次拿到建模题,先深呼吸,画图,拆解,再动手。
加油,建模路上不孤单。 🎯
附录 A:完整文件清单
| 文件名 | 功能 | 调用关系 |
|---|---|---|
main.m |
主程序,串联四个问题 | 顶层入口 |
data_preprocess.m |
数据读取与规整 | 被 main 调用 |
denoise_data.m |
综合去噪封装 | 调用 remove_outliers + savgol_smooth |
remove_outliers.m |
MAD 异常剔除 | 底层工具 |
savgol_smooth.m |
Savitzky-Golay 滤波 | 底层工具 |
segmentProfile.m |
轮廓分段 | 调用 smoothLabel |
fitGeometry.m |
几何拟合主入口 | 调用 fitLineTLS / fitCirclePratt |
fitLineTLS.m |
总体最小二乘直线 | 底层工具 |
fitCirclePratt.m |
Pratt 圆弧拟合 | 底层工具 |
correctTilt.m |
姿态校正 | 被问题 2、3 调用 |
findMainLine.m |
找最长直线段 | 被 correctTilt 调用 |
estimateNoise.m |
估计 Z 方向噪声 | 被融合模块调用 |
extractFeatures.m |
特征点提取 | 被融合模块调用 |
fuseMeasurements.m |
多次测量融合 | 问题 3 核心 |
refineWithLocal.m |
局部精修 | 问题 4 核心 |
computeParams.m |
参数提取 | 被各问题调用 |
plot_results.m |
分段拟合可视化 | 通用 |
plot_global.m |
全局轮廓可视化 | 通用 |
sensitivity_analysis.m |
灵敏度分析 | 检验模块 |
stabilityTest.m |
稳定性检验 | 检验模块 |
robustnessTest.m |
鲁棒性检验 | 检验模块 |
errorMetrics.m |
误差指标计算 | 检验工具 |
simulate_profile.m |
模拟数据生成(仅算法验证用,严禁用于论文结果) | 调试工具 |
附录 B:补充辅助函数
% findMainLine.m
function idx = findMainLine(x, z, config)
% 找最长的近水平直线段索引范围
% 思路:滑动窗口 + 局部斜率 + 最大连续低斜率段
n = length(x);
s = zeros(n,1);
for i = 2:n-1
dx = x(i+1) - x(i-1);
if dx ~= 0
s(i) = (z(i+1) - z(i-1)) / dx;
end
end
% 用斜率绝对值排序的前 50% 中位数估计基准
sortedAbs = sort(abs(s));
baseSlope = sortedAbs(round(0.3*n));
flagFlat = abs(s) <= 3 * baseSlope;
% 寻找最长 True 段
bestLen = 0; bestStart = 1; bestEnd = 1;
i = 1;
while i <= n
if flagFlat(i)
j = i;
while j < n && flagFlat(j+1), j = j+1; end
if j - i + 1 > bestLen
bestLen = j - i + 1;
bestStart = i; bestEnd = j;
end
i = j + 1;
else
i = i + 1;
end
end
idx = bestStart:bestEnd;
end
代码解析:
-
解决什么问题:自动找出"最长接近水平的直线段",作为姿态校正的基准。
-
设计要点:
- 用斜率绝对值的 30 分位数作为"基准斜率",避开极端值;
- 找最长连续低斜率段,避免被局部小台阶干扰。
-
初学者注意:阈值倍率 3 是经验值,对噪声很大时可调大到 5。
% estimateNoise.m
function sigma = estimateNoise(x, z, mainIdx)
% 在主水平段上估计 Z 方向噪声标准差
L = fitLineTLS(x(mainIdx), z(mainIdx));
% 计算所有点到直线的垂直距离
d = abs(L.a * x(mainIdx) + L.b * z(mainIdx) + L.c);
% 用 1.4826*MAD 作为稳健的标准差估计
sigma = 1.4826 * median(abs(d - median(d)));
if sigma < 1e-3, sigma = 1e-3; end % 防止权重爆炸
end
代码解析:
- 解决什么问题:估计每次测量的噪声水平,用于加权融合。
- MAD 而非 std:在主水平段上若存在残留异常点,MAD 不会被污染。
- 最小值保护:
sigma < 1e-3时直接设为 1e-3,避免除以零导致权重无穷大。
% extractFeatures.m
function F = extractFeatures(x, z, config)
% 从轮廓中提取特征点(圆心位置、拐点位置)作为配准基准
segs = segmentProfile(x, z, config.tauL, config.tauC, config.minLen);
F = [];
for k = 1:length(segs)
seg = segs{k};
g = fitGeometry(x, z, seg);
switch g.type
case 'Arc'
F = [F; g.xc, g.zc]; %#ok<AGROW>
case 'Corner'
F = [F; g.point]; %#ok<AGROW>
end
end
end
代码解析:
- 解决什么问题:在每次测量中提取唯一性强的特征点(圆心、拐点),用于跨测量配准。
- 为什么不用直线段端点:直线段端点受截断影响大,不稳定。
- 竞赛改进:可以加入"特征点置信度",按拟合残差大小赋权。
附录 C:MATLAB 运行环境说明
| 项目 | 推荐版本 / 配置 |
|---|---|
| MATLAB 版本 | R2019b 及以上 |
| 必需工具箱 | Signal Processing Toolbox(sgolayfilt), Curve Fitting Toolbox(可选) |
| 内存 | 建议 8GB 以上(10 次测量数据全部加载) |
| 平台 | Windows / macOS / Linux 均可 |
| 字体 | 论文输出建议使用 Times New Roman / 宋体混排 |
如不具备 Signal Processing Toolbox:可以用如下自实现替代
sgolayfilt:
function y = sg_filter(x, order, win)
% Savitzky-Golay 自实现(无需工具箱)
if mod(win,2)==0, win = win+1; end
m = (win-1)/2;
j = (-m:m)';
% 构造范德蒙德矩阵
J = bsxfun(@power, j, 0:order);
% S-G 系数:取 (J'J)^{-1}J' 第一行
H = (J' * J) \ J';
h = H(1,:);
% 卷积
y = filter(h, 1, x);
% 边界处理(截断或镜像)
y = circshift(y, -m);
y(end-m+1:end) = x(end-m+1:end);
y(1:m) = x(1:m);
end
写在最后
这篇文章按竞赛指导的最高标准撰写,全文约 3 万字,涵盖了 2020 D 题从理解到求解、从算法到论文的完整闭环。
如果你是一名正在备战国赛 / 美赛的同学,建议:
- 逐节阅读 + 自己手敲一遍代码——只看不敲,效果减半;
- 拿到附件数据后立刻替换 ★,跑出真实结果;
- 结合自己队伍的写作风格调整论文模板——不要照搬,要内化;
- 每完成一道真题,写一份自己的"题解 + 反思",半年后回看会有质的飞跃。
数学建模的成长,从来不是一次冲刺,而是一次次"建模—复盘—改进"循环的累积。
祝你在建模路上越走越远,拿到心仪的奖项,更重要的是——
学会用数学的眼光,去看待这个真实而复杂的世界。 ✨
声明:以上内容部分基于人工智能辅助生成,仅供参考交流,不构成任何专业建议。模型输出可能存在偏差,使用前请自行核实,后果自负。欢迎理性讨论。
若需原题 PDF、附件或历年高教社杯真题,关注技术号 「猿圈奇妙屋」,回复【高教社杯】即可获取。
🎁 文末福利
本专栏内容源自实际建模经验、竞赛题目及读者需求。如涉及版权问题,请告知,将立即处理。部分解法思路参考了网络优秀文章,若未能完全契合你的场景,欢迎在评论区分享更优解法,共同探讨、共同进步!
更多建模方法、工具与竞赛题解,欢迎访问专栏 👉 《《滚雪球学数学建模(含历年真题)》
如果本文对你有帮助,欢迎点赞、收藏、关注,你的支持是我持续创作的动力!
同时推荐关注技术号 「猿圈奇妙屋」,获取建模干货、竞赛真题解析、4000G 技术资料、简历模板等海量内容,助你快速突破瓶颈。
🫵 关于作者
我是 bug菌,数学建模竞赛指导教师,曾指导学生斩获国赛一等奖、美赛 M 奖等,擅长运动学建模、优化模型、评价模型等方向。
活跃于 CSDN · 掘金 · InfoQ · 51CTO · 华为云 · 阿里云 · 腾讯云 · 开源中国 · 博客园 · 墨天轮 等平台
🏅 CSDN 博客之星 Top30 · 华为云十佳博主 · 掘金人气作者 Top40 · 多平台签约优质作者 · 全网粉丝 30w+
更多优质内容与成长资料 👉 点击查看 👈
欢迎加入硬核技术号 「猿圈奇妙屋」,一起进阶打怪!

- End -

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 1
1 0
0- 0



 已为社区贡献167条内容
已为社区贡献167条内容

所有评论(0)