一文讲透AI大模型(架构+原理+流程)
AI大模型
大模型(Large Language Model,简称 LLM):是基于海量数据和巨量参数训练的深度神经网络模型。
LLM 的本质是一个超级大的概率模型,通过学习海量文本中的统计规律来预测“下一个最可能的词”。
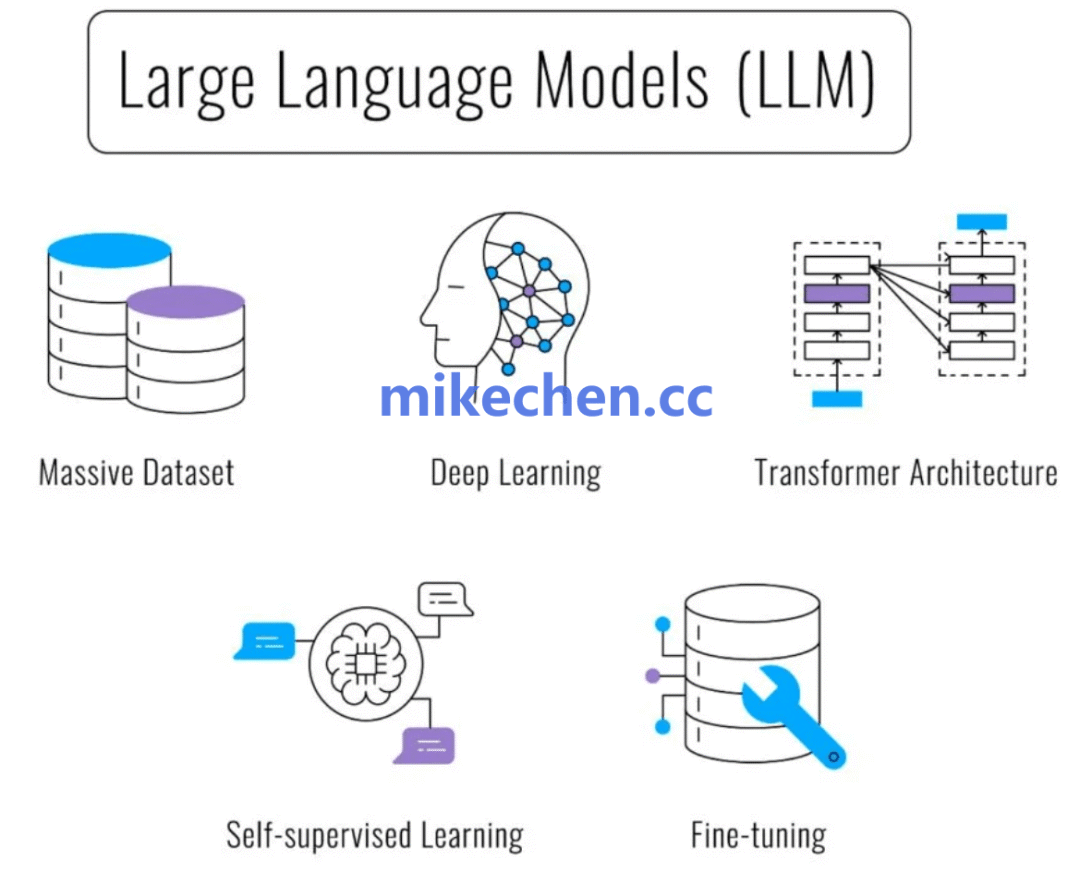
早期阶段,从基于规则与统计语言模型(n-gram)演进到神经网络语言模型(RNN/LSTM),能力随参数和数据增长而稳步提升。
发生根本的改变,2017 年革命:Google 发表《Attention Is All You Need》。
提出 Transformer 架构,使用自注意力机制(Self-Attention)并行处理序列,彻底取代 RNN,成为 LLM 基石。

然后,在2022 年彻底爆发。
OpenAI GPT-3(1750 亿参数)展现强大 few-shot 能力,ChatGPT(基于 GPT-3.5 + RLHF)让大众真正感受到 LLM 的威力。
实现了对话、写作、推理、代码生成…等复杂能力。
大模型架构
大模型之所以强大,全靠这三根“顶梁柱”支撑:
\1. Transformer 架构(结构基础)
Transformer 彻底抛弃了传统的循环结构,采用了 Self-Attention(自注意力机制)。
在 Transformer 出现之前(RNN/LSTM 时代),AI 读书是“一字一顿”,读到结尾就忘了开头。
Self-Attention(自注意力机制):这是 Transformer 的灵魂。
它能让模型在处理每一个词时,同时“扫描”全文,自动识别出哪些词更重要。
例子:处理“那个银行不给开户,因为它没钱”时,Attention 机制能瞬间锁定“它”指代的是“银行”而不是“开户”。
\2. 预训练 (Pre-training)
这是模型获取知识的过程,这是最烧钱的阶段(几千台 H100 集群跑几个月)。
通过阅读数万亿 Token 的语料(Common Crawl, GitHub, 论文等),模型学会了语法、事实、甚至基础的编程逻辑。
在这个阶段,模型学会了知识。
\3. 微调与对齐 (SFT & RLHF)
SFT (指令微调):教模型学会对话的格式。
RLHF (强化学习与人类反馈):这是大模型具备“人性”的关键。
RLHF(人类反馈强化学习),让人类给模型的多个回答打分。
模型会为了获得高分,不断调整自己的输出风格,变得更安全、更有用、更像“人”。
一句话总结:LLM 是基于 Transformer、自注意力机制和 Scaling Law 构建的超级概率模型。
它通过海量数据压缩人类知识的统计模式,从而“模拟”智能。
大模型原理
LLM 的本质是一个超级概率预测引擎:它不“理解”世界。

而是通过学习海量文本的统计规律,预测“给定上下文,下一个最可能的 token 是什么”。
预测下一个 Token 的超级神经网络,这是整个 AI 大模型最核心的一句话。
举个例子
输入:
今天天气真
模型会预测:
下一个最可能出现的词:
好
继续预测:
啊
最终生成:
今天天气真好啊
推理流程,如下:
输入Prompt
→Token化
→Transformer计算
→输出下一个Token
→循环生成
所以:LLM 真正一直在做的事情。
其实只有一个:不断预测下一个 Token。
本质上,Token:就是:模型处理文本的最小单位。
为什么 Token 很重要?
因为:AI 的:API 成本、推理成本、GPU 消耗、上下文长度,全部都和 Token 有关。
最后
选择AI大模型就是选择未来!最近两年,大家都可以看到AI的发展有多快,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,人才需求急为紧迫!
人工智能时代最缺的是什么?就是能动手解决问题还会动脑创新的技术牛人!智泊AI为了让学员毕业后快速成为抢手的AI人才,直接把课程升级到了V6.0版本。
这个课程就像搭积木一样,既有机器学习、深度学习这些基本功教学,又教大家玩转大模型开发、处理图片语音等多种数据的新潮技能,把AI技术从基础到前沿全部都包圆了!
课堂上不光教理论,还带着学员做了十多个真实项目。学员要亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
课程还教大家怎么和AI搭档一起工作,就像程序员带着智能助手写代码、优化方案,效率直接翻倍!
这么练出来的学员确实吃香,83%的应届生都进了大厂搞研发,平均工资比同行高出四成多。
智泊AI还特别注重培养"人无我有"的能力,比如需求分析、创新设计这些AI暂时替代不了的核心竞争力,让学员在AI时代站稳脚跟。
课程优势一:人才库优秀学员参与真实商业项目实训
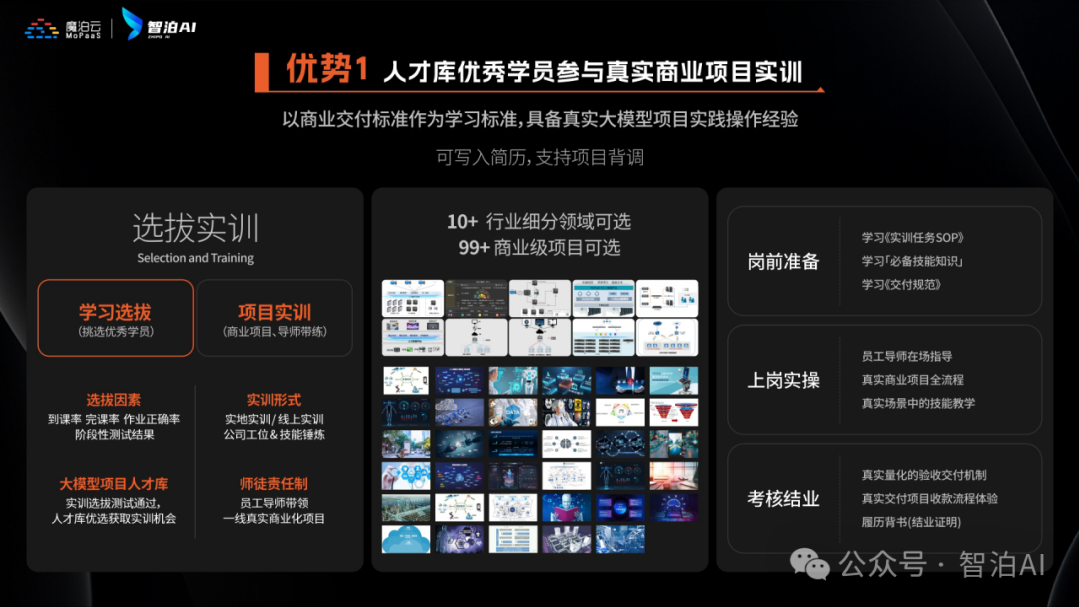
课程优势二:与大厂深入合作,共建大模型课程

课程优势三:海外高校学历提升

课程优势四:热门岗位全覆盖,匹配企业岗位需求
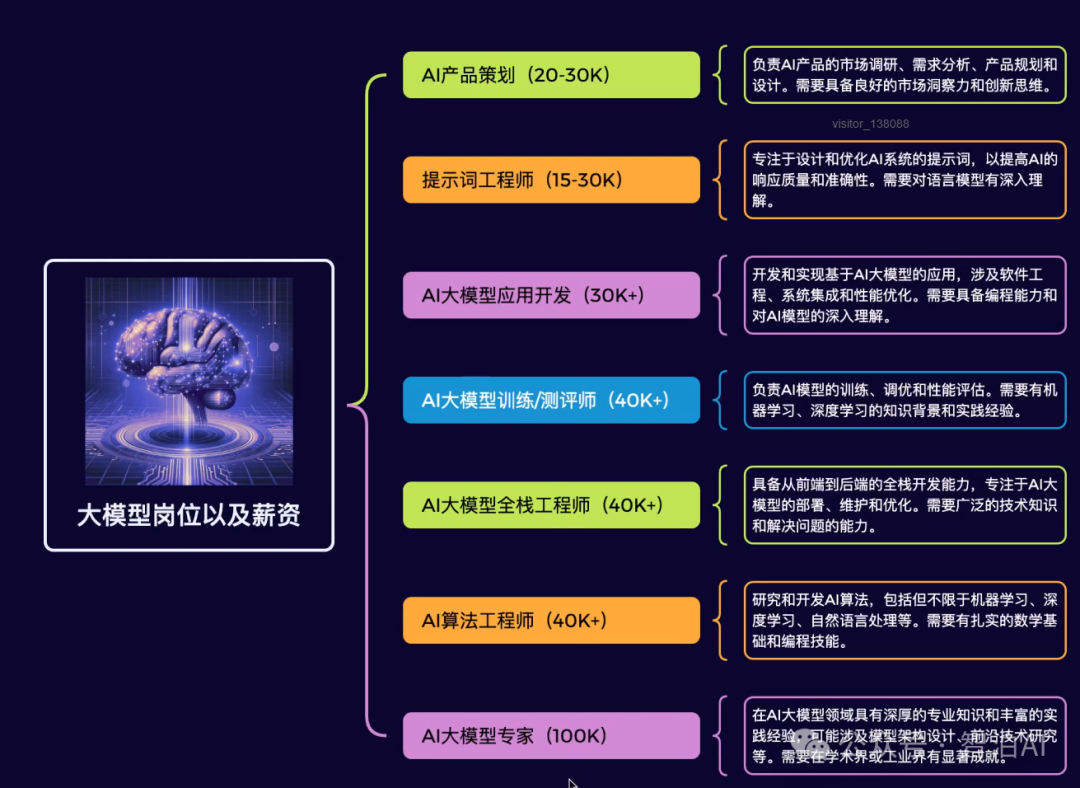
如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
·应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
·零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
·业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

智泊AI始终秉持着“让每个人平等享受到优质教育资源”的育人理念,通过动态追踪大模型开发、数据标注伦理等前沿技术趋势,构建起"前沿课程+智能实训+精准就业"的高效培养体系。
重磅消息
人工智能V6.0升级两大班型:AI大模型全栈班、AI大模型算法班,为学生提供更多选择。

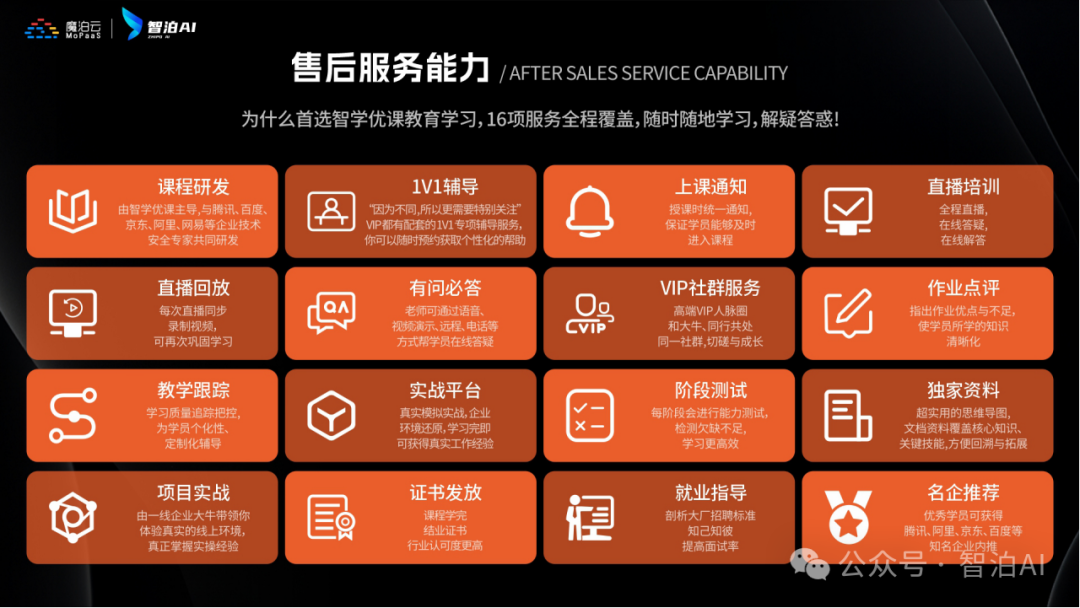
由于文章篇幅有限,在这里我就不一一向大家展示了,学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。
【最新最全版】AI大模型全套学习籽料(可无偿送):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
获取方式:有需要的小伙伴,可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
来智泊AI,高起点就业
培养企业刚需人才
扫码咨询 抢免费试学
⬇⬇⬇

AI大模型学习之路,道阻且长,但只要你坚持下去,就一定会有收获。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 5
5 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)