20张图解大模型入门必备的20个核心基础概念全解!
很多产品经理做AI产品决策时,都靠模糊的AI能力认知做判断,而非精准摸清大模型的能力边界。
这种认知短板,会引发一系列工作问题:需求文档写到一半,才发现整体方向跑偏;技术选型会上,被算法人员一句话直接否决;功能好不容易上线,才发现成本结构根本没法长期运营。
掌握大模型核心知识,不是为了让你转行做算法工程师,而是帮你在模型选型、功能设计、成本估算这三大核心决策环节,不用再依赖别人解读翻译,自己就能独立判断。
本文整理了20个P0级别的大模型基础核心概念,全部是日常工作高频用到的内容。
内容按照理解优先级排序,只聚焦大模型本体知识,不涉及Agent架构、知识库、工具调用这类应用层内容。全程不讲复杂数学公式,不用死记硬背专业定义,只分享产品工作能用得上的实操干货。
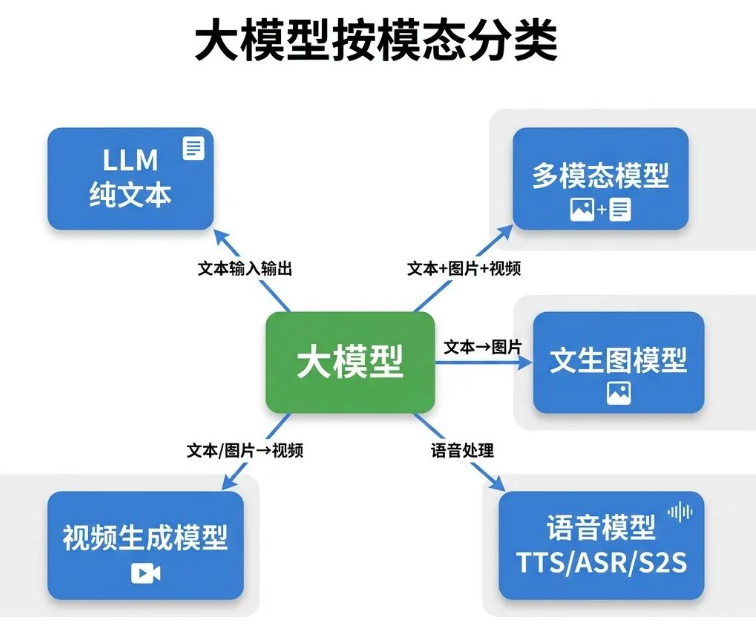
01 模型的分类
很多产品经理规划AI功能时,第一反应都是直接调用大模型API就行。但真正到了技术评审环节就会发现,文字、图片、语音、视频的处理,对应的是完全不同的模型。
大模型能够处理的信息类型,我们称之为模态。不同模态对应不同模型,这是AI产品选型的基础起点。
LLM也就是纯文本语言模型,只支持文本输入、文本输出,我们日常调用的绝大多数产品API,比如GPT-5.4对话、Claude问答,都属于这类模型。
多模态模型可以同时处理文本和图片,部分还支持视频、音频输入输出,像GPT-5.4、Gemini 3.1、Claude 4.6 Sonnet都属于多模态模型。
如果产品需要识别图片内容、分析截图、处理扫描文档,必须调用多模态模型,纯文本LLM是无法识别图片的。
文生图模型只接收文本输入、输出图片,Stable Diffusion、DALL-E 3、Midjourney都是典型的文生图模型。
这类模型和LLM是完全独立的两种类型,底层架构不一样,API不能混用。
语音模型主要分为三类:TTS是文字转语音,ASR是语音转文字,S2S是端到端语音对话。
产品里的语音交互功能,基本都需要单独接入这类模型,LLM本身是不具备音频处理能力的。
视频生成模型可以通过文字、图片输入生成视频,Sora、可灵、即梦都属于这类。
目前这类模型存在生成延迟高、帧率和分辨率有限的问题,在商业化产品中,大多只应用在内容创作场景。
根据我的实操经验,如果一款产品需要同时处理文字、图片、语音,至少要接入三套不同的模型方案,对应三套接入逻辑和三套计费规则。
如果在产品规划阶段没意识到这个问题,最终的工期预估一定会出现偏差。
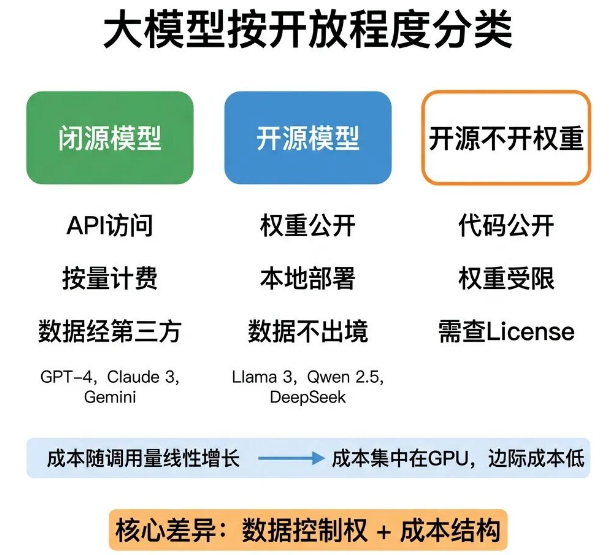
02 开源&闭源模型
做模型选型评估时,首先要确定一个核心问题:企业数据是否可以流出公司。这个问题的答案,直接决定产品该选闭源还是开源模型。
闭源模型的权重不对外公开,只能通过API调用,按照调用量计费,GPT-4系列、Claude 3系列、Gemini Ultra都属于闭源模型。
数据会通过API传输,经过第三方服务器处理,优势是可以快速落地上线,不用自己搭建、维护模型基础设施,适合轻量化快速迭代的场景。
开源模型的权重会对外公开,能够下载到本地服务器部署运行,Llama 3、Qwen 2.5、DeepSeek-V2都是主流开源模型。
核心优势是数据不会流出企业自有设备,能满足数据不出境的合规要求,缺点是需要团队自行搭建、维护GPU算力,整体运维成本需要企业自己承担。
开源和闭源模型的核心差距,不在于模型能力,而在于数据控制权和成本结构。闭源模型的使用成本会随着调用量增加线性上涨,开源模型的成本主要集中在前期GPU采购和后期运维,长期使用的边际成本极低。
金融、医疗、政务类产品大多选择开源自部署方案,核心原因就是行业监管明确禁止数据出境。
除此之外还有一种特殊中间形态:开源不开权重,也就是代码和架构完全公开,但模型权重受商业许可限制,不能随意商用。选型时不能只看GitHub的开源标签,一定要仔细核对license文件。
正式确定选型方案前,务必先和法务团队确认数据合规边界,这一步会锁定后续所有技术方案的可选范围。
03 模型本地&云端部署
方案评审阶段,模型的部署位置是绕不开的关键问题,部署方式直接决定产品的成本结构、响应延迟和数据安全等级。
云端部署,就是模型运行在云服务商的服务器上,产品通过网络API调用模型能力。
响应延迟受网络环境影响,普遍在100ms到2秒之间,计费方式为按Token数量或API调用次数收费,也是目前绝大多数AI产品的主流接入方式,上手门槛和前期成本最低。
端侧部署,是把模型部署运行在用户的终端设备上,比如手机芯片、PC的NPU。数据全程不用网络传输,不仅延迟极低,无网络环境也能正常使用。
缺点是受限于终端设备算力,只能运行7B及以下小参数量模型,苹果的Apple Intelligence、各大手机厂商的端侧AI功能,都是端侧部署的典型应用。
私有化部署,是企业自主采购或租用GPU服务器,在自有机房、私有云部署开源模型。数据全程留存企业内网,能满足最严格的合规要求,短板是GPU采购、运维成本极高。
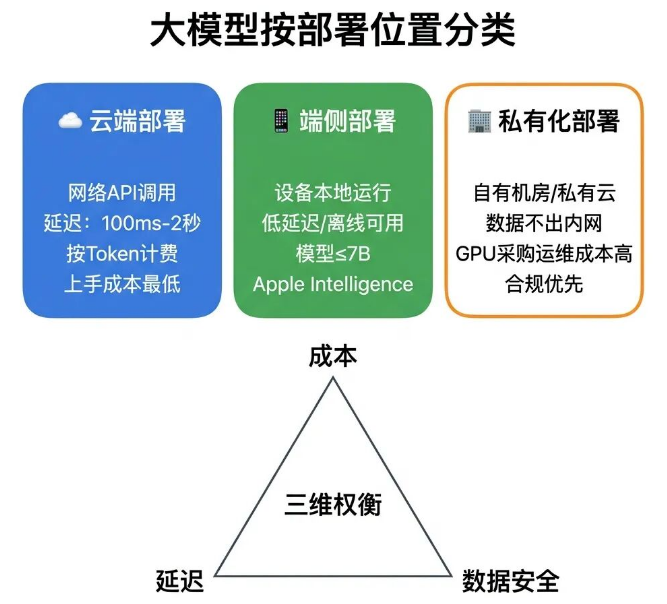
三种部署方案的选择逻辑,本质是在成本、延迟、数据安全三个维度之间做权衡。方案评审时,必须先明确这三个维度的优先级,再匹配对应的部署方式。
如果把架构决策完全交给技术团队,很容易出现后期因合规问题,需要整体推翻重做的情况。
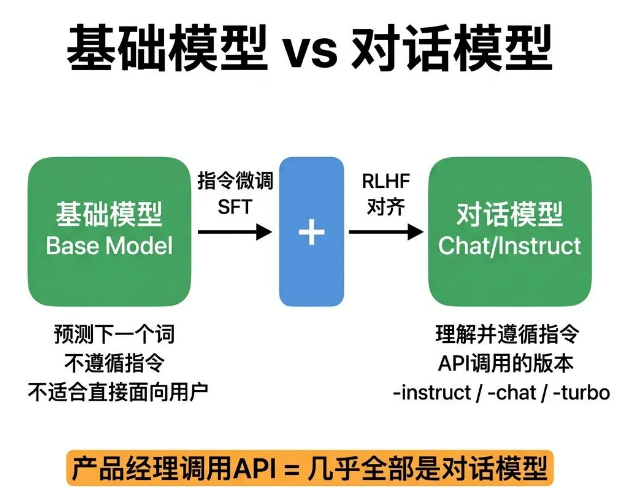
04 基础模型 vs 对话模型
这是最容易被混淆的一组概念,一旦理解出错,直接导致模型选型方向跑偏。
基础模型(Base Model)只经过大规模语料预训练,核心能力是根据上下文预测下一个字词。
这类模型不具备理解、遵循用户指令的能力,如果你直接输入“帮我写一份邮件”,模型只会根据训练数据的概率分布续写文字,大概率输出的内容不符合邮件格式和需求,完全不适合直接面向终端用户使用。
对话模型(Chat/Instruct Model)是在基础模型的基础上,经过指令微调和RLHF对齐优化,具备了理解并执行用户指令的能力。
GPT-4-turbo、Claude 3 Opus、Qwen-72B-Instruct都是标准的对话模型。大家调用API时,看到的-instruct、-chat、-turbo后缀版本,全部都是对话模型,我们日常调用的几乎都是这类模型。
基础模型一般只用在需要最大化内容生成多样性的场景,比如生成训练数据、创意实验等。大家看模型官方文档时,直接重点看对话版本的内容就足够了。
05 推理模型
处理同一个复杂分析任务,普通对话模型经常遗漏关键逻辑、出错率高,换成推理模型后准确率会大幅提升,但对应的API调用账单也会随之上涨。
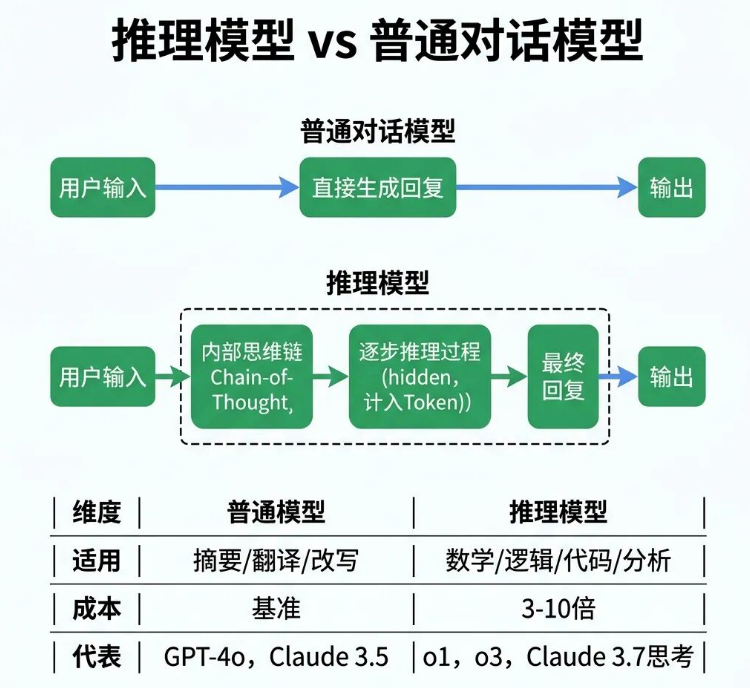
推理模型是2024年兴起的大模型新范式,和普通对话模型有本质区别。普通对话模型接收用户指令后,会直接生成回复;
而推理模型在输出最终答案前,会先完成一套隐藏的逐步思考过程,也就是思维链,这个过程用户看不到,但会正常计入Token消耗。
OpenAI的o1、o3系列,Anthropic的Claude 3.7 Sonnet扩展思考模式,阿里的Qwen3系列,都是主流推理模型。在数学计算、逻辑推理、代码生成、复杂业务分析这类任务上,推理模型的准确率远高于普通对话模型。
但如果是文案摘要、内容改写、文本翻译这类常规定性文字任务,普通对话模型完全够用,用推理模型只会徒增响应延迟和使用成本。
我总结的核心选型逻辑很简单:判断用户任务是否需要多步骤推导。简单的客服问答不用推理模型,复杂的合同风险分析、数据研判就必须用。这个判断做不好,产品的成本结构一定会出现根本性问题。
06 Token
很多人疑惑,明明自己设置的System Prompt很短,为什么每次API调用的费用依然居高不下?问题大多出在对Token计费规则不了解。
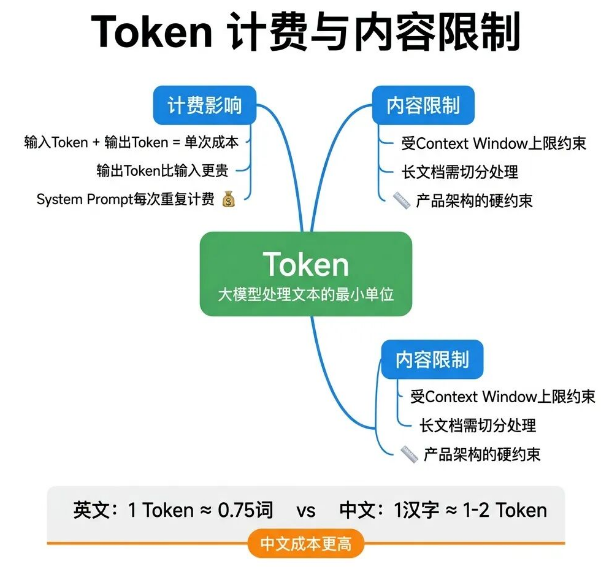
Token是大模型处理文本的最小单位,和我们日常说的字、词不是同一个概念。英文语境下,1个Token大概对应0.75个单词;中文语境下,1个汉字通常对应1到2个Token,具体要看分词器规则。
同等信息密度的文本,中文消耗的Token比英文更多,成本也更高,高频调用场景下,这个差距会被持续放大。
Token对产品工作主要有两大影响:
第一是计费。主流大模型API会分开计算输入Token和输出Token,且输出Token的单价普遍更高。
单次调用的总成本,由System Prompt、用户输入内容、模型回复内容三者的Token总量决定。如果System Prompt过长(超过3000 Token),每次调用都会重复计费,高频场景下的累计成本会非常可观。
第二是内容上限。模型的上下文窗口,限制了单次能够处理的Token总量,这是产品设计的硬性约束。处理长文档时,必须把内容拆分、分批处理,否则无法完整解析。
大家上线功能前,一定要先算清楚单次调用的成本基线:(System Prompt平均Token量 + 平均用户输入Token量 + 平均输出Token量)× 对应单价。
07 Context Window
用户上传50页PDF要求总结,模型却只输出前10页的内容,不是模型偷懒,而是模型的Context Window不够用了。
Context Window也就是上下文窗口,指模型单次推理时,能够同时处理的最大Token总量,包含输入和输出的所有内容。这个参数直接决定了产品的功能上限。
4K Token的上下文窗口,大约能处理3000字中文内容;128K Token可处理约10万字;目前部分模型已经做到1M Token上下文,能够处理75万字左右的文本。
日常产品设计中,很多问题都来自上下文窗口限制:长文档摘要时,超出窗口的内容会被直接截断,模型完全读取不到;
多轮长对话中,历史消息超出上限后,模型会遗忘前期的对话内容;代码库分析场景下,窗口大小决定了单次可分析的代码文件数量。

通常上下文窗口越大,单次API调用的费用越高,因为推理计算量和输入Token数量成正比。大家设计功能时,要先明确场景的Token使用规模,再匹配合适的模型,不要一味默认选择最大上下文的版本,导致成本浪费。
08 Hallucination
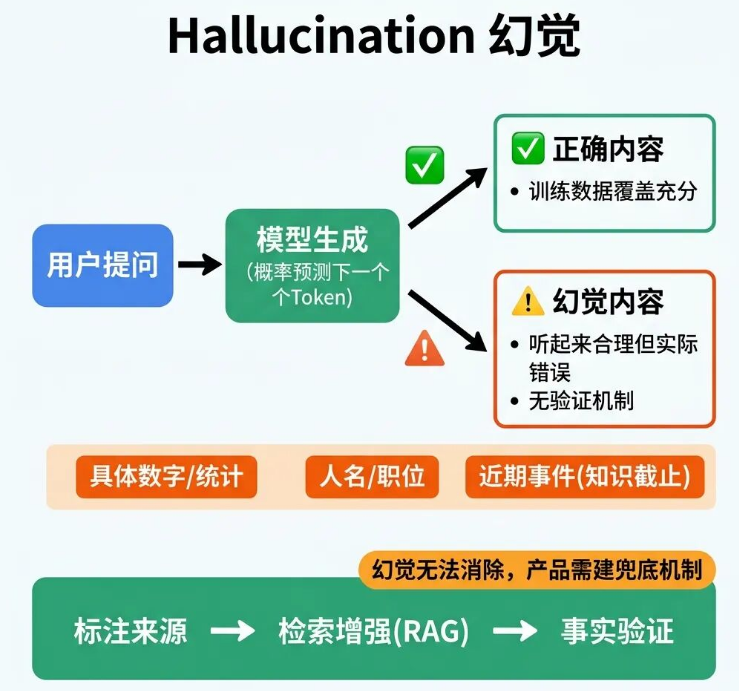
模型生成的内容看着专业严谨,还标注了数据源、引用出处,实际核查后却发现数据源根本不存在,这种情况就是模型幻觉(Hallucination)。
这不是模型出错、不严谨,而是大模型的固有生成特性。模型是依靠统计概率预测下一个Token生成内容,本身没有事实核查、真伪验证的能力,只会生成逻辑通顺、概率合理的内容,无法保证内容真实准确。
幻觉高发场景主要集中在三类:生成具体数字、引用数据源和统计数据;生成人名、职位等人物相关信息;描述模型知识截止日期之后的近期事件。
产品设计中,可以通过三种方式降低幻觉概率:要求模型回复时必须标注信息来源;接入检索系统,让模型依托原始文档作答,而非依靠自身训练数据;在模型输出内容后,增加人工或程序事实验证步骤。
这里要提醒大家,模型幻觉无法彻底消除。产品经理的核心工作,是识别高风险业务场景,提前设计兜底机制,不能默认模型输出的所有内容都是正确的。
没有兜底方案的AI产品,一旦规模化面向C端用户运营,一定会出现严重的用户信任危机。
09 Temperature
同一个Prompt,连续调用三次得到三个完全不同的结果,导致下游系统解析报错,问题往往不是Prompt写得不好,而是Temperature参数设置不当。
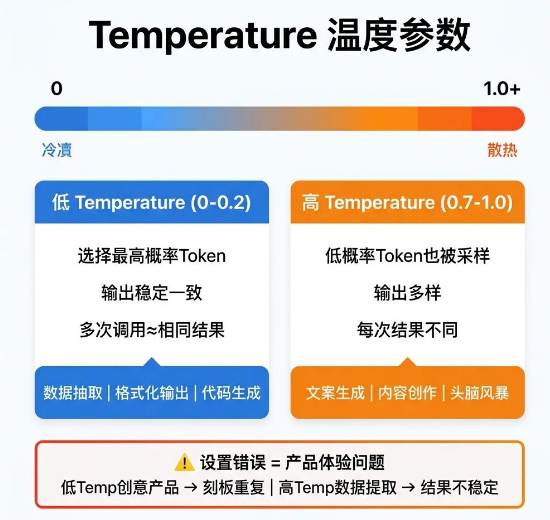
Temperature是控制模型生成内容随机性的核心参数,常规取值范围是0-1,部分模型支持最高到2。
参数设为0或接近0时,模型会优先选择概率最高的Token生成内容,输出结果高度稳定,相同输入多次调用,得到的内容基本一致。
参数调到0.7-1.0及以上时,模型会放宽采样规则,给低概率Token更多生成机会,内容多样性更强,但每次输出结果都会有差异。
不同业务场景需要匹配不同参数:数据抽取、格式化输出、代码生成这类需要精准、统一结果的场景,Temperature设置0-0.2即可;
文案创作、内容 brainstorm、创意生成这类需要多样性的场景,适合设置0.7-1.0的中高参数。
很多AI产品初期体验差、bug多,核心原因就是Temperature参数设置错误。参数过高,数据类场景输出结果不稳定、字段错乱;
参数过低,创意类场景内容刻板、重复严重。功能上线前,务必根据业务场景确定固定的Temperature值,写入配置文档。
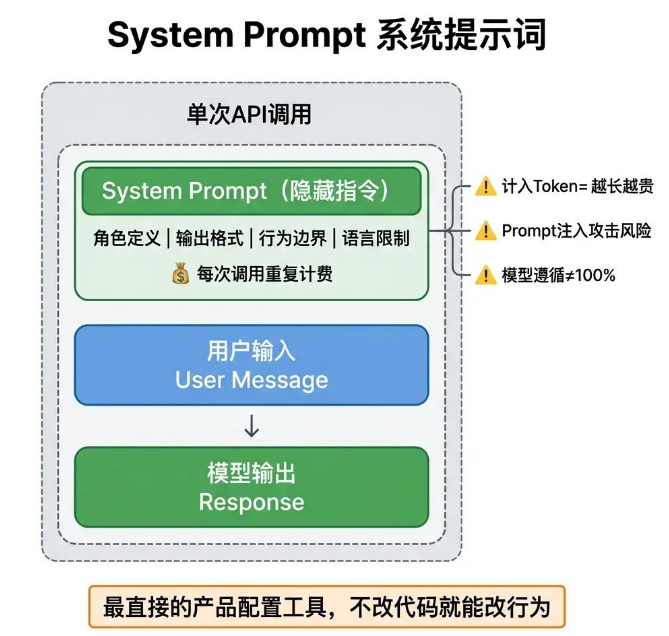
10 System Prompt
想要限制模型只回答产品相关问题,不回应无关内容,System Prompt是最直接、最高效的控制方式,不用修改代码,就能直接规范模型的行为逻辑。
System Prompt是在用户输入内容之前,提前发送给模型的隐藏指令,用来定义模型的角色身份、行为规范、输出格式和能力边界。可以明确要求模型的回复语言、排版格式、身份定位、问答范围、内容字数等各类规则。
大家必须了解三个工程层面的约束条件:
第一,System Prompt会计入输入Token,每次调用都会重复计费,内容越长,单次调用成本越高;
第二,存在Prompt注入攻击风险,用户输入可能覆盖原有指令,面向公网开放的产品,必须做好对应的防御机制;
第三,模型无法100%遵循System Prompt指令,偶尔会出现偏离,产品必须配套后处理校验逻辑,不能完全依赖模型自觉输出。
给大家一个实操建议:写完System Prompt后,用10条真实用户测试样本跑一遍实测,确认模型完全按照预期输出再上线。跳过测试直接上线,后续出现的基本都是低级可规避问题。
11 Chain-of-Thought
直接让模型解答多步骤数学题、复杂逻辑题,模型往往会省略中间推导步骤,直接给出最终答案,出错概率非常高。
Chain-of-Thought(CoT,思维链)的用法很简单,在Prompt中加入“请一步步思考,先列出所有推理步骤,再给出最终结论”,引导模型显性输出完整推导过程。
只要中间步骤完整输出,最终答案的准确率会大幅提升。
这种方法对高推理密度任务效果最明显,比如数学计算、逻辑推断、代码调试、多条件综合判断。
但简单的内容分类、文本提取任务不需要加CoT,多余的推理步骤只会增加输出Token数量,拉高延迟和成本。
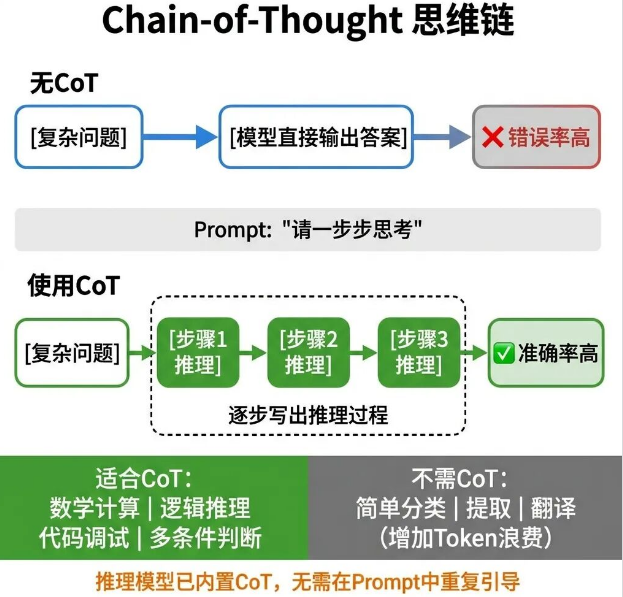
前文提到的推理模型,相当于内置了自动CoT机制,模型会自主完成思维链推理,不需要手动在Prompt中添加引导语句。如果产品已经使用推理模型,再手动加“一步步思考”,只会白白浪费Token。
12 Few-Shot
反复用文字描述输出格式,模型依然不按要求执行,与其堆砌冗长的文字说明,不如直接给2-3组参考示例。
Few-Shot的核心逻辑,是在Prompt中提供多组输入输出的标准示例,让模型参照示例的格式、逻辑和风格,处理新的用户需求。
使用方式就是在System Prompt或用户消息中,放入2-5组标准示例,再输入需要处理的新内容,模型会通过模式匹配,复刻示例的输出规范。
三类场景用Few-Shot效果最好:格式规则复杂,文字描述讲不清楚的输出要求;需要统一标准的内容分类任务;需要固定文风、排版风格的内容创作场景。
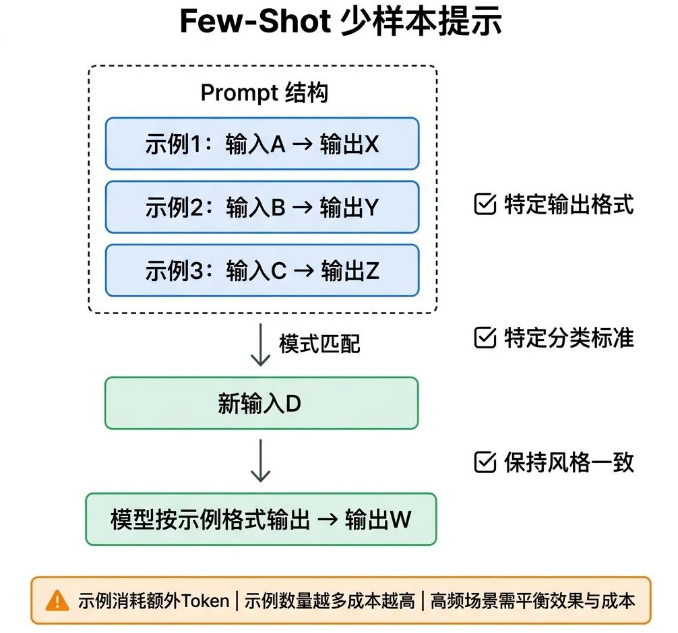
Few-Shot会增加输入Token消耗,示例数量越多、内容越长,Token成本和推理延迟就越高。高频调用场景下要平衡效果和成本,实测下来,2-3组示例是性价比最高的选择。
13 Zero-Shot
拿到全新的AI处理任务,不用第一时间准备示例样本。绝大多数常规场景,完全不需要多余示例。
Zero-Shot就是不提供任何参考示例,仅通过文字描述任务要求,让模型直接完成工作。
目前GPT-4系列、Claude 3系列、Gemini 1.5系列等主流大模型,零示例指令理解能力已经非常成熟,摘要、翻译、分类、内容提取等常规任务,不用示例就能高质量完成。
Prompt设计的最优逻辑是:先尝试Zero-Shot模式,如果输出格式、内容质量不达标,再考虑新增Few-Shot示例优化。不要默认堆砌大量示例,避免不必要的Token消耗和延迟问题。
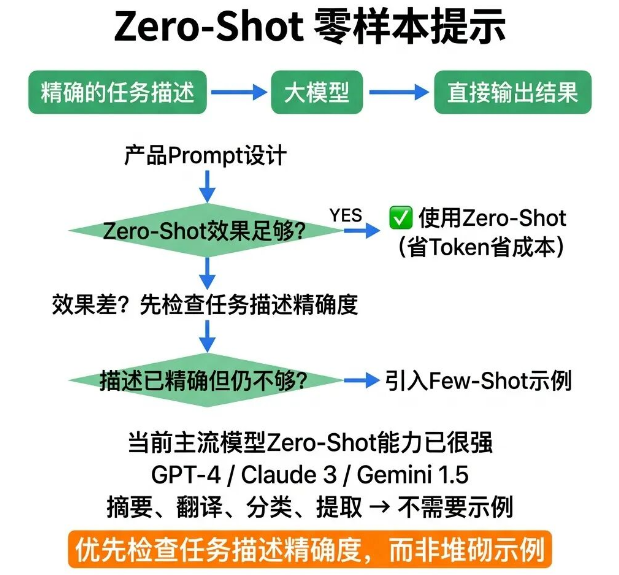
Zero-Shot效果不好时,优先自查任务描述是否精准、清晰,不要一上来就靠加示例解决问题。很多时候输出偏差,是文字指令模糊导致的,不是缺少示例。
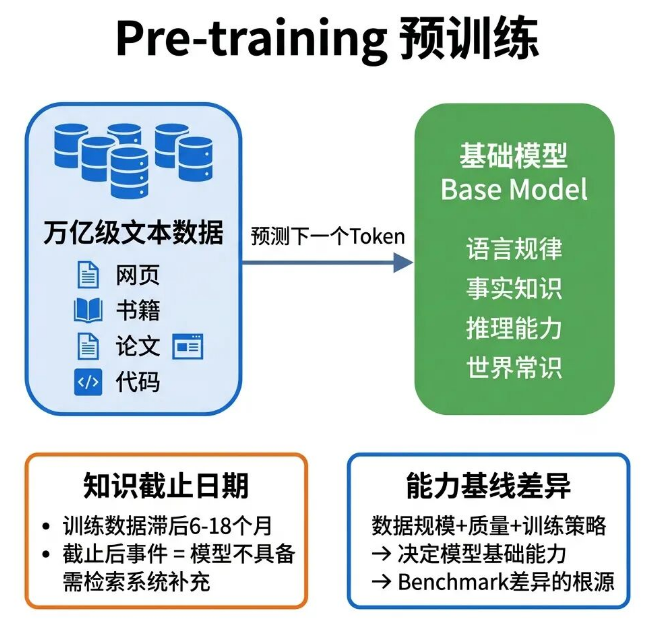
14 Pre-training
模型完全不了解近两个月的热点事件,提问就容易编造内容,核心原因就是预训练数据存在时间截止线。
Pre-training(预训练)是大模型搭建基础能力的核心阶段,也是模型研发成本最高的环节。
预训练阶段,会依托万亿级别的网页、书籍、论文、代码等海量语料数据,通过“预测下一个Token”的核心任务,持续迭代优化模型权重。
这个阶段不会针对性训练特定业务任务,但能让模型自主学习掌握语言规律、通用常识、基础推理能力和海量事实知识。
预训练对产品工作有两个关键影响:第一,预训练数据有明确时间范围,普遍比当前时间滞后6-18个月。
比如2024年Q4发布的模型,训练数据大概率截止到2024年Q1-Q2,截止日期之后的新鲜事件、新增知识,模型完全不了解,也是模型幻觉的高发原因。
涉及时效性的产品功能,必须接入检索系统补充最新数据,不能依赖模型自带知识库。
第二,不同厂商的预训练数据规模、数据质量、训练策略不同,最终模型的基础能力差距也很大,这是各类模型评测分数差异的根本原因,并非单纯由参数量决定。
实操建议:只要产品功能涉及时效性信息,默认配套检索系统补充实时数据,不要指望模型原生知识覆盖所有业务场景。
15 SFT
通用对话模型落地垂直领域时,经常出现专业术语不精准、输出格式不符合企业内部规范的问题,这种情况就可以通过SFT优化解决。
SFT(Supervised Fine-Tuning,监督微调),是在预训练基础模型之上,依托人工标注的指令-回复数据对,做针对性的监督训练,让模型学会精准理解并执行用户指令,这也是基础模型升级为对话模型的关键步骤。
SFT的训练数据是标准化的问答对,输入是各类用户指令,输出是人工筛选、撰写的高质量标准回复。经过微调训练后,模型能精准匹配任务场景,输出符合格式、规范、需求的内容。
对产品工作而言,SFT主要分两种场景:我们日常调用厂商的对话API,都是厂商已经完成SFT微调的成品模型,无需自主训练;
如果通用模型无法满足企业垂直领域的专属需求,比如特殊行业术语、定制化输出格式、企业内部规范,就可以做二次定制SFT微调。
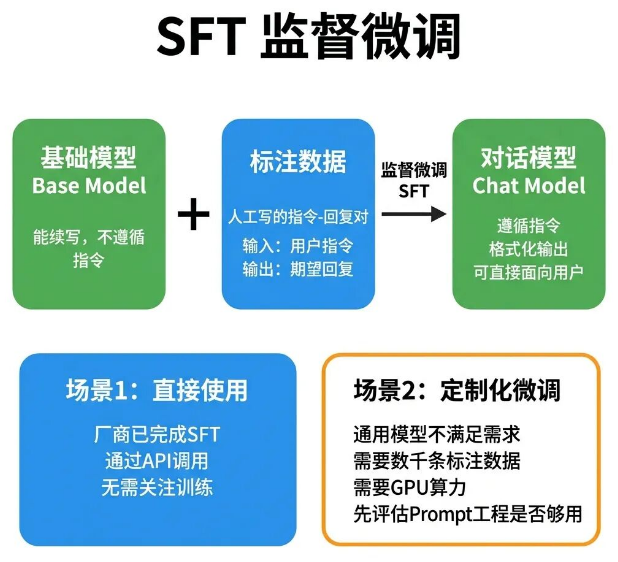
需要注意的是,定制微调至少需要数千条高质量标注数据,同时需要充足的GPU算力支撑,前期启动成本较高。
决策优先级建议:优先通过Prompt工程优化效果,能满足需求就不用做微调。
16 RLHF
同样是开源模型,有的回复合规、实用、贴合用户需求,有的却经常输出不当内容、答非所问,核心差距就来自RLHF优化。
RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习),是在SFT微调的基础上,依托人类偏好反馈,进一步优化模型输出质量的训练方式。
SFT只能让模型学会输出合理内容,但无法区分多组优质回复的优劣,而RLHF就是用来筛选、优化回复偏好的。
其训练逻辑为:标注人员对模型生成的多组回复做优劣排序,用排序数据训练专属奖励模型,再通过强化学习机制,依托奖励信号持续优化模型的生成策略,让模型优先输出更贴合人类偏好的内容。
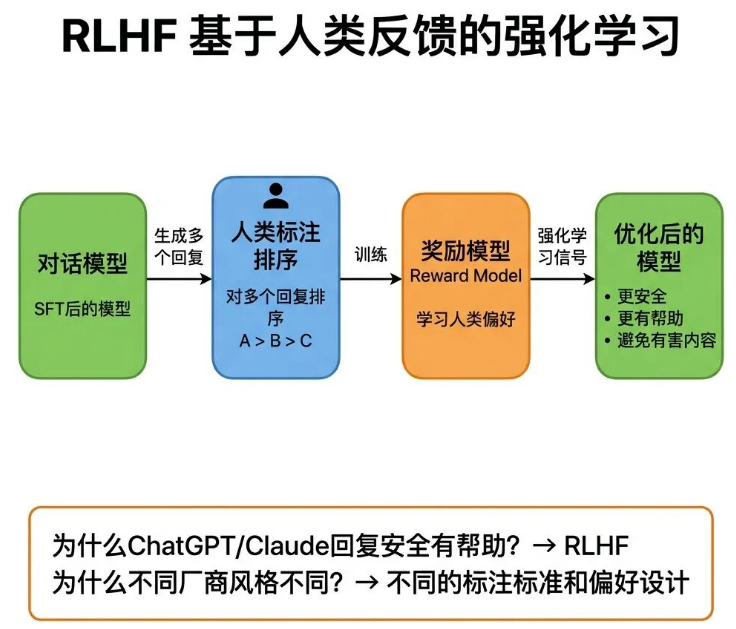
理解RLHF的核心价值,能看懂不同模型的核心差异:各品牌模型的安全限制、回复风格、语气偏好不一样,根本原因是RLHF阶段的人工标注标准、偏好设定不同,并非模型基础能力有差距。
选型时遇到模型过于保守、或者输出过于激进的问题,本质都是RLHF训练偏好导致的。
17 Quantization
直接部署大参数量模型,需要数百GB的GPU显存,硬件成本会大幅超标,量化技术就是降低硬件部署成本的核心方案。
Quantization(量化),是通过降低模型权重的数值精度,缩减模型存储空间、减少推理计算量的技术。
模型原始权重默认以16位浮点数(FP16)存储,量化可以将精度降至8位整数(INT8)或4位整数(INT4),大幅降低存储和计算压力。
量化技术对产品部署的影响主要有三点:
第一,大幅降低成本,INT4量化后的模型,相比原版FP16模型,GPU显存占用减少75%,同等硬件条件下,可以部署更大参数的模型,或承载更多并发请求;
第二,存在轻微质量损耗,量化会降低数值精度,INT4量化模型在部分任务上的准确率会略低于原版,损耗程度随任务类型、量化算法不同有差异;
第三,提升推理速度,量化后的模型运算效率更高,延迟更低,对实时交互类产品十分友好。
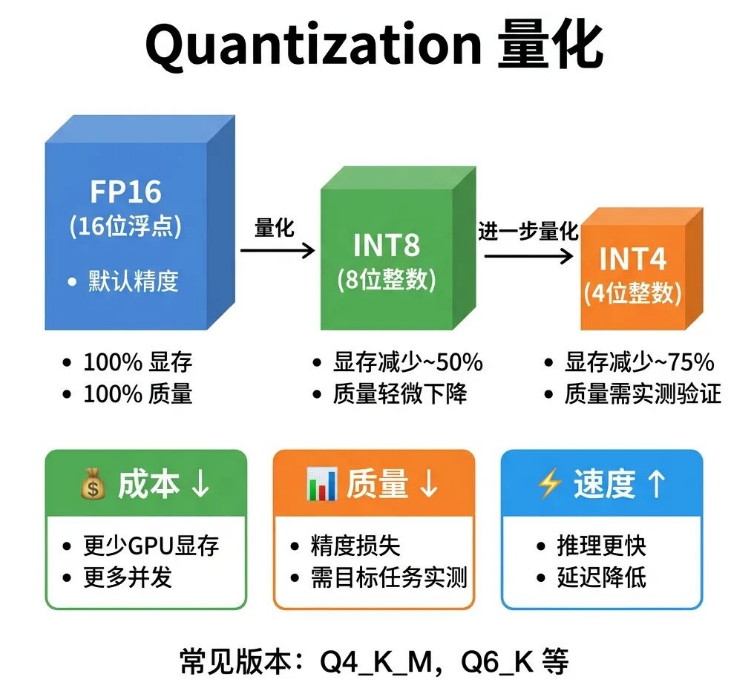
实操建议:选型量化模型时,一定要用自身业务场景数据实测,确认精度损失在可接受范围后,再确定量化等级,不要默认量化模型和原版模型质量完全一致。
18 Parameter Count
对比7B和70B两款模型,大家直觉都会觉得70B模型能力更强,大部分情况确实如此,但并非绝对。
Parameter Count(参数量),指模型中所有可训练权重的总数量,单位为十亿(B),也就是我们常说的7B、70B、405B等规格。关于参数量,有三个反直觉的核心认知:
第一,参数量大不代表能力绝对更强。同等训练质量前提下,大参数量模型综合能力更优,但训练数据质量、微调策略、模型架构的影响同样关键。
一套经过高质量数据精炼训练的7B小模型,在垂直特定任务上,性能可以超过粗制训练的70B大模型。
第二,参数量直接决定部署成本。70B模型以FP16精度部署,需要约140GB显存,至少需要2张A100显卡;405B模型需要约810GB显存,硬件成本成倍上涨。
做私有化部署方案评估时,必须把参数量和GPU硬件成本直接挂钩核算。
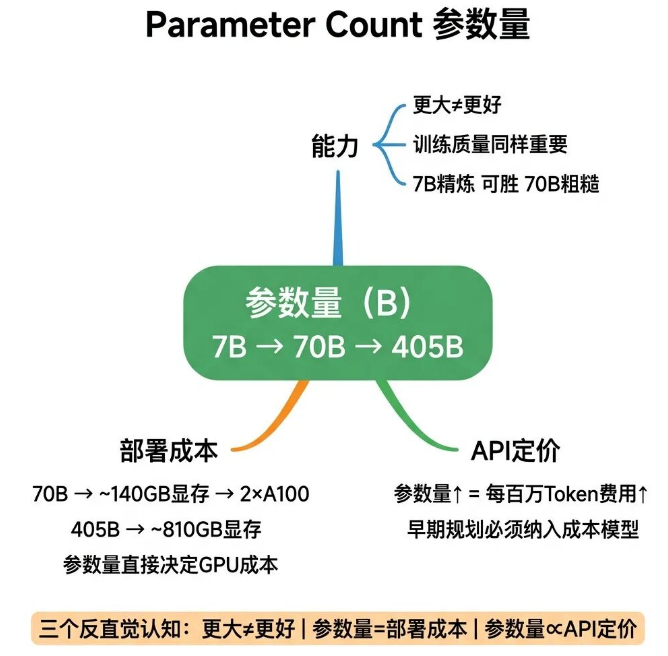
第三,参数量决定API定价。主流大模型的API收费标准,按模型参数量分级,参数越大,每百万Token的调用费用越高。
产品早期规划阶段,就要把参数量、模型能力、调用成本结合起来,优先用小模型试水,满足业务需求就无需升级大模型。
19 Benchmark
很多厂商宣传自家模型MMLU得分92.3%,超越GPT-4,看似性能顶尖,但实际落地业务场景却不好用。核心原因就是Benchmark评测分数不能等同于业务实战能力。
Benchmark(基准评测),是衡量大模型通用能力的标准化测试集,选型可以参考,但不能作为唯一依据。
常见的评测标准有这几种:MMLU覆盖57个学科的知识问答,评估模型的知识广度和理解能力;
MATH包含高中至竞赛级别数学题,用来测评数学推理能力,数学任务准确率低于60%的模型,不适合作为主力模型;
HumanEval专注编程任务,评估代码生成的正确率;
MMLU-Pro、SimpleQA分别对应专业场景知识测评和事实准确性测评。
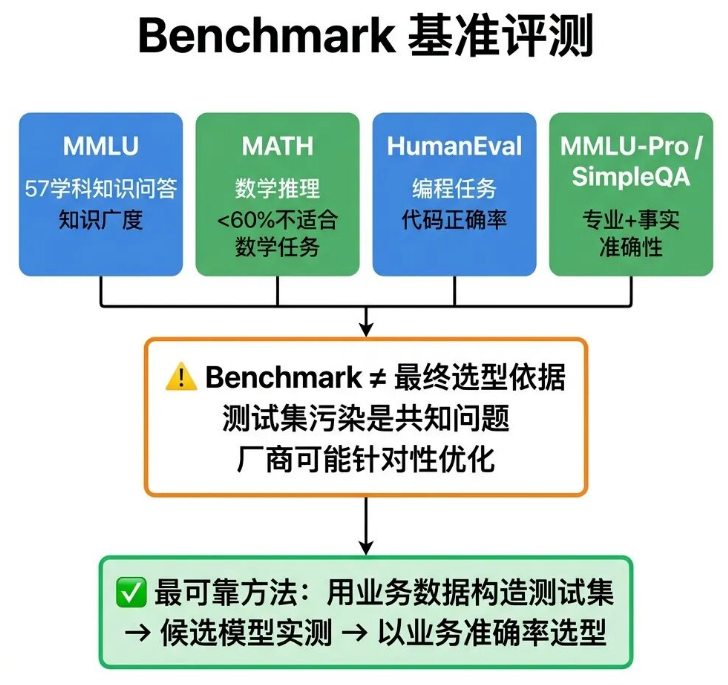
实操选型经验:最靠谱的选型方式,是用自身真实业务数据搭建专属测试集,在候选模型中实战测评,以业务场景的真实准确率为核心选型标准。厂商公开的Benchmark榜单可能存在测试集污染、针对性刷分的情况,只看官方排名极易踩坑。
20 Emergent Ability
小模型完全做不了的多步骤推理、复杂逻辑任务,换成更大参数的模型后,直接就能顺利完成,这不是偶然玄学,而是大模型的涌现能力。
Emergent Ability(涌现能力),指模型的参数量、训练数据规模达到特定阈值后,会突然具备此前完全没有的全新能力,且这种能力无法通过小模型性能线性推算出来。这也解释了为什么模型升级后,很多时候是能力质变,而非简单的量变。
多步骤数学推理、复杂代码调试、多层逻辑判断、跨语言深度理解等任务,都会在特定模型规模阈值下出现能力跃升,阈值以下准确率接近随机猜测,阈值以上准确率快速拉满。
对产品工作的实际价值是:小模型无法实现的功能,直接升级更大参数模型测试,大概率可以解锁全新能力,这是有理论依据的优化思路。
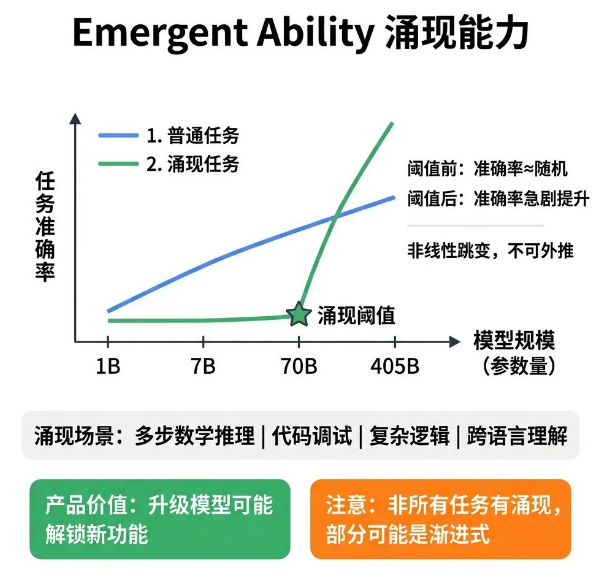
最后明确涌现能力的边界:不是所有任务都有固定涌现阈值,也不是每次模型升级都能解锁新能力。产品优化思路可以固定为:小模型无法落地的任务,先换大模型实测,能实现就落地,再考虑其他优化方案。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)