dbt Core:12.8k Star的数据转换工具,用SELECT语句构建数据管道
文章目录
dbt Core:12.8k Star的数据转换工具,用SELECT语句构建数据管道
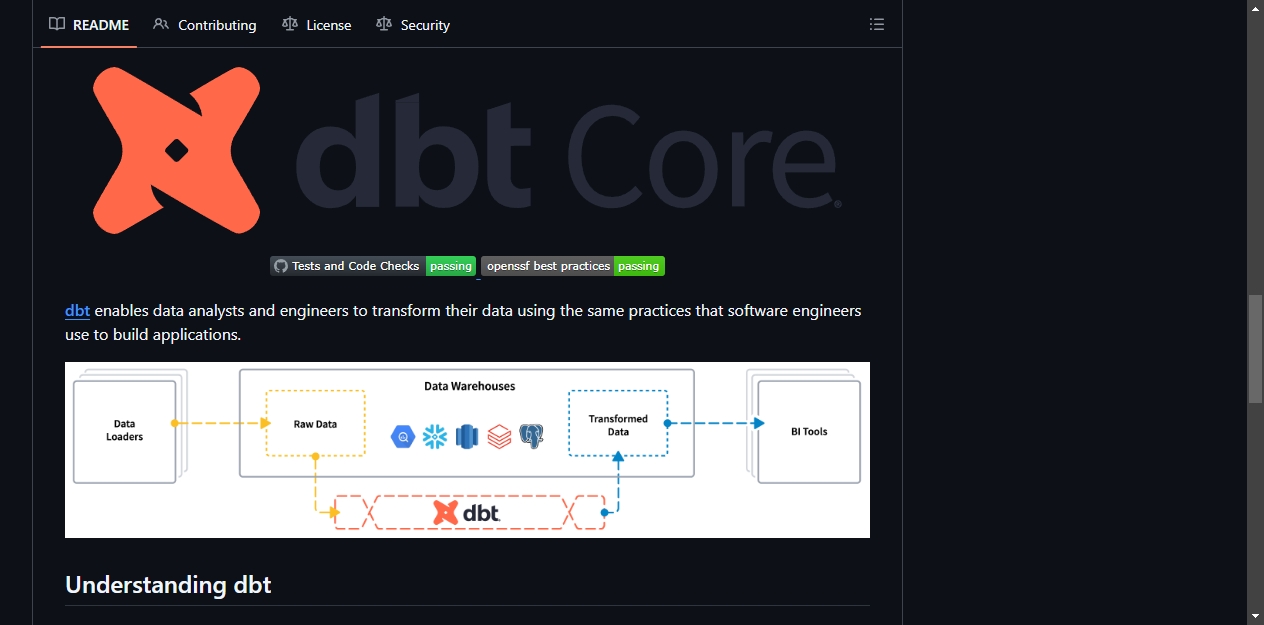
数据团队有一个共同的痛点:SQL脚本越积累越多,表之间的依赖关系逐渐失控,改一张表会影响哪些下游,没人说得清。dbt(data build tool)解决的就是这个问题,它把软件工程里的模块化、测试、文档自动生成这套方法论,搬到了数据仓库内部。
目前在GitHub上获得了12,821个Star,由dbt-labs维护,是数据转换这个细分领域中社区最活跃的开源项目。
核心逻辑:写SELECT就够了
dbt的工作方式很直接。用户只需要写SELECT语句来定义数据转换逻辑,dbt负责把这些SELECT编译成对应的DDL语句,在数据仓库里创建表或视图。
一个SELECT语句在dbt中叫作模型,对应一个SQL文件。所有模型组成一个dbt项目。模型之间通过ref()函数互相引用,dbt自动分析依赖关系,按正确的顺序执行整个转换流程。
举个例子。假设数据仓库里有一张原始订单表,你想建一个聚合后的客户汇总表。传统做法是写一个很长的嵌套SQL脚本,后期维护成本高。在dbt里,你可以拆成两个模型文件:stg_orders.sql做基础清洗,dim_customers.sql引用清洗后的数据做聚合。两个文件各自职责清晰,dbt自动保证先后执行顺序。
当模型数量从几个增长到几百个时,这种模块化拆分带来的可维护性差异会很大。
三个解决实际问题的能力
1. 自动生成数据血缘图
dbt能根据模型之间的引用关系,自动生成有向无环图。你可以直接看到整条数据管道的结构,从原始表到中间表再到最终输出,依赖链路一目了然。
2. 内置数据质量测试
数据质量问题发现得越晚,修复成本越高。dbt允许在模型上附加测试规则,比如某个字段不允许为NULL、某个字段的值必须唯一、某个指标必须落在预设范围内。每次运行dbt时自动执行这些测试,发现异常立即报错。
这种自动化检查比人工抽查可靠。很多团队都是在业务方投诉之后才发现数据出了问题,dbt的测试机制可以把这个反馈周期从周级缩短到分钟级。
3. 文档自动生成
dbt能从项目的模型定义和YAML配置中,自动生成一个静态文档站点。每张表的字段含义、数据来源、下游依赖、测试规则,全部以网页形式展示。不需要额外维护一套独立的文档系统,文档随代码同步更新。
上手门槛
dbt Core是一个Python包,通过pip安装。命令行操作,需要基本的终端使用经验。支持的数据仓库包括Snowflake、BigQuery、Redshift、Databricks、Postgres等,每种数据仓库有对应的适配器插件。
项目结构核心就三个目录:models放SQL模型文件,tests放测试定义,macros放可复用的Jinja模板。dbt使用Jinja作为模板引擎,可以在SQL里写条件判断、循环和变量引用,弥补纯SQL表达能力不足的问题。
社区沟通主要在dbt Community Slack和Discourse,GitHub issue的响应速度较快。
适用范围
dbt适合以下场景:团队以数据仓库为核心基础设施;SQL脚本数量多到管理成本明显上升;团队里有人能操作命令行和Git;希望建立一套标准化的数据转换流程。
不适合的场景:数据量很小、几个Excel就能满足需求;团队完全不接触数据仓库。另外需要注意,dbt只做数据转换这一层,不负责数据的抽取和加载。数据接入还需要Fivetran、Airbyte这类工具来配合。
dbt-labs还提供了付费的dbt Cloud产品,在开源版本上加上了任务调度、在线IDE、团队协作和权限管理等功能。如果把dbt Core比作编译器和执行引擎,dbt Cloud就是加上部署和运维面板的托管版本。核心转换能力完全开源,Cloud解决的是团队协作和托管运行的需求。
d就是加上部署和运维面板的托管版本。核心转换能力完全开源,Cloud解决的是团队协作和托管运行的需求。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)