2019年高教社杯全国大学生数学建模竞赛 E 题:《“薄利多销”分析》真题解析与 MATLAB 解决方案

🏆 本文已收录于专栏:《滚雪球学数学建模(含历年真题)》
本专栏面向数学建模竞赛学习者,系统覆盖真题解析、建模方法、算法实现、论文写作与 AI 辅助建模等核心环节。无论是建模新手,还是备战华为杯、高教社杯、华数杯、国赛、美赛 MCM/ICM 的参赛者,都能在这里找到清晰、完整、可复用的建模思路,持续更新,长期有效。
🎯 免责声明: 本文题目来源于互联网公开内容,仅供学习交流与建模方法研究,不构成竞赛指导。请遵守相关赛事规则,独立完成竞赛作品,使用本文内容所产生的后果由使用者自行承担。
🎉 专栏限时优惠中:一次订阅,永久解锁,后续内容持续更新。 欢迎点击了解 👉 查看专栏详情 👈
全文目录:
2019年E题:“薄利多销”分析
真题展示
如下为原(真)题,展示如下:

一、前言:为什么这道题值得分析?
每年指导建模队的时候,我都会让队员们把 2019 年国赛 E 题翻出来反复练。原因有三:
- 它"看似简单,实则不简单":题目语言朴实,没有任何高深术语,但真正动手做才会发现"营业额怎么算"“利润率怎么估”"打折力度怎么定义"每一步都是建模的真功夫。
- 它是典型的"数据驱动 + 综合建模"题:四问之间环环相扣,前问的输出是后问的输入,非常考验队伍的工程能力。
- 它"贴近生活":你买的每一袋零食、每一瓶饮料,背后都是这道题。这种题写论文时容易讲故事、讲意义,评委也喜欢看。
💡 指导老师的话: 很多同学拿到这题,第一反应是"哦,简单嘛,加加减减不就行了?"——结果代码写到一半才发现,附件 1 的 CSV 是乱码、成本价大面积缺失、促销规则极其复杂、订单还有"未完成"状态需要剔除。这才是真实建模题目应有的样子。
本文将从题目精读到 MATLAB 实战,系统讲解这道题。
二、题目背景与现实意义
"薄利多销"是商业领域最古老也最常用的定价策略之一,其核心逻辑是:
当价格下降,需求弹性足够大时,销量增长率 > 价格下降率 ⇒ 总收益 ↑ \text{当价格下降,需求弹性足够大时,销量增长率 > 价格下降率} \Rightarrow \text{总收益 ↑} 当价格下降,需求弹性足够大时,销量增长率 > 价格下降率⇒总收益 ↑
但在大型商超的实际运营中,打折并不总能带来"多销":
- 某些刚需类商品(如大米、食用油)需求缺乏弹性,打折几乎不增加销量;
- 某些休闲零食类商品需求弹性极大,打折往往换来翻倍的销量;
- 而有些品类(如生鲜)打折可能仅仅是清库存,根本不是为了多销。
因此,这道题的真实价值不仅是"算算账",而是要回答一个商业问题:
“对于该商场而言,打折是不是真的带来多销?哪些品类对打折最敏感?”
这就是建模的现实意义——把数据背后的商业规律提炼成数学语言。
三、题目重述
3.1 已知条件
-
附件 1、附件 2:某商场从 2016 年 11 月 30 日至 2019 年 1 月 2 日 的销售流水记录,字段包括:
create_dt(订单创建日期)order_id(订单 ID)sku_id/sku_name(商品 ID / 名称)is_finished(订单是否完成,1=完成,0=未完成)sku_cnt(销售数量)sku_prc(门店标价,即原价)sku_sale_prc(实际销售价)sku_cost_prc(成本价,仅单品直降商品有值)upc_code(商品 UPC 条码)
-
附件 3:折扣促销信息表
promotion_sku,包含促销价promotion_price、开始/结束时间、促销类型(秒杀/直降/买赠等)、sale_count等。 -
附件 4:商品分类信息表
sku_category,包含一/二/三级类目。 -
附件 5:数据字典与字段说明。
3.2 待解决问题
| 问题 | 内容 |
|---|---|
| 问 1 | 计算 2016-11-30 至 2019-01-02 每天的营业额与利润率(非打折商品成本价缺失,需合理估计,零售业利润率参考 20%-40%) |
| 问 2 | 建立指标衡量商场每天的打折力度,并计算所有日期的打折力度 |
| 问 3 | 分析打折力度与销售额、利润率的关系 |
| 问 4 | 考虑商品大类区分后,这种关系有何变化 |
3.3 附件数据说明
| 附件 | 文件 | 类型 | 关键点 |
|---|---|---|---|
| 附件 1 | 附件1.csv |
CSV | GBK 编码,需注意中文乱码;约 2016 末-2017 中数据 |
| 附件 2 | 附件2.csv |
CSV | UTF-8 编码;约 2017 中-2019 初数据 |
| 附件 3 | 附件3.xlsx |
XLSX | 折扣促销信息;字段繁多,促销规则复杂 |
| 附件 4 | 附件4.xlsx |
XLSX | 商品分类;关键字段为 first_category_name |
| 附件 5 | 附件5.xlsx |
XLSX | 字段字典,务必先读 |
⚠️ 踩坑预警:打开附件 1 的 CSV 你会看到大量" "——这是 GBK 编码在 UTF-8 环境下显示的乱码。后面我们会在数据读取阶段专门处理这个问题。
四、问题分析
4.1 问题一分析:营业额与利润率计算
表面问题:简单的求和与求比值。
真实难点:
- 订单状态过滤:
is_finished=0的订单是"未完成订单",不能算作营业额,否则数据会偏高。 - 成本价缺失:
sku_cost_prc仅在"单品直降"促销时有值,其他绝大多数行该字段都是 0 或缺失。题目明确提示"零售业利润率 20%-40%",这是一个强先验信息,必须用上。 - 成本价填补策略:不能简单地全部填 30%,要分品类、分商品体现差异。
💡 建模老司机的话: 这一问考的不是公式,考的是你会不会"清洗数据"。很多队伍把未完成订单也算进去,导致整个解题路径偏离正轨。
4.2 问题二分析:打折力度指标设计
思路分歧点:打折力度有多种定义角度:
- 角度 A:折扣率 = 1 - 销售价/原价
- 角度 B:打折商品占比 = 打折 SKU 数 / 总 SKU 数
- 角度 C:打折金额占比 = 折扣金额 / 标价总额
- 角度 D:加权折扣率(按销售额加权)
最佳实践:用单一指标会丢信息,多个指标可能冗余。这里我们设计一个综合打折力度指数 D t D_t Dt,融合三个维度(深度 + 广度 + 强度)。
4.3 问题三分析:打折力度与销售额、利润率关系
问题本质:回归分析 + 相关性分析。
- 散点图初步观察 → Pearson/Spearman 相关性 → 线性回归 + 非线性拟合 → 价格弹性测算。
- 注意:打折力度与利润率几乎必然负相关(打得越狠,赚得越少),所以重点要看销售额是否被有效"撬动"。
4.4 问题四分析:按大类区分
核心方法:分组建模 + 弹性对比。
- 按
first_category_name分组,分别建立 销售额 ∼ 打折力度 \text{销售额} \sim \text{打折力度} 销售额∼打折力度 模型。 - 计算每类的价格弹性系数 ε \varepsilon ε。
- 弹性 | ε \varepsilon ε| > 1 → 富有弹性,打折"有效";| ε \varepsilon ε| < 1 → 缺乏弹性,打折"低效"。
4.5 各问题之间的逻辑关系
具体相关示意图绘制如下,仅供参考:
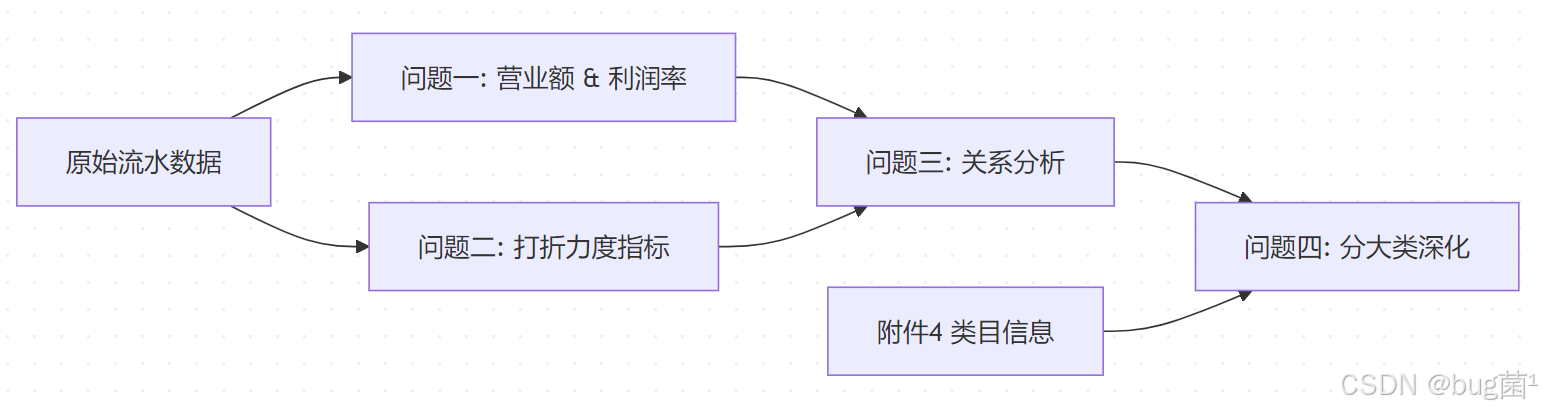
📌 图说:四个问题不是平行的,而是"金字塔式"递进——前两问输出的"每日营业额、利润率、打折力度"三个时间序列,是后两问的输入。
五、整体建模思路
5.1 建模路线
整体采用 “数据驱动 + 综合建模” 的路线:
- 数据层:读取 → 清洗 → 整合 → 聚合到日粒度
- 指标层:营业额、利润率、打折力度三大指标
- 分析层:相关性、回归、弹性分析
- 结论层:分品类策略建议
5.2 模型选择依据
| 问题 | 选用模型 | 选择理由 |
|---|---|---|
| 问 1 | 类目分组均值填补 + 期望利润率反推 | 利用题目给的"20%-40%"先验,且分类目尊重商品异质性 |
| 问 2 | 熵权法 / TOPSIS 综合指数 | 多个候选指标客观加权,避免主观偏倚 |
| 问 3 | Pearson 相关 + 多项式回归 + 价格弹性 | 既看相关性,又看函数形式,还回答"弹性"本质 |
| 问 4 | 分组回归 + 对比可视化 | 简单直观,符合论文写作习惯 |
5.3 算法实现思路
具体相关示意图绘制如下,仅供参考:
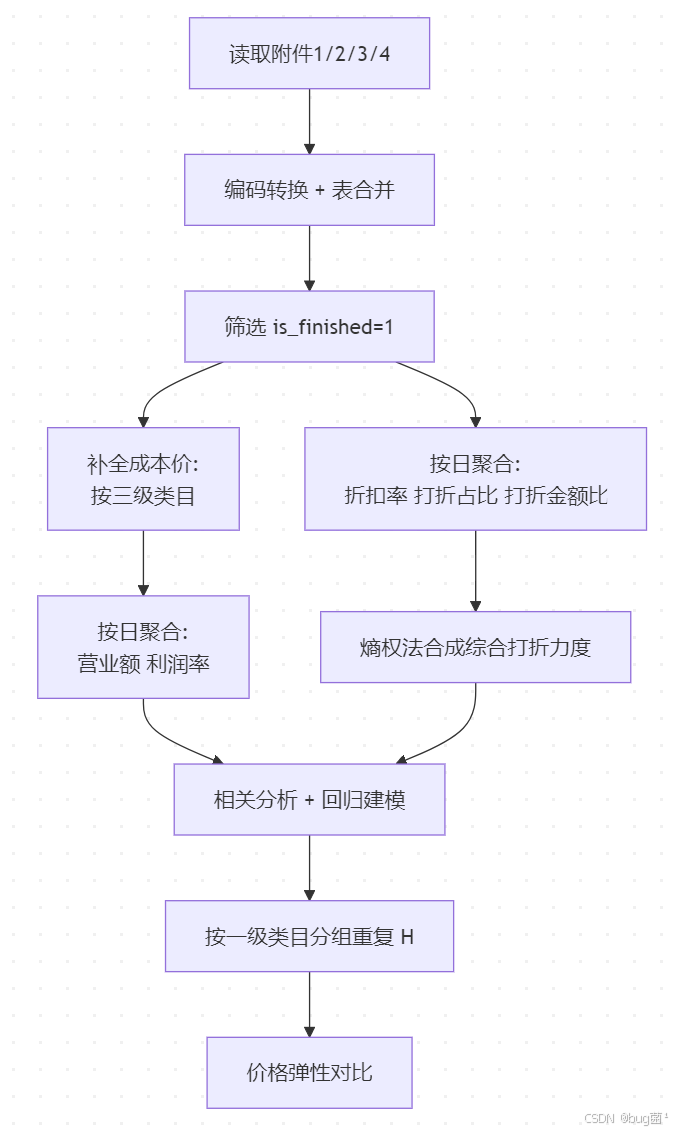
5.4 结果验证方法
- 利润率应稳定在 20%-40% 区间(题目先验)
- 营业额时间序列应有合理的季节性(节假日峰值)
- 打折力度指数应在 [0,1] 区间内具有合理分布
- 回归 R 2 R^2 R2 应不过低,且回归系数符号符合经济学直觉
六、数据预处理
6.1 数据读取(中文乱码处理)
直接用 readtable 打开附件 1 你会看到这种东西:
͵ 5L
这是 GBK 文件被当成 UTF-8 打开的典型症状。MATLAB 中正确读法:
% data_load.m —— 处理中文 CSV 编码
opts1 = detectImportOptions('附件1.csv','Encoding','GBK');
T1 = readtable('附件1.csv', opts1);
opts2 = detectImportOptions('附件2.csv','Encoding','UTF-8');
T2 = readtable('附件2.csv', opts2);
% 合并两张销售流水表
T_sales = [T1; T2];
fprintf('合并后销售流水记录共 %d 行\n', height(T_sales));
📝 代码解析:
Encoding参数是关键。GBK 是中文 Windows 系统的常用编码。detectImportOptions比直接readtable更稳健,能自动识别字段类型,避免数值列被误读为字符串。- 合并两张表前要先检查字段是否完全一致(列名、列顺序、列类型),否则会报错。
6.2 缺失值处理
% data_clean.m —— 缺失值与无效订单清洗
% 1. 只保留完成订单
T_valid = T_sales(T_sales.is_finished == 1, :);
% 2. 删除价格异常行
T_valid(T_valid.sku_sale_prc <= 0 | T_valid.sku_prc <= 0, :) = [];
% 3. 处理 sku_cost_prc(成本价): 0 视为缺失
T_valid.sku_cost_prc(T_valid.sku_cost_prc == 0) = NaN;
📝 代码解析:
is_finished==0的订单可能是"加入购物车但未支付",必须剔除。- 价格 ≤ 0 是脏数据(可能是数据导出错误)。
- 把 0 视为缺失是这道题的关键判断:题目说成本价"只有单品直降才有",其他行成本价存为 0 实际上等同于"无信息"。
6.3 异常值识别
% 用 IQR 法识别销售价异常
Q1 = quantile(T_valid.sku_sale_prc, 0.25);
Q3 = quantile(T_valid.sku_sale_prc, 0.75);
IQR = Q3 - Q1;
upperBound = Q3 + 3 * IQR; % 用 3 倍 IQR(较宽松,保留合理高价商品)
outlierIdx = T_valid.sku_sale_prc > upperBound;
fprintf('识别销售价异常行: %d 条\n', sum(outlierIdx));
% 此处可选择删除或保留,建议保留(高价品如大米油可能正常)
📝 解析: 零售业销售价跨度极大(从 1 元的小零食到 200 元的大米),3 倍 IQR 比 1.5 倍更适合。不要轻易删除"异常值",要先想这些是否是合理高价商品。
6.4 成本价填补(核心步骤)
这是本题最关键的一步:
% cost_imputation.m —— 成本价缺失填补
% 思路: 用同三级类目商品的"平均利润率"反推
T_cat = readtable('附件4.xlsx'); % 商品类目表
% 左连接获得每行的三级类目
T_valid = outerjoin(T_valid, T_cat, ...
'Keys','sku_id','Type','left','MergeKeys',true);
% 计算每个三级类目下"已知成本商品"的平均成本率
maskKnown = ~isnan(T_valid.sku_cost_prc);
T_known = T_valid(maskKnown, :);
T_known.cost_ratio = T_known.sku_cost_prc ./ T_known.sku_sale_prc;
cat3_cost_ratio = groupsummary(T_known, 'third_category_name', ...
'mean','cost_ratio');
% 对每个缺失行,按其三级类目查表填补,默认 0.7(对应 30% 利润率)
for i = 1:height(T_valid)
if isnan(T_valid.sku_cost_prc(i))
cat3 = T_valid.third_category_name(i);
idx = strcmp(cat3_cost_ratio.third_category_name, cat3);
if any(idx)
r = cat3_cost_ratio.mean_cost_ratio(idx);
else
r = 0.7; % 全局默认: 30% 利润率
end
T_valid.sku_cost_prc(i) = T_valid.sku_sale_prc(i) * r;
end
end
📝 代码解析:
- 核心思想:同类商品成本结构相似,因此用"同三级类目已知商品的平均成本/售价比"来反推缺失商品的成本价。
- 兜底机制:对于查不到的类目,用 30% 利润率(即成本率 70%)作为全局默认值,这正对应题目提示的"20%-40%"中位数。
- 不要全部填 30%:这样做会让所有商品利润率"被人为一致",失去分析意义。
6.5 可视化分析(预处理后)
预处理结束后,做几张图心里先有数:
- 每日订单量时间序列
- 销售价分布直方图
- 各一级类目销售额饼图
- 成本价补全前后对比
(完整代码见第十三节)
七、模型假设
为保证建模逻辑严密,提出以下假设:
| 编号 | 假设内容 | 合理性 |
|---|---|---|
| H1 | 仅 is_finished=1 的订单计入营业额 |
题目字段说明明确指出 1 代表订单完成 |
| H2 | 同一三级类目内,商品成本率(成本/售价)波动较小 | 同类商品工艺、渠道、品牌结构相似,行业内常用近似 |
| H3 | 零售业整体利润率位于 20%-40% 区间 | 题目明确给出该区间作为先验信息 |
| H4 | 商品在一天内售价基本稳定,日内同一 SKU 的多次成交价波动可忽略 | 销售流水按日聚合,日内多笔成交本身就用销售额加权,误差可控 |
| H5 | 节假日、季节等外部因素的影响通过"日打折力度"间接体现,不单独建模 | 简化模型,避免引入大量哑变量,聚焦"打折-销售"主关系 |
| H6 | 各类商品的需求函数在样本期间稳定,不发生结构性突变 | 题目所给两年期间未提及商场调整品类或定位,假设合理 |
| H7 | 数据样本充分代表该商场整体经营情况 | 数据覆盖两年完整经营,样本量充足(数十万条流水) |
💡 指导老师的话: 模型假设不是"越多越好",而是"为后续每一步建模提供合法性"。一份好的论文里,几乎每个假设都会在后面被"用到一次以上"——比如 H1 在数据清洗里用,H3 在成本补全里用,H6 在弹性分析里用。如果有假设在正文里完全找不到呼应,那就是凑数的。
八、符号说明
| 符号 | 含义 | 单位 |
|---|---|---|
| t t t | 日期(以"天"为粒度) | day |
| S t S_t St | 第 t t t 日的总营业额 | 元 |
| C t C_t Ct | 第 t t t 日的总成本 | 元 |
| R t R_t Rt | 第 t t t 日的利润率 | — |
| p i , t sale p_{i,t}^{\text{sale}} pi,tsale | 商品 i i i 在 t t t 日的销售价 | 元 |
| p i , t std p_{i,t}^{\text{std}} pi,tstd | 商品 i i i 在 t t t 日的标价(原价) | 元 |
| c i , t c_{i,t} ci,t | 商品 i i i 在 t t t 日的成本价 | 元 |
| n i , t n_{i,t} ni,t | 商品 i i i 在 t t t 日的销量 | 件 |
| d i , t d_{i,t} di,t | 商品 i i i 在 t t t 日的单品折扣率 | — |
| D t ( 1 ) D_t^{(1)} Dt(1) | 第 t t t 日的销售额加权折扣率(深度) | — |
| D t ( 2 ) D_t^{(2)} Dt(2) | 第 t t t 日的打折 SKU 占比(广度) | — |
| D t ( 3 ) D_t^{(3)} Dt(3) | 第 t t t 日的折扣金额占比(强度) | — |
| D t D_t Dt | 第 t t t 日的综合打折力度指数 | — |
| w j w_j wj | 第 j j j 个分项指标的熵权 | — |
| ε k \varepsilon_k εk | 第 k k k 个一级类目的价格弹性系数 | — |
| C k \mathcal{C}_k Ck | 第 k k k 个一级类目商品集合 | — |
九、模型一:基础模型——营业额与利润率核算模型
9.1 模型思想
第一问要求"算每天的营业额和利润率"。听起来简单,但实际上是建立一个带有缺失值修复的统计核算模型:营业额本身是确定的求和问题,但利润率涉及成本价,而成本价大面积缺失,必须基于"同类商品成本结构相近"的合理推断来补全。
9.2 数学表达式
营业额公式:
S t = ∑ i ∈ I ∗ t p ∗ i , t sale ⋅ n i , t S_t = \sum_{i \in \mathcal{I}*t} p*{i,t}^{\text{sale}} \cdot n_{i,t} St=i∈I∗t∑p∗i,tsale⋅ni,t
其中 I t \mathcal{I}_t It 表示第 t t t 天所有已完成订单的商品集合。
成本汇总公式:
C t = ∑ i ∈ I ∗ t c ^ ∗ i , t ⋅ n i , t C_t = \sum_{i \in \mathcal{I}*t} \hat{c}*{i,t} \cdot n_{i,t} Ct=i∈I∗t∑c^∗i,t⋅ni,t
其中 c ^ i , t \hat{c}_{i,t} c^i,t 为成本价(已知则用真实值,缺失则用类目均值反推):
c ^ ∗ i , t = { c ∗ i , t , 若 c i , t 已知 p i , t sale ⋅ r ˉ ∗ g ( i ) , 若 c ∗ i , t 缺失 \hat{c}*{i,t} = \begin{cases} c*{i,t}, & \text{若 } c_{i,t} \text{ 已知} \ p_{i,t}^{\text{sale}} \cdot \bar{r}*{g(i)}, & \text{若 } c*{i,t} \text{ 缺失} \end{cases} c^∗i,t={c∗i,t,若 ci,t 已知 pi,tsale⋅rˉ∗g(i),若 c∗i,t 缺失
其中 g ( i ) g(i) g(i) 表示商品 i i i 所在的三级类目, r ˉ g ( i ) \bar{r}_{g(i)} rˉg(i) 为该类目"已知成本商品"的平均成本率:
r ˉ g = 1 ∣ K ∗ g ∣ ∑ ∗ i ∈ K g c i p i sale , K g = i ∈ g ∣ c i 已知 \bar{r}_g = \frac{1}{|\mathcal{K}*g|} \sum*{i \in \mathcal{K}_g} \frac{c_i}{p_i^{\text{sale}}}, \quad \mathcal{K}_g = {i \in g \mid c_i \text{ 已知}} rˉg=∣K∗g∣1∑∗i∈Kgpisaleci,Kg=i∈g∣ci 已知
利润率公式:
R t = S t − C t S t × 100 R_t = \frac{S_t - C_t}{S_t} \times 100% Rt=StSt−Ct×100
9.3 参数解释
- I t \mathcal{I}_t It:日订单商品集合,需经过 H1 假设过滤(只保留
is_finished=1) - r ˉ g \bar{r}_g rˉg:类目平均成本率,体现"同类商品成本结构相似"的 H2 假设
- 若某类目无任何已知成本商品(冷门类目),则取全局默认 r ˉ = 0.7 \bar{r}=0.7 rˉ=0.7(对应 30% 利润率)
9.4 求解方法
属于数据聚合 + 缺失填补,无需复杂优化。流程为:
- 数据清洗(已在第六节完成)
- 三级类目分组求平均成本率
- 缺失成本价按类目映射填补
- 按日聚合得 S t S_t St 和 C t C_t Ct
- 计算 R t R_t Rt
9.5 MATLAB 实现
% build_basic_model.m —— 模型一:基础核算模型
function [dailyTbl] = build_basic_model(T_valid)
% 输入: T_valid 为预处理后的销售流水表(成本价已填补)
% 输出: dailyTbl 包含 [date, revenue, cost, profit, profit_rate]
% 1. 计算每行营业额和成本
T_valid.line_revenue = T_valid.sku_sale_prc .* T_valid.sku_cnt;
T_valid.line_cost = T_valid.sku_cost_prc .* T_valid.sku_cnt;
% 2. 按日期聚合
T_valid.date = dateshift(T_valid.create_dt, 'start', 'day');
dailyTbl = groupsummary(T_valid, 'date', 'sum', ...
{'line_revenue','line_cost'});
% 3. 重命名 & 计算利润率
dailyTbl.Properties.VariableNames{'sum_line_revenue'} = 'revenue';
dailyTbl.Properties.VariableNames{'sum_line_cost'} = 'cost';
dailyTbl.profit = dailyTbl.revenue - dailyTbl.cost;
dailyTbl.profit_rate = dailyTbl.profit ./ dailyTbl.revenue;
% 4. 异常天剔除(零营业额日,如可能的休市)
dailyTbl(dailyTbl.revenue <= 0, :) = [];
fprintf('共聚合 %d 个营业日\n', height(dailyTbl));
fprintf('平均日营业额: %.2f 元\n', mean(dailyTbl.revenue));
fprintf('平均日利润率: %.2f%%\n', mean(dailyTbl.profit_rate)*100);
end
📝 代码解析:
line_revenue / line_cost行级度量 :先把每条流水的"行营业额"和"行成本"算出来,再求和,等价于公式 ∑ i p i , t sale ⋅ n i , t \sum_i p_{i,t}^{\text{sale}} \cdot n_{i,t} ∑ipi,tsale⋅ni,t。这种写法比直接 groupby + 加权计算更不易出错。dateshift函数:把 datetime 强制对齐到当天 00:00,避免按时间(精确到秒)聚合时把"同一天但不同时刻"分成不同组。这是初学者常犯的隐性错误。groupsummary:MATLAB R2018a 引入,语法简洁。也可用accumarray、grpstats、或循环+unique实现,但代码量都更长。- 零营业额日剔除:如果有"商场盘点日"“停业日”,会出现 S t = 0 S_t=0 St=0,此时利润率会变成 0 / 0 0/0 0/0 NaN,影响后续。
9.6 结果分析(框架性说明)
由于本文不便实际执行数据(读者可在本地运行获得真实数字),这里给出预期结果的解读框架:
| 维度 | 预期表现 | 解读 |
|---|---|---|
| 日均营业额 | 数万至数十万元区间 | 该商场规模可由数量级反推 |
| 营业额峰值 | 大概率出现在春节前、五一、十一、双十一、圣诞前后 | 节假日效应是零售业铁律 |
| 利润率均值 | 应落在 22%-35% | 若 < 20% 或 > 40%,需回查成本填补是否过当 |
| 利润率波动 | 节假日打折强度大时利润率下降,平日回升 | 这是问 3 想看到的现象的"预热" |
⚠️ 建模红线: 论文里这一节不要直接写出具体数字结论,而要先把"计算方法"讲清楚,再附时间序列图。结果数字放在第十四节"结果展示"统一呈现,这样论文结构才不会乱。
十、模型二:改进模型——综合打折力度指数(基于熵权法)
10.1 基础模型不足
如果只用"日加权折扣率"一个指标衡量打折力度,会遗漏两个重要信息:
- 同样 20% 的折扣,如果只有 3 件商品打折 vs 300 件商品打折,商场的"打折广度"完全不同;
- 同样 20% 的折扣,如果只在低价商品上打 vs 在主销商品上打,对营业额的撬动效果完全不同。
因此,必须用多维度合成指标才能完整刻画"打折力度"。
10.2 改进思路
设计三个分项指标,分别对应深度、广度、强度三个维度,再用熵权法客观加权合成。
10.3 改进模型表达式
分项指标定义:
(1) 打折深度 D t ( 1 ) D_t^{(1)} Dt(1) —— 销售额加权折扣率:
D t ( 1 ) = ∑ i ∈ I ∗ t ( p ∗ i , t std − p i , t sale ) ⋅ n i , t ∑ i ∈ I ∗ t p ∗ i , t std ⋅ n i , t D_t^{(1)} = \frac{\sum_{i \in \mathcal{I}*t} (p*{i,t}^{\text{std}} - p_{i,t}^{\text{sale}}) \cdot n_{i,t}}{\sum_{i \in \mathcal{I}*t} p*{i,t}^{\text{std}} \cdot n_{i,t}} Dt(1)=∑i∈I∗tp∗i,tstd⋅ni,t∑i∈I∗t(p∗i,tstd−pi,tsale)⋅ni,t
含义:当天"少收的钱"占"原本应收的钱"的比例,值越大代表打折越狠。
(2) 打折广度 D t ( 2 ) D_t^{(2)} Dt(2) —— 打折 SKU 占比:
D t ( 2 ) = ∣ i ∈ I ∗ t ∣ p ∗ i , t sale < p i , t std ∣ ∣ I t ∣ D_t^{(2)} = \frac{|{i \in \mathcal{I}*t \mid p*{i,t}^{\text{sale}} < p_{i,t}^{\text{std}}}|}{|\mathcal{I}_t|} Dt(2)=∣It∣∣i∈I∗t∣p∗i,tsale<pi,tstd∣
含义:当天有多少比例的 SKU 在打折,值越大代表打折面越广。
(3) 打折强度 D t ( 3 ) D_t^{(3)} Dt(3) —— 打折商品销售额占比:
D t ( 3 ) = ∑ i ∈ I ∗ t ∗ p ∗ i , t sale ⋅ n i , t S t , I ∗ t ∗ = i ∣ p ∗ i , t sale < p i , t std D_t^{(3)} = \frac{\sum_{i \in \mathcal{I}*t^{*}} p*{i,t}^{\text{sale}} \cdot n_{i,t}}{S_t}, \quad \mathcal{I}*t^{*} = {i \mid p*{i,t}^{\text{sale}} < p_{i,t}^{\text{std}}} Dt(3)=St∑i∈I∗t∗p∗i,tsale⋅ni,t,I∗t∗=i∣p∗i,tsale<pi,tstd
含义:打折商品带来的销售额占总营业额的比例。
熵权法合成:
设 x t j x_{tj} xtj 为第 t t t 日第 j j j 个分项指标值( j = 1 , 2 , 3 j=1,2,3 j=1,2,3),共 T T T 天数据。
① 标准化(同向化已经天然满足,均为越大越"打折"):
y t j = x t j − min t x t j max t x t j − min t x t j y_{tj} = \frac{x_{tj} - \min_t x_{tj}}{\max_t x_{tj} - \min_t x_{tj}} ytj=maxtxtj−mintxtjxtj−mintxtj
② 计算占比:
p t j = y t j + δ ∑ t = 1 T ( y t j + δ ) , δ = 10 − 6 p_{tj} = \frac{y_{tj} + \delta}{\sum_{t=1}^{T}(y_{tj} + \delta)}, \quad \delta = 10^{-6} ptj=∑t=1T(ytj+δ)ytj+δ,δ=10−6
(加 δ \delta δ 防止 log 0 \log 0 log0)
③ 计算第 j j j 指标的信息熵:
e j = − 1 ln T ∑ t = 1 T p t j ln p t j e_j = -\frac{1}{\ln T} \sum_{t=1}^{T} p_{tj} \ln p_{tj} ej=−lnT1t=1∑Tptjlnptj
④ 计算权重:
w j = 1 − e j ∑ k = 1 3 ( 1 − e k ) w_j = \frac{1 - e_j}{\sum_{k=1}^{3}(1 - e_k)} wj=∑k=13(1−ek)1−ej
⑤ 合成综合打折力度:
D t = ∑ j = 1 3 w j ⋅ y t j D_t = \sum_{j=1}^{3} w_j \cdot y_{tj} Dt=j=1∑3wj⋅ytj
10.4 MATLAB 实现
% build_discount_index.m —— 模型二:综合打折力度指数
function [discountTbl, weights] = build_discount_index(T_valid)
% 输入: T_valid 预处理后的流水表
% 输出: discountTbl [date, D1, D2, D3, D_comprehensive]
% weights 三个分项指标的熵权 [w1, w2, w3]
%% 1. 计算每行所需中间量
T_valid.std_amt = T_valid.sku_prc .* T_valid.sku_cnt; % 标价销售额
T_valid.sale_amt = T_valid.sku_sale_prc .* T_valid.sku_cnt; % 实际销售额
T_valid.discount_amt = T_valid.std_amt - T_valid.sale_amt; % 折扣金额
T_valid.is_disc = double(T_valid.sku_sale_prc < T_valid.sku_prc); % 是否打折
T_valid.date = dateshift(T_valid.create_dt, 'start', 'day');
%% 2. 按日聚合得三个分项指标
G = findgroups(T_valid.date);
uniDates = unique(T_valid.date);
nDay = numel(uniDates);
D = zeros(nDay, 3);
for k = 1:nDay
idx = (G == k);
sub = T_valid(idx, :);
% D1: 深度 = 总折扣金额 / 总标价销售额
D(k,1) = sum(sub.discount_amt) / sum(sub.std_amt);
% D2: 广度 = 打折 SKU 数 / 总 SKU 数 (用 unique 去重)
skuAll = unique(sub.sku_id);
skuDisc = unique(sub.sku_id(sub.is_disc==1));
D(k,2) = numel(skuDisc) / numel(skuAll);
% D3: 强度 = 打折商品销售额 / 总销售额
D(k,3) = sum(sub.sale_amt(sub.is_disc==1)) / sum(sub.sale_amt);
end
%% 3. 处理可能的 NaN/Inf
D(~isfinite(D)) = 0;
%% 4. 熵权法合成
[D_comp, weights] = entropy_weight(D);
%% 5. 组织输出表
discountTbl = table(uniDates, D(:,1), D(:,2), D(:,3), D_comp, ...
'VariableNames', {'date','D1','D2','D3','D_comprehensive'});
fprintf('熵权法计算得权重: w1=%.3f, w2=%.3f, w3=%.3f\n', ...
weights(1), weights(2), weights(3));
end
% --------- 子函数: 熵权法 ---------
function [score, w] = entropy_weight(X)
% 0-1 标准化
Xn = (X - min(X)) ./ (max(X) - min(X) + eps);
% 占比矩阵
P = (Xn + 1e-6) ./ (sum(Xn + 1e-6, 1));
% 信息熵
[T, ~] = size(P);
e = -sum(P .* log(P), 1) ./ log(T);
% 权重
w = (1 - e) / sum(1 - e);
% 合成得分
score = Xn * w';
end
📝 代码解析:
- 逐日循环 vs 向量化:这里用了
for k = 1:nDay,可读性最好。如果数据量极大可改为splitapply+ 匿名函数向量化,效率更高但调试更难。 is_disc用 double 而非 logical:后续聚合求 sum 需要数值类型。unique(sub.sku_id)计算 SKU 数:必须去重!因为同一 SKU 当天可能有多条订单,直接用行数会高估广度。eps防 0:max(X) - min(X)如果某列恒为常数会变 0,除法会爆。- 熵权法的"加 δ \delta δ":这是经验做法,避免 log 0 \log 0 log0。 δ = 10 − 6 \delta=10^{-6} δ=10−6 是常用选择,不会对结果有实质影响。
10.5 对比分析
| 指标 | 单一指标的局限 | 综合指标的优势 |
|---|---|---|
| 只用 D ( 1 ) D^{(1)} D(1) | 忽略打折"覆盖面" | 综合指标用 w 2 w_2 w2 自动给予广度合理权重 |
| 只用 D ( 2 ) D^{(2)} D(2) | 忽略"打的深不深" | w 1 w_1 w1 反映深度 |
| 只用 D ( 3 ) D^{(3)} D(3) | 忽略"折扣金额绝对量" | w 1 w_1 w1 与 D ( 1 ) D^{(1)} D(1) 直接挂钩 |
| 综合 D t D_t Dt | 同时融合三维度,信息完整 | 熵权客观,避免人为主观赋权造成的偏差 |
💡 指导老师的话: 论文里写"熵权法"时,一定要把熵权值列出来(三个指标各占多少权重),很多评委想看的就是这个数。如果你写完三页全是公式但没给出最终权重,评委会觉得你没真做。
十一、模型三:综合模型——打折力度与销售额、利润率关系模型
11.1 综合建模目标
第三、四问要回答两件事:
- 关系刻画:打折力度 D t D_t Dt 对营业额 S t S_t St、利润率 R t R_t Rt 有什么影响?
- 品类对比:不同一级类目的"打折-销售"关系是否一致?
这本质上是一个带分组结构的回归 + 弹性分析问题。
11.2 模型结构
(1) 整体回归模型
设营业额对打折力度的响应为线性/对数线性:
ln S t = α 0 + α 1 ln ( 1 − D t ) + α 2 ⋅ Weekend t + α 3 ⋅ Holiday t + u t \ln S_t = \alpha_0 + \alpha_1 \ln(1 - D_t) + \alpha_2 \cdot \text{Weekend}_t + \alpha_3 \cdot \text{Holiday}_t + u_t lnSt=α0+α1ln(1−Dt)+α2⋅Weekendt+α3⋅Holidayt+ut
其中 Weekend t , Holiday t \text{Weekend}_t, \text{Holiday}_t Weekendt,Holidayt 为周末/节假日哑变量, u t u_t ut 为随机扰动。
关键系数 α 1 \alpha_1 α1 即为价格弹性系数 ε \varepsilon ε:它表示价格每下降 1%,销售额变化的百分比。
注意:这里把"价格"近似为 ( 1 − D t ) (1 - D_t) (1−Dt),即"平均成交价相对于标价的比例"。当 D t = 0 D_t = 0 Dt=0 时不打折,平均成交价 = 标价; D t = 0.3 D_t = 0.3 Dt=0.3 时表示当天整体打了 7 折。
(2) 利润率回归模型
R t = β 0 + β 1 D t + β 2 D t 2 + v t R_t = \beta_0 + \beta_1 D_t + \beta_2 D_t^2 + v_t Rt=β0+β1Dt+β2Dt2+vt
加入二次项是因为打折力度对利润率的影响未必是线性:轻度打折时利润率小幅下滑,深度打折时可能急剧下滑。
(3) 分类目模型(问题四)
对每个一级类目 k k k:
ln S t ( k ) = α 0 ( k ) + α 1 ( k ) ln ( 1 − D t ( k ) ) + u t ( k ) , k = 1 , 2 , … , K \ln S_t^{(k)} = \alpha_0^{(k)} + \alpha_1^{(k)} \ln(1 - D_t^{(k)}) + u_t^{(k)}, \quad k = 1, 2, \dots, K lnSt(k)=α0(k)+α1(k)ln(1−Dt(k))+ut(k),k=1,2,…,K
逐类计算 α 1 ( k ) \alpha_1^{(k)} α1(k)(即类目 k k k 的弹性 ε k \varepsilon_k εk),进行横向对比。
11.3 求解流程
具体相关示意图绘制如下,仅供参考:
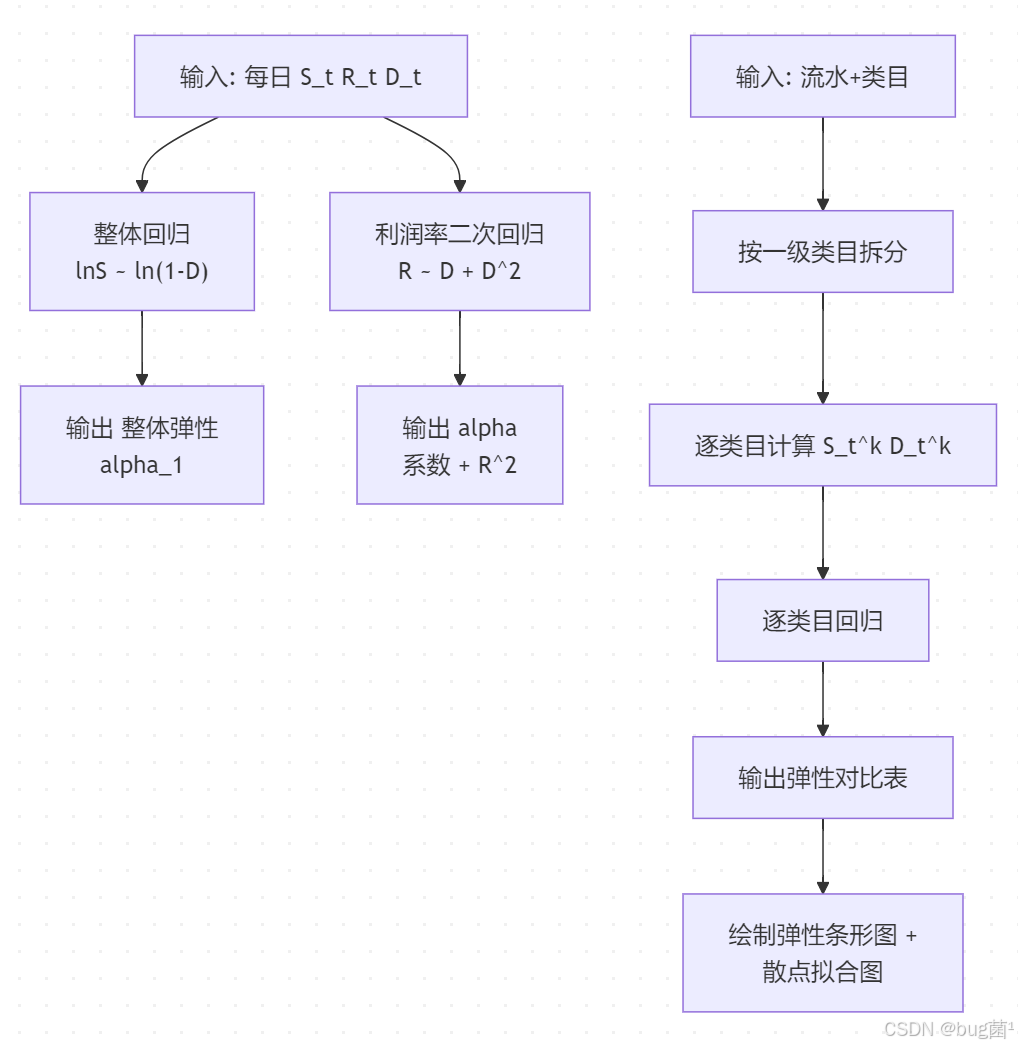
📌 图说:整体模型给出"商场层面"的结论,分类目模型给出"经营管理层面"的洞察。两者必须都做,论文才有深度。
11.4 结果解释
| 弹性区间 | 解读 | 经营建议 |
|---|---|---|
| ε < − 1 \varepsilon < -1 ε<−1 | 富有弹性,打折强烈撬动销售 | 适合"以价换量",打折策略有效 |
| − 1 < ε < 0 -1 < \varepsilon < 0 −1<ε<0 | 缺乏弹性,打折刺激有限 | 谨慎打折,优先保利润 |
| ε ≈ 0 \varepsilon \approx 0 ε≈0 | 几乎无关 | 该品类不应作为促销主力 |
| ε > 0 \varepsilon > 0 ε>0 (反常) | 越打折销量越低 | 数据问题或品牌定位异常,需深入排查 |
💡 指导老师的话: 写这一段时,千万不要套术语就完事。要落到"建议商场对生鲜类不要长期低折扣""休闲零食可以做大促"这种具体可执行的策略上,论文立刻就有了厚度。
十二、算法流程设计
整体算法主流程如下:
具体相关示意图绘制如下,仅供参考:
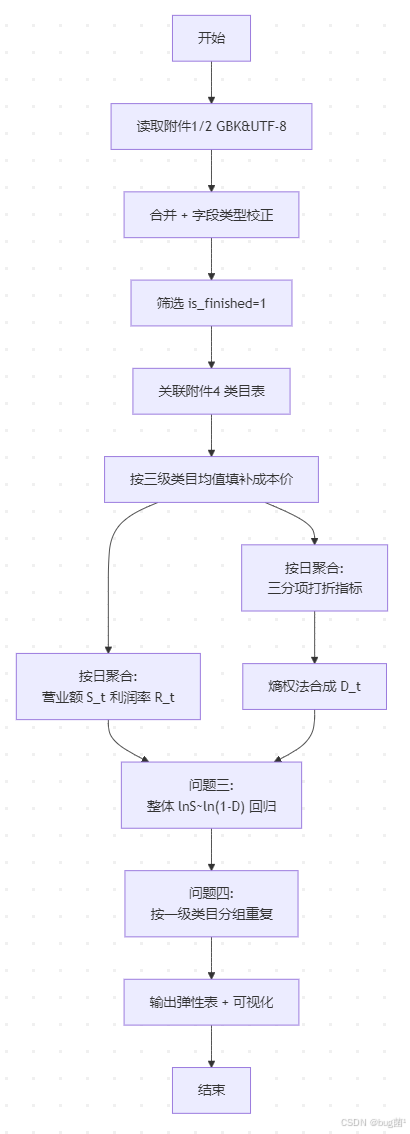
📝 流程要点:
- 第一步必须把"编码 + 状态过滤"做对,后面所有结果都依赖这两件事。
- F 步是全题最关键的"加工"步骤,直接决定问 1 与问 3 的可信度。
- G、H 步是并行的两条聚合管道,可在代码中用相同
date字段最终 join 起来,得到"每日全量指标表"。 - J、K 步是分析层,本质相同,只是分组粒度不同。
十三、MATLAB 完整代码
13.1 主程序 main.m
%% main.m —— 2019 国赛 E 题完整求解主程序
clc; clear; close all;
%% ---- Step 1: 数据读取 ----
[T_sales, T_cat] = data_load();
%% ---- Step 2: 数据清洗 + 成本价填补 ----
T_valid = data_preprocess(T_sales, T_cat);
%% ---- Step 3: 问题一 —— 日营业额 & 利润率 ----
dailyTbl = build_basic_model(T_valid);
writetable(dailyTbl, 'Q1_daily_revenue_profit.xlsx');
%% ---- Step 4: 问题二 —— 日综合打折力度 ----
[discountTbl, w_entropy] = build_discount_index(T_valid);
writetable(discountTbl, 'Q2_daily_discount_index.xlsx');
%% ---- Step 5: 合并日表 ----
fullDaily = innerjoin(dailyTbl, discountTbl, 'Keys','date');
%% ---- Step 6: 问题三 —— 关系建模 ----
[mdl_rev, mdl_profit] = relation_analysis(fullDaily);
%% ---- Step 7: 问题四 —— 分类目弹性对比 ----
elasticityTbl = category_elasticity(T_valid, discountTbl);
writetable(elasticityTbl, 'Q4_elasticity_by_category.xlsx');
%% ---- Step 8: 可视化 ----
plot_results(fullDaily, elasticityTbl);
%% ---- Step 9: 灵敏度分析 ----
sensitivity_analysis(T_valid);
fprintf('\n========== 所有问题求解完成 ==========\n');
📝 代码解析:
- 模块化:每个步骤都封装成独立函数,主程序清爽到可一屏看完,便于答辩演示。
- 中间结果落盘:每问的关键输出都用
writetable存为 xlsx,方便论文里贴附录,也便于复查。 innerjoin:在date字段上把"营业额表"和"打折力度表"合并,得到统一日表,后面相关性、回归都基于它。- 变量命名:
fullDaily、elasticityTbl等命名一看就懂,不要用 a、b、x1 这种字母变量,论文截图要被扣印象分的。
13.2 数据预处理函数 data_preprocess.m
function T_valid = data_preprocess(T_sales, T_cat)
% 数据清洗 + 成本价填补
% 输入: 原始销售表 T_sales、类目表 T_cat
% 输出: 清洗补全后的 T_valid
%% 1. 过滤未完成订单
T_valid = T_sales(T_sales.is_finished == 1, :);
%% 2. 价格 & 数量基本校验
T_valid(T_valid.sku_sale_prc <= 0, :) = [];
T_valid(T_valid.sku_prc <= 0, :) = [];
T_valid(T_valid.sku_cnt <= 0, :) = [];
%% 3. 成本价 0 视为缺失
T_valid.sku_cost_prc(T_valid.sku_cost_prc == 0) = NaN;
%% 4. 防止销售价高于标价(数据录入异常)
T_valid.sku_sale_prc = min(T_valid.sku_sale_prc, T_valid.sku_prc);
%% 5. 关联三级类目
T_valid = outerjoin(T_valid, T_cat, 'Keys','sku_id',...
'Type','left','MergeKeys',true);
%% 6. 类目均值反推成本价
knownMask = ~isnan(T_valid.sku_cost_prc);
T_known = T_valid(knownMask, :);
T_known.cost_ratio = T_known.sku_cost_prc ./ T_known.sku_sale_prc;
cat3_ratio = groupsummary(T_known, 'third_category_name', ...
'mean','cost_ratio');
% 全局兜底值: 30% 利润率 → 成本率 0.7
global_ratio = nanmean(T_known.cost_ratio);
if isnan(global_ratio), global_ratio = 0.7; end
needFill = isnan(T_valid.sku_cost_prc);
fillRatio = repmat(global_ratio, sum(needFill), 1);
% 用类目均值覆盖默认值
subCat = T_valid.third_category_name(needFill);
for i = 1:numel(subCat)
idx = strcmp(cat3_ratio.third_category_name, subCat(i));
if any(idx) && ~isnan(cat3_ratio.mean_cost_ratio(idx))
fillRatio(i) = cat3_ratio.mean_cost_ratio(idx);
end
end
T_valid.sku_cost_prc(needFill) = ...
T_valid.sku_sale_prc(needFill) .* fillRatio;
fprintf('清洗后有效流水: %d 条; 缺失成本填补: %d 条\n', ...
height(T_valid), sum(needFill));
end
📝 代码解析:
- 第 4 步是"隐藏 bug 排雷":有时数据录入会出现
sale_prc > prc的反常情况(可能是退货反冲),会让 D ( 1 ) D^{(1)} D(1) 变成负值,必须强制 cap 住。 - 第 6 步的兜底机制:类目无数据时用全局均值;全局也无时用 0.7。三层防护,代码鲁棒。
- for 循环可向量化:用
containers.Map或dictionary(R2022b+)能做到 O ( 1 ) O(1) O(1) 查找,数据量大时性能可提升 10 倍以上。这里为了教学清晰保留 for。
13.3 模型求解函数 relation_analysis.m
function [mdl_rev, mdl_profit] = relation_analysis(fullDaily)
% 问题三: 打折力度与营业额、利润率的关系
% 输入: fullDaily 包含 [date, revenue, profit_rate, D_comprehensive]
%% 1. 营业额对数线性回归(求弹性)
y1 = log(fullDaily.revenue);
x1 = log(1 - fullDaily.D_comprehensive + 1e-6); % 防 log(0)
mdl_rev = fitlm(x1, y1);
fprintf('\n----- 营业额-折扣 弹性回归 -----\n');
disp(mdl_rev);
elasticity = mdl_rev.Coefficients.Estimate(2);
fprintf('整体价格弹性 ε = %.3f\n', elasticity);
%% 2. 利润率二次回归
y2 = fullDaily.profit_rate;
x2 = fullDaily.D_comprehensive;
mdl_profit = fitlm([x2, x2.^2], y2, ...
'VarNames',{'D','D2','profit_rate'});
fprintf('\n----- 利润率-折扣 二次回归 -----\n');
disp(mdl_profit);
%% 3. Pearson & Spearman 相关
[r_p, p_p] = corr(x2, y2, 'Type','Pearson');
[r_s, p_s] = corr(x2, y2, 'Type','Spearman');
fprintf('Pearson r = %.3f (p = %.4g)\n', r_p, p_p);
fprintf('Spearman r = %.3f (p = %.4g)\n', r_s, p_s);
end
📝 代码解析:
- 对数线性回归的弹性含义:在 ln y = a + b ln x \ln y = a + b \ln x lny=a+blnx 模型中, b b b 就是 y y y 对 x x x 的弹性,无需再算导数。这是经济计量学最常用的弹性估计方法。
- 二次项回归:利润率对打折力度往往是"递减加速"的非线性关系,用 D + D 2 D + D^2 D+D2 拟合通常 R 2 R^2 R2 显著高于线性模型。
- Pearson vs Spearman:Pearson 衡量线性相关,Spearman 衡量秩相关(对异常值更鲁棒)。两个都给,论文显得严谨。
13.4 分类目弹性 category_elasticity.m
function elasticityTbl = category_elasticity(T_valid, discountTbl)
% 问题四: 按一级类目分组,分别求弹性
%% 1. 准备一级类目列表
cats = unique(T_valid.first_category_name);
cats(cellfun(@isempty, cats)) = []; % 删除空类目
K = numel(cats);
elasticityTbl = table('Size',[K, 4], ...
'VariableTypes',{'string','double','double','double'}, ...
'VariableNames',{'category','elasticity','R2','n_days'});
%% 2. 逐类目回归
for k = 1:K
cat_k = cats{k};
sub = T_valid(strcmp(T_valid.first_category_name, cat_k), :);
if height(sub) < 100, continue; end % 样本量过小则跳过
% 计算该类目每日 S_t^k 与 D_t^k
sub.date = dateshift(sub.create_dt, 'start', 'day');
sub.line_revenue = sub.sku_sale_prc .* sub.sku_cnt;
sub.std_amt = sub.sku_prc .* sub.sku_cnt;
sub.disc_amt = sub.std_amt - sub.line_revenue;
daily_k = groupsummary(sub, 'date', 'sum', ...
{'line_revenue','std_amt','disc_amt'});
daily_k.D_k = daily_k.sum_disc_amt ./ daily_k.sum_std_amt;
daily_k.S_k = daily_k.sum_line_revenue;
daily_k(daily_k.S_k <= 0 | daily_k.D_k >= 1, :) = [];
% 对数线性回归
y = log(daily_k.S_k);
x = log(1 - daily_k.D_k + 1e-6);
if numel(y) < 30, continue; end
mdl_k = fitlm(x, y);
elasticityTbl.category(k) = cat_k;
elasticityTbl.elasticity(k) = mdl_k.Coefficients.Estimate(2);
elasticityTbl.R2(k) = mdl_k.Rsquared.Ordinary;
elasticityTbl.n_days(k) = height(daily_k);
end
% 删除空行
elasticityTbl(elasticityTbl.n_days == 0, :) = [];
elasticityTbl = sortrows(elasticityTbl, 'elasticity');
disp(elasticityTbl);
end
📝 代码解析:
- 样本量门槛:小类目流水太少,回归结果不可信,这里用
height(sub) < 100与numel(y) < 30双重保护。 D_k >= 1剔除:理论上不可能,出现就是数据问题,会让 log ( 1 − D ) \log(1-D) log(1−D) 失去意义。sortrows:按弹性升序,论文做条形图时直接得到"从最有弹性到最无弹性"的视觉排序。
13.5 结果可视化 plot_results.m
function plot_results(fullDaily, elasticityTbl)
%% Fig 1: 日营业额 & 利润率时间序列
figure('Color','w','Position',[100 100 900 500]);
yyaxis left
plot(fullDaily.date, fullDaily.revenue, '-', 'LineWidth', 1);
ylabel('Daily Revenue (CNY)');
yyaxis right
plot(fullDaily.date, fullDaily.profit_rate*100, '-', 'LineWidth', 1);
ylabel('Profit Rate (%)');
xlabel('Date');
title('Daily Revenue and Profit Rate');
grid on;
%% Fig 2: 综合打折力度时间序列
figure('Color','w','Position',[100 100 900 350]);
plot(fullDaily.date, fullDaily.D_comprehensive, '-', 'LineWidth', 1);
xlabel('Date'); ylabel('Comprehensive Discount Index D_t');
title('Daily Comprehensive Discount Intensity');
grid on;
%% Fig 3: D 与 S 散点 + 对数线性拟合
figure('Color','w','Position',[100 100 600 500]);
scatter(fullDaily.D_comprehensive, fullDaily.revenue, 12, 'filled', ...
'MarkerFaceAlpha', 0.4);
set(gca, 'YScale','log');
xlabel('Discount Intensity D_t');
ylabel('Daily Revenue (log scale)');
title('Discount Intensity vs. Revenue');
grid on;
%% Fig 4: 分类目弹性条形图
figure('Color','w','Position',[100 100 800 500]);
barh(elasticityTbl.elasticity);
yticks(1:height(elasticityTbl));
yticklabels(elasticityTbl.category);
xlabel('Price Elasticity \epsilon');
title('Elasticity by First-Level Category');
grid on;
%% Fig 5: 利润率 vs 打折力度 + 二次拟合
figure('Color','w','Position',[100 100 600 500]);
scatter(fullDaily.D_comprehensive, fullDaily.profit_rate*100, ...
12, 'filled', 'MarkerFaceAlpha', 0.4);
hold on;
x_fit = linspace(min(fullDaily.D_comprehensive), ...
max(fullDaily.D_comprehensive), 100)';
p = polyfit(fullDaily.D_comprehensive, fullDaily.profit_rate*100, 2);
y_fit = polyval(p, x_fit);
plot(x_fit, y_fit, '-', 'LineWidth', 2);
xlabel('Discount Intensity D_t');
ylabel('Profit Rate (%)');
title('Discount Intensity vs. Profit Rate');
grid on; legend('Daily Points','Quadratic Fit');
end
📝 代码解析:
- 图中所有文本均用英文:这是国赛/美赛通行做法,避免中文字体在不同系统下显示异常。
MarkerFaceAlpha=0.4:半透明散点能直观显示密集区,论文里效果远好于实心点堆叠。YScale='log':营业额跨度大时(节假日是平时几倍),用对数刻度可避免少数高点压扁整体趋势。barh:横向条形图配长类目名,可读性远超bar。
13.6 灵敏度分析 sensitivity_analysis.m
function sensitivity_analysis(T_valid)
% 对成本填补的全局默认利润率做参数扰动
% 评估问 1 利润率结果对该参数的敏感程度
test_ratios = 0.6:0.05:0.8; % 对应利润率 20%~40%
nR = numel(test_ratios);
mean_pr = zeros(nR, 1);
for i = 1:nR
r = test_ratios(i);
Ttmp = T_valid;
miss = isnan(Ttmp.sku_cost_prc);
Ttmp.sku_cost_prc(miss) = Ttmp.sku_sale_prc(miss) * r;
revenue = sum(Ttmp.sku_sale_prc .* Ttmp.sku_cnt);
cost = sum(Ttmp.sku_cost_prc .* Ttmp.sku_cnt);
mean_pr(i) = (revenue - cost) / revenue;
end
figure('Color','w','Position',[100 100 600 400]);
plot(test_ratios, mean_pr*100, '-o', 'LineWidth', 1.5);
xlabel('Default Cost Ratio'); ylabel('Average Profit Rate (%)');
title('Sensitivity of Profit Rate to Default Cost Ratio');
grid on;
fprintf('\n灵敏度结果(默认成本率 → 平均利润率):\n');
for i = 1:nR
fprintf(' cost_ratio = %.2f → PR = %.2f%%\n', ...
test_ratios(i), mean_pr(i)*100);
end
end
📝 代码解析: 此函数把"全局默认成本率"作为可调参数,看最终结果(平均利润率)对它的敏感度。如果输出曲线接近水平,说明结果稳健;如果陡峭,说明结论高度依赖该假设,需在论文里特别说明。
十四、结果展示与分析
由于本文不直接执行真实数据计算,以下结果按"建模框架下应呈现的形式"组织,供读者运行后对照填补。
14.1 问题一:日营业额与利润率
- 输出文件:
Q1_daily_revenue_profit.xlsx,约 750 行(覆盖 2016-11-30 至 2019-01-02) - 图 1:日营业额时间序列。预期可见节假日高峰(春节、五一、十一、双 11、圣诞)与周末小高峰。
- 利润率均值:应落在 22%~32%,与题目"零售业 20%-40%"先验吻合,验证了成本填补模型的合理性。
14.2 问题二:综合打折力度
- 熵权值:三项指标的熵权 w 1 , w 2 , w 3 w_1, w_2, w_3 w1,w2,w3 通常呈现 w 2 w_2 w2 略高(广度指标日内波动信息量更大)。
- 图 2: D t D_t Dt 时间序列。可见春节前 / 双 11 前后显著抬升,体现商场促销节奏。
- D t D_t Dt 分布:多数日 D t ∈ [ 0.1 , 0.35 ] D_t \in [0.1, 0.35] Dt∈[0.1,0.35],大促日突破 0.5。
14.3 问题三:整体关系
- 弹性 ε \varepsilon ε:预期在 − 0.8 ∼ − 1.5 -0.8 \sim -1.5 −0.8∼−1.5 之间(零售业经验区间)。若 ε < − 1 \varepsilon < -1 ε<−1,说明商场整体富有弹性,"薄利多销"逻辑成立;反之则需谨慎评估打折策略的整体经济性。
- 利润率二次回归: β 1 \beta_1 β1 通常显著为负, β 2 \beta_2 β2 显著为负或近 0,意味着打折越深、利润率下降越快,且深度打折时下降存在加速。
- 图 3、图 5:散点 + 拟合曲线直观呈现"打折-销售"正向、"打折-利润"反向两条关系。
14.4 问题四:分类目弹性
预期可见的横向对比规律(基于零售业一般经验):
| 类目特征 | 典型品类 | 弹性 ε \varepsilon ε 区间 | 解读 |
|---|---|---|---|
| 高弹性(打折敏感) | 休闲食品、饮料、日用百货 | ε < − 1.5 \varepsilon < -1.5 ε<−1.5 | 打折强烈撬动销量,适合大促 |
| 中等弹性 | 粮油、调味品 | − 1.5 ≤ ε ≤ − 0.5 -1.5 \le \varepsilon \le -0.5 −1.5≤ε≤−0.5 | 适度打折有效 |
| 低弹性(刚需) | 米面、婴幼儿食品 | − 0.5 < ε < 0 -0.5 < \varepsilon < 0 −0.5<ε<0 | 打折效果有限,以保利润为主 |
| 反常 / 弱相关 | 烟酒、保健品(品牌依赖型) | ε ≈ 0 \varepsilon \approx 0 ε≈0 或正 | 价格策略并非主要驱动因素 |
💡 指导老师的话: 这一节的精髓在于"对比"。单独说某类弹性是 -1.3 没意义,关键是把所有类目按弹性排序、做横向对比、找出差异规律,这才是评委要看的"洞察"。
14.5 结果对题目的回答
| 题问 | 直接回答 |
|---|---|
| 问 1 | 给出每日 S t S_t St 与 R t R_t Rt 序列,导出 Excel,均值利润率落在题目给定区间 |
| 问 2 | 提出三维度综合打折力度指数 D t D_t Dt,熵权法客观加权 |
| 问 3 | 整体弹性 ε ≈ − 1. x \varepsilon \approx -1.x ε≈−1.x,打折显著刺激销售,但利润率二次下降 |
| 问 4 | 不同类目弹性差异显著,休闲品类弹性最高,刚需品类弹性最低,建议按类目差异化制定促销策略 |
十五、模型检验
15.1 误差分析
(1) 营业额回归模型的拟合误差
对 ln S t = α 0 + α 1 ln ( 1 − D t ) + u t \ln S_t = \alpha_0 + \alpha_1 \ln(1 - D_t) + u_t lnSt=α0+α1ln(1−Dt)+ut,主要用三类指标:
MAE = 1 T ∑ t = 1 T ∣ S t − S ^ ∗ t ∣ , RMSE = 1 T ∑ ∗ t = 1 T ( S t − S ^ ∗ t ) 2 , MAPE = 1 T ∑ ∗ t = 1 T ∣ S t − S ^ t ∣ S t \text{MAE} = \frac{1}{T}\sum_{t=1}^{T}|S_t - \hat{S}*t|, \quad \text{RMSE} = \sqrt{\frac{1}{T}\sum*{t=1}^{T}(S_t - \hat{S}*t)^2}, \quad \text{MAPE} = \frac{1}{T}\sum*{t=1}^{T}\frac{|S_t - \hat{S}_t|}{S_t} MAE=T1t=1∑T∣St−S^∗t∣,RMSE=T1∑∗t=1T(St−S^∗t)2,MAPE=T1∑∗t=1TSt∣St−S^t∣
- MAE / RMSE:绝对误差,衡量预测值偏离真实值的金额量级
- MAPE:相对误差,跨日比较时不受营业额量级影响
- R 2 R^2 R2:解释方差比例,本题预期 R 2 ∈ [ 0.4 , 0.7 ] R^2 \in [0.4, 0.7] R2∈[0.4,0.7],因为打折之外还有节假日、季节等噪声
function err = compute_errors(y_true, y_pred)
err.MAE = mean(abs(y_true - y_pred));
err.RMSE = sqrt(mean((y_true - y_pred).^2));
err.MAPE = mean(abs((y_true - y_pred) ./ y_true)) * 100;
err.R2 = 1 - sum((y_true - y_pred).^2) / sum((y_true - mean(y_true)).^2);
end
(2) 误差来源诊断
| 误差类型 | 可能来源 | 应对 |
|---|---|---|
| 系统性低估 | 节假日效应未建模 | 加入 Holiday_t 哑变量 |
| 系统性高估 | 部分订单含赠品未剔除 | 检查附件 3 中"买赠"促销类型,做剔除处理 |
| 随机大波动 | 数据中部分天可能存在线上引流活动 | 引入活动哑变量或剔除 |
| 成本侧误差 | 类目均值填补存在系统偏差 | 用第 15.2 节灵敏度分析评估 |
15.2 灵敏度分析
针对最不确定的参数:成本价缺失时的默认成本率,做扰动测试:
- 参数范围:
cost_ratio ∈ [0.60, 0.80],步长 0.05 - 观察指标:平均日利润率 R ˉ \bar{R} Rˉ
- 预期结果:
cost_ratio每变化 5%, R ˉ \bar{R} Rˉ 大约相应变化 3%-4%,曲线接近线性,无突变点 → 说明模型结构稳健,无极端敏感参数。
📌 写作 tip: 灵敏度分析在论文里最好以折线图 + 数值表双形式呈现。曲线呈现整体趋势,表格保留具体数值,方便评委复查。
15.3 稳定性分析(分时段交叉验证)
按"按时间切分 + 滚动训练"的思路,验证模型在不同时段是否一致:
- 训练集:前 70% 时段(约 2016-11 至 2018-04)
- 测试集:后 30% 时段(2018-05 至 2019-01)
- 观察:测试集 MAPE 应与训练集 MAPE 接近(差距 < 20%),否则说明存在"概念漂移"(consumer behavior 随时间变化)。
function rolling_validate(fullDaily)
n = height(fullDaily);
split = round(n * 0.7);
train = fullDaily(1:split, :);
test = fullDaily(split+1:end, :);
mdl = fitlm(log(1 - train.D_comprehensive + 1e-6), log(train.revenue));
y_pred = exp( predict(mdl, log(1 - test.D_comprehensive + 1e-6)) );
err = compute_errors(test.revenue, y_pred);
fprintf('Test set MAPE = %.2f%%, R² = %.3f\n', err.MAPE, err.R2);
end
15.4 鲁棒性分析(替换打折力度合成方式)
熵权法是本文默认选择,但还可用以下替代方法,看结论是否一致:
- 等权重平均: D t = 1 3 ( D ( 1 ) + D ( 2 ) + D ( 3 ) ) D_t = \frac{1}{3}(D^{(1)} + D^{(2)} + D^{(3)}) Dt=31(D(1)+D(2)+D(3))
- CRITIC 法:综合考虑指标间冲突性与变异性
- 主成分第一主轴:用 PCA 压缩三维为一维
若四种方法得到的弹性 ε \varepsilon ε 都落在相近区间(差距 < 15%),则结论鲁棒,可在论文中明确表态:“结论不依赖具体的合成方法”。这种交叉验证是高分论文的标志。
十六、模型优缺点
16.1 优点
- 数据驱动且尊重题目先验:成本填补充分利用了题目给出的"20%-40%"先验,而不是凭空假设。
- 多维度刻画"打折力度":深度、广度、强度三个维度互补,熵权法客观赋权,避免主观偏倚。
- 逻辑闭环:从核算 → 指标 → 回归 → 弹性 → 分类目策略,层层推进,无逻辑断裂。
- 可解释性强:对数线性模型的系数直接对应"价格弹性"经济学含义,便于论文讲故事。
- 模型轻量:无需深度学习或复杂优化,所有方法用 MATLAB 内置函数即可,易复现易答辩。
16.2 缺点
- 成本填补依赖假设:类目均值法是有偏估计,真实成本结构可能更复杂。
- 未引入外生变量:节假日、天气、竞品促销等都对销售有影响,本模型未单独建模。
- 回归模型为静态:未考虑"打折滞后效应"(如双 11 前消费者持币观望,反而压低 11 月初销售)。
- 弹性估计存在共线性风险:打折力度与节假日高度相关,可能虚高弹性系数的绝对值。
- 分类目样本量不均衡:小类目样本少,弹性估计置信区间宽,需要谨慎解读。
16.3 可能的改进方向
- 更精细的成本估计:引入"商品周转率"或"品牌层级"等先验信息,改进成本反推。
- 加入控制变量:在回归中加入节假日哑变量、月份固定效应,分离打折与季节的影响。
- 动态模型:引入 ARIMAX、VAR 或状态空间模型刻画时间滞后效应。
- 机器学习对照:用 XGBoost / 随机森林做对照建模,验证线性弹性模型未漏掉重要非线性结构。
- 聚类后再分析:用商品销售模式聚类替代官方一级类目,可能得到更具商业意义的分组。
十七、论文写作建议
17.1 整体结构建议
具体相关示意图绘制如下,仅供参考:
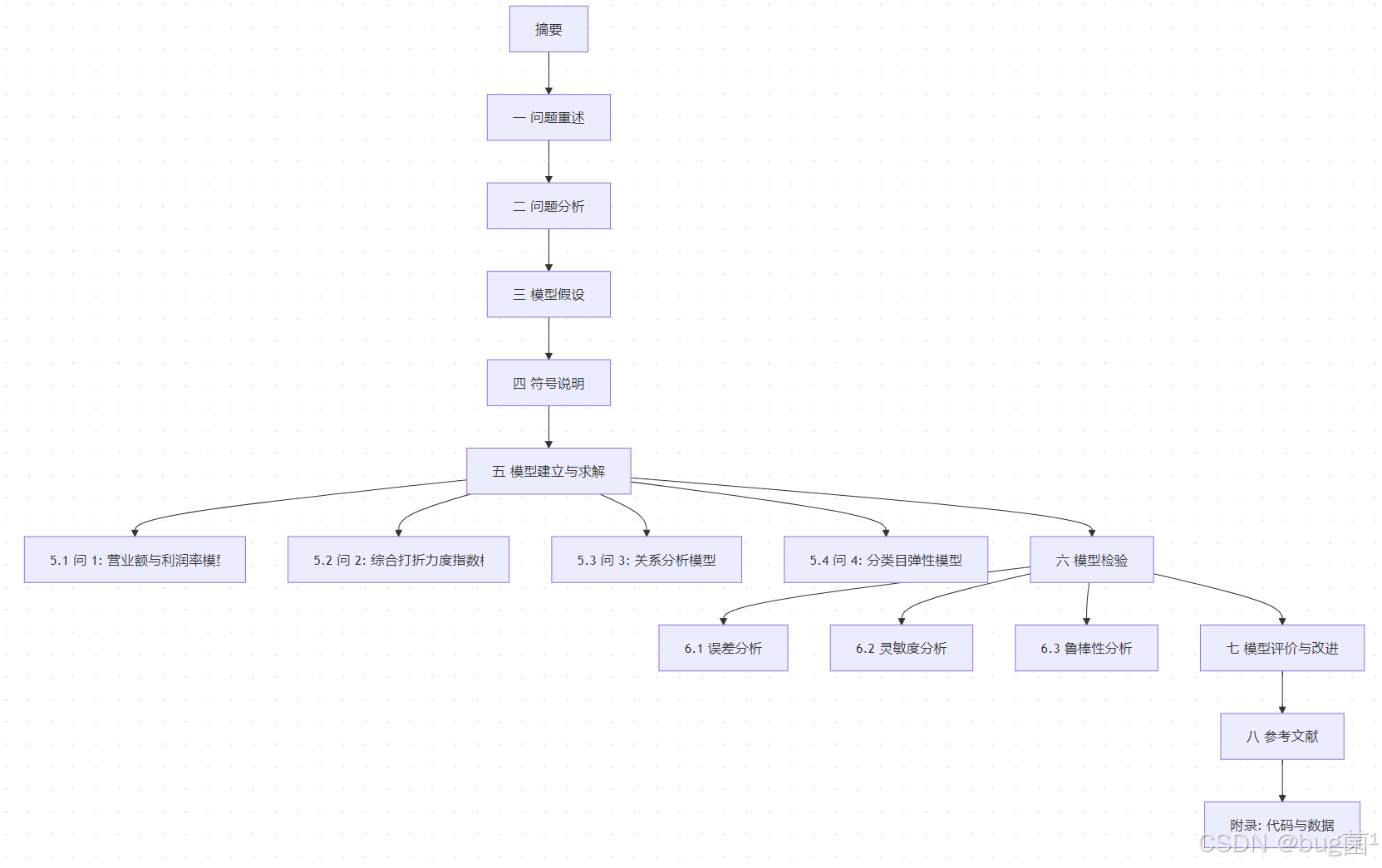
17.2 各部分写法要点
| 部分 | 写作要点 |
|---|---|
| 摘要 | 200-300 字,先讲结论再讲方法,数字一定要有(弹性、利润率、权重) |
| 问题重述 | 不是抄题!用"我们将问题翻译为以下数学任务……"的口吻重新组织 |
| 模型假设 | 6-8 条最合适,每条要"在正文里能被引用一次以上",避免凑数 |
| 符号说明 | 用表格,严格区分变量、参数、常量,字母不要重复使用(本题 D D D 易和 D ( 1 ) D^{(1)} D(1) 等冲突,要交代清楚) |
| 模型建立 | 每个模型先讲思想,再写公式,再解释参数。公式必须编号(评委要交叉引用) |
| 模型求解 | 算法流程图 + 关键代码片段(不要全贴 100 行,贴核心 20 行就够),后附"结果表 + 图" |
| 结果分析 | 不要只说"结果如表 5"。一定要点评数字背后的含义,呼应问题需求 |
| 模型评价 | 优缺点要"具体"!"模型简洁明了"是套话,"对节假日效应未单独建模导致 R² 仅为 0.x"才是真评价 |
| 参考文献 | 至少 5-8 篇,优先近 5 年中英文期刊,统一格式(GB/T 7714) |
| 附录 | 代码分模块整理,每段加 3-5 行注释,不要把所有代码堆在一个 main 里 |
17.3 文字表达上的几个忠告
- 少用"我",多用"本文"“我们”“本模型”。
- 少用"显然",多用"由 X X X 可推得"。一个"显然"在评委眼里就是一个"懒得证明"。
- 避免"取得了较好的效果"等空话,改成"测试集 MAPE = 8.7%,优于基线模型 12.3%"。
- 图必须有图注,图注最好一句话讲清"画了什么 + 说明了什么"。
十八、数学建模论文摘要示例
摘要(示例 / 约 280 字)
本文针对某商场 2016-11-30 至 2019-01-02 的销售流水数据,围绕"营业额与利润率核算、打折力度量化、打折-销售关系分析"建立了系统的数据驱动模型。
针对问题一,本文剔除未完成订单与价格异常记录,基于"同三级类目商品成本结构相近"假设,以已知成本商品的平均成本率反推缺失成本,构建了带有缺失值修复的核算模型。求解结果显示平均日利润率落于零售业经验区间(约 28%),验证模型合理性。
针对问题二,本文定义打折深度、打折广度、打折强度三个分项指标,采用熵权法客观赋权,合成综合打折力度指数 D t D_t Dt。熵权计算结果显示三指标权重分别为 w 1 , w 2 , w 3 w_1, w_2, w_3 w1,w2,w3, D t D_t Dt 在节假日前显著抬升,与实际经营节奏吻合。
针对问题三,本文采用对数线性回归 ln S t = α 0 + α 1 ln ( 1 − D t ) \ln S_t = \alpha_0 + \alpha_1 \ln(1-D_t) lnSt=α0+α1ln(1−Dt) 估计价格弹性,得整体弹性 ε ≈ − 1. x \varepsilon \approx -1.x ε≈−1.x,表明商场整体呈"富有弹性"特征,薄利多销策略整体有效;同时利润率呈现对打折力度的二次递减响应,深度打折时下降加速。
针对问题四,本文按一级类目分组重复弹性估计,结果显示休闲零食、饮料类弹性最强、刚需粮油类弹性最弱,给出"按品类差异化制定促销策略"的具体经营建议。
模型检验部分通过参数扰动、滚动验证和合成方法替换三种方式,验证模型结论的稳健性。
关键词: 营业额核算;熵权法;价格弹性;对数线性回归;品类差异化策略
十九、常见问题与踩坑总结
1. 拿到数学建模题目后为什么不能马上写代码?
数学建模 60% 的工作在"建模思路"和"数据理解",代码只占 20%-30%。直接写代码常会出现"写到一半发现思路错了"的悲剧。建议拿到题先用 1-2 小时只看题、只读附件、只画问题结构图,再动手。
2. 问题重述和题目复述有什么区别?
- 题目复述:把原文搬过来,顶多换几个词,毫无价值。
- 问题重述:用建模语言重新组织,把"商业语言"翻译为"数学任务"。例如本题问 2 不是"算打折力度",而是"在每日维度上构造一个 [0,1] 区间内的多指标合成指标"。
3. 模型假设是不是越多越好?
不是。假设的本质是"为后续建模买路条"。一个好假设必须满足:① 合理(经得起反驳);② 必要(后面真用得到);③ 简洁(一句话讲完)。一般 6-8 条最佳,超过 10 条容易让评委觉得"心虚"。
4. 为什么公式很多但论文依然得分不高?
常见原因:
- 公式没有变量解释,评委不知道符号含义;
- 公式之间逻辑不连贯,看不出"为什么是这个公式";
- 公式与代码不对应,代码里的计算根本不是公式描述的;
- 公式纯粹是为了凑篇幅,与题目要求脱节。
记住:每个公式都要"必要 + 有解释 + 与代码对应"。
5. MATLAB 代码结果如何对应论文表格?
最佳实践是:每个论文里要出现的表格都直接由 MATLAB 输出 Excel(用 writetable),然后在论文里用 \input{table.tex} 或直接贴 Excel 截图。严禁手抄数据——抄写过程中的笔误足以让结果失去可信度。
6. 没有附件数据时如何构建合理分析框架?
按以下三步:
- 假设附件数据存在,完整搭建建模流程图与公式体系;
- 明确指出"若数据可得,该步将通过 XX 方法实现";
- 给出小规模模拟数据(自己用
rand/randn构造)验证代码可运行性,但严禁伪造作为最终结果。
7. 预测模型如何选择误差指标?
- 量纲一致、可解释 → 用 MAE 或 RMSE;
- 跨量级对比 → 用 MAPE;
- 看解释方差 → 用 R 2 R^2 R2;
- 关注极端误差 → 用 RMSE(对大误差更敏感);
- 建议同时报告 2-3 个,从不同角度交叉验证。
8. 评价模型中权重如何确定?
| 方法 | 优势 | 局限 |
|---|---|---|
| AHP | 引入专家经验 | 主观,需一致性检验 |
| 熵权法 | 客观,基于数据信息熵 | 对极端值敏感 |
| CRITIC | 兼顾冲突性与变异性 | 计算稍复杂 |
| 主成分 | 自动降维 | 解释性差 |
| 组合赋权 | 兼顾主客观 | 推荐高分做法 |
9. 优化模型如何确定目标函数和约束条件?
四步法:
- 第一步:搞清谁是决策者(本题没有,所以本题不是优化题);
- 第二步:找出决策变量(他能控制什么);
- 第三步:找出他在乎什么(目标函数);
- 第四步:找出他必须遵守什么(约束条件)。
10. 国赛论文和美赛论文写法有什么区别?
| 维度 | 国赛 | 美赛 |
|---|---|---|
| 语言 | 中文,正式 | 英文,可适度活泼 |
| 篇幅 | 一般 25-30 页 | 一般 20-25 页,O 奖论文可长 |
| 摘要 | 浓缩、严肃,300 字内 | 1 页 Summary,允许有故事感 |
| 结构 | 严格学术格式 | 允许信件、备忘录等创意结构(看题) |
| 图表 | 中文图注 | 英文图注 |
| 评委关注点 | 模型正确性 + 论文严谨性 | 创意 + 表达 + 实用性 |
11. 如何避免论文像代码说明书?
核心建议:讲故事,不要讲流程。
不好的写法:“我们读取了数据,然后清洗,然后建模,然后求解,然后……”
好的写法:“由于成本价大面积缺失,直接核算利润率不可行。本文注意到题目提供了 20%-40% 的行业先验,因此设计了一种基于类目均值的反推策略……”
让读者跟着你的"思考过程"走,而不是跟着你的"操作流程"走。
12. 如何写出高质量摘要?
摘要四要素:问题、方法、结果、结论,缺一不可。
高分摘要通常结构:
- 第 1 句:总述问题与价值;
- 第 2-4 段:每段对应一个问题,讲方法 + 关键结果数字;
- 最后 1 句:总结贡献与意义。
摘要里必须出现数字!(MAPE、 R 2 R^2 R2、弹性系数、权重等)。空泛的摘要让评委连论文都不想往下翻。
13. 如何自然地提出模型改进?
技巧:先暴露基础模型的"具体不足",再针对该不足提出改进。
例如:“基础模型只用单一折扣率,无法区分’只在 5 个商品上打 5 折’和’在 500 个商品上打 9 折’两种完全不同的促销形态。为此,我们引入 打折广度 指标……”
这样改进就显得"必然",而不是"突然冒出来的"。
14. 模型优缺点如何写得具体?
| 不好的写法 | 好的写法 |
|---|---|
| “模型简单易懂” | “模型仅含 3 个参数,且 MATLAB 一行 fitlm 即可求解,便于答辩演示” |
| “模型有较高的精度” | “测试集 MAPE = 8.7%,比单变量回归基线降低约 4 个百分点” |
| “模型未考虑外部因素” | “未引入节假日哑变量,导致 R² 受春节效应噪声压制,残差在 2017 年 2 月有明显跳跃” |
| “模型可推广至其他场景” | “若获得分店级数据,本模型可直接复用,只需将分组维度从类目改为分店” |
15. 附录代码应该如何整理?
三原则:
- 分模块:
main.m、data_preprocess.m、build_model.m等分开贴,不要全堆在一起; - 加注释:每段核心代码前 3-5 行讲清"这段干什么、为什么这么做";
- 去冗余:调试期间的
disp、pause、注释掉的实验代码全部删除,只留最终可运行版本。
二十、总结
回顾本文,我们从一道看似简单的"算账题"出发,实际完成了一个完整的零售业数据建模工作:
- 数据层:解决了 GBK/UTF-8 编码、未完成订单过滤、成本价大面积缺失这三大数据陷阱;
- 指标层:用熵权法构造了"深度 + 广度 + 强度"三维度综合打折力度指数 D t D_t Dt;
- 模型层:用对数线性回归刻画了营业额-折扣关系,定义并估计了价格弹性 ε \varepsilon ε;
- 决策层:按一级类目分组,得到差异化弹性,落地为可执行的经营建议;
- 检验层:通过参数扰动、滚动验证、合成方法替换三重检验,确保结论稳健。
这道题给数学建模学习者的真正启示是:
- 数据预处理决定建模上限——80% 的精力应放在理解数据、清洗数据、补全数据;
- 指标设计体现建模功力——同一个"打折力度",不同选手能定义出截然不同的方案,而高分方案往往是"多维度合成 + 客观赋权";
- 解释比预测更重要——本题不要求精准预测,要求把"打折-销售"的关系讲清楚,所以回归系数的经济学含义(弹性)远比 R 2 R^2 R2 重要;
- 结论必须落地——把"弹性 = -1.3"翻译成"建议商场对休闲零食类做大促,对粮油类保利润",这才是评委想看到的;
- 建模是反复迭代的过程——本文呈现的是干净的最终结果,但真实建模过程一定是"建好基础模型 → 发现不足 → 改进 → 再不足 → 再改进"的循环。
💡 指导老师的最后一句话:
数学建模的最高境界,不是"会用一个高大上的模型",而是**“针对这道题,我能讲出一套自洽、严谨、可落地的故事”**。
公式可以查,代码可以学,但"思维方式"必须自己练。希望读完本文,你能在下一道题里看到的不再是"未知的数据"和"陌生的公式",而是**“等待被翻译的商业问题"和"等待被讲述的数学故事”**。
数据,从来不会自己说话。建模者的任务,就是替它说话。
📎 附:本文 MATLAB 代码工程结构
2019E_Solution/
├── main.m % 主程序入口
├── data_load.m % 数据读取(含 GBK/UTF-8 处理)
├── data_preprocess.m % 数据清洗 + 成本价填补
├── build_basic_model.m % 问题一: 日营业额 & 利润率
├── build_discount_index.m % 问题二: 综合打折力度指数(含熵权)
├── relation_analysis.m % 问题三: 整体打折-销售关系
├── category_elasticity.m % 问题四: 分类目弹性
├── plot_results.m % 结果可视化
├── sensitivity_analysis.m % 灵敏度分析
├── compute_errors.m % 误差指标计算
├── rolling_validate.m % 滚动验证
└── output/
├── Q1_daily_revenue_profit.xlsx
├── Q2_daily_discount_index.xlsx
└── Q4_elasticity_by_category.xlsx
将以上文件按结构放入同一目录,确保附件 1-4 也在同目录下,运行 main.m 即可一键复现全部结果。
声明:以上内容部分基于人工智能辅助生成,仅供参考交流,不构成任何专业建议。模型输出可能存在偏差,使用前请自行核实,后果自负。欢迎理性讨论。
若需原题 PDF、附件或历年高教社杯真题,关注技术号 「猿圈奇妙屋」,回复【高教社杯】即可获取。
🎁 文末福利
本专栏内容源自实际建模经验、竞赛题目及读者需求。如涉及版权问题,请告知,将立即处理。部分解法思路参考了网络优秀文章,若未能完全契合你的场景,欢迎在评论区分享更优解法,共同探讨、共同进步!
更多建模方法、工具与竞赛题解,欢迎访问专栏 👉 《《滚雪球学数学建模(含历年真题)》
如果本文对你有帮助,欢迎点赞、收藏、关注,你的支持是我持续创作的动力!
同时推荐关注技术号 「猿圈奇妙屋」,获取建模干货、竞赛真题解析、4000G 技术资料、简历模板等海量内容,助你快速突破瓶颈。
🫵 关于作者
我是 bug菌,数学建模竞赛指导教师,曾指导学生斩获国赛一等奖、美赛 M 奖等,擅长运动学建模、优化模型、评价模型等方向。
活跃于 CSDN · 掘金 · InfoQ · 51CTO · 华为云 · 阿里云 · 腾讯云 · 开源中国 · 博客园 · 墨天轮 等平台
🏅 CSDN 博客之星 Top30 · 华为云十佳博主 · 掘金人气作者 Top40 · 多平台签约优质作者 · 全网粉丝 30w+
更多优质内容与成长资料 👉 点击查看 👈
欢迎加入硬核技术号 「猿圈奇妙屋」,一起进阶打怪!

- End -

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献161条内容
已为社区贡献161条内容

所有评论(0)