机器学习中的数据形式转换(TensorFlow VS Numpy)
·
在机器学习中,我们有两个常用的运算库(TensorFlow 和 Numpy),由于库的开发与发展历史的种种原因,他们有着不同的数据形式。Numpy使用数组 array 进行 存储和运算,而TensorFlow 则是使用张量tensor。但其实他们两个长得几乎一模一样,只是用途不同。
# NumPy 数组 (array)
np.array([[200, 17]]) # shape (1,2)
# TensorFlow 张量 (tensor)
tf.constant([[200, 17]]) # shape (1,2) constant指常量,表示张量中的数据不可修改两者的不同在于 tensor 是专门为AI设计的超级数组,主要有下面几点不同。
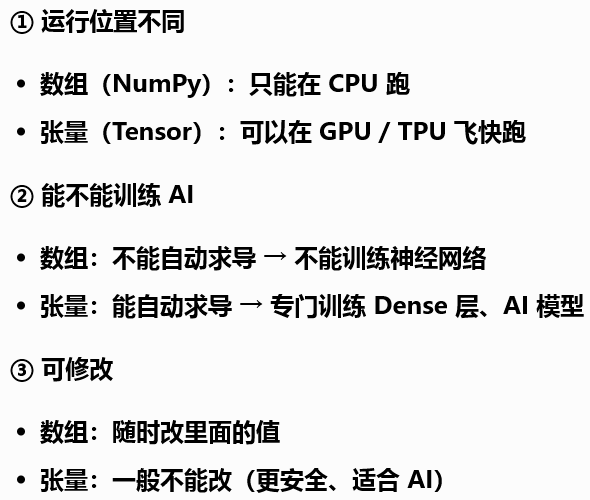
所以,当我们去处理数据的时候需要使用 Numpy ,而在模型训练的时候需要使用 TensorFlow ,对应的也要去使用相应的数据形式。
这里还需要注意对形式的理解
x = np.array([[200, 17]])
print(x.shape) # 输出:(1,2)
x = np.array([[200],[17]])
print(x.shape) # 输出:(2,1)
x = np.array([200,17])
print(x.shape) # 输出:(2,)用一个外层中括号表示数组,内层的中括号表示数据,每一个内层中括号表示一个数据,而内层中括号中数字的个数表示了数据维度的大小。从矩阵的视角来看,外层包整体, 内层是一行, 数字个数是列数, 内层个数是行数。
再者就是数据维度的变换了,在数据训练的过程中,我们常见到对数据维度的变换。但TensorFlow本身可以接受任何维度的张量,决定数据维度的是模型/层。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)